07 | @Entity 之间的关联关系注解如何正确使用?
实体与实体之间的关联关系一共分为四种,分别为 OneToOne、OneToMany、ManyToOne 和 ManyToMany;而实体之间的关联关系又分为双向的和单向的。实体之间的关联关系是在 JPA 使用中最容易发生问题的地方,接下来我将一一揭晓并解释。我们先看一下 OneToOne,即一对一的关联关系。
@OneToOne 关联关系
@OneToOne 一般表示对象之间一对一的关联关系,它可以放在 field 上面,也可以放在 get/set 方法上面。其中 JPA 协议有规定,如果是配置双向关联,维护关联关系的是拥有外键的一方,而另一方必须配置 mappedBy;如果是单项关联,直接配置在拥有外键的一方即可。
举个例子:user 表是用户的主信息,user_info 是用户的扩展信息,两者之间是一对一的关系。user_info 表里面有一个 user_id 作为关联关系的外键,如果是单项关联,我们的写法如下:
复制代码
package com.example.jpa.example1;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User {@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;private String name;private String email;private String sex;private String address;
}
User 实体里面什么都没变化,不需要添加 @OneToOne 注解。我们只需要在拥有外键的一方配置就可以,所以 UserInfo 的代码如下:
复制代码
package com.example.jpa.example1;
import lombok.*;
import javax.persistence.*;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "user")
public class UserInfo {@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;private Integer ages;private String telephone;@OneToOne //维护user的外键关联关系,配置一对一private User user;
}
我们看到,UserInfo 实体对象里面添加了 @OneToOne 注解,这时我们写一个测试用例跑一下看看有什么效果:
复制代码
Hibernate: create table user (id bigint not null, address varchar(255), email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: create table user_info (id bigint not null, ages integer, telephone varchar(255), user_id bigint, primary key (id))
Hibernate: alter table user_info add constraint FKn8pl63y4abe7n0ls6topbqjh2 foreign key (user_id) references user
因为我们新建了两个实体,跑任何一个 @SpringDataTest 就会看到上面有三个 sql 在执行,分别创建了两张表,而在 user_info 表上面还创建了一个外键索引。
上面我们说了单项关联关系,那么双向关联应该怎么配置呢?我们保持 UserInfo 不变,在 User 实体对象里面添加这一段代码即可。
复制代码
@OneToOne(mappedBy = "user")
private UserInfo userInfo;
完整的 User 实体对象就会变成如下模样。
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User {@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;private String name;private String email;@OneToOne(mappedBy = "user")private UserInfo userInfo;//变化之处private String sex;private String address;
}
我们跑任何一个测试用例,就会看到运行结果是一样的,还是上面三条 sql。那么我们再查看一下 @OneToOne 源码,看看其支持的配置都有哪些。
@interface OneToOne 源码解读
下面我列举了@OneToOne 的源码,并加以解读。通过这些你可以了解 @OneToOne 的用法。
复制代码
public @interface OneToOne {//表示关系目标实体,默认该注解标识的返回值的类型的类。Class targetEntity() default void.class;//cascade 级联操作策略,就是我们常说的级联操作CascadeType[] cascade() default {};//数据获取方式EAGER(立即加载)/LAZY(延迟加载)FetchType fetch() default EAGER;//是否允许为空,默认是可选的,也就表示可以为空;boolean optional() default true;//关联关系被谁维护的一方对象里面的属性名字。 双向关联的时候必填String mappedBy() default "";//当被标识的字段发生删除或者置空操作之后,是否同步到关联关系的一方,即进行通过删除操作,默认flase,注意与CascadeType.REMOVE 级联删除的区别boolean orphanRemoval() default false;
}
mappedBy 注意事项
只有关联关系的维护方才能操作两个实体之间外键的关系。被维护方即使设置了维护方属性进行存储也不会更新外键关联。
mappedBy 不能与 @JoinColumn 或者 @JoinTable 同时使用,因为没有意义,关联关系不在这里面维护。
此外,mappedBy 的值是指另一方的实体里面属性的字段,而不是数据库字段,也不是实体的对象的名字。也就是维护关联关系的一方属性字段名称,或者加了 @JoinColumn / @JoinTable 注解的属性字段名称。如上面的 User 例子 user 里面 mappedBy 的值,就是 UserInfo 里面的 user 字段的名字。
CascadeType用法
在 CascadeType 的用法中,CascadeType 的枚举值只有五个,分别如下:
- CascadeType.PERSIST 级联新建
- CascadeType.REMOVE 级联删除
- CascadeType.REFRESH 级联刷新
- CascadeType.MERGE 级联更新
- CascadeType.ALL 四项全选
其中,默认是没有级联操作的,关系表不会产生任何影响。此外,JPA 2.0 还新增了 CascadeType.DETACH,即级联实体到 Detach 状态。
了解了枚举值,下面我们来测试一下级联新建和级联删除。
首先,修改 UserInfo 里面的关键代码如下,并在 @OneToOne 上面添加
cascade ={CascadeType.PERSIST,CascadeType.REMOVE},如下:
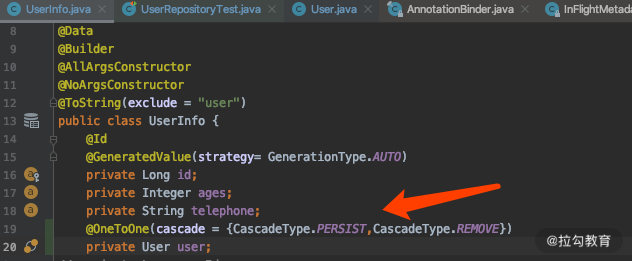
其次,我们新增一个测试方法。
复制代码
@Test@Rollback(false)public void testUserRelationships() throws JsonProcessingException {User user = User.builder().name("jackxx").email("123456@126.com").build();UserInfo userInfo = UserInfo.builder().ages(12).user(user).telephone("12345678").build();//保存userInfo的同上也会保存User信息userInfoRepository.saveAndFlush(userInfo);//删除userInfo,同时也会级联的删除user记录userInfoRepository.delete(userInfo);
