【JUC】原子操作类及LongAddr源码分析
文章目录
- 1. 十八罗汉
- 2. 原子类再分类
- 2.1 基本类型原子类
- 2.2 数组类型原子类
- 2.3 引用类型原子类
- 2.4 对象的属性修改原子类
- 2.5 原子操作增强类
- 3. 代码演示及性能比较:
- 4. LongAddr原理
- 5. LongAddr源码分析
- 5.1 add()
- 5.2 longAccumulate()
- 5.3 sum()
- 6. 小总结
- 6.1 AtomicLong
- 6.2 LongAdder
1. 十八罗汉
底层使用Unsafe类的CAS方法,而无需使用synchronized等重量锁使操作变得线程安全
- AtomicBoolean
- AtomicInteger
- AtomicIntegerArray
- AtomicIntegerFieldUpdater
- AtomicLong
- AtomicLongArray
- AtomicLongFieldUpdater
- AtomicMarkableReference
- AtomicReference
- AtomicReferenceArray
- AtomicReferenceFieldUpdater
- AtomicStampedReference
- DoubleAccumulator
- DoubleAdder
- LongAccumulator
- LongAdder
- Striped64,LongAdder是Striped64的子类
- Number,Striped64,AtomicInteger等是Number的子类
2. 原子类再分类
2.1 基本类型原子类
- AtomicBoolean
- AtomicInteger
- AtomicLong
基本使用
public class Temp {static int num = 0;static AtomicInteger atomicNum = new AtomicInteger();public static void main(String[] args) throws InterruptedException {int size = 50;CountDownLatch count = new CountDownLatch(size);for (int i = 0; i < size; i++) {new Thread(() -> {try {for (int j = 0; j < 1000; j++) {num++;atomicNum.getAndIncrement();}} finally {count.countDown();}}).start();}count.await();System.out.println(num);System.out.println(atomicNum.get());}
}
输出
39224
50000
2.2 数组类型原子类
如何理解?类比数组即可
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
2.3 引用类型原子类
- AtomicReference
- AtomicStampedReference
- 用版本号解决CAS的ABA问题,可以统计出修改过几次
- AtomicMarkableReference
- 用状态戳解决CAS的ABA问题,可以标记出是否修改过
2.4 对象的属性修改原子类
- AtomicIntegerFieldUpdater:原子更新对象中int类型字段的值
- AtomicLongFieldUpdater:原子更新对象中Long类型字段的值
- AtomicReferenceFieldUpdater:原子更新对象中引用类型字段的值
目的:以一种线程安全的方式操作非线程安全对象内的某些字段
要求:
- 更新的对象属性必须使用public volatile修饰
- 使用静态放法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性
/*** 需求:多线程环境下初始化资源类,要求只能初始化一次*/
public class Temp {public volatile Boolean isInit = Boolean.FALSE;private static final AtomicReferenceFieldUpdater<Temp, Boolean> ATOMIC_REFERENCE_FIELD_UPDATER =AtomicReferenceFieldUpdater.newUpdater(Temp.class, Boolean.class, "isInit");public void init(Temp temp) {if (ATOMIC_REFERENCE_FIELD_UPDATER.compareAndSet(temp, Boolean.FALSE, Boolean.TRUE)) {System.out.println(Thread.currentThread().getName()+":init start");try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) {}System.out.println(Thread.currentThread().getName()+":init finished");} else {System.out.println(Thread.currentThread().getName()+":已有线程正在初始化");}}public static void main(String[] args) throws InterruptedException {int size = 5;CountDownLatch count = new CountDownLatch(size);Temp temp = new Temp();for (int i = 0; i < size; i++) {new Thread(() -> {try {temp.init(temp);} finally {count.countDown();}}).start();}count.await();}
}
2.5 原子操作增强类
- DoubleAccumulator:一个或多个变量共同维护使用的函数更新的运行double值
- DoubleAdder:一个或多个变量共同维持最初的零和double总和
- LongAccumulator:一个或多个变量共同维护使用的函数更新的运行long值
- LongAdder:一个或多个变量共同维持最初的零和long总和
volatile 解决多线程内存不可见问题。对于一写多读,是可以解决变量同步问题,但是如果多写,同样无法解决线程安全问题。
说明: 如果是 count++操作,使用如下类实现: AtomicInteger count = new AtomicInteger0;count.addAndGet(1);如果是JDK8,推荐使用 LongAdder 对象,比 AtomicLong 性能更好( 减少乐观锁的重试次数 );同时,使用LongAdder的空间代价更大,故越是高并发越推荐使用LongAdder 。
LongAdder只能用来计算加法,且从零开始计算;
LongAccumulator提供了自定义函数的操作且可以传入初始值。
3. 代码演示及性能比较:
/*** 需求:点赞数统计,50个线程,每个点赞1千万次*/
public class Temp {long i = 0;public synchronized void synchronizedIncrement() {i++;}AtomicLong atomicLong = new AtomicLong();public void atomicLongIncrement() {atomicLong.getAndIncrement();}LongAdder longAdder = new LongAdder();public void longAdderIncrement() {longAdder.increment();}LongAccumulator longAccumulator = new LongAccumulator(Long::sum, 0);public void longAccumulatorIncrement() {longAdder.increment();}public static void main(String[] args) throws InterruptedException {int threadNum = 50;int times = 10000000;process(threadNum, times, 1);process(threadNum, times, 2);process(threadNum, times, 3);process(threadNum, times, 4);}public static void process(int threadNum, int times, int type) throws InterruptedException {long startTime = System.currentTimeMillis();CountDownLatch countDownLatch = new CountDownLatch(threadNum);Temp temp = new Temp();for (int i = 0; i < threadNum; i++) {new Thread(() -> {try {for (int j = 0; j < times; j++) {switch (type) {case 1: temp.synchronizedIncrement();break;case 2: temp.atomicLongIncrement();break;case 3: temp.longAdderIncrement();break;case 4: temp.longAccumulatorIncrement();break;default: throw new RuntimeException("不存在的类型");}}} finally {countDownLatch.countDown();}}).start();}countDownLatch.await();long endTime = System.currentTimeMillis();System.out.println("costTime:" + (endTime - startTime) + " 毫秒," + typeStr(type));}public static String typeStr(int type) {switch (type) {case 1: return "synchronizedIncrement";case 2: return "atomicLongIncrement";case 3: return "longAdderIncrement";case 4: return "longAccumulatorIncrement";default: throw new RuntimeException("不存在的类型");}}
}
执行结果:
costTime:22854 毫秒,synchronizedIncrement
costTime:4888 毫秒,atomicLongIncrement
costTime:215 毫秒,longAdderIncrement
costTime:214 毫秒,longAccumulatorIncrement
4. LongAddr原理
LongAddr继承了Striped64,LongAdder的基本思路就是分散热点,将value值分散到一个Cell数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回
sum()会将所有Cell数组中的value和base累加作为返回值,核心的思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,
从而降级更新热点。
Striped64比较重要的成员变量
/** Number of CPUS, to place bound on table size * CPU数量,即cells数组的最大长度*/static final int NCPU = Runtime.getRuntime().availableProcessors();/*** Table of cells. When non-null, size is a power of 2.* cells数组,长度为2的幂,2,4,8,16...,方便以后位运算*/transient volatile Cell[] cells;/*** Base value, used mainly when there is no contention, but also as* a fallback during table initialization races. Updated via CAS.* 基础value值,当并发较低时,只累加该值,主要用于没有竞争的情况,通过CAS更新*/transient volatile long base;/*** Spinlock (locked via CAS) used when resizing and/or creating Cells.* 创建或扩容Cells数组时使用的自旋锁变量调整单元格大小(扩容),创建单元格时使用的锁*/transient volatile int cellsBusy;

