Flume 简介及基本使用
1.Flume简介
Apache Flume 是一个分布式,高可用的数据收集系统。它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集。Flume 分为 NG 和 OG (1.0 之前) 两个版本,NG 在 OG 的基础上进行了完全的重构,是目前使用最为广泛的版本。下面的介绍均以 NG 为基础。
2. Flume架构和基本概念
下图为 Flume 的基本架构图:
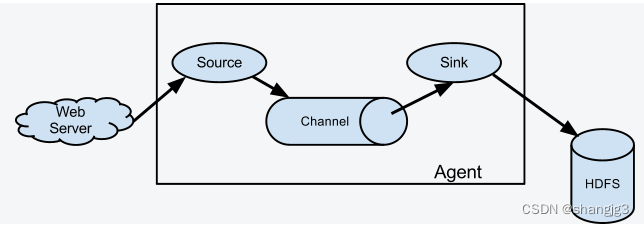
2.1 基本架构
外部数据源以特定格式向 Flume 发送 `events` (事件),当 `source` 接收到 `events` 时,它将其存储到一个或多个 `channel`,`channe` 会一直保存 `events` 直到它被 `sink` 所消费。`sink` 的主要功能从 `channel` 中读取 `events`,并将其存入外部存储系统或转发到下一个 `source`,成功后再从 `channel` 中移除 `events`。
2.2 基本概念
1. Event
`Event` 是 Flume NG 数据传输的基本单元。类似于 JMS 和消息系统中的消息。一个 `Event` 由标题和正文组成:前者是键/值映射,后者是任意字节数组。
2. Source
数据收集组件,从外部数据源收集数据,并存储到 Channel 中。
3. Channel
`Channel` 是源和接收器之间的管道,用于临时存储数据。可以是内存或持久化的文件系统:
+ `Memory Channel` : 使用内存,优点是速度快,但数据可能会丢失 (如突然宕机);
+ `File Channel` : 使用持久化的文件系统,优点是能保证数据不丢失,但是速度慢。
4. Sink
`Sink` 的主要功能从 `Channel` 中读取 `Event`,并将其存入外部存储系统或将其转发到下一个 `Source`,成功后再从 `Channel` 中移除 `Event`。
5. Agent
是一个独立的 (JVM) 进程,包含 `Source`、 `Channel`、 `Sink` 等组件。
2.3 组件种类
Flume 中的每一个组件都提供了丰富的类型,适用于不同场景:
- Source 类型 :内置了几十种类型,如 `Avro Source`,`Thrift Source`,`Kafka Source`,`JMS Source`;
- Sink 类型 :`HDFS Sink`,`Hive Sink`,`HBaseSinks`,`Avro Sink` 等;
- Channel 类型 :`Memory Channel`,`JDBC Channel`,`Kafka Channel`,`File Channel` 等。
对于 Flume 的使用,除非有特别的需求,否则通过组合内置的各种类型的 Source,Sink 和 Channel 就能满足大多数的需求。
3. Flume架构模式
Flume 支持多种架构模式,分别介绍如下
3.1 multi-agent flow

Flume 支持跨越多个 Agent 的数据传递,这要求前一个 Agent 的 Sink 和下一个 Agent 的 Source 都必须是 `Avro` 类型,Sink 指向 Source 所在主机名 (或 IP 地址) 和端口(详细配置见下文案例三)。
3.2 Consolidation

日志收集中常常存在大量的客户端(比如分布式 web 服务),Flume 支持使用多个 Agent 分别收集日志,然后通过一个或者多个 Agent 聚合后再存储到文件系统中。
3.3 Multiplexing the flow

