K邻近算法(KNN,K-nearest Neighbors Algorithm)
文章目录
- 前言
- 应用场景
- 欧几里得距离(欧氏距离)
- 两类、单一属性(1D)
- 两类、两种属性(2D)
- 两类、两种以上属性(>3D)
- Examples in R
- 再来一个
- 补充一下什么是变量
- 什么是变量?
- 什么是数值、分类变量?
前言
之前看到一篇文章,方法部分提到了这个K邻近算法,正好自己不是很熟悉其原理,所以学习整理一下😑
K邻近算法(K-nearest neighbors algorithm)是一种常用的机器学习算法,用于分类和回归问题。它基于一个简单的假设:与未知样本最相似的K个已标记样本的类别可以用来预测该未知样本的类别。
在K邻近算法中,输入数据点被表示为n维空间中的向量,并且每个数据点都有一个对应的类别标签。算法的工作原理如下:
- 计算距离:根据给定的距离度量方法(例如欧氏距离、曼哈顿距离等),计算未知样本与训练集中所有已标记样本之间的距离。
- 选择最近邻:选择距离未知样本最近的K个已标记样本。
- 预测类别:对于分类问题,通过多数表决的方式确定未知样本的类别。即,选择K个最近邻中出现次数最多的类别作为预测结果。对于回归问题,可以使用这些最近邻的平均值作为预测结果。
K值的选择很重要,较小的K值会使模型更加敏感和复杂,可能会过拟合。较大的K值则可能导致模型过于简单,无法捕捉到数据集中的复杂模式。K邻近算法简单易懂,且适用于多种问题。然而,它也有一些限制,如对于高维数据和样本不平衡问题的处理效果可能较差。此外,由于该算法需要计算距离矩阵,对于大型数据集来说会变得计算密集。
应用场景
假设有一定数量的物体,每个物体都有其独特的属性,比如,我们有有椅子床和桌子(对象),并知道其对应的长宽高(属性)。如果有人给我们一个具有已知属性的对象,让我们猜测(预测)该对象属于什么,就是说,已知数据的维度,要求预测它是椅子、床还是桌子,就可以使用knn算法。
属性是对象的属性,每个对象都可以看作一个范畴。我们可以检查新对象的属性与任何已知类别的关系。当属性已知,可以画在图上,图形表示能让我们更易于理解并计算新对象与已知类别之间的欧几里得距离,确定新对象最接近哪个类别。
欧几里得距离(欧氏距离)
欧几里得是个人名,不要被这个名字吓倒,它只是简单地表示平面上两点之间的距离。通过简单地使用公式,可以计算两点之间的距离,不管你有多少属性,比如高度、宽度、宽度、重量等等。公式为√(x2−x1)²+(y2−y1)²+(z2−z1)²……(n2-n1)²
两类、单一属性(1D)
我们有两个类别:男性和女性,其各自的高度在下表中给出。
| 性别 | 身高(cm) |
|---|---|
| 男 | 178 |
| 男 | 179 |
| 女 | 163 |
| 女 | 168 |
| 男 | 181 |
| 女 | 170 |
| 男 | 183 |
| 女 | 171 |

此时出现一个新成员,并且需要确定它是男是女。已知其身高,在1D平面上画图,看新对象的属性更接近哪里。理想情况下,我们可以计算欧几里德距离,以确定最接近新对象属性的值。如果我们在身高图上画180cm这个点(新对象的属性),它更接近男性的身高。所以推测新对象更可能是男性。
两类、两种属性(2D)
现在再加入一个新的属性:体重,它也可以描述男性和女性的特征,如下表所示。
| 性别 | 身高(cm) | 体重(kg) |
|---|---|---|
| 男 | 178 | 72 |
| 男 | 179 | 81 |
| 女 | 163 | 54 |
| 女 | 168 | 57 |
| 男 | 181 | 97 |
| 女 | 170 | 59 |
| 男 | 184 | 77 |
| 女 | 171 | 58 |

