【Rust笔记】浅聊 Rust 程序内存布局
浅聊Rust程序内存布局
内存布局看似是底层和距离应用程序开发比较遥远的概念集合,但其对前端应用的功能实现颇具现实意义。从WASM业务模块至Nodejs N-API插件,无处不涉及到FFI跨语言互操作。甚至,做个文本数据的字符集转换也得FFI调用操作系统链接库libiconv,因为这意味着更小的.exe/.node发布文件。而C ABI与内存布局正是跨(计算机)语言数据结构的基础。
大约两个月前,在封装FFI闭包(不是函数指针)过程中,我重新梳理了Rust内存布局知识点。然后,就有冲动写这么一篇长文。今恰逢国庆八天长假,汇总我之所知与大家分享。开始正文...
存储宽度size与对齐位数alignment — 内存布局的核心参数
变量值在内存中的存储信息包含两个重要属性
首字节地址
address存储宽度
size
而这两个值都不是在分配内存那一刻的“即兴选择”。而是,遵循着一组规则:
address与size都必须是【对齐位数alignment】的自然数倍。比如说,
对齐位数
alignment等于1字节的变量值可保存于任意内存地址address上。对齐位数
alignment等于2字节且有效数据长度等于3字节的变量值存储宽度
size等于0字节的变量值可接受任意正整数作为其对齐位数alignment— 惯例是1字节。
仅能保存于偶数位的内存地址
address上。存储宽度
size也得是4字节 — 从有效长度3字节到存储宽度4字节的扩容过程被称作“对齐”。
对齐位数alignment必须是2的自然数次幂。即,alignment = 2 ^ N且N是≼ 29的自然数。
存储宽度size是有效数据长度加对齐填充位数的总和字节数 — 这一点可能有点儿反直觉。
address,size与alignment的计量单位都是“字节”。
正是因为address,size与alignment之间存在倍数关系,所以程序对内存空间的利用一定会出现冗余与浪费。这些被浪费掉的“边角料”则被称作【对齐填充alignment padding】。对齐填充的计量单位也是字节。根据“边角料”出现的位置不同,对齐填充alignment padding又分为
小端填充
Little-Endian padding—0填充位出现在有效数据右侧的低位大端填充
Big-Endian padding—0填充位出现在有效数据左侧的高位
文字抽象,图直观。一图抵千词,请看图