}
最后,运行一下看看效果。
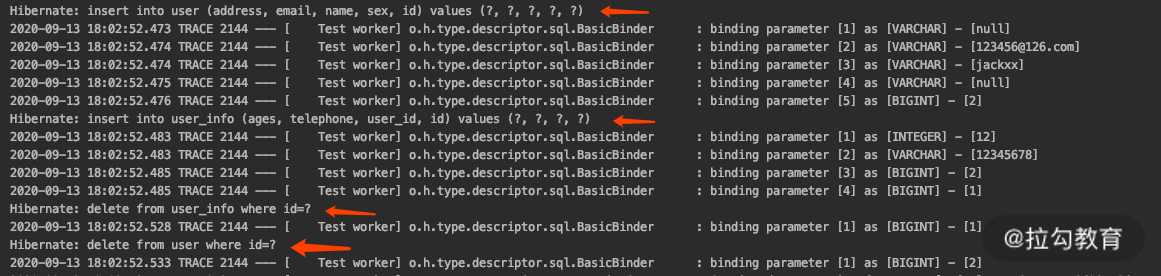
从上面的运行结果可以看到,上面的测试在执行了 insert 的时候,会执行两条 insert 的sql 和两条 delete 的 sql,这就体现出了 CascadeType.PERSIST 和 CascadeType.REMOVE 的作用。
上面讲了级联删除的场景,下面我们再说一下关联关系的删除场景该怎么做。
orphanRemoval 属性用法
orphanRemoval 表示当关联关系被删除的时候,是否应用级联删除,默认 false。什么意思呢?测试一下你就会明白。
首先,还沿用上面的例子,当我们删除 userInfo 的时候,把 User 置空,作如下改动。
复制代码
userInfo.setUser(null);
userInfoRepository.delete(userInfo);
其次,我们再运行测试,看看效果。
复制代码
Hibernate: delete from user_info where id=?
这时候你就会发现,少了一条删除 user 的 sql,说明没有进行级联删除。那我们再把 UserInfo 做一下调整。
复制代码
public class UserInfo {@OneToOne(cascade = {CascadeType.PERSIST},orphanRemoval = true)private User user;....其他没变的代码省了
}
然后,我们把 CascadeType.Remove 删除了,不让它进行级联删除,但是我们把 orphanRemoval 设置成 true,即当关联关系变化的时候级联更新。我们看下完整的测试用例。
复制代码
@Testpublic void testUserRelationships() throws JsonProcessingException {User user = User.builder().name("jackxx").email("123456@126.com").build();UserInfo userInfo = UserInfo.builder().ages(12).user(user).telephone("12345678").build();userInfoRepository.saveAndFlush(userInfo);userInfo.setAges(13);userInfo.setUser(null);//还是通过这个设置user数据为空userInfoRepository.delete(userInfo);
}
这个时候我们看一下运行结果。
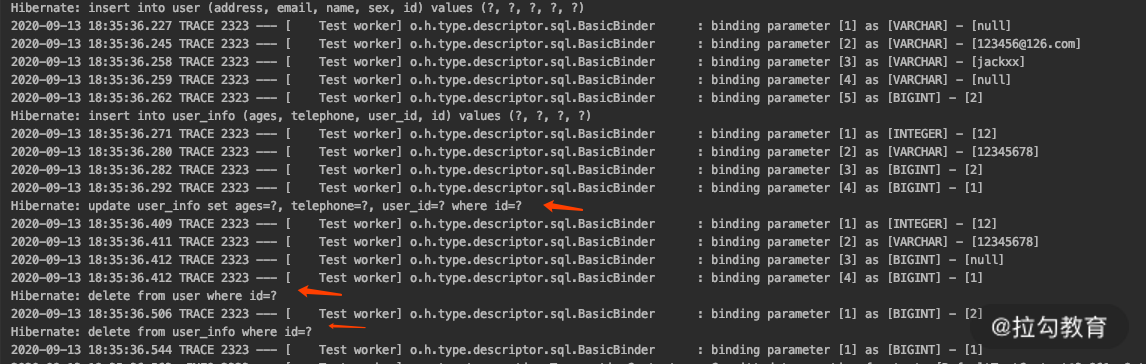
从中我们可以看到,结果依然是两个 inser 和两个 delete,但是中间多了一个 update。我来解释一下,因为去掉了 CascadeType.REMOVE,这个时候不会进行级联删除了。当我们把 user 对象更新成空的时候,就会执行一条 update 语句把关联关系去掉了。
而为什么又出现了级联删除 user 呢?因为我们修改了集合关联关系,orphanRemoval 设置为 true,所以又执行了级联删除的操作。这一点你可以仔细体会一下 orphanRemoval 和 CascadeType.REMOVE 的区别。
到这里,@OneToOne 关联关系介绍完了,接下来我们看一下日常工作常见的场景,先看场景一:主键和外键都是同一个字段的情况。
主键和外键都是同一个字段
我们假设 user 表是主表,user_info 的主键是 user_id,并且 user_id=user 是表里面的 id,那我们应该怎么写?
继续沿用上面的例子,User 实体不变,我们看看 UserInfo 变成什么样了。
复制代码
public class UserInfo implements Serializable {@Idprivate Long userId;private Integer ages;private String telephone;@MapsId@OneToOne(cascade = {CascadeType.PERSIST},orphanRemoval = true)private User user;
}
这里的做法很简单,我们直接把 userId 设置为主键,在 @OneToOne 上面添加 @MapsId 注解即可。@MapsId 注解的作用是把关联关系实体里面的 ID(默认)值 copy 到 @MapsId 标注的字段上面(这里指的是 user_id 字段)。
接着,上面的测试用例我们跑一下,看一下效果。
复制代码
Hibernate: create table user (id bigint not null, address varchar(255), email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: create table user_info (ages integer, telephone varchar(255), user_id bigint not null, primary key (user_id))
Hibernate: alter table user_info add constraint FKn8pl63y4abe7n0ls6topbqjh2 foreign key (user_id) references user
在启动的时候,我们直接创建了 user 表和 user_info 表,其中 user_info 的主键是 user_id,并且通过外键关联到了 user 表的 ID 字段,那么我们同时看一下 inser 的 sql,也发生了变化。
复制代码
Hibernate: insert into user (address, email, name, sex, id) values (?, ?, ?, ?, ?)
Hibernate: insert into user_info (ages, telephone, user_id) values (?, ?, ?)
上面就是我们讲的实战场景一,主键和外键都是同一个字段。接下来我们再说一个场景,就是在查 user_info 的时候,我们只想知道 user_id 的值就行了,不需要查 user 的其他信息,具体我们应该怎么做呢?
@OneToOne 延迟加载,我们只需要 ID 值
在 @OneToOne 延迟加载的情况下,我们假设只想查下 user_id,而不想查看 user 表其他的信息,因为当前用不到,可以有以下几种做法。
第一种做法:还是 User 实体不变,我们改一下 UserInfo 对象,如下所示:
复制代码
package com.example.jpa.example1;
import lombok.*;
import javax.persistence.*;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "user")
public class UserInfo{@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;private Integer ages;private String telephone;@MapsId@OneToOne(cascade = {CascadeType.PERSIST},orphanRemoval = true,fetch = FetchType.LAZY)private User user;
}
从上面这段代码中,可以看到做的更改如下:
- id 字段我们先用原来的
- @OneToOne 上面我们添加 @MapsId 注解
- @OneToOne 里面的 fetch = FetchType.LAZY 设置延迟加载
接着,我们改造一下测试类,完整代码如下:
复制代码
@DataJpaTest
