【推荐算法】ctr cvr联合建模问题合集
ctr和cvr分开建模相比ctcvr的优势?
在电商搜索推荐排序中,将ctr和cvr分开建模,相比直接建模ctcvr的优势是什么? - 萧瑟的回答 - 知乎
总结:
1、ctr的数据可以试试获取,能实时训练。但是cvr存在延迟现象,样本更新慢。一起训练容易出现跷跷板现象。
2、分开建模可以输出2个指标,便于调控。
3、CTR肯定是需要单独建模的,因为它影响用户的长期的参与度,也影响未来收益。
CTCVR低,不代表用户不喜欢,也可能是因为其他原因(比如没钱,这个很容易建模,拿用户过去消费的金额,与当前商品的价格,一比就能知道)
观点1
在电商搜索推荐排序中,将ctr和cvr分开建模,相比直接建模ctcvr的优势是什么? - 萧瑟的回答 - 知乎
分开建模的话。可能有下面几个好处:
- 方便机制等进行更灵活的调控。电商排序公式,往往不会就是简单的 ctr∗cvr∗pricectr*cvr*price ,很多时候可能是类似这样的一些更复杂的排序公式 ctra+ctrb∗cvrc+ctrd∗cvre∗pricefctr^a+ctr^b*cvr^c+ctr^d*cvr^e*price^f ,这个时候就需要有单独的ctr和cvr分数以便进行调控。另外像很多广告业务,基于点击计费,那么也需要单独的ctr分数。cvr分数可能会用到的广告出价bid的调整上。
- 分开使迭代更方便。样本上,cvr的转化信号往往存在一定的延迟,长的可能好几天。而ctr的点击信号,长的一般也就几十分钟,如果ctr和cvr一起建模的话,对于实时训练系统来说,样本上可能会面临比较大的挑战。另外ctr和cvr一起训练,效果可能相互影响,出现跷跷板效应,新的算法迭代ctr和cvr离线在线指标出现一个涨一个跌的问题,会让人非常头疼。
当然ctr和cvr放一起训练建模,也有一些优势,特别是如果算法组人力紧张的话,联合建模相比分开迭代,可以节省很多人力维护成本。
像淘宝一些核心业务的算法组,ctr和cvr模型也经历过多次分分合合。ctr和cvr模型是否要放一起训练迭代,并没有标准答案,和当前组内人力情况、业务情况,技术迭代情况等都息息相关。
观点2
ctr和cvr分开建模,相比一起建模的好处。https://zhuanlan.zhihu.com/p/599920653
CTR肯定是需要单独建模的,因为它影响用户的长期的参与度,也影响未来收益。
CTCVR低,不代表用户不喜欢,也可能是因为其他原因(比如没钱,这个很容易建模,拿用户过去消费的金额,与当前商品的价格,一比就能知道)
这个时候,如果只按CTCVR排序,只给用户显示那些物美价廉的东西,
一来用户审美疲劳,
二来也失去了给用户种草的机会。万一哪天用户中彩票了,或者一狠心想剁手了,在你们的app上却不展示合适的商品,岂不是白白浪费了机会。
其次,CTCVR你也预估不准。
其实哪个XTR都不可能绝对预估准,因此需要修正。
有了CTR,CVR,我修正CTCVR起来,还能多有一些信息可咨利用
另外,ctr和cvr一起训练,出现跷跷板现象,经常出现一个涨一个跌的情况,比较麻烦。
观点3
ctr和cvr联合建模的好处 https://www.zhihu.com/question/546623702/answer/2621988648
有些单个任务数据不充分造成模型不能训练收敛到较好的性能。多个相关任务在一起训练,配置合适的网络结构,可以实现多个任务的样本共用,每个任务得样本都变多了,能够帮助模型训练收敛。
举个例子,比如CTR(点击率预估)和CVR(转化率)联合建模。对于CTR任务来说,CVR的转化样本是高质量的点击人群,加入CVR转化样本能够帮助CTR任务更加倾向高质量点击。反之对于CVR任务,一般样本比较稀疏,通过加入CTR的浅层转化样本,也能够帮助先粗分辨更可能转化的人群。
当然多任务模型需要配置好网络参数和门控,增强多个任务间的互相增益,降低多个任务负向干扰。
观点4
工作时建模ctr*cvr时,关于esmm的几个疑问?
1.esmm 的ctr 网络输出还是ctr么(是否有偏)
2.esmm 针对ctr、cvr 分布差异大(任务不太相关,比如ctr多数来自新用户,cvr多数转化来自老用户)是否会带来cvr侧的不稳定
3.为什么esmm cvr 侧塔会高估?
观点5
MMOE解决跷跷板现象 https://zhuanlan.zhihu.com/p/462953458
