GEO生信数据挖掘(六)实践案例——四分类结核病基因数据预处理分析
前面五节,我们使用阿尔兹海默症数据做了一个数据预处理案例,包括如下内容:
GEO生信数据挖掘(一)数据集下载和初步观察
GEO生信数据挖掘(二)下载基因芯片平台文件及注释
GEO生信数据挖掘(三)芯片探针ID与基因名映射处理
GEO生信数据挖掘(四)数据清洗(离群值处理、低表达基因、归一化、log2处理)
GEO生信数据挖掘(五)提取临床信息构建分组,分组数据可视化(绘制层次聚类图,绘制PCA图)
本节目录
结核病基因表达数据(GSE107994)观察
临床形状数据预处理
基因表达数据预处理
绘图观察数据
结核病基因表达数据(GSE107994)观察
由于,在数据分析过程,你拿的数据样式可能会有不同,本节我们以结核病基因表达数据(GSE107994)为例,做一个实践案例。该数据集的临床形状数据和基因表达数据是单独分开的,读取,和处理都需自己改动代码。

先来看看基因表达数据,这个探针注释工作已经完成了,不需要处理。

再看看临床形状数据,需要手工删除前面的注释,把后半部分规整的数据保留下来。

临床形状数据预处理
# 手工删除前面的注释,读文件,转置
pdata <- t(read.delim("GSE107994_series_matrix_clean.txt", header = TRUE, sep = "\t"))
# 手工删除前面的注释,读文件,转置
pdata <- t(read.delim("GSE107994_series_matrix_clean.txt", header = TRUE, sep = "\t"))
pdata <-pdata[-1,]
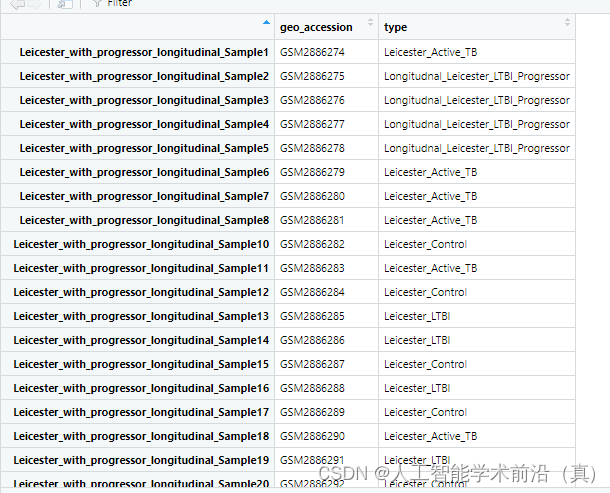
pdata_info = pdata[,c(1,7)]
colnames(pdata_info) = c('geo_accession','type')#观察样本类型的取值都有哪些(结核,潜隐进展,对照和潜隐)
unique(pdata_info[,2])
#"Leicester_Active_TB" "Longitudnal_Leicester_LTBI_Progressor" "Leicester_Control" #"Leicester_LTBI" group_data = as.data.frame(pdata_info)处理前
处理后
增加不同的类型标签,根据需要,选取实验组和对照组
# 使用grepl函数判断字符串是否包含'Control',并进行相应的修改
group_data$group_easy <- ifelse(grepl("Control", group_data$type ), "Control", "TB")# 使用grepl函数判断字符串是否包含特定内容,然后进行相应的修改
group_data$group_easy <- ifelse(grepl("Control", group_data$type), "Control",ifelse(grepl("LTBI", group_data$type), "LTBI","TB"))
# 使用grepl函数判断字符串是否包含特定内容,然后进行相应的修改
group_data$group_more <- ifelse(grepl("Control", group_data$type), "Control",ifelse(grepl("LTBI_Progressor", group_data$type), "LTBI_Progressor",ifelse(grepl("LTBI", group_data$type), "LTBI","TB")))#尝试把进展组排除出去save(group_data,file = "group_data.Rdata")
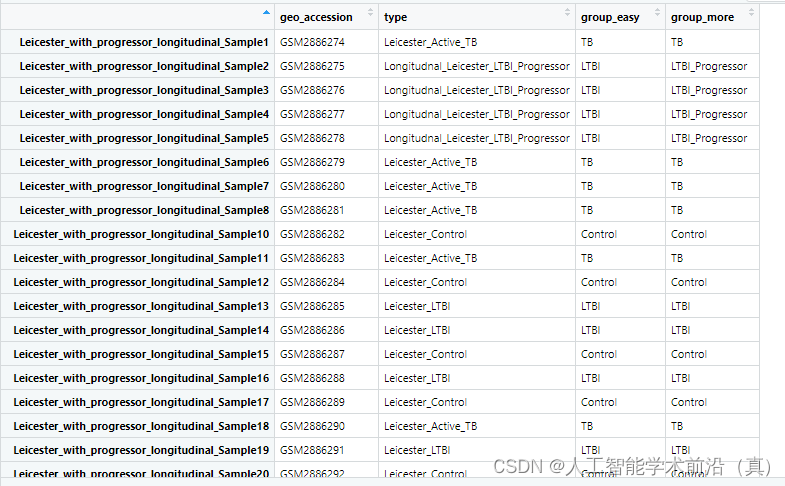
例如 我们可以进行 TB(结核) 和LTBI(潜隐结核)实验对照分析。
基因表达数据预处理
读取数据集
install.packages("openxlsx")
library(openxlsx)# 读基因表达矩阵,第一列为基因名ID
gse_info<- as.data.frame(read.xlsx("GSE107994_Raw.xlsx", sheet = 1))
colnames(gse_info)
后续运行代码过程中,发现基因名称中有全数字的情况,这里做删除操作。
library(dplyr)
dim(gse_info)
#基因里面有数字
gse_info <- gse_info[!grepl("^\\d+$", gse_info$ID), ] #有效#基因名全为空
gse_info = gse_info[gse_info$ID != "",] #无剔除
dim(gse_info) #[1] 58023 176#负值处理
gse_info[gse_info <= 0] <- 0.0001#重复值检查
table(duplicated(gse_info$ID))分组数据条件筛选,TB(结核) 和LTBI(潜隐结核)
#+=====================================================
#================================================
#+========type分组数据条件筛选step3===========
#+====================================#预处理之前,先筛选出TB组和LTBI组 的数据
unique(group_data[,"group_more"]) #"TB" "LTBI_Progressor" "Control" "LTBI" #"TB" "LTBI" 对照,则剔除 "LTBI_Progressor" "Control"
geo_accession_TB_LTBI <- group_data[group_data$group_more == "LTBI_Progressor" | group_data$group_more == "Control","geo_accession"]
gse_TB_FTBI = gse_info[,!(names(gse_info) %in% geo_accession_TB_LTBI)]gse_TB_FTBI
低表达过滤(平均值小于1)
#+=====================================================
