【爬虫实战】用pyhon爬百度故事会专栏
一.爬虫需求
- 获取对应所有专栏数据;
- 自动实现分页;
- 多线程爬取;
- 批量多账号爬取;
- 保存到mysql、csv(本案例以mysql为例);
- 保存数据时已存在就更新,无数据就添加;
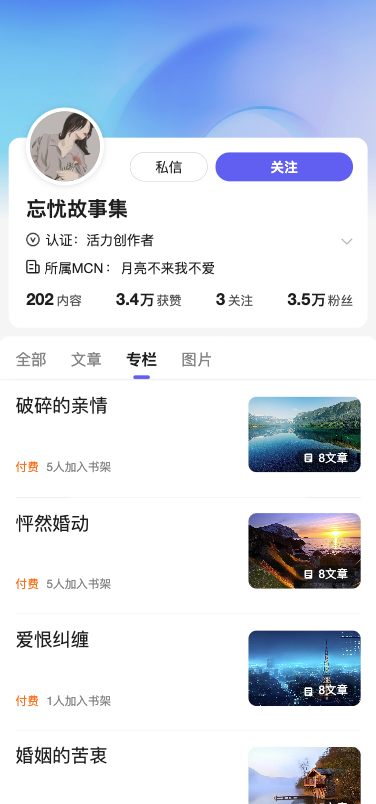
二.最终效果
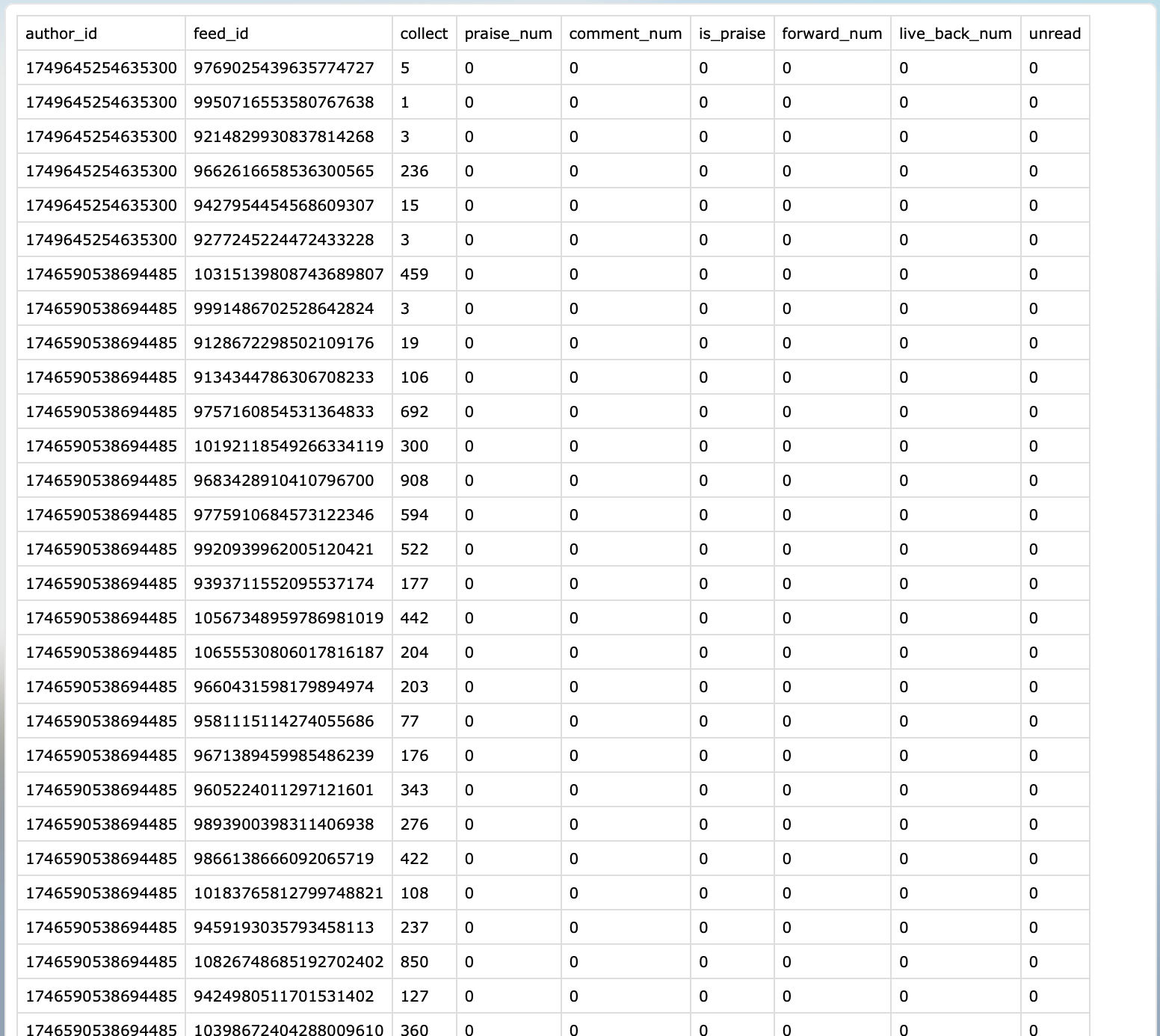
三.项目代码
3.1 新建项目
本文使用scrapy分布式、多线程爬虫框架编写的高性能爬虫,因此新建、运行scrapy项目3步骤:
1.新建项目:
scrapy startproject author
2.新建 spider:
scrapy genspider author "baidu.com"
3.运行 spider:
scrapy crawl authorSpider
注意:author 是spider中的name
4.编写item:
# Author专栏(xxx备注是预留未知对应字段)
class AuthorZhuanLanItem(scrapy.Item):# 专栏author_idauthor_id = scrapy.Field()# 专栏feed_idfeed_id = scrapy.Field()praise_num = scrapy.Field()comment_num = scrapy.Field()is_praise = scrapy.Field()forward_num = scrapy.Field()live_back_num = scrapy.Field()# 加入书架的人数collect = scrapy.Field()unread = scrapy.Field()5.编写爬虫解析代码:
# Author专栏数据
class AuthorItemPipeline(object):def open_spider(self, spider):if spider.name == 'author':# 插入数据sqlself.insert_sql = "INSERT INTO author(author_id,feed_id,praise_num,comment_num,is_praise,forward_num,live_back_num,collect,unread) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"# 更新数据sqlself.update_sql = "UPDATE author SET praise_num=%s,comment_num=%s,is_praise=%s,forward_num=%s,live_back_num=%s,collect=%s,unread=%s