【日常业务开发】接口性能优化
【日常业务开发】接口性能优化
- 缓存
- 本地缓存
- 分布式缓存
- 数据库
- 分库分表
- SQL 优化
- 业务程序
- 并行化
- 异步化
- 池化技术
- 预先计算
- 事务粒度
- 批量读写
- 锁的粒度
- 尽快return
- 上下文传递
- 空间换时间
- 集合空间大小
缓存
本地缓存
本地缓存,最大的优点是应用和cache同一个进程内部,请求缓存非常快速,没有过多的网络开销等,在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用本地缓存较合适。缺点也是因为缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
常用的本地缓存框架有 Guava、Caffeine 等,都是些单独的jar包 ,直接导入到工程里即可使用。
我们可以根据自己的需要灵活选择想要哪个框架。
@Configuration
public class CaffeineCacheConfig {@Beanpublic Cache<String, Object> caffeineCache() {return Caffeine.newBuilder()// 设置最后一次写入或访问后经过固定时间过期.expireAfterWrite(60, TimeUnit.SECONDS)// 初始的缓存空间大小.initialCapacity(100)// 缓存的最大条数.maximumSize(1000).build();}
}
本地缓存适用两种场景:
- 对缓存内容时效性要求不高,能接受一定的延迟,可以设置较短过期时间,被动失效更新保持数据的新鲜度。
- 缓存的内容不会改变。比如:订单号与uid的映射关系,一旦创建就不会发生改变。
注意问题:
- 内存 Cache 数据条目上限控制,避免内存占用过多导致应用瘫痪。
- 内存中的数据移出策略。
- 虽然实现简单,但潜在的坑比较多,最好选择一些成熟的开源框架。
分布式缓存
本地缓存的使用很容易让你的应用服务器带上“状态”,而且容易受内存大小的限制。
分布式缓存借助分布式的概念,集群化部署,独立运维,容量无上限,虽然会有网络传输的损耗,但这1~2ms的延迟相比其更多优势完成可以忽略。
优秀的分布式缓存系统有大家所熟知的Memcached 、Redis。对比关系型数据库和缓存存储,其在读和写性能上的差距可谓天壤之别,redis单节点已经可以做到8W+ QPS(系统每秒处理查询的次数)。设计方案时尽量把读写压力从数据库转移到缓存上,有效保护脆弱的关系型数据库。
注意问题:
- 缓存的命中率,如果太低无法起到抗压的作用,压力还是压到了下游的存储层。
- 缓存的空间大小,这个要根据具体业务场景来评估,防止空间不足,导致一些热点数据被置换出去。
- 缓存数据的一致性。
- 缓存的快速扩容问题。
- 缓存的接口平均RT,最大RT,最小RT。
- 缓存的QPS。
- 网络出口流量。
- 客户端连接数。
数据库
分库分表
MySQL的底层 innodb 存储引擎采用 B+ 树结构,三层结构支持千万级的数据存储。
当然,现在互联网的用户基数非常大,这么大的用户量,单表通常很难支撑业务需求,将一个大表水平拆分成多张结构一样的物理表,可以极大缓解存储、访问压力。
SQL 优化
虽然有了分库分表,从存储维度可以减少很大压力,但「富不过三代」,我们还是要学会精打细算,就比如所有的数据库操作都是通过 SQL 来执行。
一个不好的SQL会对接口性能产生很大影响。
比如:
1、搞了个深度翻页,每次数据库引擎都要预查非常多的数据。
select * from purchase_record where productCode = 'PA9044' and status=4 order by orderTime desc limit 100000,200
limit 100000,200 意味着会扫描 100200 行,然后返回 200 行,丢弃掉前 100000 行。所以执行速度很慢。一般可以采用标签记录法来优化,比如:
select * from purchase_record where productCode = 'PA9044' and status=4 and id > 100000 limit 200
这样优化的好处是命中了主键索引,无论多少页,性能都还不错,但是局限性是id需要一个连续自增的字段
2、索引缺失,走了全表扫描。
3、避免一次从 DB 中查询大量的数据到内存中,可能会导致内存不足,建议采用分批、分页查询。
业务程序
并行化
梳理业务流程,画出时序图,分清楚哪些是串行?哪些是并行?充分利用多核 CPU 的并行化处理能力。
如下图所示,存在上下文依赖的采用串行处理,否则采用并行处理。

