Docker【部署 05】docker使用tensorflow-gpu安装及调用GPU踩坑记录
tensorflow-gpu安装及调用GPU踩坑记录
- 1.安装tensorflow-gpu
- 2.Docker使用GPU
- 2.1 Could not find cuda drivers
- 2.2 was unable to find libcuda.so DSO
- 2.3 Could not find TensorRT&&Cannot dlopen some GPU libraries
- 2.4 Could not create cudnn handle: CUDNN_STATUS_NOT_INITIALIZED
- 2.5 CuDNN library needs to have matching major version and equal or higher minor version
1.安装tensorflow-gpu
Building wheels for collected packages: tensorflow-gpuBuilding wheel for tensorflow-gpu (setup.py): startedBuilding wheel for tensorflow-gpu (setup.py): finished with status 'error'Running setup.py clean for tensorflow-gpuerror: subprocess-exited-with-error× python setup.py bdist_wheel did not run successfully.│ exit code: 1╰─> [18 lines of output]Traceback (most recent call last):File "<string>", line 2, in <module>File "<pip-setuptools-caller>", line 34, in <module>File "/tmp/pip-install-i6frcfa8/tensorflow-gpu_2cea358528754cc596c541f9c2ce45ca/setup.py", line 37, in <module>raise Exception(TF_REMOVAL_WARNING)Exception:=========================================================The "tensorflow-gpu" package has been removed!Please install "tensorflow" instead.Other than the name, the two packages have been identicalsince TensorFlow 2.1, or roughly since Sep 2019. For moreinformation, see: pypi.org/project/tensorflow-gpu=========================================================[end of output]note: This error originates from a subprocess, and is likely not a problem with pip.ERROR: Failed building wheel for tensorflow-gpu
Failed to build tensorflow-gpu
Other than the name, the two packages have been identical since TensorFlow 2.1 也就是说安装2.1版本的已经自带GPU支持。
2.Docker使用GPU
不同型号的GPU及驱动版本有所区别,环境驱动及CUDA版本如下:
[root@localhost ~]# nvidia-smi
# 查询结果
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.27.04 Driver Version: 460.27.04 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
2.1 Could not find cuda drivers
# 报错
I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
在Docker容器中的程序无法识别CUDA环境变量,可以尝试以下步骤来解决这个问题:
- 检查CUDA版本:首先,需要确认宿主机上已经正确安装了CUDA。在宿主机上运行
nvcc --version命令来检查CUDA版本。 - 使用NVIDIA Docker镜像:NVIDIA提供了一些预先配置好的Docker镜像,这些镜像已经包含了CUDA和其他必要的库。可以使用这些镜像作为Dockerfile的基础镜像。
- 设置环境变量:在Dockerfile中,可以使用
ENV指令来设置环境变量。例如,如果CUDA安装在/usr/local/cuda目录下,可以添加以下行到Dockerfile中:ENV PATH /usr/local/cuda/bin:$PATH。 - 使用nvidia-docker:nvidia-docker是一个用于运行GPU加速的Docker容器的工具。
检测CUDA版本是必要的,由于使用的是导出的镜像文件,2和3的方法无法使用,最终使用-e进行环境变量设置:
# 添加cuda的环境变量
-e PATH=/usr/local/cuda-11.2/bin:$PATH -e LD_LIBRARY_PATH=/usr/local/cuda-11.2/lib64:$LD_LIBRARY_PATH# 启动命令
nvidia-docker run --name deepface --privileged=true --restart=always --net="host" -e PATH=/usr/local/cuda-11.2/bin:$PATH -e LD_LIBRARY_PATH=/usr/local/cuda-11.2/lib64:$LD_LIBRARY_PATH -v /root/.deepface/weights/:/root/.deepface/weights/ -v /usr/local/cuda-11.2/:/usr/local/cuda-11.2/ -d deepface_image
2.2 was unable to find libcuda.so DSO
I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:168] retrieving CUDA diagnostic information for host: localhost.localdomain
I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:175] hostname: localhost.localdomain
I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:199] libcuda reported version is: NOT_FOUND: was unable to find libcuda.so DSO loaded into this program
I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:203] kernel reported version is: 460.27.4
在Linux环境下,Docker可以支持将宿主机上的目录挂载到容器里。这意味着,如果宿主机上的目录包含软链接,那么这些软链接也会被挂载到容器中。然而,需要注意的是,这些软链接指向的路径必须在Docker容器中是可访问的。也就是说,如果软链接指向的路径没有被挂载到Docker容器中,那么在容器中访问这个软链接可能会失败。
原文链接:https://blog.csdn.net/u013546508/article/details/88637434,当前环境下问题解决步骤:
# 1.查找 libcuda.so 文件位置
find / -name libcuda.so*
# 查找结果
/usr/lib/libcuda.so
/usr/lib/libcuda.so.1