WHERE feed_id=%s"# 查询数据sqlself.query_sql = "SELECT * FROM author WHERE feed_id=%s"# 初始化数据库链接对象pool = PooledDB(pymysql,MYSQL['limit_count'],host=MYSQL["host"],user=MYSQL["username"],passwd=MYSQL["password"],db=MYSQL["database"],port=MYSQL["port"],charset=MYSQL["charset"],use_unicode=True)self.conn = pool.connection()self.cursor = self.conn.cursor()# 保存数据def process_item(self, item, spider):try:if spider.name == 'author':# 检查表中数据是否已经存在counts = self.cursor.execute(self.query_sql, (item['feed_id']))# counts大于0说明已经存在,使用更新sql,否则使用插入sqlif counts > 0:self.cursor.execute(self.update_sql,(...)else:self.cursor.execute(self.insert_sql,(...)...except BaseException as e:print("author错误在这里>>>>>>>>>>>>>", e, "<<<<<<<<<<<<<错误在这里")return itemimport re
import scrapy
from bs4 import BeautifulSoup as bs
from urllib.parse import urlencode
from baidu.settings import MAX_PAGE, author_headers, author_cookies
from ..items import AuthorZhuanLanItem
from baidu.Utils import Tooltool = Tool()
"""
爬虫功能:
用户-专栏-列表
"""class AuthorSpider(scrapy.Spider):name = 'author'allowed_domains = ['baidu.com']base_url = 'xxx'zhuanlan_url = "xxx"params = {...}headers = {"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"}...四.运行过程