JDK 的 CompletableFuture 提供了非常丰富的API,大约有50种 处理串行、并行、组合以及处理错误的方法,可以满足我们的场景需求。
异步化
一个接口的 RT 响应时间是由内部业务逻辑的复杂度决定的,执行的流程约简单,那接口的耗费时间就越少。
所以,普遍做法就是将接口内部的非核心逻辑剥离出来,异步化来执行。
下图是一个电商的创建订单接口,创建订单记录并插入数据库是我们的核心诉求,至于后续的用户通知,如:给用户发个短信等,如果失败,并不影响主流程的完成。
我们会将这些操作从主流程中剥离出来。

异步的实现方式,可以用线程池,也可以用消息队列,还可以用一些调度任务框架。
业务的普遍做法就是,下单成功后,发送一条异步消息到MQ 服务器,由消费端监听 topic,异步消费执行。
池化技术
我们都用过数据库连接池,线程池等,这就是池思想的体现,它们解决的问题就是避免重复创建对象或创建连接,可以重复利用,避免不必要的损耗,毕竟创建销毁也会占用时间。
池化技术的核心是资源的“预分配”和“循环使用”,常见的池化技术的使用有:线程池、内存池、数据库连接池、HttpClient 连接池等。
连接池的几个重要参数:最小连接数、空闲连接数、最大连接数。
比如创建一个线程池:
new ThreadPoolExecutor(3, 15, 5, TimeUnit.MINUTES,new ArrayBlockingQueue<>(10),new ThreadFactoryBuilder().setNameFormat("data-thread-%d").build(),(r, executor) -> {(r instanceof BaseRunnable) {((BaseRunnable) r).rejectedExecute();}});
预先计算
有很多业务的计算逻辑比较复杂,比如页面要展示一个网站的 PV、微信的拼手气红包等。
如果在用户访问接口的瞬间触发计算逻辑,而这些逻辑计算的耗时通常比较长,很难满足用户的实时性要求。
也就是预取思想,就是提前要把查询的数据,提前计算好,放入缓存,接口访问时,只需要读缓存即可,会大幅提高接口性能。
比如:定时同步mysql库存数据到redis中,当请求扣减库存时,先通过redis setNX去重/mysql去重表,再通过redis decrement减库存数据,然后发送一条异步消息到MQ 服务器
消费端监听 topic,异步多线程消费。
1、减库存(先查在更新),写订单表,必须是同一个事物。如果是单节点,可以使用synchronized加锁,解决线程安全问题。
synchronized错误加锁方法: 锁在事物里面
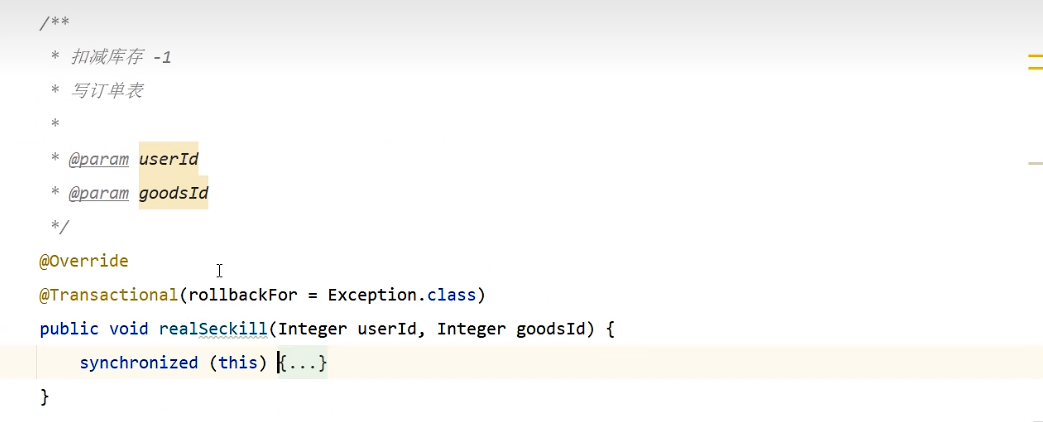
synchronized正确加锁方法: 锁在事物外面
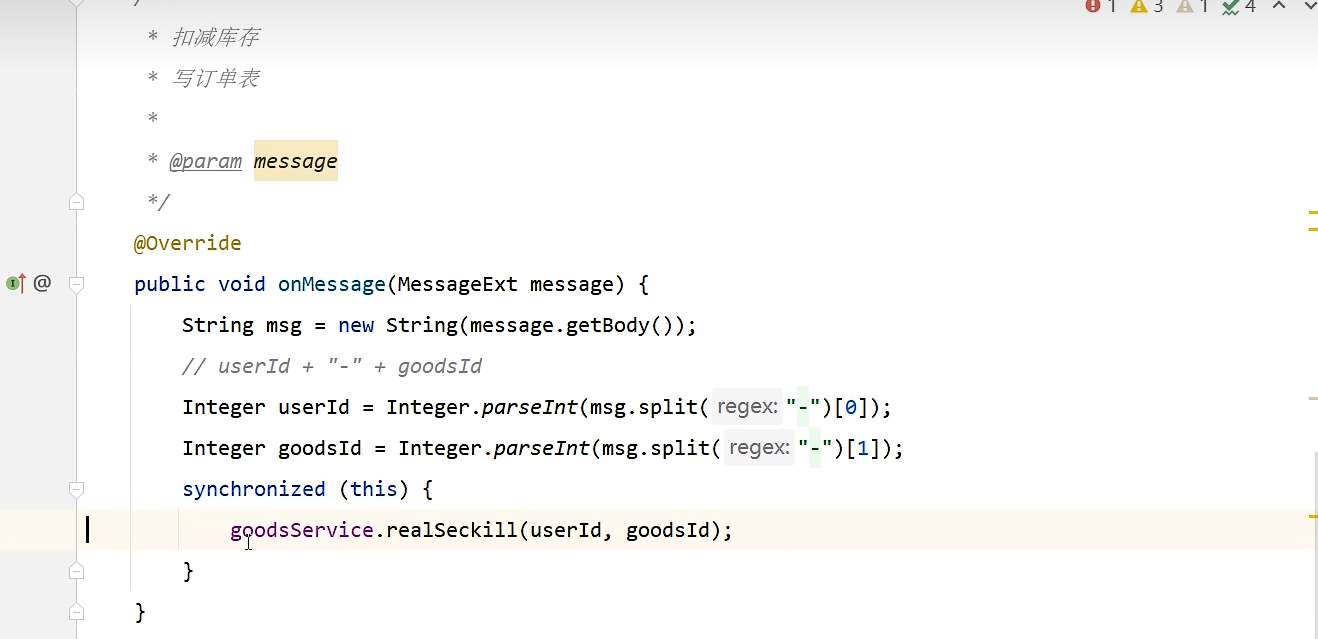
2、如果是分布式多节点,需要加分布式锁 : mysql行锁/redis锁。
mysql行锁: 向下提取,并发不高可以使用,并发高,导致数据库压力大。
update goods set total_stocks = total_stocks-1 where user_id = ? and total_stocks-1>=0
redis锁: 向上提取,redis setnx分布式锁,压力会分摊到redis和程序中执行 缓解db的压力
redisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
判断是否需要自旋
1、while(true) {} 实现自旋
@Component
@RocketMQMessageListener(topic = "seckillTopic3",consumerGroup = "seckill-consumer-group3",consumeMode = ConsumeMode.CONCURRENTLY,consumeThreadMax = 40
)
