【跟着ChatGPT学深度学习】ChatGPT教我文本分类
【跟着ChatGPT学深度学习】ChatGPT教我文本分类

ChatGPT既然无所不能,我为啥不干脆拜他为师,直接向他学习,岂不是妙哉。说干就干,我马上就让ChatGPT给我生成了一段文本分类的代码,不看不知道,一看吓一跳,比我写的还要好。
不知道ChatGPT是什么的可以看一下我的博文:ChatGPT介绍以及一些使用案例
1. 文本分类是什么
首先让它告诉我什么是文本分类:

它告诉我如下内容:
文本分类是指将一段文本分为不同的类别或标签的任务。在机器学习和自然语言处理中,文本分类通常指使用机器学习算法对文本进行分类,比如将电子邮件分类为垃圾邮件或正常邮件,将新闻文章分类为体育、政治、财经等不同的类别。文本分类技术在信息检索、情感分析、垃圾邮件过滤、推荐系统等应用中都有广泛的应用。
接着让它教我一下文本分类应该如何去学:

它告诉我:
学习文本分类可以按照以下步骤进行:
学习自然语言处理基础知识,包括分词、词性标注、句法分析、语义分析等。
学习文本分类的基本概念、任务流程、评价指标等,包括如何选择模型、如何进行模型训练和调优。
学习文本分类中常用的模型,包括朴素贝叶斯、支持向量机、深度学习模型(如卷积神经网络、循环神经网络、Transformer等)。
学习相关的工具和库,例如Python的scikit-learn、NLTK、gensim、PyTorch、TensorFlow等。
实践文本分类任务,可以使用公开的数据集进行实验,并尝试调整模型参数和超参数,以提高模型性能。
阅读文本分类相关的论文,了解最新研究进展和技术趋势,不断更新知识和技能。
除了上述学习步骤,还可以参加相关的课程、培训班、研讨会等活动,结交同行业者,共同探讨问题和解决方案。
2. 文本分类领域的知名学者
然后学习一下该领域有哪些知名的专家学者:

它告诉我如下信息:
文本分类领域的知名学者有很多,以下是一些代表性的学者:
Yann LeCun:他是深度学习领域的著名学者之一,曾经提出了卷积神经网络(CNN)的概念,也是自然语言处理领域的重要贡献者之一。
Yoshua Bengio:他是深度学习领域的权威人物之一,被誉为“深度学习之父”,他的研究重点在于神经网络、机器学习和自然语言处理等领域。
Tom M. Mitchell:他是机器学习和自然语言处理领域的知名学者之一,他的研究重点在于开发自动学习算法,特别是那些可以处理自然语言数据的算法。
Andrew Ng:他是机器学习和深度学习领域的知名学者,也是Coursera在线教育平台的创始人之一,他的研究领域包括自然语言处理、计算机视觉等。
Chris Manning:他是自然语言处理领域的知名学者,也是斯坦福大学自然语言处理组的主任,他的研究领域主要包括语言学、机器学习和深度学习等。
Dan Jurafsky:他是自然语言处理领域的知名学者,也是斯坦福大学自然语言处理组的教授之一,他的研究领域主要包括计算语言学、情感分析等。
Jianfeng Gao:他是微软亚洲研究院自然语言处理组的研究员,他的研究领域包括自然语言处理、机器翻译和对话系统等。他在深度学习和自然语言处理领域都有着很多重要的贡献。
以上学者的研究成果对文本分类领域的发展和进步做出了重要贡献。
接着我又让它推荐了一些文本分类领域的优秀论文:
 )
)
它告诉我:
以下是一些比较好的文本分类领域论文推荐:
“Attention Is All You Need” by Vaswani et al. (2017) - 提出了Transformer模型,该模型在文本分类等任务中表现出色。
“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” by Devlin et al. (2019) - 提出了基于Transformer的预训练语言模型BERT,该模型在文本分类等任务中取得了很好的效果。
“Convolutional Neural Networks for Sentence Classification” by Kim (2014) - 提出了使用卷积神经网络进行文本分类的方法,并在多个数据集上达到了当时最佳效果。
“ULMFiT: Universal Language Model Fine-tuning for Text Classification” by Howard and Ruder (2018) - 提出了使用预训练语言模型进行微调来进行文本分类的方法,并在多个数据集上取得了最佳效果。
“GloVe: Global Vectors for Word Representation” by Pennington et al. (2014) - 提出了一种用于获取单词向量表示的方法,该方法被广泛应用于文本分类等自然语言处理任务中。
“Deep Residual Learning for Image Recognition” by He et al. (2016) - 提出了残差网络,该网络在图像分类任务中取得了非常好的结果,而且已经被成功应用于文本分类任务中。
以上论文只是众多文本分类领域的优秀研究,希望能对你有所帮助。
3. 文本分类有哪些方法
然后再让它介绍一下文本分类的方法:

它告诉我如下内容:
文本分类有许多方法,下面是一些常用的方法:
词袋模型:将文本表示成单词的集合,单词的出现次数或者TF-IDF值用来表示文本。
N-gram模型:在词袋模型的基础上,将相邻的N个词组合起来,作为一个特征。
朴素贝叶斯:基于贝叶斯定理和特征条件独立假设的统计分类方法,常用于文本分类中的情感分析和垃圾邮件过滤等。
支持向量机(SVM):寻找一个最优的超平面,将不同类别的文本分隔开。
决策树:通过递归地将数据集分成小的子集,最终生成一个决策树,用于分类预测。
深度学习:通过神经网络学习输入文本与标签之间的映射关系,包括卷积神经网络、循环神经网络、Transformer等。
这些方法各有特点,具体应用时需要根据数据集的特征以及任务需求进行选择和调优。
4. 文本分类的步骤
再让它教我一下文本分类的一般步骤:

它告诉我:
实现文本分类的一般步骤如下:
数据预处理:对原始文本进行清洗、分词、去除停用词、转换成数字等操作,以便后续模型训练使用。
特征工程:根据预处理后的数据,从中提取特征。常用的特征提取方法包括词袋模型、TF-IDF模型、word2vec模型等。
模型选择和训练:选择合适的模型,并使用训练数据对模型进行训练。常用的模型包括朴素贝叶斯、支持向量机、决策树、神经网络等。
模型评估和调优:使用测试数据对训练好的模型进行评估,比较不同模型的性能并对模型进行调优。
预测:使用训练好的模型对新的文本进行分类。
近年来,基于深度学习的文本分类方法已经取得了很大的进展,常用的深度学习模型包括卷积神经网络(CNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)、Transformer等。与传统方法相比,深度学习方法不需要进行特征工程,可以自动从数据中学习出特征,因此在一些场景中表现更加优异。
5. 文本分类的研究前景
最后让它告诉我一下文本分类领域的研究前景如何:

它说:
文本分类是自然语言处理领域的一个重要问题,随着互联网技术的发展,大量的文本数据在不断产生,如何从这些文本中提取有价值的信息,成为了一个热门的研究领域。随着深度学习技术的不断发展和应用,文本分类取得了很大的进展。
未来,文本分类的研究仍将是一个热门领域,主要原因如下:
1.文本分类的应用领域广泛,例如智能客服、广告推荐、舆情分析等等,这些领域都需要高效、准确的文本分类算法。
2.深度学习技术的发展,尤其是预训练语言模型的兴起,使得文本分类的效果得到了很大的提升。未来,预训练模型的不断优化,将使得文本分类的效果更加准确和稳定。
3.随着自然语言处理领域的不断发展,文本分类将与其他自然语言处理任务(如命名实体识别、关系抽取等)结合起来,构建更加完整的自然语言处理系统,从而更好地服务于人类社会。
因此,可以预见,在未来的研究中,文本分类将继续得到广泛关注和研究。
6. 文本分类baseline构建
学到这,我对文本分类的知识点基本上已经掌握了,该去实战演练一番了,于是我让它教我如何写文本分类的代码了。
baseline1
首先让它构建了一个简单的baseline,使用transformer库和pytorch实现的代码。没过一分钟,它就给我生成了一串如下的代码,我运行了一次发现没有任何bug,这简直是强哥他妈给强哥开门,强到家了。
import torch
import torch.nn as nn
from transformers import RobertaTokenizer, RobertaModel, AdamW# 超参数
BATCH_SIZE = 16
EPOCHS = 3
LEARNING_RATE = 5e-5# 加载 RoBERTa 模型和分词器
tokenizer = RobertaTokenizer.from_pretrained('hfl/chinese-roberta-wwm-ext')
roberta_model = RobertaModel.from_pretrained('hfl/chinese-roberta-wwm-ext')# 定义模型
class TextClassifier(nn.Module):def __init__(self, num_classes):super(TextClassifier, self).__init__()self.roberta = roberta_modelself.dropout = nn.Dropout(0.1)self.linear = nn.Linear(768, num_classes)def forward(self, input_ids, attention_mask):_, pooled_output = self.roberta(input_ids=input_ids, attention_mask=attention_mask)pooled_output = self.dropout(pooled_output)logits = self.linear(pooled_output)return logits# 加载数据
# 假设数据已经准备好,分为训练集和验证集,每个样本包含文本和标签
train_data = [("这是一句文本", 1), ("这是另一句文本", 0), ...]
val_data = [("这是一句验证文本", 1), ("这是另一句验证文本", 0), ...]# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=BATCH_SIZE, shuffle=False)# 初始化模型、损失函数和优化器
model = TextClassifier(num_classes=2)
criterion = nn.CrossEntropyLoss()
optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)# 训练模型
for epoch in range(EPOCHS):# 训练model.train()for i, batch in enumerate(train_loader):input_ids, labels = batchattention_mask = (input_ids != 0).type(torch.long)logits = model(input_ids=input_ids, attention_mask=attention_mask)loss = criterion(logits, labels)loss.backward()optimizer.step()optimizer.zero_grad()# 验证model.eval()total_loss, total_correct = 0, 0with torch.no_grad():for batch in val_loader:input_ids, labels = batchattention_mask = (input_ids != 0).type(torch.long)logits = model(input_ids=input_ids, attention_mask=attention_mask)loss = criterion(logits, labels)total_loss += loss.item()preds = torch.argmax(logits, dim=1)total_correct += torch.sum(preds == labels).item()val_loss = total_loss / len(val_loader)val_acc = total_correct / len(val_data)print(f"Epoch {epoch+1}: val_loss={val_loss:.4f}, val_acc={val_acc:.4f}")
baseline2
我见状给它增加了一点难度,让它使用Trainer对象训练模型,也就差不多一分钟的功夫,它就完成了,而且甚至贴心地帮我固定了随机种子。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from transformers import RobertaTokenizer, RobertaModel, RobertaForSequenceClassification, Trainer, TrainingArguments
from sklearn.model_selection import train_test_split# 设置随机种子
torch.manual_seed(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False# 加载数据集
class TextDataset(Dataset):def __init__(self, texts, labels, tokenizer, max_len):self.texts = textsself.labels = labelsself.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.texts)def __getitem__(self, index):text = str(self.texts[index])label = self.labels[index]encoding = self.tokenizer.encode_plus(text,add_special_tokens=True,max_length=self.max_len,padding='max_length',return_attention_mask=True,return_tensors='pt')return {'text': text, 'input_ids': encoding['input_ids'].flatten(), 'attention_mask': encoding['attention_mask'].flatten(), 'labels': label}# 加载数据
texts = [...] # 文本数据
labels = [...] # 标签数据# 划分训练集和验证集
train_texts, val_texts, train_labels, val_labels = train_test_split(texts, labels, test_size=0.2, random_state=42)# 加载tokenizer
tokenizer = RobertaTokenizer.from_pretrained('hfl/chinese-roberta-wwm-ext')# 定义数据集和dataloader