五.项目说明文档
六.获取完整源码
爱学习的小伙伴,本次案例的完整源码,已上传微信公众号“一个努力奔跑的snail”,后台回复**“故事会”**即可获取。
相关文章:
【爬虫实战】用pyhon爬百度故事会专栏
一.爬虫需求 获取对应所有专栏数据;自动实现分页;多线程爬取;批量多账号爬取;保存到mysql、csv(本案例以mysql为例);保存数据时已存在就更新,无数据就添加; 二.最终效果…...

焦炭反应性及反应后强度试验方法
声明 本文是学习GB-T 4000-2017 焦炭反应性及反应后强度试验方法. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 7— 进气口; 8— 测温热电偶。 图 A.1 单点测温加热炉体结构示意图 A.3 温度控制装置 控制精度:(11003)℃。…...
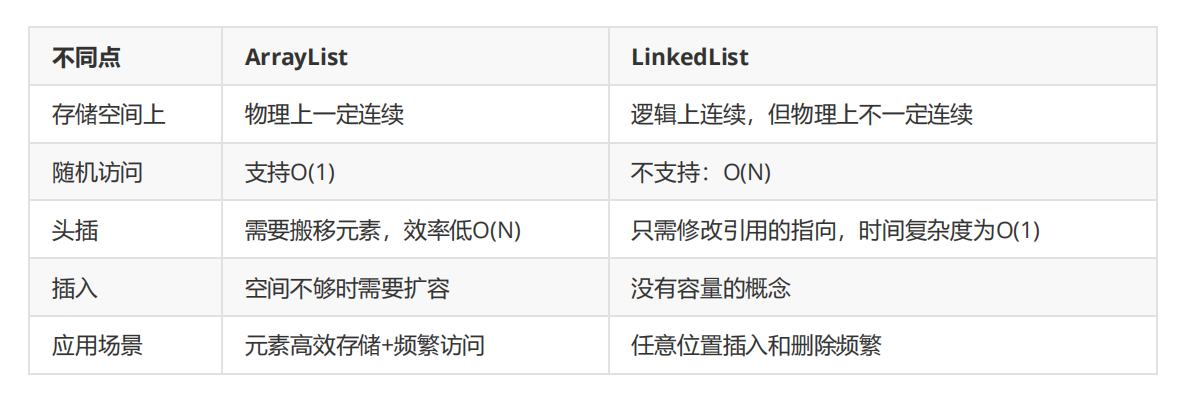
链表(3):双链表
引入 我们之前学的单向链表有什么缺点呢? 缺点:后一个节点无法看到前一个节点的内容 那我们就多设置一个格子prev用来存放前面一个节点的地址,第一个节点的prev存最后一个节点的地址(一般是null) 这样一个无头双向…...
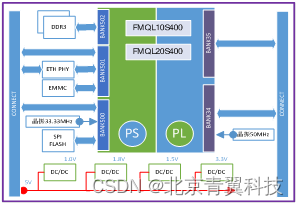
【TES720D】基于复旦微的FMQL20S400全国产化ARM核心模块
TES720D是一款基于上海复旦微电子FMQL20S400的全国产化核心模块。该核心模块将复旦微的FMQL20S400(兼容FMQL10S400)的最小系统集成在了一个50*70mm的核心板上,可以作为一个核心模块,进行功能性扩展,特别是用在控制领域…...

Python 列表切片陷阱:引用、复制与深复制
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码 Python 列表的切片和赋值操作很基础,之前也遇到过一些坑, 但今天刷 Codewars 时发现了一个更大的坑,故在此记录。 Python 列表赋值&am…...

