Text-to-SQL小白入门(八)RLAIF论文:AI代替人类反馈的强化学习
学习RLAIF论文前,可以先学习一下基于人类反馈的强化学习RLHF,相关的微调方法(比如强化学习系列RLHF、RRHF、RLTF、RRTF)的论文、数据集、代码等汇总都可以参考GitHub项目:GitHub - eosphoros-ai/Awesome-Text2SQL: Curated tutorials and resources for Large Language Models, Text2SQL, and more.,这个项目收集了Text2SQL+LLM领域的相关简介、综述、经典Text2SQL方法、基础大模型、微调方法、数据集、实践项目等等,持续更新中!
(如果觉得对您有帮助的话,可以star、fork,有问题、建议也可以提issue、pr,欢迎围观)
论文概述
基本信息
- 英文标题:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
- 中文标题:RLAIF:利用人工智能反馈扩展基于人类反馈的强化学习
- 发表时间:2023年9月
- 作者单位:Google Research
- 论文链接:https://arxiv.org/pdf/2309.00267.pdf
- 代码链接:无
摘要
摘要生成任务有效,其他任务比如Text2SQL任务是否有效呢?
- 基于人类反馈的强化学习(RLHF)在将大型语言模型(llm)与人类偏好对齐方面是有效的,但收集高质量的人类偏好标签是一个关键瓶颈。
- 作者提出了RLAIF(利用AI反馈代替人类反馈),并且和RLHF进行对比,结果如下:
- 在摘要生成任务(summarization task)中,在约70%的情况下,人类评估者更喜欢来自RLAIF和RLHF的结果,而不是SFT模型。
- 此外,当被要求对RLAIF和RLHF摘要进行评分时,人类对两者的偏好率相同。
- 这些结果表明,RLAIF可以产生人类水平的性能,为RLHF的可扩展性限制提供了一个潜在的解决方案。
数据可以让AI生成,评估也可以让AI评估,AI for anything
结果
上结果,有图有真相

结果表明,RLAIF达到了与RLHF相似的性能。(人类打分,人类评估谁更好)
- RLHF 和 SFT 相比,RLHF有73%的情况更优秀
- RLAIF 和 SFT 相比,RLAIF有71%的情况更优秀
- RLHF 和 RLAIF 相比,RLHF有50%的情况下更优秀,也就是两者五五开。
碰巧还发现了一个论文的笔误,结果应该是论文中的图1,论文写的是表1。