现在,我们创建一个二维平面,并按照相同的步骤计算新对象与旧对象的距离,它与其中一个类别的距离越近,新对象属于该类别的可能性就越大。可以看到,新成员(属性:身高169cm、体重68kg)与女性更加接近。所以推测其为女性。
两类、两种以上属性(>3D)
通常情况下,有很多属性与分类对象相关联,不能简单画在二维或一维平面上。假设有5个属性:性别、身高、体重、瞳孔的颜色、头发长度和音高,只需使用欧几里德距离公式来计算新对象与给定的对象之间的距离。
( s e x 1 − s e x 2 ) 2 + ( h e i g h t 1 − h e i g h t 2 ) 2 + ( w e i g h t 1 − w e i g h t 2 ) 2 + ( e y e _ c o l o r 1 − e y e _ c o l o r 2 ) 2 + ( h a i r _ l e n g t h 1 − h a i r _ l e n g t h 2 ) 2 + ( v o i c e _ p i t c h 1 − v o i c e _ p i t c h 2 ) 2 \sqrt{(sex1-sex2)^2 +(height1-height2)^2 + (weight1-weight2)^2+(eye\_color1-eye\_color2)^2+(hair\_length1-hair\_length2)^2+(voice\_pitch1-voice\_pitch2)^2} (sex1−sex2)2+(height1−height2)2+(weight1−weight2)2+(eye_color1−eye_color2)2+(hair_length1−hair_length2)2+(voice_pitch1−voice_pitch2)2
其中1表示已知类别数据点,2表示要确定其类别的新数据点。相比较小,新的对象与已知某类数据的距离(和)越小,则属于该类的可能性越大。
Examples in R
在使用R进行KNN之前,需要说明几点:
- KNN,K邻近法中的neighbor数量要有K定义,如果K=5,那么将将会检测最近的五个neighbor以确定所属类别。如果这5个neighbor中的大部分同属于一个类别,那么可以认定新对象很大可能属于该类。
- 对象不同的属性会有不同的标度单位,比如:KG、CM等,所以在使用数据之前需要对每个变量进行标准化(特征缩放),比如Min-Max法。
- KNN算法更适用于数值变量,但不是说它不能处理分类变量,但如果混合了分类变量和数值变量,那就需要其他方法。如果所有值都是数值,KNN是最好的method。
- 把数据分成训练集和测试集时,数据应该已经标准化了:数据标准化 → 拆分。
- KNN算法不适用于R的有序Factors
- K-mean算法和KNN算法是不同的,K-mean用于聚类,是一种无监督的学习算法,而KNN是一种用于分类问题的监督学习算法。
df <- data(iris)
head(iris, 2)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa# Min-Max方法,标准化
nor <- function(x){(x -min(x))/(max(x)-min(x))}# 生成随机数,包含数据集总行数的80%
ran <- sample(1:nrow(iris), 0.8 * nrow(iris)) # 对数据集的前4列标准化
iris_norm <- as.data.frame(lapply(iris[,c(1:4)], nor))summary(iris_norm)
# Sepal.Length Sepal.Width Petal.Length Petal.Width
# Min. :0.0000 Min. :0.0000 Min. :0.0000 Min. :0.00000
# 1st Qu.:0.2222 1st Qu.:0.3333 1st Qu.:0.1017 1st Qu.:0.08333
# Median :0.4167 Median :0.4167 Median :0.5678 Median :0.50000
# Mean :0.4287 Mean :0.4406 Mean :0.4675 Mean :0.45806
# 3rd Qu.:0.5833 3rd Qu.:0.5417 3rd Qu.:0.6949 3rd Qu.:0.70833
# Max. :1.0000 Max. :1.0000 Max. :1.0000 Max. :1.00000 # 提取训练数据集
iris_train <- iris_norm[ran,]
# 提取测试数据集
iris_test <- iris_norm[-ran,]
#提取train数据集的第5列,用作knn函数中的'cl'参数。
iris_target_category <- iris[ran,5]
# 提取test数据集的第5列,衡量预测准确性
iris_test_category <- iris[-ran,5]
library(class)
## 执行KNN,预测
pr <- knn(iris_train,iris_test,cl=iris_target_category,k=13)
(tab <- table(pr,iris_test_category))
# iris_test_category
#pr setosa versicolor virginica
# setosa 12 0 0
# versicolor 0 8 1
# virginica 0 0 9# 这个函数将正确的预测除以总预测数,告诉我们模型有多精确。
accuracy <- function(x){sum(diag(x)/(sum(rowSums(x)))) * 100}
accuracy(tab)
# [1] 96.66667
在iris数据集中,使用k近邻法,最终96.7%的准确率。首先,标准化数据集,然后,将标准化值分离为训练和测试数据集。
想象一下,将训练数据集的值绘制在一个图上,然后在运行带有所有必要参数的knn函数后,将测试数据集的值引入到图中,并计算出与图中每个已知数据点的欧氏距离。
我们将花种类的预测值存储在“pr”中,可以将预测值与原始测试数据集的值进行比较。就可以算出模型的准确性,如果有新的50个值,要求预测这50个值的类别,就可以用这个模型。
再来一个
data(diamonds,package = "ggplot2")
dia <- data.frame(diamonds)
head(dia,2)
# carat cut color clarity depth table price x y z
# 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
# 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
ran <- sample(1:nrow(dia),0.9 * nrow(dia))
dia_nor <- as.data.frame(lapply(dia[,c(1,5,6,7,8,9,10)], nor))
dia_train <- dia_nor[ran,]
dia_test <- dia_nor[-ran,]
##the 2nd column of training dataset because that is what we need to predict about testing dataset
##also convert ordered factor to normal factor
dia_target <- as.factor(dia[ran,2])##the actual values of 2nd couln of testing dataset to compaire it with values that will be predicted
##also convert ordered factor to normal factor
test_target <- as.factor(dia[-ran,2])
pr <- knn(dia_train,dia_test,cl=dia_target,k=20)
tb <- table(pr,test_target)
accuracy(tb)
## [1] 71.09752
在此数据集中,尝试预测“cut”变量,它是一个分类变量,KNN更适用于分类问题。有一些方法可以在包含分类变量和数值变量的混合数据集执行KNN。其余步骤与对iris数据集操作相同,71%的准确率。
Ps:如果不 set.seed() ,每次取的随机会不一样……要想结果可重复,就 set.seed() 。
补充一下什么是变量
什么是变量?
来自:https://m.study.163.com/article/1278429200
统计学中的变量指的是研究对象的特征,我们有时也称为属性,例如人的身高、性别等。每个变量都有变量的值和变量的类型。我们按照变量的类型对变量进行划分。统计学中的变量(variables)大致可以分为数值变量(numrical)和分类变量(categorical)。
什么是数值、分类变量?
数值型变量是值可以取一些列的数,这些值对于 加法、减法、求平均值等操作是有意义的。而分类变量对于上述的操作是没有意义的。数值变量又可以分为下面两类:
离散型变量(discrete)
值只能用自然数或整数单位计算,其数值是间断的,相邻两个数值之间不再有其他数值,这种变量的取值一般使用计数方法取得。
连续型变量(continuous)
在一定区间内可以任意取值,其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值。如身高、绳子的长度等。和离散型变量相比,连续型变量有“真零点”的概念,所以可以进行乘除操作。分类变量又可以分为下面两类:
有序分类变量(ordinal)
描述事物等级或顺序,变量值可以是数值型或字符型,可以进而比较优劣,如喜欢的程度:很喜欢、一般、不喜欢 。
无序分类变量(nominal)
取值之间没有顺序差别,仅做分类,又可分为二分类变量和多分类变量 二分类变量是指将全部数据分成两个类别,如男、女,对、错,阴、阳等,二分类变量是一种特殊的分类变量,有其特有的分析方法。 多分类变量是指两个以上类别,如血型分为A、B、AB、O。
有序分类变量和无需分类变量的区别是:前者对于“比较”操作是有意义的,而后者对于“比较”操作是没有意义的。
相关文章:
K邻近算法(KNN,K-nearest Neighbors Algorithm)
文章目录 前言应用场景欧几里得距离(欧氏距离)两类、单一属性(1D)两类、两种属性(2D)两类、两种以上属性(>3D) Examples in R再来一个补充一下什么是变量 什么是变量?…...
前端基础一:用Formdata对象来上传图片的原因
最近有人问:你是否能用json来传图片,其实应该这么理解就对了。 一、上传的数据体格式Content-Type 1.application/x-www-form-urlencoded 2.application/json 3.multipart/form-data 以上三种类型旨在告诉服务器需要接收的数据类型同事要…...

