外卖大数据案例
一、环境要求 Hadoop+Hive+Spark+HBase 开发环境。
二、数据描述
meituan_waimai_meishi.csv 是某外卖平台的部分外卖 SPU(Standard Product Unit , 标准产品单元)数据,包含了外卖平台某地区一时间的外卖信息。具体字段说明如下:
| 字段名称 | 中文名称 | 数据类型 |
| spu_id | 商品spuID | String |
| shop_id | 店铺ID | String |
| shop_name | 店铺名称 | String |
| category_name | 类别名称 | String |
| spu_name | SPU名称 | String |
| spu_price | SPU商品售价 | Double |
| spu_originprice | SPU商品原价 | Double |
| month_sales | 月销售量 | Int |
| praise_num | 点赞数 | Int |
| spu_unit | SPU单位 | String |
| spu_desc | SPU描述 | String |
| spu_image | 商品图片 | String |
三、功能要求
1.数据准备
在 HDFS 中创建目录/app/data/exam,并将 meituan_waimai_meishi.csv 文件传到该 目录。并通过 HDFS 命令查询出文档有多少行数据。
启动Hadoop
[root@kb135 ~]# start-all.sh
退出安全模式
[root@kb135 ~]# hdfs dfsadmin -safemode leave
上传文件
[root@kb135 examdata]# hdfs dfs -put ./meituan_waimai_meishi.csv /app/data/exam
查看数据行数
[root@kb135 examdata]# hdfs dfs -cat /app/data/exam/meituan_waimai_meishi.csv | wc -l
2.使用 Spark加载 HDFS 文件
加载meituan_waimai_meishi.csv 文件,并分别使用 RDD 和 Spark SQL 完成以下分析(不用考虑数据去重)。
Rdd:
启动spark
[root@kb135 ~]# spark-shell
创建Rdd
scala> val fileRdd = sc.textFile("/app/data/exam/meituan_waimai_meishi.csv")
清洗数据
scala> val spuRdd = fileRdd.filter(x=>x.startsWith("spu_id")==false).map(x=>x.split(",",-1)).filter(x=>x.size==12)
①统计每个店铺分别有多少商品(SPU)。
scala> spuRdd.map(x=>(x(2),1)).reduceByKey(_+_).collect.foreach(println)
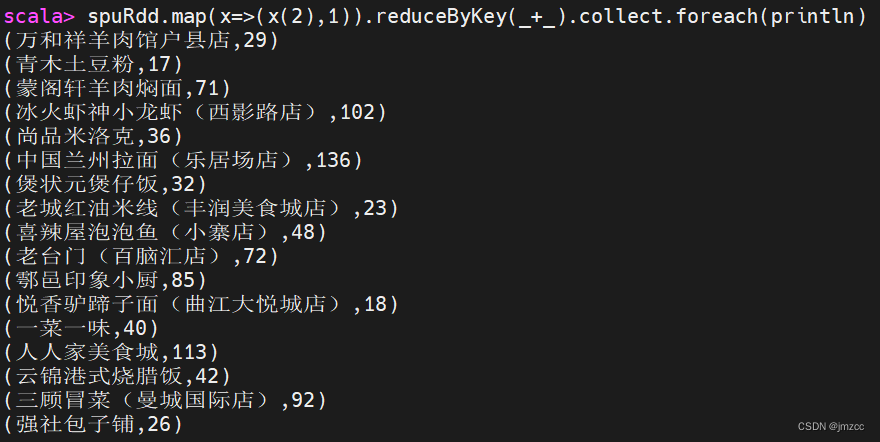
②统计每个店铺的总销售额。
scala> spuRdd.map(x=>(x(2),x(5).toDouble*x(7).toInt)).filter(x=>x._2>0).reduceByKey(_+_).collect.foreach(println)
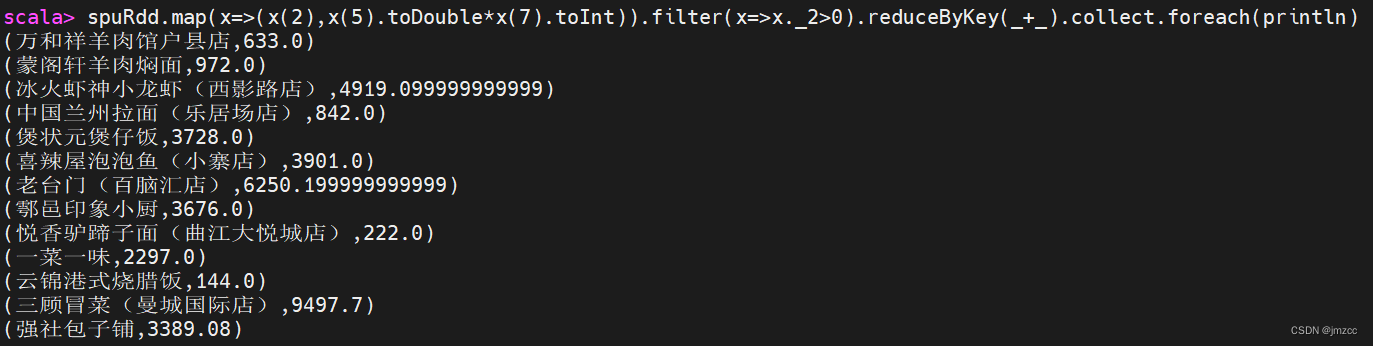
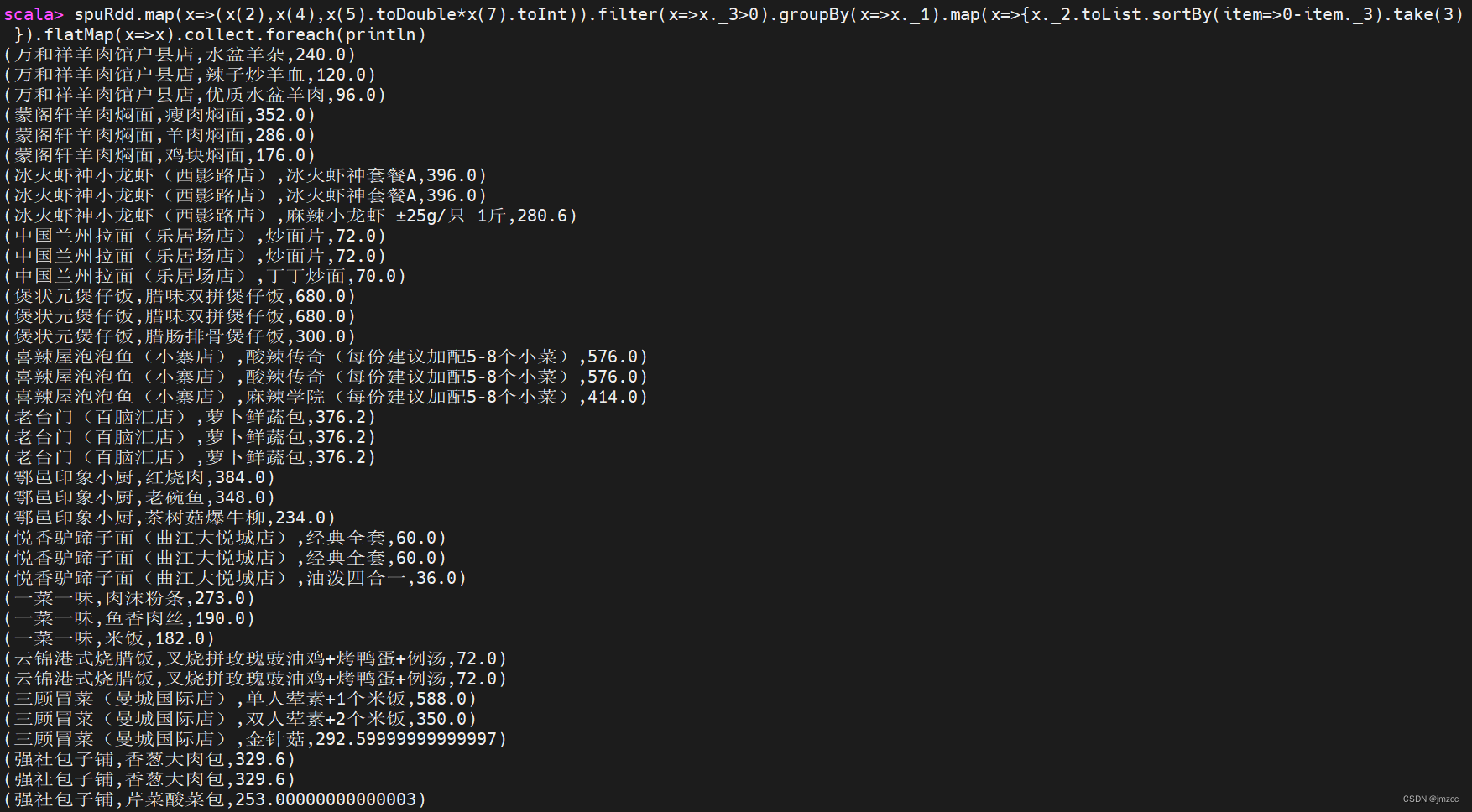
③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其 中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计。
scala> spuRdd.map(x=>(x(2),x(4),x(5).toDouble*x(7).toInt)).filter(x=>x._3>0).groupBy(x=>x._1).mapValues(x=>x.toList.sortBy(item=>0-item._3).take(3)).flatMapValues(x=>x).map(x=>x._2).collect.foreach(println)
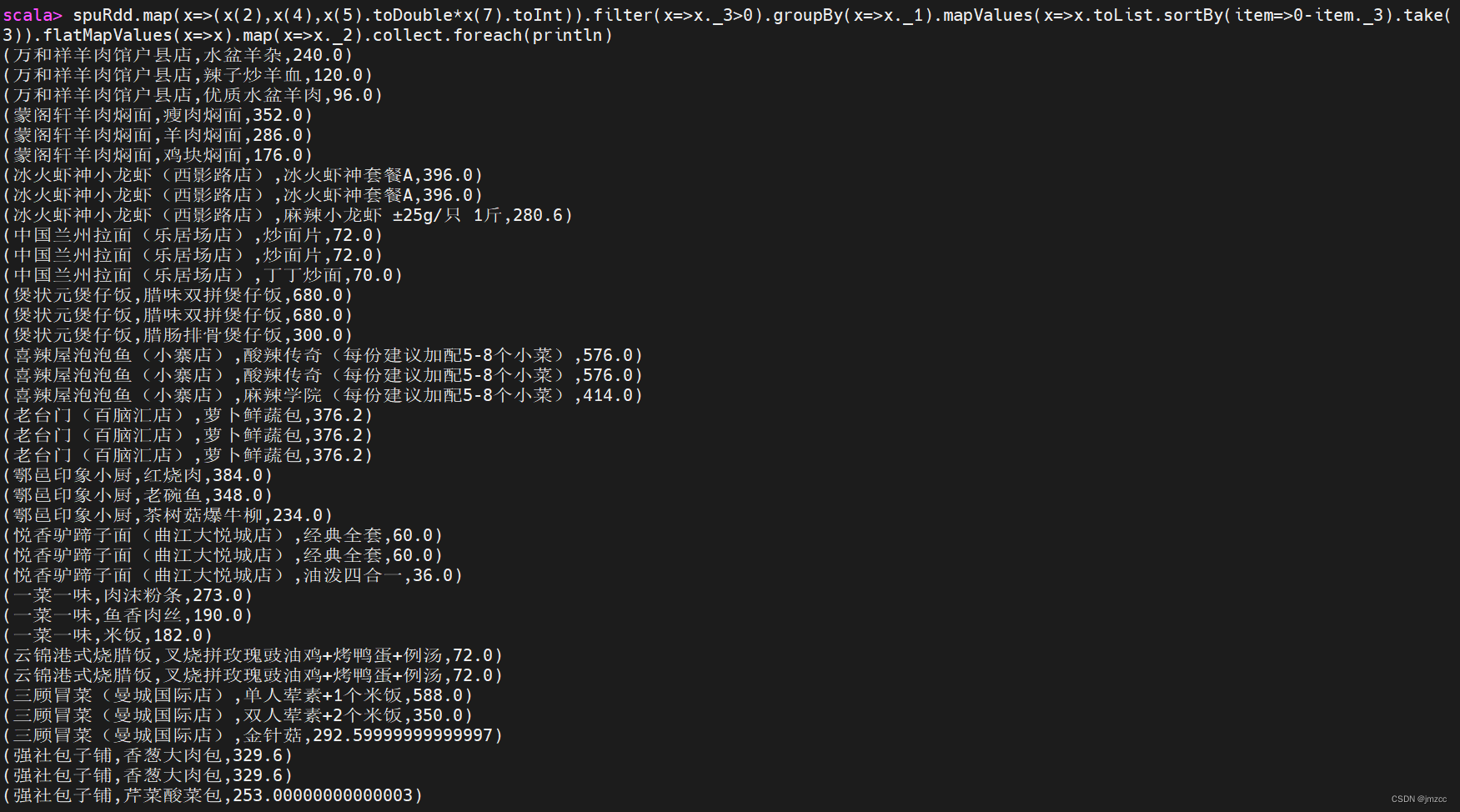
scala> spuRdd.map(x=>(x(2),x(4),x(5).toDouble*x(7).toInt)).filter(x=>x._3>0).groupBy(x=>x._1).flatMap(x=>{x._2.toList.sortBy(item=>0-item._3).take(3)}).collect.foreach(println)
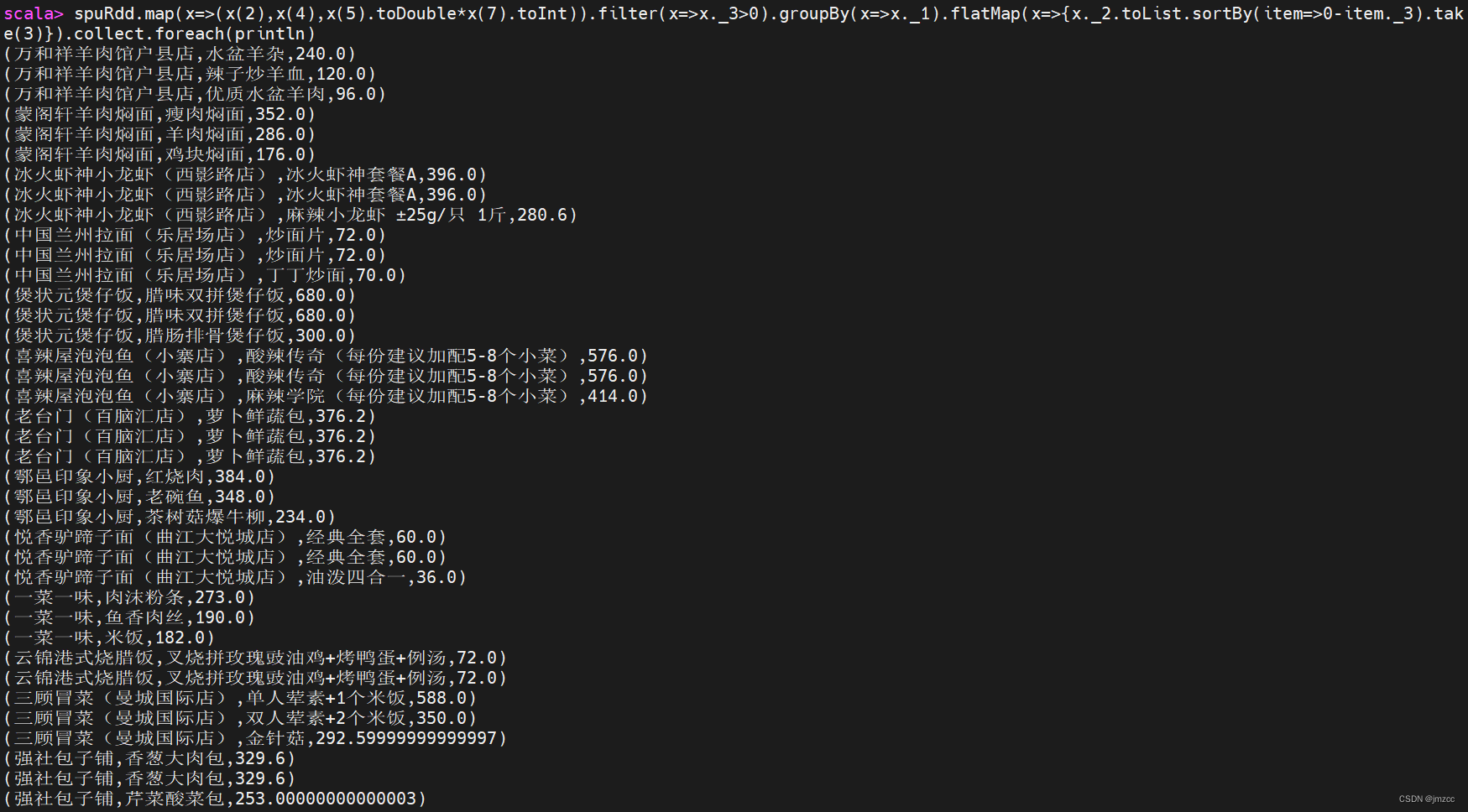
scala> spuRdd.map(x=>(x(2),x(4),x(5).toDouble*x(7).toInt)).filter(x=>x._3>0).groupBy(x=>x._1).map(x=>{x._2.toList.sortBy(item=>0-item._3).take(3) }).flatMap(x=>x).collect.foreach(println)
---------------------------------------------------------------------------------------------------------------------------------
spark sql:
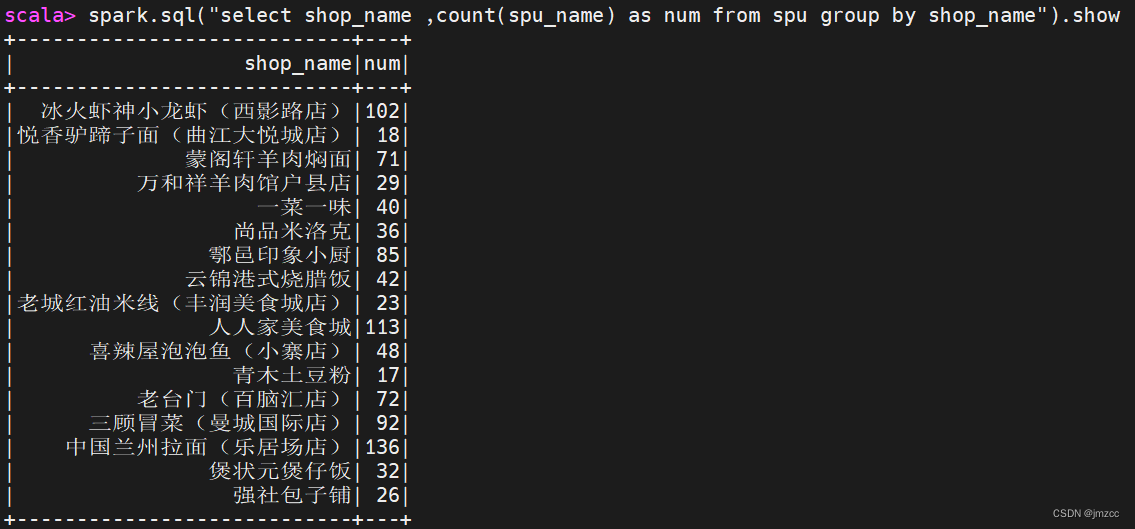
①统计每个店铺分别有多少商品(SPU)。
scala> spark.sql("select shop_name ,count(spu_name) as num from spu group by shop_name").show
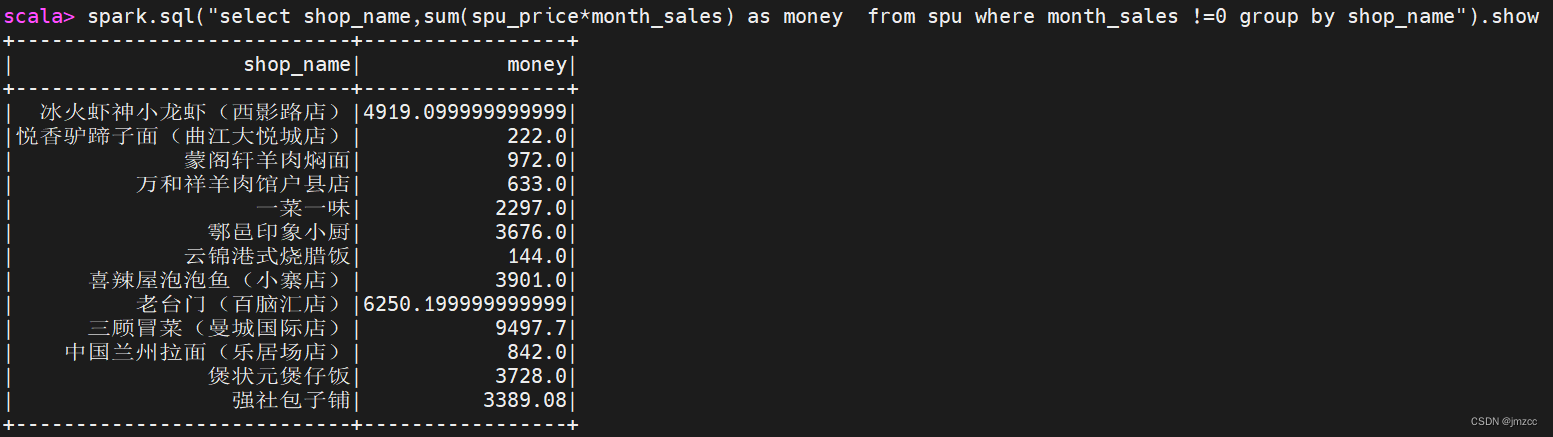