train_dataset = TextDataset(train_texts, train_labels, tokenizer, max_len=128)
val_dataset = TextDataset(val_texts, val_labels, tokenizer, max_len=128)train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=False)# 定义模型
model = RobertaForSequenceClassification.from_pretrained('hfl/chinese-roberta-wwm-ext', num_labels=10)# 定义训练参数
training_args = TrainingArguments(output_dir='./results',num_train_epochs=5,per_device_train_batch_size=32,per_device_eval_batch_size=32,warmup_steps=500,weight_decay=0.01,logging_dir='./logs',logging_steps=10,evaluation_strategy='steps',eval_steps=50,save_total_limit=2,save_steps=500,learning_rate=2e-5,load_best_model_at_end=True
)# 定义训练器
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=val_dataset
)# 训练模型
trainer.train()
它甚至给我贴心地写了如下一行注释,这是生怕我看不懂它的代码呀:
需要注意的是,上述代码只包含了训练过程,如果需要在测试集上测试模型的性能,需要使用trainer类的evaluate方法进行评估。另外,也可以使用trainer类的predict方法对新的文本数据进行分类。
baseline3
事已至此,我不甘心,打算和它刚到底,让它生成一段使用TensorFlow的文本分类代码,而不出意料,我的师傅也很快帮我生成了一段如下所示的代码:
import tensorflow as tf
from transformers import TFRobertaModel, RobertaTokenizer# 读取数据集
train_data = [...] # 训练数据
val_data = [...] # 验证数据
test_data = [...] # 测试数据# 初始化tokenizer和模型
tokenizer = RobertaTokenizer.from_pretrained('hfl/chinese-roberta-wwm-ext')
model = TFRobertaModel.from_pretrained('hfl/chinese-roberta-wwm-ext')# 构建模型
input_ids = tf.keras.layers.Input(shape=(None,), dtype=tf.int32, name='input_ids')
attention_mask = tf.keras.layers.Input(shape=(None,), dtype=tf.int32, name='attention_mask')
embeddings = model.roberta(input_ids, attention_mask)[0]
pooled_output = tf.keras.layers.GlobalMaxPooling1D()(embeddings)
dropout = tf.keras.layers.Dropout(0.1)(pooled_output)
outputs = tf.keras.layers.Dense(10, activation='softmax')(dropout)
model = tf.keras.models.Model(inputs=[input_ids, attention_mask], outputs=outputs)# 编译模型
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-5)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(x={'input_ids': train_data[0], 'attention_mask': train_data[1]},y=train_data[2],validation_data=({'input_ids': val_data[0], 'attention_mask': val_data[1]}, val_data[2]),epochs=10,batch_size=16
)# 测试模型
test_loss, test_acc = model.evaluate({'input_ids': test_data[0], 'attention_mask': test_data[1]}, test_data[2])
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)# 预测模型
def predict(text):input_ids = tf.constant(tokenizer.encode(text))[None, :]attention_mask = tf.ones_like(input_ids)outputs = model.predict({'input_ids': input_ids, 'attention_mask': attention_mask})predicted_label = tf.argmax(outputs, axis=-1).numpy()[0]return predicted_label也贴心地给我们写了如下注释:
这个代码使用了TensorFlow的高级API Keras,首先读入训练数据、验证数据和测试数据,然后初始化roberta的tokenizer和模型。接着,我们通过Keras的函数式API构建模型,这里使用了roberta的预训练模型和全局最大池化层,最后添加了一个dropout层和一个全连接层,输出10个类别的概率分布。在编译模型时,我们使用Adam优化器和交叉熵损失函数,同时记录准确率。最后使用fit方法训练模型,并在测试集上进行评估。
在预测模型中,我们首先使用tokenizer将文本转换成token序列,并构建一个attention mask。然后使用训练好的模型进行预测,并返回预测的类别。
baseline4
我敬他是个“老师”,决定再难为他一下,让它帮我生成一个paddle实现的文本分类代码,它简直无所不能,马上就完成了代码。
import paddle
import paddle.nn as nn
import paddle.optimizer as optimizer
import paddle.io as io
from paddle.metric import Accuracy
import numpy as np
import os# 定义超参数
BATCH_SIZE = 32
LEARNING_RATE = 5e-5
EPOCHS = 3# 定义数据预处理函数
def preprocess(text, tokenizer, max_seq_len):# 将文本转换为输入特征tokens = tokenizer.tokenize(text)if len(tokens) > max_seq_len - 2:tokens = tokens[:(max_seq_len - 2)]input_tokens = ['[CLS]'] + tokens + ['[SEP]']segment_ids = [0] * len(input_tokens)input_ids = tokenizer.convert_tokens_to_ids(input_tokens)input_mask = [1] * len(input_ids)# 补齐序列长度padding_length = max_seq_len - len(input_ids)input_ids += [0] * padding_lengthinput_mask += [0] * padding_lengthsegment_ids += [0] * padding_lengthreturn input_ids, segment_ids, input_mask# 定义数据读取器