论文还比较了RLHF和RLAIF分别和人类撰写的参考摘要。
- RLAIF摘要在79%的情况下优于参考摘要。
- RLHF摘要在80%的情况下优于参考摘要。
结果表明,RLAIF和RLHF策略倾向于生成比SFT策略更长的摘要,这可以解释一些质量改进。
但在控制长度后,两者的表现仍然优于SFT策略。
结论
证明了AI反馈的潜力
在这项工作中,论文证明了RLAIF可以在不依赖于人类注释者的情况下产生与RLHF相当的改进。
论文的实验表明,RLAIF在SFT基线上有很大的改进,改进幅度与RLHF相当。
在头对头比较中(head-to-head comparision,两者单挑的意思),人类对RLAIF和RLHF的偏好率相似。
还是有一些局限性。
比如任务是否可以推广到其他任务(和前面的摘要想法一样)
AI反馈 和 人工反馈的成本
RLHF+RAIF 结合是不是更好
等等
核心方法
贡献点
- 摘要任务上:RLAIF达到了和RLHF相当的性能
- 比较了各种AI 标签的技术,确定了最佳设置
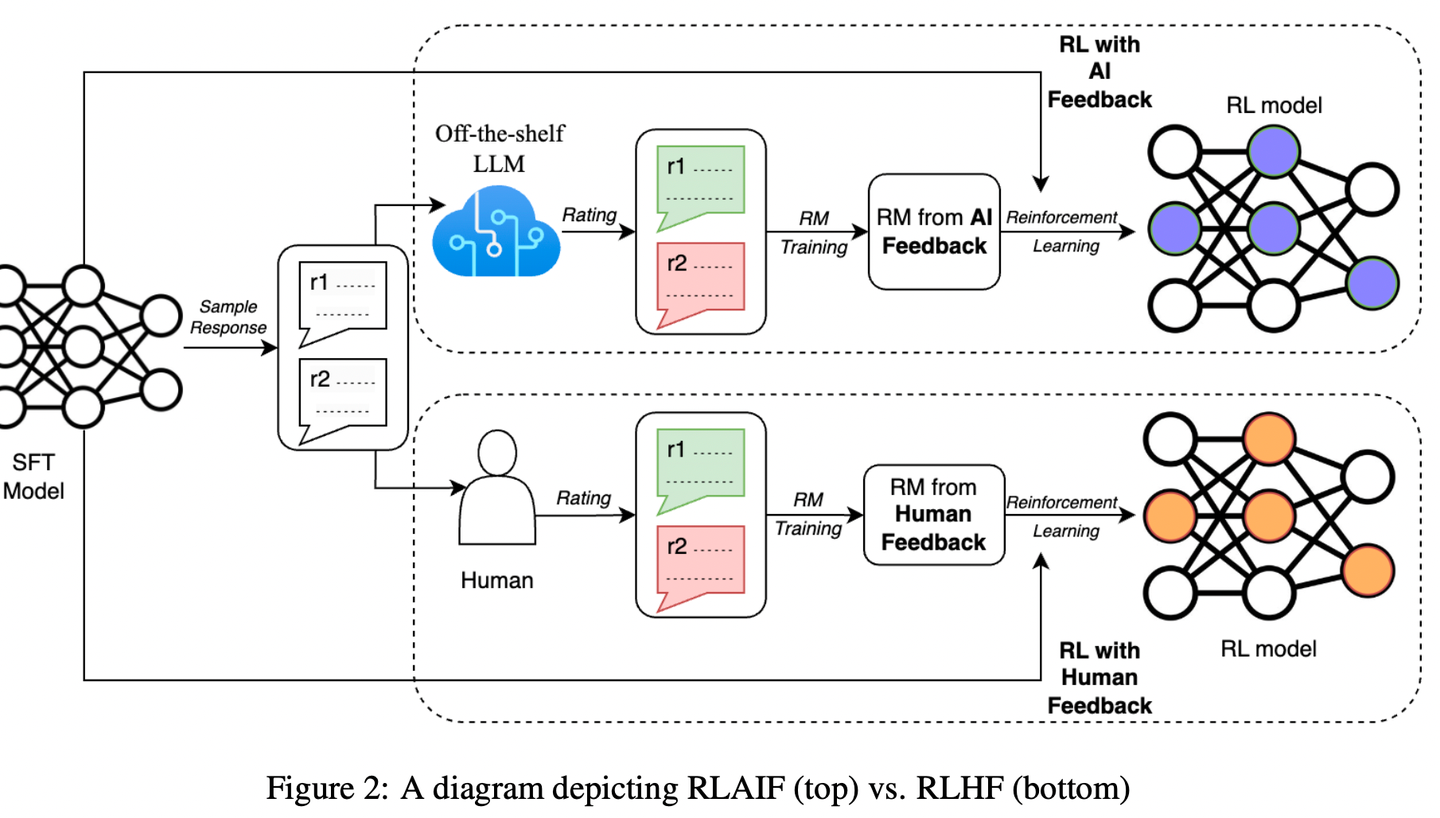
RLHF
RLHF三部曲
SFT
RM
RL
SFT——提取专家知识
Supervised Fine-tuning有监督微调,简称为SFT。
SFT的数据通常是高质量的标注数据,比如基于LLM完成Text2SQL任务的话,数据集可以构造为如下形式:
以spider数据集示例:使用DB-GPT-Hub项目中预处理得到下面类似的数据:
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","output": "SELECT count(*) FROM head WHERE age > 56"}我们可以做个测试,把prompt输入到ChatGPT-3.5中,如下:可以发现这个和标准的SQL一致,这个SQL属于比较简单的那种。

