在 Elasticsearch 中实现自动完成功能 1:Prefix queries
自动完成与搜索功能不同 - 我们应该在用户键入下一个字符后立即更新自动完成选项,每秒都会访问数据库,过滤数百万条记录,而不会导致任何性能下降!
Elasticsearch 是一种可以轻松实现此类功能的技术,它是一种基于 Apache Lucene 库构建的搜索和分析引擎。 Elasticsearch 具有分布式、多租户架构,具有内置路由和重新平衡功能,使其易于扩展。 它是一种广泛使用的数据存储,用于存储、搜索和分析大量数据。
在这个由三部分组成的博客文章系列中,我将详细介绍如何使用 Elasticsearch 中提供的各种选项来实现自动完成功能。 在第一部分(即这篇文章)中,我们将讨论前缀查询 - prefix queries。 在第二部分中,我们将了解 n-grams,在最后部分中,我们将讨论 complete suggesters。
出于示例目的,我们将使用存储电影数据的索引。 为了简单起见,title 将是该索引中唯一存在的属性。 由于 Elasticsearch 为其操作公开了 REST 接口,因此你可以使用任何基于 REST 的工具与其进行通信。
本系列假设你对 Elasticsearch 有基本的了解。 如果你是 Elasticsearch 的新手,我强烈建议你阅读 “Elastic:开发者上手指南”。
那么让我们开始吧?
前缀查询 - Prefix queries
前缀查询是 Elasticsearch 中自动完成实现的最简单形式。 我们在存储字段时不做任何特殊的事情,大部分工作都是在查询时完成的。 该字段被索引(存储!)为一个简单的文本/关键字字段,并且允许我们根据传递的前缀匹配文档的查询用于查询它。
让我们创建一个索引来运行前缀查询:
PUT /movies
{"mappings": {"properties": {"title": {"type": "keyword","fields": {"analyzed_title": {"type": "text"}}}}}
}创建索引时,我们需要提供映射,指示我们打算存储的数据类型。 出于以下示例的目的,title 被映射为 keyword 字段,也被映射为支持全文查询的文本字段。 使用 Elasticsearch 的多字段功能可以将一个字段映射为多种类型。
keyword 字段和 text 字段之间的主要区别在于关键字字段不被分析,即我们传递到关键字字段的数据按原样存储。 对文本字段进行分析,即分词化、可能进行转换(例如小写、词干等),并存储在倒排索引中。 倒排索引是一种数据结构,用于存储从术语到它们出现的文档位置的映射,从而实现高效的全文搜索。有关 keyword 和 text 类型的区别,请详细参阅文档 “Elasticsearch:Text vs. Keyword - 它们之间的差异以及它们的行为方式”。
为了测试如何分析我们的数据,我们可以使用 _analyze API。 让我们看看我们的主标题字段将如何分析:
GET /movies/_analyze
{"text": "Chamber of Secrets","field": "title"
}上面命令的响应为:
{"tokens": [{"token": "Chamber of Secrets","start_offset": 0,"end_offset": 18,"type": "word","position": 0}]
}因此,它只返回一个 token。 为什么? 没错,就是因为它是关键字字段! 让我们测试一下我们 analyzed_title 的表现:
GET /movies/_analyze
{"text": "Chamber of Secrets","field": "title.analyzed_title"
}上面命令的响应为:
{"tokens": [{"token": "chamber","start_offset": 0,"end_offset": 7,"type": "<ALPHANUM>","position": 0},{"token": "of","start_offset": 8,"end_offset": 10,"type": "<ALPHANUM>","position": 1},{"token": "secrets","start_offset": 11,"end_offset": 18,"type": "<ALPHANUM>","position": 2}]
}正如所料,它被分解为三个 token。 此外,token 是小写的。 这是为什么? 因为,即使我们不指定任何分析器,默认的标准分析器也会应用于执行基于语法的标记化的文本字段,并且还将这些标记小写。 文本分析是一种高度可配置的过程,由一个或多个字符过滤器、分词器以及一个或多个在管道中运行的分词过滤器组成。 我们可以创建自己的分析器,也可以定制内置分析器。有关分词器的详细介绍,请阅读文章 “Elasticsearch: analyzer”。
让我们将一些哈利波特电影添加到我们的索引中,即让我们索引一些文档:
POST /movies/_doc
{"title": "Harry Potter and the Chamber of Secrets"
}POST /movies/_doc
{"title": "Harry Potter and the Prisoner of Azkaban"
}让我们尝试使用前缀查询来查询我们的主 title 字段(关键字)。 前缀查询是术语级别查询的一种,用于查询非分析字段。 我们将尝试两个不同的请求 - 第一个请求使用 title 中第一个单词的前缀,另一个请求使用标题中第二个单词的前缀:
GET /movies/_search?filter_path=**.hits
