可视化上证50结构图
可视化上证50结构图
- 缘由
- 收集数据
- 先获取50支成分股列表
- 获取各成分股票K线数据
- 数据处理
- 找出来,再删除,然后重新下载数据
- 最终获得每日报价的变化值
- 图形结构处理
- 聚类分析
- 使用affinity_propagation(亲和传播)聚类
- 嵌入二维平面空间
- 可视化
- 小结
- 热力图
缘由
前些日子,看到sklearn 官网上一个事例,可视化的股市结构 ,由于萌发给咱沪深也整张图,经过一段时间的研究,现分享给大家。
收集数据
原文,是数据是来自2003年至2008年 data.nasdaq.com和alphavantage.co等API中获得。
本文的数据 采用 baostock 2020-至今天(2023-09-30)的交易数据(除权),选择上证50成分股。
import numpy as np
import pandas as pd
import baostock as bs
先获取50支成分股列表
# 登陆系统
lg = bs.login()
# 获取上证50成分股
rs = bs.query_sz50_stocks()
# 打印结果集
sz50_stocks = []
while (rs.error_code == '0') & rs.next():# 获取一条记录,将记录合并在一起sz50_stocks.append(rs.get_row_data())
result = pd.DataFrame(sz50_stocks, columns=rs.fields)
bs.logout()df=result.iloc[:,1:3]
df1=df.set_index('code')
symbol_dict =df1.to_dict()['code_name']
symbols, names = np.array(sorted(symbol_dict.i
如下图