②统计每个店铺的总销售额。
scala> spark.sql("select shop_name,sum(spu_price*month_sales) as money from spu where month_sales !=0 group by shop_name").show
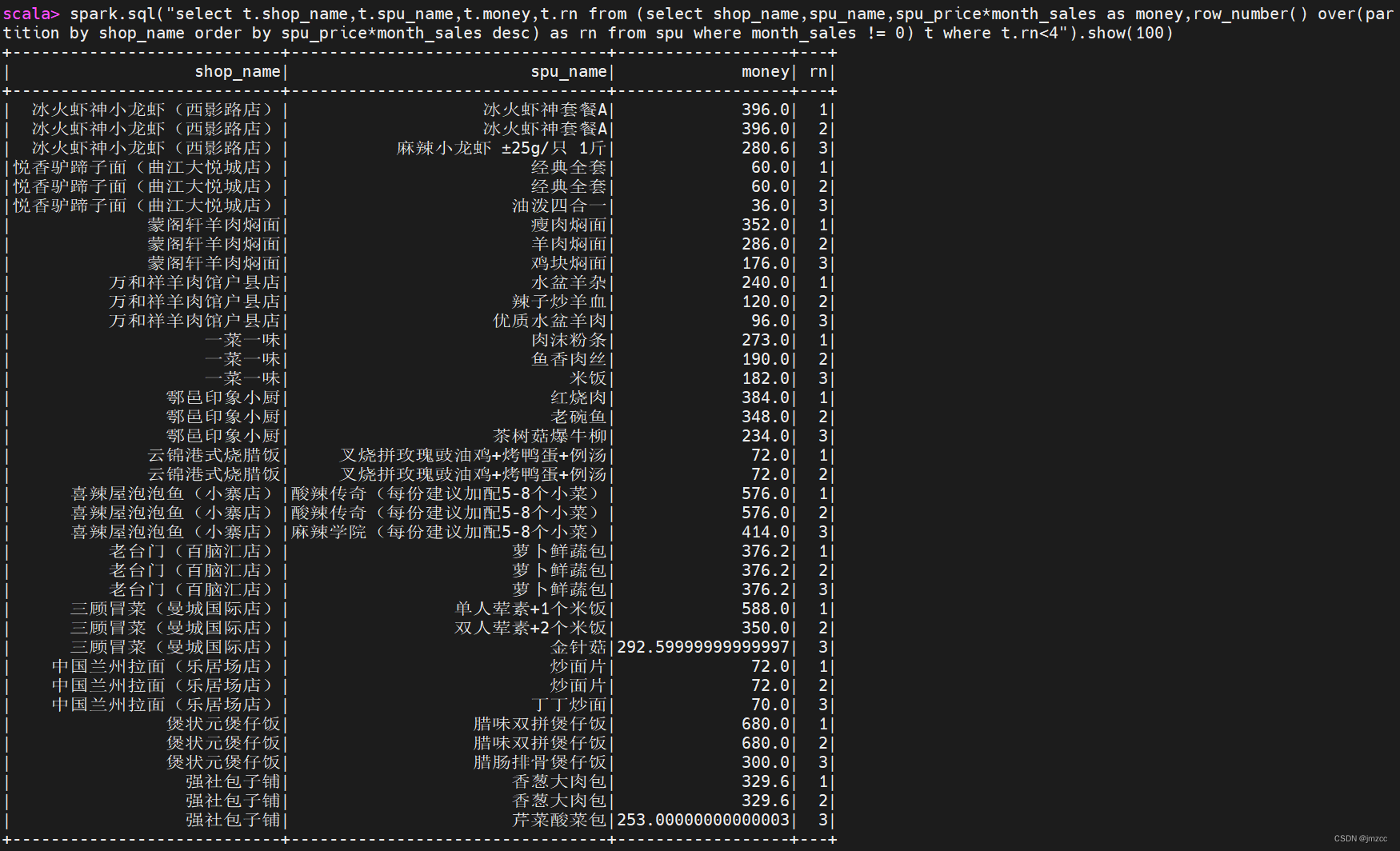
③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计。
scala> spark.sql("select t.shop_name,t.spu_name,t.money,t.rn from (select shop_name,spu_name,spu_price*month_sales as money,row_number() over(partition by shop_name order by spu_price*month_sales desc) as rn from spu where month_sales != 0) t where t.rn<4").show(100)
3.创建 HBase 数据表
在 HBase 中创建命名空间(namespace)exam,在该命名空间下创建 spu 表,该表下有
1 个列族 result。
启动zookeeper
[root@kb135 ~]# zkServer.sh start
启动hbase
[root@kb135 examdata]# start-hbase.sh
[root@kb135 examdata]# hbase shell
创建表空间
hbase(main):002:0> create_namespace 'exam202009'
创建表
hbase(main):003:0> create 'exam202009:spu','result'
4.在 Hive 中创建数据库 spu_db
在该数据库中创建外部表 ex_spu 指向 /app/data/exam 下的测试数据 ;创建外部表 ex_spu_hbase 映射至 HBase 中的 exam:spu 表的 result 列族
ex_spu 表结构如下:
| 字段名称 | 中文名称 | 数据类型 |
| spu_id | 商品spuID | string |
| shop_id | 店铺ID | string |
| shop_name | 店铺名称 | string |
| category_name | 类别名称 | string |
| spu_name | SPU名称 | string |
| spu_price | SPU商品价格 | double |
| spu_originprice | SPU商品原价 | double |
| month_sales | 月销售量 | int |
| praise_num | 点赞数 | int |
| spu_unit | SPU单位 | string |
| spu_desc | SPU描述 | string |
| spu_image | 商品图片 | string |
ex_spu_hbase 表结构如下:
| 字段名称 | 字段类型 | 字段含义 |
| key | string | rowkey |
| sales | double | 销售额 |
| praise | int | 点赞数 |
创建表语句:
create external table if not exists ex_spu(
spu_id string,
shop_id string,
shop_name string,
category_name string,
spu_name string,
spu_price double,
spu_originprice double,
month_sales int,
praise_num int,
spu_unit string,
spu_desc string,
spu_image string
)
row format delimited fields terminated by ","
stored as textfile location "/app/data/exam"
tblproperties("skip.header.line.count"="1");create external table if not exists ex_spu_hbase(
key string,
sales double,
praise int
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with
serdeproperties("hbase.columns.mapping"=":key,result:sales,result:praise")
tblproperties("hbase.table.name"="exam202009:spu");5. 统计查询
①统计每个店铺的总销售额 sales, 店铺的商品总点赞数 praise,并将 shop_id 和 shop_name 的组合作为 RowKey,并将结果映射到 HBase。
插入数据:
hive (spu_db)> insert into ex_spu_hbase (select concat(shop_id,shop_name) as key ,sum(spu_price*month_sales) as sales,sum(praise_num) as praise from ex_spu group by shop_id,shop_name);
②完成统计后,分别在 hive 和 HBase 中查询结果数据。
hive (spu_db)> select * from ex_spu_hbase;
hbase(main):005:0> scan 'exam202009:spu'
相关文章:
外卖大数据案例
一、环境要求 HadoopHiveSparkHBase 开发环境。 二、数据描述 meituan_waimai_meishi.csv 是某外卖平台的部分外卖 SPU(Standard Product Unit , 标准产品单元)数据,包含了外卖平台某地区一时间的外卖信息。具体字段说明如下&am…...