public class SeckillListener implements RocketMQListener<MessageExt> {@Autowiredprivate GoodsService goodsService;@Autowiredprivate StringRedisTemplate redisTemplate;@Overridepublic void onMessage(MessageExt message) {String msg = new String(message.getBody());Integer userId = Integer.parseInt(msg.split("-")[0]);Integer goodsId = Integer.parseInt(msg.split("-")[1]);while (true) {// 这里给一个key的过期时间,可以避免死锁的发生Boolean flag = redisTemplate.opsForValue().setIfAbsent("lock:" + goodsId, "", Duration.ofSeconds(30));if (flag) {// 拿到锁成功try {goodsService.realSeckill(userId, goodsId);return;} finally {// 删除redisTemplate.delete("lock:" + goodsId);}} else {try {Thread.sleep(200L);} catch (InterruptedException e) {e.printStackTrace();}}}}
2、递归调用实现自旋
@Override
public void onMessage(MessageExt message) {String msg = new String(message.getBody());Integer userId = Integer.parseInt(msg.split("-")[0]);Integer goodsId = Integer.parseInt(msg.split("-")[1]);// 这里给一个key的过期时间,可以避免死锁的发生Boolean flag = redisTemplate.opsForValue().setIfAbsent("lock:" + goodsId, "", Duration.ofSeconds(30));if (flag) {// 拿到锁成功try {goodsService.realSeckill(userId, goodsId);} finally {// 删除redisTemplate.delete("lock:" + goodsId);}} else {try {Thread.sleep(200L);} catch (InterruptedException e) {e.printStackTrace();}onMessage(message);}}
@Service
public class GoodsServiceImpl implements GoodsService {@Resourceprivate GoodsMapper goodsMapper;@Autowiredprivate OrderMapper orderMapper;/*** 行锁(innodb)方案 mysql 不适合用于并发量特别大的场景* 因为压力最终都在数据库承担** @param userId* @param goodsId*/@Override@Transactional(rollbackFor = Exception.class)public void realSeckill(Integer userId, Integer goodsId) {// update goods set total_stocks = total_stocks - 1 where goods_id = goodsId and total_stocks - 1 >= 0;// 通过mysql来控制锁int i = goodsMapper.updateStock(goodsId);if (i > 0) {Order order = new Order();order.setGoodsid(goodsId);order.setUserid(userId);order.setCreatetime(new Date());orderMapper.insert(order);}}
}
修改库存
<update id="updateStock">update goods set total_stocks = total_stocks - 1 ,update_time = now() where goods_id = #{value} and total_stocks - 1 >= 0
</update>
写订单表
<insert id="insert" keyColumn="id" keyProperty="id" parameterType="cn.zysheep.domain.Order" useGeneratedKeys="true">insert into `order` (userid, goodsid, createtime)values (#{userid,jdbcType=INTEGER}, #{goodsid,jdbcType=INTEGER}, #{createtime,jdbcType=TIMESTAMP})