延伸理解:借助于对齐位数,物理上一维的线性内存被重构为了逻辑上
N维的存储空间。不严谨地讲,一个数据类型 ➜ 对应一个对齐位数值 ➜ 按一个【单位一】将内存空间均分一遍 ➜ 形成一个仅存储该数据类型值(且只存在于算法与逻辑中)的维度空间。然后,在保存该数据类型的新值时,只要
选择进入正确的维度空间
跳过已被占用的【单位一】(这些【单位一】是在哪一个维度空间被占用、是被谁占用和怎么占用并不重要)
寻找连续出现且数量足够的【单位一】
就行了。
如果【对齐位数alignment】与【存储宽度size】在编译时已知,那么该类型<T: Sized>就是【静态分派】Fixed Sized Type。于是,
类型的对齐位数可由std::mem::align_of::<T>()读取
类型的存储宽度可由std::mem::size_of::<T>()读取
若【对齐位数alignment】与【存储宽度size】在运行时才可计算知晓,那么该类型<T: ?Sized>就是【动态分派】Dynamic Sized Type。于是,
值的对齐位数可由std::mem::align_of_val::<T>(&T)读取
值的存储宽度可由std::mem::size_of_val::<T>(&T)读取
存储宽度size的对齐计算
若变量值的有效数据长度payload_size正好是该变量类型【对齐位数alignment】的自然数倍,那么该变量的【存储宽度size】就是它的【有效数据长度payload_size】。即,size = payload_size;。
否则,变量的【存储宽度size】就是既要大于等于【有效数据长度payload_size】,又是【对齐位数alignment】自然数倍的最小数值。
这个计算过程的伪码描述是
variable.size = variable.payload_size.next_multiple_of(variable.alignment);这个计算被称作“(自然数倍)对齐”。
简单内存布局
基本数据类型
基本数据类型包括bool,u8,i8,u16,i16,u32,i32,u64,i64,u128,i128,usize,isize,f32,f64和char。它们的内存布局在不同型号的设备上略有差异
在非
x86设备上,存储宽度size= 对齐位数alignment(即,倍数N = 1)在
x86设备上,因为设备允许的最大对齐位数不能超过4字节,所以alignment ≼ 4 Byteu64与f64的size = alignment * 2(即,N = 2)。u128与i128的size = alignment * 4(即,N = 4)。其它基本数据类型依旧
size = alignment(即,倍数N = 1)。
FST瘦指针
瘦指针的内存布局与usize类型是一致的。因此,在不同设备和不同架构上,其性能表现略有不同
在非
x86的32位架构上,size = alignment = 4 Byte(N = 1)64位架构上,size = alignment = 8 Byte(N = 1)
在
x86的size = 8 Bytealignment = 4 Byte—x86设备最大对齐位数不能超过4字节N = 232位架构上,size = alignment = 4 Byte(N = 1)64位设备上,
DST胖指针
胖指针的存储宽度size是usize类型的两倍,对齐位数却与usize相同。就依赖于设备/架构的性能表现而言,其与瘦指针行为一致:
在非
x86的size = 16 Bytealignment = 8 ByteN = 2size = 8 Bytealignment = 4 ByteN = 232位架构上,64位架构上,
在
x86的size = 16 Bytealignment = 4 Byte—x86设备最大对齐位数不能超过4字节N = 4size = 8 Bytealignment = 4 ByteN = 232位架构上,64位设备上,
数组[T; N],切片[T]和str
str就是满足UTF-8编码规范的增强版[u8]切片。
存储宽度size是全部元素存储宽度之和
array.size = std::mem::size_of::<T>() * array.len();对齐位数alignment与单个元素的对齐位数一致。
array.alignment = std::mem::align_of::<T>();()单位类型
存储宽度size = 0 Byte
对齐位数alignment = 1 Byte
所有零宽度数据类型都是这样的内存布局配置。
来自【标准库】的零宽度数据类型包括但不限于:
()单位类型 — 模拟“空”。std::marker::PhantomData<T>— 绕过“泛型类型形参必须被使用”的编译规则。进而,成就类型状态设计模式中的Phantom Type。std::marker::PhantomPinned<T>— 禁止变量值在内存中“被挪来挪去”。进而,成就异步编程中的“自引用结构体self-referential struct”。
自定义数据结构的内存布局
复合数据结构的内存布局描绘了该数据结构(紧内一层)字段的内存位置“摆放”关系(比如,间隙与次序等)。在层叠嵌套的数据结构中,内存布局都是就某一层数据结构而言的。它既承接不了来自外层父数据结构的内存布局,也决定不了更内层子数据结构的内存布局,更代表不了整个数据结构内存布局的总览。举个例子,
#[repr(C)]
struct Data {id: u32,name: String
}#[repr(C)]仅只代表最外层结构体Data的两个字段id和name是按C内存布局规格“摆放”在内存中的。但,#[repr(C)]并不意味着整个数据结构都是C内存布局的,更改变不了name字段的String类型是Rust内存布局的事实。若你的代码意图是定义完全C ABI的结构体,那么【原始指针】才是该用的类型。
use ::std::ffi::{c_char, c_uint};
#[repr(C)]
struct Data {id: c_uint,name: *const c_char // 注意对比
}内存布局核心参数
自定义数据结构的内存布局包含如下五个属性
alignment
定义:数据结构自身的对齐位数
规则:
alignment=2的n次幂(n是≼ 29的自然数)不同于基本数据类型
alignment = size,自定义数据结构alignment的算法随不同的数据结构而相异。
size
定义:数据结构自身的宽度
规则:
size必须是alignment自然数倍。若有效数据长度payload_size不足size,就添补空白【对齐填充位】凑足宽度。
field.alignment
定义:每个字段的对齐位数
规则:
field.alignment=2的n次幂(n是≼ 29的自然数)
field.size
定义:每个字段的宽度
规则:
field.size必须是field.alignment自然数倍。若有效数据长度field.payload_size不足field.size,就添补空白【对齐填充位】凑足宽度。
field.offset
定义:每个字段首字节地址相对于上一层数据结构首字节地址的偏移字节数
规则:
field.offset必须是field.alignment自然数倍。若不足,就垫入空白【对齐填充位】和向后推移当前字段的起始位置。前一个字段的
field.offset + field.size ≼后一个字段的field.offset
自定义枚举类enum的内存布局一般与枚举类分辨因子discriminant的内存布局一致。更复杂的情况,请见下文章节。
预置内存布局方案
编译器内置了四款内存布局方案,分别是
默认
Rust内存布局 — 没有元属性注释C内存布局#[repr(C)]数字类型·内存布局
#[repr(u8 / u16 / u32 / u64 / u128 / usize / i8 / i16 / i32 / i64 / i128 / isize)]
仅适用于枚举类。
支持与
C内存布局混搭使用。比如,#[repr(C, u8)]。
透明·内存布局 #[repr(transparent)]
仅适用于单字段数据结构。
预置内存布局方案对比
相较于C内存布局,Rust内存布局面向内存空间利用率做了优化 — 省内存。具体的技术手段包括Rust编译器
重排了字段的存储顺序,以尽可能多地消减掉“边角料”(对齐填充)占用的字节位数。于是,在源程序中字段声明的词法次序经常不同于【运行时】它们在内存里的实际存储顺序。
允许多个零宽度字段共用一个内存地址。甚至,零宽度字段也被允许与普通(有数据)字段共享内存地址。
以C ABI中间格式为桥的C内存布局虽然实现了Rust跨语言数据结构,但它却更费内存。这主要出于两个方面原因:
C内存布局未对字段存储顺序做优化处理,所以字段在源码中的词法顺序就是它们在内存条里的存储顺序。于是,若 @程序员 没有拿着算草纸和数着比特位“人肉地”优化每个数据结构定义,那么由对齐填充位冗余造成的内存浪费不可避免。C内存布局不支持零宽度数据类型。零宽度数据类型是Rust语言设计的重要创新。相比之下,
(参见
C17规范的第6.7.2.1节)无字段结构体会导致标准C程序出现U.B.,除非安装与开启GNU的C扩展。Cpp编译器会强制给无字段结构体安排一个字节宽度,除非该数据结构被显式地标记为[[no_unique_address]]。
以费内存为代价,C内存布局赋予Rust数据结构的另一个“超能力”就是:“仅通过变换【指针类型】就可将内存上的一段数据重新解读为另一个数据类型的值”。比如,void * / std::ffi::c_void被允许指向任意数据类型的变量值 例程。但在Rust内存布局下,需要调用专门的标准库函数std::intrinsics::transmute()才能达到相同的目的。
除了上述鲜明的差别之外,C与Rust内存布局都允许【对齐位数alignment】参数被微调,而不一定总是全部字段alignment中的最大值。这包括但不限于:
修饰符
align(x)增加alignment至指定值。例如,#[repr(C, align(8))]将C内存布局中的【对齐位数】上调至8字节修饰符
packed(x)减小alignment至指定值。例如,#[repr(packed)]将默认Rust内存布局中的【对齐位数】下调至1字节
结构体struct的C内存布局
结构体算是最“中规中矩”的数据结构。无论是否对结构体的字段重新排序,只要将它们一个不落地铺到内存上就完成一多半功能了。所以,结构体存储宽度struct.size是全部字段size之和再(自然数倍)对齐于【结构体对齐位数struct.alignment】的结果。有点抽象上伪码