5. LongAddr源码分析
小总结:LongAdder在无竞争的情况,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则是采用化整为零分散热点的做法,用空间换时间用一个数组cells,将一个value拆分进这个数组cells。多个线程需要同时对value进行换作时候,可以对线程id进行hash得到hash值,再根据hash值映射到这个数组cells的某个下标,再对该下标所对应的值进行自增操作。当所有线程换作完毕,将数组cells的所有值和base都加起来作为最终结果
5.1 add()
public void add(long x) {// as是Striped64中的cells数组属性// b是Striped64中的base属性// v是当前线程hash到Cell中存储的值// m是cells的长度-1,hash时作为掩码使用// a是当前线程hash到的CellCell[] as; long b, v; int m; Cell a;// 首次首线程(as = cells) != null一定是false,此时走casBase方法,以CAS的方式更新base值,且只有当cas失败时,才会走到if中// 条件1: cells不为空// 条件2: cas操作base失败,说明其他线程先一步修改了base,出现竞争if ((as = cells) != null || !casBase(b = base, b + x)) {// true无竞争,false表示竞争激烈,多个线程hash到同一个cell,可能要扩容boolean uncontended = true;// 条件1:cells为空// 条件2:应该不会出现// 条件3:当前线程所在cell为空,说明当前线程还没有更新过cell,应初始化一个cell// 条件4:更新当前线程所在cell失败,说明竞争很激烈,多个线程hash到了同一个cell,应扩容if (as == null || (m = as.length - 1) < 0 ||// getProbe()方法返回的是线程中的threadLocalRandomProbe字段// 它是通过随机数生成的一个值,对于一个确定的线程这个值是固定的(除非刻意修改它)(a = as[getProbe() & m]) == null ||!(uncontended = a.cas(v = a.value, v + x)))longAccumulate(x, null, uncontended);}
}
5.2 longAccumulate()
/*** Handles cases of updates involving initialization, resizing,* creating new Cells, and/or contention. See above for* explanation. This method suffers the usual non-modularity* problems of optimistic retry code, relying on rechecked sets of* reads.** @param x the value * @param fn the update function, or null for add (this convention* avoids the need for an extra field or function in LongAdder). * @param wasUncontended false if CAS failed before call * x: 需要增加的值,一般默认都是1* fn: 默认传递的是null* wasUncontended: 竞争标识,如果是false标识有竞争。只有cells初始化之后,并且当前线程CAS修改失败才会是false*/final void longAccumulate(long x, LongBinaryOperator fn,boolean wasUncontended) {// h:存储线程的probe值int h;// 如果getProbe()方法返回0,说明随机数未初始化if ((h = getProbe()) == 0) { // 这个操作相当于给当前线程生成一个非0的hash值// 使用ThreadLocalRandom为当前线程重新计算一个hash值,强制初始化ThreadLocalRandom.current(); // force