Flume 支持从一个 Source 向多个 Channel,也就是向多个 Sink 传递事件,这个操作称之为 `Fan Out`(扇出)。默认情况下 `Fan Out` 是向所有的 Channel 复制 `Event`,即所有 Channel 收到的数据都是相同的。同时 Flume 也支持在 `Source` 上自定义一个复用选择器 (multiplexing selector) 来实现自定义的路由规则。
4.Flume配置格式
Flume 配置通常需要以下两个步骤:
1. 分别定义好 Agent 的 Sources,Sinks,Channels,然后将 Sources 和 Sinks 与通道进行绑定。需要注意的是一个 Source 可以配置多个 Channel,但一个 Sink 只能配置一个 Channel。基本格式如下:
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2># set channel for source
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...# set channel for sink
<Agent>.sinks.<Sink>.channel = <Channel1>
2. 分别定义 Source,Sink,Channel 的具体属性。基本格式如下:
<Agent>.sources.<Source>.<someProperty> = <someValue># properties for channels
<Agent>.channel.<Channel>.<someProperty> = <someValue># properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>5. Flume使用案例
介绍几个 Flume 的使用案例:
+ 案例一:使用 Flume 监听文件内容变动,将新增加的内容输出到控制台。
+ 案例二:使用 Flume 监听指定目录,将目录下新增加的文件存储到 HDFS。
+ 案例三:使用 Avro 将本服务器收集到的日志数据发送到另外一台服务器。
5.1 案例一
需求: 监听文件内容变动,将新增加的内容输出到控制台。
实现: 主要使用 `Exec Source` 配合 `tail` 命令实现。
1. 配置
新建配置文件 `exec-memory-logger.properties`,其内容如下:
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1 #配置sources属性
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /tmp/log.txt
a1.sources.s1.shell = /bin/bash -c#将sources与channels进行绑定
a1.sources.s1.channels = c1#配置sink
a1.sinks.k1.type = logger#将sinks与channels进行绑定
a1.sinks.k1.channel = c1 #配置channel类型
a1.channels.c1.type = memory2. 启动
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/exec-memory-logger.properties \
--name a1 \
-Dflume.root.logger=INFO,console
3. 测试
向文件中追加数据:

控制台的显示:

5.2 案例二
需求: 监听指定目录,将目录下新增加的文件存储到 HDFS。
实现:使用 `Spooling Directory Source` 和 `HDFS Sink`。
1. 配置
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1 #配置sources属性
a1.sources.s1.type =spooldir
a1.sources.s1.spoolDir =/tmp/logs
a1.sources.s1.basenameHeader = true
a1.sources.s1.basenameHeaderKey = fileName
#将sources与channels进行绑定
a1.sources.s1.channels =c1 #配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H/
a1.sinks.k1.hdfs.filePrefix = %{fileName}
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#将sinks与channels进行绑定
a1.sinks.k1.channel = c1#配置channel类型
a1.channels.c1.type = memory
2. 启动
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/spooling-memory-hdfs.properties \
--name a1 -Dflume.root.logger=INFO,console3. 测试
拷贝任意文件到监听目录下,可以从日志看到文件上传到 HDFS 的路径:
# cp log.txt logs/
查看上传到 HDFS 上的文件内容与本地是否一致:
# hdfs dfs -cat /flume/events/19-04-09/13/log.txt.1554788567801
5.3 案例三
需求: 将本服务器收集到的数据发送到另外一台服务器。
实现:使用 `avro sources` 和 `avro Sink` 实现。
1. 配置日志收集Flume
新建配置 `netcat-memory-avro.properties`,监听文件内容变化,然后将新的文件内容通过 `avro sink` 发送到 hadoop001 这台服务器的 8888 端口:
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1#配置sources属性
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /tmp/log.txt
a1.sources.s1.shell = /bin/bash -c
a1.sources.s1.channels = c1#配置sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop001
a1.sinks.k1.port = 8888
a1.sinks.k1.batch-size = 1
a1.sinks.k1.channel = c1#配置channel类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1002. 配置日志聚合Flume
使用 `avro source` 监听 hadoop001 服务器的 8888 端口,将获取到内容输出到控制台:
#指定agent的sources,sinks,channels
a2.sources = s2
a2.sinks = k2
a2.channels = c2#配置sources属性
a2.sources.s2.type = avro
a2.sources.s2.bind = hadoop001
a2.sources.s2.port = 8888#将sources与channels进行绑定
a2.sources.s2.channels = c2#配置sink
a2.sinks.k2.type = logger#将sinks与channels进行绑定
a2.sinks.k2.channel = c2#配置channel类型
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 1003. 启动
启动日志聚集 Flume:
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/avro-memory-logger.properties \
--name a2 -Dflume.root.logger=INFO,console在启动日志收集 Flume:
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/netcat-memory-avro.properties \
--name a1 -Dflume.root.logger=INFO,console
这里建议按以上顺序启动,原因是 `avro.source` 会先与端口进行绑定,这样 `avro sink` 连接时才不会报无法连接的异常。但是即使不按顺序启动也是没关系的,`sink` 会一直重试,直至建立好连接。

4.测试
向文件 `tmp/log.txt` 中追加内容:

可以看到已经从 8888 端口监听到内容,并成功输出到控制台:

相关文章:
Flume 简介及基本使用
1.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统。它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集。Flume 分为 NG 和 OG (1.0 之前) 两个版本,NG 在 OG 的基础上进行了完全的重构…...
行业追踪,2023-10-11
自动复盘 2023-10-11 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...
Linux:进程控制
目录 一、进程创建 写时拷贝 二、进程终止 echo $? 如何终止进程 _exit与exit 三、进程等待 进程等待的必要性 进程等待的操作 wait waitpid status 异常退出情况 status相关宏 options 四、进程程序替换 1、关于进程程序替换 2、如何进行进程程序替换 程序…...

