Hadoop3教程(十一):MapReduce的详细工作流程
文章目录
- (94)MR工作流程
- Map阶段
- Reduce阶段
- 参考文献
(94)MR工作流程
本小节将展示一下整个MapReduce的全工作流程。
Map阶段
首先是Map阶段:
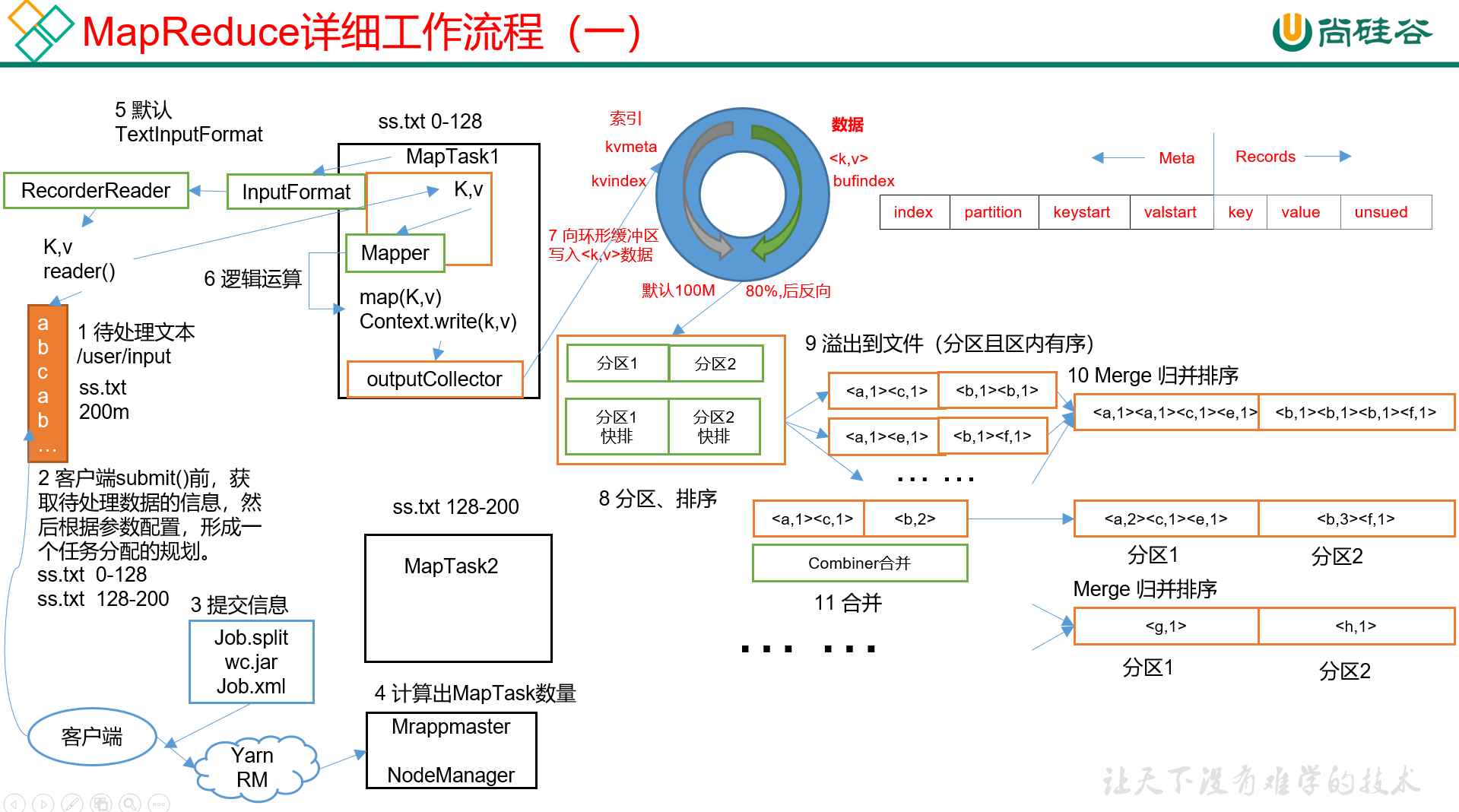
-
首先,我们有一个待处理文本文件的集合;
-
客户端开始切片规划;
-
客户端提交各种信息(如切片规划文件、代码文件及其他配置数据)到yarn;
-
yarn接收信息,计算所需的MapTask数量(按照切片数);
-
MapTask启动,读取输入文件,默认使用的是TextInputFormat。输出KV对,以TextInputFormat为例,K是偏移量(行在整个文件的字节数),V是这一行的内容;
-
TextInputFormat读取完毕后,将得到的KV对都输入Mapper(),做自定义业务逻辑处理(核心处理部分);
-
Mapper()处理完的数据,放入outputCollector,也被叫做环形缓冲区;环形缓冲区是位于内存中的,其实就是个缓冲数组,里面每行数据是分左右两部分,右边一部分是KV数据位,存放的是输入进来的K值和V值,左边一部分是对应的索引数据,存放的信息有:本行KV对的索引、本行KV对的分区、keystart以及valuestart;这里的keystart和valuestart都是指数据在内存中的存储位置,(keystart~valuestart)表示本行key值的存储起止位置,而(valuestart~下一行数据的keystart)表示本行value值的存储起止位置,其他行以此类推。
环形缓冲区默认大小是100M,它有个有趣的机制用来协调写 + 磁盘持久化。当写满到80%的时候,环形缓冲区会开始进行反向逆写操作。
什么是反向逆写呢?