initialization// 重新获取probe值,hash值被重置就好比一个全新的线程一样,所以设置了wasUncontended竞争状态为trueh = getProbe();// 重新计算了当前线程的hash后认为此次不算是一次竞争,都未初始化,肯定还不存在竞争激烈,故设置wasUncontended竞争状态为truewasUncontended = true;}// 如果hash取模映射得到的cell单元不是null,则为true,此值也可以看做是扩容意向boolean collide = false; // True if last slot nonemptyfor (;;) {// 自旋:按CASE 2,3,1看代码Cell[] as; Cell a; int n; long v;// CASE 1:cells已经被初始化了if ((as = cells) != null && (n = as.length) > 0) {// CASE 1.1 :当前线程hash到的cell还未初始化,则需要进行初始化处理,初始化的值为x即默认的1if ((a = as[(n - 1) & h]) == null) {if (cellsBusy == 0) { // Try to attach new CellCell r = new Cell(x); // Optimistically create// 双端检查并尝试抢锁if (cellsBusy == 0 && casCellsBusy()) {boolean created = false;try { // Recheck under lockCell[] rs; int m, j;if ((rs = cells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {rs[j] = r;created = true;}} finally {cellsBusy = 0;}if (created)break;continue; // Slot is now non-empty}}collide = false;}// CASE 1.2:竞争激烈,允许重新计算hash值else if (!wasUncontended) // CAS already known to failwasUncontended = true; // Continue after rehash// CASE 1.3:当前线程hash到已初始化的槽位,使用cas进行更新,更新成功则跳出循环else if (a.cas(v = a.value, ((fn == null) ? v + x :fn.applyAsLong(v, x))))break;// CASE 1.4:如果cells的长度已经大于等于CPU核数,就不要再扩容了,继续hash;cells != as说明已有线程正在扩容else if (n >= NCPU || cells != as)collide = false; // At max size or stale// CASE 1.5:将扩容意向置为true,如果再hash仍然不满足上诉条件便扩容else if (!collide)collide = true;// CASE 1.6:尝试扩容,将老数组复制到新数组上else if (cellsBusy == 0 && casCellsBusy()) {try {// 当前的cells数组和最先赋值的as是同一个,代表没有被其他线程扩容过if (cells == as) { // Expand table unless staleCell[] rs = new Cell[n << 1];for (int i = 0; i < n; ++i)rs[i] = as[i];cells = rs;}} finally {cellsBusy = 0;}collide = false;continue; // Retry with expanded table}// 允许重置当前线程的hash值h = advanceProbe(h);}// CASE 2:cells没有加锁且没有初始化,则尝试对它进行加锁,并初始化cells数组;cellsBusy=0表示无锁状态,cellsBusy=1为持锁状态else if (cellsBusy == 0 && cells == as && casCellsBusy()) {// boolean init = false;try { // Initialize