struct.size = struct.fields().map(|field| field.size).sum() // 第一步,求全部字段宽度值之和.next_multiple_of(struct.alignment); // 第二步,求既大于等于【宽度值之和】,又是`struct.alignment`自然数倍的最小数值相较于Rust内存布局优化算法的错综复杂,我好似只能讲清楚C内存布局的始末:
首先,结构体自身的对齐位数struct.alignment就是全部字段对齐位数field.alignment中的最大值。
struct.alignment = struct.fields().map(|field| field.alignment).max();其次,声明一个(可修改的)游标变量offset_cursor以实时跟踪(参照于结构体首字节地址的)字节偏移量。游标变量的初始值为0表示该游标与结构体的内存起始位置重合。
let mut offset_cursor = 0;接着,沿着源码中字段的声明次序,逐一处理各个字段:
【对齐】若游标变量值
offset_cursor不是当前字段对齐位数field.alignment的自然数倍(即,未对齐),就计算既大于等于offset_cursor又是field.alignment自然数倍的最小数值。并将计算结果更新入游标变量offset_cursor,以插入填充位对齐和向后推移字段在内存中的”摆放“位置。if offset_cursor.rem_euclid(field.alignment) > 0 {offset_cursor = offset_cursor.next_multiple_of(field.alignment); }【定位】当前游标的位置就是该字段的首字节偏移量
field.offset = offset_cursor;跳过当前字段宽度
field.size— 递归算法求值子数据结构的存储宽度。字段子数据结构的内存布局对上一层父数据结构是黑盒的。offset_cursor += field.size继续处理下一个字段。
然后,在结构体内全部字段都被如上处理之后,
【对齐】若游标变量值
offset_cursor不是结构体对齐位数struct.alignment的自然数倍(即,未对齐),就计算既大于等于offset_cursor又是struct.alignment自然数倍的最小数值。并将计算结果更新入游标变量offset_cursor,以增补填充位对齐和扩容有效数据长度至结构体存储宽度。if offset_cursor.rem_euclid(struct.alignment) > 0 {offset_cursor = offset_cursor.next_multiple_of(struct.alignment); }【定位】当前游标值就是整个结构体的宽度(含全部对齐填充位)
struct.size = offset_cursor;
至此,结构体的C内存布局结束。然后,std::alloc::GlobalAlloc就能够拿着这套“策划案”向操作系统申请内存空间去了。由此可见,每次【对齐】处理都会在有效数据周围“埋入”大量空白“边角料”(学名:对齐填充位alignment padding)。但出于历史原因,为了完成与其它计算机语言的FFI互操作,这些浪费还是必须的。下面附以完整的伪码辅助理解
// 1. 结构体的【对齐位数】就是它的全部字段【对齐位数】中的最大值。
struct.alignment = struct.fields().map(|field| field.alignment).max();
// 2. 声明一个游标变量,以实时跟踪(相对于结构体首字节地址)的偏移量。
let mut offset_cursor = 0;
// 3. 按照字段在源代码中的词法声明次序,逐一遍历每个字段。
for field in struct.fields_in_declaration_order() {if offset_cursor.rem_euclid(field.alignment) > 0 {// 4. 需要【对齐】当前字段offset_cursor = offset_cursor.next_multiple_of(field.alignment);} // 5. 【定位】字段的偏移量就是游标变量的最新值。field.offset = offset_cursor;// 6. 在跳过当前字段宽度的字节长度(含对齐填充字节数)offset_cursor += field.size;
}
if offset_cursor.rem_euclid(struct.alignment) > 0 {// 7. 需要【对齐】结构体自身offset_cursor = offset_cursor.next_multiple_of(struct.alignment);
}
// 8. 【定位】结构体的宽度(含对齐填充字节数)就是游标变量的最新值。
struct.size = offset_cursor;联合体union的C内存布局
形象地讲,联合体是给内存中同一段字节序列准备了多套“数据视图”,而每套“数据视图”都尝试将该段字节序列解释为不同数据类型的值。所以,无论在联合体内声明了几个字段,都仅有一个字段值会被保存于物理存储之上。从原则上讲,联合体union的内存布局一定与占用内存最多的字段一致,以确保任何字段值都能被容纳。从实践上讲,有一些细节处理需要斟酌:
联合体的对齐位数
union.alignment等于全部字段对齐位数中的最大值(同结构体)。union.alignment = union.fields().map(|field| field.alignment).max();联合体的存储宽度
union.size是最长字段宽度值longest_field.size(自然数倍)对齐于联合体自身对齐位数union.alignment的结果。有点抽象上伪码union.size = union.fields().map(|field| field.size).max() // 第一步,求最长字段的宽度值.next_multiple_of(union.alignment); // 第二步,求既大于等于【最长字段宽度值】,又是`union.alignment`自然数倍的最小数值
举个例子,联合体Example0内包含了u8与u16类型的两个字段,那么Example0的内存布局就一定与u16的内存布局一致。再举个例子,
use ::std::mem;
#[repr(C)]
union Example1 {f1: u16,f2: [u8; 4],
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example1>(), mem::align_of::<Example1>())看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下:
字段
f1的
存储宽度
size是2字节。对齐位数
alignment也是2字节,因为基本数据类型的【对齐位数alignment】就是它的【存储宽度size】。
字段f2的
存储宽度
size是4字节,因为数组的【存储宽度size】就是全部元素存储宽度之和。对齐位数
alignment是1字节,因为数组的【对齐位数alignment】就是元素的【对齐位数alignment】。
联合体Example1的
对齐位数
alignment就是2字节,因为取最大值存储宽度
size是4字节,因为得取最大值
再来一个更复杂点儿的例子,
use ::std::mem;
#[repr(C)]
union Example2 {f1: u32,f2: [u16; 3],
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example2>(), mem::align_of::<Example2>())同样,在看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下:
字段
f1的存储宽度与对齐位数都是4字节。字段
f2的
对齐位数是
2字节。存储宽度是
6字节。
联合体Example2的
对齐位数
alignment是4字节 — 取最大值,没毛病。存储宽度
size是8字节,因为不仅得取最大值6字节,还得向Example2.alignment自然数倍对齐。于是,才有了额外2字节的【对齐填充】和扩容【联合体】有效长度6字节至存储宽度8字节。你猜对了吗?
不经意的巧合
思维敏锐的读者可以已经注意到:单字段【结构体】与单字段【联合体】的内存布局是相同的,因为数据结构自身的内存布局就是唯一字段的内存布局。不信的话,执行下面的例程试试
use ::std::mem;
#[repr(C)]
struct Example3 {f1: u16
}
#[repr(C)]
union Example4 {f1: u16
}
// struct 内存布局 等同于 union 的内存布局
assert_eq!(mem::align_of::<Example3>(), mem::align_of::<Example4>());
assert_eq!(mem::size_of::<Example3>(), mem::size_of::<Example4>());
// struct 内存布局 等同于 u16 的内存布局
assert_eq!(mem::align_of::<Example3>(), mem::align_of::<u16>());
assert_eq!(mem::size_of::<Example3>(), mem::size_of::<u16>());枚举类enum的C内存布局
突破“枚举”字面含义的束缚,Rust的创新使Rust enum与传统计算机语言中的同类项都不同。Rust枚举类
既包括:
C风格的“轻装”枚举 — 仅标记状态,却不记录细节数据。也支持:
Rust风格的“重装”枚举 — 标记状态的同时也记录细节数据。
在Rust References一书中,
“轻装”枚举被称为“无字段·枚举类 field-less enum”或“仅单位类型·枚举类 unit-only enum”。
“重装”枚举被别名为“伴字段·枚举类
enum with fields”。在
Cpp程序中,需要借助【标准库】的Tagged Union数据结构才能模拟出同类的功能来。欲了解更多技术细节,推荐读我的另一篇文章。
禁忌:C内存布局的枚举类必须至少包含一个枚举值。否则,编译器就会报怨:error[E0084]: unsupported representation for zero-variant enum。
“轻装”枚举类的内存布局
因为“轻装”枚举值的唯一有效数据就是“记录了哪个枚举项被选中的”分辨因子discriminant,所以枚举类的内存布局就是枚举类【整数类型】分辨因子的内存布局。即,
