强化学习案例复现(1)--- MountainCar基于Q-learning
1 搭建环境
1.1 gym自带
import gym# Create environment
env = gym.make("MountainCar-v0")eposides = 10
for eq in range(eposides):obs = env.reset()done = Falserewards = 0while not done:action = env.action_space.sample()obs, reward, done, action, info = env.step(action)env.render()rewards += rewardprint(rewards)
1.2 自行搭建(建议用该方法)
按照下文搭建MountainCar环境
往期文章:强化学习实践(三)基于gym搭建自己的环境(在gym0.26.2可运行)-CSDN博客
2.基于Q-learning的模型训练
import gym
import numpy as npenv = gym.make("GridWorld-v0")# Q-Learning settings
LEARNING_RATE = 0.1 #学习率
DISCOUNT = 0.95 #奖励折扣系数
EPISODES = 100 #迭代次数SHOW_EVERY = 1000# Exploration settings
epsilon = 1 # not a constant, qoing to be decayed
START_EPSILON_DECAYING = 1
END_EPSILON_DECAYING = EPISODES//2
epsilon_decay_value = epsilon/(END_EPSILON_DECAYING - START_EPSILON_DECAYING)DISCRETE_OS_SIZE = [20, 20]
discrete_os_win_size = (env.observation_space.high - env.observation_space.low) / DISCRETE_OS_SIZEprint(discrete_os_win_size)def get_discrete_state(state):discrete_state = (state - env.observation_space.low)/discrete_os_win_size# discrete_state = np.array(state - env.observation_space.low, dtype=float) / discrete_os_win_sizereturn tuple(discrete_state.astype(np.int64)) # we use this tuple to look up the 3 Q values for the available actions in the q-q_table = np.random.uniform(low=-2, high=0, size=(DISCRETE_OS_SIZE + [env.action_space.n]))for episode in range(EPISODES):state = env.reset()discrete_state = get_discrete_state(state)if episode % SHOW_EVERY == 0:render = Trueprint(episode)else:render = Falsedone = Falsewhile not done:if np.random.random() > epsilon:# Get action from Q tableaction = np.argmax(q_table[discrete_state])else:# Get random actionaction = np.random.randint(0, env.action_space.n)new_state, reward, done, _, c = env.step(action)new_discrete_state = get_discrete_state(new_state)# If simulation did not end yet after last step - update Q tableif not done:# Maximum possible Q value in next step (for new state)max_future_q = np.max(q_table[new_discrete_state])# Current Q value (for current state and performed action)current_q = q_table[discrete_state + (action,)]# And here's our equation for a new Q value for current state and actionnew_q = (1 - LEARNING_RATE) * current_q + LEARNING_RATE * (reward + DISCOUNT * max_future_q)# Update Q table with new Q valueq_table[discrete_state + (action,)] = new_q# Simulation ended (for any reson) - if goal position is achived - update Q value with reward directlyelif new_state[0] >= env.goal_position:# q_table[discrete_state + (action,)] = rewardq_table[discrete_state + (action,)] = 0print("we made it on episode {}".format(episode))discrete_state = new_discrete_stateif render:env.render()# Decaying is being done every episode if episode number is within decaying rangeif END_EPSILON_DECAYING >= episode >= START_EPSILON_DECAYING:epsilon -= epsilon_decay_valuenp.save("q_table.npy", arr=q_table)env.close()
3.模型测试
import gym
import numpy as npenv = gym.make("GridWorld-v0")# Q-Learning settings
LEARNING_RATE = 0.1
DISCOUNT = 0.95
EPISODES = 10DISCRETE_OS_SIZE = [20, 20]
discrete_os_win_size = (env.observation_space.high - env.observation_space.low) / DISCRETE_OS_SIZEdef get_discrete_state(state):discrete_state = (state - env.observation_space.low)/discrete_os_win_sizereturn tuple(discrete_state.astype(np.int64)) # we use this tuple to look up the 3 Q values for the available actions in the q-q_table = np.load(file="q_table.npy")for