#================================================
#+========删除 低表达(平均值小于1)基因 step4===========
#+====================================
#+==============================#新增一列计算平均
gene_avg_expression <- rowMeans(gse_TB_FTBI[, -1]) # 计算每个基因的平均表达量,排除第一列(基因名)
#仅去除在所有样本里表达量都为零的基因(平均值小于1)
gse_TB_FTBI_filtered_genes_1 <- gse_TB_FTBI[gene_avg_expression >= 1, ]低表达过滤方案二(保留样本表达的排名前50%的基因)
#+=================================================================
#============================================================
#+========删除 低表达(排名前50%)基因 step5===========
#+==========================================
#+================================#仅保留在一半以上样本里表达的基因# 计算基因表达矩阵每个基因的平均值
gene_means <- rowMeans(gse_TB_FTBI_filtered_genes_1[,-1])# 计算基因平均值的排序百分位数
gene_percentiles <- rank(gene_means) / length(gene_means)# 获取阈值
threshold <- 0.25 # 删除后25%的阈值
#threshold <- 0.5 # 删除后50%的阈值
# 根据阈值筛选低表达基因
gse_TB_FTBI_filtered_genes_2 <- gse_TB_FTBI_filtered_genes_1[gene_percentiles > threshold, ]# 打印筛选后的基因表达矩阵
dim(gse_TB_FTBI_filtered_genes_2) #[1] 17049 176
删除重复基因,取平均
#+=================================================================
#============================================================
#+========重复基因,取平均值 step6===========
#+==========================================
#+================================dim(filtered_genes_2)
table(duplicated(filtered_genes_2$ID))#把重复的Symbol取平均值
averaged_data <- aggregate(.~ID , filtered_genes_2, mean, na.action = na.pass) ##把重复的Symbol取平均值#把行名命名为SYMBOL
row.names(averaged_data) <- averaged_data$ID
dim(averaged_data)#去掉缺失值
matrix_na = na.omit(averaged_data) #删除Symbol列(一般是第一列)
matrix_final <- subset(matrix_na, select = -1)
dim(matrix_final) #[1] 22687 175离群值处理
#+=================================================================
#============================================================
#+========离群值处理 step7==========================
#+==========================================
#+================================#数据离群处理
#处理极端值
#定义向量极端值处理函数
#用于处理异常值,将超出一定范围的值替换为中位数,以减少异常值对后续分析的影响。
dljdz=function(x) {DOWNB=quantile(x,0.25)-1.5*(quantile(x,0.75)-quantile(x,0.25))UPB=quantile(x,0.75)+1.5*(quantile(x,0.75)-quantile(x,0.25))x[which(x<DOWNB)]=quantile(x,0.5)x[which(x>UPB)]=quantile(x,0.5)return(x)
}#第一列设置为行名
matrix_leave=matrix_final_TB_LTBIboxplot(matrix_leave,outline=FALSE, notch=T, las=2) ##出箱线图
dim(matrix_leave)#处理离群值
matrix_leave_res=apply(matrix_leave,2,dljdz)boxplot(matrix_leave_res,outline=FALSE, notch=T, las=2) ##出箱线图
dim(matrix_leave_res)log2 处理
#+=================================================================
#============================================================
#+========log2 处理 step8==========================
#+==========================================
#+================================# limma的函数归一化,矫正差异 ,表达矩阵自动log2化#1.归一化不是绝对必要的,但是推荐进行归一化。
#有重复的样本中,应该不具备生物学意义的外部因素会影响单个样品的表达,