macbook电脑删除app怎么才能彻底清理?
macBook是苹果公司推出的一款笔记本电脑,它的操作系统是macOS。在macBook上安装的app可能会占用大量的存储空间,因此,当我们不再需要某个app时,需要将其彻底删除。macbook删除app,怎么才能彻底呢?本文将给大…...
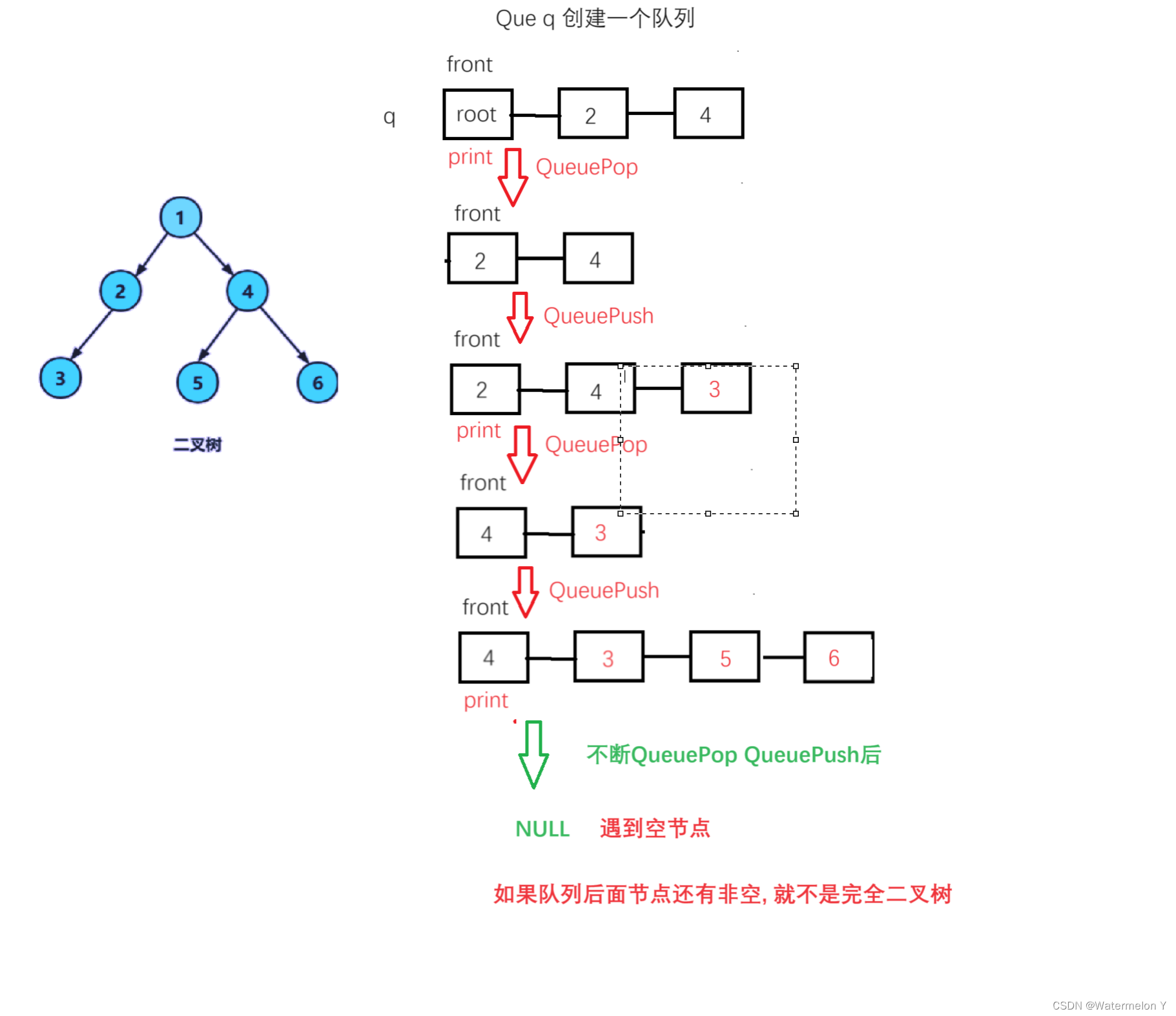
【数据结构】二叉树--链式结构的实现 (遍历)
目录 一 二叉树的遍历 1 构建一个二叉树 2 前序遍历 3 中序遍历 4 后续遍历 5 层序 6 二叉树销毁 二 应用(递归思想) 1 二叉树节点个数 2 叶子节点个数 3 第K层的节点个数 4 二叉树查找值为x的节点 5 判断是否是二叉树 一 二叉树的遍历 学习二叉树结构࿰…...

reids基础数据结构
文章目录 一.整体1.RedisDb2.对象头 二.string三.list1.ziplist2.quicklist 四.hash五.set六.zset1.查找2.插入3.删除4.更新5.元素排名 一.整体 1.RedisDb redis内部的所有键值对是两个hash结构,维护了键值对和过期时间 dict *dictdict *expire 2.对象头 int t…...

