NLG(自然语言生成)评估指标介绍
诸神缄默不语-个人CSDN博文目录
本文介绍自然语言生成任务中的各种评估指标。
因为我是之前做文本摘要才接触到这一部分内容的,所以本文也是文本摘要中心。
持续更新。
文章目录
- 1. 常用术语
- 2. ROUGE (Recall Oriented Understudy for Gisting Evaluation)
- 1. 计算指标
- 2. 对rouge指标的更深入研究和改进
- 3. BLEU (Bilingual Evaluation Understudy)
- 4. METEOR (Metric for Evaluation for Translation with Explicit Ordering)
- 5. Perplexity
- 6. Bertscore
- 7. Faithfulness
- 8. 人工评估指标
- 9. InfoLM
- 10. MOVERSCORE
- 11. BEER
- 12. BEND
- 参考资料
1. 常用术语
模型生成的句子、预测结果——candidate
真实标签——reference、ground-truth
2. ROUGE (Recall Oriented Understudy for Gisting Evaluation)
ROUGE值是文本摘要任务重最常用的机器评估指标,衡量生成文本与真实标签之间的相似程度。
precision:candidate中匹配reference的内容占candidate比例
recall:candidate中匹配reference的内容占reference比例
示例:
Reference: I work on machine learning.Candidate A: I work.Candidate B: He works on machine learning.
在这个例子中,用unigram(可以理解为一个词或token)1衡量匹配:A就比B的precision更高(A的匹配内容I work占candidate 100%,B的on machine learning占60%),但B的recall更高(60% VS 40%)。
出处论文:(2004 WS) ROUGE: A Package for Automatic Evaluation of Summaries
感觉没有2004年之后的文本摘要论文不使用这个指标的,如果看到有的话我会专门来这里提一嘴的。
分类:ROUGE-N(常用其中的ROUGE-1和ROUGE-2), ROUGE-L,ROUGE-W,ROUGE-S(后两种不常用)
原版论文中ROUGE主要关注recall值,但事实上在用的时候可以用precision、recall和F值。(我看到很多论文都用的是F值)
1. 计算指标
每种rouge值原本都是计算recall的,主要区别在于这个匹配文本的单位的选择:
ROUGE-N:基于n-grams,如ROUGE-1计算基于匹配unigrams的recall,以此类推。
ROUGE-L:基于longest common subsequence (LCS)
ROUGE-W:基于weighted LCS
ROUGE-S:基于skip-bigram co-occurence statistics(skip-bigram指两个共同出现的单词,不管中间隔了多远。要计算任何bigram的出现可能 C n 2 C_n^2 Cn2)
以ROUGE-L为例, A A A 是candidate,长度 m m m; B B B 是reference,长度 n n n:
P = L C S ( A , B ) m P=\frac{LCS(A,B)}{m} P=mLCS(A,B) R = L C S ( A , B ) n R=\frac{LCS(A,B)}{n} R=nLCS(A,B) F = ( 1 + b 2 ) R P R + b 2 P F=\frac{(1+b^2)RP}{R+b^2P} F=R+b2P(1+b2)RP
2. 对rouge指标的更深入研究和改进
(2018 EMNLP) A Graph-theoretic Summary Evaluation for ROUGE
批判文学:(2023 ACL) Rogue Scores:喷原包有bug。嘛我之前也喷过2,终于有顶会论文喷了我很欣慰
3. BLEU (Bilingual Evaluation Understudy)
常用于翻译领域。
出处论文:(2002 ACL) Bleu: a Method for Automatic Evaluation of Machine Translation
precision用modified n-gram precision估计,recall用best match length估计。
Modified n-gram precision:
n-gram precision是candidate中与reference匹配的n-grams占candidates的比例。但仅用这一指标会出现问题。
举例来说:
Reference: I work on machine learning.Candidate 1: He works on machine learning.Candidate 2: He works on on machine machine learning learning.
candidate 1的unigram precision有60%(3/5),candidate 2的有75%(6/8),但显然candidate 1比2更好。
为了解决这种问题,我们提出了“modified” n-gram precision,仅按照reference中匹配文本的出现次数来计算candidate中的出现次数。这样candidate中的on、machine和learning就各自只计算一次,candidate 2的unigram precision就变成了37.5%(3/8)。
对多个candidate的n-gram precision,求几何平均(因为precision随n呈几何增长,因此対数平均能更好地代表所有数值(这块其实我没看懂)):
P r e c i s i o n = exp ( ∑ n = 1 N w n log p n ) , where w n = 1 / n Precision=\exp(\sum_{n=1}^Nw_n\log p_n),\ \text{where} \ w_n=1/n Precision=exp(n=1∑Nwnlogpn), where wn=1/n
Best match length:
recall的问题在于可能存在多个reference texts,故难以衡量candidate对整体reference的sensitivity(这块其实我也没看懂)。显然长的candidate会包含更多匹配文本,但我们也已经保证了candidate不会无限长,因为这样的precision可能很低。因此,我们可以从惩罚candidate的简洁性(文本短)入手来设计recall指标:
在modified n-gram precision中添加一个multiplicative factor B P BP BP:
B P = { 1 , if c > r exp ( 1 − r c ) , otherwise \begin{aligned} BP=\begin{cases}1,& \text{if}\ c >r\\ \exp \left( 1-\dfrac{r}{c}\right) ,&\text{otherwise}\end{cases} \end{aligned} BP={1,exp(1−cr),if c>rotherwise
其中 c c c 是candidates总长度, r r r 是reference有效长度(如reference长度平均值),随着candidate长度( c c c)下降, B P BP BP 也随之减少,起到了惩罚短句的作用。
4. METEOR (Metric for Evaluation for Translation with Explicit Ordering)
常用于翻译领域。
出处:(2005) METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
BLEU的问题在于 B P BP BP 值所用的长度是平均值,因此单句得分不清晰。而METEOR调整了precision和recall的计算方式,用基于mapping unigrams的weighted F-score和penalty function for incorrect word order来代替。
Weighted F-score:
首先,我们要找到candidate和reference间最大的可以形成对齐(alignment)的映射(mappings)子集(subset)。在经过Porter stemming[^3]、用了WordNet同义词后,假设找到的对齐数是 m m m,则precision就是 m / c m/c m/c( c c c 是candidate长度)、recall是 m / r m/r m/r( r r r 是reference长度),F就是 F = P R α P + ( 1 − α ) R F=\frac{PR}{\alpha P+(1-\alpha)R} F=αP+(1−α)RPR
Penalty function:
考虑candidate中的单词顺序:
P e n a l t y = γ ( c m ) β , where 0 ≤ γ ≤ 1 Penalty=\gamma(\frac{c}{m})^\beta,\ \text{where}\ 0\leq\gamma\leq1 Penalty=γ(mc)β, where 0≤γ≤1
其中 c c c 是matching chunks数, m m m 是matches总数。因此如果大多数matches是连续的, c c c 就会小,penalty就会低。这部分我的理解是:连续的matches组成一个chunk。但我不确定,可能我会去查阅更多资料。
最终METEOR得分的计算方式为:
( 1 − P e n a l t y ) F (1-Penalty)F (1−Penalty)F
5. Perplexity
常用于语言模型训练。
待补。
6. Bertscore
使用该指标的论文:Rewards with Negative Examples for Reinforced Topic-Focused Abstractive Summarization
待补。
7. Faithfulness
- Entailment Ranking Generated Summaries by Correctness: An Interesting but Challenging Application for Natural Language Inference:用预训练的基于entailment的方法评估原文蕴含生成摘要的概率
- FactCC Evaluating the Factual Consistency of Abstractive Text Summarization:用基于规则的变换生成假摘要,训练基于Bert的模型,分类生成摘要是否faithful
- DAE Annotating and Modeling Fine-grained Factuality in Summarization:收集细粒度的词/依赖/句级别的faithfulness的标注,用这些标注训练factuality检测模型
8. 人工评估指标
文本的流畅程度、对原文的忠实程度、对原文重要内容的包含程度、语句的简洁程度等
9. InfoLM
出处论文:(2022 AAAI) InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation
待补。
10. MOVERSCORE
待补
11. BEER
待补。
12. BEND
待补。
参考资料
- Metrics for NLG evaluation. Simple natural language processing… | by Desh Raj | Explorations in Language and Learning | Medium
- 我还没看,等我看完了补上:
Revisiting Automatic Evaluation of Extractive Summarization Task: Can We Do Better than ROUGE?
Benchmarking Answer Verification Methods for Question Answering-Based Summarization Evaluation Metrics
SARI
InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation
SPICE
Play the Shannon Game With Language Models: A Human-Free Approach to Summary Evaluation
Reference-free Summarization Evaluation via Semantic Correlation and Compression Ratio
参考unigram_百度百科
父词条:n-gram
unigram: 1个word
bigram: 2个word
trigram : 3个word
(注意此处的word是英文的概念,在中文中可能会根据需要指代字或词)
中文中如果用字作为基本单位,示例:
西安交通大学:
unigram 形式为:西/安/交/通/大/学
bigram形式为: 西安/安交/交通/通大/大学
trigram形式为:西安交/安交通/交通大/通大学 ↩︎pyrouge和rouge在Linux上的安装方法以及结果比较 ↩︎
相关文章:
评估指标介绍)
NLG(自然语言生成)评估指标介绍
诸神缄默不语-个人CSDN博文目录 本文介绍自然语言生成任务中的各种评估指标。 因为我是之前做文本摘要才接触到这一部分内容的,所以本文也是文本摘要中心。 持续更新。 文章目录 1. 常用术语2. ROUGE (Recall Oriented Understudy for Gisting Evaluation)1. 计算…...