RM——类似于loss function
Reward Modeling 奖励模型,简称RM训练,最终目标就是训练一个模型,这个模型可以对LLM生成的response进行打分,得分高,代表response回答比较好。
RM的训练数据通常来说比SFT训练数据少,之前看见个例子说SFT数据占60%, RM数据占20%, RL数据占20%.
同样的,我们还是以Text2SQL任务举例子,RM数据可以构造为(prompt,chosen,rejected}的三元组,如下所示:
- chosen数据就是SFT的标准输出,groundtruth
- rejected数据通常来源于SFT 模型的错误输出,也就是bad case
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","chosen": "SELECT count(*) FROM head WHERE age > 56","rejected":"SELECT COUNT(head_name) FROM head WHERE age > 56;"}损失函数如下形式:
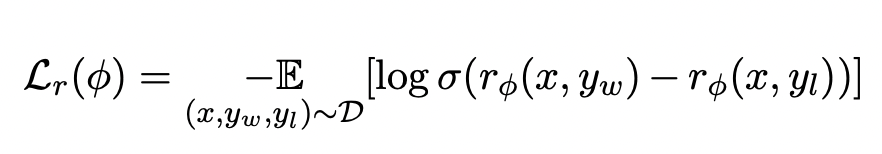
- 这里的x就是输入prompt
- y_w就是chosen data
- y_l就是rejected data
RL——引入强化学习方法
Reinforcement Learning 强化学习,简称为RL,就是利用强化学习的方法训练一个模型,使得奖励分数最高。
如下所示:
- 优化分数最大使用的是max
- 使用了KL散度,让训练的RL模型和原始模型差距不能过大
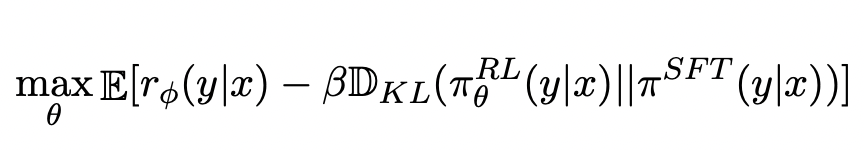
同样的,我们还是以Text2SQL任务举例子,RL数据可以构造为(prompt,output}的三元组,如下所示:
- 数据形式和SFT阶段保持一致
- SFT阶段训练的数据,不应和RL数据重叠。
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","output": "SELECT count(*) FROM head WHERE age > 56"}RLAIF
进入主题RLAIF
LLM偏好标注
- 前言介绍和说明任务
- 1个例子说明:
-
- 需要输入一段文本Text、一对摘要(摘要1和摘要2)
- 模型输出偏好 Preferred Summary=1
- 给出文本和等待标注的摘要1、摘要2
- 结束:给出偏好 Preferred Summary=