可以结合数组做简单理解,就是假设数组有100个位置,即索引位0~99,当写到80%位置,即从索引0开始,到索引79写完了之后,就开始反向逆写,从索引99开始往前写,依次是98/97这样子。
为什么要这么设置?
很简单,当写满到80%的时候,系统会开启一个线程,将这80%的数据持久化到磁盘,但持久化的同时,一般希望不会影响正常的写,于是留了20%的空位置,供正常的写操作。因此是持久化 + 写,并行运行。
想象一下,如果规定只有写满到100%之后才能持久化到磁盘,或者说溢出到磁盘,那么在它持久化的过程中,整个写流程就必须暂停,直到持久化完成后,环形缓冲区清空后才能继续写,这个时间消耗未免太长,效率太低。这么看的话,它这个80%后开始逆写的设置,还挺棒的。
这里有个潜在的问题,就是如果系统写的很快,在没有持久化完那80%之前,那20%的空位置就写满了,这时候会发生什么情况?
这时候,写流程就不得不暂停,直到持久化完成之后再恢复写。
-
注意,上一步中持久化,或者说溢写数据之前,会先将数据分区(不同分区的数据在Reduce阶段将会被送进不同的ReduceTask)。然后分区内做排序,一般使用快排。
那排序是针对什么来排呢?
不是数据的KV,而是数据的那几个索引。
-
将数据溢出至文件。注意,单次溢写的数据虽然是写在一个文件里,但是是分区且分区内有序的。
-
在数据溢出数次后,我们就有了好几个文件,接下来我们将这些文件merge,做归并排序,相当于是合并成一个文件,然后将结果存储在磁盘。
-
做预聚合。比如说如果有两个
<a, 1>,那可以直接合并成<a, 2>。当然,这一步并不是必要的,可以结合实际场景具体看是否需要。
到这里,一个MapTask的工作就正式结束了,其他的MapTask就是重复以上过程。
Reduce阶段
Reduce阶段:
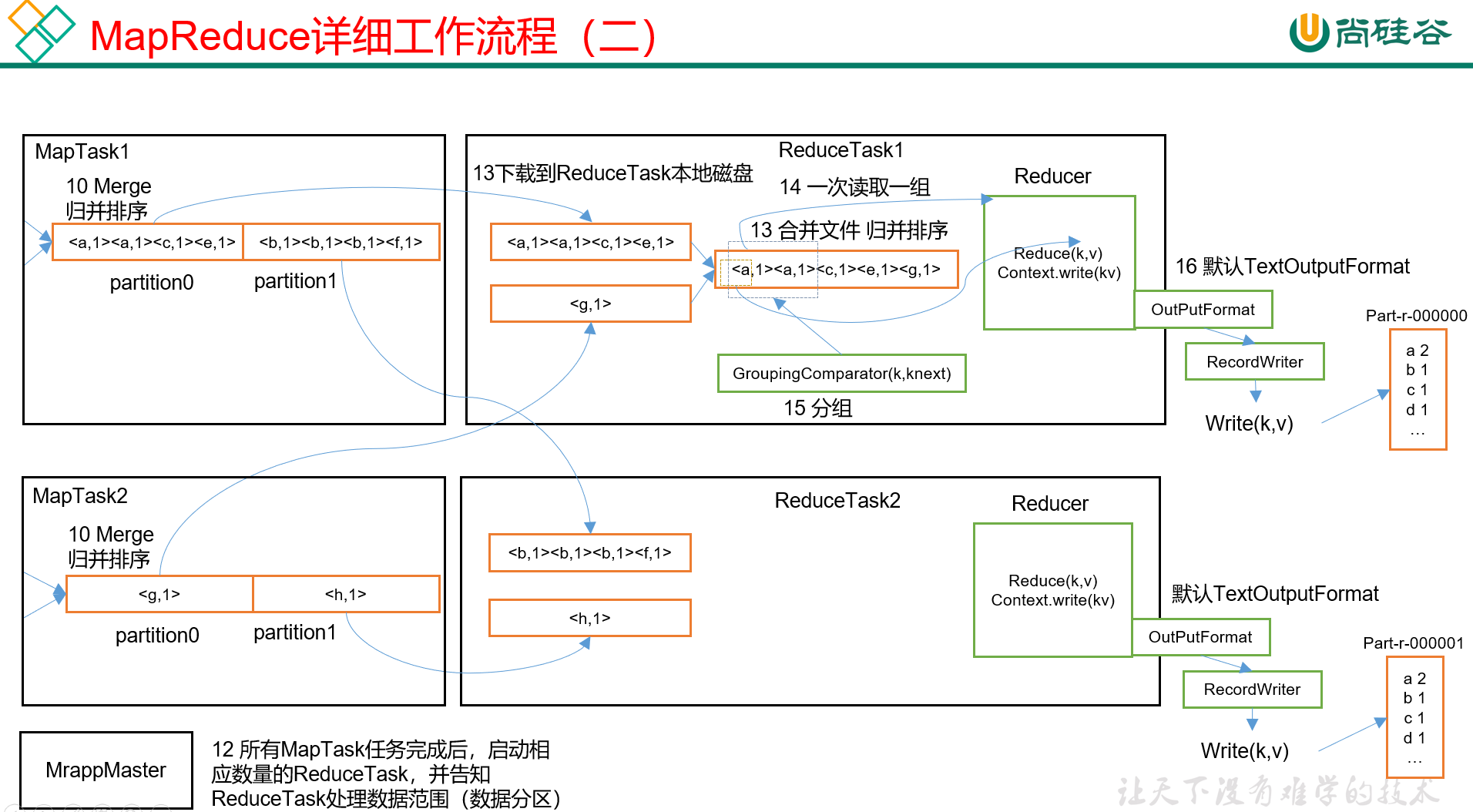