CSS的布局 Day03
一、显示模式: 网页中HTML的标签多种多样,具有不同的特征。而我们学习盒子模型、使用定位和弹性布局把内容分块,利用CSS布局使内容脱离文本流,使用定位或弹性布局让每块内容摆放在想摆放的位置,让网站页面布局更合理、…...
nodejs+vue+elementui养老院老年人服务系统er809
“养老智慧服务平台”是运用nodejs语言和vue框架,以MySQL数据库为基础而发出来的。为保证我国经济的持续性发展,必须要让互联网信息时代在我国日益壮大,蓬勃发展。伴随着信息社会的飞速发展,养老智慧服务平台所面临的问题也一个接…...

antd表格宽度超出屏幕,列宽自适应失效
最近遇到个诡异的问题,Table用的好好的,可就有一个页面的表格显示不全,超出浏览器宽,设定表格宽度也没用。 仔细分析了用户上传展示的数据后发现,不自动换行的超宽列都是url地址,一开始还以为是地址里有不…...
布局--QT Designer
一、在我们使用Qt做界面设计时,为了界面的整洁美观,往往需要对界面中的所有控件做一个有序的排列,以及设置各个控件之间的间距等等,为此Qt为界面设计提供了基本布局功能,使用基本布局可以使组件有规则地分布。 1.1 基…...