</insert>
事务粒度
很多业务逻辑有事务要求,针对多个表的写操作要保证事务特性。
但事务本身又特别耗费性能,为了能尽快结束,不长时间占用数据库连接资源,我们一般要减少事务的范围。
将很多查询逻辑放到事务外部处理。
另外在事务内部,一般不要进行远程的 RPC 接口访问,一般占用的时间比较长。引发的问题主要有:死锁、接口超时、主从延迟等。
批量读写
当下的计算机CPU处理速度还是很多的,而 IO 一般是个瓶颈,如:磁盘IO、网络IO。
有这么一个场景,查询 100 个人的账户余额?
有两个设计方案:
方案一:开单次查询接口,调用方内部循环调用 100 次。
方案二:服务提供方开一个批量查询接口,调用方只需查询 1 次。
你觉得那种方案更好?
答案不言而喻,肯定是方案二。
数据库的写操作也是一样道理,为了提高性能,我们一般都是采用批量更新。
锁的粒度
锁一般是为了在高并发场景下保护共享资源采用的一种手段,但是如果锁的粒度太粗,会很影响接口性能。
关于锁粒度:就是你要锁的范围有多大,不管是synchronized 还是 redis分布式锁,只需要在临界资源处加锁即可,不涉及共享资源的,不必要加锁,就好比你要上卫生间,只需要把卫生间的门锁上就可以,不需要把客厅的门也锁上。
控制锁的范围是我们要考虑的重点。
错误的加锁方式:
//非共享资源private void notShare(){}//共享资源private void share(){}private int wrong(){synchronized (this) {share();notShare();}}
正确的加锁方式:
//非共享资源
private void notShare(){
}
//共享资源
private void share(){
}
private int right(){notShare();synchronized (this) {share();}
}
尽快return
业务逻辑开始前先对必要参数或者集合进行判断,不成立尽快return/throw返回
if(CollectionUtils.isEmpty(list)) {throw new RuntimeException("数据不合法");
}
上下文传递
当需要一个数据时,如果没有调 RPC 接口去查,比如想用户信息这种通用型接口。
因为前面要用,肯定已经查过。但是我们知道方法的调用都是以栈帧的形式来传递,随着一个方法执行完毕而出栈,方法内部的局部变量也就被回收了。
后面如果又要用到这个信息,只能重新去查。
如果能定义一个Context 上下文对象(ThreadLocal),将一些中间信息存储并传递下来,会大大减轻后面流程的再次查询压力。
空间换时间
一个很好理解的空间换时间的例子是合理使用缓存,针对一些频繁使用且不频繁变更的数据,可以提前缓存起来,需要时直接查缓存,避免频繁地查询数据库或者重复计算。
集合空间大小
如果我们预先知道集合要存储多少元素,初始化集合时尽量指定大小,尤其是容量较大的集合。
ArrayList 初始大小是 10,超过阈值会按 1.5 倍大小扩容,涉及老集合到新集合的数据拷贝,浪费性能。
相关文章:
【日常业务开发】接口性能优化
【日常业务开发】接口性能优化 缓存本地缓存分布式缓存 数据库分库分表SQL 优化 业务程序并行化异步化池化技术预先计算事务粒度批量读写锁的粒度尽快return上下文传递空间换时间集合空间大小 缓存 本地缓存 本地缓存,最大的优点是应用和cache同一个进程内部&…...
Android 10.0 禁止弹出系统simlock的锁卡弹窗功能实现
1.前言 在10.0的系统开发中,在一款产品中,需要实现simlock锁卡功能,在系统实现锁卡功能以后,在开机的过程中,或者是在插入sim卡 后,当系统检测到是禁用的sim卡后,就会弹出simlock锁卡弹窗,要求输入puk 解锁密码,功能需求禁用这个弹窗,所以就需要看是 哪里弹的,禁用…...
VulnHub lazysysadmin
一、信息收集 1.nmap扫描开发端口 开放了:22、80、445 访问80端口,没有发现什么有价值的信息 2.扫描共享文件 enum4linux--扫描共享文件 使用: enum4linux 192.168.103.182windows访问共享文件 \\192.168.103.182\文件夹名称信息收集&…...