mmoe借鉴了ensamble的解决思路,训练一批模型,每个task用其中不同的一些模型。这样也就缓解了样本分布差别大导致的跷跷板问题。实践经验表明expert的个数越多效果会越好,但边际效应递减,而且过多可能模型难以收敛。根据数据量,一般都会学习4-6个expert。
观点6(好)
cvr是否ctr的简单复制 - 彭红卿的文章 - 知乎
分别预估然后相乘算pctcvr是最佳做法么
初次碰到计算pctcvr是用pctr和pcvr相乘得出的,有人可能习以为常,有人可能就会有疑惑,为啥非得这么做,为啥不直接预估pctcvr,有哪些好处和坏处?
这么做的理由可以列好些出来,比如,分开预估就是两个模型,就可以有两拨人有事情做(大雾)。技术上呢?有一种说法是,ctcvr的正例太稀疏了,拆开来更好学习。业务上的理由有,比如app的转化有延迟,因此app ctr和app cvr数据处理流程不一样,模型的更新周期不一样,拆开更合理。还有一种说法是,ctr和cvr的特征不一样,所以拆开合情合理。
端到端预估也有不少好处,比如app ctr在某些媒体上可能有很多行为码不好界定是否属于点击,比如自动播放的那些。端到端就直接跨过这个问题,毕竟转化的定义是清晰的。
另外,在召回和粗排阶段,是否直接预估pctcvr又更合理呢?
ctr有的特征是否cvr就该有
比如ctr使用了用户行为特征,cvr模型是否就一定也要用上,cvr特征永远是ctr特征的超集?
ctr是否能使用转化相关的特征,cvr能否使用点击相关特征
比如ctr能否使用用户转化行为相关特征,为什么会有效?而cvr使用点击相关特征又会有正面效果么?
ctr和cvr预估值怎样相互影响
ctr和cvr的低估和高估会怎样影响到对方?ctr数据的收集基本在站内就能完成,因此ctr相对来说会更容易做的更准确,当然点击label定义不清又是另外一种情形。而转化受广告主回传等因素的影响,真值的波动会比ctr大,从而容易导致预估偏差。因此ctr是pctcvr预估的稳定剂,预估偏差不能太大。
采样偏差在预估和统计上的影响
sampling selection bias的问题在esmm论文里头已经说的比较清楚了,训练的样本空间(其实是特征空间)应该跟推断的样本空间一致。不一致会发生什么情况呢?就拿cvr预估来说,如果还是用点击作为负样本,转化作为正样本来训练模型,相比esmm来说,正样本是没丢的,也就是正样本的特征空间也不会有损失。点击未转化的样本(通常意义的cvr负样本)也一个没少,那么损失的都是什么呢,是那些曝光没点击的,大概率是cvr的负样本。这些负样本会对特征空间有所扩充,而且会让负样本本身预估更准确。举个例子,有点击的用户可能集中在20-60岁之间,假设其他岁数就变成一个缺省值“-”,如果是按照非esmm的cvr训练模式训练出来一个模型,在线上会有大量的样本命中“-”,这个时候这些样本的预估值就会比较接近,没有区分度。对于ocpx系统来说,这是比较要命的,我们希望所有样本之间都有能区分它们的特征,从而能预估一个更细致的值,更好地控制成本,哪怕是这些预估值很低,意味着几乎不可能发生转化。个人理解可以看做是easy negative(相对positive而言)里头的hard(negative之间)情形,因为你需要把“-”再分开。这块跟召回用全量空间的样本有相似之处,都是一不小心就会导致训练的样本空间小于推断的样本空间,区别在于召回的全量空间包括没有曝光的样本,而esmm的全量空间包括没有点击的样本。esmm认为能曝光出来已经是能产生转化的最低要求了,未曝光样本(同样会出现新特征值)在esmm看来属于冷启动问题,需要靠实时模型和泛化特征等手段来解决。
采样偏差在一个不太为人注意的任务上也存在,那就是统计。比如计算pcvr和tcvr之间的预估偏差,这个时候,是统计发生了点击后的预估值和点击后的真实值之间的gap,还是统计所有曝光的预估值的均值再和真实值相比?
在线学习
ctr模型用在线方式的处理,问题不太大,毕竟点击行为从端上上报不会比曝光延迟太久,漏掉正样本的情况比较少。但cvr的转化就不一样了,延迟的转化在app安装和激活上尤其明显,电商推荐的收藏到付费也可能时间很长。label延迟的情况下到底是否适合在线学习,这个事情业界好像是先整在线再说,快速数据流转成为一种理念。于是梯度补偿等方法也被提出来,没太多理论保证,但这也是为“快”所付出的代价。按预估转化时间分桶打散听起来更合理一些,也能跟在线处理结合,只是更复杂一些。
相关文章:

【推荐算法】ctr cvr联合建模问题合集
ctr和cvr分开建模相比ctcvr的优势? 在电商搜索推荐排序中,将ctr和cvr分开建模,相比直接建模ctcvr的优势是什么? - 萧瑟的回答 - 知乎 总结: 1、ctr的数据可以试试获取,能实时训练。但是cvr存在延迟现象&…...

安装njnx --chatGPT
gpt: 要在 Debian 11 上安装 Nginx(通常称为 "nginx"),您可以使用 apt 包管理器执行以下步骤: 1. **登录到您的 Debian 11 服务器**。您可以使用 SSH 客户端以 root 或具有管理员权限的用户身份登录。 2. **更新软件…...
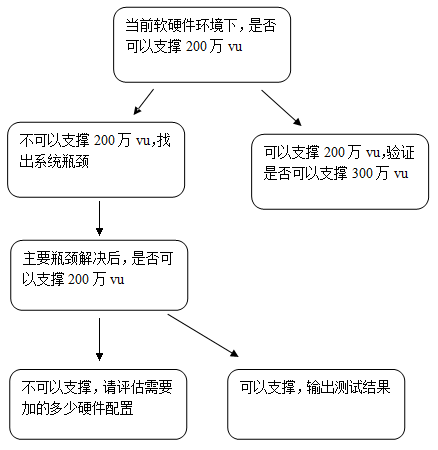
性能测试需求分析
1、客户方提出 客户方能提出明确的性能需求,说明对方很重视性能测试,这样的企业一般是金融、电信、银行、医疗器械等;他们一般对系统的性能要求非常高,对性能也非常了解。提出需求也比较明确。 曾经有一个银行项目,已经…...
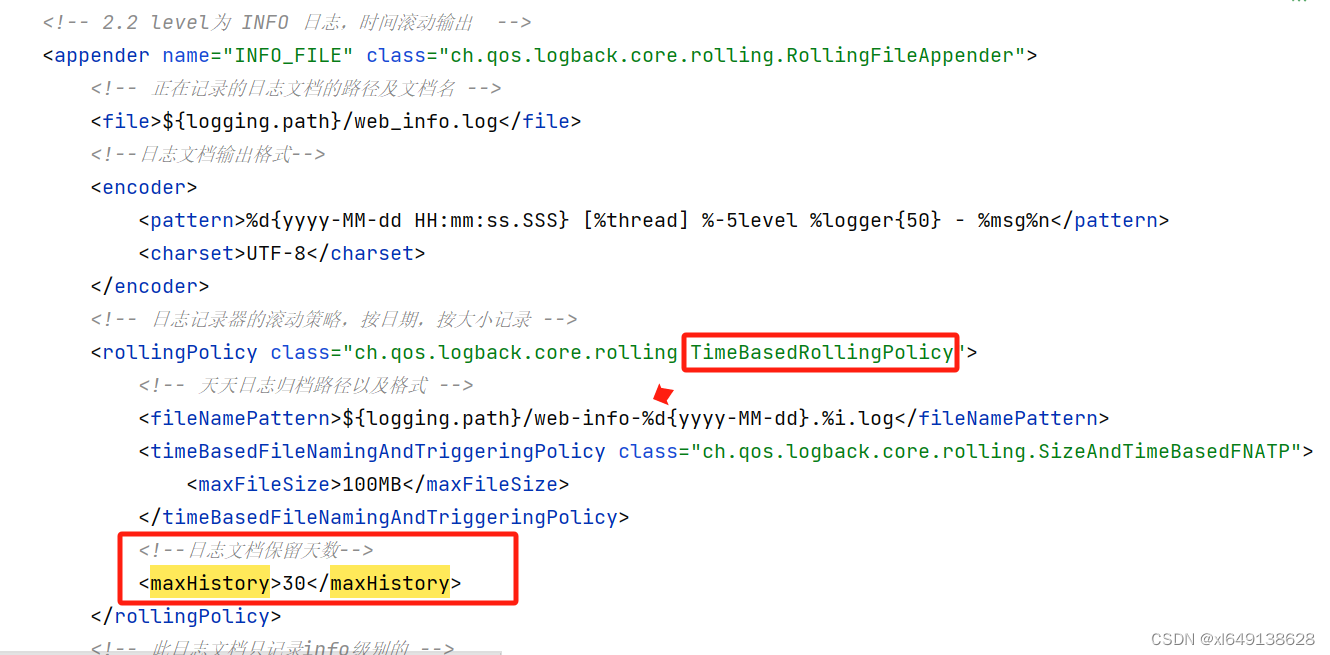
logback服务器日志删除原理分析
查看以下的logback官方文档 Chapter 4: Appendershttps://logback.qos.ch/manual/appenders.html 按文档说明,maxHistory是设置保存归档日志的最大数量,该数量的单位受到fileNamePattern里的值%d控制,如果有多个%d,只能有一个主%d࿰…...

到底什么才是真正的商业智能(BI)
随着人工智能、云计算、大数据、互联网、物联网等新一代信息化、数字化技术在各行各业内开始大规模的应用,社会上的数字化、信息化程度不断加深,而数据价值也在这样的刺激下成为了个人、机构、企业乃至国家的重要战略资源,成为了继土地、劳动…...

Pulsar Manager配置自定义认证插件访问
Pulsar Manager配置自定义认证插件访问 Pulsar Manager和dashboard部署和启用认证 pulsar自定义认证插件开发 前面博客讲了以token方式访问pulsar 这节博客讲如何配置自定义认证插件的方式访问pulsar #启动pulsar-manager docker run --name pulsar-manager -dit \-p 9527:…...