到底什么是5G-R?
近日,工信部向中国国家铁路集团有限公司(以下简称“国铁集团”)批复5G-R试验频率的消息,引起了行业内的广泛关注。 究竟什么是5G-R?为什么工信部会在此时批复5G-R的试验频率? 今天,小枣君就通过…...
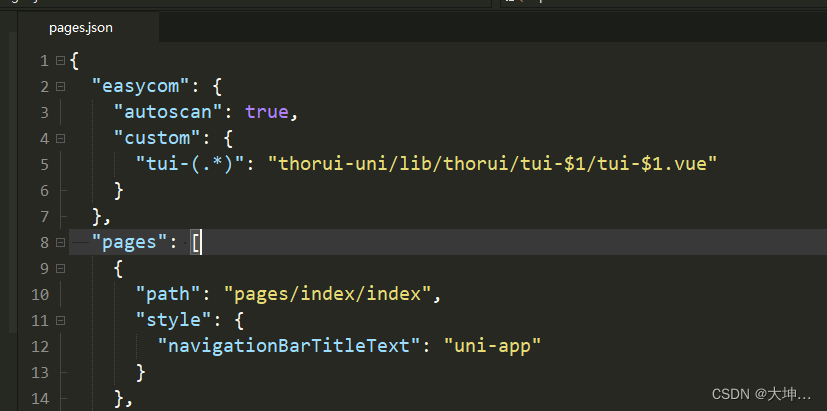
uniapp 使用和引入 thorui
1. npm install thorui-uni 2. "easycom": { "autoscan": true, "custom": { "tui-(.*)": "thorui-uni/lib/thorui/tui-$1/tui-$1.vue" } }, 3....