-
一般情况下,等所有MapTask任务都完成后,就会启动响应数据的ReduceTask,并告知每个ReduceTask它需要处理的数据范围。
这里说的是一般情况下,实际上我们也可以设置,等到一部分MapTask完成之后就先启动几个ReduceTask做处理,相当于Map阶段和Reduce阶段同时进行。这个比较适合MapTask很多的情况,比如说有100个MapTask,等到100个都执行完,才进入Reduce阶段,未免太慢了,所以可以这样并行走。
-
ReduceTask 主动 从MapTask的结果数据中去拉取需要的数据,然后做合并文件 + 归并排序。
举个例子,ReduceTask_1可能会从MapTask_1拉取指定分区数据,也会从MapTask_2中拉取该分区的数据,这样的话就会有多个文件,而且虽然每个文件内部是有序的(MapTask处理过),但是不同文件之间可能是无序的,因此合并文件 + 归并排序,是很有必要的。
-
对上一步产生的结果,一次读取一组,送进Reducer()去做业务逻辑处理。这里的一组是KEY值相同作为一组,因为上一步中已经排序过了,所以KEY值相同的会被放在一起,直接取这一组就可以了。
-
分组,暂且不表;
-
Reducer()处理完了之后,由OutputFormat往外输出,默认是TextOutputFormat,即输出成文本文件。
这就是整个MR处理的流程。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
Hadoop3教程(十一):MapReduce的详细工作流程
文章目录 (94)MR工作流程Map阶段Reduce阶段 参考文献 (94)MR工作流程 本小节将展示一下整个MapReduce的全工作流程。 Map阶段 首先是Map阶段: 首先,我们有一个待处理文本文件的集合; 客户端…...