HTTP中的GET方法与POST方法
1、GET 和 POST方法之间的区别 根据 RFC 规范,GET 的语义是从服务器获取指定的资源,这个资源可以是静态的文本、页面、图片视频等。GET 请求的参数位置一般是写在 URL 中,URL 规定只能支持 ASCII,所以 GET 请求的参数只允许 ASCI…...
)
2023年10月16日-10月22日,(光追+ue+osg继续按部就班进行即可。)
根据月计划, 本周计划如下: 2023年10月16日-10月22日,光追10.7-10.13,ue rpg(p47-p53),ue5底层渲染01A19-01B4,osg29,osg30,filament文档每天看 落实到天就是 2023年10月16日光追10.7,ue rpg(p47),ue5底层渲染01A19,o…...

【Docker】命令使用大全
【Docker】命令使用大全 目录 【Docker】命令使用大全 简述 Docker 的主要用途 基本概念 容器周期管理 run start/stop/restart kill rm pause/unpause create exec 容器操作 ps inspect top attach events logs wait export port 容器 rootfs 命令 c…...

查找算法:二分查找、插值查找、斐波那契查找
二分查找 查找的前提是数组有序 思路分析 代码实现 # 二分查找(递归法实现) # 找到一个相等的值就返回该值的下标 def binary_search(arr: list, find_val: int, left: int, right: int):mid (left right) // 2 # 寻找数组中间位置的下标if left &…...
python+django高校教室资源预约管理系统lqg8u
技术栈 后端:pythondjango 前端:vueCSSJavaScriptjQueryelementui 开发语言:Python 框架:django/flask Python版本:python3.7.7 数据库:mysql 数据库工具:Navicat 开发软件:PyChar…...
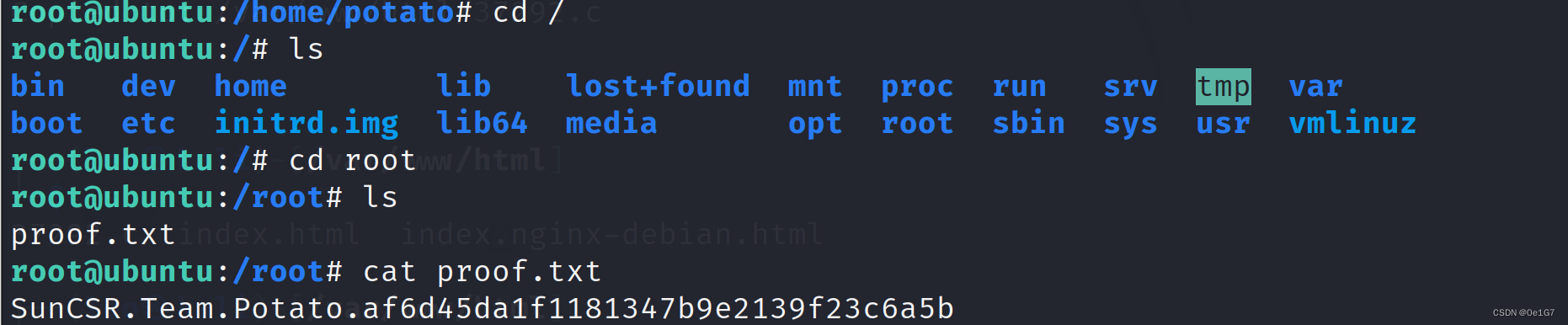
Potato靶机
信息搜集 设备发现 扫描端口 综合扫描 开放了80端口的HTTP服务和7120端口的SSH服务 目录扫描 扫描目录 看看这个info.php,发现只有php的版本信息,没有可以利用的注入点 SSH突破 hydra 爆破 考虑到 7120 端口是 ssh 服务,尝试利用 hydra …...

