爬虫 | 正则、Xpath、BeautifulSoup示例学习
文章目录
- 📚import requests
- 📚import re
- 📚from lxml import etree
- 📚from bs4 import BeautifulSoup
- 📚小结
契机是课程项目需要爬取一份数据,于是在CSDN搜了搜相关的教程。在博主【朦胧的雨梦】主页学到很多😄。本文基于大佬给出的实例学习记录自用。以下将相关博客列出,推荐学习~
- Python |浅谈爬虫的由来
- Python爬虫 | 利用python爬虫获取想要搜索的数据
- Python爬虫经典战役——正则实战
- Python爬虫| 一文掌握XPath
- Python爬虫之美丽的汤——BeautifulSoup
📚import requests
-
使用模板
import requests url ='xxxxxxxxxxxx' #发送请求 response = request.get(url, params,headers) (get请求或者post请求) #根据相应的格式解码 response.encoding=response.appareent_encoding
-
在爬虫应用中,伪装请求头里的User-Agent和Cookie具有以下作用和目的:
- User-Agent:User-Agent是HTTP请求头的一部分,用于告诉服务器发送请求的客户端的信息,其中常用的是浏览器标识。在爬虫中,通过设置一个合适的User-Agent,可以模拟不同的浏览器或客户端发起请求,使得请求看起来更像是来自真实的人而不是自动化程序。有些网站可能会根据User-Agent的不同来返回不同的内容,所以在编写爬虫时,设置合适的User-Agent可以提高请求的成功率。
- Cookie:Cookie是存储在客户端(浏览器)中的一小段数据,用于跟踪用户的会话状态。在爬虫中,有些网站会使用Cookie来记录用户的登录状态、浏览历史等信息。为了模拟用户登录状态或以合适的身份进行访问,我们可以在请求头中添加Cookie信息。通过使用合适的Cookie值,可以使请求看起来更像是经过登录验证的用户发起的请求,从而获取到需要登录才能访问的内容。
-
通过伪装请求头中的User-Agent和Cookie,可以增加爬虫对目标网站的访问成功率,避免被服务器拒绝访问或返回错误的内容。另外,在使用伪装请求头时,需要注意遵守网站的使用规则和避免非法操作,以免违反相关法律法规或引起不必要的麻烦。
-
代码精读
import requestsdata = input('输入你想要查找的数据:').split() # 地址 url ='http://www.baidu.com/s'# 伪装请求头 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36','Cookie': 'BIDUPSID=CDE3B4BEE7AE0D336C4D0734E42BCF8B; PSTM=1664331801; BAIDUID=CDE3B4BEE7AE0D33996D27FED1DDB4DB:FG=1; BD_UPN=12314753; BDUSS=JNdXVzTXMyWmFKM0x1VWJ5eG9GUjg4UmVCRFQxY1dtejBPVDFBfjc0VHhYRnRqRVFBQUFBJCQAAAAAAAAAAAEAAACse3WjanNuZGJpZAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAPHPM2PxzzNjTT; BDUSS_BFESS=JNdXVzTXMyWmFKM0x1VWJ5eG9GUjg4UmVCRFQxY1dtejBPVDFBfjc0VHhYRnRqRVFBQUFBJCQAAAAAAAAAAAEAAACse3WjanNuZGJpZAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAPHPM2PxzzNjTT; newlogin=1; ZFY=utLrULRdQjGdhXHuTriamg7jZ2PZMLmnKmUCBUiVrTw:C; BAIDUID_BFESS=CDE3B4BEE7AE0D33996D27FED1DDB4DB:FG=1; BA_HECTOR=ag04ah242k2l2h0la0010ofe1ho8t901f; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; COOKIE_SESSION=765400_1_9_9_5_15_1_0_9_7_0_0_1292084_0_0_0_1668919087_1669684425_1669684425%7C9%234656831_6_1669684425%7C3; B64_BOT=1; BDRCVFR[7FEYkXni5q3]=mk3SLVN4HKm; BD_HOME=1; H_PS_PSSID=26350; BD_CK_SAM=1; PSINO=3; delPer=1; H_PS_645EC=3d48biiwjEvDlNFtMaUHuepsRu67OxRgPoEiOrMKvfRketUwB4GowDbv4KmDa%2BaTHUgCCoc; baikeVisitId=e1f583c7-eb15-4940-a709-054666f30f48; BDSVRTM=443' }data = {# 'wd'是百度搜索的关键字参数'wd': data } # 获得响应 response = requests.get(url=url, params=data, headers=headers) # 智能解码 response.encoding = response.apparent_encoding # 返回响应内容 print(response.text)
📚import re
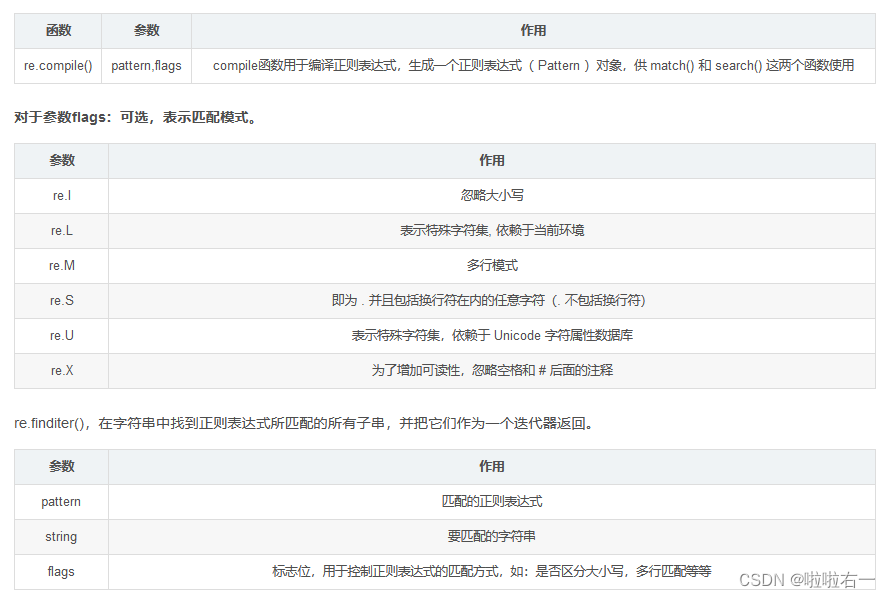
- 贪婪匹配,尽可能多的匹配字符:
.* - 非贪婪匹配,尽可能少的匹配字符:
.*?
-
代码精读
import requests import re# 目标网页的URL url = 'https://movie.douban.com/top250' # 请求头信息 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36' } # 使用requests库发送GET请求,获取目标网页的内容,并将其编码为对应的字符编码格式。 response = requests.get(url=url, headers=headers) response.encoding = response.apparent_encoding # 响应内容的文本形式,存储在变量h h = response.text # 通过正则表达式模式匹配和提取电影信息 pattern = re.compile(r'<img width="100" alt="(?P<name>.*?)"'r'.*?<p class="">.*? 'r'导演: (?P<director>.*?) .*?'r'主演: (?P<actors>.*?)<br>'r'(?P<year>.*?) .*?'r'/ (?P<country>.*?) .*?'r';(?P<type>.*?)</p>.*?'r'<span class="rating_num" property="v:average">(?P<mark>.*?)</span>.*?'r'<span>(?P<evaluate>.*?)</span>', re.S) # 在字符串h中搜索与pattern匹配的内容,并返回一个迭代器对象 result = pattern.finditer(h) for item in result:with open('豆瓣电影信息.txt', 'a', encoding='utf-8') as fp:fp.write('\n')# 使用group方法获取每个匹配项中各个信息字段的值fp.write(item.group('name'))# 写入文件fp.write('\n')fp.write(item.group('director'))fp.write('\n')fp.write(item.group('actors'))fp.write('\n')fp.write(item.group('year').strip())fp.write('\n')fp.write(item.group('country'))fp.write('\n')fp.write(item.group('type'))fp.write('\n')fp.write(item.group('mark'))fp.write('\n')fp.write(item.group('evaluate'))fp.write('\n') print('爬取完成')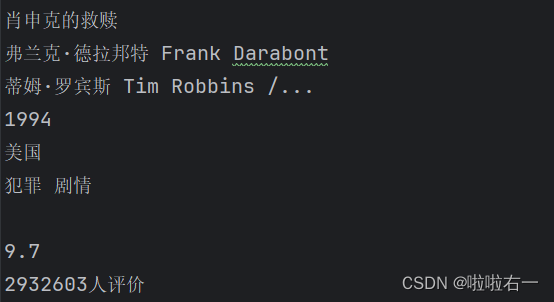