class TextClassificationDataset(io.Dataset):def __init__(self, data_list, tokenizer, max_seq_len):super(TextClassificationDataset, self).__init__()self.data = data_listself.tokenizer = tokenizerself.max_seq_len = max_seq_lendef __getitem__(self, index):text, label = self.data[index]input_ids, segment_ids, input_mask = preprocess(text, self.tokenizer, self.max_seq_len)return input_ids, segment_ids, input_mask, labeldef __len__(self):return len(self.data)# 定义模型结构
class TextClassificationModel(nn.Layer):def __init__(self, num_classes):super(TextClassificationModel, self).__init__()self.roberta = paddle.incubate.hapi.module.get_module_api("roberta")(pretrained="roberta-wwm-ext-chinese")self.dropout = nn.Dropout(p=0.1, axis='rows')self.classifier = nn.Linear(self.roberta.config["hidden_size"], num_classes)def forward(self, input_ids, segment_ids, input_mask):encoded_text, _ = self.roberta(input_ids, segment_ids, input_mask)encoded_text = self.dropout(encoded_text)logits = self.classifier(encoded_text)return logits# 定义训练函数
def train(model, optimizer, data_loader, criterion, metric):model.train()metric.reset()total_loss = 0.0for i, data in enumerate(data_loader()):input_ids, segment_ids, input_mask, label = datainput_ids = paddle.to_tensor(input_ids)segment_ids = paddle.to_tensor(segment_ids)input_mask = paddle.to_tensor(input_mask)label = paddle.to_tensor(label)logits = model(input_ids, segment_ids, input_mask)loss = criterion(logits, label)total_loss += loss.numpy()[0]loss.backward()optimizer.step()optimizer.clear_grad()metric.update(logits, label)if (i + 1) % 100 == 0:print("batch %d, loss %.5f, acc %.5f" % (i + 1, loss.numpy()[0],
由于使用paddle实现的代码太长,超过了ChatGPT能生成的最大长度,我试了几次最终只能出现不完整的代码,但是总体来说,还是很赞的。
7. 对baseline进行优化
作为一名热爱学习的好学生,我决定在想ChatGPT老师学更多的东西,于是我又让它告诉我如何对baseline进行优化了。我让它又增加了五折交叉验证的功能:
import torch
import numpy as np
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from sklearn.model_selection import StratifiedKFold# 加载数据集
X = # 读入文本数据
y = # 读入标签数据# 定义五折交叉验证器
kfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)# 开始五折交叉验证
for fold, (train_idx, val_idx) in enumerate(kfold.split(X, y)):# 将数据集分成训练集和验证集X_train, y_train = X[train_idx], y[train_idx]X_val, y_val = X[val_idx], y[val_idx]# 加载预训练模型和分词器model_name = 'hfl/chinese-roberta-wwm-ext'tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)# 对文本进行编码train_encodings = tokenizer(X_train.tolist(), truncation=True, padding=True)val_encodings = tokenizer(X_val.tolist(), truncation=True, padding=True)# 将编码后的文本数据和标签数据封装成Dataset对象class TextClassificationDataset(torch.utils.data.Dataset):def __init__(self, encodings, labels):self.encodings = encodingsself.labels = labelsdef __getitem__(self, idx):item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}item['labels'] = torch.tensor(self.labels[idx])return itemdef __len__(self):return len(self.labels)train_dataset = TextClassificationDataset(train_encodings, y_train)val_dataset = TextClassificationDataset(val_encodings, y_val)# 定义训练参数training_args = TrainingArguments(output_dir='./results',num_train_epochs=3,per_device_train_batch_size=16,per_device_eval_batch_size=64,warmup_steps=500,weight_decay=0.01,logging_dir='./logs',logging_steps=500,evaluation_strategy='steps',eval_steps=500,save_total_limit=3,save_steps=500)# 定义Trainer对象trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=val_dataset)# 训练模型trainer.train()# 评估模型trainer.evaluate()
本来还想让它在增加一点其他的功能,但是奈何它的最大长度的限制,我也就只能作罢。
8. 感想
是我自取其辱了(bushi)。
总的来说,关于知识点方面,该说不说,它并不能完全替代我的老师,对于这些知识点,只能说达到及格的水平(作为一个老师的标准),尤其是对知识不能做到实时更新,官方说它的知识只能到2021年,后续的知识它并不能做到自学,只能通过不断地喂入数据才能精进。
关于代码生成方面,虽然每次都能给我生成出来我想要的代码,但是每次生成的代码都是差异很大的,不能在代码的基础上增加新的功能,这个我觉得主要是它只是记住了代码的内容,并不能做到对代码的逻辑做到了如指掌,个人猜测是根据我们输入的关键词去匹配它知识库里面的代码,然后选一个匹配度很高的代码返回,如果能搜索到的话,如果搜索不到就需要对部分代码进行拼接操作了。
相关文章:
【跟着ChatGPT学深度学习】ChatGPT教我文本分类
【跟着ChatGPT学深度学习】ChatGPT教我文本分类 ChatGPT既然无所不能,我为啥不干脆拜他为师,直接向他学习,岂不是妙哉。说干就干,我马上就让ChatGPT给我生成了一段文本分类的代码,不看不知道,一看吓一跳&am…...