苍穹外卖(七) Spring Task 完成订单状态定时处理
Spring Task 完成订单状态定时处理, 如处理支付超时订单 Spring Task介绍 Spring Task 是Spring框架提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑。 应用场景: 信用卡每月还款提醒 火车票售票系统处理未支付订单 入职纪念日为用户发送通知 点外…...

【探索Linux】—— 强大的命令行工具 P.11(基础IO,文件操作)
阅读导航 前言一、C语言的文件操作二、C的文件操作三、Linux系统文件操作(I/O接口)1. open()⭕传入多个打开方式(按位或操作将不同的标志位组合在一起) 2. write()3. read()4. close()5. lseek() 温馨提示 前言 前面我们讲了C语言…...

前端练习项目(附带页面psd图片及react源代码)
一、前言 相信很多学完前端的小伙伴都想找个前端项目练练手,检测自己的学习成果。但是现在很多项目市面上都烂大街了。今天给大家推荐一个全新的项目——电子校园 项目位置:https://github.com/v5201314/eSchool 二、项目介绍(部分页面展示)ÿ…...

【从零开始学习Redis | 第三篇】在Java中操作Redis
前言: 本文算是一期番外,介绍一下如何在Java中使用Reids ,而其实基于Java我们有很多的开源框架可以用来操作redis,而我们今天选择介绍的是其中比较常用的一款:Spring Data Redis 目录 前言: Spring Data…...
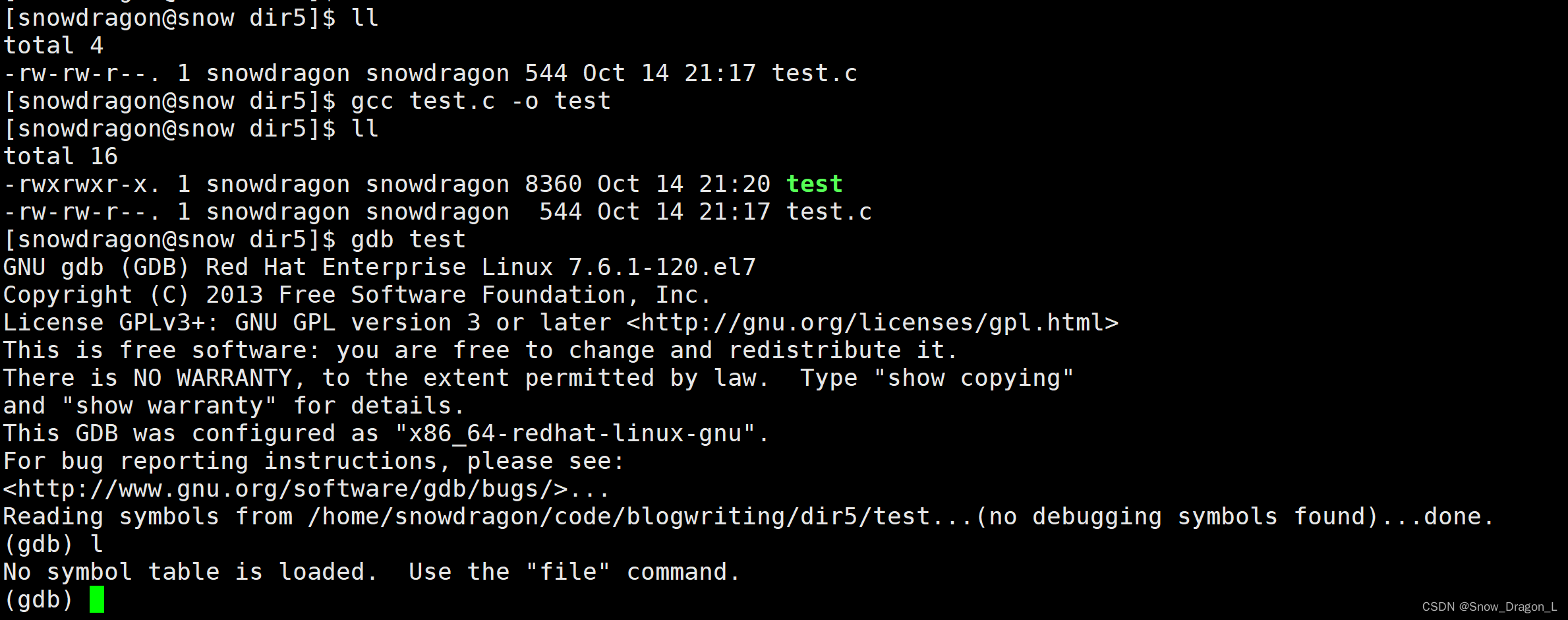
vim、gcc/g++、make/Makefile、yum、gdb
vim、gcc/g、make/Makefile、yum、gdb 一、Linux编辑器vim1、简介2、三种模式的概念(1)正常/普通/命令模式(Normal mode)(2)插入模式(Insert mode)(3)末行/底行模式(last line mode) 3、三种模式的切换4、正…...

2022最新版-李宏毅机器学习深度学习课程-P13 局部最小值与鞍点
一、优化失败的原因 局部最小值?鞍点? 二、数学推导分析 用泰勒公式展开 一项与梯度(L的一阶导)有关,一项与海赛矩阵(L的二阶导)有关 海瑟矩阵 VTHV通过海瑟矩阵的性质可以转为判断H是否是正…...
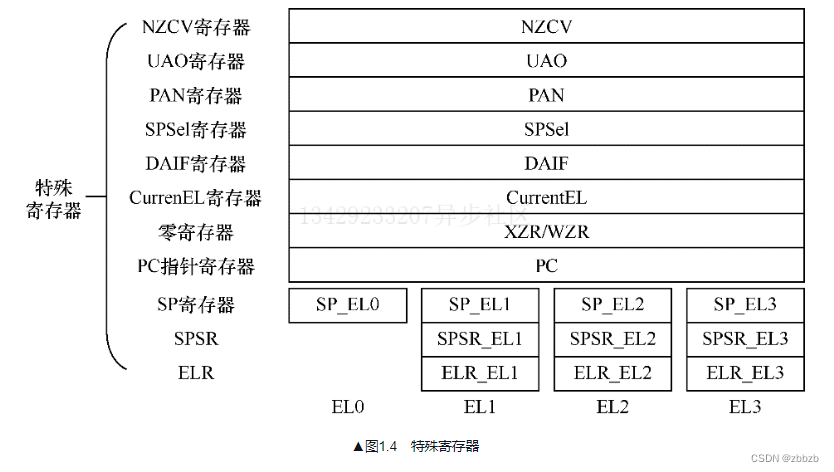
ARM架构的基本知识
ARM两种授权 体系结构授权, 一种硬件规范, 用来约定指令集, 芯片内部体系结构(内存管理, 高速缓存管理), 只约定每一条指令的格式, 行为规范, 参数, 客户根据这个规范自行设计与之兼容的处理器处理IP授权, ARM公司根据某个版本的体系结构设计处理器, 再把处理器设计方案授权给…...

