Flink Log4j 2.x使用Filter过滤日志类型
Flink Log4j 2.x使用Filter过滤日志类型(区别INFO、ERROR)
文章目录
- Flink Log4j 2.x使用Filter过滤日志类型(区别INFO、ERROR)
- ThresholdFilter
- LevelMatchFilter
日志级别:
ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF
log4j官网:
https://logging.apache.org/log4j/2.x/index.html
ThresholdFilter
在官网中,有一个Filters的组件。Filters组件允许对日志事件进行评估,以确定是否或如何发布它们。Filter将在其过滤器方法之一上被调用,并将返回一个Result,这是一个Enum,具有3个值之一- ACCEPT, DENY或NEUTRAL。
如果LogEvent中的级别与配置的级别相同或更具体,则此过滤器返回onMatch结果,否则返回onMismatch值。例如,如果ThresholdFilter配置了ERROR级别,并且LogEvent包含DEBUG级别,那么onMismatch值将被返回,因为ERROR事件比DEBUG事件更高。
ThresholdFilter过滤器的原理是,如果LogEvent的日志级别被配置的高,则会执行onMatch,否则执行onMismatch。比如如果ThresholdFilter配置了INFO级别,而LogEvent是WARN、ERROR级别,那么onMatch值将会执行。而当LogEvent是DEBUG级别时,则onMismatch值将会执行。
这里有一个Threshold的过滤器,参数包含了:
- Level:要匹配的有效日志级别。
- onMatch: 当过滤器匹配时要采取的操作。可以是ACCEPT, DENY或NEUTRAL。缺省值为NEUTRAL。
- onMismatch:当过滤器不匹配时采取的操作。可以是ACCEPT, DENY或NEUTRAL。缺省值为DENY。
借助于这个Threshold过滤器,可以初步实现过滤日志的功能:
显示info 级别的日志
appender.rolling.filter.threshold.type = ThresholdFilter
appender.rolling.filter.threshold.level = ERROR
appender.rolling.filter.threshold.onMatch = DENY
appender.rolling.filter.threshold.onMismatch = ACCEPT
由于log4j.properties的rootLogger.level = INFO,因此最小的日志级别就已经是INFO了,所以上面的配置可以保证当前appender的输出日志只包含INFO信息。相当于是对ERROR及以上级别的日志执行onMatch=>DENY,而对小于ERROR级别,也就是INFO级别,执行onMismatch => ACCEPT。
或者xml的配置方式:
<RollingFile name="RollingFileInfo" fileName="${logFilePath}/${logFileName}-info.log"filePattern="${logFilePath}/$${date:yyyy-MM}/${logFileName}-%d{yyyy-MM-dd}_%i.log.gz"><Filters><!-- onMatch:Action to take when the filter matches. The default value is NEUTRAL --><!-- onMismatch: Action to take when the filter does not match. The default value is DENY --><!-- 级别在 ERROR 之上的都拒绝输出 --><!-- 在组合过滤器中,接受使用 NEUTRAL(中立),被第一个过滤器接受的日志信息,会继续用后面的过滤器进行过滤,只有符合所有过滤器条件的日志信息,才会被最终写入日志文件 --><ThresholdFilter level="ERROR" onMatch="DENY" onMismatch="NEUTRAL"/><ThresholdFilter level="INFO" onMatch="ACCEPT" onMismatch="DENY"/></Filters><PatternLayout pattern="%d{yyyy.MM.dd HH:mm:ss z} %-5level %class{36} %L %M - %msg%xEx%n"/><Policies><TimeBasedTriggeringPolicy/><SizeBasedTriggeringPolicy size="30MB"/></Policies></RollingFile>
这种方式看着总感觉有点别扭,那有没有其他的Filter组件能更好地支持呢?
LevelMatchFilter
查询资料发现,有一个LevelMatchFilter的过滤器组件,其执行原理是:
如果日志级别等于${指定的日志级别},则onMatch,否则onMismatch
刚好符合我们的需求,于是此时,log4j.properties的配置文件就可以变成:
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################# Allows this configuration to be modified at runtime. The file will be checked every 30 seconds.
monitorInterval=30# This affects logging for both user code and Flink# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.rolling.ref = RollingFileAppender
rootLogger.appenderRef.errorLogFile.ref = errorLogFile# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = true
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.policies.startup.type = OnStartupTriggeringPolicy
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = ${env:MAX_LOG_FILE_NUMBER:-10}
appender.rolling.filter.threshold.type = LevelMatchFilter
appender.rolling.filter.threshold.level = INFO
appender.rolling.filter.threshold.onMatch = ACCEPT
appender.rolling.filter.threshold.onMisMatch = DENYappender.errorFile.name = errorLogFile
appender.errorFile.type = RollingFile
appender.errorFile.append = true
appender.errorFile.fileName = ${sys:log.file}.err
appender.errorFile.filePattern = ${sys:log.file}.err.%i
appender.errorFile.layout.type = PatternLayout
appender.errorFile.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.errorFile.policies.type = Policies
appender.errorFile.policies.size.type = SizeBasedTriggeringPolicy
appender.errorFile.policies.size.size = 100MB
appender.errorFile.policies.startup.type = OnStartupTriggeringPolicy
appender.errorFile.strategy.type = DefaultRolloverStrategy
appender.errorFile.strategy.max = ${env:MAX_LOG_FILE_NUMBER:-10}
appender.errorFile.filter.threshold.type = LevelMatchFilter
appender.errorFile.filter.threshold.level = ERROR
appender.errorFile.filter.threshold.onMatch = ACCEPT
appender.errorFile.filter.threshold.onMisMatch = DENY# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF大家如果在部署flink任务时有类似的需求,可以参考上面的配置进行修改,实际上主要添加的只有filter.threshold配置参数即可。
分享一些讲解比较好的相关文章:
log4j2使用filter过滤日志
Log4j2 将不同线程不同级别日志输出到不同的文件中
log4j2中LevelRangeFilter的注意点
Log4j2的Filters配置
相关文章:

Flink Log4j 2.x使用Filter过滤日志类型
Flink Log4j 2.x使用Filter过滤日志类型(区别INFO、ERROR) 文章目录 Flink Log4j 2.x使用Filter过滤日志类型(区别INFO、ERROR)ThresholdFilterLevelMatchFilter 日志级别: ALL < TRACE < DEBUG < INFO < …...
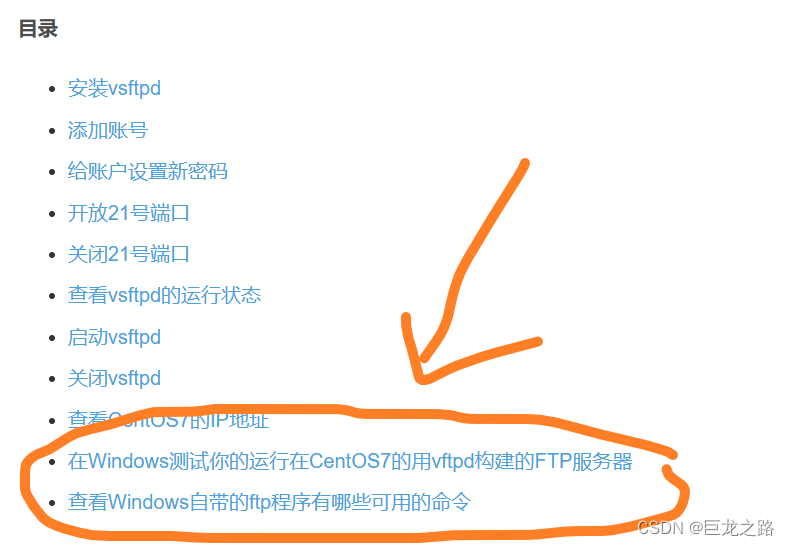
Ubuntu下怎么配置vsftpd
2023年10月12日,周四中午 目录 首先要添加一个系统用户然后设置这个系统用户的密码给新创建的系统用户创建主目录启动vsftpd服务查看vsftpd服务的状态打开外界访问vsftpd服务所需的端口获取服务器的IP地址大功告成 首先要添加一个系统用户 useradd 用户名然后设置…...