vue3中ref和reactive的区别
原文地址 深入聊一聊vue3中的reactive()_vue3 reactive_忧郁的蛋~的博客-CSDN博客 ref和reactive的区别-CSDN博客 理解: 1.ref是定义简单类型 和单一的对象 2.reactive 定义复杂的类型 梳理文档: ref和reactive都是Vue.js 3.x版本中新增的响应式API&…...
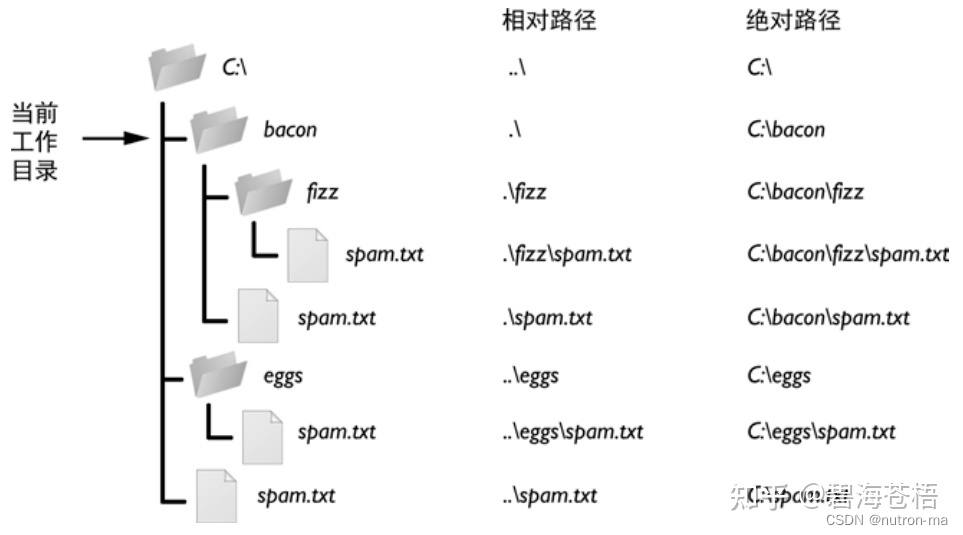
文件路径操作
避开-转义字符 python文件路径导致的错误常常与“\”有关,因为在路径中的“\”常会被误认为转义字符。 所以在上述路径中,\table\name\rain中的\t,\n,\r都易被识别为转义字符。 解决的办法主要由以下三种: #1 前面加r表示不转义 pathr&quo…...