gitlab 维护
一 环境信息 二 日常维护 2.1 gitlab mirror 2.1.1 常见方法 社区版本gitab mirror 只能push,默认限制了局域网内mirror 需要修改admin/setting/network(网络)/outbound(出站请求) 勾选允许局域网即可。 2.1.2 疑难问题 内网有三个gitlab A: GITLAB 12 B\C GI…...
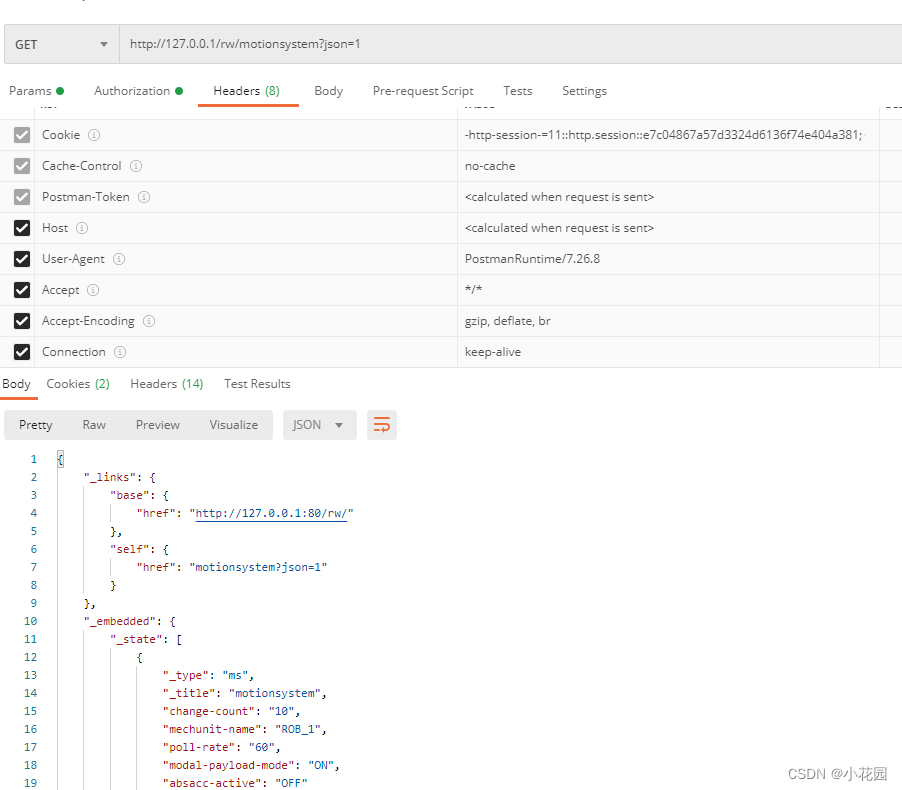
ABB机器人RWS连接方法
目录 方法一:curl 方法二:网页地址 方法三:Postman 与ABB机器人通讯,较新机器人,可以使用Robot Web Services,直接方便地使用网页进行查看当前数据,但是网页需要用户名密码验证,测…...

Spring Boot的循环依赖问题
目录 1.循环依赖的概念 2.解决循环依赖的方法 1.构造器方法注入: 2.Lazy注解 3.DependsOn注解 1.循环依赖的概念 两个或多个bean之间互相依赖,形成循环,此时,Spring容器无法确定先实例化哪个bean,导致循环依赖的…...

postgresql|数据库|恢复备份的时候报错:pg_restore: implied data-only restore的处理方案
一, 前情回顾 某次在使用pg_dump命令逻辑备份出来的备份文件对指定的几个表恢复的时候,报错pg_restore: implied data-only restore 当然,遇到问题首先就是百度了,但好像没有什么明确的解决方案,具体的报错命令和…...
Elasticsearch:使用 Langchain 和 OpenAI 进行问答
这款交互式 jupyter notebook 使用 Langchain 将虚构的工作场所文档拆分为段落 (chunks),并使用 OpenAI 将这些段落转换为嵌入并将其存储到 Elasticsearch 中。然后,当我们提出问题时,我们从向量存储中检索相关段落,并使用 langch…...