2024第八届杭州国际智慧城市博览会:建筑与智能,智慧与未来
浙江,中国最具活力的省份之一,将再次迎来一场盛大的智慧城市行业展会。2024年第八届浙江智慧城市博览会,由浙江省土木建筑学会发起主办,以“探索未来,智能引领”为主题,于2024年4月份在美丽的杭州国际博览中…...
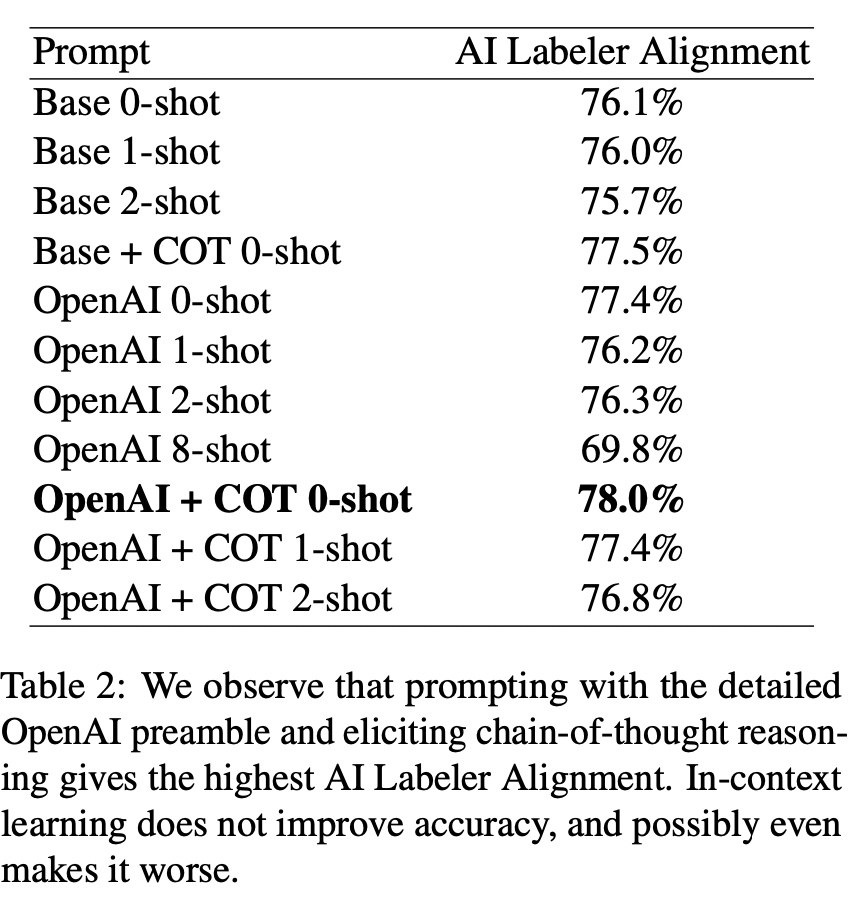
Text-to-SQL小白入门(八)RLAIF论文:AI代替人类反馈的强化学习
学习RLAIF论文前,可以先学习一下基于人类反馈的强化学习RLHF,相关的微调方法(比如强化学习系列RLHF、RRHF、RLTF、RRTF)的论文、数据集、代码等汇总都可以参考GitHub项目:GitHub - eosphoros-ai/Awesome-Text2SQL: Cur…...

C语言联合体和枚举
C语言联合体和枚举 文章目录 C语言联合体和枚举一、联合体①联合体简介②联合体大小的计算 二、枚举 一、联合体 ①联合体简介 union Un {char c;int i; };像结构体一样,联合体也是由⼀个或者多个成员构成,这些成员可以不同的类型。但是编译器只为最大…...
Ubuntu 上传项目到 GitHub
一、前言 GitHub 作为时下最大的开源代码管理项目,广泛被工程和科研人员使用,本文主要介绍如何如何将自己的项目程序上传到 GitHub 上。 要上传本地项目到 GitHub 上,主要分为两步,第一步是 二、创建 SSH keys 首先登录 GitHu…...