获取各成分股票K线数据
def get_kdata(code):rs = bs.query_history_k_data_plus(code,"date,open,close",start_date='2020-01-01', end_date='2023-09-30',frequency="d", adjustflag="3")data_list = []while (rs.error_code == '0') & rs.next():data_list.append(rs.get_row_data())result = pd.DataFrame(data_list, columns=rs.fields)return result
bs.login()
quotes = []
#
for symbol in symbols:#print(symbol)ddf=get_kdata(symbol)quotes.append(ddf)
bs.logout()
数据处理
由于这里有些股票数据个数不一致,导致后继执行出错,因此,将不一致的数据进行删除。
for i,quote in enumerate(quotes):if (len(quote)!=910):print(i,symbols[i],names[i],len(quote))
23 sh.600905 三峡能源 563
42 sh.601995 中金公司 711
49 sh.688599 天合光能 806
找出来,再删除,然后重新下载数据
那样的话,并非50支票,而是47支。
result.drop(labels=[23,42,49],inplace=True)
df=result.iloc[:,1:3]
df1=df.set_index('code')
symbol_dict =df1.to_dict()['code_name']
symbols, names = np.array(sorted(symbol_dict.items())).T
bs.login()
quotes = []
for symbol in symbols:ddf=get_kdata(symbol)quotes.append(ddf)
bs.logout()
最终获得每日报价的变化值
close_prices = np.vstack([q["close"].astype("float") for q in quotes])
open_prices = np.vstack([q["open"].astype("float") for q in quotes])# 报价的每日变化是信息最多的地方
variation = close_prices - open_prices
图形结构处理
我们使用稀疏逆协方差估计来找出哪些引号与其他引号有条件地相关。具体来说,稀疏逆协方差给了我们一个图,这是一个连接列表。对于每个符号,它所连接的符号都是用来解释其波动的。
协方差矩阵的逆矩阵,通常称为精度矩阵(precision matrix),它与部分相关矩阵(partial correlation matrix)成正比。 它给出部分独立性关系。换句话说,如果两个特征在其他特征上有条件地独立, 则精度矩阵中的对应系数将为零。这就是为什么估计一个稀疏精度矩阵是有道理的: 通过从数据中学习独立关系,协方差矩阵的估计能更好处理。这被称为协方差选择。
在小样本的情况,即 n_samples 是数量级 n_features 或更小, 稀疏的逆协方差估计往往比收敛的协方差估计更好。 然而,在相反的情况下,或者对于非常相关的数据,它们可能在数值上不稳定。 此外,与收敛估算不同,稀疏估计器能够恢复非对角线结构 (off-diagonal structure)。
from sklearn import covariancealphas = np.logspace(-1.5, 1, num=10)
edge_model = covariance.GraphicalLassoCV(alphas=alphas)#标准化时间序列:使用相关性而不是协方差
#前者对结构恢复更有效
X = variation.copy().T
X /= X.std(axis=0)
edge_model.fit(X)
聚类分析
使用affinity_propagation(亲和传播)聚类
我们使用聚类将行为相似的引号分组在一起。在这里,在scikit-learn中可用的各种集群技术中,我们使用Affinity Propagation,因为它不强制执行相同大小的集群,并且它可以从数据中自动选择集群的数量。
请注意,这给了我们一个与图不同的指示,因为图反映了变量之间的条件关系,而聚类反映了边际性质:聚集在一起的变量可以被认为在整个股市水平上具有类似的影响。
Affinity Propagation是一种基于图论的聚类算法,旨在识别数据中的"exemplars"(代表点)和"clusters"(簇)。与K-Means等传统聚类算法不同,Affinity Propagation不需要事先指定聚类数目,也不需要随机初始化簇心,而是通过计算数据点之间的相似性得出最终的聚类结果。
Affinity Propagation算法的优点是不需要预先指定聚类数目,且能够处理非凸形状的簇。但是该算法的计算复杂度较高,需要大量的存储空间和计算资源,并且对于噪声点和离群点的处理能力较弱。
from sklearn import cluster_, labels = cluster.affinity_propagation(edge_model.covariance_, random_state=0)
n_labels = labels.max()for i in range(n_labels + 1):print(f"Cluster {i + 1}: {', '.join(names[labels == i])}")
Cluster 1: 中信证券, 上汽集团, 航发动力, 中信建投, 华泰证券
Cluster 2: 包钢股份, 北方稀土, 国电南瑞
Cluster 3: 三一重工, 万华化学, 恒力石化, 紫金矿业, 中远海控
Cluster 4: 通威股份, 隆基绿能, 长城汽车, 合盛硅业, 华友钴业
Cluster 5: 复星医药, 恒瑞医药, 片仔癀, 贵州茅台, 海尔智家, 山西汾酒, 伊利股份, 中国中免, 药明康德, 海天味业
Cluster 6: 中国神华, 陕西煤业, 中国石油