IM即时通讯架构技术:可靠性、有序性、弱网优化等
消息的可靠性是IM系统的典型技术指标,对于用户来说,消息能不能被可靠送达(不丢消息),是使用这套IM的信任前提。 换句话说,如果这套IM系统不能保证不丢消息,那相当于发送的每一条消息都有被丢失的…...

【算法】三道算法题两道难度中等一道困难
算法目录只出现一次的数字(中等难度)java解答参考二叉树的层序遍历(难度中等)java 解答参考给表达式添加运算符(比较困难)java解答参考大家好,我是小冷。 上一篇是算法题目 接下来继续看下算法题…...
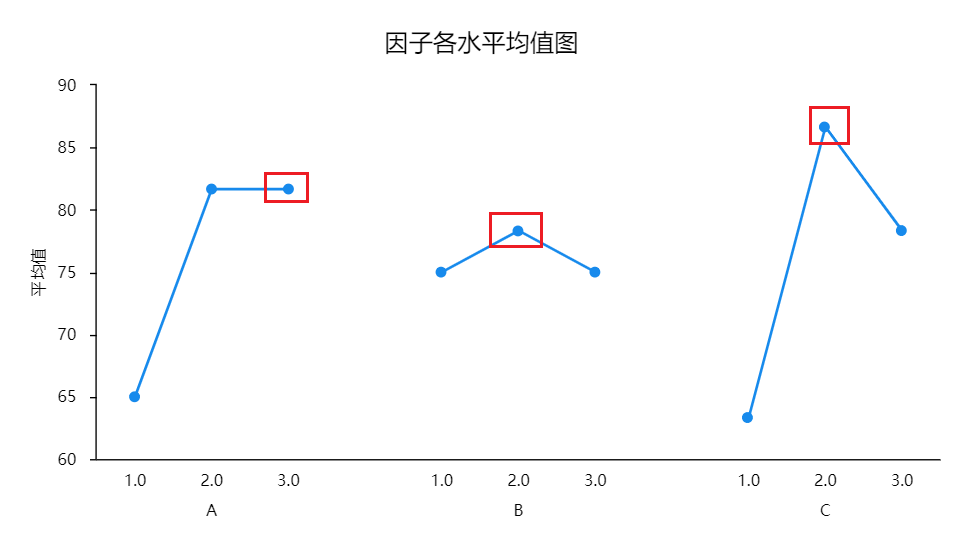
正交实验与极差分析
正交试验极差分析流程如下图: 正交试验说明 正交试验是研究多因素试验的设计方法。对于多因素、多水平的实验要求,如果每个因素的每个水平都要进行试验,这样就会耗费大量的人力和时间,正交试验可以选择出具有代表性的少数试验进行…...
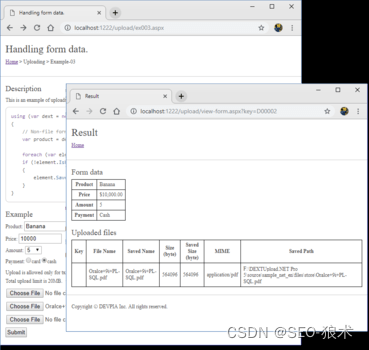
DEXTUpload .NET增强的上传速度和可靠性
DEXTUpload .NET增强的上传速度和可靠性 DEXTUpload.NET Pro托管在Windows操作系统上的Internet Information Server(IIS)上,服务器端组件基于HTTP协议,支持从web浏览器到web服务器的文件上载。它也可以在ASP.NET服务器应用程序平台开发的任何网站上使用…...
)
SkyWalking 将方法加入追踪链路(@Trace)
SkyWalking8 自定义链路追踪@Trace 自定义链路,需要依赖skywalking官方提供的apm-toolkit-trace包.在pom.xml的dependencies中添加如下依赖: <dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-trace</artifactId>&…...
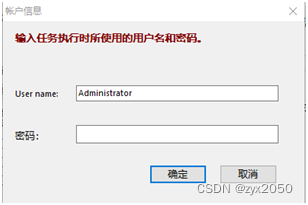
MySQL Administrator定时备份MySQL数据库
1、下载并安装软件mysql-gui-tools-5.0-r17-win32.exe 2、将汉化包zh_CN文件夹拷贝到软件安装目录 3、菜单中打开MySql Adminstrator,见下图,初次打开无服务实例。 点击已存储连接右侧按钮①,打开下图对话框。点击“新连接”按钮ÿ…...