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class UserInfoRepositoryTest {@Autowiredprivate UserInfoRepository userInfoRepository;@BeforeAll@Rollback(false)@Transactionalvoid init() {User user = User.builder().name("jackxx").email("123456@126.com").build();UserInfo userInfo = UserInfo.builder().ages(12).user(user).telephone("12345678").build();userInfoRepository.saveAndFlush(userInfo);}/*** 测试用User关联关系操作** @throws JsonProcessingException*/@Test@Rollback(false)public void testUserRelationships() throws JsonProcessingException {UserInfo userInfo1 = userInfoRepository.getOne(1L);System.out.println(userInfo1);System.out.println(userInfo1.getUser().getId());
}
然后,我们跑一下测试用例,看看测试结果。
复制代码
Hibernate: insert into user (address, email, name, sex, id) values (?, ?, ?, ?, ?)
Hibernate: insert into user (address, email, name, sex, id) values (?, ?, ?, ?, ?)
两条inser照旧,而只有一个select
Hibernate: select userinfo0_.user_id as user_id3_6_0_, userinfo0_.ages as ages1_6_0_, userinfo0_.telephone as telephon2_6_0_ from user_info userinfo0_ where userinfo0_.user_id=?
最后你会发现,打印的结果符合预期。
复制代码
UserInfo(id=1, ages=12, telephone=12345678)
1
接下来介绍第二种做法,这种做法很简单,只要在 UserInfo 对象里面直接去掉 @OneToOne 关联关系,新增下面的字段即可。
复制代码
@Column(name = "user_id")
private Long userId;
第三做法是利用 Hibernate,它给我们提供了一种字节码增强技术,通过编译器改变 class 解决了延迟加载问题。这种方式有点复杂,需要在编译器引入 hibernateEnhance 的相关 jar 包,以及编译器需要改变 class 文件并添加 lazy 代理来解决延迟加载。我不太推荐这种方式,因为太复杂,你知道有这回事就行了。
以上我们掌握了这么多用法,那么最佳实践是什么?双向关联更好还是单向关联更好?根据最近几年的应用,我总结出了一些最佳实践,我们来看一下。
@OneToOne 的最佳实践是什么?
第一,我要说一种 Java 面向对象的设计原则:开闭原则。
即对扩展开放,对修改关闭。如果我们一直使用双向关联,两个实体的对象耦合太严重了。想象一下,随着业务的发展,User 对象可能是原始对象,围绕着 User 可能会扩展出各种关联对象。难道 User 里面每次都要修改,去添加双向关联关系吗?肯定不是,否则时间长了,对象与对象之间的关联关系就是一团乱麻。
所以,我们尽量、甚至不要用双向关联,如果非要用关联关系的话,只用单向关联就够了。双向关联正是 JPA 的强大之处,但同时也是问题最多,最被人诟病之处。所以我们要用它的优点,而不是学会了就一定要使用。
第二,我想说 CascadeType 很强大,但是我也建议保持默认。
即没有级联更新动作,没有级联删除动作。还有 orphanRemoval 也要尽量保持默认 false,不做级联删除。因为这两个功能很强大,但是我个人觉得这违背了面向对象设计原则里面的“职责单一原则”,除非你非常非常熟悉,否则你在用的时候会时常感到惊讶——数据什么时间被更新了?数据被谁删除了?遇到这种问题查起来非常麻烦,因为是框架处理,有的时候并非预期的效果。
一旦生产数据被莫名更新或者删除,那是一件非常糟糕的事情。因为这些级联操作会使你的方法名字没办法命名,而且它不是跟着业务逻辑变化的,而是跟着实体变化的,这就会使方法和对象的职责不单一。
第三,我想告诉你,所有用到关联关系的地方,能用 Lazy 的绝对不要用 EAGER,否则会有 SQL 性能问题,会出现不是预期的 SQL。
以上三点是我总结的避坑指南,有经验的同学这时候会有个疑问:外键约束不是不推荐使用的吗?如果我的外键字段名不是约定的怎么办?别着急,我们再看一下 @JoinColumn 注解和 @JoinColumns 注解。
@JoinCloumns & JoinColumn
这两个注解是集合关系,他们可以同时使用,@JoinColumn 表示单字段,@JoinCloumns 表示多个 @JoinColumn,我们来一一看一下。
我们还是先直接看一下 @JoinColumn 源码,了解下这一注解都有哪些配置项。
复制代码
public @interface JoinColumn {//关键的字段名,默认注解上的字段名,在@OneToOne代表本表的外键字段名字;String name() default "";//与name相反关联对象的字段,默认主键字段String referencedColumnName() default "";//外键字段是否唯一boolean unique() default false;//外键字段是否允许为空boolean nullable() default true;//是否跟随一起新增boolean insertable() default true;//是否跟随一起更新boolean updatable() default true;//JPA2.1新增,外键策略ForeignKey foreignKey() default @ForeignKey(PROVIDER_DEFAULT);
}
其次,我们看一下 @ForeignKey(PROVIDER_DEFAULT) 里面枚举值有几个。
复制代码
public enum ConstraintMode {//创建外键约束CONSTRAINT,//不创建外键约束NO_CONSTRAINT,//采用默认行为PROVIDER_DEFAULT
}
然后,我们看看这个注解的语法,就可以解答我们上面的两个问题。修改一下 UserInfo,如下所示:
复制代码
public class UserInfo{@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;private Integer ages;private String telephone;@OneToOne(cascade = {CascadeType.PERSIST},orphanRemoval = true,fetch = FetchType.LAZY)@JoinColumn(foreignKey = @ForeignKey(ConstraintMode.NO_CONSTRAINT),name = "my_user_id")private User user;
...其他不变}
可以看到,我们在其中指定了字段的名字:my_user_id,并且指定 NO_CONSTRAINT 不生成外键。而测试用例不变,我们看下运行结果。
复制代码
Hibernate: create table user (id bigint not null, address varchar(255), email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: create table user_info (id bigint not null, ages integer, telephone varchar(255), my_user_id bigint, primary key (id))
这时我们看到 user_info 表里面新增了一个字段 my_user_id,insert 的时候也能正确 inser my_user_id 的值等于 user.id。
复制代码
Hibernate: insert into user_info (ages, telephone, my_user_id, id) values (?, ?, ?, ?)
而 @JoinColumns 是 JoinColumns 的复数形式,就是通过两个字段进行的外键关联,这个不常用,我们看一个 demo 了解一下就好。
复制代码
@Entity
public class CompanyOffice {@ManyToOne(fetch = FetchType.LAZY)@JoinColumns({@JoinColumn(name="ADDR_ID", referencedColumnName="ID"),@JoinColumn(name="ADDR_ZIP", referencedColumnName="ZIP")})private Address address;