测试中Android与IOS分别关注的点
目录 1、自身不同点 2、测试注重点 3、其他测试点 主要从本身系统的不同点、系统造成的不同点、和注意的测试点做总结 1、自身不同点 研发商:Adroid是google公司做的手机系统,IOS是苹果公司做的手机系统 开源程度:Android是开源的&a…...
评估指标介绍)
NLG(自然语言生成)评估指标介绍
诸神缄默不语-个人CSDN博文目录 本文介绍自然语言生成任务中的各种评估指标。 因为我是之前做文本摘要才接触到这一部分内容的,所以本文也是文本摘要中心。 持续更新。 文章目录 1. 常用术语2. ROUGE (Recall Oriented Understudy for Gisting Evaluation)1. 计算…...

苍穹外卖(七) Spring Task 完成订单状态定时处理
Spring Task 完成订单状态定时处理, 如处理支付超时订单 Spring Task介绍 Spring Task 是Spring框架提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑。 应用场景: 信用卡每月还款提醒 火车票售票系统处理未支付订单 入职纪念日为用户发送通知 点外…...

【探索Linux】—— 强大的命令行工具 P.11(基础IO,文件操作)
阅读导航 前言一、C语言的文件操作二、C的文件操作三、Linux系统文件操作(I/O接口)1. open()⭕传入多个打开方式(按位或操作将不同的标志位组合在一起) 2. write()3. read()4. close()5. lseek() 温馨提示 前言 前面我们讲了C语言…...

前端练习项目(附带页面psd图片及react源代码)
一、前言 相信很多学完前端的小伙伴都想找个前端项目练练手,检测自己的学习成果。但是现在很多项目市面上都烂大街了。今天给大家推荐一个全新的项目——电子校园 项目位置:https://github.com/v5201314/eSchool 二、项目介绍(部分页面展示)ÿ…...

【从零开始学习Redis | 第三篇】在Java中操作Redis
前言: 本文算是一期番外,介绍一下如何在Java中使用Reids ,而其实基于Java我们有很多的开源框架可以用来操作redis,而我们今天选择介绍的是其中比较常用的一款:Spring Data Redis 目录 前言: Spring Data…...
vim、gcc/g++、make/Makefile、yum、gdb
vim、gcc/g、make/Makefile、yum、gdb 一、Linux编辑器vim1、简介2、三种模式的概念(1)正常/普通/命令模式(Normal mode)(2)插入模式(Insert mode)(3)末行/底行模式(last line mode) 3、三种模式的切换4、正…...

2022最新版-李宏毅机器学习深度学习课程-P13 局部最小值与鞍点
一、优化失败的原因 局部最小值?鞍点? 二、数学推导分析 用泰勒公式展开 一项与梯度(L的一阶导)有关,一项与海赛矩阵(L的二阶导)有关 海瑟矩阵 VTHV通过海瑟矩阵的性质可以转为判断H是否是正…...
ARM架构的基本知识
ARM两种授权 体系结构授权, 一种硬件规范, 用来约定指令集, 芯片内部体系结构(内存管理, 高速缓存管理), 只约定每一条指令的格式, 行为规范, 参数, 客户根据这个规范自行设计与之兼容的处理器处理IP授权, ARM公司根据某个版本的体系结构设计处理器, 再把处理器设计方案授权给…...

网络安全(黑客技术)——如何高效自学
前言 前几天发布了一篇 网络安全(黑客)自学 没想到收到了许多人的私信想要学习网安黑客技术!却不知道从哪里开始学起!怎么学?如何学? 今天给大家分享一下,很多人上来就说想学习黑客,…...
云原生场景下高可用架构的最佳实践
作者:刘佳旭(花名:佳旭),阿里云容器服务技术专家 引言 随着云原生技术的快速发展以及在企业 IT 领域的深入应用,云原生场景下的高可用架构,对于企业服务的可用性、稳定性、安全性越发重要。通…...

图论-最短路径算法-弗洛伊德算法与迪杰斯特拉算法
弗洛伊德算法: 弗洛伊德算法本质是动态规划,通过添加点进如可选择的点组成的集合的同时更新所有点之间的距离,从而得到每两个点之间的最短距离。 初始化: 创建一个二维数组 dist,其中 dist[i][j] 表示从节点 i 到节点…...

[23] IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts
pdf Text-to-3D任务中,对3D模型外观的控制不强,本文提出IPDreamer来解决该问题。在NeRF Training阶段,IPDreamer根据文本用ControlNet生成参考图,并将参考图作为Zero 1-to-3的控制条件,用基于Zero 1-to-3的SDS损失生成…...

深入理解React中的useEffect钩子函数
引言: React是一种流行的JavaScript库,它通过组件化和声明式编程的方式简化了前端开发。在React中,一个核心概念是组件的生命周期,其中包含了许多钩子函数,用于管理组件的不同阶段。其中之一就是useEffect钩子函数&…...