Kubernetes入门教程 --- 使用二进制安装
Kubernetes入门教程 --- 使用二进制安装1. Introduction1.1 架构图1.2 关键字介绍1.3 简述2. 使用Kubeadm Install2.1 申请三个虚拟环境2.2 准备安装环境2.3 配置yum源2.4 安装Docker2.4.1 配置docker加速器并修改成k8s驱动2.5 时间同步2.6 安装组件3. 基础知识3.1 Pod3.2 控制…...

深度学习模型压缩方法概述
一,模型压缩技术概述 1.1,模型压缩问题定义 因为嵌入式设备的算力和内存有限,因此深度学习模型需要经过模型压缩后,方才能部署到嵌入式设备上。 模型压缩问题的定义可以从 3 角度出发: 模型压缩的收益: 计算: 减少浮点运算量(FLOPs),降低延迟(Latency)存储: 减少内…...

《NFL橄榄球》:坦帕湾海盗·橄榄1号位
坦帕湾海盗(英语:Tampa Bay Buccaneers)是一支位于佛罗里达州的坦帕湾职业美式橄榄球球队。他们是全国橄榄球联盟的南区其中一支球队。在1976年,与西雅图海鹰成为NFL的球队。球队在最初的两个球季连败26场,在二十世纪七…...
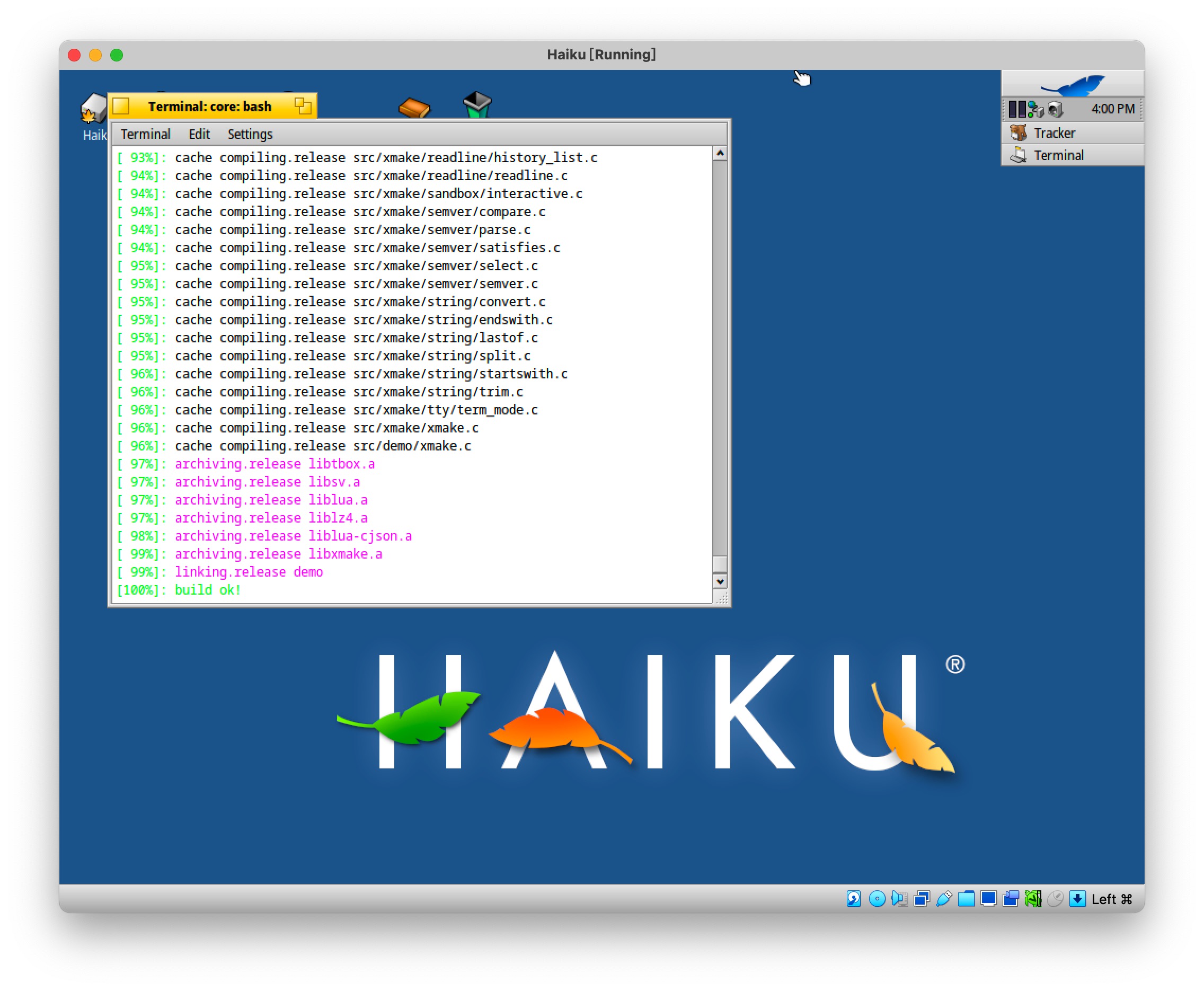
Xmake v2.7.7 发布,支持 Haiku 平台,改进 API 检测和 C++ Modules 支持
layout: post.cn title: “Xmake v2.7.7 发布,支持 Haiku 平台,改进 API 检测和 C Modules 支持” tags: xmake lua C/C package modules haiku cmodules categories: xmake Xmake 是一个基于 Lua 的轻量级跨平台构建工具。 它非常的轻量,没…...

苹果ios签名证书的生成方法
在使用hbuilderx打包uniapp或html5应用的时候,假如是打包ios应用,是需要ios签名证书,和证书profile文件的,这个证书要求是p12格式的证书,profile文件又叫描述文件。 这两个文件,需要在苹果开发者中心生成&…...

c++开发配置常用网站记录
1.ubuntu 镜像源: (1) 清华源:https://mirror.tuna.tsinghua.edu.cn/help/ubuntu/ (2) 阿里源:https://developer.aliyun.com/mirror/ubuntu?spma2c6h.13651102.0.0.3e221b11VuM27s 包含了ubuntu各个版本的source源 2.ubuntu iso镜像下载…...
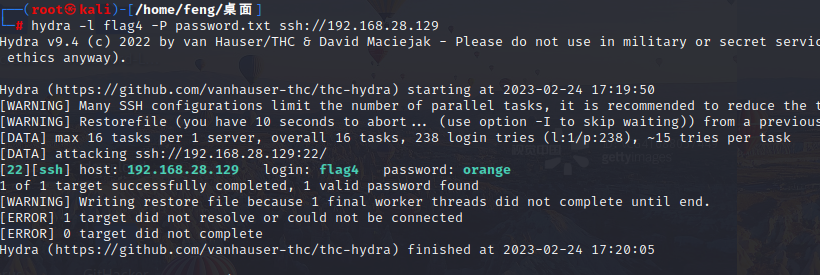
DC-1 靶场学习
以前写过了,有一些忘了,快速的重温一遍。 DC一共九个靶场,目标一天一个。 文章目录环境配置:信息搜集:漏洞复现:FLAG获取环境配置: 最简单的办法莫过于将kali和DC-1同属为一个nat的网络下。 信…...

oracle 不使用索引深入解析
首先,我们要确定数据库运行在何种优化模式下,相应的参数是:optimizer_mode。缺省的设置应是"choose",即如果对已分析的表查询的话选择CBO,否则选择RBO。如果该参数设为“rule”,则不论表是否分析…...