网络安全(黑客技术)——如何高效自学
前言 前几天发布了一篇 网络安全(黑客)自学 没想到收到了许多人的私信想要学习网安黑客技术!却不知道从哪里开始学起!怎么学?如何学? 今天给大家分享一下,很多人上来就说想学习黑客,…...
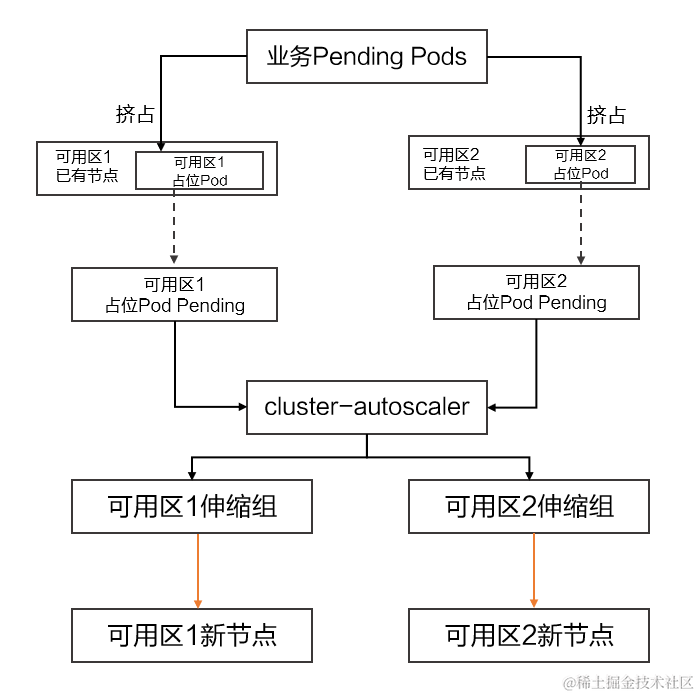
云原生场景下高可用架构的最佳实践
作者:刘佳旭(花名:佳旭),阿里云容器服务技术专家 引言 随着云原生技术的快速发展以及在企业 IT 领域的深入应用,云原生场景下的高可用架构,对于企业服务的可用性、稳定性、安全性越发重要。通…...

图论-最短路径算法-弗洛伊德算法与迪杰斯特拉算法
弗洛伊德算法: 弗洛伊德算法本质是动态规划,通过添加点进如可选择的点组成的集合的同时更新所有点之间的距离,从而得到每两个点之间的最短距离。 初始化: 创建一个二维数组 dist,其中 dist[i][j] 表示从节点 i 到节点…...

[23] IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts
pdf Text-to-3D任务中,对3D模型外观的控制不强,本文提出IPDreamer来解决该问题。在NeRF Training阶段,IPDreamer根据文本用ControlNet生成参考图,并将参考图作为Zero 1-to-3的控制条件,用基于Zero 1-to-3的SDS损失生成…...

深入理解React中的useEffect钩子函数
引言: React是一种流行的JavaScript库,它通过组件化和声明式编程的方式简化了前端开发。在React中,一个核心概念是组件的生命周期,其中包含了许多钩子函数,用于管理组件的不同阶段。其中之一就是useEffect钩子函数&…...