链表(7.27)
3.3 链表的实现 3.3.1头插 原理图: newnode为新创建的节点 实现: //头插 //让新节点指向原来的头指针(节点),即新节点位于开头 newnode->next plist; //再让头指针(节点)指向新节点&#…...
在 Elasticsearch 中实现自动完成功能 1:Prefix queries
自动完成与搜索功能不同 - 我们应该在用户键入下一个字符后立即更新自动完成选项,每秒都会访问数据库,过滤数百万条记录,而不会导致任何性能下降! Elasticsearch 是一种可以轻松实现此类功能的技术,它是一种基于 Apac…...

『PyQt5-Qt Designer篇』| 13 Qt Designer中如何给工具添加菜单和工具栏?
13 Qt Designer中如何给工具添加菜单和工具栏? 1 创建默认窗口2 添加菜单栏3 查看和调用1 创建默认窗口 当新创建一个窗口的时候,默认会显示有:菜单栏和状态栏,如下: 可以在菜单栏上右键-移除菜单栏: 可以在菜单栏上右键-移除状态栏: 2 添加菜单栏 在窗口上,右键-创建…...
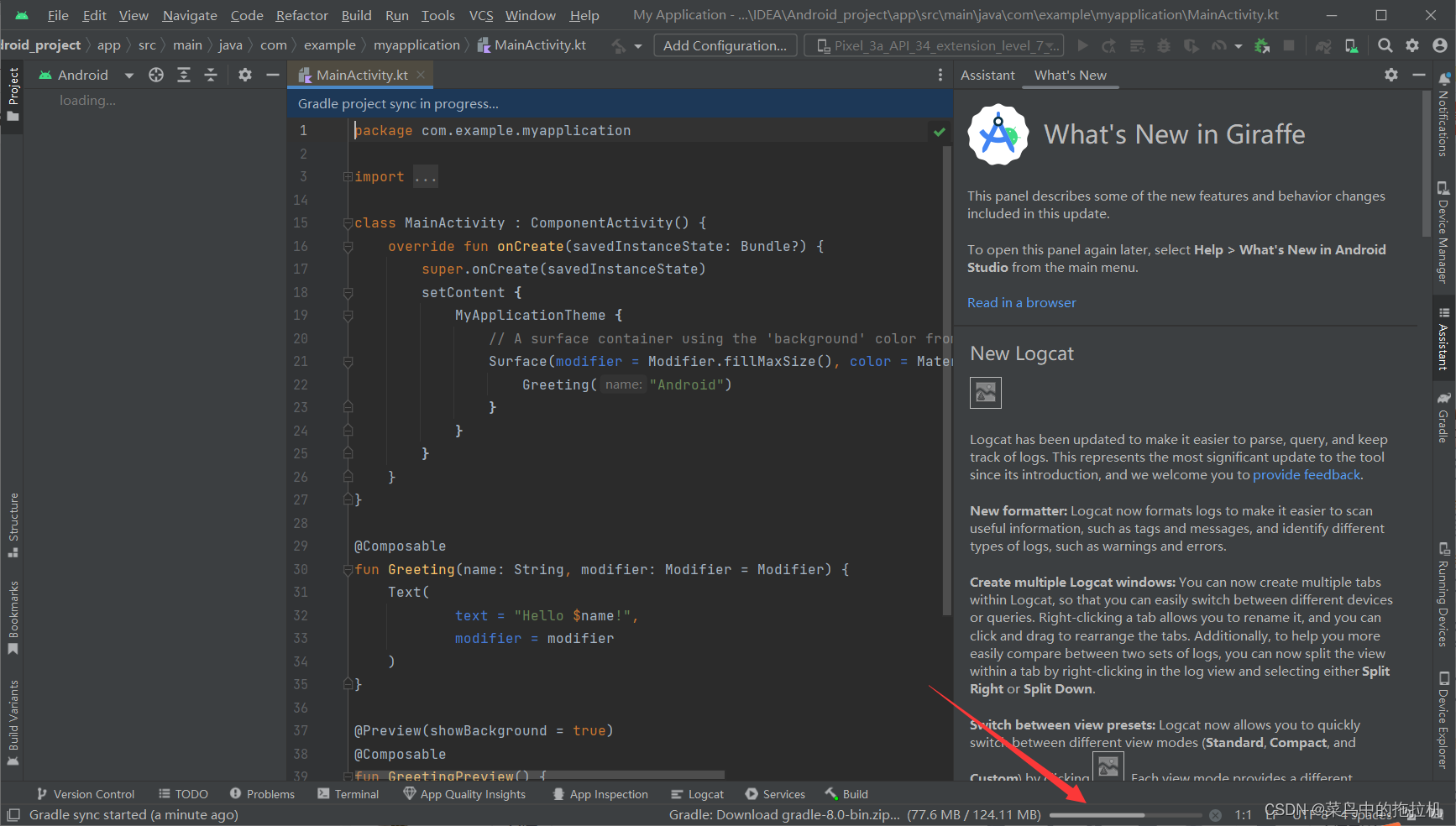
Android Studio新建项目教程
Android Studio新建项目教程 一、创建新项目 二、选择空白页项目类型 配置然后finish 等待项目完成初试化 等待初始化结束,创建完成...