}
上面的实例中,CompanyOffice 通过 ADDR_ID 和 ADDR_ZIP 两个字段对应一条 address 信息,解释了一下@JoinColumns的用法。
如果你了解了 @OneToOne 的详细用法,后面要讲的几个注解就很好理解了,因为他们有点类似,那么我们接下来看看 @ManyToOne 和 @OneToMany 的用法。
@ManyToOne& @OneToMany
@ManyToOne 代表多对一的关联关系,而 @OneToMany 代表一对多,一般两个成对使用表示双向关联关系。而 JPA 协议中也是明确规定:维护关联关系的是拥有外键的一方,而另一方必须配置 mappedBy。看下面的代码。
复制代码
public @interface ManyToOne {Class targetEntity() default void.class;CascadeType[] cascade() default {};FetchType fetch() default EAGER;boolean optional() default true;
}public @interface OneToMany {Class targetEntity() default void.class;//cascade 级联操作策略:(CascadeType.PERSIST、CascadeType.REMOVE、CascadeType.REFRESH、CascadeType.MERGE、CascadeType.ALL)
如果不填,默认关系表不会产生任何影响。CascadeType[] cascade() default {};
//数据获取方式EAGER(立即加载)/LAZY(延迟加载)FetchType fetch() default LAZY;//关系被谁维护,单项的。注意:只有关系维护方才能操作两者的关系。String mappedBy() default "";
//是否级联删除。和CascadeType.REMOVE的效果一样。两种配置了一个就会自动级联删除boolean orphanRemoval() default false;
}
我们看到上面的字段和 @OneToOne 里面的基本一样,用法是一样的,不过需要注意以下几点:
- @ManyToOne 一定是维护外键关系的一方,所以没有 mappedBy 字段;
- @ManyToOne 删除的时候一定不能把 One 的一方删除了,所以也没有 orphanRemoval 的选项;
- @ManyToOne 的 Lazy 效果和 @OneToOne 的一样,所以和上面的用法基本一致;
- @OneToMany 的 Lazy 是有效果的。
我们看个例子,假设 User 有多个地址 Address,我们看看实体应该如何建立。
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable {@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;private String name;private String email;private String sex;@OneToMany(mappedBy = "user",fetch = FetchType.LAZY)private List<UserAddress> address;
}
上述代码我们可以看到,@OneToMany 双向关联并且采用 LAZY 的机制;这时我们新建一个 UserAddress 实体维护关联关系如下:
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "user")
public class UserAddress {@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;private String address;@ManyToOne(cascade = CascadeType.ALL)private User user;
}
再新建一个测试用例,完整代码如下:
复制代码
package com.example.jpa.example1;
import com.fasterxml.jackson.core.JsonProcessingException;
import org.assertj.core.util.Lists;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.TestInstance;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import org.springframework.test.annotation.Rollback;
import javax.transaction.Transactional;
@DataJpaTest
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class UserAddressRepositoryTest {@Autowiredprivate UserAddressRepository userAddressRepository;@Autowiredprivate UserRepository userRepository;/*** 负责添加数据*/@BeforeAll@Rollback(false)@Transactionalvoid init() {User user = User.builder().name("jackxx").email("123456@126.com").build();UserAddress userAddress = UserAddress.builder().address("shanghai1").user(user).build();UserAddress userAddress2 = UserAddress.builder().address("shanghai2").user(user).build();userAddressRepository.saveAll(Lists.newArrayList(userAddress,userAddress2));}/*** 测试用User关联关系操作* @throws JsonProcessingException*/@Test@Rollback(false)public void testUserRelationships() throws JsonProcessingException {User user = userRepository.getOne(2L);System.out.println(user.getName());System.out.println(user.getAddress());}
}
然后,我们看一下运行结果。
复制代码
Hibernate: create table user (id bigint not null, email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: create table user_address (id bigint not null, address varchar(255), user_id bigint, primary key (id))
Hibernate: alter table user_address add constraint FKk2ox3w9jm7yd6v1m5f68xibry foreign key (user_id) references user
接着我们创建两张表,并且创建外键。
复制代码
Hibernate: insert into user (email, name, sex, id) values (?, ?, ?, ?)
Hibernate: insert into user_address (address, user_id, id) values (?, ?, ?)
Hibernate: insert into user_address (address, user_id, id) values (?, ?, ?)
这时我们得到了符合预期的三条 inser 语句,可以看到 lazy 起作用了,说明了只有用到 address 的时候才会取重新加载 SQL。