数字化时代的财务管理:挑战与机遇
导语:随着数字化技术的不断发展,财务管理正面临着前所未有的挑战和机遇。数字化不仅改变了财务数据的收集、处理和分析方式,还为财务决策提供了更多的依据和方向。本文将探讨数字化时代财务管理的新特点,以及如何利用数字化技术提…...
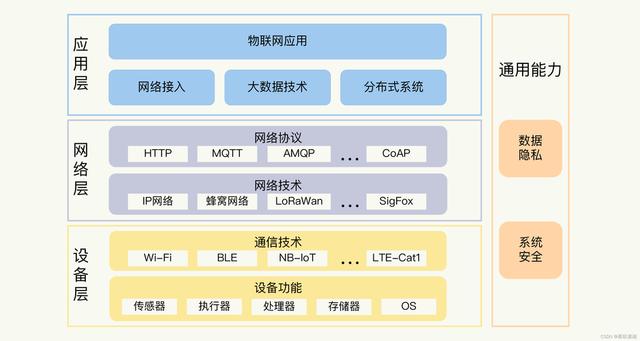
网络通信协议-HTTP、WebSocket、MQTT的比较与应用
在今天的数字化世界中,各种通信协议起着关键的作用,以确保信息的传递和交换。HTTP、WebSocket 和 MQTT 是三种常用的网络通信协议,它们各自适用于不同的应用场景。本文将比较这三种协议,并探讨它们的主要应用领域。 HTTPÿ…...
、dataloader、长短期记忆网络(LSTM)、门控循环单元(GRU)、超参数对比)
【深度学习】深度学习实验四——循环神经网络(RNN)、dataloader、长短期记忆网络(LSTM)、门控循环单元(GRU)、超参数对比
一、实验内容 实验内容包含要进行什么实验,实验的目的是什么,实验用到的算法及其原理的简单介绍。 1.1 循环神经网络 (1)理解序列数据处理方法,补全面向对象编程中的缺失代码,并使用torch自带数据工具将数据封装为dataloader。 (2)分别采用手动方式以及调用接口方式…...

DB2分区表详解
一、分区表基本概念 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。分区后的表称为分区表。 表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个“表空间”(物理文件上),这样查询数据时…...

基本地址变换机构
基本地址变换机构:用于实现逻辑地址到物理地址转换的一组硬件机构。 关于页号页表的定义,放个本人的传送门 1.页表寄存器 基本地址变换机构可以借助进程的页表将逻辑地址转换为物理地址。 1.作用 通常会在系统中设置一个页表寄存器(PTR&…...
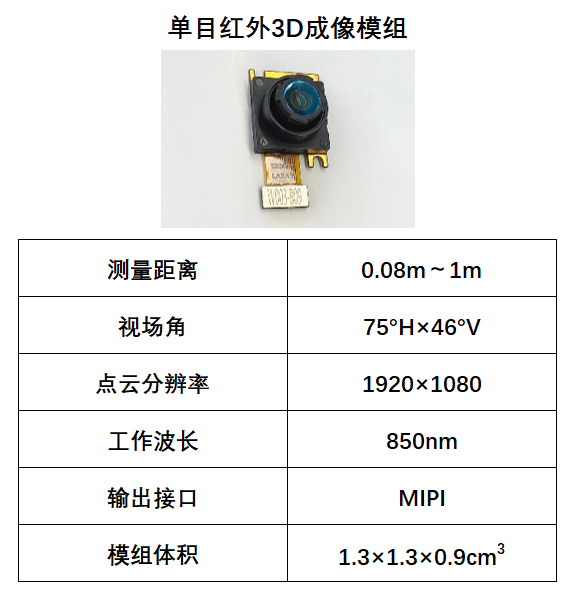
以单颗CMOS摄像头重构三维场景,维悟光子发布单目红外3D成像模组
维悟光子近期发布全新单目红外3D成像模组,现可提供下游用户进行测试导入。通过结合微纳光学元件编码和人工智能算法解码,维悟光子单目红外3D成像模组采用单颗摄像头,通过单帧拍摄,可同时获取像素级配准的3D点云和红外图像信息,可被应用于机器人、生物识别等广阔领域。 市场…...
Jinja2模板注入 | python模板注入特殊属性 / 对象讲解
在进行模板利用的时候需要使用特殊的属性和对象进行利用,这里对这些特殊属性及方法进行讲解 以下实验输出python3版本为 3.10.4, python2版本为 2.7.13 特殊属性 __class__ 类实例上使用,它用于获取该实例对应的类__base__ 用于获取父类__mr…...