episode in range(EPISODES):state = env.reset()discrete_state = get_discrete_state(state)rewards = 0done = Falsewhile not done:# Get action from Q tableaction = np.argmax(q_table[discrete_state])new_state, reward, done, _, c = env.step(action)new_discrete_state = get_discrete_state(new_state)rewards += reward# If simulation did not end yet after last step - update Q tableif done and new_state[0] >= env.goal_position:print("we made it on episode {}, rewards {}".format(episode, rewards))discrete_state = new_discrete_stateenv.render()env.close()相关文章:
--- MountainCar基于Q-learning)
强化学习案例复现(1)--- MountainCar基于Q-learning
1 搭建环境 1.1 gym自带 import gym# Create environment env gym.make("MountainCar-v0")eposides 10 for eq in range(eposides):obs env.reset()done Falserewards 0while not done:action env.action_space.sample()obs, reward, done, action, info env.…...
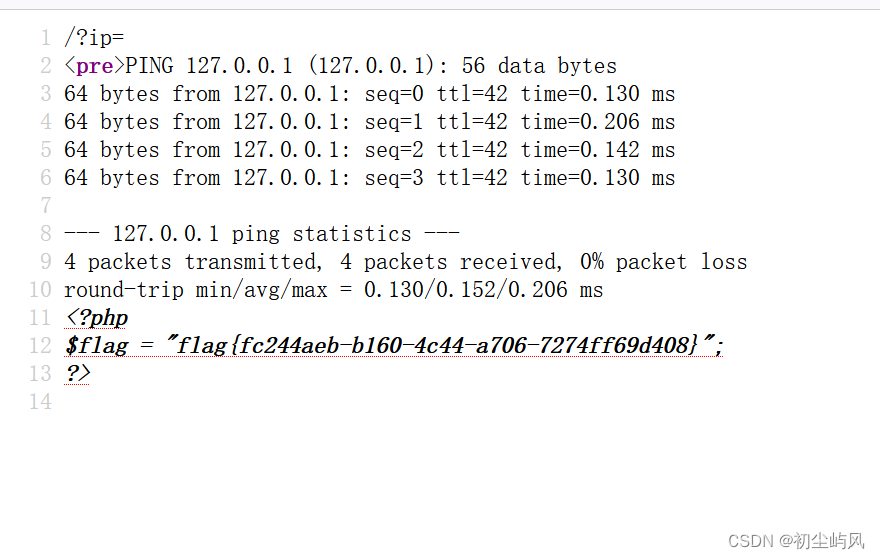
BUUCTF学习(6): 命令执行ip
1、介绍 2、hackbar安装 BUUCTF学习(四): 文件包含tips-CSDN博客 ?ip127.0.0.1;ag;cat$IFS$9fla$a.php 空格过滤 $IFS$9 检查源代码 结束...
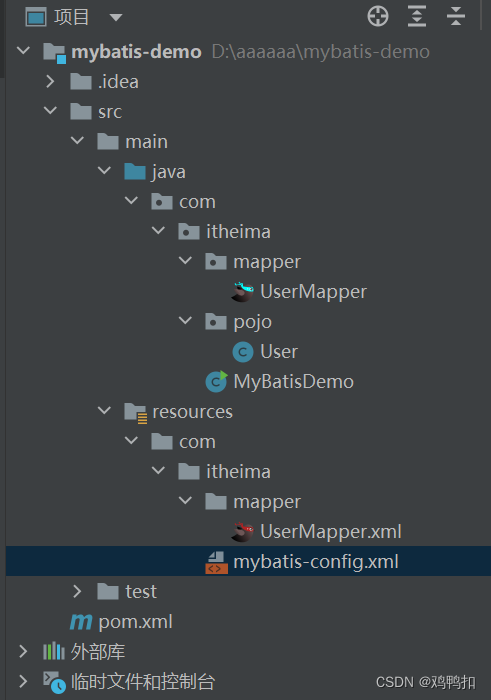
javaweb:mybatis:mapper(sql映射+代理开发+配置文件之设置别名、多环境配置、顺序+注解开发)
1.0版本 sql映射文件实现 流程 首先程序进入启动类MyBatisDemo.java中,读取配置文件mybatis-config.xml 再由mybatis-config的mappers属性 <mappers><mapper resource"UserMapper.xml"></mapper></mappers>找到sql映射文件Use…...
)
JavaScript基础知识——练习巩固(2)
写一个程序,要求如下 需求1:让用户输入五个有效年龄(0-100之间),放入数组中 必须输入五个有效年龄年龄,如果是无效年龄,则不能放入数组中 需求2:打印出所有成年人的年龄 (数组筛选)…...
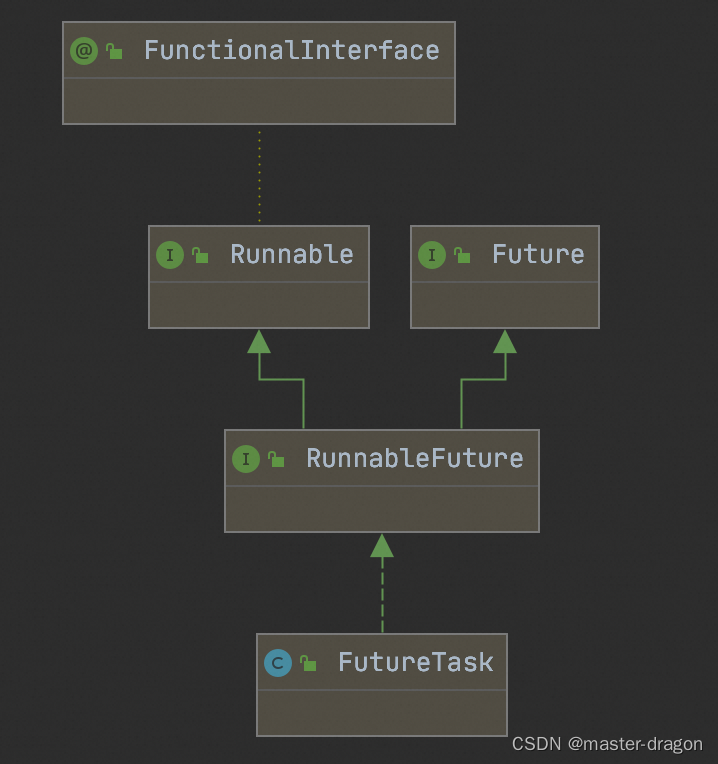
FutureTask的测试使用和方法执行分析
FutureTask类图如下 java.util.concurrent.FutureTask#run run方法执行逻辑如下 public void run() {if (state ! NEW ||!RUNNER.compareAndSet(this, null, Thread.currentThread()))return;try {Callable<V> c callable;if (c ! null && state NEW) {V res…...