#例如中第一批制备的样品会总体上表达高于第二批制备的样品,假设所有样品表达值的范围和分布都应当相似,
#需要进行归一化来确保整个实验中每个样本的表达分布都相似。
#2.归一化要在log2标准化之前做library(limma) exprSet=normalizeBetweenArrays(matrix_leave_res)boxplot(exprSet,outline=FALSE, notch=T, las=2) ##出箱线图## 这步把矩阵转换为数据框很重要
class(exprSet) ##注释:此时数据的格式是矩阵(Matrix)
exprSet <- as.data.frame(exprSet)#标准化 表达矩阵自动log2化
qx <- as.numeric(quantile(exprSet, c(0., 0.25, 0.5, 0.75, 0.99, 1.0), na.rm=T))
LogC <- (qx[5] > 100) ||(qx[6]-qx[1] > 50 && qx[2] > 0) ||(qx[2] > 0 && qx[2] < 1 && qx[4] > 1 && qx[4] < 2)#负值全部置为空
#exprSet[exprSet <= 0] <- 0.0001
#去掉缺失值
#exprSet = na.omit(exprSet) #15654
#save (exprSet,file = "waitlog_data_TB_LTBI.Rdata")## 开始判断
if (LogC) { exprSet [which(exprSet <= 0)] <- NaN## 取log2exprSet_clean <- log2(exprSet+1) #@@@@是否加一 加一的话不产生负值@#@¥@#@#@%@%¥@@@@@@print("log2 transform finished")
}else{print("log2 transform not needed")
}boxplot(exprSet_clean,outline=FALSE, notch=T, las=2) ##出箱线图dataset_TB_LTBI =exprSet_clean绘图观察数据
#+=================================================================
#============================================================
#+========对照组不同颜色画箱线图 step9==========================
#+==========================================
#+================================# 使用grepl函数判断字符串是否包含'LTBI',并进行颜色标记,为了画图
group_data_TB_LTBI$group_color <- ifelse(grepl("LTBI", group_data_TB_LTBI$group_more), "yellow", "blue")#画箱线图查看数据分布
group_list_color = group_data_TB_LTBI$group_color
boxplot( data.frame(dataset_TB_LTBI),outline=FALSE,notch=T,col=group_list_color,las=2)dev.off()#+=================================================================
#============================================================
#+========绘制层次聚类图 step10==========================
#+==========================================
#+================================
#+#检查表达矩阵的样本名称,和分租信息的样本名称顺序,是否一致对应
colnames(dataset_TB_LTBI)
group_data_TB_LTBI$geo_accessionexprSet =dataset_TB_LTBI
#修改GSM的名字,改为分组信息
#colnames(exprSet)=paste(group_list,1:ncol(exprSet),sep = '')#定义nodePar
nodePar=list(lab.cex=0.6,pch=c(NA,19),cex=0.7,col='blue')
#聚类
hc=hclust(dist(t(exprSet))) #t()的意思是转置#绘图
plot(as.dendrogram(hc),nodePar = nodePar,horiz = TRUE)dev.off()#+=================================================================
#============================================================
#+========绘制PCA散点样本可视化图 step11===================
#+==========================================
#+================================##PCA图
#install.packages('ggfortify')
library(ggfortify)
df=as.data.frame(t(exprSet)) #转置后就变成了矩阵
dim(df) #查看数据维度
dim(exprSet)df$group=group_data_TB_LTBI$group_more #加入样本分组信息
autoplot(prcomp(df[,1:ncol(df)-1]),data=df,colour='group') #PCA散点图dev.off()至此,我们对两个数据集进行了预处理工作,下面我们可以对处理完毕的数据进行差异分析了。
相关文章:
GEO生信数据挖掘(六)实践案例——四分类结核病基因数据预处理分析
前面五节,我们使用阿尔兹海默症数据做了一个数据预处理案例,包括如下内容: GEO生信数据挖掘(一)数据集下载和初步观察 GEO生信数据挖掘(二)下载基因芯片平台文件及注释 GEO生信数据挖掘&…...