CSS 复杂卡片/导航栏特效运用目录
主要是记录复杂卡片/导航栏相关的特效实践案例和实现思路。 章节名称完成度难度文章地址完整代码下载地址多曲面卡片实现完成复杂文章链接代码下载倒置边框半径卡片完成一般文章链接代码下载...

QT: 一种精确定时器类的实现与使用
1)类的实现 #ifndef CPRECISETIMER_H #define CPRECISETIMER_H#include <windows.h>class CPreciseTimer { public:CPreciseTimer();bool SupportsHighResCounter();void StartTimer();void StopTimer();__int64 GetTime();private://Auxiliary Functionvoid…...
SQLite4Unity3d安卓 在手机上创建sqlite失败解决
总结 要在Unity上运行一次出现库,再打包进APK内 问题 使用示例代码的创建库 var dbPath string.Format("Assets/StreamingAssets/{0}", DatabaseName); #else// check if file exists in Application.persistentDataPathvar filepath string.Format…...

跨站请求伪造:揭秘攻击与防御
1、什么是CSRF 其目标是在用户不知情的情况下,以用户身份执行未经授权的操作。攻击者通过引诱用户访问恶意网站或点击包含恶意代码的链接,来伪造一个请求发送给服务器,来触发 CSRF 攻击。一旦用户被攻击,他们的登录凭据将被用于执…...

matlab 图像均值滤波
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠翻译,放入付费专栏只为防不要脸的爬虫。专栏值钱的不是本文,切勿因本文而订阅。 一、算法原理 均值滤波是一种常用的线性滤波方法,用于平滑图像并减少噪声。它的实现过程如下: 确定滤波器的大小:选择一个固定的…...

P1433 吃奶酪
#include <iostream> #include <cmath> using namespace std; #define M 15 #define S(n) ((n) * (n)) double indx[M 5], indy[M 5], ans 0, sum 0;//坐标数组,从下标为1开始记录 int n, vis[M 5] { 0 };//vis数组,选过的数字标记为1…...
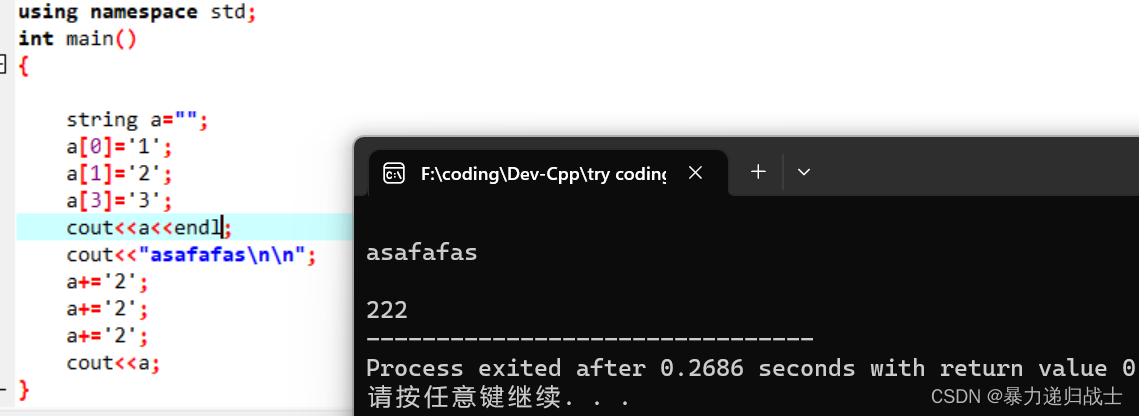
c++string类的赋值问题
来看问题: 为什么呢?是因为定义string a""时候a没有占用空间,所以没有a[0],a[1],a[3]。如果说string a"hhhhhh",那么图中a[0],a[1],a[3]就有效了。正确的做法是用连接,或者是定义时写成string a(6…...

服务器中了mkp勒索病毒怎么办?mkp勒索病毒特点,解密数据恢复
Mkp勒索病毒是最近比较流行的勒索病毒,从10月份国庆节假期结束以来,云天数据恢复中心陆续收到很多企业的求助,企业的服务器被mkp勒索病毒攻击,导致企业的众多软件无法正常使用,像用友与金蝶软件都有遭受过mkp勒索病毒的…...

深入探析网络代理与网络安全
随着互联网的快速发展,网络安全问题日益突出,而网络代理技术正成为应对安全挑战的重要工具。本文将深入探讨Socks5代理、IP代理以及它们在网络安全、爬虫开发和HTTP协议中的关键作用,以期帮助读者更好地理解和应用这些技术。 1. Socks5代理&…...