Cluster 7: 中国石化, 农业银行, 工商银行
Cluster 8: 招商银行, 兴业银行, 中国平安, 中国太保, 中国人寿
Cluster 9: 保利发展, 海螺水泥, 长江电力, 中国建筑, 中国电建
Cluster 10: 闻泰科技, 韦尔股份, 兆易创新
嵌入二维平面空间
为了出于可视化目的,我们需要在二维画布上显示不同的符号。为此,我们使用流形学习技术来检索2D嵌入。我们使用密集的本征分解器来实现再现性(arpack是用我们不控制的随机向量启动的)。此外,我们使用大量的邻居来捕捉大规模的结构。
#为可视化寻找低维嵌入:找到 最佳的二维平面位置(股票)from sklearn import manifoldnode_position_model = manifold.LocallyLinearEmbedding(n_components=2, eigen_solver="dense", n_neighbors=6
)
embedding = node_position_model.fit_transform(X.T).T
可视化
3种模型的输出组合成一个二维平面图,其中节点表示股票,边缘表示:
- 集群标签用于定义节点的颜色
- 使用稀疏协方差模型来显示边的强度(边的宽度)
- 二维嵌入用于定位平面中的节点
这个示例包含大量与可视化相关的代码,因为可视化在这里对于显示图形至关重要。其中一个挑战是定位标签,使重叠最小化。为此,我们使用基于每个轴上最近邻居方向的启发式方法。
import matplotlib.pyplot as plt
from matplotlib.collections import LineCollection
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 #有中文出现的情况,需要u'内容'plt.figure(1, facecolor="w", figsize=(20, 16))
plt.clf()
ax = plt.axes([0.0, 0.0, 1.0, 1.0])
plt.axis("off")# Plot the graph of partial correlations
partial_correlations = edge_model.precision_.copy()
d = 1 / np.sqrt(np.diag(partial_correlations))
partial_correlations *= d
partial_correlations *= d[:, np.newaxis]
non_zero = np.abs(np.triu(partial_correlations, k=1)) > 0.02# Plot the nodes using the coordinates of our embedding
plt.scatter(embedding[0], embedding[1], s=100 * d**2, c=labels, cmap=plt.cm.nipy_spectral
);# Plot the edges
start_idx, end_idx = np.where(non_zero)
# a sequence of (*line0*, *line1*, *line2*), where::
# linen = (x0, y0), (x1, y1), ... (xm, ym)
segments = [[embedding[:, start], embedding[:, stop]] for start, stop in zip(start_idx, end_idx)
]
values = np.abs(partial_correlations[non_zero])
lc = LineCollection(segments, zorder=0, cmap=plt.cm.hot_r, norm=plt.Normalize(0, 0.7 * values.max())
)
lc.set_array(values)
lc.set_linewidths(15 * values)
ax.add_collection(lc)# Add a label to each node. The challenge here is that we want to
# position the labels to avoid overlap with other labels
for index, (name, label, (x, y)) in enumerate(zip(names, labels, embedding.T)):dx = x - embedding[0]dx[index] = 1dy = y - embedding[1]dy[index] = 1this_dx = dx[np.argmin(np.abs(dy))]this_dy = dy[np.argmin(np.abs(dx))]if this_dx > 0:horizontalalignment = "left"x = x + 0.002else:horizontalalignment = "right"x = x - 0.002if this_dy > 0:verticalalignment = "bottom"y = y + 0.002else:verticalalignment = "top"y = y - 0.002plt.text(x,y,name,size=10,horizontalalignment=horizontalalignment,verticalalignment=verticalalignment,bbox=dict(facecolor="w",edgecolor=plt.cm.nipy_spectral(label / float(n_labels)),alpha=0.6,),)plt.xlim(embedding[0].min() - 0.15 * embedding[0].ptp(),embedding[0].max() + 0.10 * embedding[0].ptp(),
)
plt.ylim(embedding[1].min() - 0.03 * embedding[1].ptp(),embedding[1].max() + 0.03 * embedding[1].ptp(),
)plt.show();