{"query": {"prefix": {"title": "Harr"}}
}上面的响应为:
{"hits": {"hits": [{"_index": "movies","_id": "er9oHIsByaLf0EuTh81O","_score": 1,"_source": {"title": "Harry Potter and the Chamber of Secrets"}},{"_index": "movies","_id": "e79oHIsByaLf0EuTjc3H","_score": 1,"_source": {"title": "Harry Potter and the Prisoner of Azkaban"}}]}
}我们做另外一个查询:
GET /movies/_search?filter_path=**.hits
{"query": {"prefix": {"title": "Pott"}}
}上述查询返回:
{"hits": {"hits": []}
}也即没有任何的结果。
tilte 是关键字字段,我们必须提供具有正确大小写的前缀。 如果我们在查询中传递 “harr”,它将不匹配。 第一个请求按预期返回上面索引的两个文档。 但第二个请求不会返回任何内容。 这是因为这个查询不支持中缀(在 title 中间匹配)匹配。
如果我们想在 title 内进行匹配,我们应该使用 match_phrase_prefix - 一种用于在分析的文本字段上进行前缀匹配的查询类型:
GET /movies/_search?filter_path=**.hits
{"query": {"match_phrase_prefix": {"title.analyzed_title": {"query": "pott"}}}
}上述命令返回的结果为:
{"hits": {"hits": [{"_index": "movies","_id": "er9oHIsByaLf0EuTh81O","_score": 0.18232156,"_source": {"title": "Harry Potter and the Chamber of Secrets"}},{"_index": "movies","_id": "e79oHIsByaLf0EuTjc3H","_score": 0.18232156,"_source": {"title": "Harry Potter and the Prisoner of Azkaban"}}]}
}当我们搜索 analyzed_title 时,“pott” 前缀与属于我们两个文档的标记 “potter” 匹配。 因此,两份文件均被召回。
前缀乱序怎么办? 由于 title 中的单词被分词,我们期望 “potter harry” 与两个文档匹配。 但这是一个短语前缀查询,它尊重输入的顺序。 如果我们想要无序匹配,我们可以使用 match_bool_prefix。
GET /movies/_search
{"query": {"match_phrase_prefix": {"title.analyzed_title": {"query": "potter harry"}}}
}上述查询将不会返回任何的结果。而如下的查询:
GET /movies/_search?filter_path=**.hits
{"query": {"match_bool_prefix": {"title.analyzed_title": {"query": "pott harr"}}}
}将返回如下的结果:
{"hits": {"hits": [{"_index": "movies","_id": "er9oHIsByaLf0EuTh81O","_score": 1,"_source": {"title": "Harry Potter and the Chamber of Secrets"}},{"_index": "movies","_id": "e79oHIsByaLf0EuTjc3H","_score": 1,"_source": {"title": "Harry Potter and the Prisoner of Azkaban"}}]}
}这就是我要讨论的使用前缀查询自动完成的全部内容。 在选择此作为实现自动完成功能的方法时,我们需要考虑一些事项:
- 这是最不推荐的方法,与其他自动完成(另外的两篇文章)实现相比,这种方法被认为是最慢的方法。 搜索速度很慢,因为我们在索引字段时没有做任何有助于自动完成查询的工作。 它被索引为一个简单的文本字段,将文档与查询文本进行匹配的大部分工作都是在搜索时完成的。 它将转到倒排索引并检查是否有任何标记以查询中提供的文本开头,这是一项昂贵的操作。
- 在 Elasticsearch 的最新版本中,为术语级别前缀查询添加了 index_prefixes 选项,该选项允许通过将前缀存储在单独的字段中来加速前缀查询。
- 如果你已经有一个工作索引并且不需要更新映射,那么前缀查询将是适合你的方法,因为自动完成不是系统中频繁使用的功能之一。 但如果是这样,那么你可能会遇到性能问题。 最好使用本系列下一部分中讨论的方法之一并重新索引数据。
如果你想了解这种方法的详细实现,请阅读 “Elasticsearch:创建一个 autocomplete 输入系统 - 前端 + 后端”。
相关文章:
在 Elasticsearch 中实现自动完成功能 1:Prefix queries
自动完成与搜索功能不同 - 我们应该在用户键入下一个字符后立即更新自动完成选项,每秒都会访问数据库,过滤数百万条记录,而不会导致任何性能下降! Elasticsearch 是一种可以轻松实现此类功能的技术,它是一种基于 Apac…...