在给出输入信息后,得到LLM的输出偏好1 或者 2之后,计算对数概率和softmax,得到偏好分布。
论文提到计算偏好分布也有其他的替代方法:
- 比如直接让模型输出output = "The first summary is better"
- 或者直接让偏好分布是one-hot编码
那么论文为什么不这么做呢?因为论文说就用上面的方法(输出1 或者 2),准确率已经足够高了。
论文做了一个实验,就是对比不同的任务前沿介绍,看看LLM标注的差距。
- Base:代表任务介绍比较简单,比如是“which summary is bet- ter?”(这个是论证任务介绍应该简单点还是详细点?)
- OpenAI:代表任务介绍比较详细,密切模仿了OpenAI,生成的任务介绍包含了哪些构成好的摘要信息
- COT:代表chain-of-thought思维链。(这个是论证思维链是否有效)
- 1-shot:代表给出1个例子,其他shot类似。(这个是论证上下文学习是否有效)
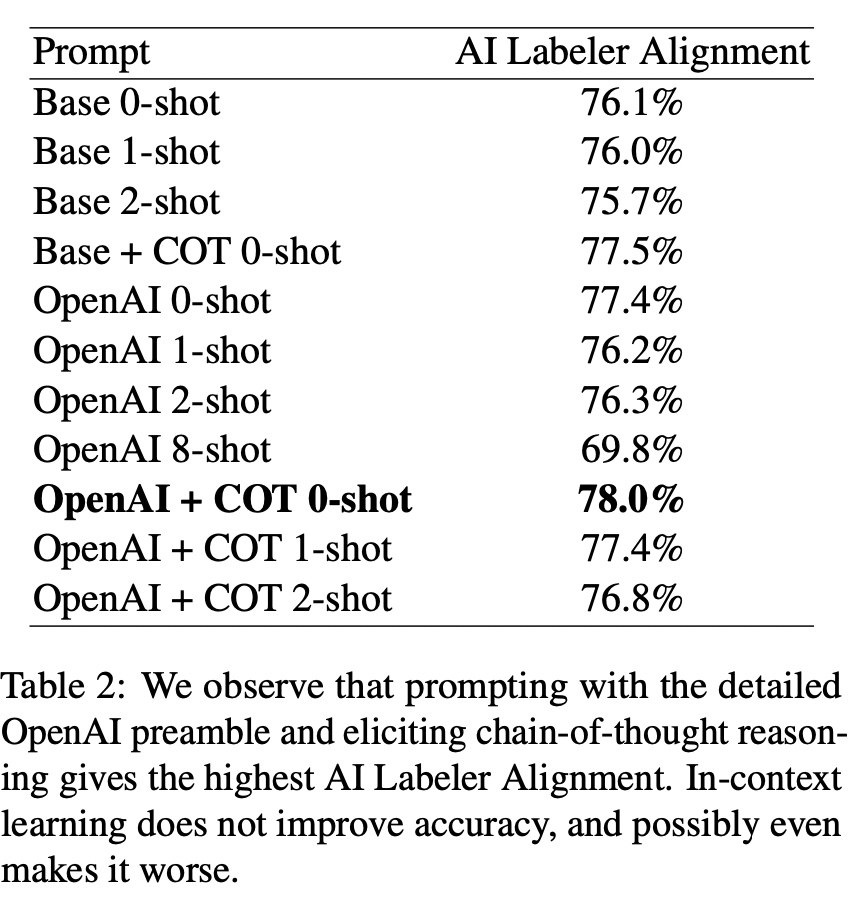
这个实验证明了:效果最好是OpenAI + COT + 0-shot
- 任务说明应该详细点好,OpenAI变现更好
- 思维链是有效的
- 上下文学习无效,甚至会降低效果,因为shot越多,效果越差。
Position Bias位置偏差
注意例子不要都是第一个更好,或者都是第二个更好
这样可能让模型有记忆以为都是第一个更好/第二个更好
所以输入要有随机性。
论文如何减少这个偏差的?
实验两次,取平均值。
- 正常顺序来一次,比如输入「摘要1-摘要2」
- 反方向顺序来一次,比如输入「摘要2-摘要1」
Chain-of-thought Reasoning思维链推理
思维链就是让模型模仿人类思考问题的方式。
回答问题的时候,不仅要有答案,更要有思考的过程。
比如摘要任务,选取第一个摘要更好,是因为第一个摘要的准确性,覆盖性更好。
Self-Consistency自洽性/前后一致性
采用多个推理路径,得到答案。
取平均值。
RLAIF步骤
LLM标记偏好后,训练奖励模型RM模型来预测偏好。
- 论文的方法产生的是软标签比如(preferencesi =[0.6, 0.4]),使用softmax交叉熵损失,而不是前面提到的RLHF中RM的损失函数。
蒸馏方法:用小模型去逼近大模型,让小模型的输出尽量和大模型保持一致。(模型轻量化的方法之一)
- 小模型:学生模型
- 大模型:教师模型
使用AI标注的数据进行训练RM模型,可以理解为模型蒸馏的一部分,因为AI打标签的大模型LLM通常比RM更大、更强。
RL训练不使用PPO算法。
RL训练采用 Advantage Actor Critic (A2C)方法,因为更简单,更有效,在摘要任务上。
相关文章:
Text-to-SQL小白入门(八)RLAIF论文:AI代替人类反馈的强化学习
学习RLAIF论文前,可以先学习一下基于人类反馈的强化学习RLHF,相关的微调方法(比如强化学习系列RLHF、RRHF、RLTF、RRTF)的论文、数据集、代码等汇总都可以参考GitHub项目:GitHub - eosphoros-ai/Awesome-Text2SQL: Cur…...