tableif (cells == as) {// 与条件中cells == as形成双重检查Cell[] rs = new Cell[2];rs[h & 1] = new Cell(x); // 按照当前线程hash到数组中的位置并创建其对应的Cellcells = rs;init = true;}} finally {cellsBusy = 0;}if (init)break;}// CASE 3:cells正在进行初始化,则尝试直接在基数base上进行累加操作;兜底操作,当新线程进来,而数组正在初始化时,则用base进行累加else if (casBase(v = base, ((fn == null) ? v + x :fn.applyAsLong(v, x))))break; // Fall back on using base}}
5.3 sum()
/*** Returns the current sum. The returned value is <em>NOT</em> an* atomic snapshot; invocation in the absence of concurrent* updates returns an accurate result, but concurrent updates that* occur while the sum is being calculated might not be* incorporated.** @return the sum*/public long sum() {Cell[] as = cells; Cell a;long sum = base;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;}
sum执行时,并没有限制对base和cells的更新。所以LongAdder不是强一致性的,它是最终一致性的
6. 小总结
6.1 AtomicLong
原理:CAS+自旋
场景:低并发下的全局计算,AtomicLong能保证并发情况下计数的准确性,内部使用CAS来解决并发安全问题
缺陷:高并发后性能急剧下降,N个线程CAS操作修改线程的值,每次只有一个成功,其它N-1失败,失败的不停的自旋直到成功,这样大量失败自旋的情况,很浪费CPU资源
6.2 LongAdder
原理:CAS+Base+Cell数组分散,空间换时间并分散了热点数据
场景:高并发下的全局计算
缺陷:sum求和时还有计算线程修改结果的话,最后的结果不够准确
相关文章:
【JUC】原子操作类及LongAddr源码分析
文章目录 1. 十八罗汉2. 原子类再分类2.1 基本类型原子类2.2 数组类型原子类2.3 引用类型原子类2.4 对象的属性修改原子类2.5 原子操作增强类 3. 代码演示及性能比较:4. LongAddr原理5. LongAddr源码分析5.1 add()5.2 longAccumulate()5.3 sum() 6. 小总结6.1 Atomi…...
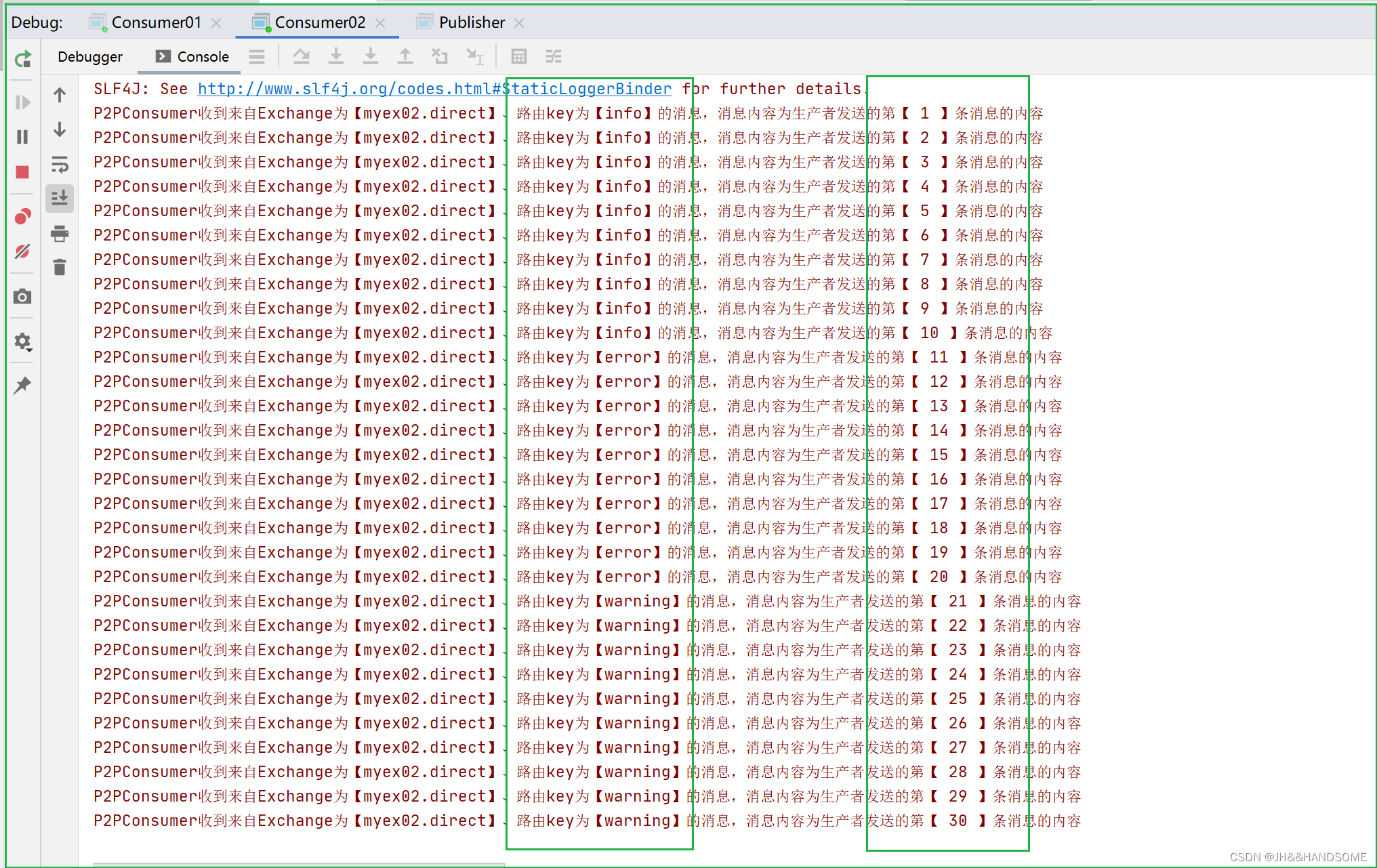
203、RabbitMQ 之 使用 direct 类型的 Exchange 实现 消息路由 (RoutingKey)
目录 ★ 使用direct实现消息路由代码演示这个情况二ConstantUtil 常量工具类ConnectionUtil 连接RabbitMQ的工具类Publisher 消息生产者测试消息生产者 Consumer01 消息消费者01测试消费者结果: Consumer02 消息消费者02测试消费者结果: 完整代码&#x…...
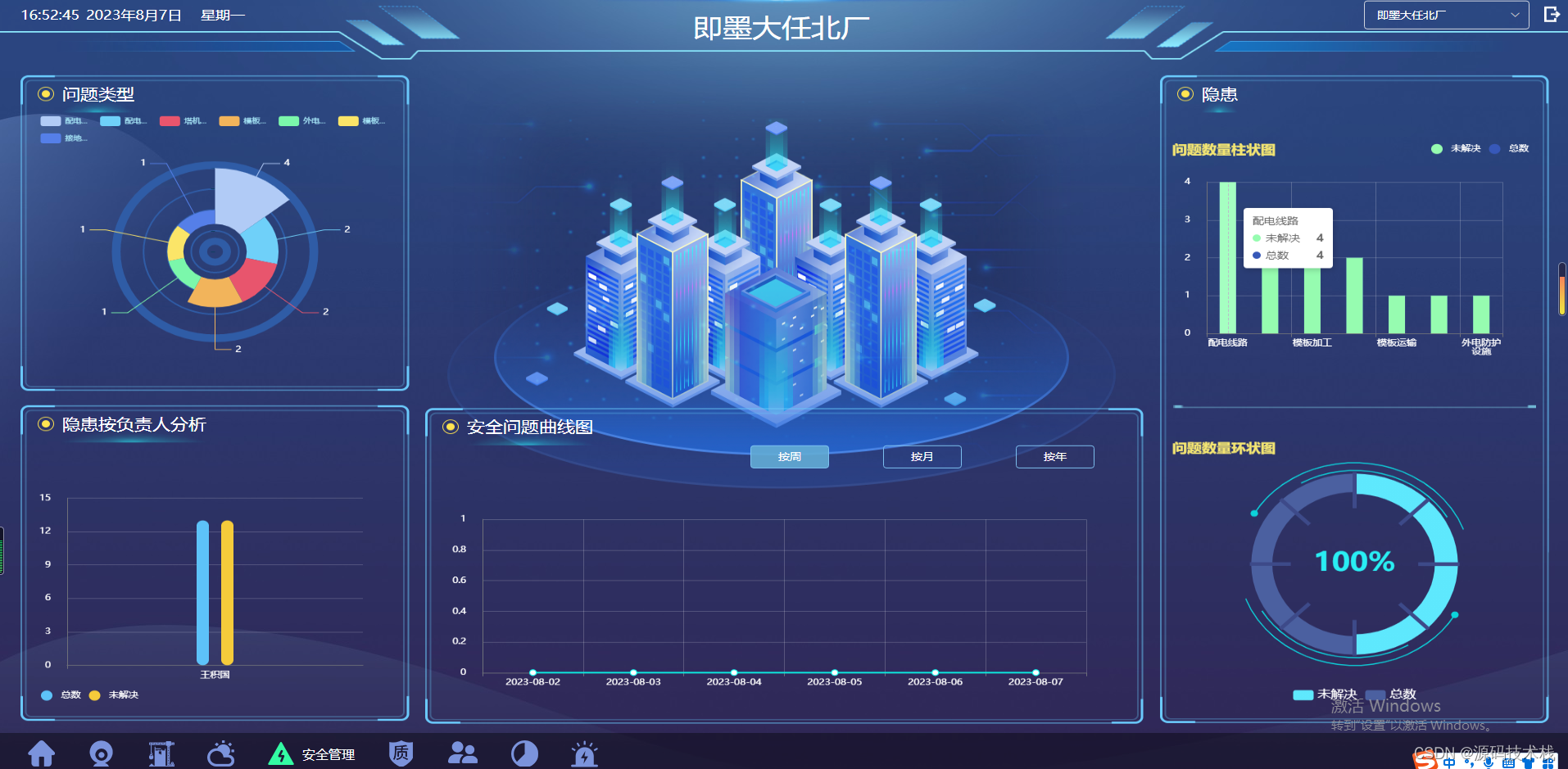
微服务+Java+Spring Cloud +UniApp +MySql智慧工地综合管理云平台源码,SaaS模式
智慧工地围绕工程现场人、机、料、法、环及施工过程中质量、安全、进度、成本等各项数据满足工地多角色、多视角的有效监管,实现工程建设管理的降本增效. 智慧工地综合管理云平台源码,PC监管端、项目端;APP监管端、项目端、数据可视化大屏端源码…...
QMidi Pro for Mac:打造您的专属卡拉OK体验
你是否曾经厌倦于在KTV里与朋友们争夺麦克风?是否想要在家中享受自定义的卡拉OK体验?现在,有了QMidi Pro for Mac,一切变得简单而愉快! QMidi Pro是一款功能强大的卡拉OK播放器,专为Mac用户设计。它充分利…...