Java SimpleDateFormat linux时间字符串转时间轴的坑
Mon Oct 16 09:51:28 2023 这是linux 的 date命令得到的时间,要转换称时间戳。 EEE MMM dd HH:mm:ss yyyy 这样的格式,看起来就是正确的,可是就是报错 Unparseable date: "Mon Oct 16 09:51:28 2023" 下面是正确的代码 String[…...
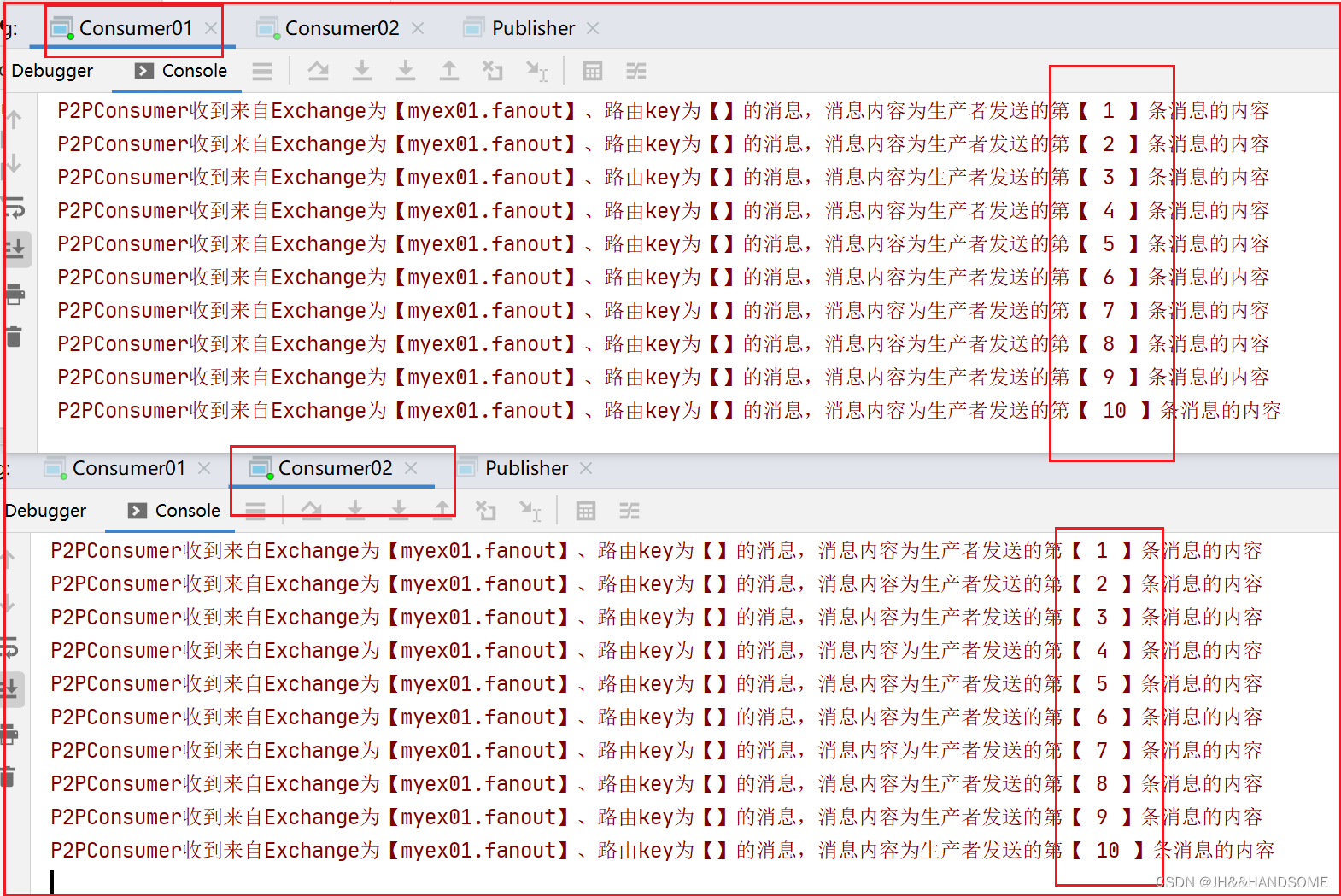
202、RabbitMQ 之 使用 fanout 类型的Exchange 实现 Pub-Sub 消息模型---fanout类型就是广播类型
目录 ★ 使用 fanout 类型的Exchange 实现 Pub-Sub 消息模型代码演示:生产者:producer消费者:Consumer01消费者:Consumer02测试结果 完整代码ConnectionUtilPublisherConsumer01Consumer02pom.xml ★ 使用 fanout 类型的Exchange …...
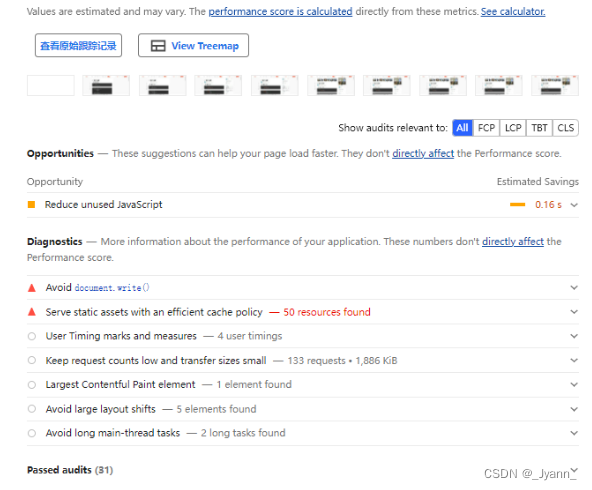
web 性能优化详解(Lighthouse工具、优化方式、强缓存和协商缓存、代码优化、算法优化)