C语言联合体和枚举
C语言联合体和枚举 文章目录 C语言联合体和枚举一、联合体①联合体简介②联合体大小的计算 二、枚举 一、联合体 ①联合体简介 union Un {char c;int i; };像结构体一样,联合体也是由⼀个或者多个成员构成,这些成员可以不同的类型。但是编译器只为最大…...
Ubuntu 上传项目到 GitHub
一、前言 GitHub 作为时下最大的开源代码管理项目,广泛被工程和科研人员使用,本文主要介绍如何如何将自己的项目程序上传到 GitHub 上。 要上传本地项目到 GitHub 上,主要分为两步,第一步是 二、创建 SSH keys 首先登录 GitHu…...

CSS 复杂卡片/导航栏特效运用目录
主要是记录复杂卡片/导航栏相关的特效实践案例和实现思路。 章节名称完成度难度文章地址完整代码下载地址多曲面卡片实现完成复杂文章链接代码下载倒置边框半径卡片完成一般文章链接代码下载...

QT: 一种精确定时器类的实现与使用
1)类的实现 #ifndef CPRECISETIMER_H #define CPRECISETIMER_H#include <windows.h>class CPreciseTimer { public:CPreciseTimer();bool SupportsHighResCounter();void StartTimer();void StopTimer();__int64 GetTime();private://Auxiliary Functionvoid…...
SQLite4Unity3d安卓 在手机上创建sqlite失败解决
总结 要在Unity上运行一次出现库,再打包进APK内 问题 使用示例代码的创建库 var dbPath string.Format("Assets/StreamingAssets/{0}", DatabaseName); #else// check if file exists in Application.persistentDataPathvar filepath string.Format…...

跨站请求伪造:揭秘攻击与防御
1、什么是CSRF 其目标是在用户不知情的情况下,以用户身份执行未经授权的操作。攻击者通过引诱用户访问恶意网站或点击包含恶意代码的链接,来伪造一个请求发送给服务器,来触发 CSRF 攻击。一旦用户被攻击,他们的登录凭据将被用于执…...

matlab 图像均值滤波
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠翻译,放入付费专栏只为防不要脸的爬虫。专栏值钱的不是本文,切勿因本文而订阅。 一、算法原理 均值滤波是一种常用的线性滤波方法,用于平滑图像并减少噪声。它的实现过程如下: 确定滤波器的大小:选择一个固定的…...

P1433 吃奶酪
#include <iostream> #include <cmath> using namespace std; #define M 15 #define S(n) ((n) * (n)) double indx[M 5], indy[M 5], ans 0, sum 0;//坐标数组,从下标为1开始记录 int n, vis[M 5] { 0 };//vis数组,选过的数字标记为1…...
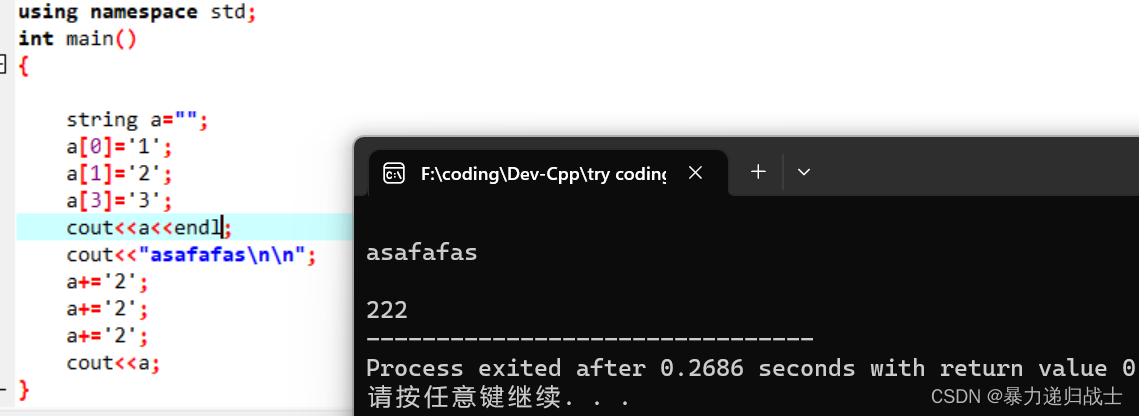
c++string类的赋值问题
来看问题: 为什么呢?是因为定义string a""时候a没有占用空间,所以没有a[0],a[1],a[3]。如果说string a"hhhhhh",那么图中a[0],a[1],a[3]就有效了。正确的做法是用连接,或者是定义时写成string a(6…...