综上,@ManyToOne 的 lazy 机制和用法,与 @OneToOne 的一样,我们就不过多介绍了。而 @ManyToOne 和 @OneToMany 的最佳实践,与 @OneToOne 的完全一样,也是尽量避免双向关联,一切级联更新和 orphanRemoval 都保持默认规则,并且 fetch 采用 lazy 延迟加载。
以上就是关于 @ManyToOne 和 @OneToMan 的讲解,实际开发过程中可以详细体会一下上面老师讲的用法。接下来我们介绍一下 @ManyToMany 多对多关联关系的用法。
@ManyToMany
@ManyToMany 代表多对多的关联关系,这种关联关系任何一方都可以维护关联关系。我们还是先看个例子感受一下。
我们假设 user 表和 room 表是多对多的关系,看看两个实体怎么写。
复制代码
package com.example.jpa.example1;
import lombok.*;
import javax.persistence.*;
import java.io.Serializable;
import java.util.List;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User{@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;private String name;@ManyToMany(mappedBy = "users")private List<Room> rooms;
}
接着,我们让 Room 维护关联关系。
复制代码
package com.example.jpa.example1;
import lombok.*;
import javax.persistence.*;
import java.util.List;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "users")
public class Room {@Id@GeneratedValue(strategy = GenerationType.AUTO)private Long id;private String title;@ManyToManyprivate List<User> users;
}
然后,我们跑一下测试用例,可以看到如下结果:
复制代码
Hibernate: create table room (id bigint not null, title varchar(255), primary key (id))
Hibernate: create table room_users (rooms_id bigint not null, users_id bigint not null)
Hibernate: create table user (id bigint not null, email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: alter table room_users add constraint FKld9phr4qt71ve3gnen43qxxb8 foreign key (users_id) references user
Hibernate: alter table room_users add constraint FKtjvf84yquud59juxileusukvk foreign key (rooms_id) references room
从结果上我们看到 JPA 帮我们创建的三张表中,room_users 表维护了 user 和 room 的多对多关联关系。其实这个情况还告诉我们一个道理:当用到 @ManyToMany 的时候一定是三张表,不要想着建两张表,两张表肯定是违背表的设计原则的。
那么我们看下 @ManyToMany 的语法。
复制代码
public @interface ManyToMany {Class targetEntity() default void.class;CascadeType[] cascade() default {};FetchType fetch() default LAZY;String mappedBy() default "";
}
源码里面字段就这么多,基本和上面雷同,我就不多介绍了。这个时候有的同学可能会问,我们怎么去掉外键索引?怎么改中间表的表名?怎么指定外键字段的名字呢?我们继续引入另外一个注解——@JoinTable。
我先看一下例子,修改一下 Room 里面的内容。
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "users")
public class Room {@Id@GeneratedValue(strategy = GenerationType.AUTO)private Long id;private String title;@ManyToMany@JoinTable(name = "user_room_ref",joinColumns = @JoinColumn(name = "room_id_x"),inverseJoinColumns = @JoinColumn(name = "user_id_x"))private List<User> users;
}
接着,我们在 Room 里面添加了 @JoinTable 注解,看一下 junit 的运行结果。
复制代码
Hibernate: create table room (id bigint not null, title varchar(255), primary key (id))
Hibernate: create table user (id bigint not null, email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: create table user_room_ref (room_id_x bigint not null, user_id_x bigint not null)
Hibernate: alter table user_room_ref add constraint FKoxolr1eyfiu69o45jdb6xdule foreign key (user_id_x) references user
Hibernate: alter table user_room_ref add constraint FK2sl9rtuxo9w130d83e19f3dd9 foreign key (room_id_x) references room
到这里可以看到,我们创建了一张中间表,并且添加了两个在预想之内的外键关系。
复制代码
public @interface JoinTable {//中间关联关系表明String name() default "";//表的catalogString catalog() default "";//表的schemaString schema() default "";//维护关联关系一方的外键字段的名字JoinColumn[] joinColumns() default {};//另一方的表外键字段JoinColumn[] inverseJoinColumns() default {};//指定维护关联关系一方的外键创建规则ForeignKey foreignKey() default @ForeignKey(PROVIDER_DEFAULT);//指定另一方的外键创建规则ForeignKey inverseForeignKey() default @Forei gnKey(PROVIDER_DEFAULT);
}
那么通过上面的介绍,你知道了 @ManyToMany 的用法,然而实际开发者对 @ManyToMany 用得比较少,一般我们会用成对的 @ManyToOne 和 @OneToMany 代替,因为我们的中间表可能还有一些约定的公共字段,如 ID、update_time、create_time等其他字段。
利用 @ManyToOne 和 @OneToMany 表达多对多的关联关系
我们修改一下上面的 Demo,来看一下通过 @ManyToOne 和 @OneToMany 如何表达多对多的关联关系。
我们新建一张表 user_room_relation 来存储双方的关联关系和额外字段,实体如下:
复制代码
package com.example.jpa.example1;
import lombok.*;
import javax.persistence.*;
import java.util.Date;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class UserRoomRelation {@Id@GeneratedValue(strategy = GenerationType.AUTO)private Long id;private Date createTime,udpateTime;@ManyToOneprivate Room room;@ManyToOneprivate User user;
}
而 User 变化如下:
复制代码
public class User implements Serializable {@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;@OneToMany(mappedBy = "user")private List<UserRoomRelation> userRoomRelations;
....}Room 变化如下:
public class Room {@Id@GeneratedValue(strategy = GenerationType.AUTO)private Long id;@OneToMany(mappedBy = "room")private List<UserRoomRelation> userRoomRelations;
...}
到这里我们再看一下 JUnit 运行结果。
复制代码
Hibernate: create table user_room_relation (id bigint not null, create_time timestamp, udpate_time timestamp, room_id bigint, user_id bigint, primary key (id))
Hibernate: create table room (id bigint not null, title varchar(255), primary key (id))
Hibernate: create table user (id bigint not null, email varchar(255), name varchar(255), sex varchar(255), primary key (id))
可以看到,上面我们依然创建了三张表,唯一不同的是 user_room_relation 里面多了很多字段,而外键索引也是如约创建,如下所示:
复制代码
Hibernate: alter table user_room_relation add constraint FKaesy2rg60vtaxxv73urprbuwb foreign key (room_id) references room
Hibernate: alter table user_room_relation add constraint FK45gha85x63026r8q8hs03uhwm foreign key (user_id) references user
好了,跑一下测试是不是就很容易理解了。下面我总结了关于 @ManyToMany 的最佳实践和你分享。
@ManyToMany 的最佳实践
- 上面我们介绍的 @OneToMany 的最佳实践同样适用,我为了说明方便,采用的是双向关联,而实际生产一般是在中间表对象里面做单向关联,这样会让实体之间的关联关系简单很多。
- 与 @OneToMany 一样的道理,不要用级联删除和 orphanRemoval=true。
- FetchType 采用默认方式:fetch = FetchType.LAZY 的方式。
相关文章:
07 | @Entity 之间的关联关系注解如何正确使用?
实体与实体之间的关联关系一共分为四种,分别为 OneToOne、OneToMany、ManyToOne 和 ManyToMany;而实体之间的关联关系又分为双向的和单向的。实体之间的关联关系是在 JPA 使用中最容易发生问题的地方,接下来我将一一揭晓并解释。我们先看一下…...