『PyQt5-Qt Designer篇』| 13 Qt Designer中如何给工具添加菜单和工具栏?
13 Qt Designer中如何给工具添加菜单和工具栏? 1 创建默认窗口2 添加菜单栏3 查看和调用1 创建默认窗口 当新创建一个窗口的时候,默认会显示有:菜单栏和状态栏,如下: 可以在菜单栏上右键-移除菜单栏: 可以在菜单栏上右键-移除状态栏: 2 添加菜单栏 在窗口上,右键-创建…...
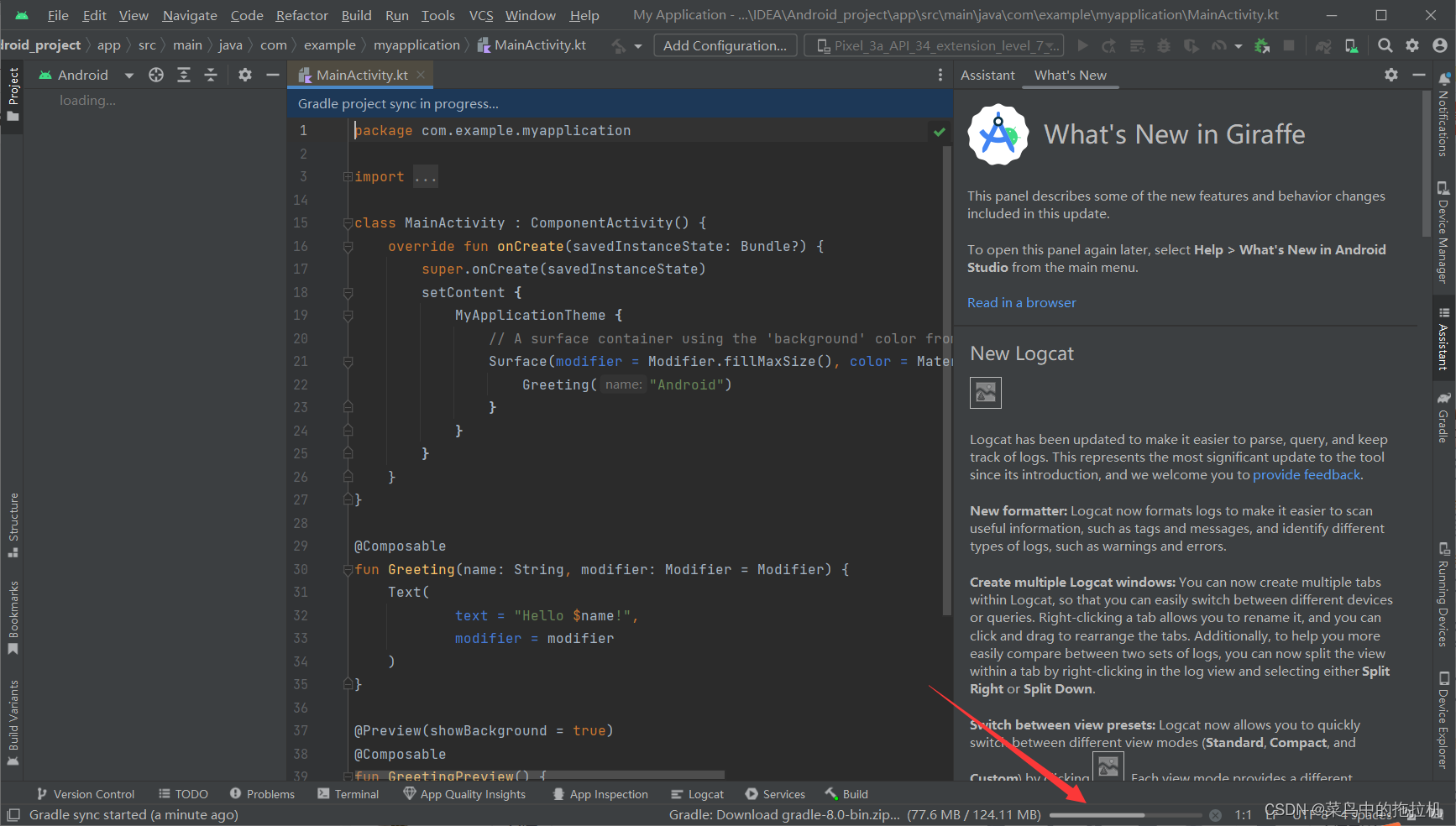
Android Studio新建项目教程
Android Studio新建项目教程 一、创建新项目 二、选择空白页项目类型 配置然后finish 等待项目完成初试化 等待初始化结束,创建完成...