服务器中了mkp勒索病毒怎么办?mkp勒索病毒特点,解密数据恢复
Mkp勒索病毒是最近比较流行的勒索病毒,从10月份国庆节假期结束以来,云天数据恢复中心陆续收到很多企业的求助,企业的服务器被mkp勒索病毒攻击,导致企业的众多软件无法正常使用,像用友与金蝶软件都有遭受过mkp勒索病毒的…...

深入探析网络代理与网络安全
随着互联网的快速发展,网络安全问题日益突出,而网络代理技术正成为应对安全挑战的重要工具。本文将深入探讨Socks5代理、IP代理以及它们在网络安全、爬虫开发和HTTP协议中的关键作用,以期帮助读者更好地理解和应用这些技术。 1. Socks5代理&…...

如何开始使用 Kubernetes RBAC
基于角色的访问控制 (RBAC) 是一种用于定义用户帐户可以在 Kubernetes 集群中执行的操作的机制。启用 RBAC 可以降低与凭证盗窃和帐户接管相关的风险。向每个用户授予他们所需的最低权限集可以防止帐户拥有过多的特权。 大多数流行的 Kubernetes 发行版都从单个用户帐户开始,…...

8.简易无线通信
预备知识 Zigbee无线通信,需要高频的载波来提供发射效率,Zigbee模块之间要可以正常的收发,接收模块必须把接收频率设置和发射模块的载波频率一致。Zigbee有27个载波可以进行通信,载波叫做信道(无线通信的通道…...

渗透测试漏洞挖掘技巧
文章目录 一、使用.json进行敏感数据泄漏二、如何查找身份验证绕过漏洞三、在Drupal上找到隐藏的页面四、遗忘的数据库备份五、电子邮件地址payloads六、HTTP主机头:localhost七、通过篡改URI访问管理面板八、通过URL编码空格访问管理面板九、篡改URI绕过403十、Byp…...