8.Mobilenetv2网络代码实现
代码如下: import math import os import numpy as npimport torch import torch.nn as nn import torch.utils.model_zoo as model_zoo#1.建立带有bn的卷积网络 def conv_bn(inp, oup, stride):return nn.Sequential(nn.Conv2d(inp,oup,3,stride,biasFalse),nn.Bat…...

Spring Boot Controller
刚入门小白,详细请看这篇SpringBoot各种Controller写法_springboot controller-CSDN博客 Spring Boot 提供了Controller和RestController两种注解。 Controller 返回一个string,其内容就是指向的html文件名称。 Controller public class HelloControll…...

在网络安全、爬虫和HTTP协议中的重要性和应用
1. Socks5代理:保障多协议安全传输 Socks5代理是一种功能强大的代理协议,支持多种网络协议,包括HTTP、HTTPS和FTP。相比之下,Socks5代理提供了更高的安全性和功能性,包括: 多协议支持: Socks5代…...
Web测试框架SeleniumBase
首先,SeleniumBase支持 pip安装: > pip install seleniumbase它依赖的库比较多,包括pytest、nose这些第三方单元测试框架,是为更方便的运行测试用例,因为这两个测试框架是支持unittest测试用例的执行的。 Seleniu…...

jvm打破砂锅问到底- 为什么要标记或记录跨代引用
为什么要标记或记录跨代引用. ygc时, 直接把老年代引用的新生代对象(可能是对象区域)记录下来当做根, 这其实就是依据第二假说和第三假说, 强者恒强, 跨代引用少(存在互相引用关系的两个对象,是应该倾 向于同时生存或者同时消亡的). 拿ygc老年代跨代引用对象当做根…...

小程序长期订阅
准备工作 ::: tip 管理后台配置 小程序类目:住建(硬性要求) 功能-》订阅消息-》我的模版 申请模版:1、预约进度通知 2、申请结果通知 3、业务办理进度提醒 ::: 用户订阅一次后,可长期下发多条消息。目前长期性订阅…...

Studio One6.5中文版本版下载及功能介绍
Studio One是一款专业的音乐制作软件,由美国PreSonus公司开发。该软件提供了全面的音频编辑和混音功能,包括录制、编曲、合成、采样等多种工具,可用于制作各种类型的音乐,如流行音乐、电子音乐、摇滚乐等。 Studio One的主要特点…...