深入理解AQS之ReentrantLock源码分析
开题:如何自己生成一把独占锁? 1. 管程 — Java同步的设计思想 管程:指的是管理共享变量以及对共享变量的操作过程,让他们支持并发。 互斥:同一时刻只允许一个线程访问共享资源; 同步:线程之间…...

微软宣布延长Azure支持Apache Cassandra 3.11时间到2024年
近日微软表示为缓解管理员不适应升级节奏,将Azure托管实例对Apache Cassandra 3.11 的支持延长1年,从而时间将持续到2024年年底。 Multiable万达宝汽车ERP(www.multiable.com.cn/solutions_qc)支持自定义栏位,实时生产排产,提高生产效率 此…...

cv_bridge和opencv 记录
过程记录 背景 实验室笔记本上想跑一下vins-fusion。但是因为是有毕业师兄的代码,不敢随意破坏环境。 电脑环境: ubuntu 20.04 opencv 3.3.1 和 4.2.0 Error: vins-fusion中修改CMakeLists.txt,find_package(OpenCV 3.3.1 REQUIRED)&…...
)
关于OWL-carousel插件在ajax调用后需要重新实例化问题(页面无轮播效果)
维护公司老项目,发现问题,记录一下~ 1.产生原因 owl 已经实例已经存在,在ajax请求成功后并更改完页面数据后, 但是没有销毁之前实例,并重新生成新的实例,导致没有owl插件没有轮播效果. 2.解决方案 html: <div class"owl-slider …...
day4作业
1,判断一个整数是奇数还是偶数,至少有两种方式实现 #1,判断一个整数是奇数还是偶数,至少有两种方式实现 #1) number int(input("请输入一个数:"))if number % 2 0:print("偶数") else:print("奇数&qu…...

