数据结构 - 6(优先级队列(堆)13000字详解)
一:堆
1.1 堆的基本概念
堆分为两种:大堆和小堆。它们之间的区别在于元素在堆中的排列顺序和访问方式。
- 大堆(Max Heap):
在大堆中,父节点的值比它的子节点的值要大。也就是说,堆的根节点是堆中最大的元素。大堆被用于实现优先级队列,其中根节点的元素始终是队列中最大的元素。大堆可以通过以下特点来进行维护:
- 对于每个父节点,它的值大于或等于其子节点的值。
- 小堆(Min Heap):
在小堆中,父节点的值比它的子节点的值要小。也就是说,堆的根节点是堆中最小的元素。小堆常用于实现优先级队列,其中根节点的元素始终是队列中最小的元素。小堆可以通过以下特点来进行维护:
- 对于每个父节点,它的值小于或等于其子节点的值。
以下是一个示例图示,展示了一个包含7个元素的大堆和小堆的结构:
大堆:90/ \75 30/ \ / \20 15 10 7小堆:7/ \10 30/ \ / \20 15 75 90
这些图示说明了大堆和小堆的不同排列顺序。在大堆中,父节点的值大于子节点的值,而在小堆中,父节点的值小于子节点的值。
注意:堆总是一颗完全二叉树
1.2堆的存储方式
从堆的概念可知,堆是一棵完全二叉树,因此可以层序的规则采用顺序的方式来高效存储,
注意:对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。
将元素存储到数组中后,可以根据二叉树章节的性质5对树进行还原。假设i为节点在数组中的下标,则有:
- 如果i为0,则i表示的节点为根节点
- 如果2 * i + 1 小于节点个数,则节点i的左孩子下标为2 * i + 1,否则没有左孩子
- 如果2 * i + 2 小于节点个数,则节点i的右孩子下标为2 * i + 2,否则没有右孩子
1.3 堆的下沉
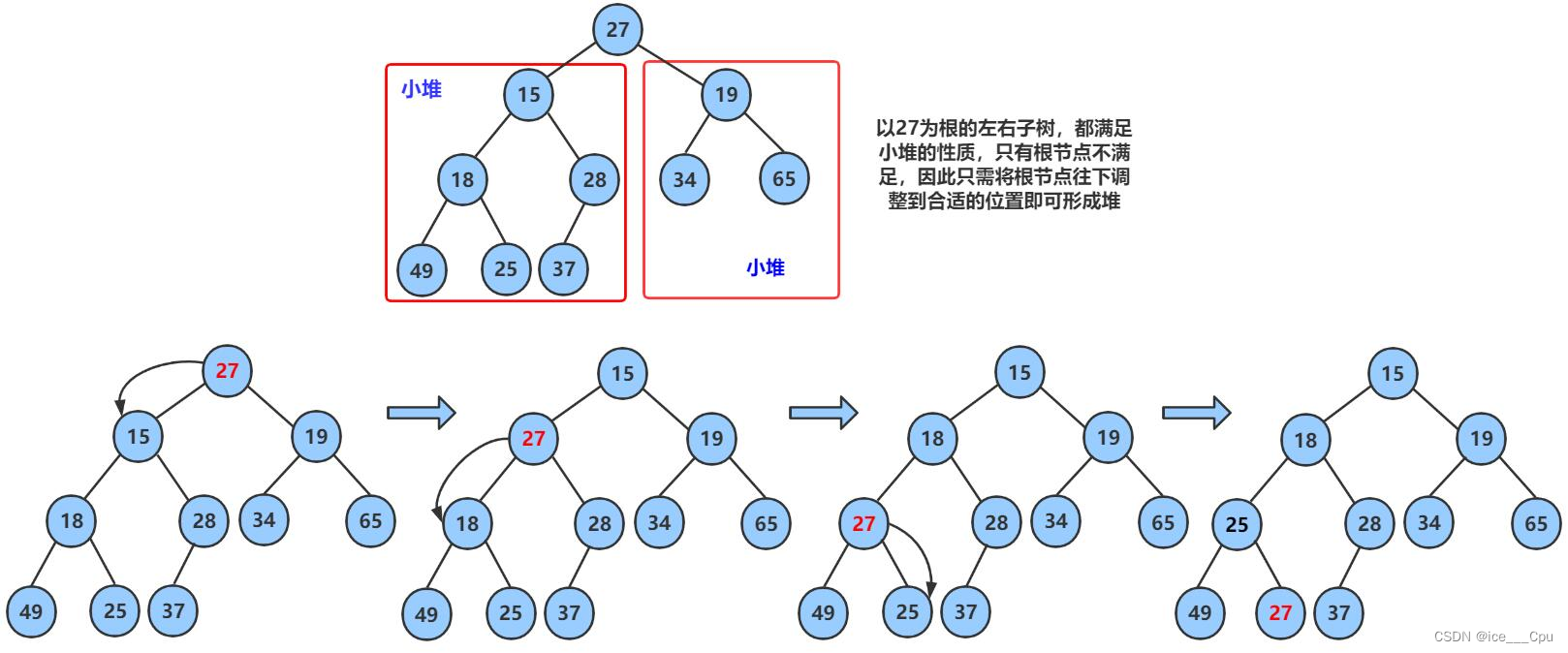
对于集合{ 27,15,19,18,28,34,65,49,25,37 }中的数据,如果将其创建成小堆呢?
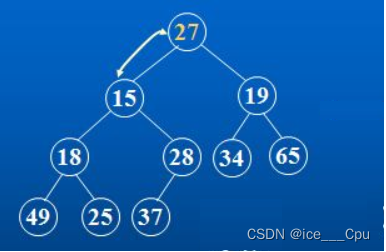
仔细观察上图后发现:根节点的左右子树已经完全满足堆的性质,因此只需将根节点向下调整好即可。
下面是代码实现:
// shiftDown方法用来实现下沉操作
// array参数是待构建小堆的数组
// parent参数是当前需要下沉的节点的索引
public void shiftDown(int[] array, int parent) {int length = array.length;int child = 2 * parent + 1; // 左子节点索引while (child < length) {// 找到左右孩子中较小的孩子if (child + 1 < length && array[child] > array[child + 1]) {child++; // 如果右子节点存在并且小于左子节点的值,则将child指向右子节点}// 如果当前节点小于或等于左右子节点中较小的节点,说明已经符合小堆要求if (array[parent] <= array[child]) {break;}// 否则,交换当前节点和较小子节点的值,接着需要继续向下调整int temp = array[parent];array[parent] = array[child];array[child] = temp;parent = child;child = 2 * parent + 1;}
}这段代码实现了堆排序中的下沉操作(也称为向下调整或堆化)。下沉操作用于维护小堆的性质,确保父节点永远小于或等于其子节点。
时间复杂度分析:
最坏的情况即图示的情况,从根一路比较到叶子,比较的次数为完全二叉树的高度,即时间复杂度为O(log n)
1.4 堆的创建
那对于普通的序列{ 1,5,3,8,7,6 },即根节点的左右子树不满足堆的特性,又该如何调整呢?
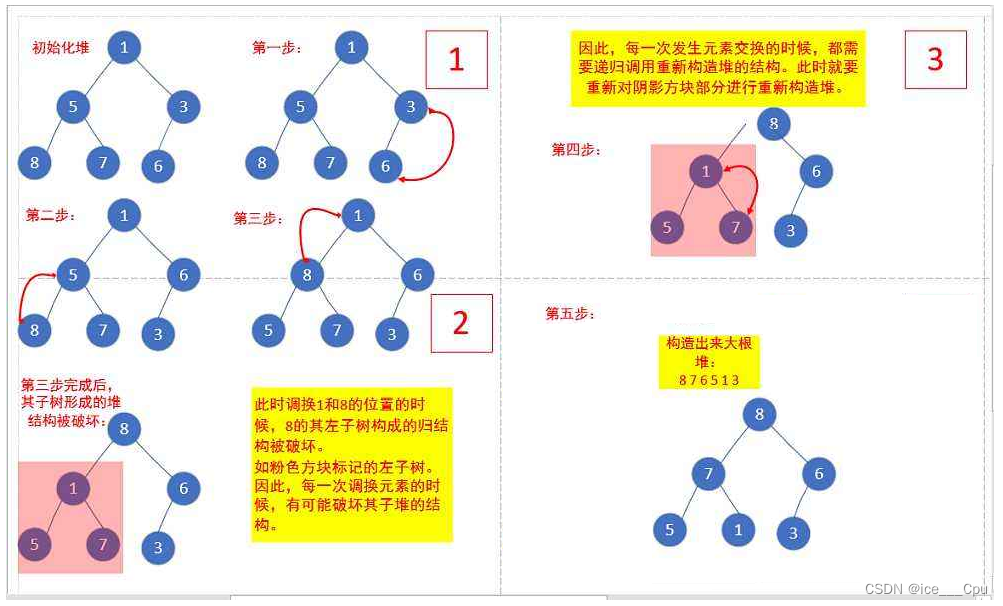
参考代码:
public static void createHeap(int[] array) {// 找倒数第一个非叶子节点,从该节点位置开始往前一直到根节点,遇到一个节点,应用向下调整int root = ((array.length-2)>>1);for (; root >= 0; root--) {shiftDown(array, root);}
}
1.5建堆的时间复杂度
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果):
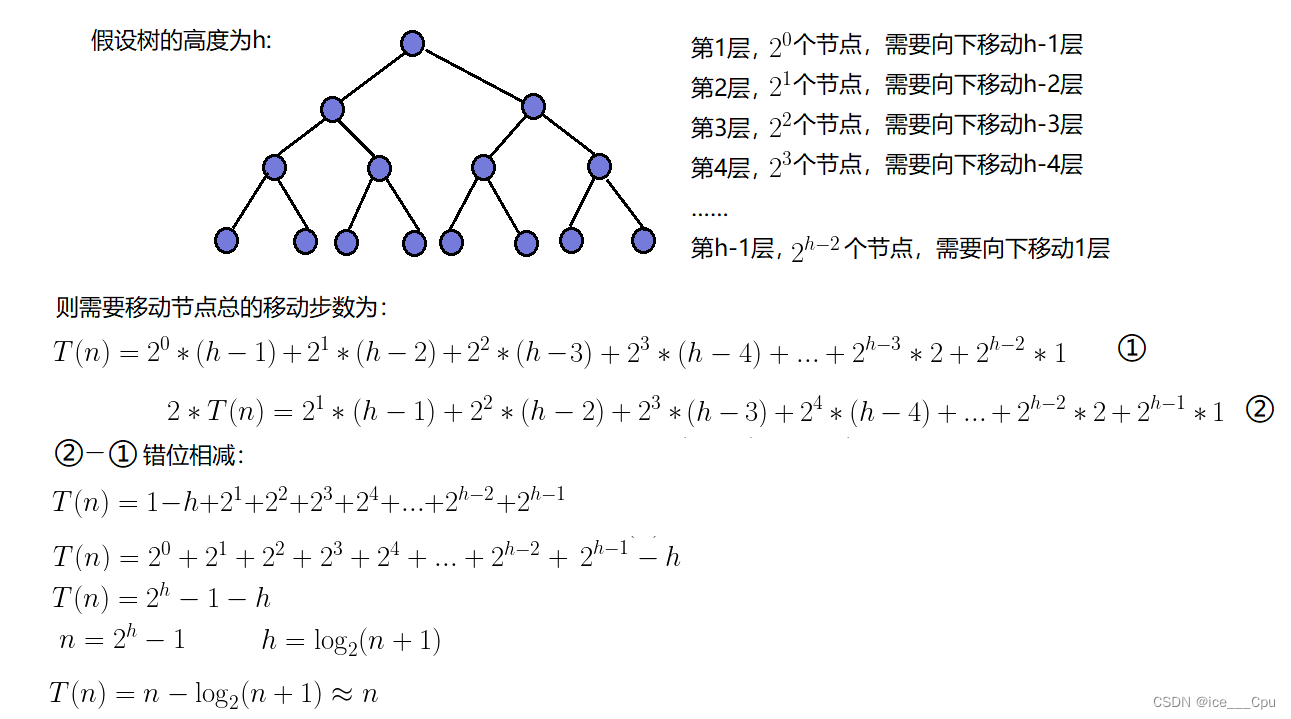
因此:建堆的时间复杂度为O(N)。
1.6堆的插入和删除
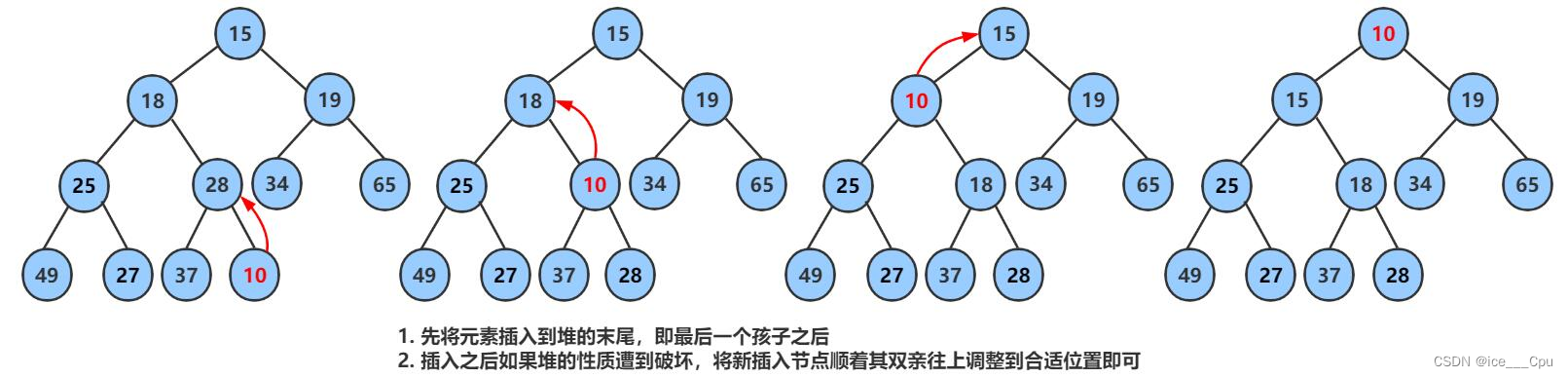
1.6.1 堆的插入
堆的插入总共需要两个步骤:
- 先将元素放入到底层空间中(注意:空间不够时需要扩容)
- 将最后新插入的节点向上调整,直到满足堆的性质
下面是堆的删除操作的代码实现,包含详细注释:
public void shiftUp(int child) {// 找到child的双亲int parent = (child - 1) / 2;while (child > 0) {// 如果双亲比孩子大,parent满足堆的性质,调整结束if (array[parent] > array[child]) {break;}else{// 将双亲与孩子节点进行交换int t = array[parent];array[parent] = array[child];array[child] = t;// 小的元素向下移动,可能到值子树不满足对的性质,因此需要继续向上调增child = parent;parent = (child - 1) / 1;}}
}
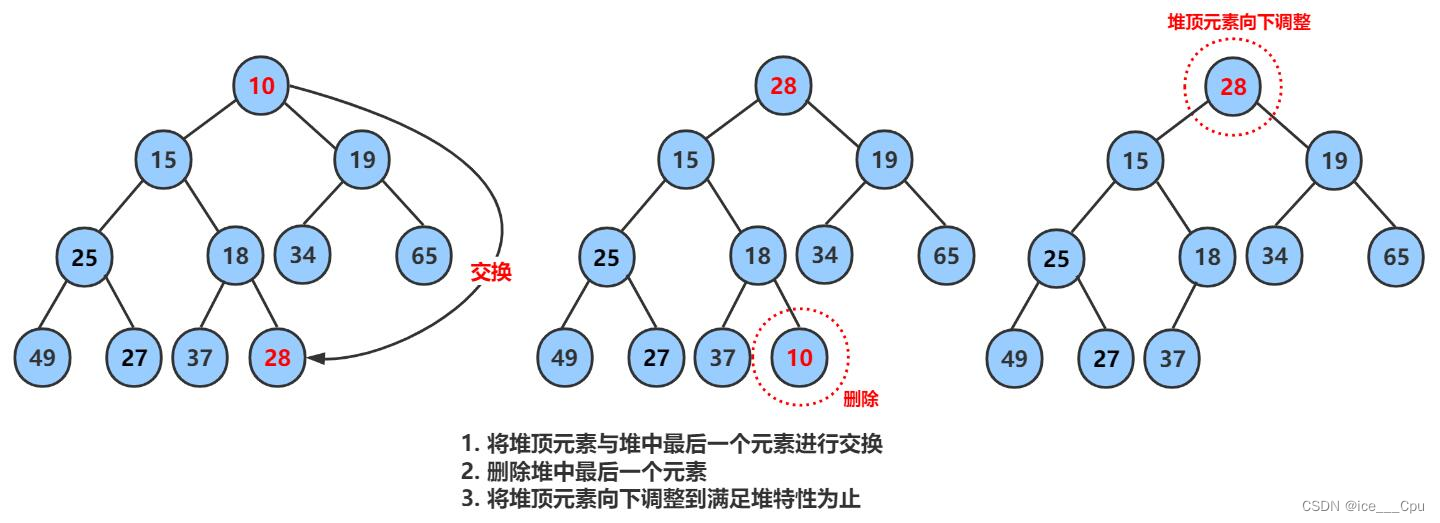
1.6.2 堆的删除
注意:堆的删除一定删除的是堆顶元素。具体如下:
- 将堆顶元素对堆中最后一个元素交换
- 将堆中有效数据个数减少一个
- 对堆顶元素进行向下调整
下面是堆的删除操作的代码实现,包含详细注释:
public void deleteTop() {// 将堆顶元素与堆中最后一个元素交换array[0] = array[size - 1];// 堆中有效数据个数减少一个size--;// 对堆顶元素进行向下调整int parent = 0; // 当前节点的索引// 持续向下调整,直到满足堆的性质while (true) {// 左孩子节点的索引int leftChild = parent * 2 + 1;// 右孩子节点的索引int rightChild = leftChild + 1;// 父节点与左右孩子节点中值最大的节点进行交换int maxChild = parent; // 最大值节点的索引// 如果左孩子存在且大于父节点,则更新最大值节点if (leftChild < size && array[leftChild] > array[maxChild]) {maxChild = leftChild;}// 如果右孩子存在且大于当前最大值节点,则更新最大值节点if (rightChild < size && array[rightChild] > array[maxChild]) {maxChild = rightChild;}// 如果最大值节点是当前节点本身,则调整结束 if (maxChild == parent) {break;} else {// 交换最大节点与父节点int temp = array[parent];array[parent] = array[maxChild];array[maxChild] = temp;// 更新当前节点为最大值节点parent = maxChild;}}
}
二:优先级队列
2.1 概念
前面介绍过队列,队列是一种先进先出(FIFO)的数据结构,但有些情况下,操作的数据可能带有优先级,一般出队列时,可能需要优先级高的元素先出队列,该中场景下,使用队列显然不合适,比如:在手机上玩游戏的时候,如果有来电,那么系统应该优先处理打进来的电话;初中那会班主任排座位时可能会让成绩好的同学先挑座位。
在这种情况下,数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)。
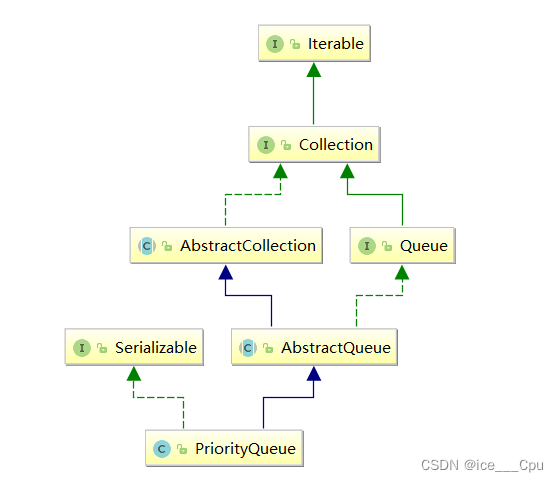
2.2堆的使用
Java集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列,PriorityQueue是线程不安全的,PriorityBlockingQueue是线程安全的,本文主要介绍PriorityQueue。
关于PriorityQueue的使用要注意:
- 使用时必须导入PriorityQueue所在的包,即:
- PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出
ClassCastException异常 - 不能插入null对象,否则会抛出NullPointerException
- 没有容量限制,可以插入任意多个元素,其内部可以自动扩容
- 插入和删除元素的时间复杂度为
- PriorityQueue底层使用了堆数据结构
- PriorityQueue默认情况下是小堆—即每次获取到的元素都是最小的元素
PriorityQueue中常见的构造方法:
| 构造器 | 功能介绍 |
|---|---|
| PriorityQueue() | 创建一个空的优先级队列,默认容量是11 |
| PriorityQueue(int initialCapacity) | 创建一个初始容量为initialCapacity的优先级队列,注意: initialCapacity不能小于1,否则会抛IllegalArgumentException异 常 |
| PriorityQueue(Collection<? extends E> c) | 用一个集合来创建优先级队列 |
下面是使用示例:
static void TestPriorityQueue(){// 创建一个空的优先级队列,底层默认容量是11PriorityQueue<Integer> q1 = new PriorityQueue<>();// 创建一个空的优先级队列,底层的容量为initialCapacityPriorityQueue<Integer> q2 = new PriorityQueue<>(100);ArrayList<Integer> list = new ArrayList<>();list.add(4);list.add(3);list.add(2);list.add(1);// 用ArrayList对象来构造一个优先级队列的对象// q3中已经包含了三个元素PriorityQueue<Integer> q3 = new PriorityQueue<>(list);System.out.println(q3.size());System.out.println(q3.peek());}
注意:默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器
// 用户自己定义的比较器:直接实现Comparator接口,然后重写该接口中的compare方法即可
class IntCmp implements Comparator<Integer>{@Overridepublic int compare(Integer o1, Integer o2) {return o2-o1;}
}
public class TestPriorityQueue {public static void main(String[] args) {PriorityQueue<Integer> p = new PriorityQueue<>(new IntCmp());p.offer(4);p.offer(3);p.offer(2);p.offer(1);p.offer(5);System.out.println(p.peek());}
}
下面是 PriorityQueue中常用的方法:
| 函数名 | 功能介绍 |
|---|---|
| booleanoffer(E e) | 插入元素e,插入成功返回true,如果e对象为空,抛出NullPointerException异常,时间复杂度 ,注意:空间不够时候会进行扩容 |
| E peek() | 获取优先级最高的元素,如果优先级队列为空,返回null |
| E poll() | 移除优先级最高的元素并返回,如果优先级队列为空,返回null |
| int size() | 获取有效元素的个数 |
| void clear() | 清空 |
| boolean isEmpty() | 检测优先级队列是否为空,空返回true |
下面是这些方法的使用示例:
import java.util.PriorityQueue;public class Main {public static void main(String[] args) {PriorityQueue<Integer> heap = new PriorityQueue<>();// 测试插入元素heap.offer(10); // 返回 trueheap.offer(5); // 返回 trueheap.offer(15); // 返回 trueheap.offer(2); // 返回 true// 测试获取优先级最高的元素// 结果为 2System.out.println(heap.peek());// 测试移除优先级最高的元素// 结果为 2System.out.println(heap.poll());// 测试获取有效元素的个数// 结果为 3System.out.println(heap.size());// 测试清空优先级队列heap.clear();// 测试检测优先级队列是否为空// 结果为 trueSystem.out.println(heap.isEmpty());}
}以下是JDK 1.8中,PriorityQueue的扩容方式:
优先级队列的扩容说明:
- 如果容量小于64时,是按照oldCapacity的2倍方式扩容的
- 如果容量大于等于64,是按照oldCapacity的1.5倍方式扩容的
- 如果容量超过MAX_ARRAY_SIZE,按照MAX_ARRAY_SIZE来进行扩容
MAX_ARRAY_SIZE等于Integer.MAX_VALUE - 8,Integer.MAX_VALUE - 8。等于 2,147,483,639。
2.3 用堆模拟实现优先级队列
我们通过堆可以模拟实现优先级队列,因为堆具有以下特性:
- 大堆或小堆:堆可以是大堆或小堆,其中大堆意味着父节点的值大于或等于其子节点的值,而小堆意味着父节点的值小于或等于其子节点的值。
- 优先级定义:我们可以将堆中的元素与优先级相关联。较高的优先级可以根据堆类型来确定是最大值还是最小值。
优先性在优先级队列中体现在以下方面:
- 插入元素:由于堆的性质,插入的元素会按照其优先级找到正确的位置插入。较高优先级的元素会被放置在堆的顶部(根节点)。
- 删除元素:从堆中删除元素时,会删除具有最高(最大堆)或最低(最小堆)优先级的元素。这样,每次删除的元素都是具有最高/最低优先级的元素。
通过以上方式,可以使用堆来实现优先级队列,确保具有更高优先级的元素优先被处理或删除。
下面我们基于堆来模拟实现一个优先级队列:
public class MyPriorityQueue {// 演示作用,不再考虑扩容部分的代码private int[] array = new int[100]; // 使用数组来存储元素private int size = 0; // 当前队列的大小// 向优先队列中插入元素public void offer(int e) {array[size++] = e; // 将元素插入数组末尾shiftUp(size - 1); // 对插入的元素进行上浮操作,以保持堆的性质}// 弹出并返回优先队列中最高优先级的元素public int poll() {int oldValue = array[0]; // 保存堆顶元素的值array[0] = array[--size]; // 将堆尾元素移到堆顶shiftDown(0); // 对堆顶元素进行下沉操作,以保持堆的性质return oldValue; // 返回弹出的元素值}// 返回优先队列中最高优先级的元素public int peek() {return array[0]; // 直接返回堆顶元素的值}
}
请注意,此处的代码仅展示了演示目的,没有考虑扩容部分的代码实现。
三: 堆的应用
3.1PriorityQueue的实现
用堆作为底层结构封装优先级队列,这点我们已经讲过,在此不过多赘述
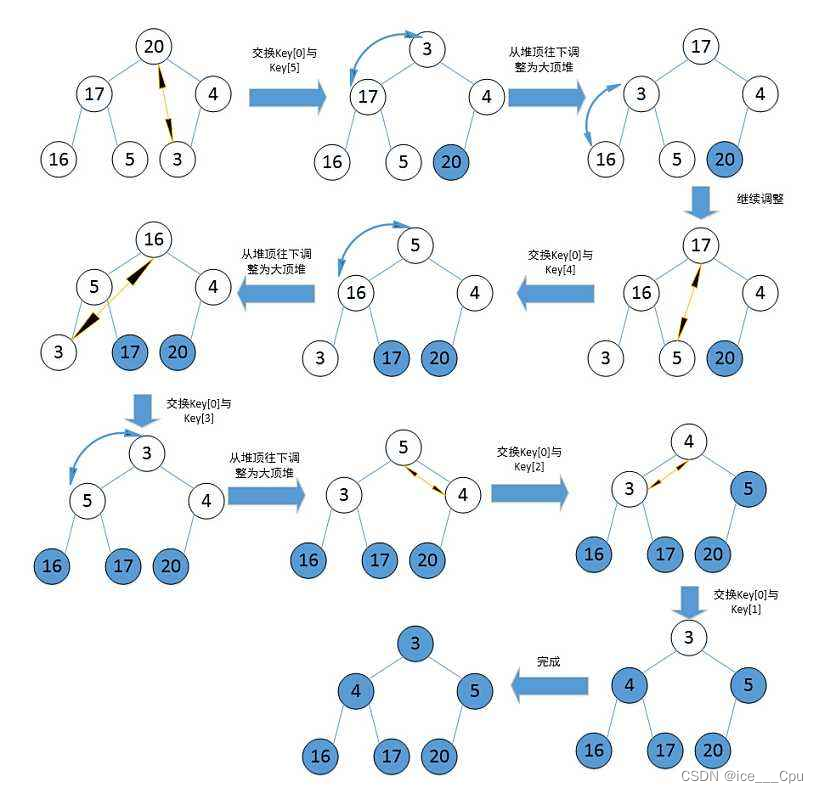
3.2堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
- 建堆
升序:建大堆
降序:建小堆 - 利用堆删除思想来进行排序
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
3.3Top-k问题
TOP-K问题:即求数据集合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
我们可以通过使用堆来解决TOP-K问题,具体步骤如下:
一: 创建一个大小为K的最小堆(或最大堆,取决于你是求前K个最小值还是最大值)。
二:遍历数据集合,对于每个元素执行以下操作:
- 如果堆的大小小于K,将当前元素插入堆中。
- 如果堆的大小等于K,比较当前元素与堆顶元素的大小
- 如果当前元素大于堆顶元素(最小堆),将堆顶元素弹出,将当前元素插入堆中。
- 如果当前元素小于堆顶元素(最大堆),跳过当前元素。
三: 遍历完数据集合后,堆中的元素即为前K个最小(或最大)的元素。
下面是一个使用Java实现堆解决TOP-K问题的示例代码:
import java.util.PriorityQueue;public class TopK {public static void main(String[] args) {int[] nums = {9, 3, 7, 5, 1, 8, 2, 6, 4};int k = 4;findTopK(nums, k);}private static void findTopK(int[] nums, int k) {PriorityQueue<Integer> minHeap = new PriorityQueue<>();for (int num : nums) {if (minHeap.size() < k) {minHeap.offer(num);} else if (num > minHeap.peek()) {minHeap.poll();minHeap.offer(num);}}System.out.println("Top " + k + " elements:");while (!minHeap.isEmpty()) {System.out.print(minHeap.poll() + " ");}}
}
以上示例中,对数组nums求前4个最小元素,使用了PriorityQueue实现了一个小顶堆。遍历数组时,根据堆的大小和当前元素与堆顶元素的比较进行插入和调整。最后,打印出堆中的元素即为前4个最小的元素。
四:java对象的比较
4.1PriorityQueue中插入对象
优先级队列在插入元素时有个要求:插入的元素不能是null或者元素之间必须要能够进行比较,为了简单起见,我们只是插入了Integer类型,那优先级队列中能否插入自定义类型对象呢?
class Card {public int rank; // 数值public String suit; // 花色public Card(int rank, String suit) {this.rank = rank;this.suit = suit;}
}
public class TestPriorityQueue {public static void TestPriorityQueue(){PriorityQueue<Card> p = new PriorityQueue<>();p.offer(new Card(1, "♠"));p.offer(new Card(2, "♠"));}public static void main(String[] args) {TestPriorityQueue();}
}
优先级队列底层使用堆,而向堆中插入元素时,为了满足堆的性质,必须要进行元素的比较,而此时Card是没有办法直接进行比较的,因此抛出异常。