前端页面布局之【响应式布局】
目录 🌟前言🌟优点🌟缺点🌟media兼容性🌟利用CSS3-Media Query实现响应式布局🌟常见的媒体类型🌟常见的操作符🌟属性值🌟设备检测🌟响应式阈值选取dz…...

定制排序小案例
案例:自定义 Book 类,里面包含 name 和 price,按 price 排序(从大到小)。 要求使用两种方式排序 , 有一个 Book[] books 4 本书对象. 使用前面学习过的传递 实现 Comparator 接口匿名内部类,也称为定制排序。 可以按照 price …...
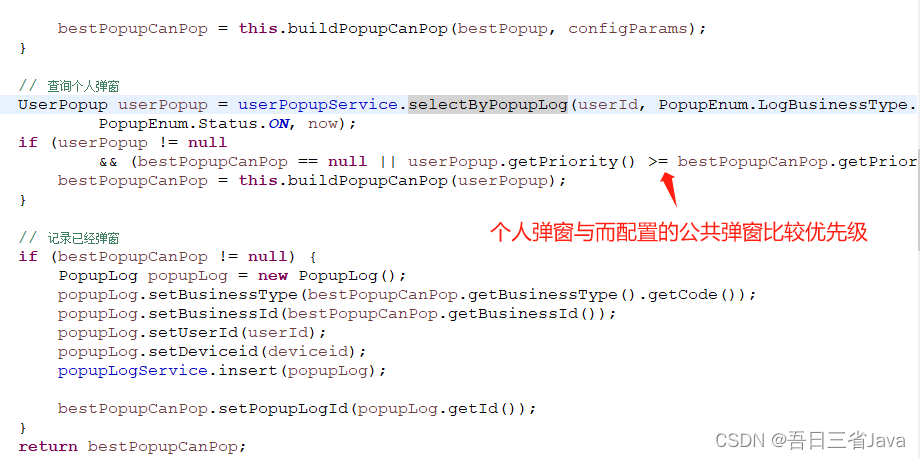
如何设计一个ToC的弹窗
本文主要分享了如何设计一个具有高可扩展性的弹窗功能。 本设计参考了优惠券功能的设计思路,有兴趣的朋友可以看看优惠券的分享:如何设计一个可扩展的优惠券功能_java优惠券系统设计-CSDN博客 一、需求介绍 假如你的项目需要实现以下弹窗,…...
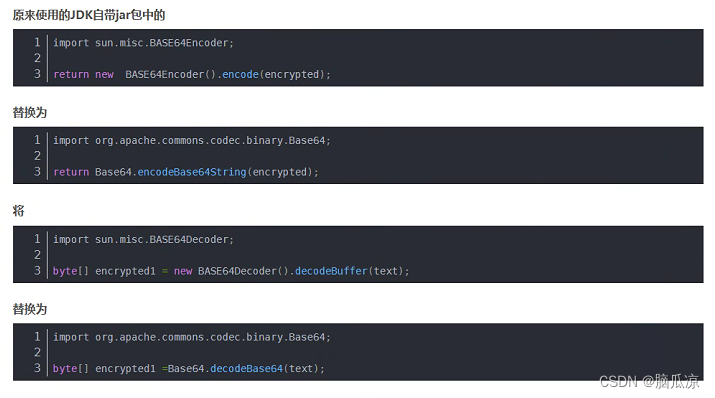
Idea执行Pom.xml导入jar包提示sun.misc.BASE64Encoder jar找不到---SpringCloud工作笔记197
奇怪之前都是好好的,这个是因为,jdk的版本不对,重新打开以后自动被选择成jdk11了...记录一下 原因是从jdk9的时候,这个jar包已经被删除了,所以会报错,如果你用的是jdk自带的这个jar包就会报错,那么还可以,修改,不让他用jdk的,让他用 用org.apache.commons.codec.binary.Base64…...