小结
从上图可以看出同类股票,并非分布在同一区域,距离的远近也反映了两两的相关性。
从一个侧面也反映了各股票之间的关系。如果有可能,将二维平面扩展成三维立体图,可能会更加直观。
热力图
基于相关性,本文引入了热力图来进一步可视化。
import seaborn as sns
fig = plt.figure(figsize= (15,10))
ax = fig.add_subplot(111)
sns.set()
ax = sns.heatmap(edge_model.covariance_)

从上图可以看出,相关性绝大多数在0.2 左右,只有小数达到0.8以上。
相关文章:
可视化上证50结构图
可视化上证50结构图 缘由收集数据先获取50支成分股列表获取各成分股票K线数据 数据处理找出来,再删除,然后重新下载数据最终获得每日报价的变化值 图形结构处理聚类分析使用affinity_propagation(亲和传播)聚类 嵌入二维平面空间可视化小结热力图 缘由 …...

STM32_PID通用算法增量式和位置式
STM32_PID通用算法增量式和位置式 前言: 此算法为入门级PID算法,调试好参数后可应用于温度控制、舵机控制、直流电机的转速控制和直流电机的角度控制等等,下面就以温度控制举例 pid.c #include "pid.h" #include "sensor.h&q…...

Spark的数据输入、数据计算、数据输出
PySpark的编程,主要氛围三大步骤:1)数据输入、2)数据处理计算、3)数据输出 1)数据输入:通过SparkContext对象,晚上数据输入 2)数据处理计算:输入数据后得到RDD对象,对RDD…...
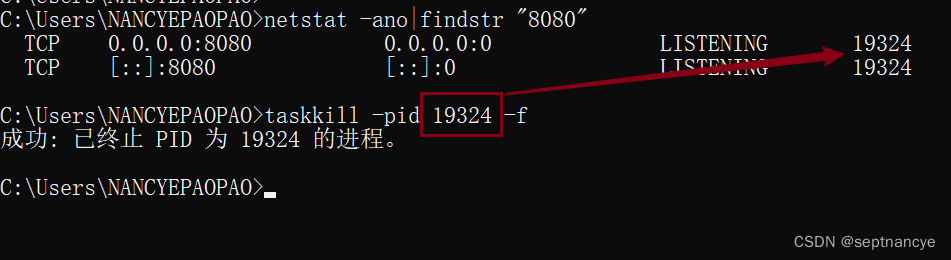
Windows端口号被占用的查看方法及解决办法
Windows端口号被占用的查看方法及解决办法 Error starting ApplicationContext. To display the conditions report re-run your application with debug enabled. 2023-10-14 22:58:32.069 ERROR 6488 --- [ main] o.s.b.d.LoggingFailureAnalysisReporter : ***…...
Web3 整理React项目 导入Web3 并获取区块链信息
上文 WEB3 创建React前端Dapp环境并整合solidity项目,融合项目结构便捷前端拿取合约 Abi 我们用react 创建了一个 dapp 项目 并将前后端代码做了个整合 那么 我们就来好好整理一下 我们的前端react的项目结构 我们在 src 目录下创建一个 components 用来存放我们的…...

基于SpringBoot的旅游网站开题报告
一、选题背景 随着旅游业的蓬勃发展和人们对旅游需求的增长,开发一个基于Spring Boot的旅游网站具有重要的意义。传统的旅行社模式逐渐不能满足人们个性化、多样化的旅游需求,因此开发一个在线旅游网站能够为用户提供更加便捷、灵活、个性化的旅游服务&…...
基于SSM的班级事务管理系统
基于SSM的班级事务管理系统 开发语言:Java数据库:MySQL技术:SpringSpringMVCMyBatisVue工具:IDEA/Ecilpse、Navicat、Maven 系统展示 前台界面 登录界面 班委界面 学生界面 管理员界面 摘要 基于SSM(Spring、Spring…...

基于Spring Boot开发的汽车租赁管理系统
文章目录 项目介绍主要功能截图:后台前台部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于Spring Boot开发的汽车租赁…...
精品基于django的高校竞赛比赛管理系统Python
《[含文档PPT源码等]精品基于django的高校竞赛管理系统》该项目含有源码、文档、PPT、配套开发软件、软件安装教程、项目发布教程等! 软件开发环境及开发工具: 开发语言:python 使用框架:Django 前端技术:JavaScri…...

RustDay04------Exercise[01-10]
1.做题须知 这一题告诉我们可以尝试修改下面的输出,在觉得OK之后删除// I AM NOT DONE注释即可进入下一题 // intro1.rs // About this I AM NOT DONE thing: // We sometimes encourage you to keep trying things on a given exercise, even // after you already figured …...
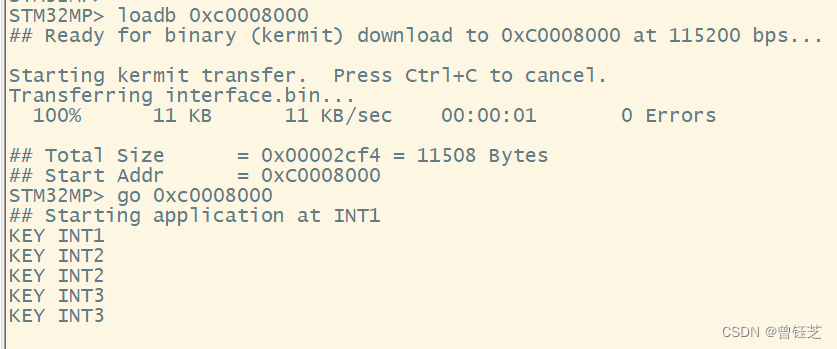
ARM day9
src/key_it.c #include "key_it.h" #include "led.h" void key_it_config() {//RCC使能GPIOF时钟RCC->MP_AHB4ENSETR | (0x1<<5);//设置PF9 PF7 PF8GPIO输入//PF9GPIOF->MODER & (~(0x3<<18));//PF8GPIOF->MODER & (~(0x3&l…...