数字化时代的财务管理:挑战与机遇
导语:随着数字化技术的不断发展,财务管理正面临着前所未有的挑战和机遇。数字化不仅改变了财务数据的收集、处理和分析方式,还为财务决策提供了更多的依据和方向。本文将探讨数字化时代财务管理的新特点,以及如何利用数字化技术提…...
网络通信协议-HTTP、WebSocket、MQTT的比较与应用
在今天的数字化世界中,各种通信协议起着关键的作用,以确保信息的传递和交换。HTTP、WebSocket 和 MQTT 是三种常用的网络通信协议,它们各自适用于不同的应用场景。本文将比较这三种协议,并探讨它们的主要应用领域。 HTTPÿ…...
、dataloader、长短期记忆网络(LSTM)、门控循环单元(GRU)、超参数对比)
【深度学习】深度学习实验四——循环神经网络(RNN)、dataloader、长短期记忆网络(LSTM)、门控循环单元(GRU)、超参数对比
一、实验内容 实验内容包含要进行什么实验,实验的目的是什么,实验用到的算法及其原理的简单介绍。 1.1 循环神经网络 (1)理解序列数据处理方法,补全面向对象编程中的缺失代码,并使用torch自带数据工具将数据封装为dataloader。 (2)分别采用手动方式以及调用接口方式…...

DB2分区表详解
一、分区表基本概念 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。分区后的表称为分区表。 表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个“表空间”(物理文件上),这样查询数据时…...

基本地址变换机构
基本地址变换机构:用于实现逻辑地址到物理地址转换的一组硬件机构。 关于页号页表的定义,放个本人的传送门 1.页表寄存器 基本地址变换机构可以借助进程的页表将逻辑地址转换为物理地址。 1.作用 通常会在系统中设置一个页表寄存器(PTR&…...

量子错误校正与机器学习中的辅助比特影响研究
1. 量子错误校正与量子机器学习的基础概念量子计算的核心挑战之一是量子态的脆弱性。与环境相互作用导致的退相干效应会迅速破坏量子信息,这使得量子错误校正(QEC)成为实现实用量子计算的关键技术。在传统量子计算中,QEC通过冗余编…...

AI智能体集群如何革新代码审查:架构、实现与CI/CD集成
1. 项目概述:一个为代码审查提效的智能体集群如果你是一名团队的技术负责人或资深开发者,肯定对代码审查(Code Review)这个环节又爱又恨。爱的是,它是保证代码质量、促进知识共享的关键闸门;恨的是…...

Postman便携版:打造零污染的API测试工作环境终极指南
Postman便携版:打造零污染的API测试工作环境终极指南 【免费下载链接】postman-portable 🚀 Postman portable for Windows 项目地址: https://gitcode.com/gh_mirrors/po/postman-portable Postman便携版是一款专为Windows平台设计的绿色免安装A…...

对比直接使用厂商 API 通过 Taotoken 聚合调用的账单清晰度差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 与通过 Taotoken 聚合调用的账单清晰度差异 在集成多个大语言模型到业务中时,开发者通常会面临一…...

ARM SMMU-700内存管理单元原理与优化实践
1. MMU-700 SMMU架构概述与典型应用场景内存管理单元(MMU)是现代计算机系统中不可或缺的核心组件,负责处理虚拟地址到物理地址的转换。在ARM架构中,系统级内存管理单元(SMMU)扮演着更为关键的角色ÿ…...

Ix开源平台:基于Kubernetes的私有云与家庭实验室一体化管理方案
1. 项目概述与核心价值最近在折腾一个叫Ix的开源项目,它来自ix-infrastructure这个组织。乍一看这个名字,你可能觉得有点抽象,但如果你对自托管、家庭实验室、私有云或者想找一个更现代、更易用的 TrueNAS 替代品感兴趣,那这个项目…...

使用mcp-maker快速构建AI工具调用服务器:从协议原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上更强大的“手脚”,让它能直接操作我电脑上的各种软件和工具。这听起来很酷,对吧?但实际操作起来,你会发现一个核心痛…...

合宙Air153C看门狗芯片:嵌入式系统可靠性的硬件守护方案
1. 项目概述:一颗“小而美”的国产看门狗芯片最近在做一个低功耗的户外监测设备项目,主控用的就是合宙的Air系列MCU。在调试过程中,最让我头疼的就是系统偶尔的“死机”问题。设备部署在野外,不可能每次都跑过去手动重启。正当我琢…...

如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南
如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_…...

2026生鲜店收银软件特点功能对比
每天傍晚高峰期,生鲜店门口排起的长队总是让店主心头一紧。顾客手里拿着刚挑好的蔬菜水果,眼神里透着急切,而收银台前的店员却还在手忙脚乱地查找商品代码、手动输入重量,甚至因为系统卡顿导致支付失败。这种场景不仅流失了潜在客…...