SpringMVC的请求处理
目录 请求映射路径的配置 请求数据的接收 接收Restful风格的数据 什么是Restful风格? 接收上传文件 获取headers头信息和cookie信息 JavaWeb常用对象获取 请求静态资源 注解驱动标签 请求映射路径的配置 请求映射路径的配置主要是通过RequestMapping注解实现…...

260. 只出现一次的数字 III
给你一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。你可以按 任意顺序 返回答案。 你必须设计并实现线性时间复杂度的算法且仅使用常量额外空间来解决此问题。 示例 1: 输入&…...

家政预约接单系统,家政保洁小程序开发;
家政预约接单系统,家政保洁维修小程序开发,阿姨管理,家政保险,合同管理,资金管理,营销推广等功能,包括:推广、营销、管理、培训、周边服务等等 家政系统详细功能介绍: 家…...

网络安全工程师需要学什么?零基础怎么从入门到精通,看这一篇就够了
网络安全工程师需要学什么?零基础怎么从入门到精通,看这一篇就够了 我发现关于网络安全的学习路线网上有非常多看似高大上却无任何参考意义的回答。大多数的路线都是给了一个大概的框架,告诉你那些东西要考,以及建议了一个学习顺…...
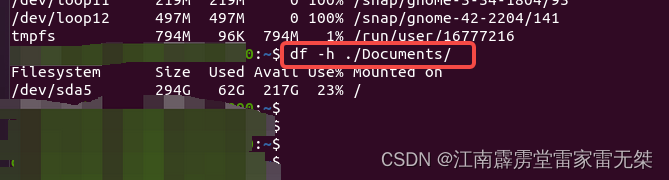
出差学知识No3:ubuntu查询文件大小|文件包大小|磁盘占用情况等
1、查询单个文件占用内存大小2、显示一个目录下所有文件和文件包的大小3、显示ubuntu所有磁盘的占用情况4、查看ubuntu单个包的占用情况 1、查询单个文件占用内存大小 使用指令:ls -lh 文件 2、显示一个目录下所有文件和文件包的大小 指令:du -sh* 3…...

详解cv2.copyMakeBorder函数【OpenCV图像边界填充Python版本】
文章目录 简介函数原型代码示例参考资料 简介 做深度学习图像数据集时,有时候需要调整一张图片的长和宽。如果直接使用cv2.resize函数会造成图像扭曲失真,因此我们可以采取填充图像短边的方法解决这个问题。cv2.copyMakeBorder函数提供了相关操作。本篇…...
前端技术-并发请求
并发请求 代码解释 定义了一个函数 concurRequest,用于并发请求多个 URL 并返回它们的响应结果。 function concurRequest(urls, maxNum) {return new Promise((resolve, reject) > {if (urls.length 0) {resolve([]);return;}const results [];let index …...
:React中获取Refs的几种方式)
面试题-React(十三):React中获取Refs的几种方式
一、Refs的基本概念 Refs是React提供的一种访问DOM元素或组件实例的方式。通过Refs,我们可以在React中获取到底层的DOM节点或组件实例,并进行一些操作。Refs的使用场景包括但不限于:访问DOM属性、调用组件方法、获取输入框的值等。 二、获取…...

Linux CentOS 7升级curl8.4.0使用编译安装方式
1、查看当前版本 # curl --version curl 7.29.0 (x86_64-redhat-linux-gnu) libcurl/7.29.0 NSS/3.19.1 Basic ECC zlib/1.2.7 libidn/1.28 libssh2/1.4.3 Protocols: dict file ftp ftps gopher http https imap imaps ldap ldaps pop3 pop3s rtsp scp sftp smtp smtps tel…...
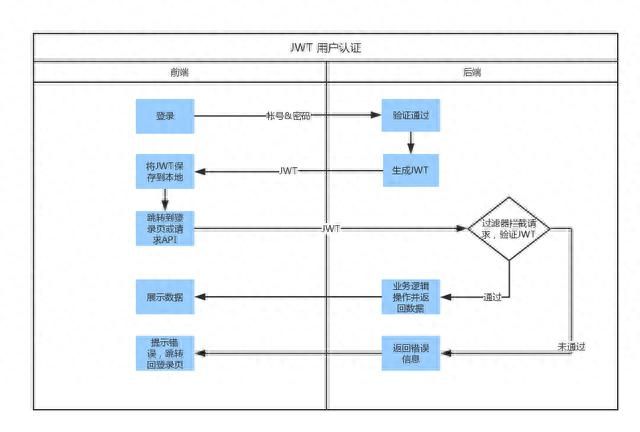
探寻JWT的本质:它是什么?它有什么作用?
JWT(JSON Web Token)是一种基于 JSON 格式的轻量级令牌(token)协议,它被广泛应用于网络应用程序的身份验证和授权。相较于传统的 session-based 认证机制,JWT 具有更好的扩展性和互操作性,同时也…...