【TensorFlow2 之013】TensorFlow-Lite
一、说明 在这篇文章中,我们将展示如何构建计算机视觉模型并准备将其部署在移动和嵌入式设备上。有了这些知识,您就可以真正将脚本部署到日常使用或移动应用程序中。 教程概述: 介绍在 TensorFlow 中构建模型将模型转换为 TensorFlow Lite训练…...

Java基础--阳光总在风雨后,请相信彩虹
1、今日任务 JAVA SE-韩顺平视频教程–30p以上(今天得50p以上因为是基础)计算机基础八股记忆总结刷题(两题)可以先用python 1、SSM ssm->Spring(轻量级的文本开发框架)/SpringMVC(分层的w…...

高级网络调试技巧:使用Charles Proxy捕获和修改HTTP/HTTPS请求
今天我将与大家分享一种强大的网络调试技巧,那就是使用Charles Proxy来捕获和修改HTTP/HTTPS请求。如果您是一位开发人员或者网络调试爱好者,那么这个工具肯定对您有着很大的帮助。接下来,让我们一起来学习如何使用Charles Proxy进行高级网络…...
Discuz大气游戏风格模板/仿lol英雄联盟游戏DZ游戏模板GBK
Discuz大气游戏风格模板,lol英雄联盟游戏模板,DZ游戏娱乐模板GBK。模板名称:lol英雄联盟游戏(m0398_lol) 下载地址:https://bbs.csdn.net/topics/617408069...
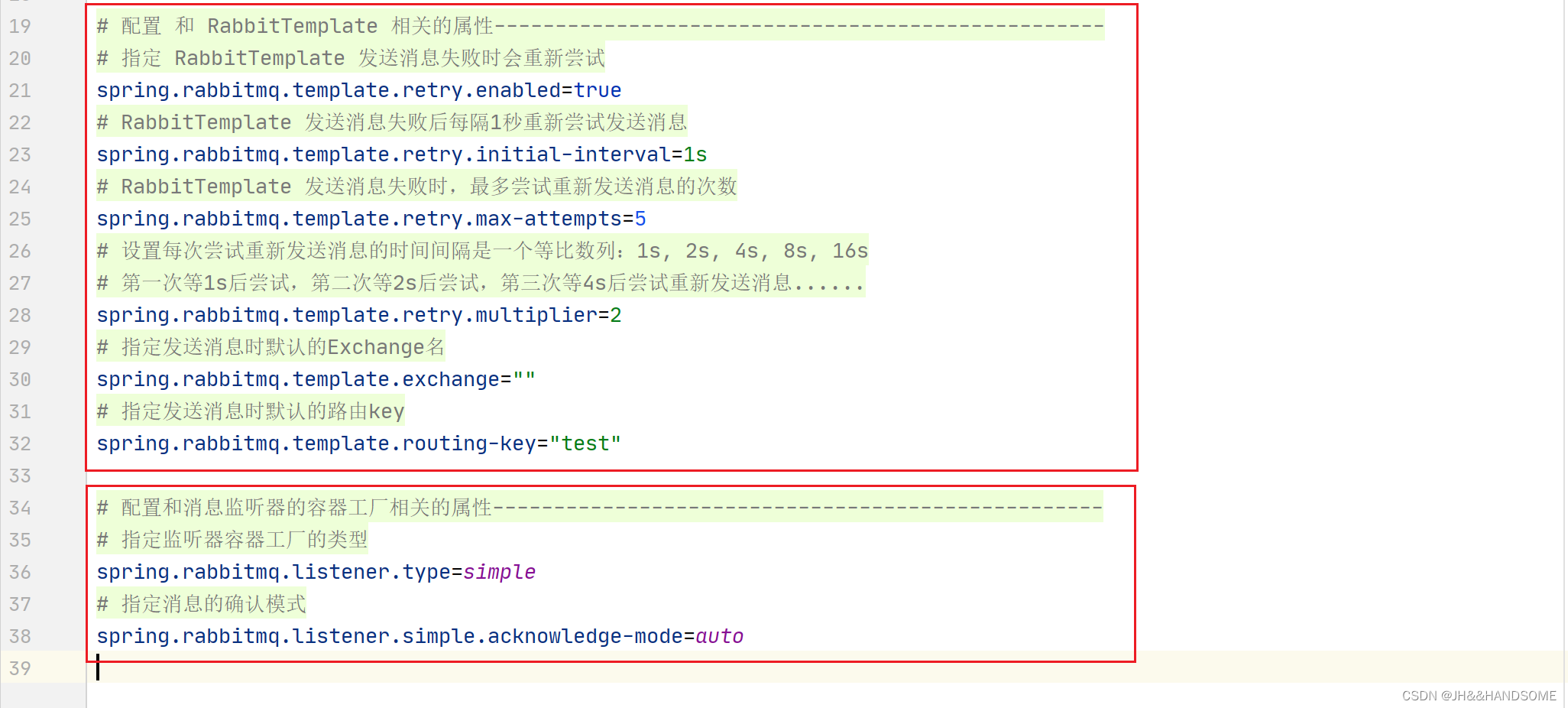
206、SpringBoot 整合 RabbitMQ 的自动配置类 和 对应的属性处理类 的知识点
目录 ★ Spring Boot 为 RabbitMQ 提供的自动配置▲ 自动配置类:RabbitAutoConfiguration▲ 属性处理类:RabbitProperties相关配置 ★ AmqpAdmin的方法★ AmqpTemplate的方法代码演示创建一个springboot的项目。application.properties 配置属性 ★ Spri…...
网络链接失败怀疑是服务器处于非正常状态?如何用本地电脑查看服务器是否正常?
网络链接失败怀疑是服务器处于非正常状态?如何用本地电脑查看服务器是否正常? 网页会出现链接失败,可以实时用cdm大法,cdm可以更好的排查字节数据的返回,可以让我们更好的要检查服务器是否处于正常状态,接下…...