07-Zookeeper分布式一致性协议ZAB源码剖析
上一篇:06-Zookeeper选举Leader源码剖析 整个Zookeeper就是一个多节点分布式一致性算法的实现,底层采用的实现协议是ZAB。 1. ZAB协议介绍 ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议)。 Zook…...

云原生安全应用场景有哪些?
当今数字化时代,数据已经成为企业最宝贵的资产之一,而云计算作为企业数字化转型的关键技术,其安全性也日益受到重视。随着云计算技术的快速发展,云原生安全应用场景也越来越广泛,下面本文将从云原生安全应用场景出发&a…...

Step 1 搭建一个简单的渲染框架
Step 1 搭建一个简单的渲染框架 万事开头难。从萌生到自己到处看源码手抄一个mini engine出来的想法,到真正敲键盘去抄,转眼过去了很久的时间。这次大概的确是抱着认真的想法,打开VS从零开始抄代码。不知道能坚持多久呢。。。 本次的主题是搭…...
Excel 插入和提取超链接
构造超链接 HYPERLINK(D1,C1)提取超链接 Sheet页→右键→查看代码Sub link()Dim hl As HyperlinkFor Each hl In ActiveSheet.Hyperlinkshl.Range.Offset(0, 1).Value hl.AddressNext End Sub工具栏→运行→运行子过程→提取所有超链接地址参考: https://blog.cs…...

基础架构开发-操作系统、编译器、云原生、嵌入式、ic
基础架构开发-操作系统、编译器、云原生、嵌入式、ic 操作系统编译器词法分析AST语法树生成语法优化生成机器码 云原生容器开发一般遇到的岗位描述RDMA、DPDK是什么东西NFV和VNF是什么RisingWave云原生存储引擎开发实践 单片机、嵌入式雷达路线规划 ic开发 操作系统 以C和Rust…...
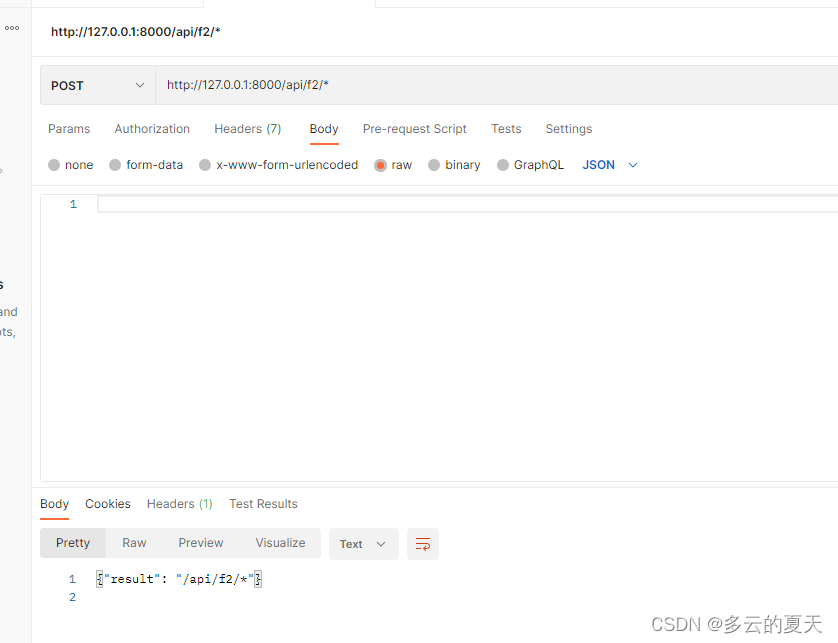
C++-Mongoose(3)-http-server-https-restful
1.url 结构 2.http和 http-restful区别在于对于mg_tls_opts的赋值 2.1 http和https 区分 a) port地址 static const char *s_http_addr "http://0.0.0.0:8000"; // HTTP port static const char *s_https_addr "https://0.0.0.0:8443"; // HTTP…...
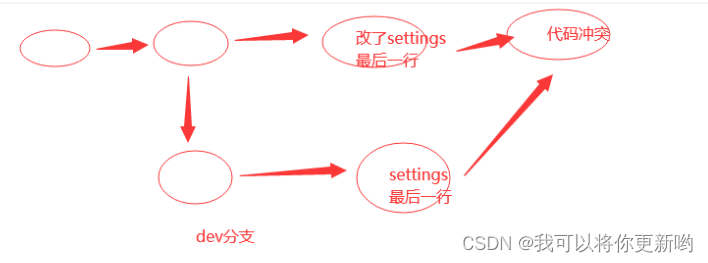
git多分支、git远程仓库、ssh方式连接远程仓库、协同开发(避免冲突)、解决协同冲突(多人在同一分支开发、 合并分支)
1 git多分支 2 git远程仓库 2.1 普通开发者,使用流程 3 ssh方式连接远程仓库 4 协同开发 4.1 避免冲突 4.2 协同开发 5 解决协同冲突 5.1 多人在同一分支开发 5.2 合并分支 1 git多分支 ## 命令操作分支-1 创建分支git branch dev-2 查看分支git branch-3 分支合…...