关于雅思听力答案限定字数的解释。
1. No more than three words and/or a number:31,可以填3/2/1个单词;1个数字;3/2/1个单词1个数字 2. No more than three words and/or numbers:3n,可以填3/2/1个单词;n个数字;3/2…...

化工python | CSTR连续搅拌反应器系统
绝热连续搅拌釜反应器 (CSTR) 是过程工业中常见的化学系统。 容器中发生单个一级放热且不可逆的反应 A → B,假定容器始终完全混合。 试剂 A 的入口流以恒定的体积速率进入罐。 产物流B以相同的体积速率连续排出,液体密度恒定。 因此,反应液体的体积是恒定的。 在反应器中发…...

交通物流模型 | 基于自监督学习的交通流预测模型
交通物流模型 | 基于自监督学习的交通流预测模型 在智能交通系统中,准确预测不同时间段的城市交通流量是至关重要的。现有的方法存在两个关键的局限性:1、大多数模型集中预测所有区域的交通流量,而没有考虑空间异质性,即不同区域的交通流量分布可能存在偏差;2、现有模型无…...
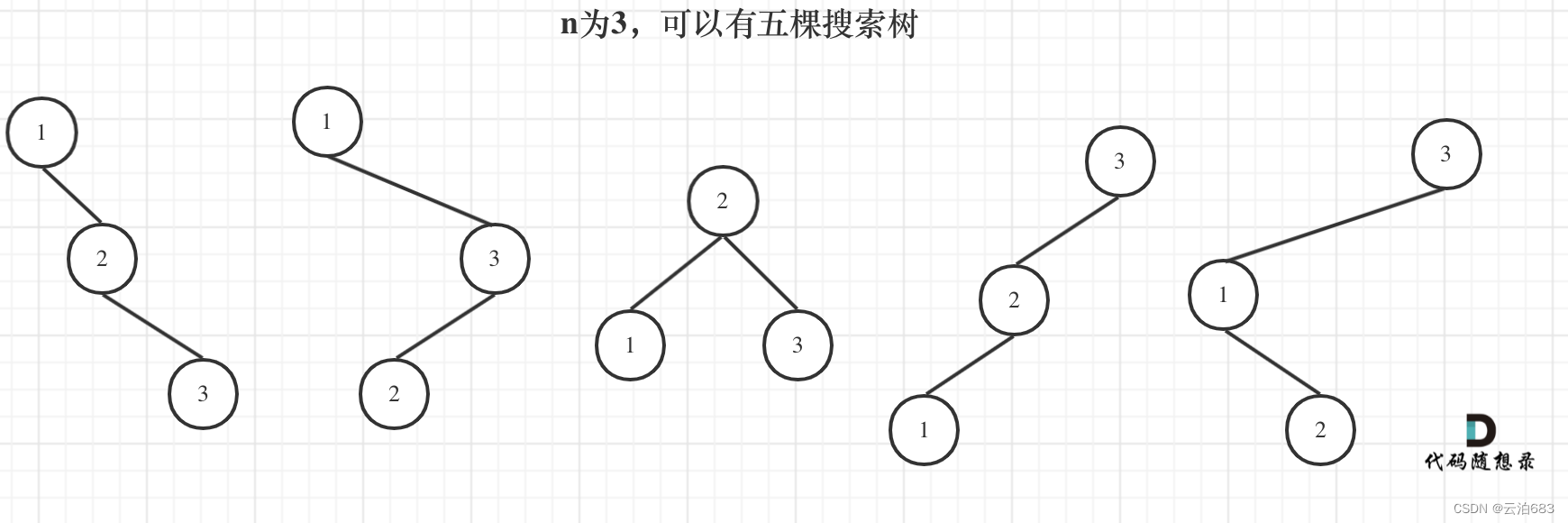
343. 整数拆分 96.不同的二叉搜索树
343. 整数拆分 设dp[i]表示拆分 数字i 出来的正整数相乘值最大的值 (i - j) * j,和dp[i - j] * j是获得dp[i]的两种乘法,在里面求最大值可以得到当前dp[i]的最大值,但是这一次的得出的最大值如果赋值给dp[i],可能没有没赋值的dp[i]大&#…...
)
Vue3理解(9)
侦听器 1.计算属性允许我们声明性地计算衍生值,而在有些情况下,我们需要状态变化时执行一些方法例如修改DOM。 2.侦测数据源类型,watch的第一个参数可以市不同形式的‘数据源’,它可以市一个ref(包括计算属性),一个响应式对象&…...
)
Spring Boot项目对接公司AD域,手把手搞定用户登录和密码重置(附SSL证书避坑指南)
Spring Boot企业级AD域集成实战:从登录到密码重置的全链路解决方案 当企业IT系统发展到一定规模,统一身份认证就成了刚需。上周我接手了一个内部ERP系统的改造项目,要求对接公司Active Directory实现员工单点登录——听起来简单,但…...