【环境搭建】linux docker-compose安装gitlab和redis
gitlab需要redis,一起安装了 新建gitlab和redis挂载目录 mkdir -p /data/docker/redis/data mkdir -p /data/docker/redis/logs mkdir -p /data/docker/redis/confmkdir -p /data/docker/gitlab/data mkdir -p /data/docker/gitlab/logs mkdir -p /data/docker/gi…...

JAVAEE初阶相关内容第十三弹--文件操作 IO
写在前 终于完成了!!!!内容不多就是本人太拖拉! 这里主要介绍文件input,output操作。File类,流对象(分为字节流、字符流) 需要掌握每个流对象的使用方式:打…...

POI报表的高级应用
POI报表的高级应用 掌握基于模板打印的POI报表导出理解自定义工具类的执行流程 熟练使用SXSSFWorkbook完成百万数据报表打印理解基于事件驱动的POI报表导入 模板打印 概述 自定义生成Excel报表文件还是有很多不尽如意的地方,特别是针对复杂报表头,单…...

【计算机毕设选题推荐】超市管理系统SpringBoot+SSM+Vue
前言:我是IT源码社,从事计算机开发行业数年,专注Java领域,专业提供程序设计开发、源码分享、技术指导讲解、定制和毕业设计服务 项目名 基于SpringBoot的超市管理系统 技术栈 SpringBootVueMySQLMaven 文章目录 一、超市管理系统…...
【算法1-4】递推与递归-P1002 [NOIP2002 普及组] 过河卒
## 题目描述 棋盘上 A 点有一个过河卒,需要走到目标 B 点。卒行走的规则:可以向下、或者向右。同时在棋盘上 C 点有一个对方的马,该马所在的点和所有跳跃一步可达的点称为对方马的控制点。因此称之为“马拦过河卒”。 棋盘用坐标表示&#…...

浅谈压力测试的作用是什么
随着现代应用程序变得越来越复杂,用户的期望也在不断提高,对性能和可靠性的要求变得更加苛刻。在应用程序开发和维护的过程中,压力测试是一项至关重要的活动,它可以帮助发现潜在的问题、评估系统的性能极限,以及确保在…...

互联网Java工程师面试题·Java 总结篇·第一弹
目录 1、面向对象的特征有哪些方面? 2、访问修饰符 public,private,protected,以及不写(默认)时的区别? 3、String 是最基本的数据类型吗? 4、float f3.4;是否正确? 5、short s1 1; s1 s1 1;有错吗…...
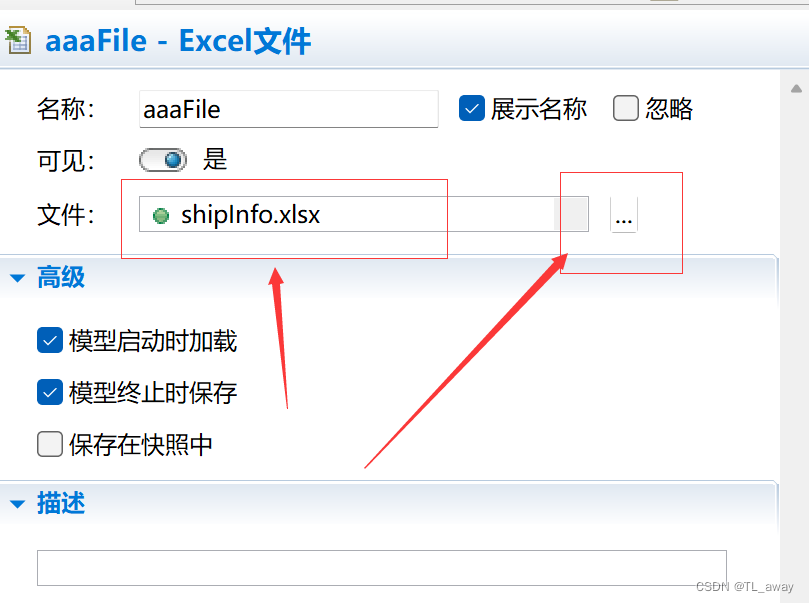
Anylogic 读取和写入Excel文件
1、选择面板-连接-Excel文件,拖入到视图中 然后在excel文件的属性中进行绑定外部excel文件。 绑定完之后,在你需要读取的地方进行写代码, //定义开始读取的行数 //这里设为2,是因为第一行是数据名称 int row12; //读取excel文件信…...
茶百道全链路可观测实战
作者:山猎 茶百道是四川成都的本土茶饮连锁品牌,创立于 2008 年 。经过 15 年的发展,茶百道已成为餐饮标杆品牌,全国门店超 7000 家,遍布全国 31 个省市,实现中国大陆所有省份及各线级城市的全覆盖。2021 …...