bindtap和catchtap的区别?
bindtap和catchtap都是小程序中用于绑定点击事件的方法。 1.bindtap的作用是绑定一个触摸事件并指定对应的处理函数。当用户点击或触摸相关元素时,会触发该事件,并执行相应的处理逻辑。 示例: <button bindtap"handleTap">…...
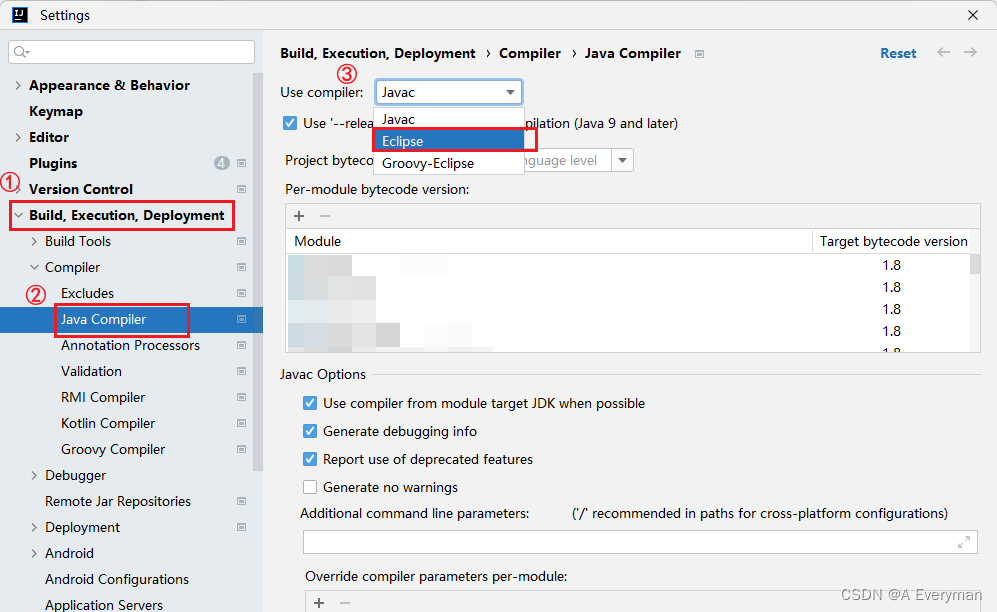
IDEA—java: 常量字符串过长问题解决
问题描述: Error: java: 常量字符串过长 问题分析: 字符串长度过长,导致 idea 默认使用的 javac 编译器编译不了。 解决办法: Javac 编译器改为 Eclipse 编译器。 File -> Settings -> Build,Execution,Deployment -&…...

