Hadoop3教程(十二):MapReduce中Shuffle机制的概述
文章目录
- (95) Shuffle机制
- 什么是shuffle?
- Map阶段
- Reduce阶段
- 参考文献
(95) Shuffle机制
面试的重点
什么是shuffle?
Map方法之后,Reduce方法之前的这段数据处理过程,就叫做shuffle,中文直译"洗牌"。
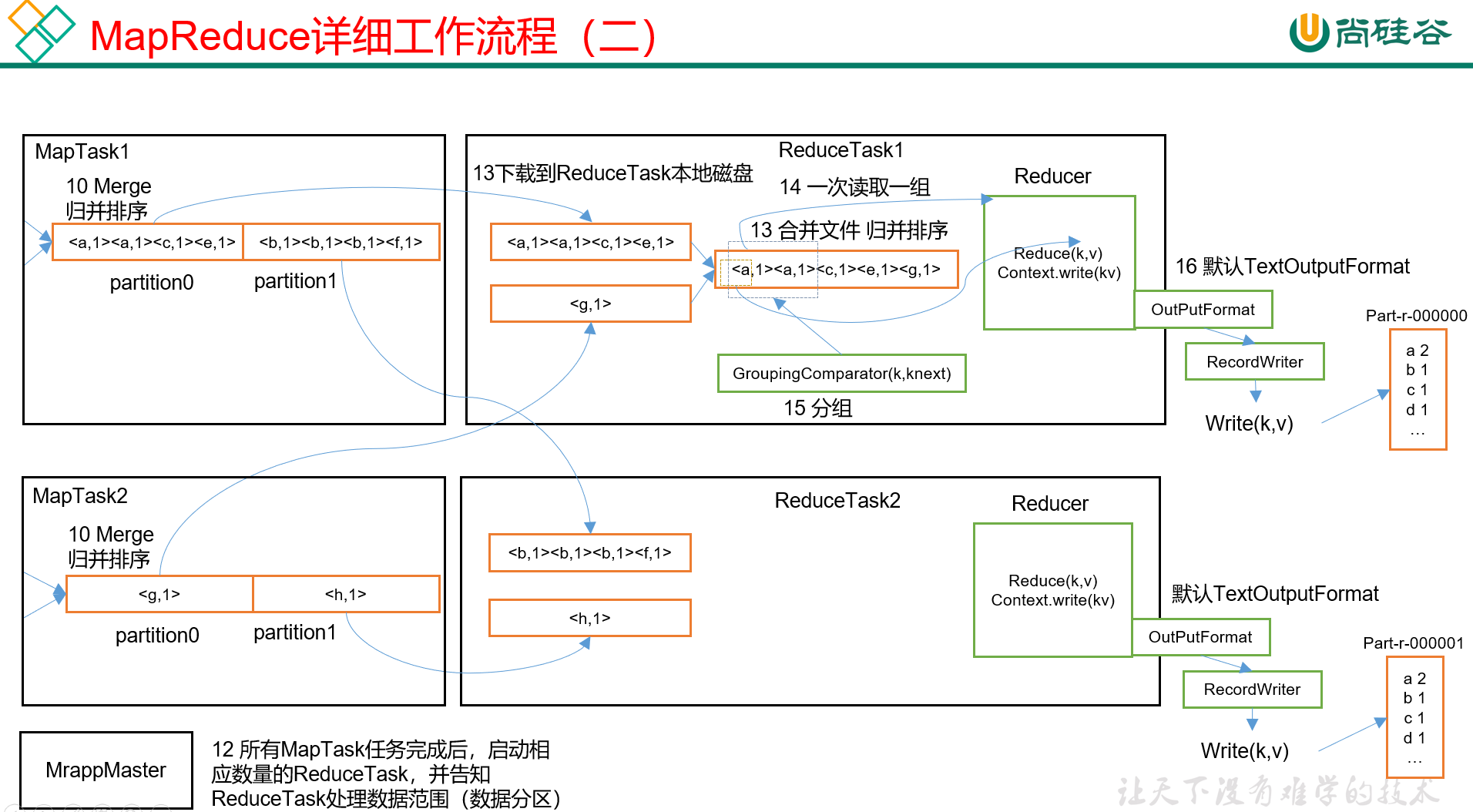
参考上一小节的MR工作流程,整个shuffle的工作流程如下图,可以理解成shuffle横跨map和reduce阶段:
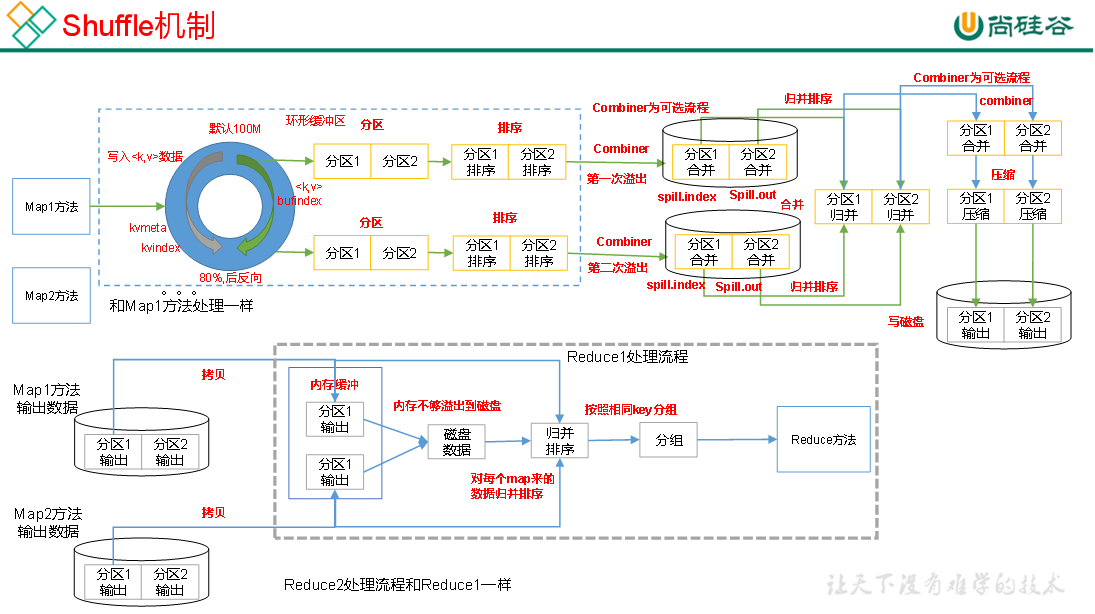
Map阶段
1) Map()处理之后的数据,会被传输进环形缓冲区,而在这个过程中,数据会被打上一个"分区",之后会讲这个分区是怎么来的。打好分区后,数据会被正式写入环形缓冲区。
2) 环形缓冲区的机制在上一小节里有介绍,看那个就行。需要注意,它在溢写到磁盘之前,需要对数据进行排序,即针对KEY值的索引,按照字典顺序进行快排。
每次溢写后会形成两个文件,一个是保存索引用的spill.index,一个是保存数据用的spill.out。这个过程中有一个可选环节,即combiner,即简单聚合,如果开启这个环节的话,会对本次溢写的文件做一些简单的预聚合,如将<a,1>, <a,1>合并成<a,2>,从而在一定程度上减轻reduce阶段的输入量。
3) 溢写会进行很多轮,即生成很多个.out文件。 当输入数据全部溢写完成后,会以分区为单位,对所有溢写结果做归并排序,并最终整合成一个大文件。相当于是在该MapTask下,最终只保留一个文件,且这个文件内部是按照分区由低到高排列,分区内部有序。