SSMS中的SQL sever代理
目录 一、用途: 二、用法 SQL Server代理(SQL Server Agent)是SQL Server Management Studio (SSMS) 2008中的一个功能模块,它用于执行和调度自动化任务、作业和脚本,如作业和警报。SQL Server代理允许在指定的时间间…...
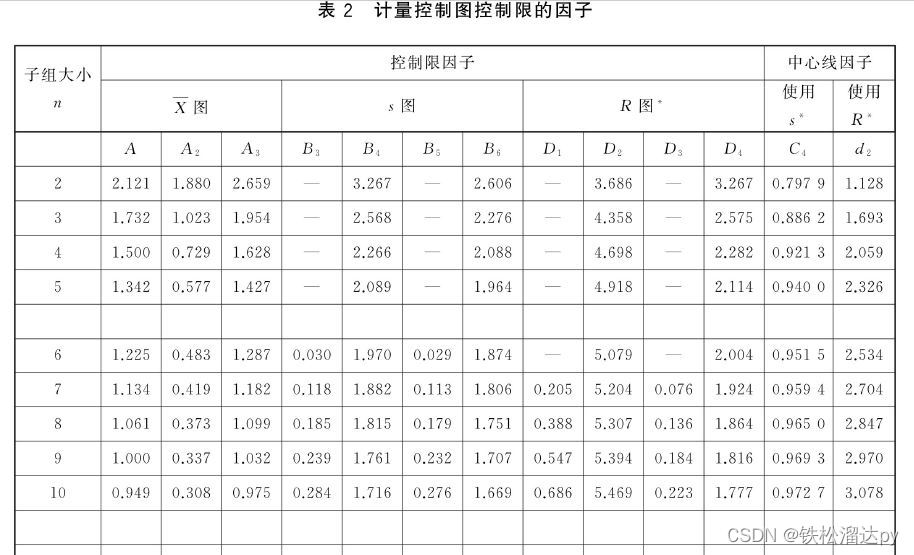
估算总体标准差的极差均值估计法sigma = R/d2
总体标准差的估算值可以通过将平均极差除以合适的常数因子d2来计算。这个估算方法是用于估算总体标准差的一种常见方法,尤其在质量控制和过程监控中经常使用。 总体标准差的估算值 (平均极差) / d2 其中: "总体标准差的估算值" 表示用极差…...