云原生SIEM解决方案
云原生(Cloud Native)是一种基于云计算的软件开发和部署方法论,它强调将应用程序和服务设计为云环境下的原生应用,以实现高可用性、可扩展性和灵活性。 云原生的优势有哪些 高可用性:云原生可以实现应用程序的高可用…...

工艺边与定位孔设计经验规则总结
🏡《总目录》 目录 1,什么是工艺边和定位孔2,工艺边的设计经验原则2.1,避免尖锐角2.2,工艺边宽度设置2.3,工艺边的方向2.4,定位孔尺寸2.5,定位孔的位置3,去除工艺边的方法注意事项4,总结1,什么是工艺边和定位孔 工艺边是在SMT焊接时,为了PCB和导轨接触预留的PCB边…...
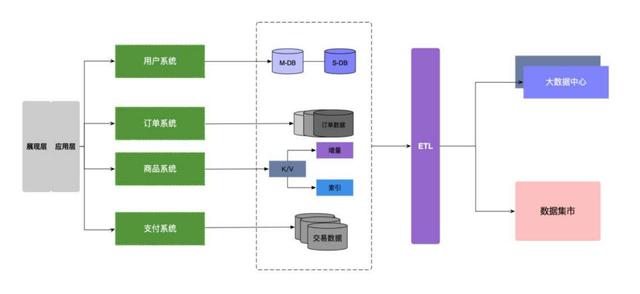
软件架构设计(业务架构、应用架构、数据架构、技术架构)
一、架构相关概念 1、系统 系统:由一群有关联的个体组成,根据某种规则运作,能完成个别原件不能独立完成的工作的群体。大的系统可以嵌套小系统,被嵌套的小系统往往称为大系统的子系统。 2、模块 模块是从逻辑上将系统分解&#…...