<img width="100" alt="(?P<name>.*?)"- 匹配电影海报的img标签,其中包含了电影名称。
(?P<name>.*?)使用?P<name>为该匹配项命名为’name’,并使用非贪婪模式匹配任意字符。
- 匹配电影海报的img标签,其中包含了电影名称。
.*?<p class="">.*?- 匹配电影信息中的起始标签
<p class="">之后的任意字符。
- 匹配电影信息中的起始标签
导演: (?P<director>.*?) .*?- 匹配导演姓名,导演姓名使用
(?P<director>.*?)命名为’director’,并使用非贪婪模式匹配任意字符。
- 匹配导演姓名,导演姓名使用
主演: (?P<actors>.*?)<br>- 匹配主演姓名,主演姓名使用
(?P<actors>.*?)命名为’actors’,并使用非贪婪模式匹配任意字符。该部分以<br>标签结尾。
- 匹配主演姓名,主演姓名使用
(?P<year>.*?) .*?- 该部分匹配包含电影年份的文本,年份使用
(?P<year>.*?)命名为’year’,并使用非贪婪模式匹配任意字符。该部分以 结尾。
- 该部分匹配包含电影年份的文本,年份使用
/ (?P<country>.*?) .*?- 匹配电影国家/地区,国家/地区使用
(?P<country>.*?)命名为’country’,并使用非贪婪模式匹配任意字符。该部分以 结尾。
- 匹配电影国家/地区,国家/地区使用
;(?P<type>.*?)</p>.*?- 匹配包含电影类型的文本,类型使用
(?P<type>.*?)命名为’type’,并使用非贪婪模式匹配任意字符。该部分以;和</p>标签结尾。
- 匹配包含电影类型的文本,类型使用
<span class="rating_num" property="v:average">(?P<mark>.*?)</span>.*?- 匹配电影评分,评分使用
(?P<mark>.*?)命名为’mark’,并使用非贪婪模式匹配任意字符。该部分以<span class="rating_num" property="v:average">和</span>标签结尾。
- 匹配电影评分,评分使用
<span>(?P<evaluate>.*?)</span>- 匹配电影评价,评价使用
(?P<evaluate>.*?)命名为’evaluate’,并使用非贪婪模式匹配任意字符。该部分以<span>和</span>标签结尾。
- 匹配电影评价,评价使用
📚from lxml import etree
- 代码精读
import requests from lxml import etree # 需要请求的url url = 'https://www.duanmeiwen.com/xinshang/3203373.html' # 伪装请求头 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36', } # 获得响应 response = requests.get(url=url, headers=headers) # 智能解码 response.encoding = response.apparent_encoding# 提取数据 # 使用etree.HTML函数将HTML文本转换为可进行XPath操作的树结构对象tree。 tree = etree.HTML(response.text) # 指定了要提取的目标位置 # 即在HTML文档中,位于/html/body/div[2]/div[2]/div/div[2]/h2这个路径下的<h2>标签。 # div[2]表示选择第二个div元素 # text()表示提取选定元素的文本内容。 # 将结果存储在titles变量 titles = tree.xpath('/html/body/div[2]/div[2]/div/div[2]/h2/text()') # 同上 message = tree.xpath('/html/body/div[2]/div[2]/div/div[2]/p/text()')#遍历保存数据 for i in range(len(message)):with open('优美文艺句子.txt', 'a', encoding='utf-8') as fp:fp.write(message[i])fp.write('\n') print('文章爬取完成')