1.性能优化包含的方面 优化性能概念宽泛,可以从信号、系统、计算机原理、操作系统、网络通信、DNS解析、负载均衡、页面渲染。只要结合一个实际例子讲述清楚即可。 2.什么是性能? Web 性能是客观的衡量标准,是用户对加载时间和运行时的直观…...
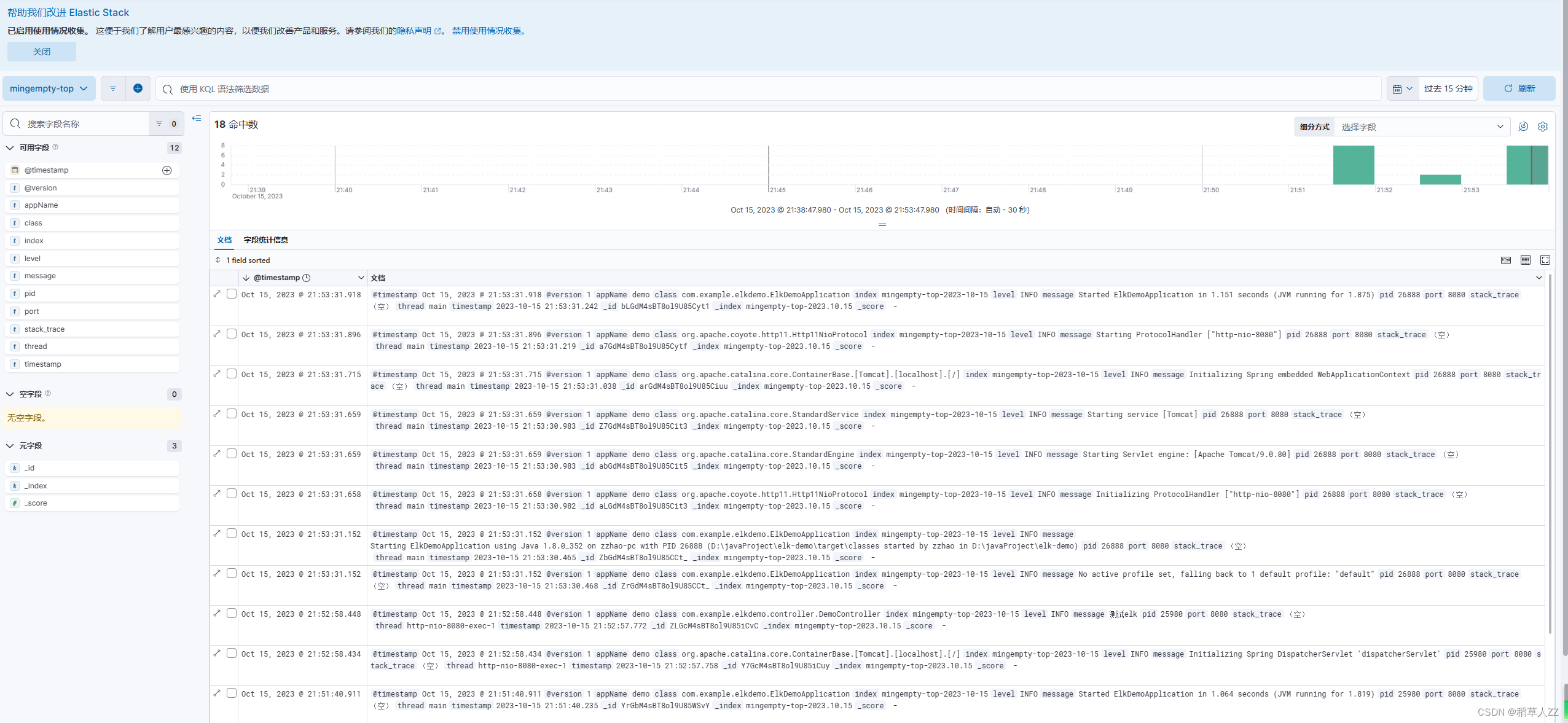
docker-compose部署elk(8.9.0)并开启ssl认证
docker部署elk并开启ssl认证 docker-compose部署elk部署所需yml文件 —— docker-compose-elk.yml部署配置elasticsearch和kibana并开启ssl配置基础数据认证配置elasticsearch和kibana开启https访问 配置logstash创建springboot项目进行测试kibana创建视图,查询日志…...
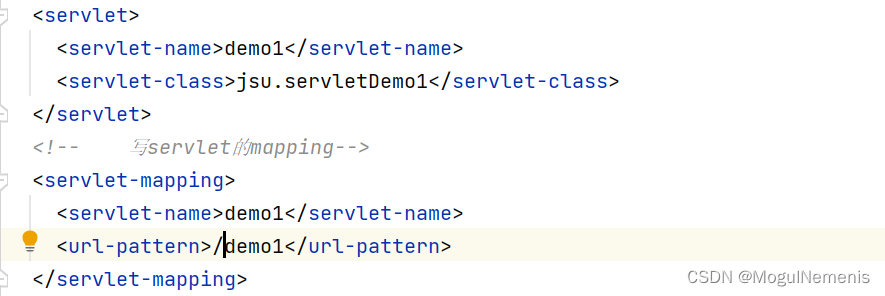
解决java.lang.IllegalArgumentException: servlet映射中的<url pattern>[demo1]无效
当我使用tomcat启动使用servlet项目时,出现了报错: java.lang.IllegalArgumentException: servlet映射中的<url pattern>[demo1]无效 显示路径错误,于是去检查Web.xml中的配置,发现是配置文件的路径写错了,少写了…...