LightEnum.alignment = discriminant.alignment; // 对齐位数
LightEnum.size = discriminant.size; // 存储宽度别庆幸!故事远没有看起来这么简单,因为【整数类】是一组数字类型的总称(馁馁的“集合名词”)。所以,它包含但不限于
| Rust | C | 存储宽度 |
|---|---|---|
| u8 / i8 | unsigned char / char | 单字节 |
| u16 / i16 | unsigned short / short | 双字节 |
| u32 / i32 | unsigned int / int | 四字节 |
| u64 / i64 | unsigned long / long | 八字节 |
| usize / isize | 没有概念对等项,可能得元编程了 | 等长于目标架构“瘦指针”宽度 |
维系FFI两端Rust和C枚举类分辨因子都采用相同的整数类型才是最“坑”的,因为
C / Cpp enum实例可存储任意类型的整数值(比如,char,short,int和long)— 部分原因或许是C系语法灵活的定义形式:“typedef enum块 + 具名常量”。所以,C / Cpp enum非常适合被做成“比特开关”。但在Rust程序中,就不得不引入外部软件包bitflags了。C内存布局Rust枚举类分辨因子discriminant只能是i32类型 — 【存储宽度size】是固定的4字节。Rust内存布局·枚举类·分辨因子discriminant的整数类型是编译时由rustc决定的,但最宽支持到isize类型。
这就对FFI - C端的程序设计提出了额外的限制条件:至少,由ABI接口导出的枚举值得用int类型定义。否则,Rust端FFI函数调用就会触发U.B.。FFI门槛稍有上升。
扼要归纳:
FFI - Rust端C内存布局的枚举类对FFI - C端枚举值的【整数类型】提出了“确定性假设invariant”:枚举值的整数类型是int且存储宽度等于4字节。C端 @程序员 必须硬编码所有枚举值的数据类型,以满足该假设。FFI跨语言互操作才能成功“落地”,而不是发生U.B.。
来自C端的迁就固然令人心情愉悦,但新应用程序难免要对接兼容遗留系统与旧链接库。此时,再给FFI - C端提要求就不那么现实了 — 深度改动“屎山”代码风险巨大,甚至你可能都没有源码。【数字类型·内存布局】正是解决此棘手问题的技术方案:
以【元属性】
#[repr(整数类型名)]注释枚举类定义明确指示
Rust编译器采用给定【整数类型】的内存布局,组织【分辨因子discriminant】的数据存储,而不总是遵循i32内存布局。
从C / Cpp整数类型至Rust内存布局元属性的映射关系包括但不限于
| C | Rust 元属性 |
|---|---|
| unsigned char / char | #[repr(u8)] / #[repr(i8)] |
| unsigned short / short | #[repr(u16)] / #[repr(i16)] |
| unsigned int / int | #[repr(u32)] / #[repr(i32)] |
| unsigned long / long | #[repr(u64)] / #[repr(i64)] |
举个例子,
use ::std::mem;
#[repr(C)]
enum Example5 { // ”轻装“枚举类,因为A(), // field-less variantB {}, // field-less variantC // unit variant
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example5>(), mem::align_of::<Example5>());上面代码定义的是C内存布局的“轻装”枚举类Example5,因为它的每个枚举值不是“无字段”,就是“单位类型”。于是,Example5的内存布局就是i32类型的alignment = size = 4 Byte。
再举个例子,
use ::std::mem;
#[repr(u8)]
enum Example6 { // ”轻装“枚举类,因为A(), // field-less variantB {}, // field-less variantC // unit variant
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example6>(), mem::align_of::<Example6>());上面代码定义的是【数字类型·内存布局】的“轻装”枚举类Example6。它的内存布局是u8类型的alignment = size = 1 Byte。
“重装”枚举类的内存布局
【“重装”枚举类】绝对是Rust语言设计的一大创新,但同时也给FFI跨语言互操作带来了严重挑战,因为在其它计算机语言中没有概念对等的核心语言元素“接得住它”。对此,在做C内存布局时,编译器rustc会将【“重装”枚举类】“降维”成一个双字段结构体:
第一个字段是:剥去了所有字段的【“轻装”枚举】,也称【分辨因子枚举类
Discriminant enum】。第二个字段是:由枚举值
variant内字段fields拼凑成的【结构体struct】组成的【联合体union】。
前者记录选中项的“索引值” — 谁被选中;后者记忆选中项内的值:根据索引值,以对应的数据类型,读/写联合体实例的字段值。
文字描述着实有些晦涩与抽象。边看下图,边再体会。一图抵千词!(关键还是对union数据类型的理解)
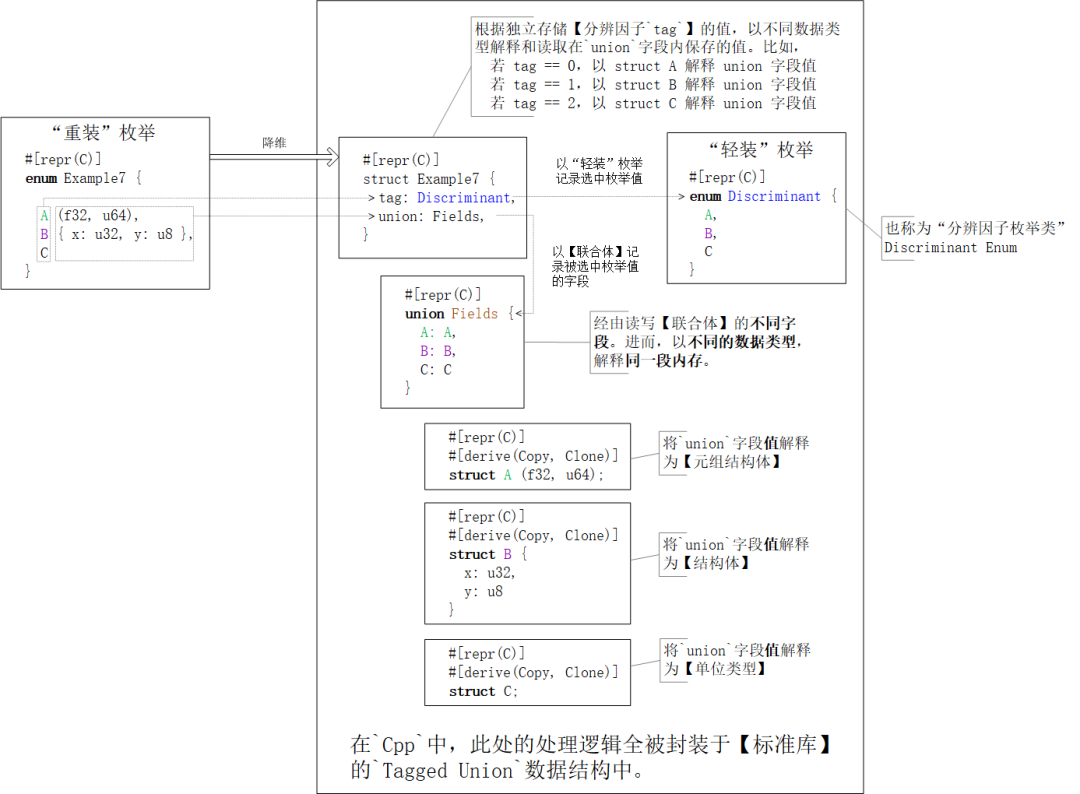
上图中有三个很细节的知识点容易被读者略过,所以在这里特意强调一下:
保存枚举值字段的结构体
struct A / B / C都既派生了trait Copy,又派生了trait Clone,因为
union数据结构要求它的每个字段都是可复制的同时,
trait Copy又是trait Clone的subtrait
降维后结构体struct Example7内的字段名不重要,但字段排列次序很重要。因为在C ABI中,结构体字段的存储次序就是它们在源码中的声明次序,所以Cpp标准库中的Tagged Union数据结构总是,根据约定的字段次序,
将第一个字段解释为“选中项的索引号”,
将第二个字段解读为“选中项的数据值”。
C内存布局的分辨因子枚举类enum Discriminant的分辨因子discriminant依旧是i32类型值,所以FFI - C端的枚举值仍旧被要求采用int整数类型。
举个例子,
use ::std::mem;
#[repr(C)]
enum Example8 {Variant0(u8),Variant1,
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example8>(), mem::align_of::<Example8>())看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下:
enum被“降维”成struct就
C内存布局而言,struct的alignment是全部字段alignment中的最大值。字段
union.Variant0是单字段元组结构体,且字段类型是基本数据类型。所以,union.Variant0.alignment = union.Variant0.size = 1 Byte字段
union.Variant1是单位类型。所以,union.Variant1.alignment = 1 Byte和union.Variant1.size = 0 Byte于是,
union.alignment = 1 Byte字段
tag是C内存布局的“轻装”枚举类。所以,tag.alignment = tag.size = 4 Byte字段
union是union数据结构。所以,union的alignment也是全部字段alignment中的最大值。于是,
struct.alignment = 4 Byte
struct的size是全部字段size之和。union.Variant0.size = 1 Byteunion.Variant1.size = 0 Byte于是,
union.size = 1 Byte字段
tag是C内存布局的“轻装”枚举类。所以,tag.size = 4 Byte字段
union是union数据结构。union的size是全部字段size中的最大值。于是,不精准地
struct.size ≈ 5 Byte(约等)此刻
struct.size并不是struct.alignment的自然数倍。所以,需要给struct增补“对齐填充位”和向struct.alignment自然数倍对齐于是,
struct.size = 8 Byte(直等)
哎!看见没,C内存布局还是比较费内存的,一少半都是空白“边角料”。
【“重装”枚举类】同样会遇到FFI - ABI两端【Rust枚举类分辨因子discriminant】与【C枚举值】整数类型一致约定的难点。为了迁就C端遗留系统和旧链接库对枚举值【整数类型】的选择,Rust编译器依旧选择“降维”处理enum。但,这次不是将enum变形成struct,而是跳过struct封装和直接以union为“话事人”。同时,将【分辨因子·枚举值】作为union字段子数据结构的首个字段:
对元组枚举值,分辨因子就是子数据结构第
0个元素对结构体枚举值,分辨因子就子数据结构第一个字段。注:字段名不重要,字段次序更重要。
文字描述着实有些晦涩与抽象。边看下图,边对比上图,边体会。一图抵千词!
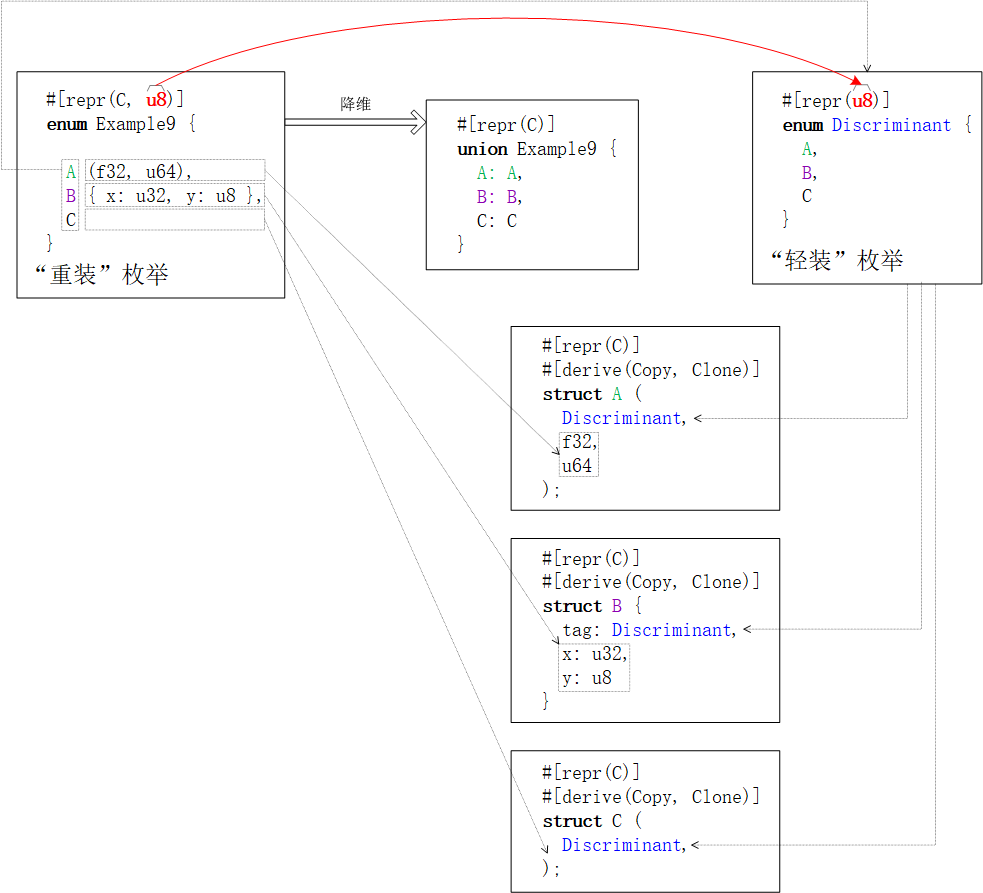
由上图可见,C与【数字类型】的混合内存布局
既保证了降级后
union与struct数据结构继续满足C ABI的存储格式要求。又确保了【
Rust端枚举类分辨因子】与【C端枚举值】之间整数类型的一致性。
举个例子,假设目标架构是32位系统,
use ::std::mem;
#[repr(C, u16)]
enum Example10 {Variant0(u8),Variant1,
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example10>(), mem::align_of::<Example10>())看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下:
enum被“降维”成unionunion的alignment是全部字段alignment中的最大值。第一个字段是