大数据面试题:Spark和Flink的区别
面试题来源: 《大数据面试题 V4.0》 大数据面试题V3.0,523道题,679页,46w字 可回答:1)Spark Streaming和Flink的区别 问过的一些公司:杰创智能科技(2022.11),阿里蚂蚁(2022.11)&…...
 等级考试试卷(二级))
2023年9月青少年软件编程(C 语言) 等级考试试卷(二级)
2023年9月青少年软件编程(C 语言) 等级考试试卷(二级) 编程题 1.数组指定部分逆序重放 题目描述 将一个数组中的前k项按逆序重新存放。 例如,将数组8,6,5,4,1前3项逆序重放得到5,6,8,4,1。 输入 输入为两行ÿ…...

【Wifi】Wifi架构介绍
Wifi架构介绍 本文基于Android介绍其Wifi架构。Wifi是许多操作系统提供的重要功能之一,特别是越来越多的车载系统wifi是其必备功能。为啥wifi是必备功能? 一方面是传统的上网(现在有些车载使用DCM模块管理网络),另一方…...

攻防世界数据逆向 2023
https://adworld.xctf.org.cn/contest/list?rwNmOdr1697354606875 目录 请求数据参数加密 cookie加密 响应数据解密 代码 请求数据参数加密 我们可以根据请求的关键字qmze1yzvhyzcyyjr获取到对应的加密地方 可以看到使用了函数_0x1dc70进行了加密 cookie加密 该步骤需…...
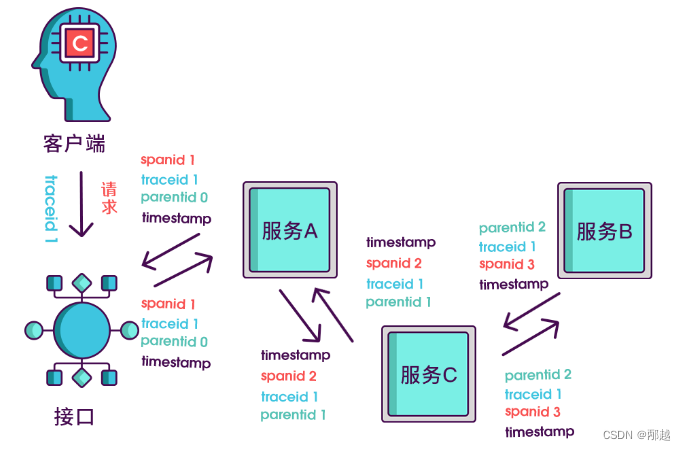
分布式链路追踪如何跨线程
背景 我们希望实现全链路信息,但是代码中一般都会异步的线程处理。 解决思路 我们可以对以前的 Runable 和 Callable 进行增强。 可以使用 ali 已经存在的实现方式。 TransmittableThreadLocal (TTL) 解决异步执行时上下文传递的问题 核心的实现思路如下&#…...