4.2 元素的比较
4.2.1基本元素的比较
在Java中,基本类型的对象可以直接比较大小。
public class TestCompare {public static void main(String[] args) {int a = 10;int b = 20;System.out.println(a > b);System.out.println(a < b);System.out.println(a == b);char c1 = 'A';char c2 = 'B';System.out.println(c1 > c2);System.out.println(c1 < c2);System.out.println(c1 == c2);boolean b1 = true;boolean b2 = false;System.out.println(b1 == b2);System.out.println(b1 != b2);}
}
4.2.2 对象比较的问题
4.2.2.1equals
class Card {public int rank; // 数值public String suit; // 花色public Card(int rank, String suit) {this.rank = rank;this.suit = suit;}
}
public class TestPriorityQueue {public static void main(String[] args) {Card c1 = new Card(1, "♠");Card c2 = new Card(2, "♠");Card c3 = c1;//System.out.println(c1 > c2); // 编译报错System.out.println(c1 == c2); // 编译成功 ----> 打印false,因为c1和c2指向的是不同对象//System.out.println(c1 < c2); // 编译报错System.out.println(c1 == c3); // 编译成功 ----> 打印true,因为c1和c3指向的是同一个对象}
}
c1、c2和c3分别是Card类型的引用变量,上述代码在比较编译时:
- c1 > c2 编译失败
- c1== c2 编译成功
- c1 < c2 编译失败
从编译结果可以看出,Java中引用类型的变量不能直接按照 > 或者 < 方式进行比较。 那为什么== 可以比较?
因为:对于用户实现自定义类型,都默认继承自Object类,而Object类中提供了equal方法,而==默认情况下调用的就是equal方法,但是该方法的比较规则是:没有比较引用变量引用对象的内容,而是直接比较引用变量的地址,但有些情况下该种比较就不符合题意。
// Object中equal的实现,可以看到:直接比较的是两个引用变量的地址
public boolean equals(Object obj) {return (this == obj);
}
有些情况下,需要比较的是对象中的内容,比如:向优先级队列中插入某个对象时,需要对按照对象中内容来调整堆,那该如何处理呢?答案是重写覆盖基类的equals
public class Card {public int rank; // 数值public String suit; // 花色public Card(int rank, String suit) {this.rank = rank;this.suit = suit;}@Overridepublic boolean equals(Object o) {// 自己和自己比较if (this == o) {return true;}// o如果是null对象,或者o不是Card的子类if (o == null || !(o instanceof Card)) {return false;}// 注意基本类型可以直接比较,但引用类型最好调用其equal方法Card c = (Card)o;return rank == c.rank&& suit.equals(c.suit);}
}
注意: 一般覆写 equals 的套路就是上面演示的
- 如果指向同一个对象,返回 true
- 如果传入的为 null,返回 false
- 如果传入的对象类型不是 Card,返回 false
- 按照类的实现目标完成比较,例如这里只要花色和数值一样,就认为是相同的牌
- 注意下调用其他引用类型的比较也需要 equals,例如这里的 suit 的比较
覆写基类equal的方式虽然可以比较,但缺陷是:equal只能按照相等进行比较,不能按照大于、小于的方式进行比较。
4.2.2.2 Comparble接口
Comparble是JDK提供的泛型的比较接口类,源码实现具体如下:
public interface Comparable<E> {// 返回值:// < 0: 表示 this 指向的对象小于 o 指向的对象// == 0: 表示 this 指向的对象等于 o 指向的对象// > 0: 表示 this 指向的对象大于 o 指向的对象int compareTo(E o);
}
对用用户自定义类型,如果要想按照大小与方式进行比较时:在定义类时,实现Comparble接口即可,然后在类中重写compareTo方法。
Java中的Comparable接口是用于实现对象的自然排序的接口。它包含一个compareTo方法,用于比较两个对象的顺序。
compareTo方法有以下三种返回值:
- 如果当前对象小于被比较对象,则返回一个负整数。
- 如果当前对象等于被比较对象,则返回0。
- 如果当前对象大于被比较对象,则返回一个正整数。
下面是一个简单的例子,演示如何使用Comparable接口来自然排序自定义的Person类:
import java.util.ArrayList;
import java.util.Collections;class Person implements Comparable<Person> {private String name;private int age;public Person(String name, int age) {this.name = name;this.age = age;}// 实现compareTo方法@Overridepublic int compareTo(Person other) {return this.age - other.age; // 按照年龄排序}// 其他getter和setter方法@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}
}public class Main {public static void main(String[] args) {ArrayList<Person> people = new ArrayList<>();people.add(new Person("Alice", 25));people.add(new Person("Bob", 20));people.add(new Person("Charlie", 30));System.out.println("排序前:");for (Person person : people) {System.out.println(person);}Collections.sort(people); // 使用Collections.sort()方法进行排序时,会自动调用compareTo()方法进行比较System.out.println("排序后:");for (Person person : people) {System.out.println(person);}}
}
输出结果:
排序前:
Person{name='Alice', age=25}
Person{name='Bob', age=20}
Person{name='Charlie', age=30}
排序后:
Person{name='Bob', age=20}
Person{name='Alice', age=25}
Person{name='Charlie', age=30}
在上面的代码中,我们定义了一个Person类,并实现了Comparable接口。我们通过compareTo方法比较了两个Person对象的年龄,并在Main类中使用Collections.sort方法对people列表进行了排序。排序后,列表中的Person对象按照年龄的升序排列。
注意:Compareble是java.lang中的接口类,可以直接使用。
4.2.2.3 基于比较器比较
在Java中,如果我们想要比较两个对象,并根据它们的属性值进行排序或判断它们的相对顺序,我们可以使用比较器(Comparator)进行操作。
比较器是一个用于定义对象之间比较行为的接口。它包含了一个用于比较两个对象的方法 - compare()。该方法接受两个参数,分别是要比较的两个对象,然后返回一个整数值来表示它们的相对顺序。
下面是一个简单的示例,展示如何使用比较器比较两个Person对象:
import java.util.*;// 定义Person类
class Person {private String name;private int age;public Person(String name, int age) {this.name = name;this.age = age;}// 省略其他属性和方法public String getName() {return name;}public int getAge() {return age;}
}// 定义比较器类
class AgeComparator implements Comparator<Person> {@Overridepublic int compare(Person person1, Person person2) {if (person1.getAge() < person2.getAge()) {return -1; // person1在前} else if (person1.getAge() > person2.getAge()) {return 1; // person2在前} else {return 0; // 保持顺序不变}}
}public class Main {public static void main(String[] args) {// 创建Person对象Person person1 = new Person("Alice", 25);Person person2 = new Person("Bob", 30);Person person3 = new Person("John", 20);// 创建比较器对象AgeComparator comparator = new AgeComparator();// 使用比较器比较对象int result1 = comparator.compare(person1, person2); // 返回-1,person1在前int result2 = comparator.compare(person2, person1); // 返回1,person2在前int result3 = comparator.compare(person1, person3); // 返回0,保持顺序不变System.out.println(result1);//-1System.out.println(result2);//1System.out.println(result3);//0}
}
在上述代码中,我们定义了一个Person类,其中包含了姓名(name)和年龄(age)属性。然后,我们创建了一个比较器类AgeComparator,实现了Comparator接口,并重写了compare()方法来根据年龄来判断相对顺序。
在main()方法中,我们创建了三个Person对象,并使用AgeComparator比较器对象来比较它们的年龄。最后,我们打印了比较的结果,验证了对象之间的比较行为。
这就是基于比较器比较两个对象的示例。通过实现Comparator接口并重写compare()方法,我们可以定制化对象之间的比较行为,从而实现根据特定属性进行排序或判断相对顺序。
注意:Comparator是java.util 包中的泛型接口类,使用时必须导入对应的包。
我们要注意区分Comparable和Comparato:
- 实现Comparable接口,重写compareTo方法
- 实现Comparator接口,重写compare方法
三种比较方式对比:
| 覆写的方法 | 说明 |
|---|---|
| Object.equals | 因为所有类都是继承自 Object 的,所以直接覆写即可,不过只能比较相等与否 |
| Comparable.compareTo | 需要手动实现接口,侵入性比较强,但一旦实现,每次用该类都有顺序,属于内部顺序,Compareble是java.lang中的接口类,可以直接使用。 |
| Comparator.compare | 需要实现一个比较器对象,对待比较类的侵入性弱,但对算法代码实现侵入性强 ,Comparator是java.util 包中的泛型接口类,使用时必须导入对应的包。 |
相关文章:
数据结构 - 6(优先级队列(堆)13000字详解)
一:堆 1.1 堆的基本概念 堆分为两种:大堆和小堆。它们之间的区别在于元素在堆中的排列顺序和访问方式。 大堆(Max Heap): 在大堆中,父节点的值比它的子节点的值要大。也就是说,堆的根节点是堆…...