文件操作(打开关闭文件、文件顺序以及随机读写)
文章目录 写在前面1. 文件的打开与关闭1.1 文件指针1.2 文件的打开(fopen)与关闭(fclose)1.2.1 fopen函数1.2.2 fclose函数 2. 文件的顺序读写2.1. fgetc 和 fputc函数2.1.1 fputc函数2.1.2 fgetc函数 2.2 fgets 和 fputs函数2.2.1 fputs函数2.2.2 fgets函数 2.3 fscanf和fprin…...
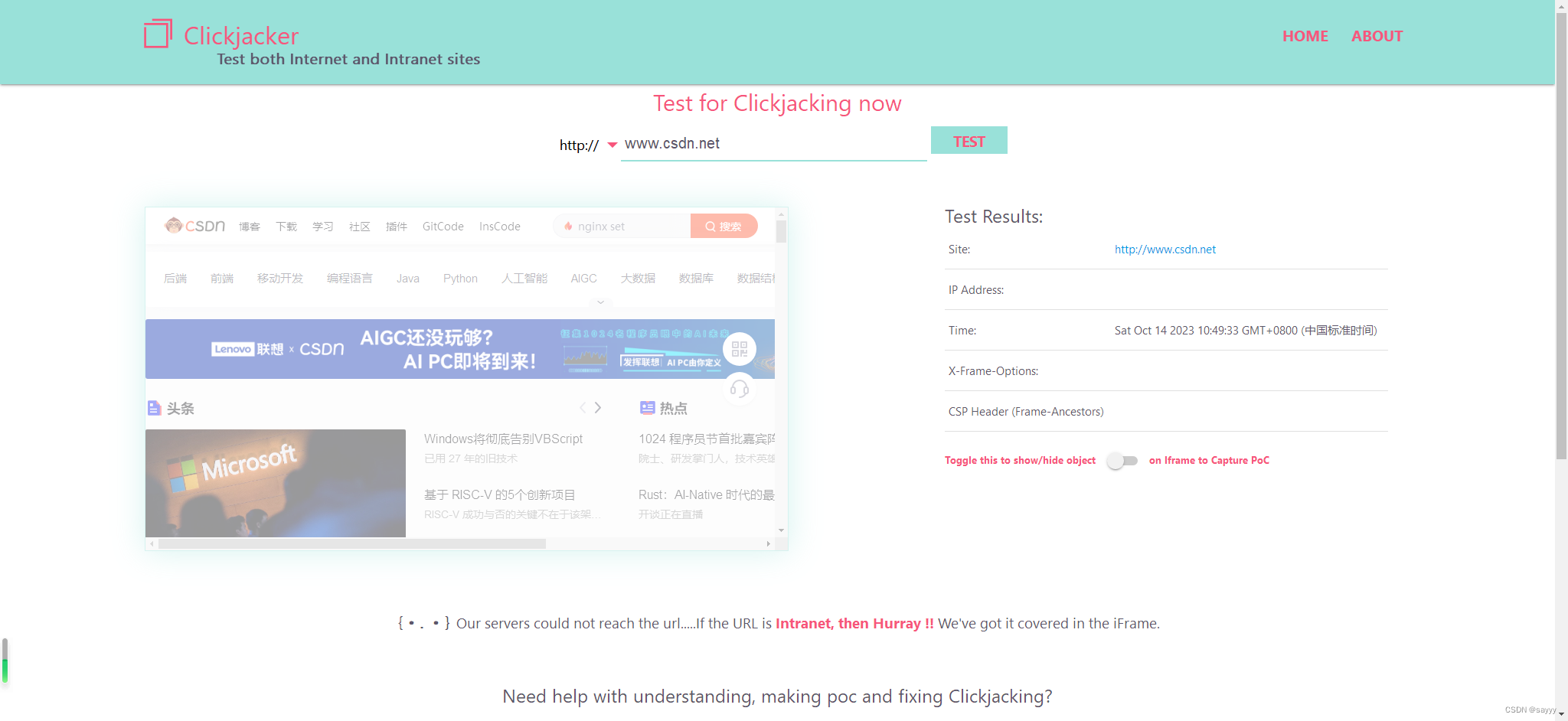
HTTP 响应头 X-Frame-Options