u16类型的分辨因子枚举值。所以,Variant0.0.alignment = Variant0.0.size = 2 Byte第二个字段是
u8类型数字。所以,Variant0.1.alignment = Variant0.1.size = 1 Byte于是,
union.Variant0.alignment = 2 Byte字段
union.Variant0是双字段元组结构体。所以,struct的alignment是全部字段alignment中的最大值。字段
union.Variant1是单字段元组结构体且唯一字段就是u16分辨因子枚举值。所以,union.Variant1.alignment = union.Variant1.size = 2 Byte于是,
union.alignment = 2 Byte
union的size是全部字段size中的最大值。第一个字段是
u16类型的分辨因子枚举值。所以,Variant0.0.size = 2 Byte第二个字段是
u8类型数字。所以,Variant0.1.size = 1 byte于是,不精准地
union.Variant0.size ≈ 3 Byte(约等)此刻
union.Variant0.size不是union.Variant0.alignment的自然数倍。所以,需要对union.Variant0增补“对齐填充位”和向union.Variant0.alignment自然数倍对齐于是,
union.Variant0.size = 4 Byte(直等)字段
union.Variant0是双字段元组结构体。所以,struct的size是全部字段size之和。字段
union.Variant1是单字段元组结构体且唯一字段就是u16分辨因子枚举值。所以,union.Variant1.size = 2 Byte于是,
union.size = 4 Byte
哎!看见没,C 内存布局还是比较费内存的,一少半的“边角料”。
新设计方案好智慧
优化掉了一层
struct封装。即,从enum ➜ struct ➜ union缩编至enum ➜ union将被优化掉的
struct的职能(— 记录选中项的“索引值”)合并入了union字段的子数据结构中。于是,联合体的每个字段
既要,保存枚举值的字段数据 — 旧职能
还要,记录枚举值的“索引号” — 新职能
但有趣的是,比较上一版数据存储设计方案,C内存布局却没有发生变化。逻辑描述精简了但物理实质未变,这太智慧了!因此,由Cpp标准库提供的Tagged Union数据结构依旧“接得住”Rust端【“重装”枚举值】。
仅【数字类型·内存布局】的“重装”枚举类
若不以C加【数字类型】的混合内存布局来组织枚举类enum Example9的数据存储,而仅保留【数字类型】内存布局,那么上例中被降维后的【联合体】与【结构体】就都会缺省采用Rust内存布局。参见下图:
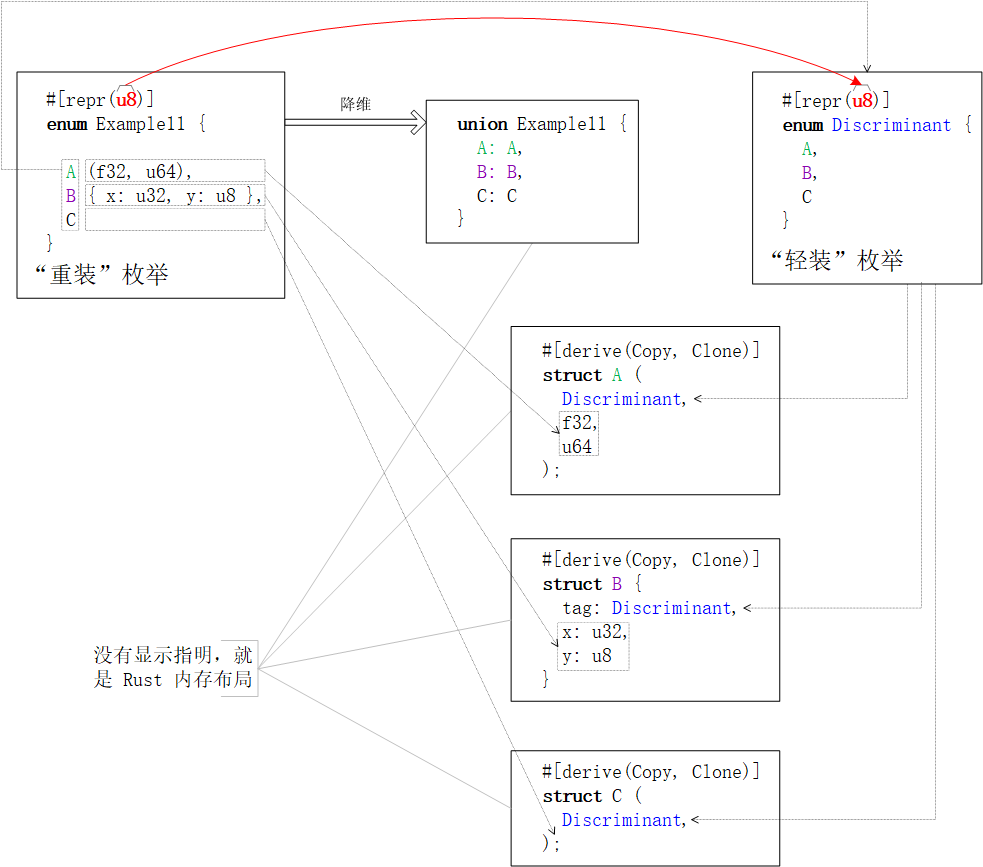
补充于最后,思维活跃的读者这次千万别想太多了。没有#[repr(transparent, u16)]的内存布局组合,因为【透明·内存布局】向来都是“孤来孤往”的。
数字类型·内存布局
仅【枚举类】支持【数字类型·内存布局】。而且,将无枚举值的枚举类注释为【数字类型·内存布局】会导致编译失败。举个例子
#[repr(u16)]
enum Example12 {// 没有任何枚举值
}会导致编译失败error[E0084]: unsupported representation for zero-variant enum。
透明·内存布局
“透明”不是指“没有”,而是意味着:在层叠嵌套数据结构中,外层数据结构的【对齐位数】与【存储宽度】等于(紧)内层数据结构的【对齐位数】和【存储宽度】。因此,它仅适用于
单字段的结构体 — 结构体的【对齐位数】与【存储宽度】等于唯一字段的【对齐位数】和【存储宽度】。
struct.alignment = struct.field.alignment; struct.size = struct.field.size;单枚举值且单字段的“重装”枚举类 — 枚举类的【对齐位数】与【存储宽度】等于唯一枚举值内唯一字段的【对齐位数】和【存储宽度】。
HeavyEnum.alignment = HeavyEnum::variant.field.alignment; HeavyEnum.size = HeavyEnum::variant.field.size;单枚举值的“轻装”枚举类 — 枚举类的【对齐位数】与【存储宽度】等于单位类型的【对齐位数】和【存储宽度】。
LightEnum.alignment = 1; LightEnum.size = 0;
原则上,数据结构中的唯一字段必须是非零宽度的。但是,若【透明·内存布局】数据结构涉及到了
类型状态设计模式
异步多线程
,那么Rust内存布局的灵活性也允许:结构体和“重装”枚举值额外包含任意数量的零宽度字段。比如,
std::marker::PhantomData<T>为类型状态设计模式,提供Phantom Type支持。std::marker::PhantomPinned<T>为自引用数据结构,提供!Unpin支持。
举个例子,
use ::std::{marker::PhantomData, mem};
#[repr(transparent)]
enum Example13<T> { // 含`Phantom Type`的“重装”枚举类Variant0 (f32, // 普通有数据字段PhantomData<T> // 零宽度字段。泛型类型形参未落实到有效数据上。)
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example13<String>>(), mem::align_of::<Example13<String>>())看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下:
因为
Example14.Variant0.1字段是零宽度数据类型PhantomData,所以它的和不参与内存布局计算。
alignment = 1 Bytesize = 0 Byte首字节地址
address与Example10.Variant0.0字段重叠。
因为【透明·内存布局】,所以 外层枚举类的
【对齐位数】
Example14.alignment = Example10::Variant0.0.alignment = 4 Byte【存储宽度】
Example14.size = Example10::Variant0.0.size = 4 Byte
不同于【数字类型·内存布局】,【透明·内存布局】不被允许与其它内存布局混合使用。比如,
#[repr(C, u16)]是合法的#[repr(C, transparent)]和#[repr(transparent, u16)]就会导致语编译失败
其它类型的内存布局
trait Object与由胖指针&dyn Trait/Box<dyn Trait>引用的变量值的【内存布局】相同。闭包
Closure没有固定的【内存布局】。
微调内存布局
只有Rust与C内存布局具备微调能力,且只能修改【对齐位数alignment】参数值。另外,不同数据结构可做的微调操作也略有不同:
struct,union,enum数据结构可上调对齐位数仅
struct,union被允许下调对齐位数
数据结构【对齐位数alignment】值的增加与减少需要使用不同的元属性修饰符
#[repr(align(新·对齐位数))]增加对齐位数至新值。将小于等于数据结构原本对齐位数的值输入align(x)修饰符是无效的。#[repr(packed(新·对齐位数))]减少对齐位数至新值。将大于等于数据结构原本对齐位数的值输入packed(x)修饰符也是无效的。
align(x)与packed(x)修饰符的实参是【目标】字节数,而不是【增量】字节数。所以,#[repr(align(8))]指示编译器增加对齐数至8字节,而不是增加8字节。另外,新对齐位数必须是2的自然数次幂。
禁忌
同一个数据类型不被允许既增加又减少对齐位数。即,
align(x)与packed(x)修饰符不能共同注释一个数据类型定义。减小对齐位数的外层数据结构禁止包含增加对齐位数的子数据结构。即,
#[repr(packed(x))]数据结构不允许嵌套包含#[repr(align(y))]子数据结构。
枚举类内存布局的微调
首先,枚举类不允许下调对齐位数。
其次,上调枚举类的对齐位数也会触发“内存布局重构”的负作用。编译器会效仿Newtypes 设计模式重构#[repr(align(x))] enum枚举类为嵌套包含了enum的#[repr(align(x))] struct元组结构体。一图抵千词,请参阅下图。
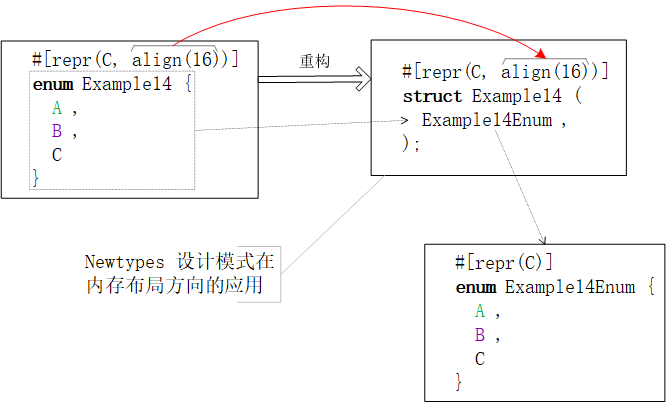
由上图可见,在内存布局重构之后,C内存布局继续保留在枚举类上,而align(16)修饰符仅对外层的结构体有效。所以,从底层实现来讲,枚举类是不支持内存布局微调的,仅能借助外层的Newtypes数据结构间接限定。
以上面的数据结构为例,
use ::std::mem;
#[repr(C, align(16))]
enum Example15 {A,B,C
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example15>(), mem::align_of::<Example15>())看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下:
因为
C内存布局,所以枚举类的分辨因子是i32类型和枚举类的存储宽度size = 4 Byte。但,
align(16)将内存空间占用强制地从alignment = size = 4 Byte提升到alignment = size = 16 Byte。
结束语
这次分享的内容比较多,感谢您耐心地读到文章结束。文章中问答式例程的输出结果,您猜对了几个呀?
内存布局是一个非常宏大技术主题,这篇文章仅是抛砖引玉,讲的粒度比较粗,涉及的具体数据结构也都很基础。更多FFI和内存布局的实践经验沉淀与知识点汇总,我将在相关技术线的后续文章中陆续分享。
路过神仙哥哥与仙女妹妹们,多给文章发评论与点赞呀!
相关文章:
【Rust笔记】浅聊 Rust 程序内存布局
浅聊Rust程序内存布局 内存布局看似是底层和距离应用程序开发比较遥远的概念集合,但其对前端应用的功能实现颇具现实意义。从WASM业务模块至Nodejs N-API插件,无处不涉及到FFI跨语言互操作。甚至,做个文本数据的字符集转换也得FFI调用操作系统…...