Js高级技巧—拖放
拖放基本功能实现 拖放是一种非常流行的用户界面模式。它的概念很简单:点击某个对象,并按住鼠标按钮不放,将 鼠标移动到另一个区域,然后释放鼠标按钮将对象“放”在这里。拖放功能也流行到了 Web 上,成为 了一些更传统…...
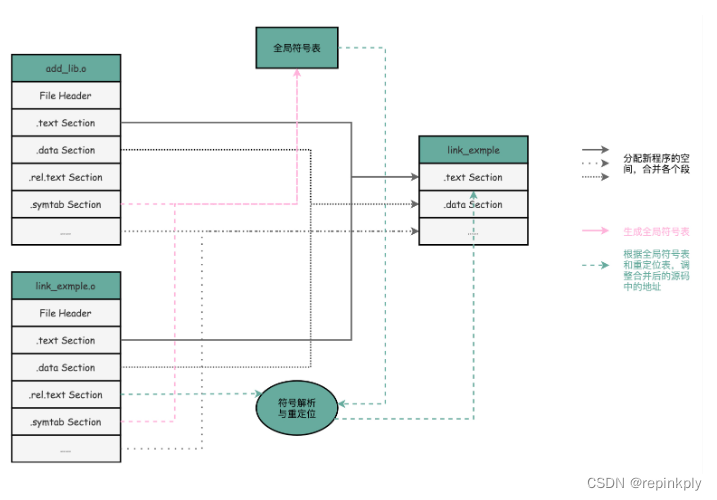
ELF和静态链接:为什么程序无法同时在Linux和Windows下运行?
目录 疑问 编译、链接和装载:拆解程序执行 ELF 格式和链接:理解链接过程 小结 疑问 既然我们的程序最终都被变成了一条条机器码去执行,那为什么同一个程序,在同一台计算机上,在 Linux 下可以运行,而在…...
【爬虫实战】python微博热搜榜Top50
一.最终效果 二.项目代码 2.1 新建项目 本文使用scrapy分布式、多线程爬虫框架编写的高性能爬虫,因此新建、运行scrapy项目3步骤: 1.新建项目: scrapy startproject weibo_hot 2.新建 spider: scrapy genspider hot_search "weibo.com" 3…...
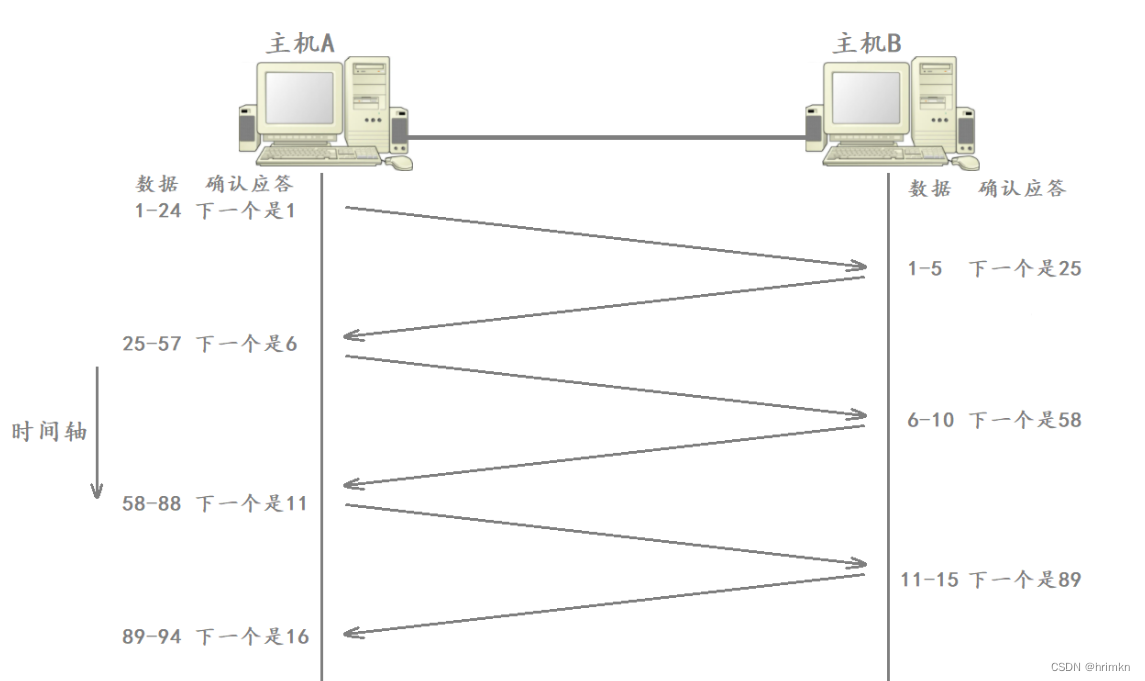
【网络基础】——传输层
目录 前言 传输层 端口号 端口号范围划分 知名端口号 进程与端口号的关系 netstat UDP协议 UDP协议位置 UDP协议格式 UDP协议特点 面向数据报 UDP缓冲区 UDP的使用注意事项 基于UDP的应用层协议 TCP协议 TCP简介 TCP协议格式 确认应答机制&#…...
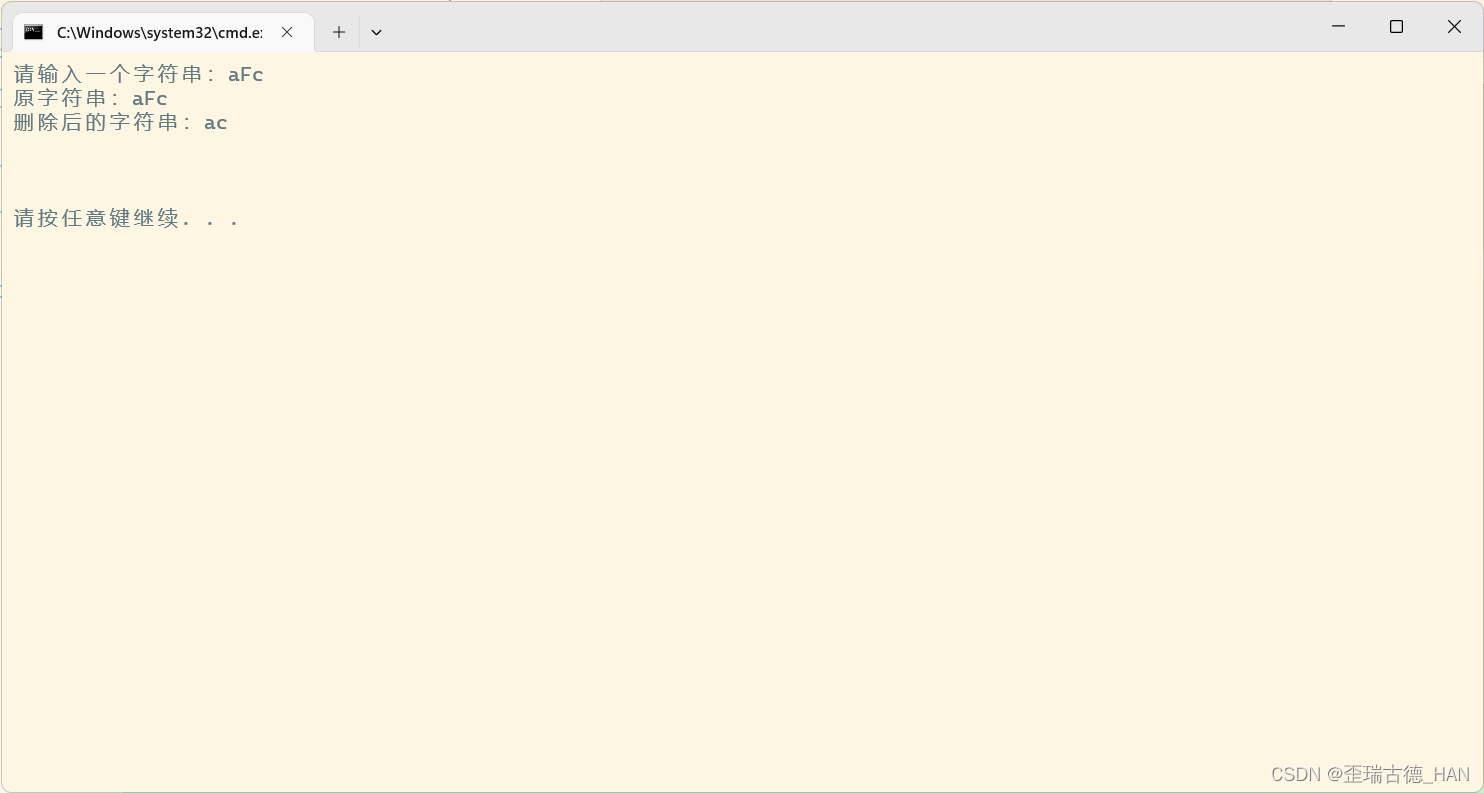
删除字符串特定的字符(fF)C语言
代码: #include <stdio.h> void funDel(char *str) {int i, j;for (i j 0; str[i] ! \0; i)if (str[i] ! f && str[i] ! F)str[j] str[i];str[j] \0; }int main() {char str[100];printf("请输入一个字符串:");gets(str);pr…...
:命名空间,IO流 输入输出,缺省参数)
C++入门(1):命名空间,IO流 输入输出,缺省参数
一、命名空间 1.1 命名空间的作用: 避免标识符命名冲突 1.2 命名空间定义: 关键字:namespace namespace test {// 命名空间内可以定义变量/函数/类型int a 10;int Add(int x, int y){return x y;}struct Stack{int* a;int top;int …...
:并发编程)
Go 语言面试题(三):并发编程
文章目录 Q1 无缓冲的 channel 和 有缓冲的 channel 的区别?Q2 什么是协程泄露(Goroutine Leak)?Q3 Go 可以限制运行时操作系统线程的数量吗? Q1 无缓冲的 channel 和 有缓冲的 channel 的区别? 对于无缓冲的 channel,…...