4) 归并排序后,仍然是一个可选的combiner环节,对文件内数据做再次的预聚合。
5) combiner之后,会对各分区的数据文件做压缩。从归并排序到压缩,这部分工作都是在内存中完成的,最后会将压缩后的数据写入磁盘。
为什么要进行压缩呢?
这是一个优化的手段,因为最终的输出是要传到Reduce里的,待传输的文件越小,输出的时间就越短,相比就更加高效。这个后面具体会讲
6) 最后,会将压缩后的文件放进磁盘中,等待Reduce来主动拉取。
Reduce阶段
在Reduce阶段
1) 每个ReduceTask会主动拉取Map阶段的处理结果(指定分区),优先读取到内存,因为内存里面直接处理会更快,但是如果内存不够那就没办法了,只能溢写到磁盘,后续一点点处理了。
2) 然后对从每个MapTask收上来的数据,做归并排序。
3) 归并排序完之后,再根据相同的key进行分组,分组之后的数据类似于如<key, [v1, v2, v3,...]>。
4) 最终,把分组后的数据送进Reduce(),做相应的业务逻辑处理,并输出。
以上流程,就是一个完整的shuffle流程。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
Hadoop3教程(十二):MapReduce中Shuffle机制的概述
文章目录 (95) Shuffle机制什么是shuffle?Map阶段Reduce阶段 参考文献 (95) Shuffle机制 面试的重点 什么是shuffle? Map方法之后,Reduce方法之前的这段数据处理过程,就叫做shuff…...