软件测试学习(三)易用性测试、测试文档、软件安全性测试、网站测试
目录 易用性测试 用户界面测试 优秀Ul由什么构成 符合标准和规范 直观 一致 灵活 舒适 正确 实用 为有残疾障碍的人员测试:辅助选项测试 测试文档 软件文档的类型 文档测试的重要性 软件安全性测试 了解黑客的动机 威胁模式分析 网站测试 网页基…...
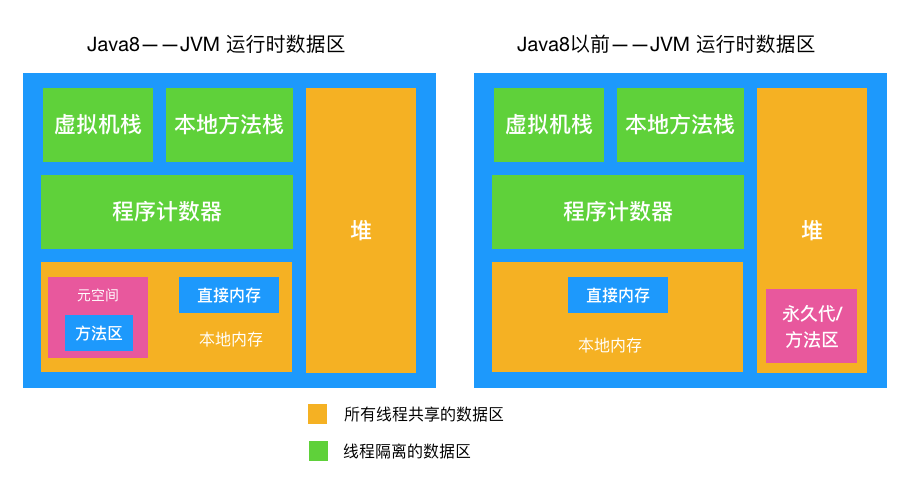
Java中,对象一定在堆中分配吗?
在我们的日常编程实践中,我们经常会遇到各种类型的对象,比如字符串、列表、自定义类等等。这些对象在内存中是如何存储的呢? 你可能会毫不犹豫地回答:“在堆中!”如果你这样回答了,那你大部分情况下是正确…...