Linux - make命令 和 makefile
make命令和 makefile 如果之前用过 vim 的话,应该会对 vim 又爱又恨吧,刚开始使用感觉非常的别扭,因为这种编写代码的方式,和在 windows 当中用图形化界面的方式编写代码的方式差别是不是很大。当你把vim 用熟悉的之后࿰…...

FPGA复习(功耗)
减小功耗 就得减小电流 电流和CF有关( C: 电容(被门数目和布线长度影响) F:时钟频率) 方法大纲 减小功耗:1 时钟控制 2输入控制 3减小供电电压 4双沿触发器 5修改终端 同步数字电路降低动态功耗:动态禁止…...
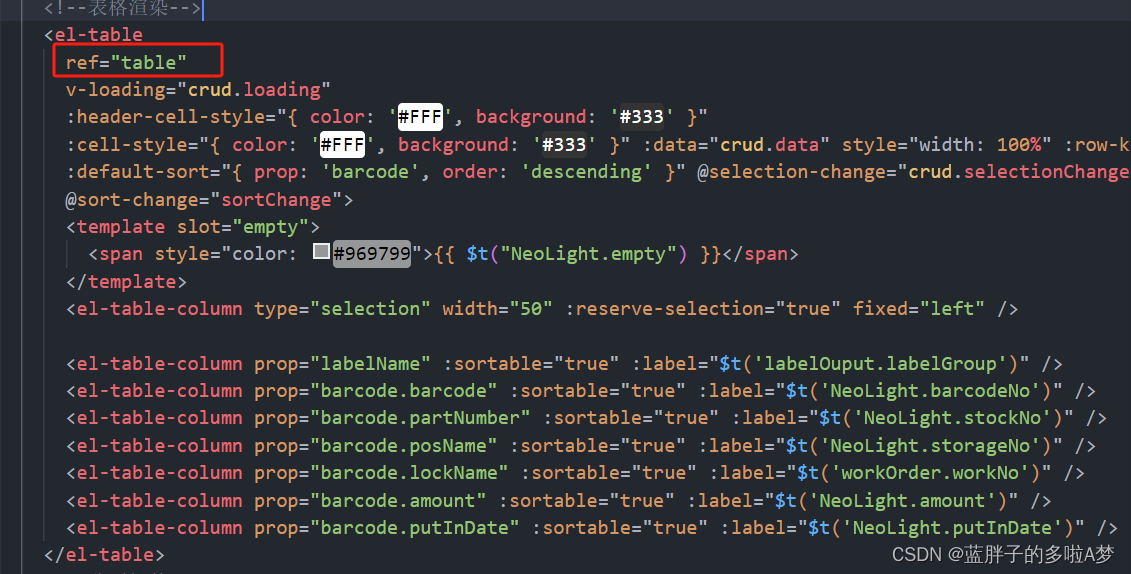
element ui el-table表格复选框,弹框关闭取消打勾选择
//弹框表格复选框清空 this.$nextTick(()>{this.$refs.table.clearSelection();})<el-table ref"table" v-loading"crud.loading" :header-cell-style"{ color: #FFF, background: #333 }":cell-style"{ color: #FFF, background: #3…...