如何开始使用 Kubernetes RBAC
基于角色的访问控制 (RBAC) 是一种用于定义用户帐户可以在 Kubernetes 集群中执行的操作的机制。启用 RBAC 可以降低与凭证盗窃和帐户接管相关的风险。向每个用户授予他们所需的最低权限集可以防止帐户拥有过多的特权。 大多数流行的 Kubernetes 发行版都从单个用户帐户开始,…...

LangChain消息系统深度解析:从OpenAI格式到Claude 3.5,如何设计一个健壮的对话状态机?
LangChain消息系统架构设计:构建企业级对话状态机的工程实践 在当今AI应用开发领域,对话系统的复杂度和功能性需求正呈指数级增长。从简单的单轮问答到需要维护长期记忆、处理多模态输入、执行工具调用的复杂Agent系统,开发者面临的挑战已远超…...

不止于上传预览:在若依框架中构建一个轻量级企业文档管理模块
若依框架下的企业级文档中心设计与实战 在数字化转型浪潮中,企业文档管理正从简单的文件存储向智能化协作平台演进。基于若依微服务框架构建文档中心模块,不仅能满足基础的PDF上传预览需求,更能为企业提供版本控制、权限管理、全文检索等进阶…...
)
手把手教你用smarteye免费搭建GB28181监控平台(支持海康/大华/NVR接入)
零代码搭建GB28181监控平台:兼容海康/大华/NVR的智能方案 在数字化转型浪潮下,视频监控系统已成为企业安全防护和运营管理的重要基础设施。然而,传统监控方案常面临设备品牌混杂、协议不统一的痛点,导致系统集成困难、维护成本居…...

3个颠覆性策略实现网站到Figma设计的智能双向转换
3个颠覆性策略实现网站到Figma设计的智能双向转换 【免费下载链接】figma-html Convert any website to editable Figma designs 项目地址: https://gitcode.com/gh_mirrors/fi/figma-html 你是否曾为设计还原度低、开发周期长、团队协作效率低下而困扰?Figm…...

千问3.5-2B保姆级教程:从模型原理到业务集成的全栈技术路径
千问3.5-2B保姆级教程:从模型原理到业务集成的全栈技术路径 1. 认识千问3.5-2B视觉语言模型 千问3.5-2B是Qwen系列中的小型视觉语言模型,它能够同时理解图片内容和处理自然语言。简单来说,这个模型就像是一个能"看懂"图片并回答问…...

Jable视频下载工具:高效解决方案与专业使用指南
Jable视频下载工具:高效解决方案与专业使用指南 【免费下载链接】jable-download 方便下载jable的小工具 项目地址: https://gitcode.com/gh_mirrors/ja/jable-download 问题诊断:视频下载的四大核心挑战 技术门槛障碍 传统视频下载工具往往需要…...

PySimpleGUI V5付费升级初体验:从免费到许可,开发者如何平滑过渡?
1. 当程序突然弹窗要License Key时 那天下午同事跑来找我,说我的工具弹出一个从没见过的窗口,要求输入什么License Key。我第一反应是代码被篡改了?仔细一看才发现是PySimpleGUI自动更新到了V5版本。这个突如其来的变化让我想起很多开源项目商…...

前端CSS样式详细笔记
文章目录一、CSS基础概念1. 什么是CSS2. CSS三大核心特性3. CSS基本语法结构二、CSS引入方式三、CSS选择器详解1. 基础选择器2. 组合选择器3. 属性选择器4. 伪类与伪元素四、选择器优先级规则1. 优先级计算方法2. 优先级实战示例3. 优先级注意事项五、CSS盒模型1. 盒模型组成2.…...

Python使用DrissionPage实现自动化处理的简单入门指南
在Python自动化领域,Selenium和Requests是两个常用工具,但各有局限。DrissionPage巧妙结合了两者优势,既能用浏览器自动化处理动态页面,又能通过HTTP请求提升效率。本文将带你从零开始,用10分钟掌握DrissionPage的核心…...

KubeSphere vs Kuboard:Kubernetes管理工具选型与实战对比
KubeSphere vs Kuboard:深度对比与选型指南 1. 开篇:为什么需要Kubernetes管理工具? 在云原生技术蓬勃发展的今天,Kubernetes已成为容器编排领域的事实标准。然而,原生Kubernetes Dashboard的功能相对基础,…...