/usr/lib/libcuda.so.460.27.04
/usr/lib64/libcuda.so
/usr/lib64/libcuda.so.1
/usr/lib64/libcuda.so.460.27.04# 2.查看LD_LIBRARY_PATH
echo $LD_LIBRARY_PATH
# 查询结果
/usr/local/cuda/lib64# 3.将64位的libcuda.so.460.27.04复制到LD_LIBRARY_PATH路径下【libcuda.so和libcuda.so.1都是软连接】
cp /usr/lib64/libcuda.so.460.27.04 /usr/local/cuda-11.2/lib64/# 4.创建软连接
ln -s libcuda.so.460.27.04 libcuda.so.1
ln -s libcuda.so.1 libcuda.so
2.3 Could not find TensorRT&&Cannot dlopen some GPU libraries
I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
W tensorflow/core/common_runtime/gpu/gpu_device.cc:1960] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
这个问题实际上是Docker镜像文件未安装TensorRT导致的,可以在Dockerfile里添加安装命令后重新构建镜像:
RUN pip install tensorrt -i https://pypi.tuna.tsinghua.edu.cn/simple
以下操作不推荐,进入容器进行安装:
# 1.查询容器ID
docker ps# 2.在running状态进入容器
docker exec -it ContainerID /bin/bash# 3.安装软件
pip install tensorrt -i https://pypi.tuna.tsinghua.edu.cn/simple# 4.提交新的镜像【可以将新的镜像导出使用】
docker commit ContainerID imageName:version
安装后的现象:
root@localhost:/app# python
Python 3.8.18 (default, Sep 20 2023, 11:41:31)
[GCC 12.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.# 使用tensorflow报错
>>> import tensorflow as tf
2023-10-09 10:15:55.482545: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-10-09 10:15:56.498608: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT# 先导入tensorrt后使用tensorflow看我用
>>> import tensorrt as tr
>>> import tensorflow as tf
>>> tf.test.is_gpu_available()
WARNING:tensorflow:From <stdin>:1: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
2023-10-09 10:16:41.452672: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Created device /device:GPU:0 with 11389 MB memory: -> device: 0, name: Tesla T4, pci bus id: 0000:2f:00.0, compute capability: 7.5
True
尝试解决,在容器启动要执行的py文件内加入以下代码,我将以下代码加入到app.py文件内:
import tensorrt as tr
import tensorflow as tfif __name__ == "__main__":available = tf.config.list_physical_devices('GPU')print(f"available:{available}")
加入代码后的文件为:
# 3rd parth dependencies
import tensorrt as tr
import tensorflow as tf
from flask import Flask
from routes import blueprintdef create_app():available = tf.config.list_physical_devices('GPU')print(f"available:{available}")app = Flask(__name__)app.register_blueprint(blueprint)return app启动容器:
nvidia-docker run --name deepface --privileged=true --restart=always --net="host" -e PATH=/usr/local/cuda-11.2/bin:$PATH -e LD_LIBRARY_PATH=/usr/local/cuda-11.2/lib64:$LD_LIBRARY_PATH -v /root/.deepface/weights/:/root/.deepface/weights/ -v /usr/local/cuda-11.2/:/usr/local/cuda-11.2/ -v /opt/xinan-facesearch-service-public/deepface/api/app.py:/app/app.py -d deepface_image
2.4 Could not create cudnn handle: CUDNN_STATUS_NOT_INITIALIZED
E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:437] Could not create cudnn handle: CUDNN_STATUS_NOT_INITIALIZED
E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:441] Memory usage: 1100742656 bytes free, 15843721216 bytes total.
E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:451] Possibly insufficient driver version: 460.27.4
W tensorflow/core/framework/op_kernel.cc:1828] OP_REQUIRES failed at conv_ops_impl.h:770 : UNIMPLEMENTED: DNN library is not found.
未安装cuDNN导致的问题,安装即可。
2.5 CuDNN library needs to have matching major version and equal or higher minor version
安装版本跟编译项目的版本不匹配,调整版本后成功使用GPU。
E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:425] Loaded runtime CuDNN library: 8.1.1 but source was compiled with: 8.6.0. CuDNN library needs to have matching major version and equal or higher minor version. If using a binary install, upgrade your CuDNN library. If building from sources, make sure the library loaded at runtime is compatible with the version specified during compile configuration.
相关文章:

Docker【部署 05】docker使用tensorflow-gpu安装及调用GPU踩坑记录
tensorflow-gpu安装及调用GPU踩坑记录 1.安装tensorflow-gpu2.Docker使用GPU2.1 Could not find cuda drivers2.2 was unable to find libcuda.so DSO2.3 Could not find TensorRT&&Cannot dlopen some GPU libraries2.4 Could not create cudnn handle: CUDNN_STATUS_…...

前后端分离中,前端请求和后端接收请求格式总结
get请求可以携带的参数 1)前端:传统键值对(http:xx?a1&b1) <--> 后端:RequestParam("a") int a , RequestParam("b") int b 2)前端:(http:xx/a/b) <--> 后端:Reque…...

pytorch的基本运算,是不是共享了内存,有没有维度变化
可以把PyTorch简单看成是Python的深度学习第三方库,在PyTorch中定义了适用于深度学习的基本数据结构——张量,以及张量的各类计算。其实也就相当于NumPy中定义的Array和对应的科学计算方法,正是这些基本数据类型和对应的方法函数,…...
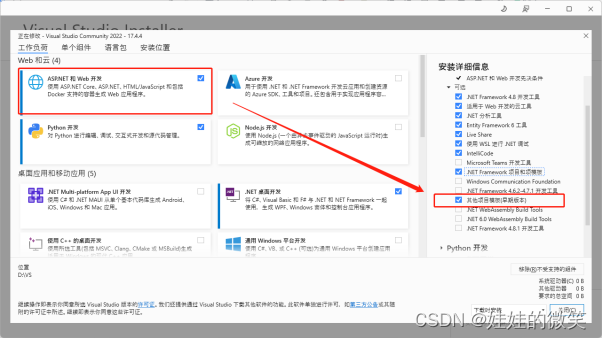
Visual Studio 2022新建项目时没有ASP.NET项目
一、Visual Studio 2022新建项目时没有ASP.NET项目 1、打开VS开发工具,选择工具菜单,点击“获取工具和功能” 2、选择“ASP.NET和Web开发”和把其他项目模板(早期版本)勾选上安装即可...

nuiapp项目实战:导航栏动态切换效果实践案例树
测试软件的百忙之中去进行软件开发的工作,开展开发软件的工作事情,也真是繁忙至极点的了。 不到一刻钟的课程内容,个人用了三次去写串联的知识点,然后这是第三次,还是第四次了才完全写出来一个功能的效果。 一刻钟的功…...