ppt怎么压缩到10m以内?分享ppt缩小方法
在日常工作中,我们常常需要制作和分享PowerPoint演示文稿,然而,有时候文稿中的图片、视频等元素会导致文件过大,无法在电子邮件或其他平台上顺利传输。为了将PPT文件压缩到10M以内,我们可以使用一些专门的文件压缩工具…...
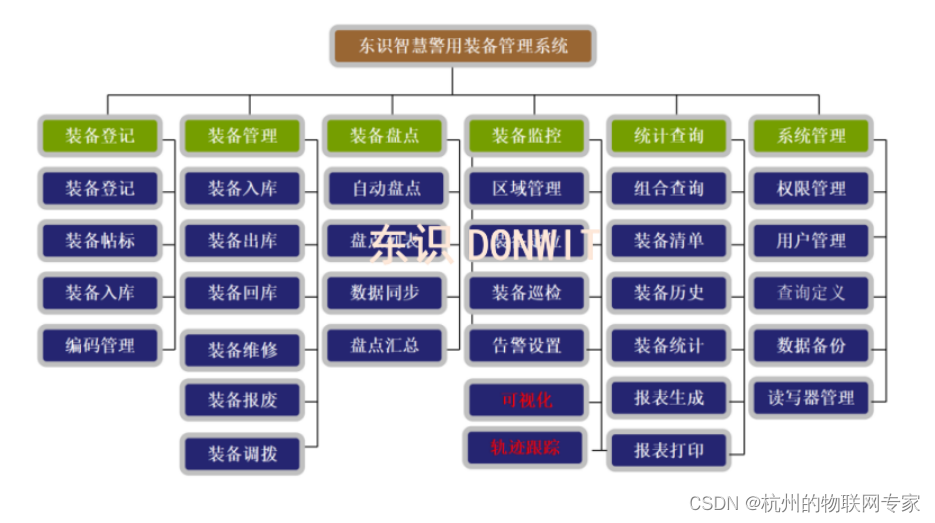
智能警用装备管理系统-科技赋能警务
警用物资装备管理系统(智装备DW-S304)是依托互云计算、大数据、RFID技术、数据库技术、AI、视频分析技术对警用装备进行统一管理、分析的信息化、智能化、规范化的系统。 (1)感知智能化 装备感知是整个方案的基础,本方…...