📚from bs4 import BeautifulSoup
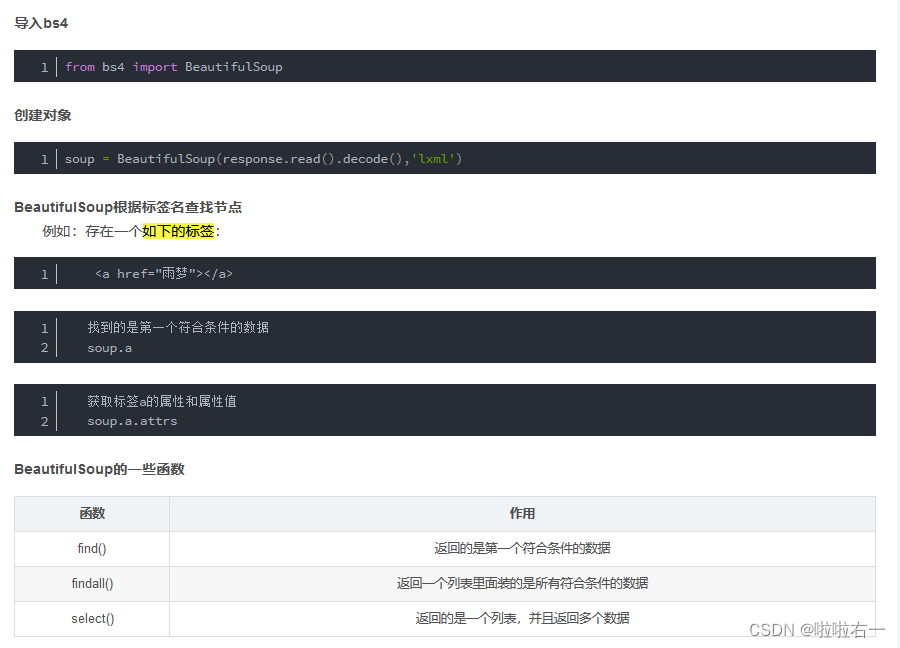
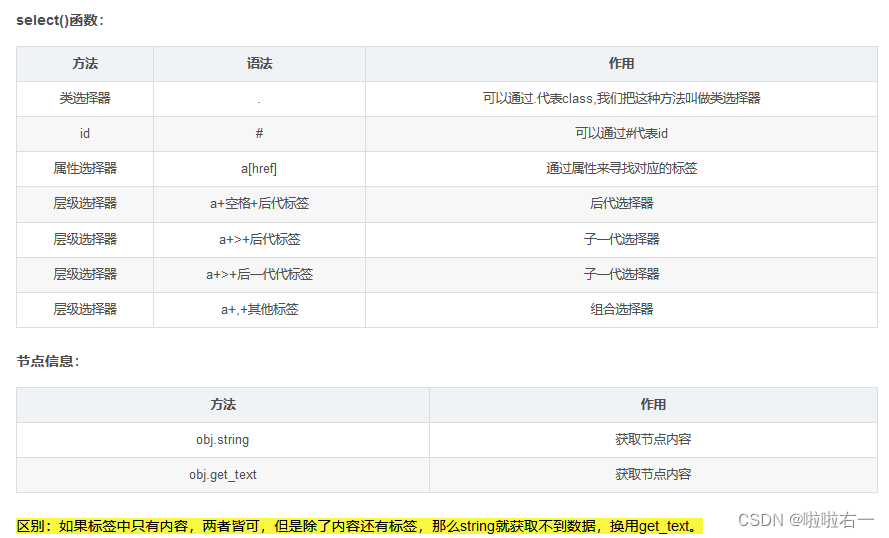
-
代码精读
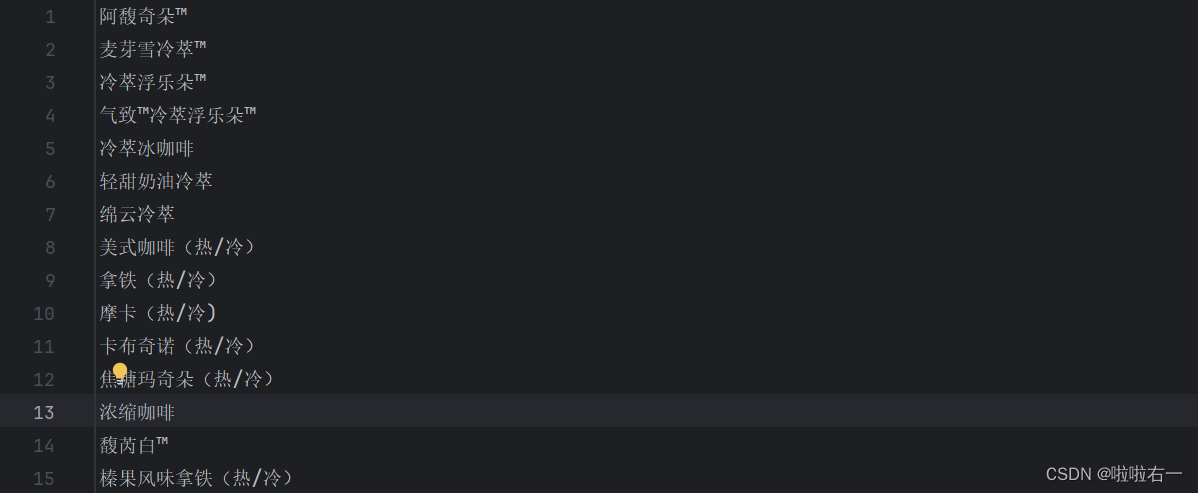
import requests from bs4 import BeautifulSoup# 需要请求的url url = 'https://www.starbucks.com.cn/menu/' # 伪装请求头 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36', } # 获得响应 response = requests.get(url=url, headers=headers) # 智能解码 response.encoding = response.apparent_encoding# 提取数据 soup = BeautifulSoup(response.text, 'lxml') # 通过选择器找到了class为"grid padded-3 product"的ul元素下的strong标签,并将其结果存储在name_list变量中 name_list = soup.select('ul[class="grid padded-3 product"] strong') print(name_list)# 保存数据 for i in name_list:with open('星巴克.txt', 'a', encoding='utf-8') as fp:# 提取HTML或XML文档中指定元素的文本内容fp.write(i.get_text())fp.write('\n') print('文章爬取完成')
📚小结
在爬虫应用中,常用的第三方库包括requests、re、lxml和beautifulsoup。
-
requests库:requests是一个功能强大且易于使用的HTTP库,用于发送HTTP请求。它可以方便地进行网页的访问和数据的获取,包括发送GET和POST请求,设置请求头、参数、Cookie等,并获取响应结果。它可以用于下载网页内容、API数据等。