MySQL为什么用b+树
索引是一种数据结构,用于帮助我们在大量数据中快速定位到我们想要查找的数据。 索引最形象的比喻就是图书的目录了。注意这里的大量,数据量大了索引才显得有意义,如果我想要在[1,2,3,4]中找到4这个数据,直接对全数据检索也很快&am…...

浅谈机器学习中的概率模型
浅谈机器学习中的概率模型 其实,当牵扯到概率的时候,一切问题都会变的及其复杂,比如我们监督学习任务中,对于一个分类任务,我们经常是在解决这样一个问题,比如对于一个n维的样本 X [ x 1 , x 2 , . . . .…...

MySQL 函数 索引 事务 管理
目录 一. 字符串相关的函数 二.数学相关函数 编辑 三.时间日期相关函数 date.sql 四.流程控制函数 centrol.sql 分页查询 使用分组函数和分组字句 group by 数据分组的总结 多表查询 自连接 子查询 subquery.sql 五.表的复制 六.合并查询 七.表的外连接 …...

Flink如何基于事件时间消费分区数比算子并行度大的kafka主题
背景 使用flink消费kafka的主题的情况我们经常遇到,通常我们都是不需要感知数据源算子的并行度和kafka主题的并行度之间的关系的,但是其实在kafka的主题分区数大于数据源算子的并行度时,是有一些注意事项的,本文就来讲解下这些注…...
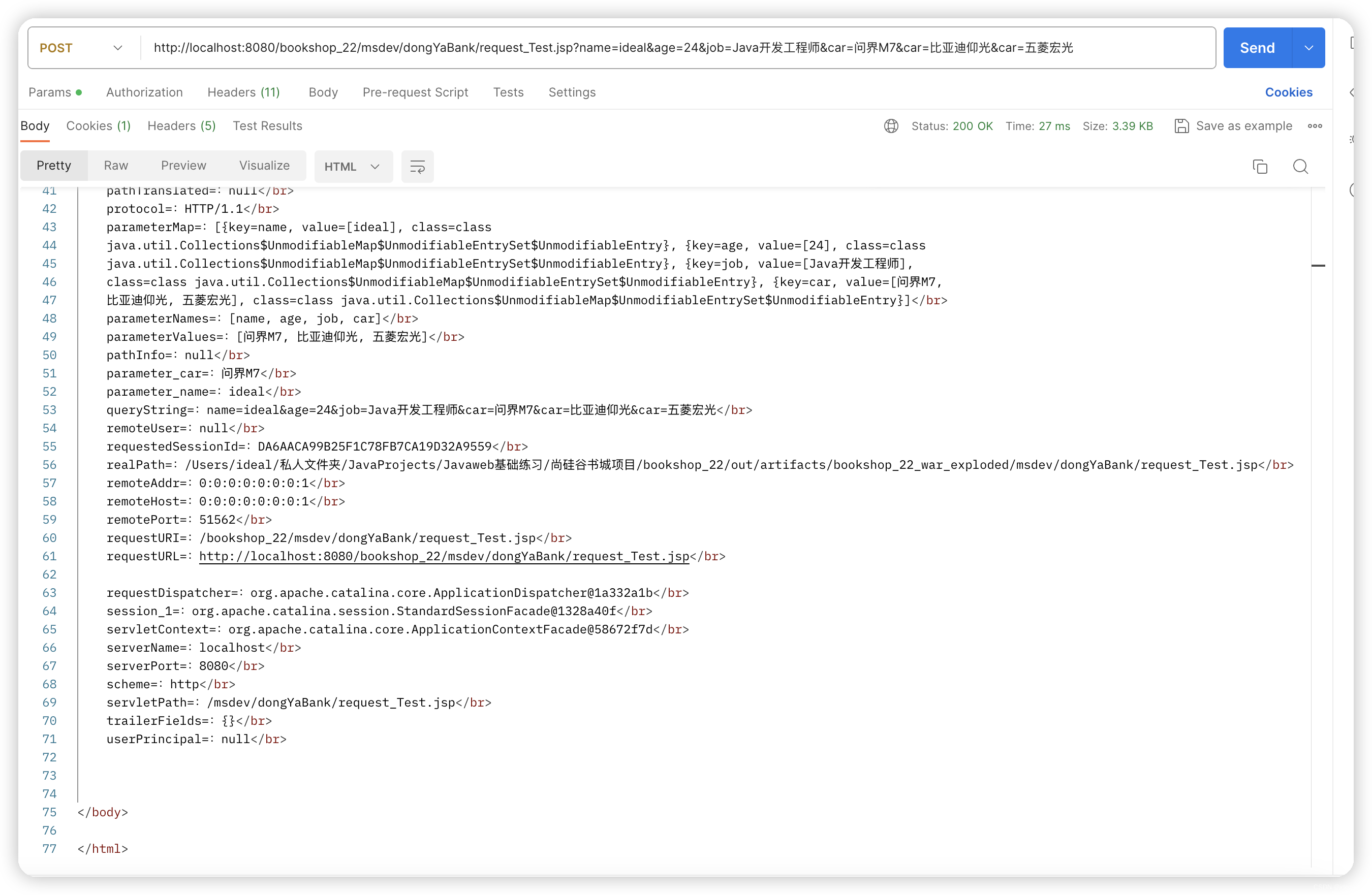
总结:JavaEE的Servlet中HttpServletRequest请求对象调用各种API方法结果示例
总结:JavaEE的Servlet中HttpServletRequest请求对象调用各种API方法结果示例 一方法调用顺序是按照英文字母顺序从A-Z二该示例可以用作servlet中request的API参考,从而知道该如何获取哪些路径参数等等三Servlet的API版本5.0.0、JSP的API版本:…...
ChatGPT AIGC 完成Excel跨多表查找操作vlookup+indirect
VLOOKUP和INDIRECT的组合在Excel中用于跨表查询,其中VLOOKUP函数用于在另一张表中查找数据,INDIRECT函数则用于根据文本字符串引用不同的工作表。具体操作如下: 1.假设在工作表1中,A列有你要查找的值,B列是你希望查询的工作表名称。 2.在工作表1的C列输入以下公式:=VLO…...