玻璃生产过程中的窑内压力高精度恒定控制解决方案
摘要:在玻璃生产中对玻璃窑炉中窑压的要求极高,通常需要控制微正压4.7Pa(表压),偏差控制在0.3Pa,而窑炉压力还会受到众多因素的影响,所以实现高稳定性的熔窑压力控制具有很大难度,为…...

创意营销:初期推广的多种策略!
文章目录 🍊 预热🎉 制定预热计划和目标🎉 利用社交媒体传播🎉 创造独特的体验🎉 利用口碑营销🎉 定期发布更新信息🎉 案例说明 🍊 小范围推广🎉 明确目标用户群体&#…...
【小黑嵌入式系统第一课】嵌入式系统的概述(一)
文章目录 一、嵌入式系统基本概念计算机发展的三大阶段CPU——计算机的核心什么是嵌入式系统嵌入式系统的分类 二、嵌入式系统的特点三、嵌入式系统发展无操作系统阶段简单操作系统阶段实时操作系统阶段面向Internet阶段 四、嵌入式系统的应用工业控制 工业设备通信设备信息家电…...

RK平台使用MP4视频做开机动画以及卡顿问题
rk平台android11以后系统都可以使用MP4格式的视频做开机动画,系统源码里面默认使用的是ts格式的视频,其实使用mp4的视频也是可以的。具体修改如下: diff --git a/frameworks/base/cmds/bootanimation/BootAnimation.cpp b/frameworks/base/cmds/bootanimation/BootAnimat…...
通讯网关软件023——利用CommGate X2HTTP实现HTTP访问Modbus TCP
本文介绍利用CommGate X2HTTP实现HTTP访问Modbus TCP。CommGate X2HTTP是宁波科安网信开发的网关软件,软件可以登录到网信智汇(http://wangxinzhihui.com)下载。 【案例】如下图所示,SCADA系统上位机、PLC、设备具备Modbus RTU通讯接口,现在…...
Python性能测试框架Locust实战教程!
01、认识Locust Locust是一个比较容易上手的分布式用户负载测试工具。它旨在对网站(或其他系统)进行负载测试,并确定系统可以处理多少个并发用户,Locust 在英文中是 蝗虫 的意思:作者的想法是在测试期间,放…...
c++视觉处理---仿射变换和二维旋转变换矩阵的函数
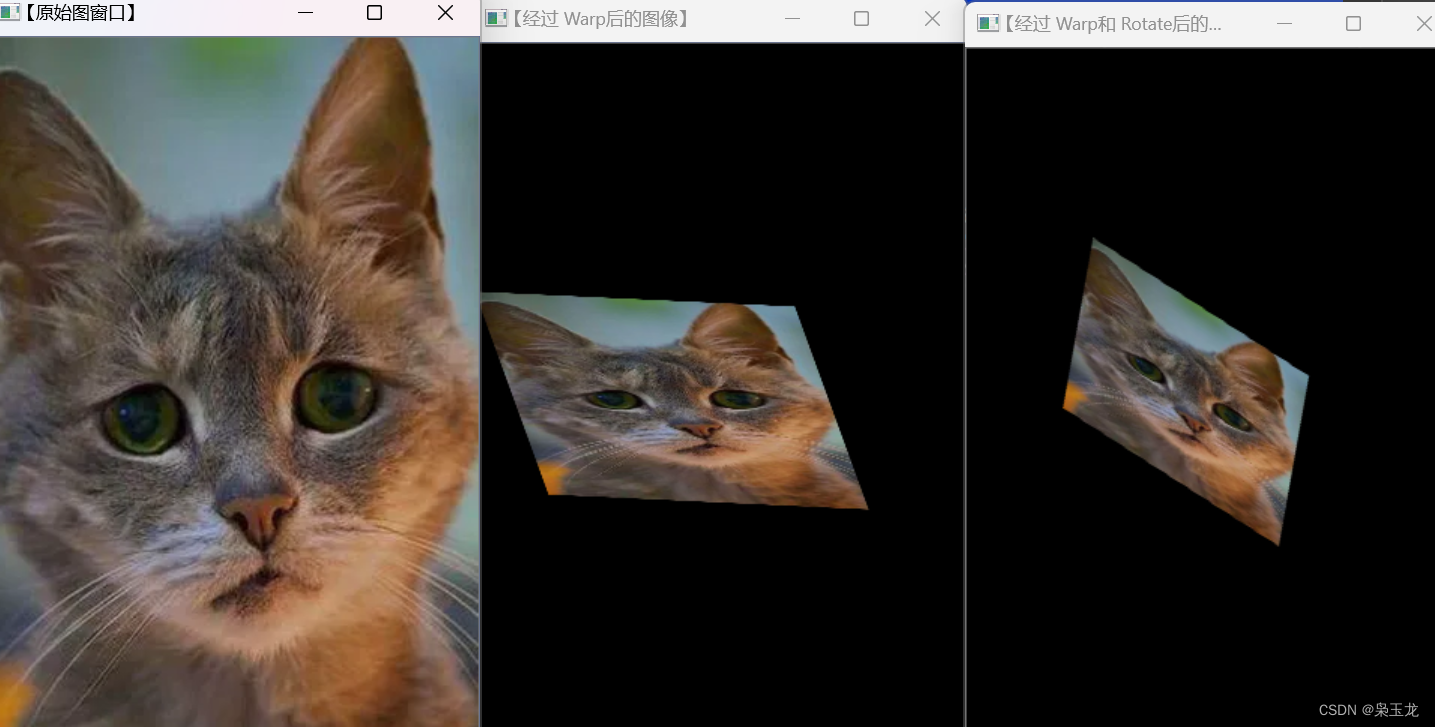
仿射变换cv::warpAffine cv::warpAffine 是OpenCV中用于执行仿射变换的函数。仿射变换是一种线性变换,可用于执行平移、旋转、缩放和剪切等操作。下面是 cv::warpAffine 函数的基本用法: cv::warpAffine(src, dst, M, dsize, flags, borderMode, borde…...
)
uiautomator2遍历子元素.all()
当你获取了页面某个元素之后 elements d(’//*[clickable“true”]’).all() 返回的是一个list,其中是<uiautomator2.xpath.XMLElement>类型的变量。 可以通过以下方式获取它所有子类的信息。 for ele in elements:children ele.elem.getchildren()注意…...