ChatGPT或将引发现代知识体系转变
作为当下大语言模型的典型代表,ChatGPT对人类学习方式和教育发展所产生的变革效应已然引起了广泛关注。技术的快速发展在某种程度上正在“倒逼”教育领域开启更深层次的变革。在此背景下,教育从业者势必要学会准确识变、科学应变、主动求变、以变应变&am…...
【爬虫实战】用pyhon爬百度故事会专栏
一.爬虫需求 获取对应所有专栏数据;自动实现分页;多线程爬取;批量多账号爬取;保存到mysql、csv(本案例以mysql为例);保存数据时已存在就更新,无数据就添加; 二.最终效果…...

焦炭反应性及反应后强度试验方法
声明 本文是学习GB-T 4000-2017 焦炭反应性及反应后强度试验方法. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 7— 进气口; 8— 测温热电偶。 图 A.1 单点测温加热炉体结构示意图 A.3 温度控制装置 控制精度:(11003)℃。…...
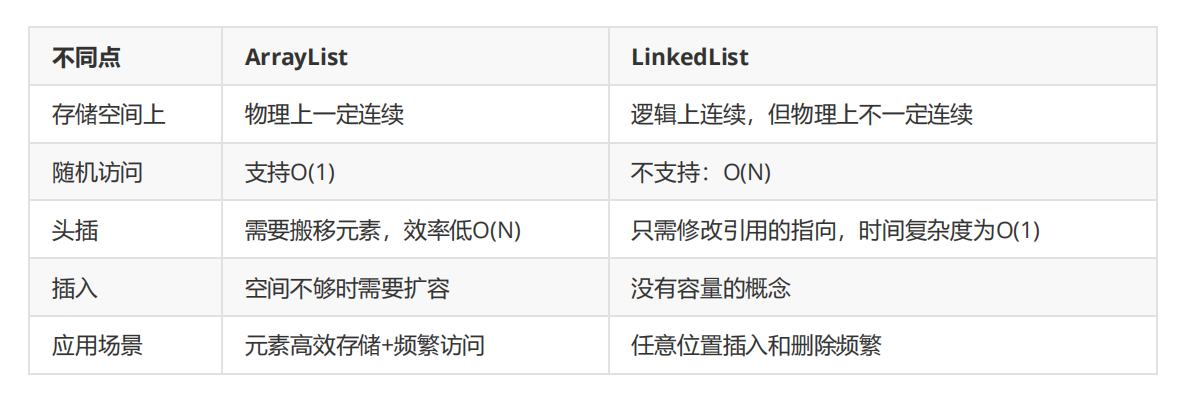
链表(3):双链表
引入 我们之前学的单向链表有什么缺点呢? 缺点:后一个节点无法看到前一个节点的内容 那我们就多设置一个格子prev用来存放前面一个节点的地址,第一个节点的prev存最后一个节点的地址(一般是null) 这样一个无头双向…...
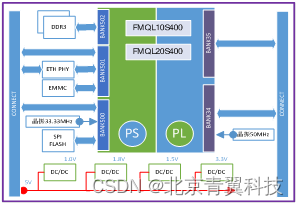
【TES720D】基于复旦微的FMQL20S400全国产化ARM核心模块
TES720D是一款基于上海复旦微电子FMQL20S400的全国产化核心模块。该核心模块将复旦微的FMQL20S400(兼容FMQL10S400)的最小系统集成在了一个50*70mm的核心板上,可以作为一个核心模块,进行功能性扩展,特别是用在控制领域…...