攻防千层饼
近年来,网络安全领域正在经历一场不断升级的攻防对抗,这场攻防已经不再局限于传统的攻击与防御模式,攻击者和防守者都已经越发熟练,对于传统攻防手法了如指掌。 在这个背景下,攻击者必须不断寻求创新的途径࿰…...

组件封装使用?
组件封装是指在软件开发中,将功能代码或数据封装成一个独立的、可重用的模块或组件。这种封装可以使得代码更加模块化、可维护性和可重用性。在许多编程语言和开发框架中,都有不同的方式来实现组件封装。 以下是一些常见的组件封装方法和技巧࿱…...
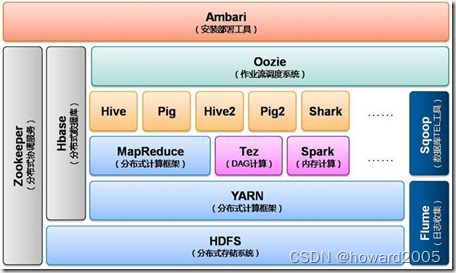
2.3 初探Hadoop世界
文章目录 零、学习目标一、导入新课二、新课讲解(一)Hadoop的前世今生1、Google处理大数据三大技术2、Hadoop如何诞生3、Hadoop主要发展历程 (二)Hadoop的优势1、扩容能力强2、成本低3、高效率4、可靠性5、高容错性 (三…...
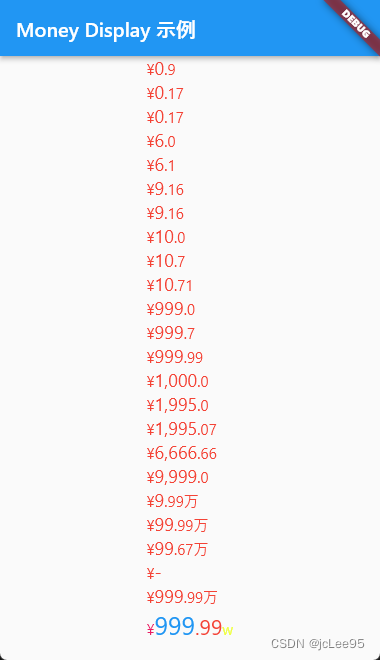
Flutter笔记:发布一个电商中文货币显示插件Money Display
Flutter笔记 电商中文货币显示插件 Money Display 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/1338…...
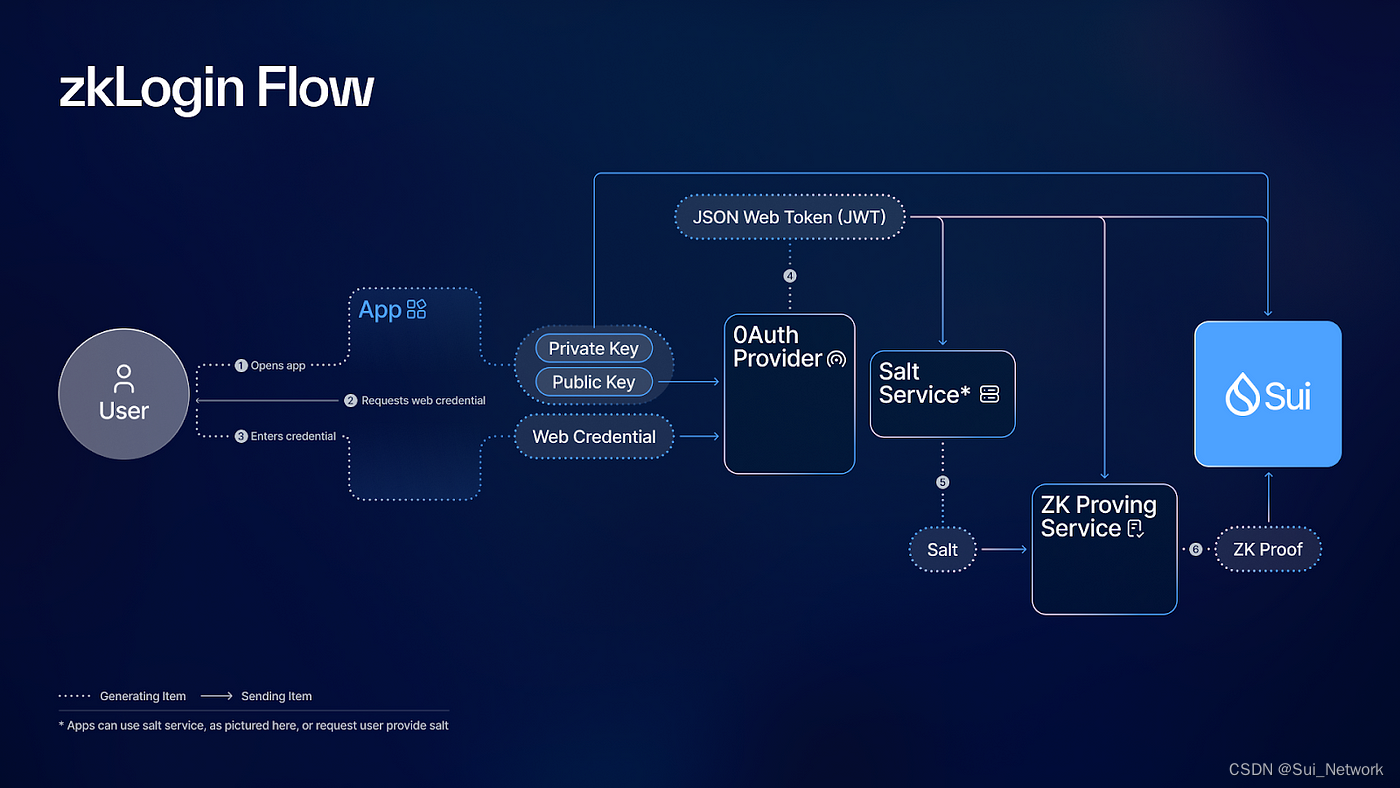
解密zkLogin:探索前沿的Sui身份验证解决方案
由于钱包复杂性导致的新用户入门障碍是区块链中一个长期存在的问题,而zkLogin是其简单的解决方案。通过使用前沿的密码学和技术,zkLogin既优雅又复杂。本文深入探讨了zkLogin的工作原理,涵盖了用户和开发者的安全性方面,并解释了S…...