AI:38-基于深度学习的抽烟行为检测
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌本专栏包含以下学习方向: 机器学习、深度学…...
Hadoop 配置 Kerberos 认证
1、安装 Kerberos 服务器和客户端 1.1 规划 服务端: bigdata3 客户端(Hadoop集群): bigdata0 bigdata1 bigdata2 192.168.50.7 bigdata0.example.com bigdata0 192.168.50.8 bigdata1.example.com bigdata1 192.168.50.9 b…...
在 Elasticsearch 中实现自动完成功能 2:n-gram
在第一部分中,我们讨论了使用前缀查询,这是一种自动完成的查询时间方法。 在这篇文章中,我们将讨论 n-gram - 一种索引时间方法,它在基本标记化后生成额外的分词,以便我们稍后在查询时能够获得更快的前缀匹配。 但在此…...

美客多、亚马逊卖家如何运用自养账号进行有效测评?
到了10月,卖家朋友们都在忙着准备Q4旺季吧! 首先,祝愿所有看到这条推文的卖家朋友,今年旺季都能爆单,赚得盆满钵满! 测评是珑哥常谈,一直备受关注,不论是新老卖家都是一个逃不开的…...
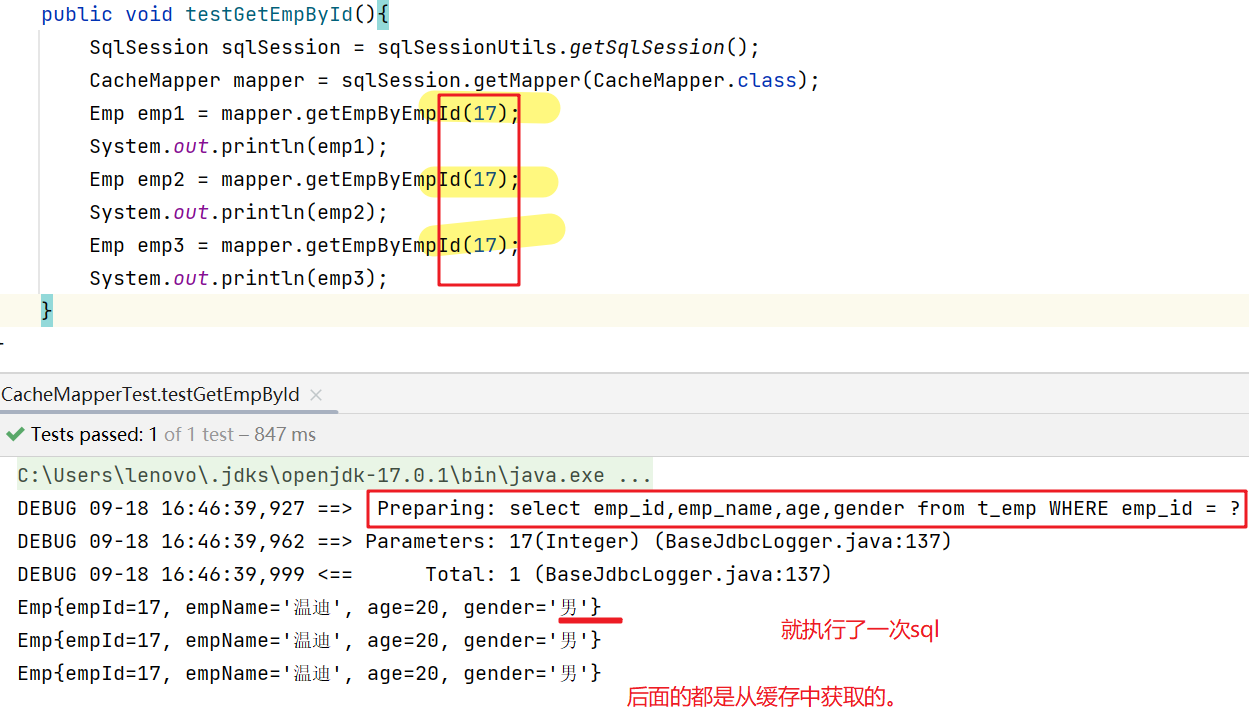
MyBatis的缓存,一级缓存,二级缓存
10、MyBatis的缓存 10.1、MyBatis的一级缓存 一级缓存是SqlSession级别的,通过同一个SqlSession对象 查询的结果数据会被缓存,下次执行相同的查询语句,就 会从缓存中(缓存在内存里)直接获取,不会重新访问…...
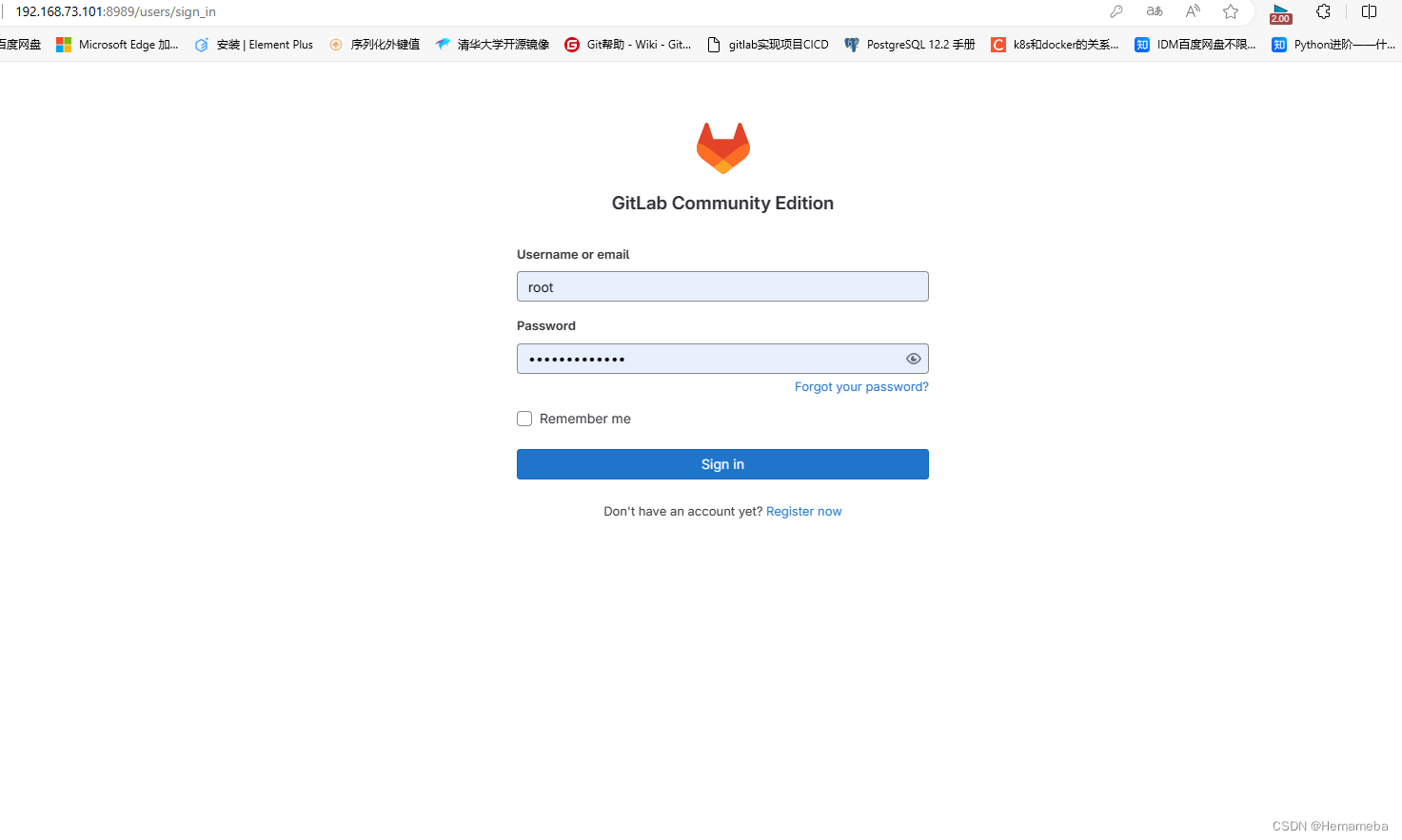
GitLab(1)——GitLab安装
目录 一、使用设备 二、使用rpm包安装 Gitlab国内清华源下载地址: ①下载命令如下: ②安装命令如下: ③删除rpm包 ④配置 ⑤重载 ⑥重启 ⑦配置自启动 ⑧打开8989端口并重启防火墙 三、GitLab登录 ①访问GitLab的URL ②输入用户…...