Nginx - 反向代理与负载均衡
目录 一、Nginx 1.1、Nginx 下载 1.2、nginx 基础配置的认识 a)第一部分:全局块 b)第二部分:events 块 c)第三部分:http 块 http 块中 内嵌的 server 块 1.3、一些常用配置 1.3.1、location 匹配级…...
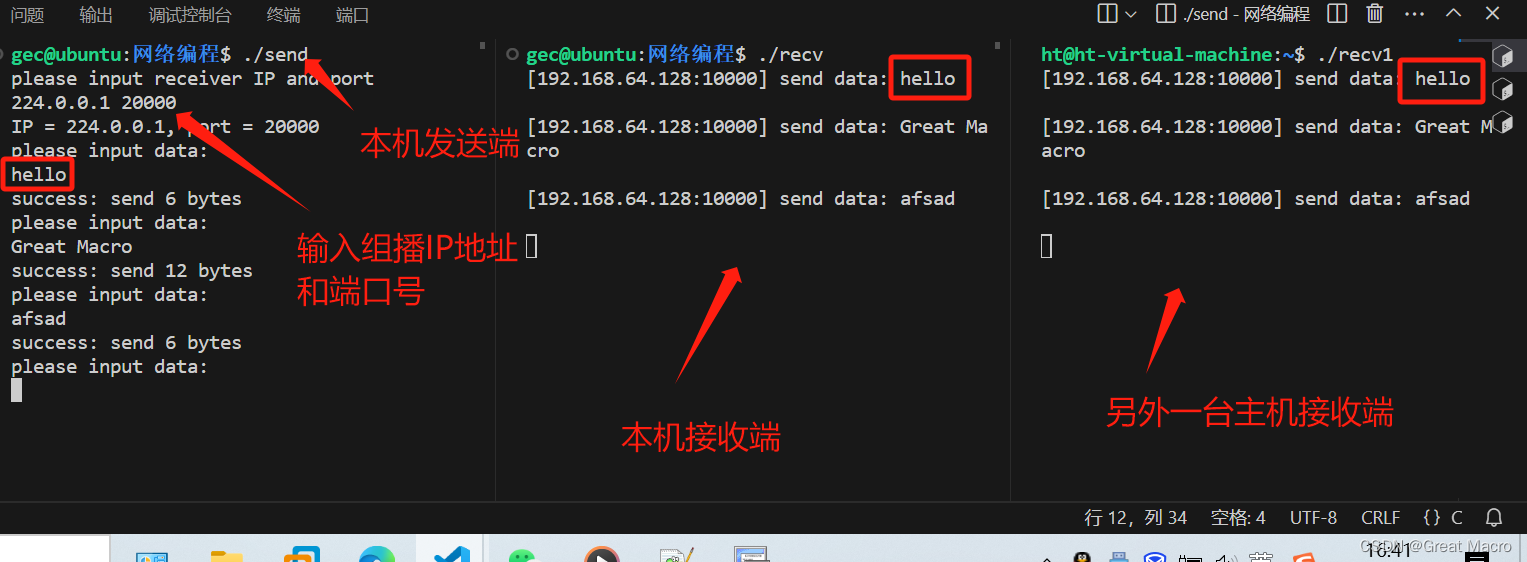
Linux网络编程系列之UDP组播
一、什么是UDP组播 UDP组播是指使用用户数据报协议(UDP)实现的组播方式。组播是一种数据传输方式,允许单一数据包同时传输到多个接收者。在UDP组播中,一个数据包可以被多个接收者同时接收,这样可以降低网络传输的负载和…...
-23)
设计模式~状态模式(state)-23
目录 (1)优点: (2)缺点: (3)使用场景: (4)注意事项: (5)应用实例: 代码 在状态模式(State Pattern)中,类的行为是基于它的状态改变的。这种类型的设计模式属于行为型模式。在状…...
linux环境下使用lighthouse与selenium
一、安装谷歌浏览器、谷歌浏览器驱动、lighthouse shell脚本 apt update && apt -y upgrade apt install -y curl curl -fsSL https://deb.nodesource.com/setup_18.x | bash apt install -y nodejs apt install -y npm npm install -g lighthouse apt-get install -y …...
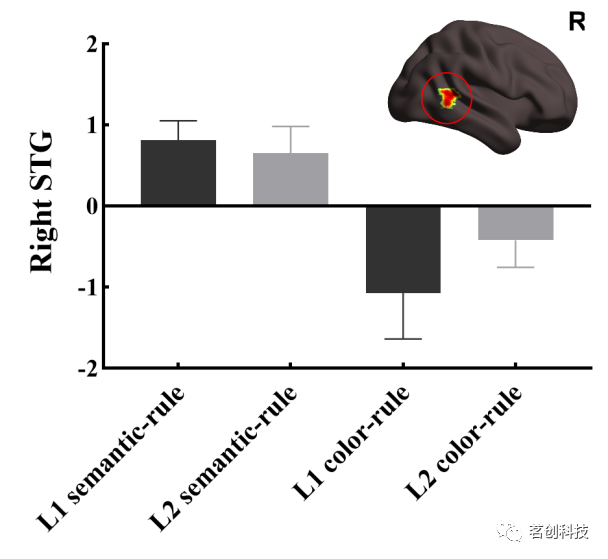
NeuroImage | 右侧颞上回在语义规则学习中的作用:来自强化学习模型的证据
在现实生活中,许多规则的获取通常需要使用语言作为桥梁,特别是语义在信息传递中起着至关重要的作用。另外,个体使用的语言往往具有明显的奖励和惩罚元素,如赞扬和批评。一种常见的规则是寻求更多的赞扬,同时避免批评。…...