前端页面布局之【响应式布局】
目录 🌟前言🌟优点🌟缺点🌟media兼容性🌟利用CSS3-Media Query实现响应式布局🌟常见的媒体类型🌟常见的操作符🌟属性值🌟设备检测🌟响应式阈值选取dz…...

定制排序小案例
案例:自定义 Book 类,里面包含 name 和 price,按 price 排序(从大到小)。 要求使用两种方式排序 , 有一个 Book[] books 4 本书对象. 使用前面学习过的传递 实现 Comparator 接口匿名内部类,也称为定制排序。 可以按照 price …...
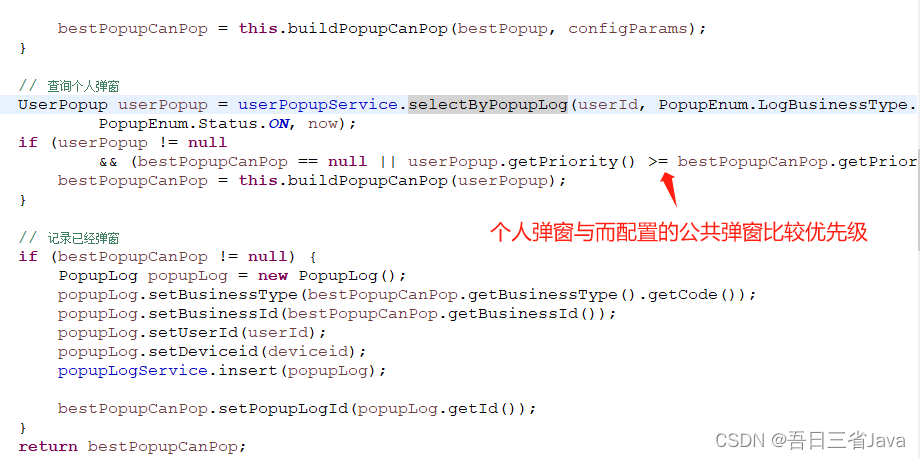
如何设计一个ToC的弹窗
本文主要分享了如何设计一个具有高可扩展性的弹窗功能。 本设计参考了优惠券功能的设计思路,有兴趣的朋友可以看看优惠券的分享:如何设计一个可扩展的优惠券功能_java优惠券系统设计-CSDN博客 一、需求介绍 假如你的项目需要实现以下弹窗,…...
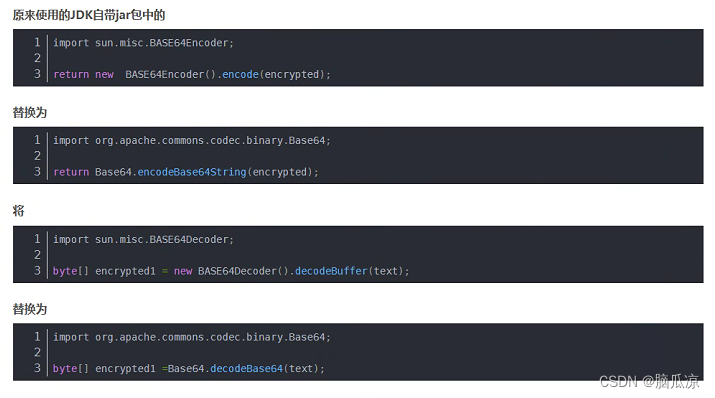
Idea执行Pom.xml导入jar包提示sun.misc.BASE64Encoder jar找不到---SpringCloud工作笔记197
奇怪之前都是好好的,这个是因为,jdk的版本不对,重新打开以后自动被选择成jdk11了...记录一下 原因是从jdk9的时候,这个jar包已经被删除了,所以会报错,如果你用的是jdk自带的这个jar包就会报错,那么还可以,修改,不让他用jdk的,让他用 用org.apache.commons.codec.binary.Base64…...