什么是自助式BI工具,有没有推荐
为什么需要自助式BI? 传统的BI采用的是“业务提报表需求,IT进行开发”的模式。决策管理者和业务人员提出用报表等来展示经营管理数据的需求;接着IT响应需求,进行需求沟通、数据处理加工、报表开发等主体工作;最后决策管…...

如何高效管理自己的时间,可以从这几个方向着手
如果你是上班族,天选打工人,你的绝大多数时间都属于老板,能够自己支配的时间其实并不多,所以你可能察觉不到时间管理的重要性。但如果你是自由职业者或者创业者,想要做出点成绩,那你就需要做好时间管理&…...
)
【PAT甲级题解记录】1014 Waiting in Line (30 分)
【PAT甲级题解记录】1014 Waiting in Line (30 分) 前言 Problem:1014 Waiting in Line (30 分) Tags:模拟 双端队列 Difficulty:剧情模式 想流点汗 想流点血 死而无憾 Address:1014 Waiting in Line (30 分) 问题描述 银行有N个…...

web接入大华摄像头实时视频
目录 一、FFmpeg下载及配置 二、nginx下载及配置 三、摄像rtsp取流 四、ffmpeg推流 五、html前端工作 一、FFmpeg下载及配置 地址:Download FFmpeg 下载并解压FFmpeg文件夹,配置环境变量:在“Path”变量原有变量值内容…...
Git代码冲突-不同分支之间的代码冲突
1、解决思路在团队开发中,提交代码到Git仓库时经常会遇到代码冲突的问题。- 原因:多人对相同的文件进行了编辑,造成代码存在差异化- 解决方案:1. 使用工具或git命令对比不同分支代码的差异化2. 把不同分支中有效代码进行保留&…...

python文化旅游服务系统 小程序系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能技术栈项目亮点应用场景项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目概述 Python文化旅游服…...

通过curl命令快速测试Taotoken上不同大模型的响应效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken上不同大模型的响应效果 对于开发者而言,在集成大模型能力时,快速验证接口连…...

如何制作微信小程序店铺?无技术商家实操全流程避坑指南
大家好,我是右以云SaaS平台的小右。今天就把如何制作微信小程序店铺的全流程讲透,没技术基础也能自己落地,还帮你们避掉我见过的大部分坑。很多老板想做微信小程序店铺,第一反应是找外包,报价动辄大几千甚至几万&#…...

SQL 语句:从产生、发展到内容全景
引言:数据世界的通用语言 SQL(Structured Query Language,结构化查询语言)是当今数据领域最核心、最通用的语言。无论是数据分析师、后端工程师还是数据科学家,都离不开 SQL。它就像数据世界的“普通话”,连…...

Supervisely完整指南:5步打造AI视觉标注神器
Supervisely完整指南:5步打造AI视觉标注神器 【免费下载链接】supervisely Supervisely SDK for Python - convenient way to automate, customize and extend Supervisely Platform for your computer vision task 项目地址: https://gitcode.com/gh_mirrors/su…...

【Typescript】13-tsconfig与工程化实践
tsconfig 与工程化实践 很多人学 TypeScript 时,会把注意力几乎全部放在语法上:泛型会不会写、infer 看不看得懂、工具类型会不会用。可真正在工程里决定 TypeScript 上限的,往往不是这些,而是 tsconfig.json。因为它决定了编译器…...

AI测试工具百花齐放,选型之前先搞懂这4个核心问题
在软件测试领域,AI 测试工具正以前所未有的速度涌现。从智能用例生成、缺陷预测到自愈型自动化测试,厂商们构建起一个眼花缭乱的技术矩阵。然而,当团队真正面临选型决策时,却发现“百花齐放”往往意味着“乱花渐欲迷人眼”。许多团…...

抓包实战:用Wireshark深度解析ENSP中VxLAN静态隧道的封装过程
抓包实战:用Wireshark深度解析ENSP中VxLAN静态隧道的封装过程 当你第一次在Wireshark中看到VxLAN报文时,是否曾被那层层嵌套的协议头搞得一头雾水?本文将带你亲历一次完整的VxLAN报文"解剖"过程,通过ENSP实验环境中的真…...

NotebookLM显著性判断失效真相:92%用户忽略的3个统计学前提及实时校验脚本
更多请点击: https://codechina.net 第一章:NotebookLM显著性判断失效的典型现象与影响评估 NotebookLM 在处理多源异构文档时,其内置的“显著性判断”模块(Significance Scorer)常因语义稀疏、上下文截断或引用锚点偏…...

SPT-AKI存档编辑器:5分钟掌握离线塔科夫角色定制终极方案
SPT-AKI存档编辑器:5分钟掌握离线塔科夫角色定制终极方案 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirror…...