怎样在线修剪音频文件了?【免费,无须注册】
怎样在线修剪音频文件了? 推荐一个免费网址,且不用任何注册,直接可以使用 https://mp3cut.net/cn/ 上传音频文件, 拖动前后滚动条,对音频文件进行修剪。 修剪完成,可以保存如下格式 enjoy!! 作者简介…...

iMeta框架使用方法
📢📢📢📣📣📣 哈喽!大家好,我是「奇点」,江湖人称 singularity。刚工作几年,想和大家一同进步🤝🤝 一位上进心十足的【Java ToB端大厂…...
视频编辑软件 Premiere Pro 2024 macv24.0中文版 (pr2024)
Premiere Pro 2024 mac编辑任何现代格式的素材,从8K到虚拟现实。广泛的原生文件支持和简单的代理工作流程可以轻松使用您的媒体,即使在移动工作站上也是如此。提供针对任何屏幕或平台优化的内容比以往任何时候都快。 Premiere Pro 2024 Mac版软件介绍 视…...

C/C++:双向队列的实现
/** * * Althor:Hacker Hao * Create:2023.10.11 * */#include <bits/stdc.h> using namespace std; #define MAXSIZE 200 typedef struct Deque {int front; //头int rear; //尾int num; //队列中的元素数量int arr[MAXSIZE]; //队列中存储的数字 };Deque…...
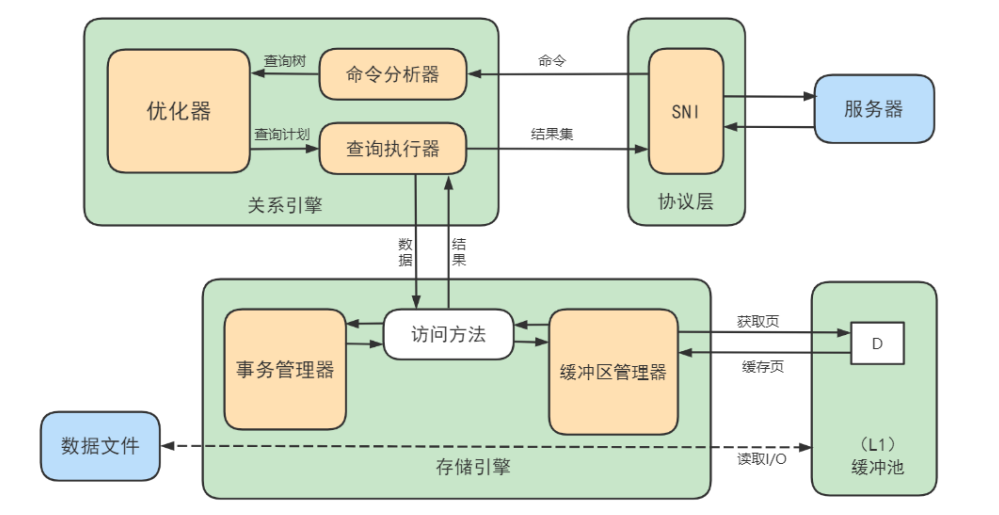
MySQL逻辑架构
文章目录 逻辑架构剖析1. 连接层2. 服务层3. 引擎层4. 存储层 SQL执行流程1. MySQL中的 SQL执行流程(理论)2. MySQL8中的 SQL 执行流程(实践)确认profiling 是否开启多次执行相同SQL查询查看profiles查看profile 3. SQL语法顺序 数…...