大数据面试题:Spark和Flink的区别
面试题来源: 《大数据面试题 V4.0》 大数据面试题V3.0,523道题,679页,46w字 可回答:1)Spark Streaming和Flink的区别 问过的一些公司:杰创智能科技(2022.11),阿里蚂蚁(2022.11)&…...
 等级考试试卷(二级))
2023年9月青少年软件编程(C 语言) 等级考试试卷(二级)
2023年9月青少年软件编程(C 语言) 等级考试试卷(二级) 编程题 1.数组指定部分逆序重放 题目描述 将一个数组中的前k项按逆序重新存放。 例如,将数组8,6,5,4,1前3项逆序重放得到5,6,8,4,1。 输入 输入为两行ÿ…...

【Wifi】Wifi架构介绍
Wifi架构介绍 本文基于Android介绍其Wifi架构。Wifi是许多操作系统提供的重要功能之一,特别是越来越多的车载系统wifi是其必备功能。为啥wifi是必备功能? 一方面是传统的上网(现在有些车载使用DCM模块管理网络),另一方…...

攻防世界数据逆向 2023
https://adworld.xctf.org.cn/contest/list?rwNmOdr1697354606875 目录 请求数据参数加密 cookie加密 响应数据解密 代码 请求数据参数加密 我们可以根据请求的关键字qmze1yzvhyzcyyjr获取到对应的加密地方 可以看到使用了函数_0x1dc70进行了加密 cookie加密 该步骤需…...
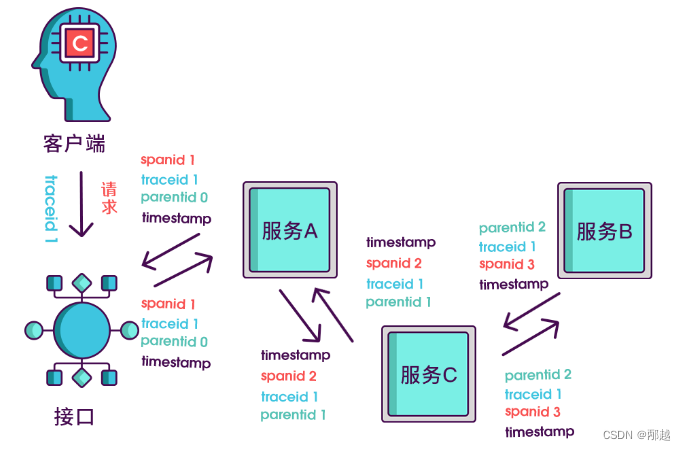
分布式链路追踪如何跨线程
背景 我们希望实现全链路信息,但是代码中一般都会异步的线程处理。 解决思路 我们可以对以前的 Runable 和 Callable 进行增强。 可以使用 ali 已经存在的实现方式。 TransmittableThreadLocal (TTL) 解决异步执行时上下文传递的问题 核心的实现思路如下&#…...