js构造函数
构造函数 通过 new 函数名 来实例化对象的函数叫构造函数。 任何的函数都可以作为构造函数存在。之所以有构造函数与普通函数之分,主要从功能上进行区别的,构造函数的主要 功能为 初始化对象,特点是和new 一起使用。new就是在创建对象&#x…...
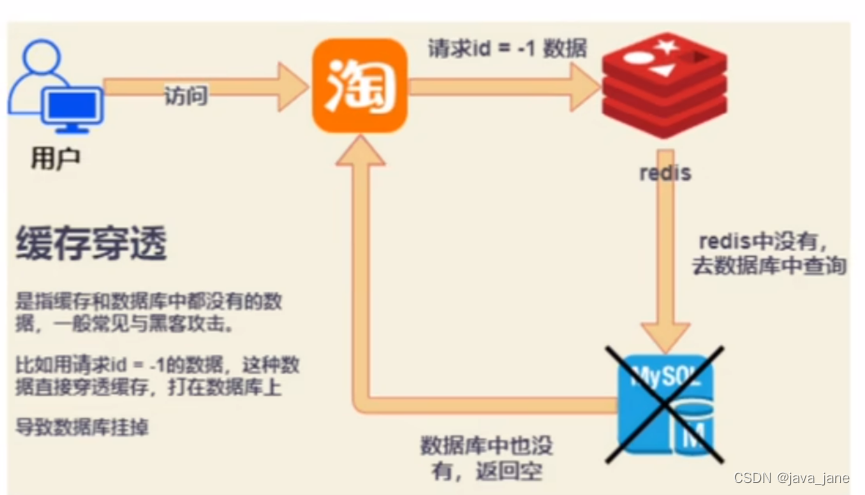
性能测试-redis常见问题
缓存击穿、缓存穿透、缓存雪崩 缓存雪崩 解决办法 1.设置缓存失效时间,不要在同一时间 2.redis集群部署 3.不设置缓存设置时间 4.定时刷缓存的时间 缓存穿透 请求不管返回什么数据都返回给redis对参数合法器进行验证,不合法的时候直接过滤掉使用布…...

预测:2024 年将是互联网永远改变的一年。
人工智能的下一步发展将彻底改变互联网的各个方面。 如果你真的认为人工智能只是另一个炒作周期,那么你就会迎来新的觉醒。 以下是即将发生的事情: 1. 自主待办事项列表/代理:无需人工干预即可执行任务的人工智能。 这些代理将发送您的电子邮…...

Vue2 与 React 的区别
【5年以上前端】Vue 和 React 的区别看这里 - 知乎 vue和react的区别_vue react-CSDN博客 Vue 和 React 有什么不同?_vue和react区别-CSDN博客 1、相同点: ① 都使用了虚拟 DOM; ② 组件化开发; ③ 都是单向数据流ÿ…...

【AI视野·今日Robot 机器人论文速览 第五十一期】Tue, 10 Oct 2023
AI视野今日CS.Robotics 机器人学论文速览 Tue, 10 Oct 2023 Totally 54 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers On Multi-Fidelity Impedance Tuning for Human-Robot Cooperative Manipulation Authors Ethan Lau, Vaibhav Srivastava, Sh…...

零经验想跳槽转行网络安全,需要准备什么?
最近在后台看到很多私信都是有关转行网络安全的问题,目前咨询最多的都是:觉得现在的工作没有发展空间,替代性强,工资低,想跳槽转行网络安全。其中,他们主要关心的是:没有经验怎么学习࿱…...

Rust-是否使用Rc<T>
Rust的所有权机制,数据允许通过借用的方式,在函数的上下文中传递数据。如果离开数据作用的有效范围,这个借用就会失效,编译就会报错。这也是我们不会将借用(引用)作为函数的返回值的原因。下面的代码编译失败。 fn cr…...