Ku频段相控阵天线避坑指南:从G/T骤降到EIRP波动,这些实测数据你要知道
Ku频段相控阵天线性能衰减实测:60离轴角下的G/T与EIRP工程修正策略 相控阵天线在卫星通信领域正经历从实验室到工程应用的跨越式发展。当无人机以60离轴角追踪卫星时,实测数据显示天线增益可能骤降4.5dB——这个数字足以让精心计算的链路预算彻底失效。在…...
)
告别配置迷茫!手把手教你用DaVinci Configurator配置Autosar NvM Block(含三种类型详解)
告别配置迷茫!手把手教你用DaVinci Configurator配置Autosar NvM Block(含三种类型详解) 在汽车电子开发中,非易失性存储(NVM)的配置往往是工程师们最头疼的环节之一。面对复杂的AUTOSAR存储协议栈…...

OpenClaw是什么?OpenClaw能做什么?OpenClaw详细介绍及保姆级部署教程-周红伟
1. 什么是 OpenClaw? 1.1 核心定义 OpenClaw(前身为 Clawdbot/Moltbot)是一款开源、本地优先、可执行任务的 AI 自动化代理引擎,遵循 MIT 协议。它以自然语言指令为驱动,在本地或私有云环境中完成文件操作、流程编排…...

Qwen3.5-9B实战案例:用128K上下文做法律合同比对与风险提示
Qwen3.5-9B实战案例:用128K上下文做法律合同比对与风险提示 1. 项目概述 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,在专业领域的逻辑推理和长文本处理方面表现出色。本文将重点展示如何利用其128K tokens的超长上下文能力,实现法律合…...

保姆级避坑指南:在Windows上用VirtualBox 6.0.24跑Ubuntu,从开机报错到完美显示的完整流程
从开机报错到完美显示:VirtualBox 6.0.24运行Ubuntu全流程实战手册 当你第一次在Windows上用VirtualBox启动Ubuntu虚拟机时,那个刺眼的报错提示可能会让你措手不及。别担心,这几乎是每个虚拟化新手都会经历的"成人礼"。本文将带你完…...

【Java边缘运行时部署终极指南】:20年专家亲授5大避坑法则与3步极速上线实战
第一章:Java边缘运行时部署全景认知与演进脉络Java在边缘计算场景中的运行时部署正经历从传统云中心化架构向轻量、自治、低延迟方向的深刻演进。早期Java应用依赖完整JDK和重量级容器(如Tomcat)部署于虚拟机或Kubernetes集群,难以…...
)
从MP3到微信语音:一份完整的Java音频格式转换工具链搭建指南(附FFmpeg与silk_v3_encoder配置)
Java音频处理实战:构建MP3到微信语音的高效转换工具链 引言 在即时通讯应用开发中,音频消息的处理一直是技术难点之一。特别是当我们需要将常见的MP3格式转换为微信、QQ等平台专用的SILK编码格式时,开发者往往需要跨越多个技术环节。本文将带…...

【LangGraph】 官方demo调整为本地大模型实现
官网文档链接: https://docs.langchain.com/oss/python/langgraph/quickstart#full-code-example 样例代码: # 第一步:定义工具与大模型 # 导入LangChain工具装饰器,用于将普通函数封装为Agent可调用的工具 from langchain.tool…...

基于COMSOL光学仿真的光子晶体光纤与微纳光学研究
comsol光学仿真光子晶体光纤,comsol光学方方向COMLOS微纳光学,仿真双芯光子晶体光,锥形光纤 光子晶体光光纤滤波器等,bpm,rsoft,fullware,论文复现在光学仿真领域,COMSOL Multiphysi…...
)
当BFD不可用时:用华为NQA+静态路由实现低成本链路监测(含ICMP测试例详解)
华为NQA静态路由:低成本链路监测的实战指南 在传统企业网络中,静态路由因其配置简单、资源消耗低的特点,常被用于小型网络或边缘设备互联。但静态路由最大的痛点在于缺乏自动检测机制——当链路出现故障时,管理员往往要等到用户投…...