【机器学习】集成学习(以随机森林为例)
文章目录 集成学习随机森林随机森林回归填补缺失值实例:随机森林在乳腺癌数据上的调参附录参数 集成学习 集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据…...
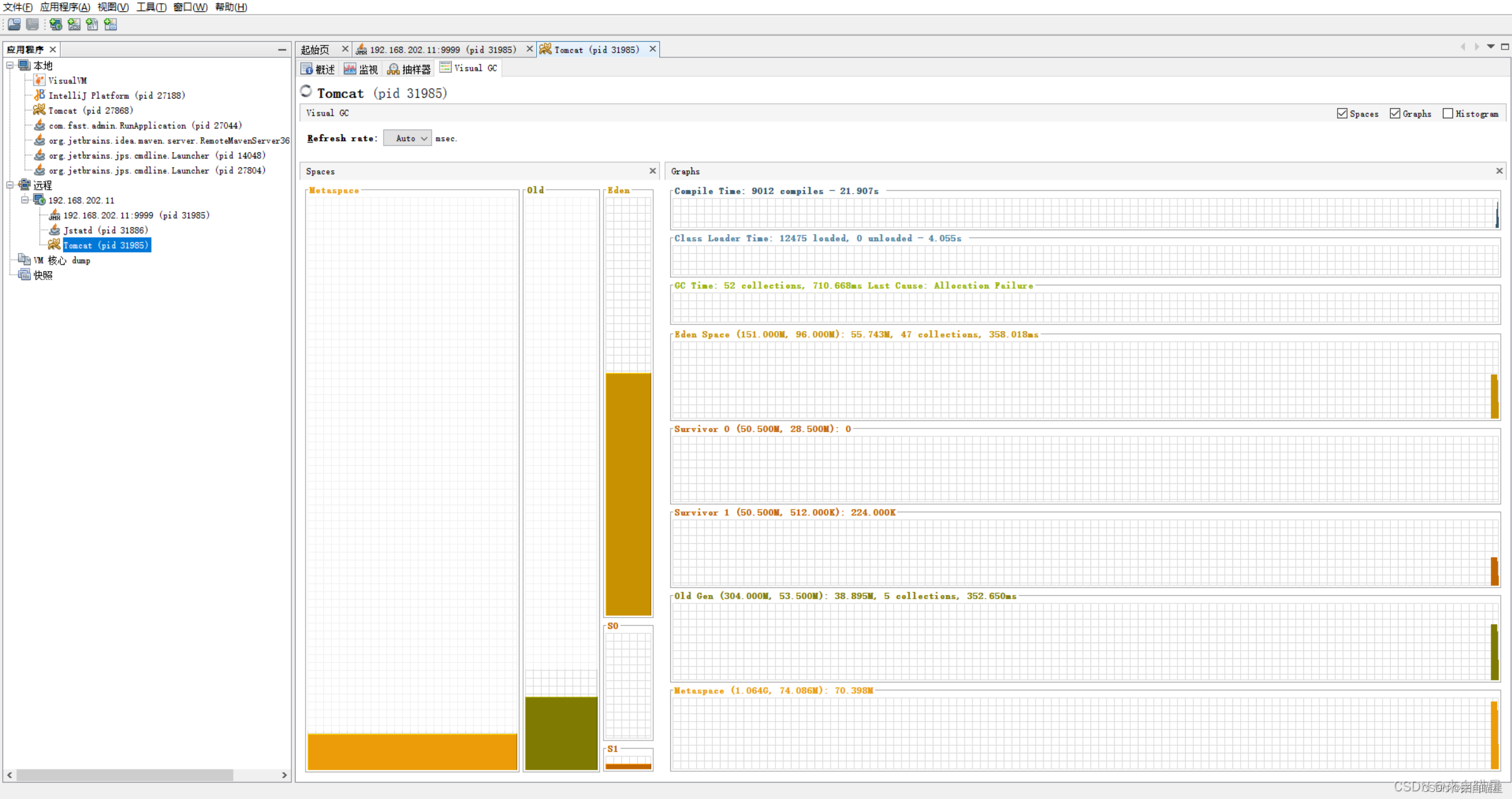
主机jvisualvm连接到tomcat服务器查看jvm状态
使用JMX方式连接到tomcat,连接后能够查看前边的部分内容,但是不能查看Visual GC,显示不受此JVM支持, 对了,要显示Visual GC,首先要安装visualvm工具,具体安装方式就是根据自己的jdk版本下载…...

uniapp 自定义tabbar页面不刷新
最近在做自定义tabbar时,每次切换页面都要刷新,页面渲染很慢,需要实现切换页面不刷新问题。 结局思路,原生的tabbar切换页面时就不选新,用switchTab来跳转 1.pages.json中配置tabbar,如下,设置高度为0&am…...

