竞赛 深度学习OCR中文识别 - opencv python
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 文本区域检测网络-CTPN
- 4 文本识别网络-CRNN
- 5 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习OCR中文识别系统 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
在日常生产生活中有大量的文档资料以图片、PDF的方式留存,随着时间推移 往往难以检索和归类 ,文字识别(Optical Character
Recognition,OCR )是将图片、文档影像上的文字内容快速识别成为可编辑的文本的技术。
高性能文档OCR识别系统是基于深度学习技术,综合运用Tensorflow、CNN、Caffe
等多种深度学习训练框架,基于千万级大规模文字样本集训练完成的OCR引擎,与传统的模式识别的技术相比,深度学习技术支持更低质量的分辨率、抗干扰能力更强、适用的场景更复杂,文字的识别率更高。
本项目基于Tensorflow、keras/pytorch实现对自然场景的文字检测及OCR中文文字识别。
2 实现效果
公式检测

纯文字识别

3 文本区域检测网络-CTPN
对于复杂场景的文字识别,首先要定位文字的位置,即文字检测。
简介
CTPN是在ECCV
2016提出的一种文字检测算法。CTPN结合CNN与LSTM深度网络,能有效的检测出复杂场景的横向分布的文字,效果如图1,是目前比较好的文字检测算法。由于CTPN是从Faster
RCNN改进而来,本文默认读者熟悉CNN原理和Faster RCNN网络结构。

相关代码
def main(argv):pycaffe_dir = os.path.dirname(__file__)parser = argparse.ArgumentParser()# Required arguments: input and output.parser.add_argument("input_file",help="Input txt/csv filename. If .txt, must be list of filenames.\If .csv, must be comma-separated file with header\'filename, xmin, ymin, xmax, ymax'")parser.add_argument("output_file",help="Output h5/csv filename. Format depends on extension.")# Optional arguments.parser.add_argument("--model_def",default=os.path.join(pycaffe_dir,"../models/bvlc_reference_caffenet/deploy.prototxt.prototxt"),help="Model definition file.")parser.add_argument("--pretrained_model",default=os.path.join(pycaffe_dir,"../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel"),help="Trained model weights file.")parser.add_argument("--crop_mode",default="selective_search",choices=CROP_MODES,help="How to generate windows for detection.")parser.add_argument("--gpu",action='store_true',help="Switch for gpu computation.")parser.add_argument("--mean_file",default=os.path.join(pycaffe_dir,'caffe/imagenet/ilsvrc_2012_mean.npy'),help="Data set image mean of H x W x K dimensions (numpy array). " +"Set to '' for no mean subtraction.")parser.add_argument("--input_scale",type=float,help="Multiply input features by this scale to finish preprocessing.")parser.add_argument("--raw_scale",type=float,default=255.0,help="Multiply raw input by this scale before preprocessing.")parser.add_argument("--channel_swap",default='2,1,0',help="Order to permute input channels. The default converts " +"RGB -> BGR since BGR is the Caffe default by way of OpenCV.")parser.add_argument("--context_pad",type=int,default='16',help="Amount of surrounding context to collect in input window.")args = parser.parse_args()mean, channel_swap = None, Noneif args.mean_file:mean = np.load(args.mean_file)if mean.shape[1:] != (1, 1):mean = mean.mean(1).mean(1)if args.channel_swap:channel_swap = [int(s) for s in args.channel_swap.split(',')]if args.gpu:caffe.set_mode_gpu()print("GPU mode")else:caffe.set_mode_cpu()print("CPU mode")# Make detector.detector = caffe.Detector(args.model_def, args.pretrained_model, mean=mean,input_scale=args.input_scale, raw_scale=args.raw_scale,channel_swap=channel_swap,context_pad=args.context_pad)# Load input.t = time.time()print("Loading input...")if args.input_file.lower().endswith('txt'):with open(args.input_file) as f:inputs = [_.strip() for _ in f.readlines()]elif args.input_file.lower().endswith('csv'):inputs = pd.read_csv(args.input_file, sep=',', dtype={'filename': str})inputs.set_index('filename', inplace=True)else:raise Exception("Unknown input file type: not in txt or csv.")# Detect.if args.crop_mode == 'list':# Unpack sequence of (image filename, windows).images_windows = [(ix, inputs.iloc[np.where(inputs.index == ix)][COORD_COLS].values)for ix in inputs.index.unique()]detections = detector.detect_windows(images_windows)else:detections = detector.detect_selective_search(inputs)print("Processed {} windows in {:.3f} s.".format(len(detections),time.time() - t))# Collect into dataframe with labeled fields.df = pd.DataFrame(detections)df.set_index('filename', inplace=True)df[COORD_COLS] = pd.DataFrame(data=np.vstack(df['window']), index=df.index, columns=COORD_COLS)del(df['window'])# Save results.t = time.time()if args.output_file.lower().endswith('csv'):# csv# Enumerate the class probabilities.class_cols = ['class{}'.format(x) for x in range(NUM_OUTPUT)]df[class_cols] = pd.DataFrame(data=np.vstack(df['feat']), index=df.index, columns=class_cols)df.to_csv(args.output_file, cols=COORD_COLS + class_cols)else:# h5df.to_hdf(args.output_file, 'df', mode='w')print("Saved to {} in {:.3f} s.".format(args.output_file,time.time() - t))
CTPN网络结构