怎样在线修剪音频文件了?【免费,无须注册】
怎样在线修剪音频文件了? 推荐一个免费网址,且不用任何注册,直接可以使用 https://mp3cut.net/cn/ 上传音频文件, 拖动前后滚动条,对音频文件进行修剪。 修剪完成,可以保存如下格式 enjoy!! 作者简介…...

iMeta框架使用方法
📢📢📢📣📣📣 哈喽!大家好,我是「奇点」,江湖人称 singularity。刚工作几年,想和大家一同进步🤝🤝 一位上进心十足的【Java ToB端大厂…...
视频编辑软件 Premiere Pro 2024 macv24.0中文版 (pr2024)
Premiere Pro 2024 mac编辑任何现代格式的素材,从8K到虚拟现实。广泛的原生文件支持和简单的代理工作流程可以轻松使用您的媒体,即使在移动工作站上也是如此。提供针对任何屏幕或平台优化的内容比以往任何时候都快。 Premiere Pro 2024 Mac版软件介绍 视…...

C/C++:双向队列的实现
/** * * Althor:Hacker Hao * Create:2023.10.11 * */#include <bits/stdc.h> using namespace std; #define MAXSIZE 200 typedef struct Deque {int front; //头int rear; //尾int num; //队列中的元素数量int arr[MAXSIZE]; //队列中存储的数字 };Deque…...
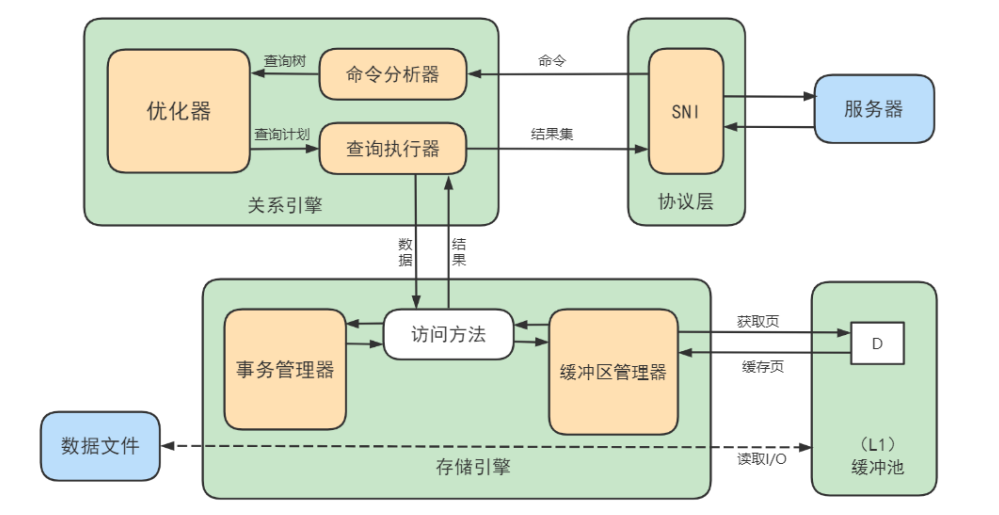
MySQL逻辑架构