-
re库:re是Python内置的正则表达式库,它提供了丰富的方法来处理字符串匹配和替换的操作。在爬虫应用中,re经常被用来从HTML页面或文本中提取所需的信息,比如通过正则表达式来匹配特定的文本内容或URL。
-
lxml库:lxml是一个用于解析XML和HTML的库,并提供了XPath和CSS选择器等灵活的选择器语法,用于定位和提取HTML或XML文档中的元素和文本。lxml库具有高效的解析速度和稳定的性能,在爬虫应用中经常被用来解析HTML页面,提取所需的数据。
-
BeautifulSoup库:BeautifulSoup库是基于lxml或者html.parser库构建的Python库,用于将HTML或XML文档解析为可以操作和搜索的树形结构,更方便地进行数据提取。BeautifulSoup提供了直观而简洁的API,可以使用选择器语法来定位元素、获取文本内容、提取属性等。它还具有处理错误和不完整的HTML文档的能力,方便地处理各种网页结构。在爬虫应用中,BeautifulSoup经常被用来解析和处理网页数据,从中提取所需的信息。
这些库在爬虫应用中通常是相互配合使用的,requests用于发送HTTP请求获取网页内容,re用于对网页内容进行正则匹配提取,lxml用于解析网页内容,而BeautifulSoup则用于定位和提取所需的数据。
相关文章:
爬虫 | 正则、Xpath、BeautifulSoup示例学习
文章目录 📚import requests📚import re📚from lxml import etree📚from bs4 import BeautifulSoup📚小结 契机是课程项目需要爬取一份数据,于是在CSDN搜了搜相关的教程。在博主【朦胧的雨梦】主页学到很多…...
nginx的location的优先级和匹配方式
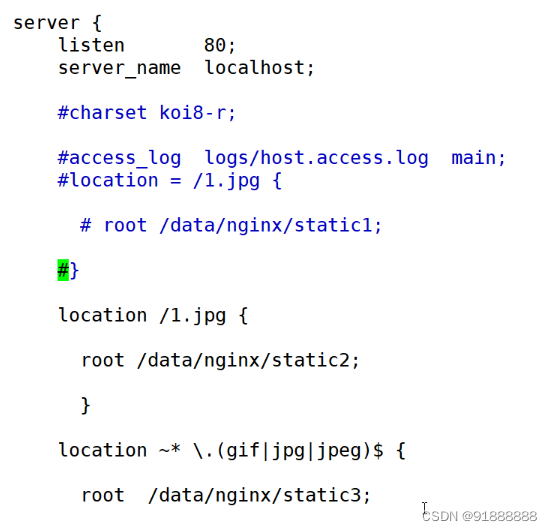
nginx的location的优先级和匹配方式 在http模块中有server,server模块中有location,location匹配的是uri 在一个server中,会有多个location,如何来确定匹配哪个location niginx的正则表达式 ^ 字符串的起始位置 $ 字符串的…...