安全巡检管理系统—隐患排查治理
安全管理越来越重要,每个生产企业都需要一个安全隐患排查治理小程序!利用凡尔码平台搭建安全巡检管理系统主要有以下四个功能 1、制定巡检计划:安全巡检管理系统可以帮助用户制定巡检计划,用户可以根据需要创建不同的计划…...
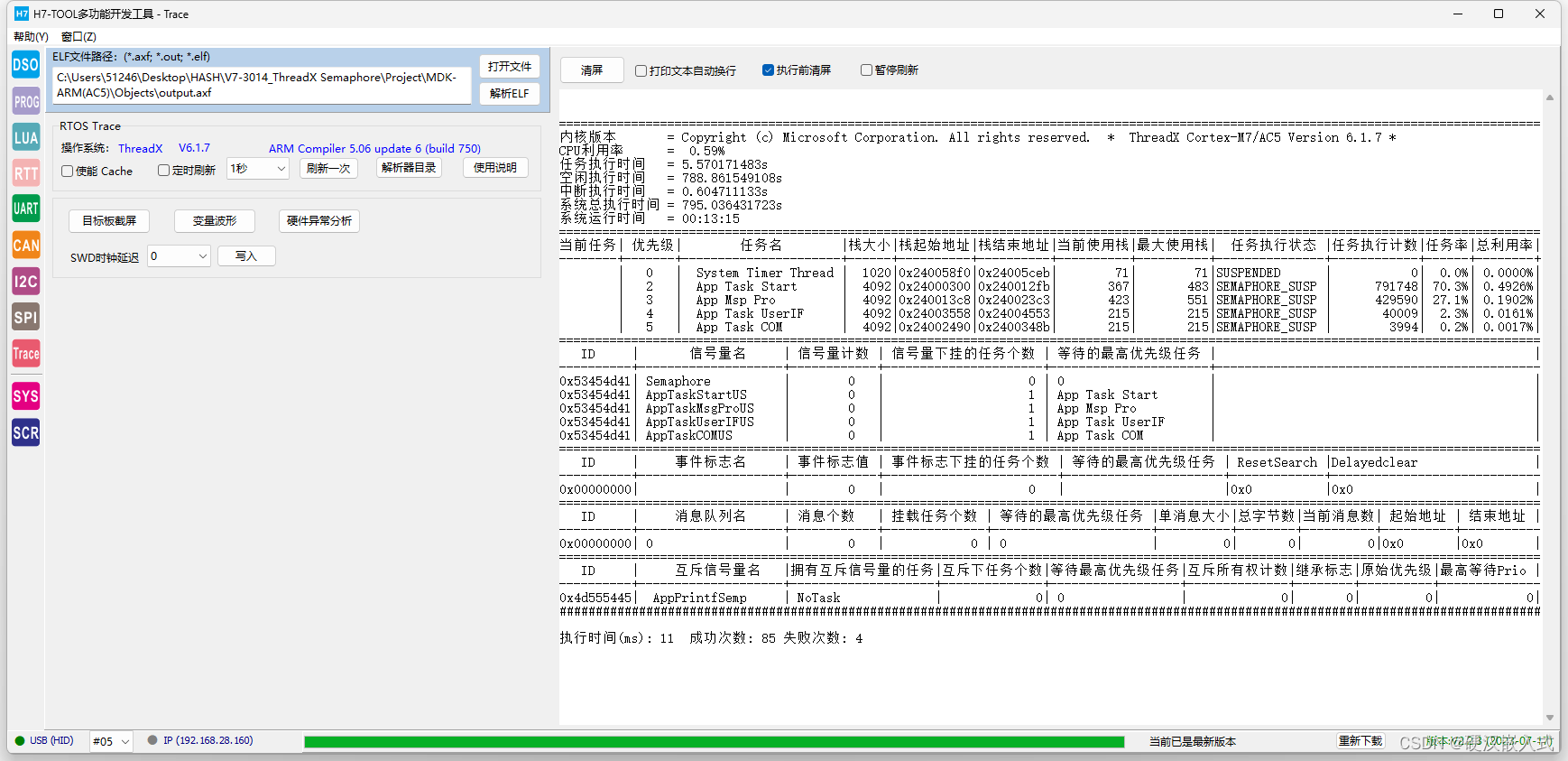
第9期ThreadX视频教程:自制个微秒分辨率任务调度实现方案(2023-10-11)
视频教程汇总帖:【学以致用,授人以渔】2023视频教程汇总,DSP第12期,ThreadX第9期,BSP驱动第26期,USB实战第5期,GUI实战第3期(2023-10-11) - STM32F429 - 硬汉嵌入式论坛 …...

C++ 11 lamdba表达式详解
C lamdba 表达式 Lambda表达式是C11引入的一个新特性,它允许我们在需要函数对象的地方,使用一种更加简洁的方式定义匿名函数。Lambda表达式通常用于STL中的算法、回调函数、事件处理程序等场合。 Lambda表达式的基本语法为: Copy Code[captu…...

Linux运行环境搭建系列-Zookeeper安装
Zookeeper安装 ## 下载Zookeeper:https://zookeeper.apache.org/releases.html https://dlcdn.apache.org/zookeeper/zookeeper-3.8.3/apache-zookeeper-3.8.3-bin.tar.gz ## 解压 tar -zxvf apache-zookeeper-3.8.3-bin.tar.gz ## 删除原文件,重命名 r…...

vscode利用lauch.json和docker中的delve调试本地crdb
---- vscode利用delve调试crdb 创建了一个delve容器用于debug crdbdelve: Delve是一个用于Go编程语言的调试器。它提供了一组命令和功能,可以帮助开发人员在调试过程中检查变量、设置断点、单步执行代码等操作。Delve可以与Go程序一起使用,…...