Linux系统conda虚拟环境离线迁移移植
本人创建的conda虚拟环境名为yys(每个人的虚拟环境名不一样,替换下就行) 以下为迁移步骤: 1.安装打包工具将虚拟环境打包: conda install conda-pack conda pack -n yys -o yys.tar.gz 2.将yys.tar.gz上传到服务器&…...

Vue16 绑定css样式 style样式
绑定样式: 1. class样式写法:class"xxx" xxx可以是字符串、对象、数组。字符串写法适用于:类名不确定,要动态获取。对象写法适用于:要绑定多个样式,个数不确定,名字也不确定。数组写法适用于&…...
[Spring] SpringMVC 简介(三)
目录 九、SpringMVC 中的 AJAX 请求 1、简单示例 2、RequestBody(重点关注“赋值形式”) 3、ResponseBody(经常用) 4、为什么不用手动接收 JSON 字符串、转换 JSON 字符串 5、RestController 十、文件上传与下载 1、Respo…...

kettle应用-从数据库抽取数据到excel
本文介绍使用kettle从postgresql数据库中抽取数据到excel中。 首先,启动kettle 如果kettle部署在windows系统,双击运行spoon.bat或者在命令行运行spoon.bat 如果kettle部署在linux系统,需要执行如下命令启动 chmod x spoon.sh nohup ./sp…...
Git Commit Message规范
概述 Git commit message规范是一种良好的实践,可以帮助开发团队更好地理解和维护代码库的历史记录。它可以提高代码质量、可读性和可维护性。下面是一种常见的Git commit message规范,通常被称为"Conventional Commits"规范: 一…...

Linux网络编程系列之UDP广播
Linux网络编程系列 (够吃,管饱) 1、Linux网络编程系列之网络编程基础 2、Linux网络编程系列之TCP协议编程 3、Linux网络编程系列之UDP协议编程 4、Linux网络编程系列之UDP广播 5、Linux网络编程系列之UDP组播 6、Linux网络编程系列之服务器编…...
)
spring中事务相关面试题(自用)
1 什么是spring事务 Spring事务管理的实现原理是基于AOP(面向切面编程)和代理模式。Spring提供了两种主要的方式来管理事务:编程式事务管理和声明式事务管理。 声明式事务管理: Spring的声明式事务管理是通过使用注解或XML配置来…...
09 | JpaSpecificationExecutor 解决了哪些问题
QueryByExampleExecutor用法 QueryByExampleExecutor(QBE)是一种用户友好的查询技术,具有简单的接口,它允许动态查询创建,并且不需要编写包含字段名称的查询。 下面是一个 UML 图,你可以看到 QueryByExam…...
之su)
Linux命令(93)之su
linux命令之su 1.su介绍 linux命令su用于变更为其它使用者的身份,如root用户外,需要输入使用者的密码 2.su用法 su [参数] user su参数 参数说明-c <command>执行指定的命令,然后切换回原用户-切换到目标用户的环境变量 3.实例 3…...