深入了解Spring Boot Actuator
文章目录 引言什么是ActuatorActuator的底层技术和原理端点自动配置端点请求处理端点数据提供端点数据暴露 如何使用Actuator添加依赖访问端点自定义端点 实例演示结论 引言 Spring Boot Actuator是一个非常强大且广泛使用的模块,它为Spring Boot应用程序提供了一套…...

【SQL】NodeJs 连接 MySql 、MySql 常见语句
1.安装 mysql npm install mysql 2.引入MySql import mysql from mysql 3.连接MySql const connection mysql.createConnection({host: yourServerip,user: yourUsername,password: yourPassword,database: yourDatabase })connection.connect(err > {if (err) {console…...

SSH 基础学习使用
什么是SSH 1.SSH SSH(Secure Shell) 是较可靠,专为远程登录会话和其他网络服务提供安全性的协议,利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。 实际应用中,主要用于保证远程登录和远程通信的安全&#…...
JavaFX: 使用本地openjfx包
JavaFX: 使用本地openjfx包 1、注释配置2、下载openjfx包3、导入openjfx的jar包 1、注释配置 build.gradle配置注释: 2、下载openjfx包 下载javaFx地址:https://gluonhq.com/products/javafx/ 3、导入openjfx的jar包...
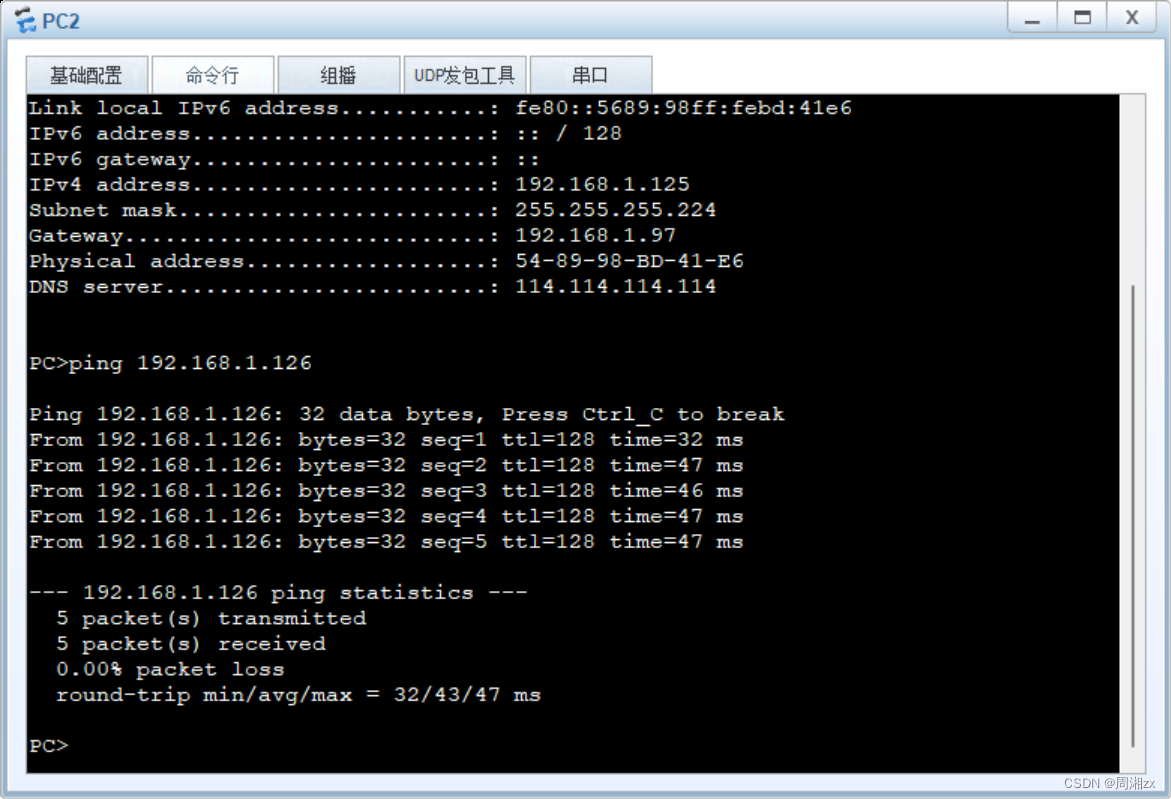
【HCIA】静态路由综合实验
实验要求: 1、R6为ISP,接口IP地址均为公有地址,该设备只能配置IP地址之后不能再对其进行任何配置 2、R1-R5为局域网,私有IP地址192.168.1.0/24,请合理分配 3、R1、R2、R4,各有两个环回IP地址;R5,R6各有一…...
Django框架集成Celery异步-【2】:django集成celery,拿来即用,可用操作django的orm等功能
一、项目结构和依赖 study_celery | --user |-- models.py |--views.py |--urls.py |--celery_task |--__init__.py |--async_task.py |-- celery.py | --check_task.py | --config.py | --scheduler_task.py | --study_celery | --settings.py | --manage.py 依赖:…...