【java|golang】多字段排序以及排序规则
奖励最顶尖的 K 名学生 给你两个字符串数组 positive_feedback 和 negative_feedback ,分别包含表示正面的和负面的词汇。不会 有单词同时是正面的和负面的。 一开始,每位学生分数为 0 。每个正面的单词会给学生的分数 加 3 分,每个负面的词…...
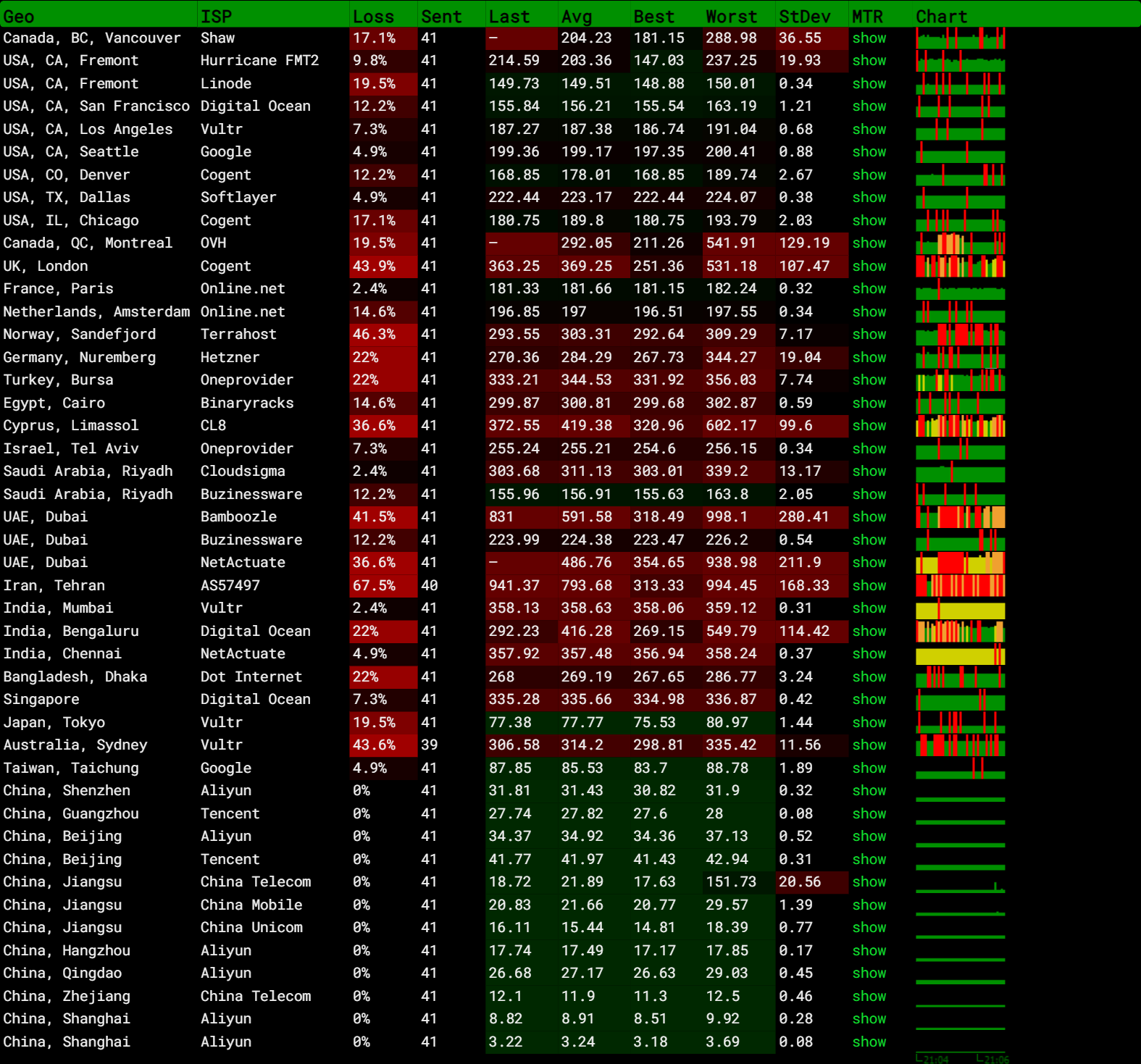
腾讯云 轻量云 上海 VPS 测评
description: 发布于 2023-07-05腾讯云 轻量云 上海 VPS 测评 腾讯云国内机非常稳定,一年用下来没有掉线丢包的情况。国内机适合与备案域名一起建站使用。带宽很小,图片资源使用CDN加速或海外机提供。 规格 CPU - 2核 内存 - 2GB 系统盘 - SSD云硬盘…...