深入解析Enso:构建高性能可编程代理与API网关的Go框架
1. 项目概述:一个被低估的“瑞士军刀”如果你在开源社区里混迹过一段时间,大概率见过这样的场景:一个项目仓库,名字起得挺酷,比如“Enso”,简介里写着“一个现代化的代理工具”,但点进去一看&am…...

Next.js全栈开发最佳实践:从零搭建现代化Web应用
1. 项目概述:一个现代Web开发的“瑞士军刀”如果你和我一样,在过去几年里频繁地使用Next.js、TypeScript和Tailwind CSS来构建前端应用,那么你肯定也经历过无数次重复的“项目初始化”工作。从安装依赖、配置TypeScript和ESLint,到…...

3大核心功能深度解析:茉莉花插件如何彻底解决中文文献管理难题
3大核心功能深度解析:茉莉花插件如何彻底解决中文文献管理难题 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 您是否…...

智慧巡检-基于Yolo26的目标检测系统 带登录界面的基于Yolo26的目标检测系统完整源码+原始ui文件+环境配置教程 相关技术文档包含:2万字算法文档+详细操作指南+技术设计文档+流程图+yolo
智慧巡检-基于Yolo26的目标检测系统带登录界面的基于Yolo26的目标检测系统完整源码原始ui文件环境配置教程 相关技术文档包含:2万字算法文档详细操作指南技术设计文档流程图yolo26网络结构图各文件作用说明 可视化界面基于pyside6,数据库为sqlite3&#…...

Chrome 148紧急安全更新深度解析:127个漏洞背后的GPU UAF沙箱逃逸与防御实战
一、引言:史上最密集的Chrome安全更新风暴 2026年5月5日,Google紧急推送了Chrome 148稳定版的第二次安全更新(版本号Windows/Mac 148.0.7778.96/97,Linux 148.0.7778.96),一次性修复了127个安全漏洞&#x…...

原来选对床垫还能改善全家睡眠质量?
选对床垫,改善全家睡眠质量的秘密在快节奏的现代生活中,良好的睡眠质量变得越来越重要。一张合适的床垫不仅能提升个人的睡眠体验,还能改善全家人的睡眠质量。本文将探讨如何选择适合全家人的床垫,并重点介绍美德丽床垫的独特优势…...

终极Markdown浏览器扩展:如何打造完美的文档阅读体验
终极Markdown浏览器扩展:如何打造完美的文档阅读体验 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展,专为开发…...

用PyTorch和ECANet18搞定RAF-DB表情分类:从数据集下载到模型部署的保姆级教程
基于ECANet18的RAF-DB表情识别实战:从零构建高精度分类模型 人脸表情识别(FER)作为计算机视觉领域的重要分支,在情感计算、智能交互等领域展现出巨大潜力。本文将带您完整实现一个基于PyTorch和ECANet18的端到端表情识别系统&…...

5大优势解析:如何高效使用免费离线OCR工具
5大优势解析:如何高效使用免费离线OCR工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 项目…...

镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书
镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书副标题:聚合动态三维实时重构、无感厘米级定位、全域跨镜连续追踪、身体指纹生物核验四大自研核心,一站式覆盖楼宇、仓储、硐室全场景透明智能管控前言当下城市建筑楼宇、物资仓储…...