获取本地缓存数据修改后,本地缓存中的值也修改问题
获取本地缓存数据修改后,本地缓存中的值也修改问题 JAVA缓存,获取数据后修改,缓存中的数值也会修改,解决方法是创建新的对象再修改值比如使用BeanUtils.copyProperties()方法。如果值是List,可以使用两种方法解决循环…...
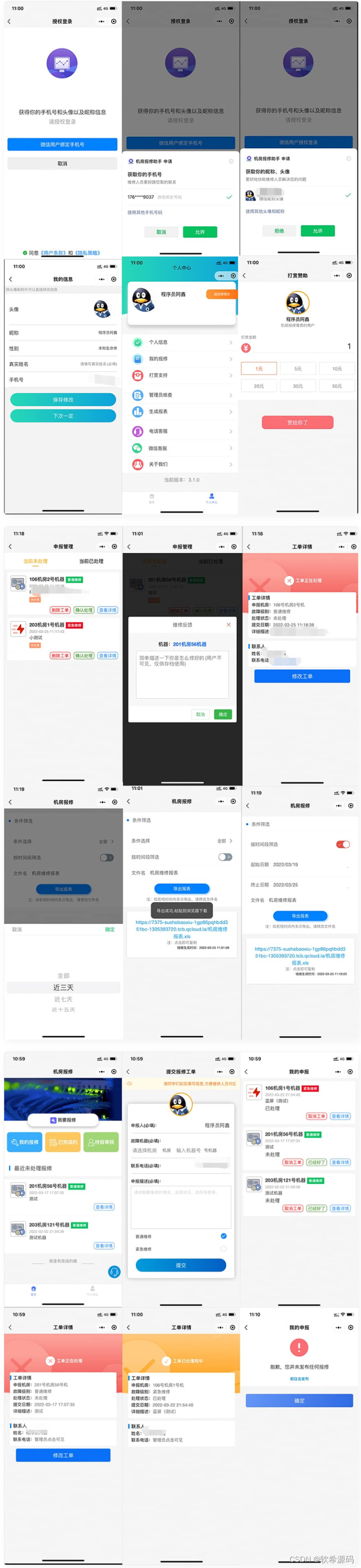
云开发校园宿舍/企业/部门/物业故障报修小程序源码
微信小程序云开发校园宿舍企业单位部门物业报修小程序源码,这是一款云开发校园宿舍报修助手工具系统微信小程序源码,适用于学校机房、公司设备、物业管理以及其他团队后勤部,系统为简单云开发,不需要服务器域名即可部署࿰…...