Java Cache 缓存方案详解及代码-Ehcache
一、Spring缓存概念 Spring从3.1开始定义了 org.springframework.cache.Cache 和 org.springframework.cache.CacheManager 接口来统一不同的缓存技术; 并支持使用 JCache(JSR-107) 注解简化我们开发。 常用的缓存实现有 RedisCache 、EhCach…...
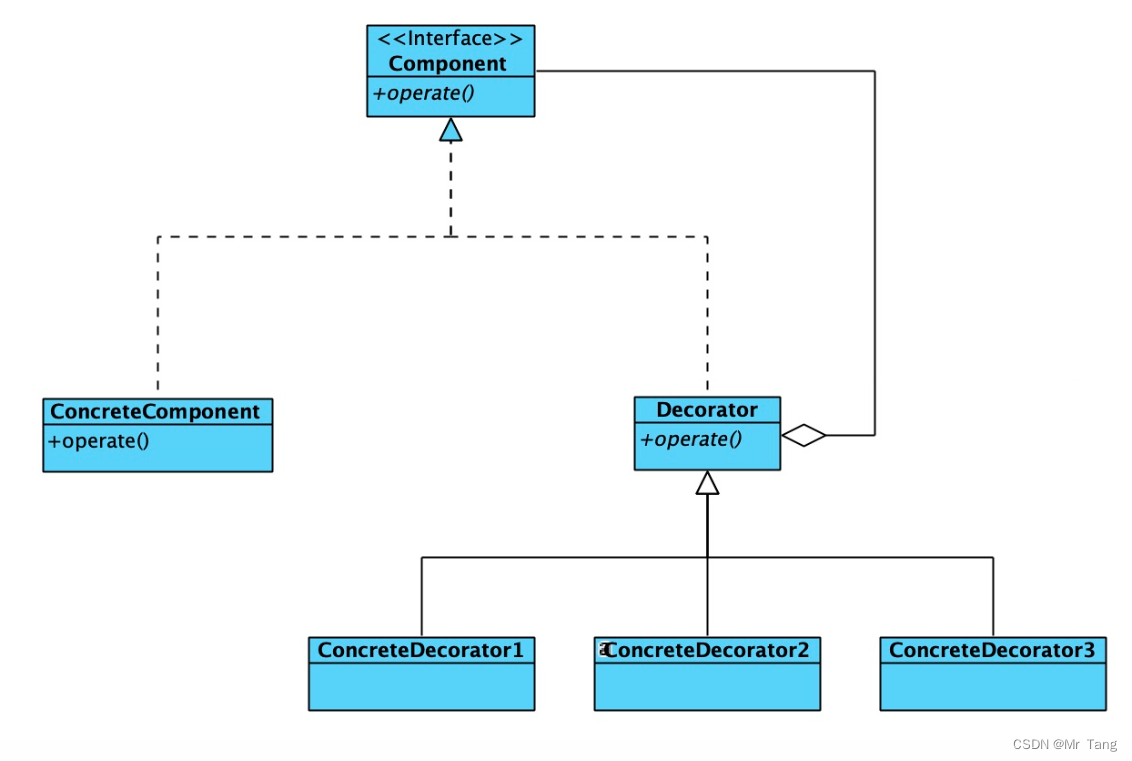
JAVA设计模式-装饰者模式
一.概念 装饰器模式(Decorator Pattern),动态地给一个对象添加一些额外的职责,就增加功能来说,装饰器模式比生成子类更灵活。 —-《大话设计模式》 允许向一个现有的对象添加新的功能,同时又不改变其结构。这种类型的设计模式属…...