【手写数据库toadb】SQL字符串如何被数据库认识? 词法语法分析基础原理,常用工具
词法语法分析 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定期更新,对应的代码也会定期更新,每个阶段的代码会打上tag,方便阶段…...

手把手教你基于windows系统使用GNVM进行node切换版本
GNVM是什么? GNVM 是一个简单的 Windows 下 Node.js 多版本管理器,类似的 nvm nvmw nodist 。 安装 进入官网,下载你所需要的包,直达链接 下载完成 放到我们的node环境包下,点击运行 请注意区分: 不存在 Node.js 环…...
c#画五角星
c#画一个五角星,最重要的就是计算哪些坐标点出来,也是最难的一部分,这要涉及到一些数学方面的知识.对数学坐标知识不是很熟的人,如果想学画图,我建议多去看一下数学书,对我们写程序的人来说是没有什么坏处可言的. 想学习的朋友可以一起学习,我觉得分享学习是一种快乐,所以把自…...
第三章 数据链路层 | 计算机网络(谢希仁 第八版)
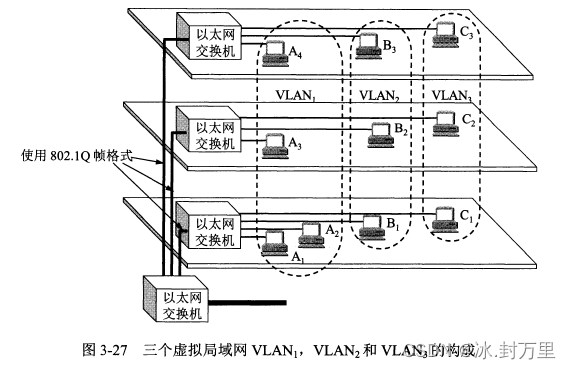
文章目录 第三章 数据链路层3.1 使用点对点信道的数据链路层3.1.1 数据链路和帧3.1.2 三个基本问题 3.2 点对点协议PPP3.2.1 PPP协议的特点3.2.2 PPP协议的帧格式3.2.3 PPP协议的工作状态 3.3 使用广播信道的数据链路层3.3.1 局域网的数据链路层3.3.2 CSMA/CD协议3.3.3 使用集线…...

李沐机器学习环境配置相关
李沐机器学习环境配置相关 condapython环境安装指令安装miniconda安装cpu版本torch安装jupyter测试GPU是否可以使用 conda 退出 conda 环境 conda deactivate进入都d2l环境 conda activate d2l启动jupyter notebook: jupyter notebookpython 列出所有安装的包 pip lsit环…...
笔试选择题:文件描述符+ionde和动静态库)
零基础Linux_16(基础IO_文件)笔试选择题:文件描述符+ionde和动静态库
目录 一. 文件描述符等 1. Linux下两个进程可以同时打开同一个文件,这时如下描述错误的是: 2. 以下关于标准输入输出错误的描述正确的是 3. 以下描述正确的是 4. 以下描述正确的是 [多选] 5. 在bash中,在一条命令后加入”1>&2”…...