开发者效率工具集claw:从Unix哲学到现代开发工作流集成
1. 项目概述:一个为开发者打造的“瑞士军刀”式工具集最近在GitHub上闲逛,发现了一个名为opsyhq/claw的项目,它的名字和图标(一个爪子)一下子就抓住了我的眼球。点进去一看,简介很简单:“A coll…...

PyCharm 运行 FastAPI 接口请求阻塞?竟是后台多进程残留导致
问题描述在 PyCharm 中启动 FastAPI 项目进程后,使用 Postman 发起接口请求出现明显阻塞现象,不仅请求迟迟无法得到响应,项目控制台也完全接收不到任何请求日志,接口调用彻底失效。 问题根源分析日常开发中习惯性直接关闭运行终端…...

CodeDroidAI:本地化AI代码助手的设计原理与工程实践
1. 项目概述:一个面向开发者的AI代码助手最近在GitHub上看到一个挺有意思的项目,叫“FMXExpress/CodeDroidAI”。光看这个名字,可能有点摸不着头脑,但如果你是个经常和代码打交道的开发者,尤其是对提升编码效率、探索A…...
基于ESP32与NeoPixel的智能灯光控制系统:从硬件选型到Web控制全解析
1. 项目概述:打造你的专属智能光效中心几年前,我为了给家里的节日装饰增添点科技感,琢磨着怎么让一串普通的LED灯带变得“听话”——能从手机或电脑上随意切换颜色和动画。当时市面上成品的智能灯带要么价格不菲,要么功能受限&…...

ARM Cortex-M调试陷阱:Flash断点残留如何导致Hard Fault
1. 项目概述:一次由断点引发的“血案”与深度剖析最近在支持一个基于NXP KW36(Cortex-M0内核)的BLE项目时,我遇到了一个极其隐蔽且令人抓狂的问题。同一批次的板子,烧录完全相同的固件,绝大多数运行正常&am…...
)
手把手教你用TTL线刷救活咪咕MGV3200盒子(GK6323V100C芯片/安卓9系统)
咪咕MGV3200盒子救砖全指南:从TTL焊接到底层刷机实战 当你的咪咕MGV3200电视盒子因为一次鲁莽的卡刷操作变成"砖头",指示灯不再亮起,屏幕一片漆黑时,那种绝望感只有经历过的人才能体会。不同于普通刷机教程,…...

别只改fillText了!深入Chromium渲染引擎,打造更隐蔽的Canvas指纹混淆方案
深入Chromium渲染引擎:构建自然化的Canvas指纹混淆体系 Canvas指纹识别技术早已从实验室走向实际应用,成为现代Web追踪的重要手段。传统对抗方案往往停留在简单的随机偏移或文本修改层面,这种"粗暴"的修改方式很容易被高级指纹库通…...

独立开发者如何借助Taotoken模型广场为不同任务选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken模型广场为不同任务选型 作为一名独立开发者,日常工作中常需处理多种类型的任务࿱…...

基于Feather M0与VS1053打造可穿戴MP3播放器:从硬件到软件的完整DIY指南
1. 项目概述:打造你的专属可穿戴音乐伴侣几年前,我在一个创客市集上看到一个朋友把MP3播放器做成了复古磁带的样子,当时就觉得特别酷。那种把数字音乐和实体交互结合起来的乐趣,是手机播放器给不了的。后来接触到Adafruit的Feathe…...

AI工作流编排框架aiflows:构建模块化、可维护的多智能体系统
1. 项目概述:当AI工作流成为团队协作的“操作系统”如果你和我一样,在过去几年里尝试过将多个大语言模型(LLM)串联起来,构建一个能处理复杂任务的智能体(Agent)或工作流,那你一定经历…...