数据结构——队列
1.队列元素逆置 【问题描述】 已知Q是一个非空队列,S是一个空栈。仅使用少量工作变量以及对队列和栈的基本操作,编写一个算法,将队列Q中的所有元素逆置。 【输入形式】 输入的第一行为队列元素个数,第二行为队列从首至尾的元素…...

【Unity引擎核心-Object,序列化,资产管理,内存管理】
文章目录 整体介绍Native & Managed Objects什么是序列化序列化用来做什么Editor和运行时序列化的区别脚本序列化针对序列化的使用建议 Unity资产管理导入Asset Process为何要做引擎资源文件导入Main-Assets和 Sub-Assets资产的导入管线Hook,AssetPostprocessor…...

Generics/泛型, ViewBuilder/视图构造器 的使用
1. Generics 泛型的定义及使用 1.1 创建使用泛型的实例 GenericsBootcamp.swift import SwiftUIstruct StringModel {let info: String?func removeInfo() -> StringModel{StringModel(info: nil)} }struct BoolModel {let info: Bool?func removeInfo() -> BoolModel…...
数据结构之手撕顺序表(增删查改等)
0.引言 在本章之后,就要求大家对于指针、结构体、动态开辟等相关的知识要熟练的掌握,如果有小伙伴对上面相关的知识还不是很清晰,要先弄明白再过来接着学习哦! 那进入正题,在讲解顺序表之前,我们先来介绍…...

进阶JAVA篇- ZoneId 类与 ZoneDateTime 类、Instant类的常用API(七)
目录 API 1.0 ZoneId 类的说明 1.1 如何创建 ZoneId 类的对象呢? 1.2 ZoneId 类中的 getAvailableZoneIds() 静态方法 2.0 ZoneDateTime 类的说明 2.1 如何创建 ZoneDateTime 类的对象呢? 3.0 Instant 类的说明 3.1 如何创建 Instant 类的对象呢…...

bat脚本字符串替换:路径中\需要替换,解决一些文件写入路径不对的问题
脚本 set dir_tmp%~dp0 set dir%dir_tmp:\\\\\% set dir_tmp%~dp0 新建一个变量dir_tmp,存储获取的脚本当前路径 set dir%dir_tmp:\\\\\% 新建一个变量dir ,存储字符串替换之后的路径 其中黄色的\\实际上代表的是一个\...

python一行命令搭建web服务,实现内网共享文件
python一行命令搭建web服务,实现内网共享文件 有时候我们在本地电脑访问自己的虚拟机的时候,可能因为某些原因无法直接CV文件到虚拟机。但此时我们又想上传文件到虚拟机,如果虚拟机和本地电脑可以互通。那么我们可以直接通过python来启动一个…...

RK3562开发板:升级摄像头ISP,突破视觉体验边界
RK3562开发板作为深圳触觉智能新推出的爆款产品,采用 Rockchip 新一代 64 位处理器 RK3562(Quad-core ARM Cortex-A53,主频最高 2.0GHz),最大支持 8GB 内存;内置独立的 NPU,可用于轻量级人工智能…...

数据结构与算法-队列
队列 🎈1.队列的定义🎈2.队列的抽象数据类型定义🎈3.顺序队列(循环队列)🔭3.1循环队列🔭3.1循环队列类定义🔭3.2创建空队列🔭3.3入队操作🔭3.4出队操作&#…...

Windows性能优化:任务管理器深度使用指南
Windows性能优化:任务管理器深度使用指南Windows系统运行缓慢、卡顿?系统自带的任务管理器是诊断和解决性能瓶颈的强大工具。本文将带你深度挖掘Windows任务管理器的各项功能,重点介绍如何利用它进行进程管理、性能监控、启动项优化等操作&am…...

从光波“数环”到材料“测温”:迈克尔逊干涉仪在热膨胀系数测量中的创新实践
1. 光波如何变成材料"温度计"? 第一次接触迈克尔逊干涉仪时,我盯着那些不断变化的彩色圆环发了半天呆。谁能想到这些看似简单的光环,竟然能精确测量出金属棒受热后百万分之一米级别的长度变化?这就像用一把能测量头发丝…...

卡证检测矫正模型开发环境搭建:PyCharm/IDEA项目配置全攻略
卡证检测矫正模型开发环境搭建:PyCharm/IDEA项目配置全攻略 你是不是刚拿到一个卡证检测矫正模型的项目,看着一堆代码和配置文件有点无从下手?特别是想用PyCharm或者IDEA这样的专业工具来开发调试,却不知道从哪一步开始配置环境&…...

FireRedASR Pro避坑指南:模型加载报错的快速解决方法
FireRedASR Pro避坑指南:模型加载报错的快速解决方法 1. 常见模型加载问题概述 当你第一次尝试运行FireRedASR Pro时,可能会遇到各种模型加载报错。这些错误通常集中在三个关键环节: 权重文件加载失败:PyTorch版本不兼容导致的…...

Hasklig字体终极指南:多语言编程环境中的完美适配方案
Hasklig字体终极指南:多语言编程环境中的完美适配方案 【免费下载链接】Hasklig Hasklig - a code font with monospaced ligatures 项目地址: https://gitcode.com/gh_mirrors/ha/Hasklig Hasklig是一款专为程序员设计的等宽字体,通过智能连字技…...

保姆级教程:用YOLO+DeepSORT在UCF101-24数据集上实现实时时空动作检测
从零搭建实时时空动作检测系统:YOLODeepSORT实战指南 当你在篮球场边拍摄一段视频,能否让AI自动标记出每个球员的投篮动作?或者在游泳比赛中实时框选运动员的跳水瞬间?这就是时空动作检测技术的魅力所在——它不仅要知道"发生…...

Swagger2Word:高效转换与文档自动化的API文档解决方案
Swagger2Word:高效转换与文档自动化的API文档解决方案 【免费下载链接】swagger2word 项目地址: https://gitcode.com/gh_mirrors/swa/swagger2word 在软件开发过程中,API文档的管理和维护常常成为团队协作的痛点。开发人员使用Swagger/OpenAPI规…...
)
告别手动维护!用DataX-Web搞定MySQL到ClickHouse的增量同步(含时间戳配置)
高效构建MySQL到ClickHouse的增量同步管道:DataX-Web实战指南 在数据驱动的商业环境中,企业每天都会产生海量的业务数据。这些数据通常存储在OLTP系统如MySQL中,但为了进行分析和报表生成,我们需要将这些数据同步到OLTP系统如Clic…...

英飞凌TC377芯片选型指南:从300MHz三核到FlexRay,汽车电子工程师如何快速上手?
英飞凌TC377芯片选型实战:汽车电子工程师的黄金法则 当汽车电子工程师面对英飞凌TC377这颗"三核300MHz怪兽"时,数据手册上密密麻麻的参数表格往往让人无从下手。我曾参与过某新能源车企的域控制器开发,团队花了整整两周时间争论芯片…...

开源OFA模型多场景落地:新闻图库自动配文、政府信息公开图片无障碍描述生成
开源OFA模型多场景落地:新闻图库自动配文、政府信息公开图片无障碍描述生成 1. 项目概述:让图片会说话的智能助手 你有没有遇到过这样的情况:看着一张图片,却不知道该怎么用文字描述它?或者需要为大量图片手动添加文…...