JavaScript之正则表达式
详见MDN 正则表达式(RegExp) 正则表达式不是JS独有的内容,大部分语言都支持正则表达式 JS中正则表达式使用得不是那么多,我们可以尽量避免使用正则表达式 在JS中,正则表达式就是RegExp对象,RegExp 对象用于将文本与一个模式匹配 正…...

Spring实战 | Spring AOP核心功能分析之葵花宝典
国庆中秋特辑系列文章: 国庆中秋特辑(八)Spring Boot项目如何使用JPA 国庆中秋特辑(七)Java软件工程师常见20道编程面试题 国庆中秋特辑(六)大学生常见30道宝藏编程面试题 国庆中秋特辑&…...

linux之/etc/skel目录
/etc/skel目录是在使用useradd添加用户时,一个需要用到的目录,该目录用来存放新建用户时需要拷贝到新建用户家目录下的文件。即:当我们新建新用户时,这个目录下的所有文件会自动被复制到新建用户的家目录下,默认情况下…...

文件介绍---C语言编程
0 Preface/Foreword 1 C文件概述 文件(File)是程序设计中的一个重要的概念。所谓“文件”一般指存储在外部介质上数据的集合。一批数据是以文件的形式存放在外部介质(如磁盘)上。操作系统是以文件为单位对数据进行管理,…...
)
软考 系统架构设计师系列知识点之特定领域软件体系结构DSSA(6)
接前一篇文章:软考 系统架构设计师系列知识点之特定领域软件体系结构DSSA(5) 所属章节: 第7章. 系统架构设计基础知识 第5节. 特定领域软件体系结构 相关试题 3. 特定领域软件架构(Domain Specific Software Archite…...
TensorFlow入门(二十三、退化学习率)
学习率 学习率,控制着模型的学习进度。模型训练过程中,如果学习率的值设置得比较大,训练速度会提升,但训练结果的精度不够,损失值容易爆炸;如果学习率的值设置得比较小,精度得到了提升,但训练过程会耗费太多的时间,收敛速度慢,同时也容易出现过拟合的情况。 退化学习率 退化学…...
登录中获取验证码的节流
一. 验证码框 <el-input placeholder"请输入验证码" prefix-icon"el-icon-lock" v-model"ruleForm.code"><el-button slot"suffix" :disabled"disabled" type"text" size"mini" click"ch…...

spring boot 实现Minio分片上传
应用场景 分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。 分片上传的场景…...

2023年09月 C/C++(六级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C编程(1~8级)全部真题・点这里 Python编程(1~6级)全部真题・点这里 第1题:生日相同 在一个有180人的大班级中,存在两个人生日相同的概率非常大,现给出每个学生的名字,出生月日。试…...

docker-compose 部署示例
文章目录 docker-compose文件格式docker-compose 下载 docker-compose文件格式 这个软件的实际很小,只是根据配置文件产生一些docker命令来执行可以。 配置文件本身是yml的格式,如下 version: 3.5services:# Etherpad: real-time collaborative docume…...

新版WordPress插件短视频去水印小程序源码
最新版去水印小程序源码,本版本全开源,是WordPress插件 上传到Wordpress 安装插件 启动之后 绑定自己的小程序id wordpress可以在宝塔一键部署 也可以用我的这个 搭建前我们需要一下东西: 第一个:一台服务器(国内外都可…...

如何提高MES系统的落地成功率?
导 读 ( 文/ 2768 ) 制造执行系统(MES)在现代制造业中扮演着至关重要的角色,但实施MES系统并取得成功并非易事。为了帮助企业提高MES系统的落地成功率,本文将介绍关键的方法和策略。通过深入了解业务需求、有效的团队合作、全面的…...

HoRain云--Skills 基本结构
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

移动Git客户端:Android上的完整版本控制解决方案
移动Git客户端:Android上的完整版本控制解决方案 【免费下载链接】MGit A Git client for Android. 项目地址: https://gitcode.com/gh_mirrors/mg/MGit 在移动开发日益普及的今天,开发者需要在不同场景下管理代码版本。移动Git客户端MGit为Andro…...

火绒安全软件实战教程:快速查杀、全盘查杀、自定义查杀到底怎么选?
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

深入解析Enso:构建高性能可编程代理与API网关的Go框架
1. 项目概述:一个被低估的“瑞士军刀”如果你在开源社区里混迹过一段时间,大概率见过这样的场景:一个项目仓库,名字起得挺酷,比如“Enso”,简介里写着“一个现代化的代理工具”,但点进去一看&am…...

如何在10分钟内搭建自己的游戏串流服务器:Sunshine开源游戏串流完整教程
如何在10分钟内搭建自己的游戏串流服务器:Sunshine开源游戏串流完整教程 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想在任何设备上玩PC游戏吗?Sunshin…...

在VSCode中重塑R语言开发体验:vscode-R插件深度解析
在VSCode中重塑R语言开发体验:vscode-R插件深度解析 【免费下载链接】vscode-R R Extension for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-R 你是否曾为R语言开发环境的局限性感到困扰?传统IDE虽然功能齐全&#…...

为什么83%的用户误读NotebookLM引用溯源?一文讲透证据链完整性校验四步法
更多请点击: https://intelliparadigm.com 第一章:为什么83%的用户误读NotebookLM引用溯源?一文讲透证据链完整性校验四步法 NotebookLM 的“引用溯源”功能并非传统意义上的文献标注,而是一套基于语义锚点与片段置信度的轻量级证…...

开源补丁工具包OpenClaw-Patchkit:无侵入式热更新与二进制修改实战
1. 项目概述:一个开源补丁工具包的深度解析最近在整理一些老项目的维护工具链时,又翻出了mahsumaktas/openclaw-patchkit这个仓库。这名字乍一看有点神秘,“OpenClaw”配上“Patchkit”,让人联想到某种模块化的修补工具。实际上&a…...

原来选对床垫还能改善全家睡眠质量?
选对床垫,改善全家睡眠质量的秘密在快节奏的现代生活中,良好的睡眠质量变得越来越重要。一张合适的床垫不仅能提升个人的睡眠体验,还能改善全家人的睡眠质量。本文将探讨如何选择适合全家人的床垫,并重点介绍美德丽床垫的独特优势…...

Python自动化拍照邮件系统:从摄像头调用到SMTP发送全流程实战
1. 项目概述:从零搭建一个自动化拍照邮件系统最近在工作室搞了个小项目,需要定时监控一个实验区域的状态,拍下照片后自动发到邮箱里方便随时查看。这个需求听起来简单,但真动手做起来,从摄像头调用、图像处理到邮件发送…...