3.1 SQL概述
思维导图: 前言: 前言笔记:第3章 关系数据库标准语言SQL - **SQL的定义**: - 关系数据库的标准和通用语言。 - 功能强大,不仅限于查询。 - 功能覆盖:数据库模式创建、数据插入/修改、数据库安全性与…...
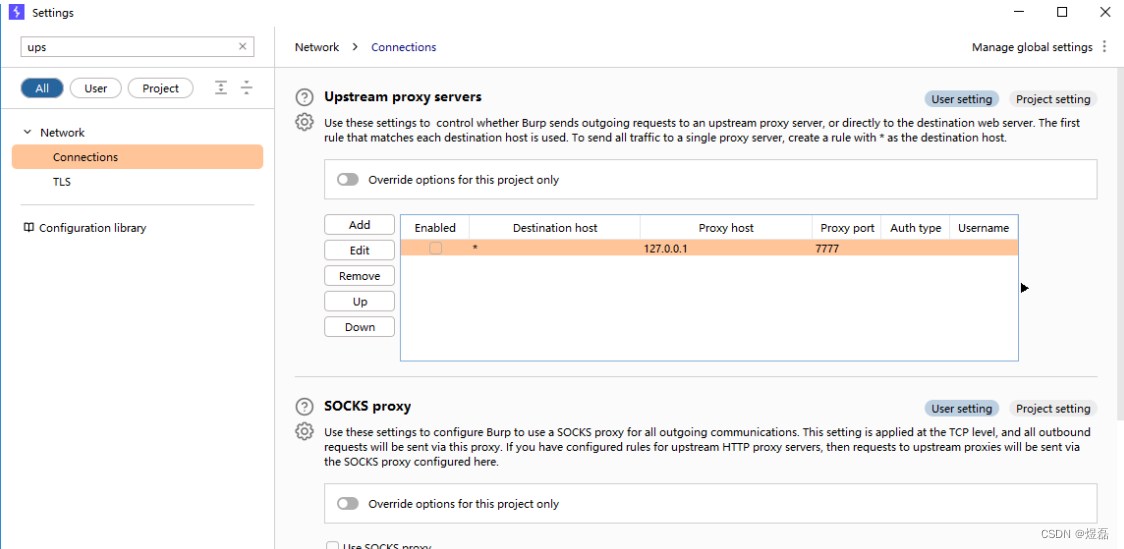
xray安装与bp组合使用-被动扫描
xray安装与bp组合使用-被动扫描 文章目录 xray安装与bp组合使用-被动扫描1 工具官方文档:2 xray官网3 工具使用4 使用指令说明5 此为设置被动扫描6 被动扫描-启动成功7 启动bp7.1 设置bp的上层代理7.2 添加上层代理7777 --》指向的是xray7.3 上层代理设置好后&#…...

Java 中Maven 和 ANT
Java 中Maven 和 ANT Maven 和 Ant 都是用于构建和管理Java项目的工具,但它们在设计和功能上有一些重要的区别。以下是关于 Maven 和 Ant 的区别、优缺点以及它们的作用,以及示例说明: Maven: 设计理念: Maven 是基于…...

Flutter通过Pigeon插件与Android同步异步交互
Flutter 调用原生(Android)方法以及数据传输_flutter调用原生sdk_TDSSS的博客-CSDN博客 https://www.cnblogs.com/baiqiantao/p/16340272.html 可以同时参考这两篇文章...

GTW验厂是什么?GTW验厂评级分类
【GTW验厂是什么?GTW验厂评级分类】 GTW验厂是什么? 全称叫GreenToWear。是为了集合所有环境和产品健康方面的要求,Inditex集团开发的可持续发展准则(简称GTW)此准则适用于Inditex集 及其供应链中所包含的湿加工厂&…...

CVE-2017-12615 Tomcat远程命令执行漏洞
漏洞简介 2017年9月19日,Apache Tomcat官方确认并修复了两个高危漏洞,漏洞CVE编号:CVE-2017-12615和CVE-2017-12616,其中 远程代码执行漏洞(CVE-2017-12615) 当 Tomcat 运行在 Windows 主机上,…...

灿芯股份将上会:计划募资6亿元,董事长、总经理均为外籍
10月11日,上海证券交易所披露的信息显示,灿芯半导体(上海)股份有限公司(下称“灿芯股份”)将于10月18日接受上市审核委员会审议会议的现场审议。目前,该公司已递交了招股书(上会稿&a…...