简介 X-Frame-Options HTTP 响应头用来给浏览器一个指示。该指示的作用为:是否允许页面在 <frame>, </iframe> 或者 <object> 中展现。 网站可以使用此功能,来确保自己网站的内容没有被嵌套到别人的网站中去,也从而避免了…...
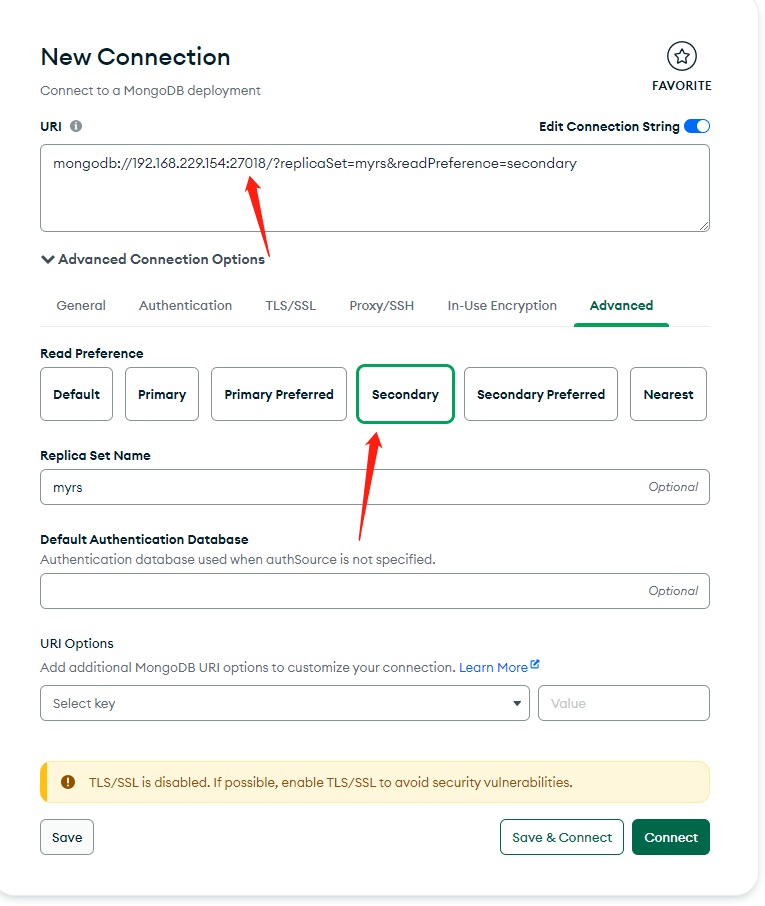
MongoDB 集群配置
一、副本集 Replica Sets 1.1 简介 MongoDB 中的副本集(Replica Set)是一组维护相同数据集的 mongod 服务。 副本集可提供冗余和高可用性,是所有生产部署的基础。 也可以说,副本集类似于有自动故障恢复功能的主从集群。通俗的讲就…...