论文解析——一种面向Chiplet互连的高效传输协议设计与实现
作者及发刊详情 熊国杰, 张津铭, 贺光辉. 一种面向Chiplet互连的高效传输协议设计与实现[J]. 计算机工程与科学, 2023, 45(08): 1339-1346.XIONG Guo-jie, ZHANG Jin-ming, HE Guang-hui. Design and implementation of an efficient transmission protocol for Chiplet inter…...

svo2.0 svo pro 编译运行
sudo apt-get install python-catkin-tools python-vcstool unable to locate python-vcstool 添加ros源 然后sudo apt update 依赖库下载,查看dependencies.yaml文件: 逐个clone到src目录下即可 dbow2_catkin 编译出错: 把https://gi…...
微信小程序前端生成动态海报图
//页面显示<canvas id"myCanvas" type"2d" style" width: 700rpx; height: 600rpx;" />onShareShow(e){var that this;let user_id wx.getStorageSync(user_id);let sharePicUrl wx.getStorageSync(sharePicUrl);if(app.isBlank(user_i…...

别再死记硬背了!用“餐厅经营”的比喻,5分钟搞懂批处理、分时和实时操作系统的区别
用餐厅经营智慧解锁操作系统核心概念 想象一下走进一家餐厅,菜单上的选择琳琅满目,服务员穿梭忙碌,厨房里热火朝天——这个看似普通的就餐场景,其实暗藏着计算机操作系统的精妙设计。就像餐厅需要高效协调顾客、服务员和厨师的关系…...

终极指南:1000+编程语言Hello World全解析与学习秘籍 [特殊字符]
终极指南:1000编程语言Hello World全解析与学习秘籍 🚀 【免费下载链接】hello-world Hello world in every computer language. Thanks to everyone who contributes to this, make sure to see contributing.md for contribution instructions! 项目…...
)
从服务端到登录器:《传奇世界》单机架设全流程拆解与工具选择指南(AFT/彩虹/凤凰引擎对比)
从服务端到登录器:《传奇世界》单机架设全流程拆解与工具选择指南 在经典网游《传奇世界》的爱好者圈子里,单机架设一直是技术玩家热衷探索的领域。不同于简单的游戏体验,搭建一个完整的单机环境意味着对游戏架构的深度理解和技术掌控。本文将…...

边缘计算能效革命:从架构革新到产业落地的破局之路
1. 边缘计算的核心矛盾:智能需求与能源瓶颈的碰撞在过去的几年里,我亲眼见证了计算范式的一次深刻迁徙:从集中式的云端,正不可逆转地向着物理世界的每一个角落——也就是我们常说的“边缘”——扩散。驱动这股浪潮的,是…...

RISC-V在AI与边缘计算领域的崛起:从开放架构到异构计算新范式
1. RISC-V在AI与边缘计算领域的崛起:一场意料之中的“超预期” 如果你最近关注处理器架构的新闻,大概率会被“RISC-V在AI领域超预期增长”这类标题刷屏。这不仅仅是媒体的噱头,而是正在硅谷和全球半导体设计实验室里发生的真实故事。作为一名…...

Cursor AI代码助手:重塑IDE开发体验,从智能补全到项目级协作
1. 项目概述:当AI代码助手遇上IDE,Cursor如何重塑开发体验 如果你是一名开发者,最近一定在圈子里频繁听到“Cursor”这个名字。它不是一个全新的编程语言,也不是一个颠覆性的框架,但它却实实在在地在改变着许多人的编码…...

自签名证书
证书生成私钥openssl genrsa -out localhost.key 2048生成自签名证书openssl req -new -x509 -key localhost.key -out localhost.crt -days 365 \-subj "/CNlocalhost" \-addext "subjectAltNameDNS:localhost,IP:127.0.0.1,IP:::1"...

深入GD32F407时钟树:对比STM32F4,聊聊国产MCU时钟设计的异同与调试技巧
深入解析GD32F407时钟树:从STM32F4迁移的实战指南 当工程师第一次将STM32F4项目移植到GD32F407平台时,最常遇到的"幽灵问题"往往与时钟配置有关。我曾亲眼见证一个团队花费两周时间追踪CAN总线通信异常,最终发现仅仅是APB1时钟分频…...

量子支持向量机原理与硬件优化实践
1. 量子支持向量机基础原理与硬件挑战量子支持向量机(QSVM)是传统支持向量机在量子计算框架下的扩展,其核心创新点在于利用量子态空间的高维特性构建核函数。与传统核方法相比,量子核映射通过量子电路将经典数据编码到希尔伯特空间…...

OctoSuite代码审查:深入理解GitHub数据模型设计的5个关键要点
OctoSuite代码审查:深入理解GitHub数据模型设计的5个关键要点 【免费下载链接】octosuite Terminal-based toolkit for GitHub data analysis. 项目地址: https://gitcode.com/gh_mirrors/oc/octosuite OctoSuite是一个强大的终端GitHub数据分析工具包&#…...