从“制造”到“智造”:TVA如何成为智能工厂的底层代码?
当我们在谈论AI视觉检测,尤其是AI智能体视觉检测(TVA)时,我们究竟在谈论什么?如果只把它看作是“替代几个质检工人”的工具,那就太低估它的价值了。在产业升级的洪流中,每一次技术的迭代&#x…...

javaweb蔚来新能源汽车对比推荐平台设计与实现
目录同行可拿货,招校园代理 ,本人源头供货商功能模块设计技术实现方案数据安全措施扩展功能设计项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能模块设计 用户管理模块 实现用户注…...
)
从SEED-Labs实验到实战:手把手教你编写无零字节的x86 Shellcode(附完整代码)
从SEED-Labs实验到实战:手把手教你编写无零字节的x86 Shellcode(附完整代码) 当你第一次看到"Shellcode"这个词时,可能会联想到某种神秘的编程黑魔法。实际上,它是安全研究中最具实用价值的技能之一——一段…...

Windows 10 PL-2303串口驱动终极修复指南:告别老旧芯片兼容性问题
Windows 10 PL-2303串口驱动终极修复指南:告别老旧芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为Windows 10系统下PL-2303串口适配器…...

通义千问大模型+Flask:打造智能PDF批量解析与问答系统
1. 为什么需要智能PDF解析与问答系统 每天都有海量的PDF文档在各个行业流转,从合同协议到财务报表,从学术论文到产品手册。传统的人工阅读和提取方式效率低下,容易出错。我曾经帮一家律师事务所处理过上千份合同,光是找出所有涉及…...

用Multisim 14.2仿真一个可调直流稳压电源:从变压器选型到波形调试全流程
Multisim 14.2仿真可调直流稳压电源:从元器件选型到波形优化的实战指南 在电子工程领域,仿真软件已经成为设计和验证电路不可或缺的工具。对于初学者而言,通过仿真可以快速理解电路原理、验证设计思路,而无需担心元器件损坏或安全…...

3D模型优化终极指南:glTF Pipeline如何让Web应用加载更快
3D模型优化终极指南:glTF Pipeline如何让Web应用加载更快 【免费下载链接】gltf-pipeline Content pipeline tools for optimizing glTF assets. :globe_with_meridians: 项目地址: https://gitcode.com/gh_mirrors/gl/gltf-pipeline glTF Pipeline是一款功能…...

OpenClaw技能市场巡礼:Top5适合Phi-3-vision-128k-instruct的图文处理插件
OpenClaw技能市场巡礼:Top5适合Phi-3-vision-128k-instruct的图文处理插件 1. 为什么需要为多模态模型搭配专用技能? 去年我在尝试用OpenClaw处理一批产品截图时,发现一个有趣现象:当我把图片直接丢给普通文本模型时,…...

javaweb企业设备信息资讯展示网站
目录同行可拿货,招校园代理 ,本人源头供货商功能模块划分核心业务功能技术实现要点安全与维护项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能模块划分 用户管理模块 用户注册与登…...

基于WPS云服务架构的Vue文档预览组件技术实现与性能优化
基于WPS云服务架构的Vue文档预览组件技术实现与性能优化 【免费下载链接】wps-view-vue wps在线编辑、预览前端vue项目,基于es6 项目地址: https://gitcode.com/gh_mirrors/wp/wps-view-vue 在微前端架构和云原生应用日益普及的技术背景下,企业级…...