如何高效获取金融数据:Python通达信接口的完整指南
如何高效获取金融数据:Python通达信接口的完整指南 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易领域,获取准确、及时且成本可控的市场数据一直…...

LinkSwift网盘直链下载助手:八大平台高速下载解决方案
LinkSwift网盘直链下载助手:八大平台高速下载解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

LoRA微调工程化2026:从实验到生产的完整落地指南
LoRA(Low-Rank Adaptation)已经成为大模型微调的工业标准。不是因为它最先进,而是因为它在成本、效果、灵活性之间取得了最好的平衡。本文从工程实践角度,覆盖LoRA微调的完整流程——从数据准备、训练配置到生产部署。 LoRA的工程…...

Google Authenticator停更引发恐慌?自建TOTP动态口令系统其实没那么难,附技术实现方案
摘要:2023年,Google Authenticator推出账号同步功能,将TOTP密钥同步到Google账号云端,引发了安全社区的广泛争议——密钥上云意味着什么?企业级场景中,依赖第三方应用管理关键认证密钥本身就是隐患。本文讲…...

基于MCP协议快速构建AI助手自定义工具:从入门到生产实践
1. 项目概述:一个为AI助手打造自定义工具的快速启动器如果你正在使用Claude Desktop或者Cursor这类AI编程助手,并且觉得它们内置的功能还不够用,比如你想让它直接查询你项目的数据库、调用某个内部API,或者执行一些特定的文件操作…...

光伏产业价值链迁移:从硬件制造到系统服务与金融创新的黄金机遇
1. 光伏行业的价值转移:从硬件制造到系统服务十年前,当我在深圳第一次接触光伏组件生产线时,满眼都是硅料、银浆和层压机,行业里人人谈论的是转换效率又提升了零点几个百分点,或是每瓦成本又降了几分钱。那时候&#x…...
)
别再死记硬背公式了!用‘井字棋’和‘抢30’游戏带你直观理解巴什博弈(Bash Game)
用童年游戏破解数学奥秘:从"抢30"到巴什博弈的思维跃迁 记得小时候和伙伴们玩"抢30"游戏吗?两人轮流报数,每次可以说1到3个连续数字,谁先喊出"30"谁就获胜。这个看似简单的游戏背后,隐藏…...

解决ROS的‘Done checking log file disk usage’卡顿:你的~/.bashrc里ROS_IP设对了吗?
解决ROS日志检查卡顿:环境变量配置的深层解析与实战指南 当你在终端启动roscore时,是否遇到过长时间卡在"Done checking log file disk usage"提示的尴尬?这个问题看似简单,背后却隐藏着ROS环境配置的关键细节。本文将带…...

基于Rust构建命令行任务监控与通知工具:openclaw-tui-notify实践
1. 项目概述与核心价值最近在折腾一个后台数据处理脚本,它经常一跑就是好几个小时。问题来了,我总不能一直盯着终端看它什么时候结束吧?有时候去开个会、吃个饭,回来发现脚本早就跑完了,白白浪费了时间等结果。更头疼的…...