2026年小程序多少钱:8款高口碑产品排行榜解锁最优选择
导读:2026年,小程序开发已成为企业数字化运营的核心工具,其成本结构受功能复杂度、平台选择及服务商专业度等多因素影响。市场调研显示,基础展示型小程序报价集中在5000-15000元,而定制化多功能方案可达5万元以上。行业…...
)
告别双系统!用WSL2+Ubuntu20.04+ROS Noetic玩转AirSim仿真(保姆级避坑指南)
告别双系统!用WSL2Ubuntu20.04ROS Noetic玩转AirSim仿真(保姆级避坑指南) 在机器人开发与自动驾驶仿真领域,AirSim与ROS的结合堪称黄金搭档——前者提供高保真物理引擎与视觉渲染,后者则是机器人算法开发的行业标准。…...

SBA系列生物传感分析仪的工作原理是什么?
SBA系列生物传感分析仪利用酶促反应来进行定量分析,测定的关键传感器是固定化酶和过氧化氢电极复合传感器,分析过程基于以下生化反应:底物 固定化酶膜 → 产物谷氨酸 谷氨酸氧化酶 α-酮戊二酸葡萄糖 葡萄糖氧化…...
:谷歌AI团队内部培训手册泄露版)
NotebookLM具身智能落地实战(从零部署到ROS2集成):谷歌AI团队内部培训手册泄露版
更多请点击: https://intelliparadigm.com 第一章:NotebookLM具身智能研究 NotebookLM 是 Google 推出的基于用户自有文档进行语义理解与推理的 AI 助手,其核心能力在于“文档感知”(document-grounded reasoning)。当…...

量子纠错与Floquet码:动态编码与ZX演算实践
1. 量子纠错与Floquet码基础量子纠错码是构建容错量子计算机的核心技术。与传统纠错码不同,量子态具有不可克隆特性,使得量子纠错必须采用特殊方法。稳定子码(Stabilizer Codes)是目前最成熟的量子纠错方案,通过测量多…...

iPhone/iPad移动端CircuitPython嵌入式开发实战指南
1. 项目概述:当嵌入式开发遇上移动生产力作为一名在嵌入式硬件和创客领域折腾了十多年的老玩家,我经历过各种开发环境的变迁。从早年抱着一台厚重的笔记本电脑在实验室里调试,到后来用树莓派做便携式开发机,我一直希望能有一种更轻…...

SAP 实战篇:Script脚本进阶,从录制到智能循环批量处理
1. SAP脚本自动化:从入门到进阶 刚接触SAP脚本时,我和大多数新手一样,以为它只是个简单的"动作录制器"。直到有次需要处理500多条订单修改,我才发现这个被低估的工具能带来多大改变。SAP Script脚本本质上是通过VBScrip…...

让框架跑得久一点:失败继续、日志、截图、HTML 与网络现场
摘要 前面几篇讲了框架如何执行 CSV、如何处理变量和状态、如何做网络断言。 到这里,框架已经能跑起来。 但自动化测试长期使用时,真正麻烦的不是失败,而是失败后看不懂。 这篇文章讲框架为了“失败后能排查”做了哪些设计:contin…...

Umi-CUT:三分钟解决图片批量处理难题,让工作效率翻倍!
Umi-CUT:三分钟解决图片批量处理难题,让工作效率翻倍! 【免费下载链接】Umi-CUT 图片批量去黑边/裁剪/压缩工具,带界面。可排除图片边缘的色块干扰,将黑边删除干净。基于 Opencv 。 项目地址: https://gitcode.com/g…...

紫光同创FPGA网络摄像头方案中,RGMII转GMII模块的Verilog实现与调试避坑指南
紫光同创FPGA网络摄像头方案中RGMII-GMII转换模块的深度解析与实战指南 当你在调试紫光同创FPGA网络摄像头方案时,是否遇到过这样的场景:PHY芯片与FPGA之间的物理层连接已经建立,但网络数据始终无法正常传输?或者上位机接收到的视…...