STM32F1简介
前言 本次学习使用的是STM32F1系列的芯片,72MHz的Cortex-M3内核; 名词解释 STM32是ST公司基于ARM Cortex-M内核开发的32位微控制器(MCU); ARM Cortex-M内核是ARM公司设计的,程序指令的执行,…...

SpringBoot面试题6:Spring Boot 2.X 有什么新特性?与 1.X 有什么区别?
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:Spring Boot 2.X 有什么新特性?与 1.X 有什么区别? Spring Boot是一种用于简化Spring应用程序开发的框架,它提供了自动配置、起步依赖和快速开…...
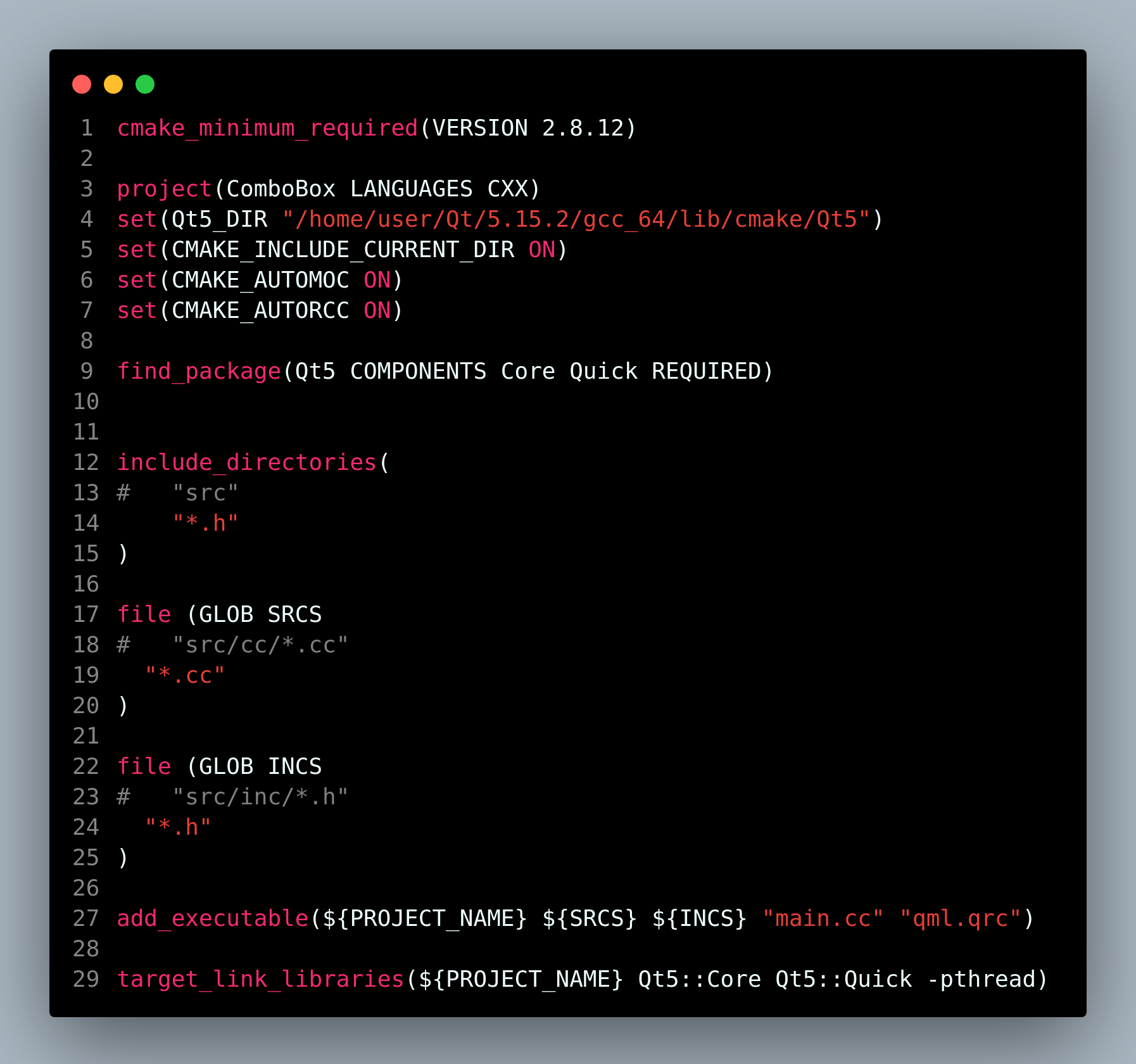
qt笔记之qml下拉标签组合框增加发送按钮发送标签内容
qt笔记之qml下拉标签组合框增加发送按钮发送标签内容 code review! 文章目录 qt笔记之qml下拉标签组合框增加发送按钮发送标签内容1.运行2.文件结构3.main.qml4.main.cc5.MyClass.h6.MyClass.cc7.CMakeLists.txt8.ComboBox.pro9.qml.qrc 1.运行 2.文件结构 3.main.qml 代码 …...