1.HTML-HTML解决中文乱码问题
题记 下面是html文件解决中文乱码的方法 方法一 在 HTML 文件的 <head> 标签中添加 <meta charset"UTF-8">,确保文件以 UTF-8 编码保存 <head> <meta charset"UTF-8"> <!-- 其他标签和内容 --> </head> --…...

Vue3 + Nodejs 实战 ,文件上传项目--实现拖拽上传
目录 1.拖拽上传的剖析 input的file默认拖动 让其他的盒子成为拖拽对象 2.处理文件的上传 处理数据 上传文件的函数 兼顾点击事件 渲染已处理过的文件 测试效果 3.总结 博客主页:専心_前端,javascript,mysql-CSDN博客 系列专栏:vue3nodejs 实战-…...
Windows:VS Code IDE安装ESP-IDF【保姆级】
物联网开发学习笔记——目录索引 参考: VS Code官网:Visual Studio Code - Code Editing. Redefined 乐鑫官网:ESP-IDF 编程指南 - ESP32 VSCode ESP-ID Extension Install 一、前提条件 Visual Studio Code IDE安装ESP-IDF扩展…...
Hadoop3教程(十一):MapReduce的详细工作流程
文章目录 (94)MR工作流程Map阶段Reduce阶段 参考文献 (94)MR工作流程 本小节将展示一下整个MapReduce的全工作流程。 Map阶段 首先是Map阶段: 首先,我们有一个待处理文本文件的集合; 客户端…...

法律条款时间逻辑的DSL与状态机实现:从概念到工程实践
1. 项目概述:当法律条款遇上时间逻辑最近在做一个挺有意思的项目,叫“Clause-Logic/exoclaw-temporal”。光看名字,可能有点摸不着头脑,但如果你接触过合同、协议或者任何带有法律效力的文书,并且尝试过用代码去处理它…...

从栅格到矢量:基于ArcScan的河道中心线智能提取与精度优化实践
1. 从栅格到矢量的技术背景 河道中心线提取是水文分析中的基础性工作。传统人工勾绘方式效率低下,一条10公里长的河道可能需要耗费专业人员半天时间。而基于ArcScan的自动化提取方法,能将这个时间缩短到10分钟以内,同时保证亚米级精度。 我在…...

智能网联单轨捷运编组协同控制【附仿真】
✨ 长期致力于跨座式单轨车辆、单轨捷运系统、智能编组运行、协同避撞、协同控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)融合车距与速度的多层…...
、事务管理和文件上传(阿里云OSS))
员工管理(新增员工)、事务管理和文件上传(阿里云OSS)
员工管理(新增员工) 思路就是就是新增的员工基本信息和批量保存员工的工作经历信息,也就是后端对应了两条sql语句, 1.保存员工基本信息 Emp实体类中新添一个字段用于保存员工工作经历 //封装工作经历 private List<EmpExpr> exprList; (1)Cont…...

Kinovea运动视频分析:免费开源的专业动作量化工具终极指南
Kinovea运动视频分析:免费开源的专业动作量化工具终极指南 【免费下载链接】Kinovea Video solution for sport analysis. Capture, inspect, compare, annotate and measure technical performances. 项目地址: https://gitcode.com/gh_mirrors/ki/Kinovea …...

2026届必备的六大AI辅助写作网站横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 现今,各类数字化内容的AI生成痕迹核验标准不断持续迭代,多数内容创作…...

SpringBoot+Vue的牙科诊所预约平台毕业设计源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的牙科诊所预约平台以解决传统医疗预约模式中存在的信息不对称问题和资源分配效率低下问题。随着数字化医疗技术的快…...

Flow区块链开发:用AI规则库提升Cadence智能合约与FCL前端开发效率
1. 项目概述与核心价值 如果你正在Flow区块链上用Cadence语言开发智能合约,并且恰好也在用Cursor这样的AI辅助编程工具,那你可能和我一样,经历过一个有点“分裂”的阶段。一方面,Cadence作为一门资源导向型语言,其独特…...

Applite:Mac软件管理的图形化革命,告别命令行操作
Applite:Mac软件管理的图形化革命,告别命令行操作 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为Mac软件安装更新而烦恼吗?Applite作…...

FPGA设计避坑指南:从复位电路到跨时钟域,手把手教你搞定亚稳态
FPGA实战:亚稳态问题全解析与工程级解决方案 在FPGA开发中,亚稳态问题如同潜伏的幽灵,往往在系统最不稳定的时候显现,导致数据错误、系统崩溃等难以追踪的故障。本文将从一个真实的UART接收模块案例出发,深入剖析亚稳态…...