我们又组织了一次欧洲最大开源社区活动,Hugging Face 博客欢迎社区成员发帖、Hugging Chat 功能更新!...
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」。本期 Hugging News 有哪些有趣的消息࿰…...
学信息系统项目管理师第4版系列26_项目绩效域(下)
1. 项目工作绩效域 1.1. 涉及项目工作相关的活动和职能 1.2. 预期目标 1.2.1. 高效且有效的项目绩效 1.2.2. 适合项目和环境的项目过程 1.2.3. 干系人适当的沟通和参与 1.2.4. 对实物资源进行了有效管理 1.2.5. 对采购进行了有效管理 1.2.6. 有效处理了变更 1.2.7. 通…...
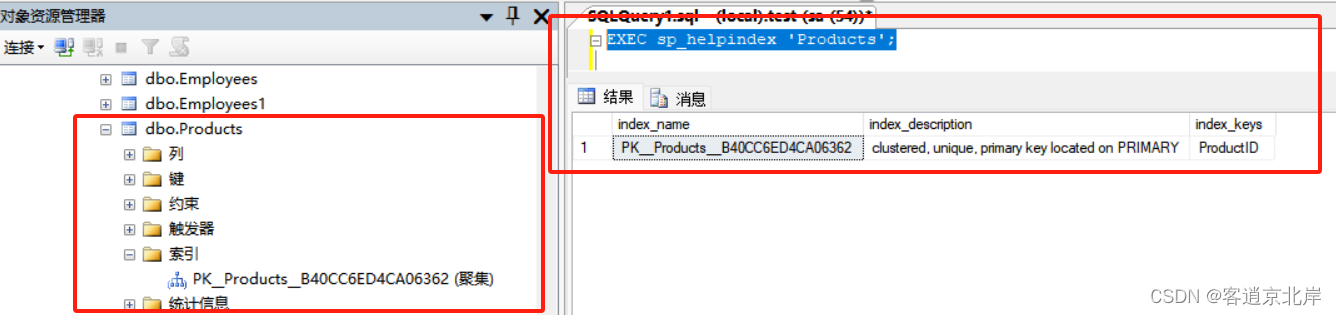
SQL sever中的索引
目录 一、索引定义 二、索引结构 2.1. B-树索引结构: 2.2. 哈希索引结构: 三、索引作用 四、索引与约束区别 五、索引级别 六、索引分类 6.1. 聚集索引(Clustered Index): 6.2. 非聚集索引(Noncl…...
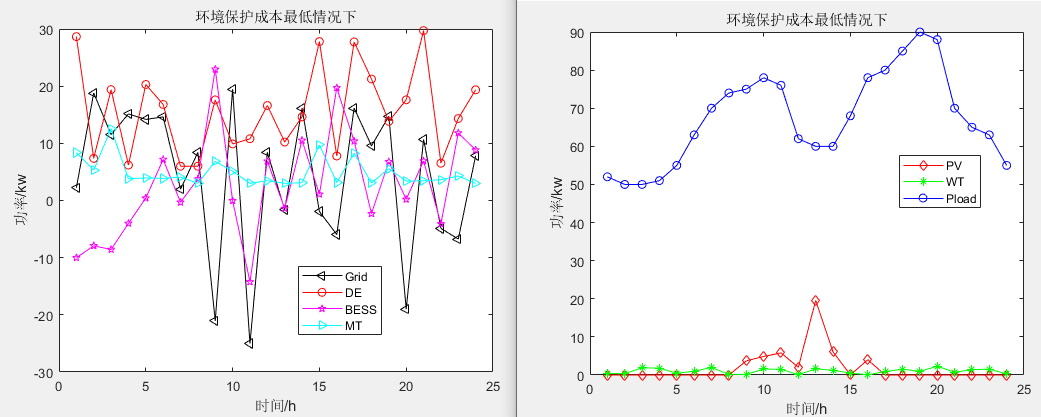
多目标鳟海鞘算法(Multi-objective Salp Swarm Algorithm,MSSA)求解微电网优化MATLAB
一、微网系统运行优化模型 微电网优化模型介绍: 微电网多目标优化调度模型简介_IT猿手的博客-CSDN博客 参考文献: [1]李兴莘,张靖,何宇,等.基于改进粒子群算法的微电网多目标优化调度[J].电力科学与工程, 2021, 37(3):7 二、多目标鳟海鞘算法MSSA 多…...
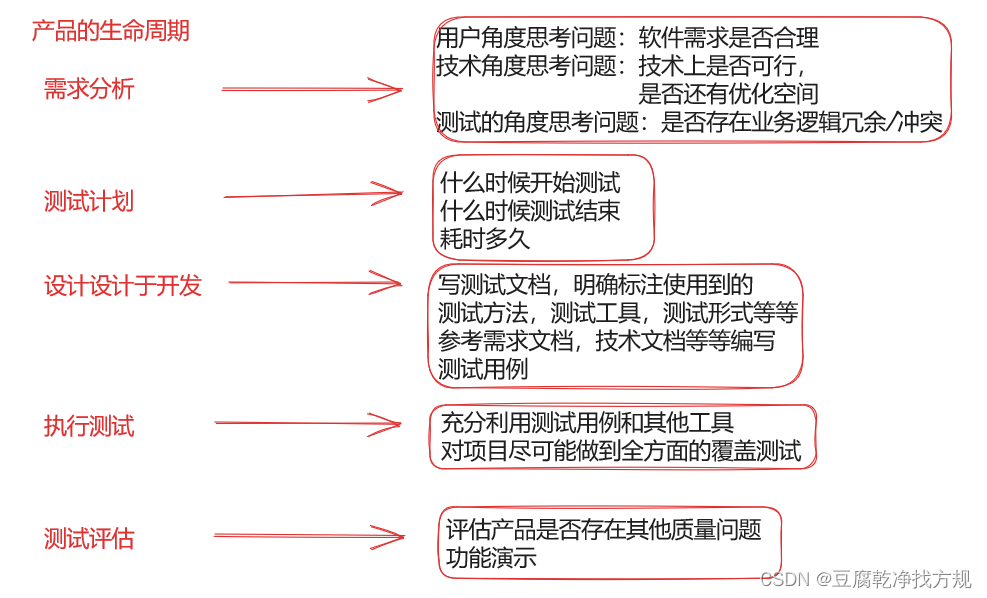
软件测试之概念篇(需求,测试用例,BUG描述,产品的生命周期)
目录 1.什么是需求 2.什么是测试用例 3.什么是BUG 4.软件的生命周期 5.测试的生命周期 1.什么是需求 在大多数软件公司,一般会有两部分需求: 用户需求:可以理解为就是甲方提出需求,如果没有甲方,那么就是终端用…...