linux上构建任意版本的rocketmq多架构x86 arm镜像——筑梦之路
现状 目前市面上和官方均只有rocketmq x86架构下的docker镜像,而随着国产化和信创适配的需求越来越多,显然现有的x86架构下的docker镜像不能满足多样化的需求,因此我们需要根据官方发布的版本制作满足需求的多架构镜像,以在不同cp…...
-- Stream的3种创建方法)
Java8 新特性之Stream(五)-- Stream的3种创建方法
目录 1. 集合 创建Stream流 拓展: 2. 数组 创建Stream流 3. 静态方法 创建Stream流 1. 集合 创建Stream流 @...

Vue实现模糊查询搜索功能
第一步 先创建一个val变量 // 用户搜索内容 let val ref(""); 第二步:给input绑定v-model (为了获取input框的值) <input v-model"val" type"text" placeholder"请输入行业/公司/名称"/> 第…...
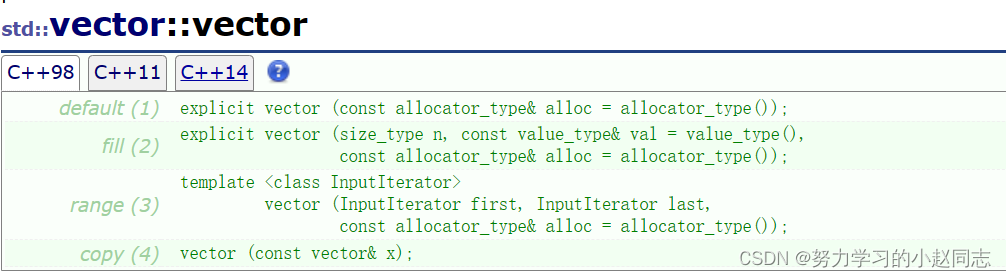
(C++ STL) 详解vector模拟实现
目录 一.vector的介绍 1.vector的介绍 二.vector的定义模拟实现 三.vector各接口的模拟实现 1.vector迭代器的模拟实现 2.构造函数 2.1无参构造 2.2 n个val构造 2.3迭代器区间构造 2.4通过对象初始化(拷贝构造) 3.析构函数 4.size 5.operato…...