K邻近算法(KNN,K-nearest Neighbors Algorithm)
文章目录 前言应用场景欧几里得距离(欧氏距离)两类、单一属性(1D)两类、两种属性(2D)两类、两种以上属性(>3D) Examples in R再来一个补充一下什么是变量 什么是变量?…...
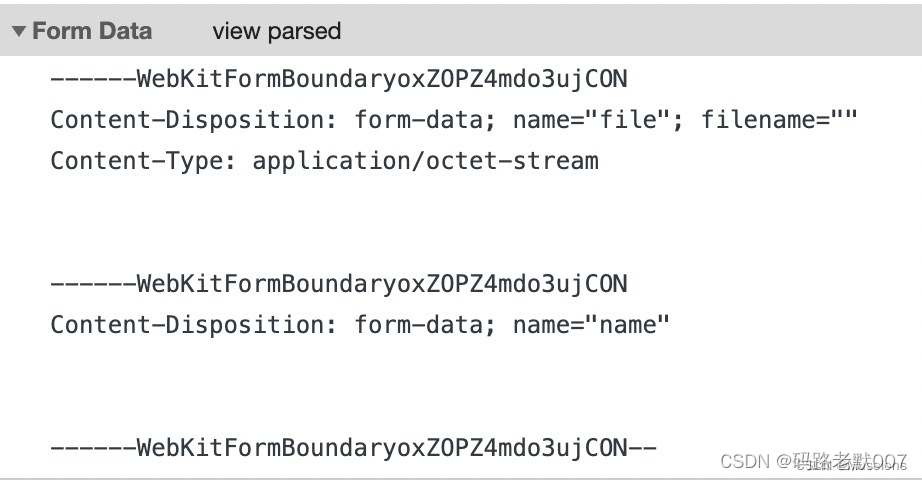
前端基础一:用Formdata对象来上传图片的原因
最近有人问:你是否能用json来传图片,其实应该这么理解就对了。 一、上传的数据体格式Content-Type 1.application/x-www-form-urlencoded 2.application/json 3.multipart/form-data 以上三种类型旨在告诉服务器需要接收的数据类型同事要…...

CSS的布局 Day03
一、显示模式: 网页中HTML的标签多种多样,具有不同的特征。而我们学习盒子模型、使用定位和弹性布局把内容分块,利用CSS布局使内容脱离文本流,使用定位或弹性布局让每块内容摆放在想摆放的位置,让网站页面布局更合理、…...
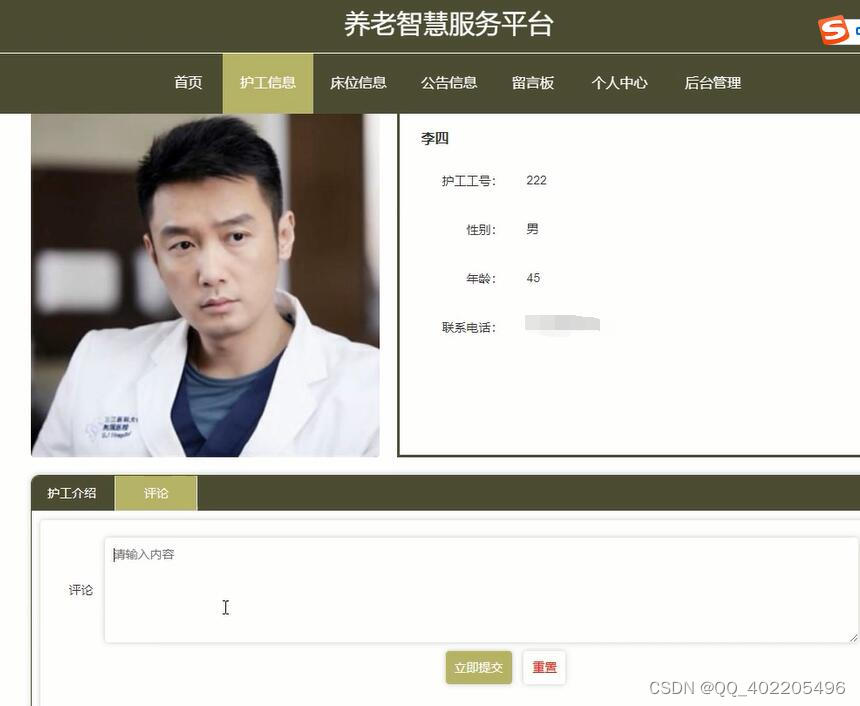
nodejs+vue+elementui养老院老年人服务系统er809
“养老智慧服务平台”是运用nodejs语言和vue框架,以MySQL数据库为基础而发出来的。为保证我国经济的持续性发展,必须要让互联网信息时代在我国日益壮大,蓬勃发展。伴随着信息社会的飞速发展,养老智慧服务平台所面临的问题也一个接…...

antd表格宽度超出屏幕,列宽自适应失效
最近遇到个诡异的问题,Table用的好好的,可就有一个页面的表格显示不全,超出浏览器宽,设定表格宽度也没用。 仔细分析了用户上传展示的数据后发现,不自动换行的超宽列都是url地址,一开始还以为是地址里有不…...
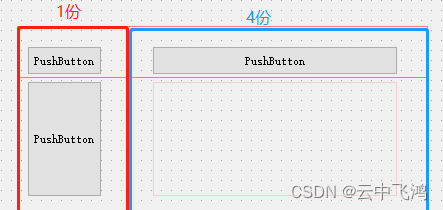
布局--QT Designer
一、在我们使用Qt做界面设计时,为了界面的整洁美观,往往需要对界面中的所有控件做一个有序的排列,以及设置各个控件之间的间距等等,为此Qt为界面设计提供了基本布局功能,使用基本布局可以使组件有规则地分布。 1.1 基…...