jwt详细介绍
jwt详细介绍 1.jwt 简介:2.jwt 工具类介绍3.案列演示:3.1并在web.xml进行配置过滤器 3.2过滤3.3全局响应设置 1.jwt 简介: 。JWT(JSON Web Token) 是一种用于安全传输信息的开放标准(RFC 7519)…...
电子笔记真的好用吗?手机上适合记录学习笔记的工具
提及笔记,不少人都会和学习挂钩,的确学习过程中我们经常会遇到很多难题,而经常记录笔记可以有效地帮助大家记住很多知识,而且时常拿出笔记查看一下,可方便巩固过去学习的知识。 手机作为大家日常随身携带的工具&#…...

用 SQL 找出某只股票连续上涨的最长天数
涉及多张中间表: SELECT MAX(consecutive_day) FROM (SELECT COUNT(*) as consecutive_dayFROM (SELECT trade_date, SUM(rise_mark) OVER (ORDER BY trade_date) AS days_no_gainFROM (SELECT trade_date,CASEWHEN closing_price > LAG(closing_price) OVER (ORDER BY tra…...
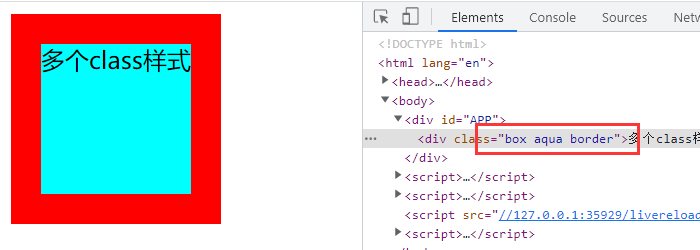
Vue 绑定 class 与 style
在应用界面中,某些元素的样式是动态的。class 与 style 绑定就是专门用来实现动态样式效果的技术。 如果需要动态绑定 class 或 style 样式,可以使用 v-bind 绑定。 绑定 class 样式【字符串写法】 适用于:类名不确定,需要动态指…...

【微服务部署】九、使用Docker Compose搭建高可用双机热备MySQL数据库
通常,一般业务我们使用云服务器提供的数据库,无论是MySQL数据库还是其他数据库,云服务厂商都提供了主备功能,我们不需要自己配置处理。而如果需要我们自己搭建数据库,那么考虑到数据的高可用性、故障恢复和扩展性&…...

HTTP Basic 认证
HTTP Basic 认证 难度等级:【初级】 由RFC7617定义的HTTP Basic认证是一种非常基础而简单的认证模式,因此叫他Basic认证。他本质上就是浏览器提供的一个接口,能够根据HTTP返回值,自动弹出一个登录框,让用户输入ID和密码…...

歌词滚动姬:重新定义歌词时间轴同步的专业级工具
歌词滚动姬:重新定义歌词时间轴同步的专业级工具 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为歌词与音乐不同步而烦恼吗?是否曾经花…...

5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐
5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirr…...

DLSS Swapper终极指南:一键管理游戏超采样文件,免费提升显卡性能
DLSS Swapper终极指南:一键管理游戏超采样文件,免费提升显卡性能 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为NVIDIA、AMD和Intel显卡用户设计的智能超采样文件管理工…...

ESP32驱动LCD1602:从I2C协议到动态数据展示
1. ESP32与LCD1602的完美组合 如果你正在寻找一种简单可靠的方式在物联网项目中显示实时数据,ESP32搭配LCD1602液晶屏绝对是个不错的选择。我最近在一个智能温室项目中就用了这套方案,用来实时显示温度和湿度数据,效果非常稳定。LCD1602虽然看…...

G-Helper终极指南:如何彻底解决华硕笔记本散热与性能管理难题
G-Helper终极指南:如何彻底解决华硕笔记本散热与性能管理难题 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenb…...

如何在Windows上快速安装ViGEmBus虚拟手柄驱动:终极指南
如何在Windows上快速安装ViGEmBus虚拟手柄驱动:终极指南 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows电脑上畅玩所有游戏&#…...

告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南
告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次开机都看到"需要激活"的提…...

通过taotoken审计日志追溯api调用详情与安全分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken审计日志追溯API调用详情与安全分析 对于将大模型API集成到业务流程中的团队而言,API调用的可见性与可控性…...

保姆级教程:用CH34xSerCfg修改USB转串口芯片的VID/PID,解决驱动冲突和串口号固定问题
嵌入式开发实战:用CH34xSerCfg定制USB转串口设备标识与驱动管理 当你的工作台上同时连接着五个相同型号的USB转TTL模块,Windows设备管理器里COM端口像走马灯一样随机变换编号时;当团队协作开发中,每个成员需要固定识别自己的调试设…...

Boss直聘职位数据自动化采集:Python爬虫架构设计与工程实践
1. 项目概述与核心价值最近在技术社区里,看到不少朋友在讨论一个叫longsizhuo/BossZhiPin_Job_Search的项目。光看名字,你大概就能猜到,这是一个跟“Boss直聘”和“职位搜索”相关的自动化工具。作为一个在招聘数据分析和自动化领域摸爬滚打了…...