基于OpenCV的灰度图的图片相似度计算
from skimage.metrics import structural_similarity as ssim import matplotlib.pyplot as plt import cv2 def picture_recognization(imagname):# 读取两张图片image1 cv2.imread(D:/AutoTest/PythonProject/standard_img/ imagname)image2 cv2.imread(D:/AutoTest/Pytho…...
【python海洋专题二十】subplots_adjust布局调整
上期读取soda,并subplot 但是存在一些不完美,本期修饰 本期内容 subplots_adjust布局调整 1:未调整布局的 2:调整布局 往期推荐 【python海洋专题一】查看数据nc文件的属性并输出属性到txt文件 【python海洋专题二】读取水深…...
)
TensorFlow入门(二十四、初始化学习参数)
参数的初始化关系到网络能否训练出好的结果或者是以多快的速度收敛,对训练结果有着重要的影响。 初始化学习参数需要注意的规则 不可以将网络中的所有参数初始化为0,也不能全部初始化为同一个值。如果参数全部初始化为0或者是同一个值,会使得所有神经元的输出都是相同的,进而造…...

工厂WMS系统货架位管理:优化仓储效率
货架位管理作为WMS系统中的重要环节,对于提高工厂的仓储效率和精确库存管理至关重要。本文将从多个角度全方位介绍工厂的WMS系统货架位管理,探讨其重要性以及如何优化、应用该系统,提升工厂的仓储效率和运营水平。 1. 优化仓库空间利用&…...
[C++随想录] 继承
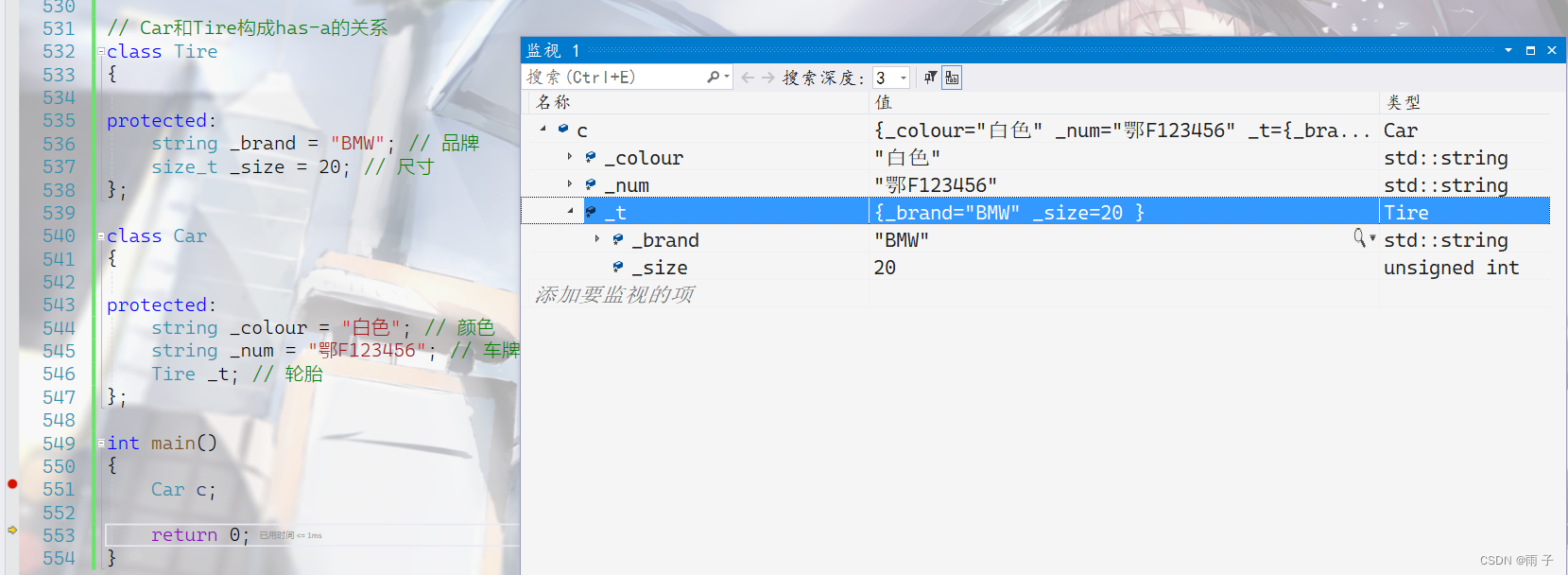
继承 继承的引言基类和子类的赋值转换继承中的作用域派生类中的默认成员函数继承与友元继承与静态成员多继承的结构棱形继承的结构棱形虚拟继承的结构继承与组合 继承的引言 概念 继承(inheritance)机制是面向对象程序设计使代码可以 复用的最重要的手段,它允许程序…...

如何在Mac上轻松导出微信聊天记录:WeChatExporter完整指南
如何在Mac上轻松导出微信聊天记录:WeChatExporter完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而焦虑?…...

如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南
如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在寻找百度网盘资源时,被一个小小的提取码卡住,不得不花费…...

GitClaw:基于Go的轻量级Git钩子服务器与集中式权限管理方案
1. 项目概述与核心价值如果你是一名开发者,尤其是经常在团队协作中处理Git仓库的工程师,那么你一定对“权限管理”这四个字又爱又恨。爱的是它能保障代码安全,恨的是它配置起来繁琐,尤其是在处理跨项目、跨团队的复杂权限矩阵时。…...

AI原生产品管理:多智能体协作如何重塑产品开发工作流
1. 项目概述:当AI成为你的产品经理最近在GitHub上看到一个挺有意思的项目,叫NathanJCW/ai-native-pm-cortex。光看名字,你大概能猜到它想做什么——“AI原生的产品经理大脑”。这可不是一个简单的聊天机器人插件,它试图构建一个完…...

基于IMAP的邮件自动化处理工具mymailclaw配置与实战指南
1. 项目概述:一个轻量级的邮件抓取与处理工具最近在折腾一个需要自动化处理邮件通知的小项目,发现市面上的方案要么太重,要么不够灵活。直到我遇到了psandis/mymailclaw这个项目,它就像一把小巧而锋利的瑞士军刀,专门用…...

量子控制中的动态校正门与SCQC几何方法
1. 量子控制中的噪声挑战与动态校正门在超导量子处理器上实现高保真度的量子门操作,最大的障碍来自环境噪声。这些噪声主要分为两类:失谐噪声(δz)和幅度噪声(ϵ)。失谐噪声源于量子比特频率的漂移…...

MCP服务器部署模板:容器化与CI/CD自动化实践指南
1. 项目概述:一个为MCP服务器量身定制的部署蓝图如果你正在开发或维护一个基于模型上下文协议(Model Context Protocol, MCP)的服务器,并且对如何将其优雅、可靠地部署到生产环境感到头疼,那么你很可能已经…...

量子计算优化Benders分解:减少量子比特与提升收敛效率
1. 量子辅助Benders分解框架概述混合整数线性规划(MILP)在供应链管理、金融优化和资源调度等领域有着广泛应用。传统Benders分解算法通过将原问题拆分为处理整数变量的主问题(MP)和处理连续变量的子问题(SP)进行迭代求解。然而,随着问题规模扩大,主问题的…...

大模型涌现能力:从原理到工程实践的激发与评测方法
1. 项目概述:从“玄学”到“可操作”的涌现能力拆解最近和几个做模型训练和评测的朋友聊天,话题总绕不开“涌现能力”。这个词现在火得不行,但聊深了发现,大家对这个概念的理解其实挺割裂的。有人说它是大模型“开窍”的瞬间&…...

Hash-Buster未来展望:AI驱动的智能哈希破解技术
Hash-Buster未来展望:AI驱动的智能哈希破解技术 【免费下载链接】Hash-Buster Crack hashes in seconds. 项目地址: https://gitcode.com/gh_mirrors/ha/Hash-Buster Hash-Buster作为一款高效的哈希破解工具,目前已支持MD5、SHA1、SHA256等多种哈…...