文章目录 逻辑架构剖析1. 连接层2. 服务层3. 引擎层4. 存储层 SQL执行流程1. MySQL中的 SQL执行流程(理论)2. MySQL8中的 SQL 执行流程(实践)确认profiling 是否开启多次执行相同SQL查询查看profiles查看profile 3. SQL语法顺序 数…...
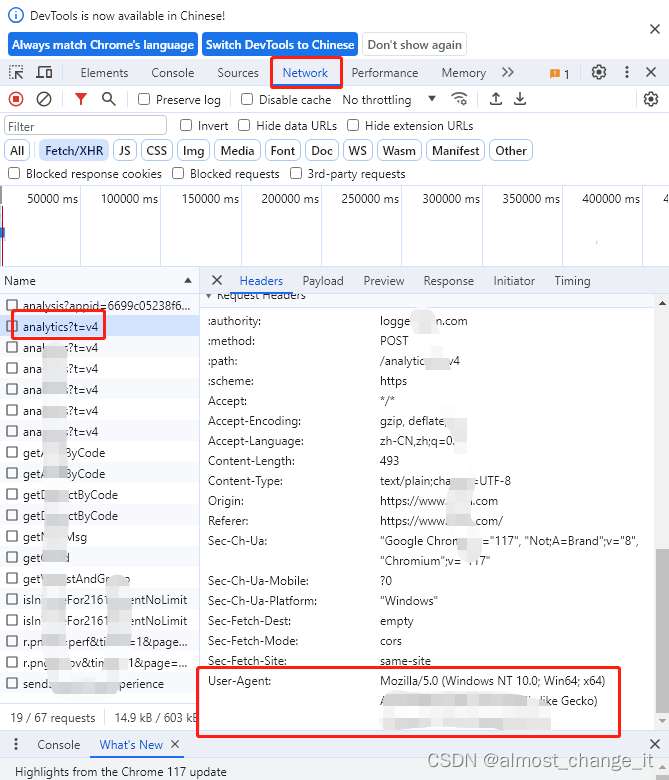
python爬虫练手项目之获取某地企业名录
因为很多网站都增加了登录验证,所以需要添加一段利用cookies跳过登陆验证码的操作 import pandas as pd import requests from lxml import etree # 通过Chrome浏览器F12来获取cookies,agent,headers cookies {ssxmod_itna2:eqfx0DgQGQ0QGDC…...
)
Python —— 接口自动化(1)
1、接口测试的基础概述 1、接口测试的方式 1、主流的工具类型 - jmeter,postman,apifox,fastapi,apipost.... 2、公开的自动化平台 - metersphere,yapi.... 3、公司内部自研平台 - 4、全面使用代码自己去完成框架搭建,项目实战.... 不论是平台还是工具࿰…...
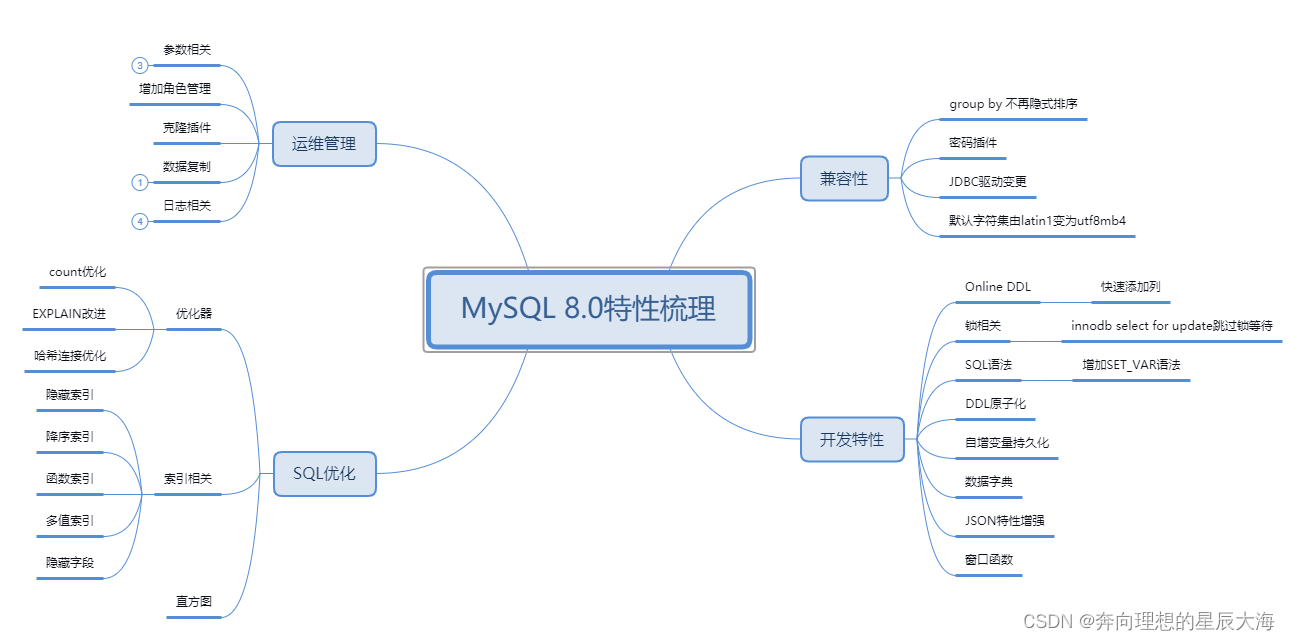
【MySQL】关于MySQL升级到8.0版本的实践方案
关于MySQL升级到8.0版本的实践方案 关于数据库版本升级,一直都是热议话题,对于升级的缘由各家也有所不同,有业务驱动的,有DBA自发驱动的,有规划导向也有方向指引的……抛开各种原因,当升级这个决定落下来的时候,对于DBA手头的几百几千套数据库来说,就好比是一场动物大…...