探秘书匠策AI:毕业论文写作的“智慧引擎”
在学术探索的征途中,毕业论文如同一座巍峨的山峰,让无数学生既敬畏又向往。它不仅是对所学知识的综合检验,更是学术生涯的重要里程碑。然而,面对这座大山,许多人常常感到力不从心,选题迷茫、文献难觅、结构…...

51单片学习ing
现在能够实现LED闪烁了!! 开心 今天学习了让LED闪烁以及LED流水灯,主要是了解了软件延时计算器这个工具 现在可以更灵活的变换LED的变换速度了,如下: 接下来学习到了c语言里模块化的思想,之前学习c的时候…...

Mermaid Live Editor:5分钟快速创建专业图表的终极免费工具
Mermaid Live Editor:5分钟快速创建专业图表的终极免费工具 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-e…...

RIFE智能帧插值技术全解析:从原理到实战的视频流畅度提升指南
RIFE智能帧插值技术全解析:从原理到实战的视频流畅度提升指南 【免费下载链接】video2x A machine learning-based video super resolution and frame interpolation framework. Est. Hack the Valley II, 2018. 项目地址: https://gitcode.com/GitHub_Trending/v…...

「码动四季·开源同行」go语言:统一认证与授权如何保障服务安全
认证与授权对于当前的互联网应用是非常重要的基础功能:认证用于验证当前用户的身份,而授权意味着用户在认证成功后,会被系统授予访问系统资源的权限。只有具备相应身份和权限的人才能访问系统中的相应资源,比如在购物网站中你只能…...

r5:天气预测
- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/o-DaK6aQQLkJ8uE4YX1p3Q) 中的学习记录博客** - **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)** 文章目录 概要整体架构流程代码运行技术名词解释小…...

【GitHub项目推荐--Godogen:一句话生成完整 Godot 游戏的 AI 流水线】⭐⭐⭐
简介 Godogen 是一套基于 Claude Code 构建的自动化游戏开发流水线。它不仅仅是一个代码生成器,更是一个全栈的“AI 开发团队”:你只需用自然语言描述游戏创意,它便能自动完成架构设计、美术生成、代码编写、引擎截图、视觉质检的全流程…...

突破媒体捕获限制:猫抓cat-catch浏览器扩展全方位实战指南
突破媒体捕获限制:猫抓cat-catch浏览器扩展全方位实战指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓cat-catch是一款专注于网…...

基于SpringBoot + Vue的校园流浪动物救助平台
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...

MySQL数据恢复实战:从frm和ibd文件重建完整数据表
1. MySQL数据恢复实战:从frm和ibd文件重建完整数据表 数据库管理员最怕听到的就是"数据丢了"三个字。我经历过好几次半夜被叫起来处理数据丢失的紧急情况,那种头皮发麻的感觉至今难忘。不过别担心,只要.frm和.ibd文件还在ÿ…...