c语言从入门到实战——C语言数据类型和变量
C语言数据类型和变量 前言1. 数据类型介绍1.1 字符型1.2 整型1.3 浮点型1.4 布尔类型1.5 各种数据类型的长度1.5.1 sizeof操作符1.5.2 数据类型长度1.5.3 sizeof中表达式不计算 2. signed 和 unsigned3. 数据类型的取值范围4. 变量4.1 变量的创建4.2 变量的分类 5. 算术操作符&…...
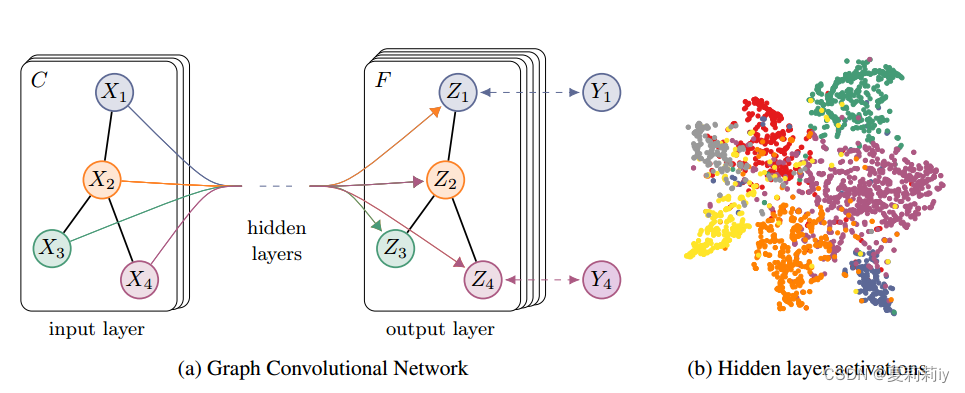
[论文精读]Semi-Supervised Classification with Graph Convolutional Networks
论文原文:[1609.02907] Semi-Supervised Classification with Graph Convolutional Networks (arxiv.org) 论文代码:GitHub - tkipf/gcn: Implementation of Graph Convolutional Networks in TensorFlow 英文是纯手打的!论文原文的summari…...

CICD:使用docker+ jenkins + gitlab搭建cicd服务
持续集成解决什么问题 提高软件质量效率迭代便捷部署快速交付、便于管理 持续集成(CI) 集成,就是一些孤立的事物或元素通过某种方式集中在一起,产生联系,从而构建一个有机整体的过程。 持续,就是指长期…...

新能源电池试验中准确模拟高空环境大气压力的解决方案
摘要:针对目前新能源电池热失控和特性研究以及生产中缺乏变环境压力准确模拟装置、错误控制方法造成环境压力控制极不稳定以及氢燃料电池中氢气所带来的易燃易爆问题,本文提出了相应的解决方案。方案的关键一是采用了低漏率电控针阀作为下游控制调节阀实…...

Python 中的模糊字符串匹配
文章目录 Python中使用thefuzz模块匹配模糊字符串使用process模块高效地使用模糊字符串匹配今天,我们将学习如何使用 thefuzz 库,它允许我们在 python 中进行模糊字符串匹配。 此外,我们将学习如何使用 process 模块,该模块允许我们借助模糊字符串逻辑有效地匹配或提取字符…...

记录一个奇怪bug
一开始Weapon脚本是继承Monobehavior的,实例化后挂在gameObject上跟着角色。后来改成了不继承mono的,也不实例化。过程都是顺利的,运行也没问题,脚本编辑器也没有错误。 但偶尔有一次报了一些错误,大概是说Weapon (1)…...

5分钟终极指南:如何免费激活Windows和Office的完整解决方案
5分钟终极指南:如何免费激活Windows和Office的完整解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统未激活的提示而烦恼吗?或者Office办公软件显…...

【限时解密】Google内部测试版Gemini插件Beta通道开放倒计时——附3个已验证的早期功能入口及Token获取密钥
更多请点击: https://intelliparadigm.com 第一章:Gemini Chrome浏览器插件的演进脉络与Beta通道战略意义 Gemini Chrome 插件自 2023 年底首次公开测试以来,已历经三次重大架构重构:从初始的轻量级内容注入脚本,演进…...

别让求解器‘装傻’:COMSOL中‘事件接口’的隐藏用法与常见坑点
别让求解器‘装傻’:COMSOL中‘事件接口’的隐藏用法与常见坑点 在瞬态耦合仿真中,你是否遇到过这样的场景:电磁场脉冲已经结束,但温度场仍在缓慢爬升;或者结构载荷突然释放,但求解器却将突变平滑处理&…...

终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽
终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 想为你的机械键盘打造一套独一无二的键帽吗?Cherr…...

Primr:开源AI研究代理,35分钟自动生成公司深度战略分析报告
1. 项目概述:Primr,一个将公司网站转化为深度战略分析的AI研究代理 如果你做过公司研究、市场分析或者投资尽调,你肯定知道那有多痛苦。打开浏览器,输入公司网址,在“关于我们”、“产品”、“新闻”和“博客”之间来…...

禅论技术分析插件:通达信量化交易系统的架构与实践
禅论技术分析插件:通达信量化交易系统的架构与实践 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 禅论作为中国特色的技术分析理论,其严谨的数学结构和逻辑体系为市场分析提供了…...

多视角时空对齐 + 跨镜轨迹融合:镜像视界打造无断点跟踪闭环
多视角时空对齐 跨镜轨迹融合:镜像视界打造无断点跟踪闭环在工业安防、智慧仓储、园区管控等全域场景智能化升级进程中,目标跟踪的连续性、精准性、全域性,始终是衡量管控体系效能的核心指标,也是传统视频监控技术难以逾越的行业…...
)
从空洞卷积到多尺度感知:图解PyTorch中ASPP的设计哲学与实现细节(附可运行代码)
从空洞卷积到多尺度感知:图解PyTorch中ASPP的设计哲学与实现细节(附可运行代码) 当我们观察一幅画时,眼睛会自然地聚焦在不同尺度的细节上——从整体构图到局部纹理,这种多尺度感知能力是人类视觉系统的核心优势。计算…...

终极Vim分屏体验:vim-airline轻量级状态栏与标签栏全攻略
终极Vim分屏体验:vim-airline轻量级状态栏与标签栏全攻略 【免费下载链接】vim-airline lean & mean status/tabline for vim thats light as air 项目地址: https://gitcode.com/gh_mirrors/vi/vim-airline vim-airline是一款轻量级的Vim状态栏与标签栏…...

VMware Unlocker 3.0:5分钟快速配置macOS虚拟机终极指南
VMware Unlocker 3.0:5分钟快速配置macOS虚拟机终极指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker VMware Unlocker 3.0是一款专为破解VMware限制而设计的开源工具,让您能在…...