2024第八届杭州国际智慧城市博览会:建筑与智能,智慧与未来
浙江,中国最具活力的省份之一,将再次迎来一场盛大的智慧城市行业展会。2024年第八届浙江智慧城市博览会,由浙江省土木建筑学会发起主办,以“探索未来,智能引领”为主题,于2024年4月份在美丽的杭州国际博览中…...
Text-to-SQL小白入门(八)RLAIF论文:AI代替人类反馈的强化学习
学习RLAIF论文前,可以先学习一下基于人类反馈的强化学习RLHF,相关的微调方法(比如强化学习系列RLHF、RRHF、RLTF、RRTF)的论文、数据集、代码等汇总都可以参考GitHub项目:GitHub - eosphoros-ai/Awesome-Text2SQL: Cur…...

C语言联合体和枚举
C语言联合体和枚举 文章目录 C语言联合体和枚举一、联合体①联合体简介②联合体大小的计算 二、枚举 一、联合体 ①联合体简介 union Un {char c;int i; };像结构体一样,联合体也是由⼀个或者多个成员构成,这些成员可以不同的类型。但是编译器只为最大…...
Ubuntu 上传项目到 GitHub
一、前言 GitHub 作为时下最大的开源代码管理项目,广泛被工程和科研人员使用,本文主要介绍如何如何将自己的项目程序上传到 GitHub 上。 要上传本地项目到 GitHub 上,主要分为两步,第一步是 二、创建 SSH keys 首先登录 GitHu…...

开源音乐解锁工具:浏览器端全平台音频解密解决方案
开源音乐解锁工具:浏览器端全平台音频解密解决方案 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://…...

多功能 PEG 衍生物 Ergosterol-PEG-MAL,Ergosterol-PEG-Maleimide详解
试剂基本信息中文名称:麦角固醇-聚乙二醇-马来酰亚胺英文名称:Ergosterol-PEG-MAL,Ergosterol-PEG-Maleimide分子量:0.4k,0.6k,1k,2k,3.4k,5k,10k,…...

森利威尔SL3041B替换LM5018 100V降压3.3V5V12V恒压芯片
在工业、汽车及电池供电的电子系统中,高压降压转换器的选择往往需要在性能、可靠性与成本之间取得平衡。传统上,LM5018等进口芯片凭借其高输入电压范围和稳定的性能占据一定市场,但随着国内半导体技术的成熟,国产替代方案已具备与…...
)
华为OD机考双机位C卷 - 数字游戏 (Java)
# 数字游戏 2026华为OD机试双机位C卷 - 华为OD上机考试双机位C卷 华为OD机试双机位C卷真题目录(Java)点击查看: 【全网首发】2026华为OD机位C卷 机考真题题库含考点说明以及在线OJ(Java题解) 题目描述 小明玩一个游戏。 系统发1+n张牌,每张牌上有一个整数。 第一张给…...
)
不花一分钱!用闲置电脑搭建永久Mac远程控制台(VNC+cpolar固定TCP教程)
零成本打造24小时在线的Mac远程开发环境 你是否有一台闲置的Mac电脑放在角落积灰?或者需要随时随地访问家里的开发环境?将旧Mac改造成全天候在线的远程工作站,不仅能充分利用闲置资源,还能为移动办公提供极大便利。本文将手把手教…...

安防相机WDR功能实测:逆光场景下如何拍清车牌和人脸?
安防相机WDR功能实战解析:逆光场景下的车牌与人脸清晰拍摄指南 停车场出入口的监控画面中,一辆黑色轿车缓缓驶过,阳光从车尾方向直射镜头,车牌区域瞬间变成一片刺眼的白光——这是安防工程中最令人头疼的逆光场景。现代宽动态范围…...

批量为视频文件添加内嵌封面:两种模式的适用场景与配置
记录一下使用【批量添加MP4封面工具】的实践经验,重点讲两种封面模式的选择和配置。背景视频文件(MP4、MKV等)支持在文件内部嵌入封面图片(attached_pic)。嵌入后,在文件管理器的缩略图视图中会显示指定的封…...

XGantt:Vue3项目管理的终极可视化解决方案
XGantt:Vue3项目管理的终极可视化解决方案 【免费下载链接】gantt A powerful and flexible Gantt chart component library for developers, written in native JS Canvas. Supports TypeScript. 中文文档 项目地址: https://gitcode.com/gh_mirrors/gantt/gant…...

百度网盘提取码智能方案:从繁琐搜索到效率革命的技术跃迁
百度网盘提取码智能方案:从繁琐搜索到效率革命的技术跃迁 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 问题诊断:资源获取的现代困境 时间成本的指数级浪费 传统提取码查找流程涉及多平台切换、关键…...

RWKV7-1.5B-g1a开源模型部署:RWKV-7架构在国产GPU平台适配进展
RWKV7-1.5B-g1a开源模型部署:RWKV-7架构在国产GPU平台适配进展 1. 平台简介 rwkv7-1.5B-g1a 是基于新一代 RWKV-7 架构的开源多语言文本生成模型,特别针对国产GPU平台进行了优化适配。这个1.5B参数的轻量级模型非常适合以下场景: 基础问答&…...