Spring Cloud Gateway 搭建网关
新建一个module添加依赖: <!--Spring Cloud Gateway依赖--> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId> </dependency><!-- nacos客户端依赖…...
ETL数据转换方式有哪些
ETL数据转换方式有哪些 ETL(Extract, Transform, Load)是一种常用的数据处理方式,用于从源系统中提取数据,进行转换,并加载到目标系统中。 数据清洗(Data Cleaning)&am…...

CVE-2017-15715 apache换行解析文件上传漏洞
影响范围 httpd 2.4.0~2.4.29 复现环境 vulhub/httpd/CVE-2017-15715 docker-compose 漏洞原理 在apache2的配置文件: /etc/apache2/conf-available/docker-php.conf 中,php的文件匹配以正则形式表达 ".php$"的正则匹配模式意味着以.ph…...

振弦采集仪应用水坝安全监测的方案
振弦采集仪应用水坝安全监测的方案 随着工业化和城市化的快速发展,水资源的开发和利用越来越广泛。由于水坝在水利工程中起着至关重要的作用,因此对水坝进行安全监测变得越来越必要。为了实现对水坝的安全监测,振弦采集仪可以作为一种有效的…...

【Java】查找jdk步骤
需求描述 解决方法 第一步 第二步 第三步 第四步 参考文章...

如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南
如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否厌倦了每次启动Minecraft都要手动配…...

Linuxbonding链路稳定性治理方法
Linuxbonding链路稳定性治理方法这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限…...

3分钟掌握Seraphine:英雄联盟智能助手完全指南
3分钟掌握Seraphine:英雄联盟智能助手完全指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于英雄联盟官方LCU API开发的智能游戏助手,通过自动BP系统和实时战绩查…...

猫抓插件:5分钟掌握浏览器资源嗅探的终极武器
猫抓插件:5分钟掌握浏览器资源嗅探的终极武器 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容无处不在的今天,你…...

服务网格Istio实战
服务网格Istio实战 引言 服务网格(Service Mesh)作为微服务架构的基础设施层,提供了对服务间通信的精细控制能力。Istio是目前最流行的开源服务网格解决方案,它通过Sidecar代理拦截所有网络通信,提供流量管理、安全、可…...

MCP服务器自动发现与管理工具mcpfinder详解
1. 项目概述:一个用于发现与管理MCP服务器的工具如果你正在构建或使用基于模型上下文协议(Model Context Protocol, 简称MCP)的应用,那么你很可能遇到过这样的困扰:手头有几个不同功能的MCP服务器ÿ…...

Qwen2.5-14B实战指南:3个关键步骤突破本地大模型部署瓶颈
Qwen2.5-14B实战指南:3个关键步骤突破本地大模型部署瓶颈 【免费下载链接】Qwen2.5-14B 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/Qwen2.5-14B 当开发者面对复杂的代码生成任务或技术文档分析需求时,往往会受限于云端API的延迟和…...

MedAgentBench:大模型临床决策能力评估基准详解与应用
1. 项目概述:当大模型成为医疗决策的“实习生” 最近在医疗AI的圈子里,一个名为“MedAgentBench”的开源项目引起了不小的讨论。这个由斯坦福机器学习组(Stanford ML Group)发布的项目,其核心目标非常明确:…...

PAC技术演进与核心趋势:从多域控制到边缘智能的工业自动化平台
1. 项目概述:为什么今天还要聊PAC?如果你在工业自动化、楼宇控制或者任何涉及逻辑控制的领域工作,那么“PAC”这个词对你来说应该不陌生。但很多时候,它就像一个熟悉的陌生人——大家好像都知道它,但真要细说它现在发展…...

AI模型GUI开发实战:从架构设计到部署的完整指南
1. 项目概述:一个为AI模型打造的图形化交互界面最近在GitHub上看到一个挺有意思的项目,叫GrahamMiranda-AI/openclaw-model-gui。光看名字,就能猜个八九不离十:这大概率是一个为某个名为“OpenClaw”的AI模型配套开发的图形用户界…...