退税政策线上VR互动科普展厅为税收工作带来了强大活力
缴税纳税是每个公民应尽的义务和责任,由于很多人缺乏专业的缴税纳税操作专业知识和经验,因此为了提高大家的缴税纳税办事效率和好感度,越来越多地区税务局开始引进VR虚拟现实、web3d开发和多媒体等技术手段,基于线上为广大公民提供…...
)
告别手动建模!用ArcGIS+SWMM+慧天平台,5步搞定城市内涝模拟(附实战数据)
城市内涝模拟实战:ArcGISSWMM慧天平台高效协同工作流 暴雨过后街道成河、地下车库变泳池的场景,已成为许多城市规划者和工程师的噩梦。传统的内涝模拟方法需要手动处理海量管网数据,不仅耗时费力,还容易在数据转换过程中丢失关键信…...

基于本地大模型与Playwright的隐私优先求职自动化助手RedClaw实践
1. 项目概述:一个真正为你掌控的本地化求职AI助手在求职季,我们常常面临一个两难困境:一方面,海投简历耗时耗力,重复填写那些大同小异的在线申请表让人筋疲力尽;另一方面,市面上一些所谓的“自动…...

FPGA硬件在环验证:GateRocket方案加速系统级调试
1. 项目概述:为什么FPGA验证需要“硬件在环”?在FPGA设计领域,尤其是当项目规模膨胀到数百万甚至上千万门级时,纯软件仿真(Simulation)会变成一个令人头疼的瓶颈。想象一下,你写了一段新的RTL代…...

OBS Source Record插件深度解析:5个实战技巧实现多源独立录制
OBS Source Record插件深度解析:5个实战技巧实现多源独立录制 【免费下载链接】obs-source-record 项目地址: https://gitcode.com/gh_mirrors/ob/obs-source-record 你是否曾经在直播或视频制作中,想要单独录制某个摄像头画面、游戏窗口或浏览器…...

从丝杆到直线电机:半导体运动台驱动技术演进与选型指南
1. 半导体运动台驱动技术的核心挑战 在半导体制造领域,运动平台就像精密仪器的心脏,每一次跳动都关乎生产效率和产品质量。想象一下,光刻机要在指甲盖大小的芯片上绘制比头发丝还细的电路,这相当于让一台卡车在足球场上精准停到误…...

AI编程助手代码质量守护:Quality Guardian MCP实战指南
1. 项目概述:为AI编程助手打造的“质量守门员”如果你和我一样,日常重度依赖 Claude Code、Cursor 这类 AI 编程助手来写代码,那你肯定也遇到过这个头疼的问题:助手写的代码,语法上没问题,但一跑静态检查&a…...

Raycast扩展vscode-control:用全局启动器遥控VS Code提升开发效率
1. 项目概述:一个为Raycast打造的VS Code遥控器 如果你和我一样,每天大部分时间都泡在代码编辑器里,那么你一定对频繁在编辑器、终端、浏览器和启动器之间切换感到厌烦。尤其是当你需要快速执行一个格式化操作、运行一个NPM脚本,…...

Godot 4.x ECS插件GECS:数据驱动架构提升游戏性能与可维护性
1. 项目概述:GECS,为Godot 4.x注入ECS架构之力如果你正在用Godot开发游戏,尤其是那种实体数量多、交互逻辑复杂的项目,比如RTS、模拟经营或者一个满屏敌人的弹幕游戏,你很可能已经感受到了传统面向对象(OOP…...

【最新版】heic格式转换器下载教程 livp格式转jpg超详细图文转换教程
文章目录准备工作安卓手机拍摄的heic格式转jpg教程苹果heic格式转jpg专用工具livp格式转jpg教程heic格式文件无法打开的原因及解决方法heic转换jpg后文件变大是什么原因本文将详细教你实现heic格式转jpg与livp格式转jpg的操作方法,同时免费提供实用的heic格式转换器…...

WeChatMsg:微信聊天记录本地化解析与多格式导出技术方案
WeChatMsg:微信聊天记录本地化解析与多格式导出技术方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeC…...