如何将笔记从 iCloud 传输到 iPhone:分步指南
iPhone 上的“备忘录”应用是一款便捷的工具,可以用来记录待办事项、日记、想法等等。它能帮助我们追踪需要完成的事情。借助 iCloud 的自动同步功能,你的备忘录可以安全地存储在云端,并可通过任何 Apple 设备甚至电脑访问。将笔记从 iPhone …...

March7thAssistant:崩坏:星穹铁道企业级自动化解决方案
March7thAssistant:崩坏:星穹铁道企业级自动化解决方案 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 【核心价值定位】游戏工作室效率倍增引…...

Calypso vs PC-DMIS:三坐标两大软件脱机编程实战对比与选型指南
Calypso vs PC-DMIS:三坐标测量软件脱机编程深度对比与实战选型策略 在精密制造领域,三坐标测量机(CMM)的脱机编程能力直接决定了检测效率与资源利用率。作为行业两大标杆,蔡司Calypso与海克斯康PC-DMIS在用户界面设计、编程逻辑、仿真验证等…...

终极指南:如何在NixOS上完美打包与使用SilentSDDM主题
终极指南:如何在NixOS上完美打包与使用SilentSDDM主题 【免费下载链接】SilentSDDM A very customizable SDDM theme that actually looks good. 项目地址: https://gitcode.com/gh_mirrors/si/SilentSDDM SilentSDDM是一款高度可定制且视觉精美的SDDM登录主…...

企微API集成指南——从回调到主动发送,全流程代码解析
企业微信提供了丰富的API,用于接收用户添加事件、发送消息、管理标签等。今天从实战角度,给出API集成的最佳实践,附带伪代码。一、核心API清单API用途频率限制获取access_token调用其他API的前提2000次/分钟添加外部联系人通过好友每个号300人…...

BVH构建优化:四种分割算法在光线追踪中的性能对比
1. BVH分割算法基础概念 当你在玩3D游戏时,有没有想过为什么场景中的物体能够如此快速地渲染出来?这背后就离不开BVH(边界体积层次结构)技术的支持。简单来说,BVH就像是一个高效的"物体分类系统",…...
)
车载Android Auto兼容性开发全链路(车规级Java SDK集成手册)
第一章:车载Android Auto兼容性开发全链路概览Android Auto 是 Google 提供的车载信息娱乐系统集成框架,其兼容性开发并非仅限于应用层适配,而是一条横跨设备端、车机系统、认证流程与用户交互的完整技术链路。开发者需同步关注 Android 应用…...

LimeReport:终极跨平台Qt报表生成解决方案
LimeReport:终极跨平台Qt报表生成解决方案 【免费下载链接】LimeReport Report generator for Qt Framework 项目地址: https://gitcode.com/gh_mirrors/li/LimeReport LimeReport 是一款专为 Qt 开发者设计的开源报表生成库,提供完整的报表设计、…...

STM32串口通信实战指南与常见问题解析
1. 串口通信基础概念解析串口通信作为嵌入式系统中最基础也最常用的通信方式之一,其核心原理是通过单根数据线按位顺序传输数据。与并行通信相比,虽然传输速率较低,但具有布线简单、成本低廉、传输距离远等显著优势。在实际工程应用中&#x…...

R16增强型Type II码本:空频域联合压缩与量化反馈机制解析
1. R16增强型Type II码本的技术背景 在5G Massive MIMO系统中,信道状态信息(CSI)反馈的精度和效率直接影响着系统性能。R15 Type II码本虽然已经实现了空域压缩,但随着频段向毫米波延伸和天线规模扩大,传统方案面临反馈…...