Java-JDBC
JDBC JDBC英文名为:Java Data Base Connectivity(Java数据库连接),官方解释它是Java编程语言和广泛的数据库之间独立于数据库的连接标准的Java API 根本上说JDBC是一种规范,它提供的接口,一套完整的,允许便捷式访问底…...

【ROS】Nav2源码之nav2_planner详解
【ROS】郭老二博文之:ROS目录 1、简述 nav2_planner是路径规划器,把起始位置、姿势的信息输入nav2_planner模块,将会生成可行路径。 nav2_planner路径规划器和nav2_controller控制器相似,也使用插件的形式加载不同的路径规划器。 常用的路径规划器插件有: 1)NavFn Plan…...

Illustrator脚本合集:设计师的10倍效率提升神器
Illustrator脚本合集:设计师的10倍效率提升神器 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是否厌倦了在Adobe Illustrator中重复繁琐的操作?是否渴望…...
:降级策略与熔断保护,保证高峰期服务不被大图请求拖垮)
Pytorch图像去噪实战(八十):降级策略与熔断保护,保证高峰期服务不被大图请求拖垮
Pytorch图像去噪实战(八十):降级策略与熔断保护,保证高峰期服务不被大图请求拖垮 一、问题场景:高峰期几个大图请求,把整个服务拖慢 图像去噪服务在高峰期最怕两类请求: 超大图片 高质量模型请求 它们会占用大量 CPU/GPU 时间,导致普通小图请求也变慢。 这时如果没有…...

FPGA实战:基于Verilog的正交调制解调系统设计与仿真验证
1. 正交调制解调系统基础认知 第一次接触正交调制解调时,我也被那些数学公式绕得头晕。后来发现,用日常生活中的例子理解会简单很多——就像两个人同时往同一个方向扔球(I路和Q路信号),接收端需要准确接住这两个球并还…...

Postman实战:自动化管理API访问令牌的两种高效策略
1. 为什么需要自动化管理API访问令牌 在如今的API开发中,身份验证和授权已经成为必不可少的安全机制。大多数现代API都采用基于令牌(Token)的认证方式,其中Bearer Token是最常见的标准之一。想象一下,每次调用API都需要手动复制粘贴一长串Tok…...

资本意志下的工程师生存指南:从高通裁员看技术与商业的博弈
1. 从一封信到四千七百张解雇单:当资本意志敲响工程师的门在科技行业,尤其是半导体这个以创新为生命线的领域,我们常常沉浸于晶体管密度、架构革新和制程竞赛的技术叙事中。然而,2015年夏天,一封来自华尔街的公开信&am…...

HiveWE:现代魔兽争霸III地图编辑器终极指南
HiveWE:现代魔兽争霸III地图编辑器终极指南 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版地图编辑器的缓慢加载和复杂操作而烦恼吗?HiveWE作为一款专注于速度…...

在多模型间切换时Taotoken路由策略带来的稳定性体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型间切换时Taotoken路由策略带来的稳定性体验 在构建基于大模型的应用时,服务的稳定性是开发者关心的核心问题之…...

禅论技术分析插件:通达信量化交易系统的架构与实践
禅论技术分析插件:通达信量化交易系统的架构与实践 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 禅论作为中国特色的技术分析理论,其严谨的数学结构和逻辑体系为市场分析提供了…...

MemOS:为AI智能体构建统一记忆操作系统,提升长期对话与RAG性能
1. 项目概述:MemOS,为AI智能体装上“记忆大脑” 如果你正在开发基于大语言模型的AI智能体,或者在使用RAG(检索增强生成)技术,那么你一定遇到过这个核心痛点: 对话上下文太短,智能体…...
)
别再手动查字典了!用EggNOG-mapper 5.0一键搞定GO/KEGG/COG注释(附完整流程)
基因功能注释自动化:EggNOG-mapper 5.0实战指南 在基因组学研究中,功能注释是连接序列数据与生物学意义的关键桥梁。传统的手动注释流程往往需要研究人员在多数据库间反复切换,不仅耗时费力,还容易引入人为误差。而EggNOG-mapper…...