4 文本识别网络-CRNN
CRNN 介绍
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长的文本序列进行识别,不用
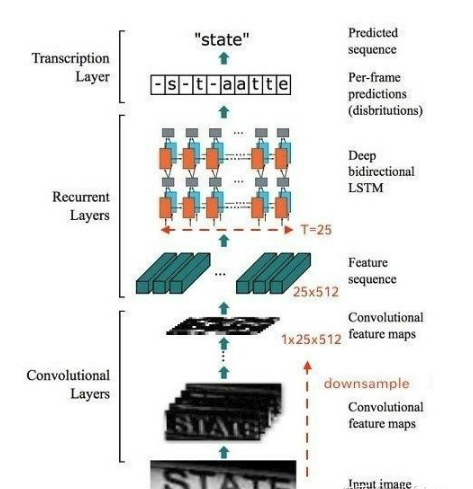
整个CRNN网络结构包含三部分,从下到上依次为:
- CNN(卷积层),使用深度CNN,对输入图像提取特征,得到特征图;
- RNN(循环层),使用双向RNN(BLSTM)对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标签(真实值)分布;
- CTC loss(转录层),使用 CTC 损失,把从循环层获取的一系列标签分布转换成最终的标签序列。
CNN
卷积层的结构图:
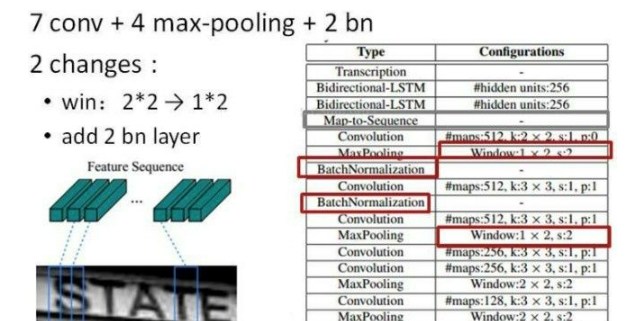
这里有一个很精彩的改动,一共有四个最大池化层,但是最后两个池化层的窗口尺寸由 2x2 改为 1x2,也就是图片的高度减半了四次(除以 2^4
),而宽度则只减半了两次(除以2^2),这是因为文本图像多数都是高较小而宽较长,所以其feature
map也是这种高小宽长的矩形形状,如果使用1×2的池化窗口可以尽量保证不丢失在宽度方向的信息,更适合英文字母识别(比如区分i和l)。
CRNN 还引入了BatchNormalization模块,加速模型收敛,缩短训练过程。
输入图像为灰度图像(单通道);高度为32,这是固定的,图片通过 CNN
后,高度就变为1,这点很重要;宽度为160,宽度也可以为其他的值,但需要统一,所以输入CNN的数据尺寸为 (channel, height,
width)=(1, 32, 160)。
CNN的输出尺寸为 (512, 1, 40)。即 CNN 最后得到512个特征图,每个特征图的高度为1,宽度为40。
Map-to-Sequence
我们是不能直接把 CNN 得到的特征图送入 RNN 进行训练的,需要进行一些调整,根据特征图提取 RNN 需要的特征向量序列。
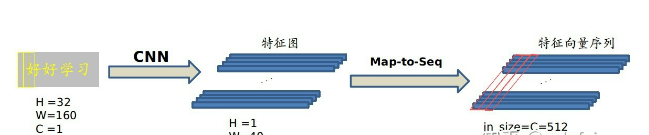
现在需要从 CNN 模型产生的特征图中提取特征向量序列,每一个特征向量(如上图中的一个红色框)在特征图上按列从左到右生成,每一列包含512维特征,这意味着第
i 个特征向量是所有的特征图第 i 列像素的连接,这些特征向量就构成一个序列。
由于卷积层,最大池化层和激活函数在局部区域上执行,因此它们是平移不变的。因此,特征图的每列(即一个特征向量)对应于原始图像的一个矩形区域(称为感受野),并且这些矩形区域与特征图上从左到右的相应列具有相同的顺序。特征序列中的每个向量关联一个感受野。
如下图所示:

这些特征向量序列就作为循环层的输入,每个特征向量作为 RNN 在一个时间步(time step)的输入。
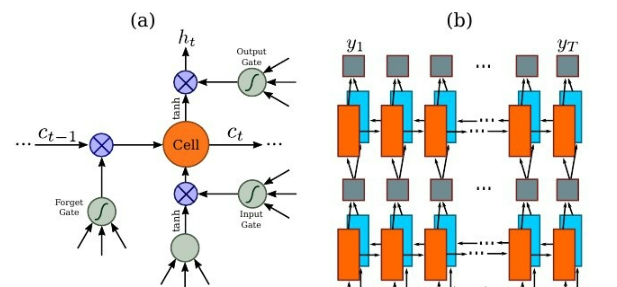
RNN
因为 RNN 有梯度消失的问题,不能获取更多上下文信息,所以 CRNN 中使用的是 LSTM,LSTM
的特殊设计允许它捕获长距离依赖,不了解的话可以看一下这篇文章 对RNN和LSTM的理解。
LSTM
是单向的,它只使用过去的信息。然而,在基于图像的序列中,两个方向的上下文是相互有用且互补的。将两个LSTM,一个向前和一个向后组合到一个双向LSTM中。此外,可以堆叠多层双向LSTM,深层结构允许比浅层抽象更高层次的抽象。
这里采用的是两层各256单元的双向 LSTM 网络:
通过上面一步,我们得到了40个特征向量,每个特征向量长度为512,在 LSTM 中一个时间步就传入一个特征向量进行分
我们知道一个特征向量就相当于原图中的一个小矩形区域,RNN
的目标就是预测这个矩形区域为哪个字符,即根据输入的特征向量,进行预测,得到所有字符的softmax概率分布,这是一个长度为字符类别数的向量,作为CTC层的输入。
因为每个时间步都会有一个输入特征向量 x^T ,输出一个所有字符的概率分布 y^T ,所以输出为 40 个长度为字符类别数的向量构成的后验概率矩阵。
如下图所示:

然后将这个后验概率矩阵传入转录层。
CTC loss
这算是 CRNN 最难的地方,这一层为转录层,转录是将 RNN
对每个特征向量所做的预测转换成标签序列的过程。数学上,转录是根据每帧预测找到具有最高概率组合的标签序列。
端到端OCR识别的难点在于怎么处理不定长序列对齐的问题!OCR可建模为时序依赖的文本图像问题,然后使用CTC(Connectionist Temporal
Classification, CTC)的损失函数来对 CNN 和 RNN 进行端到端的联合训练。
相关代码
def inference(self, inputdata, name, reuse=False):"""Main routine to construct the network:param inputdata::param name::param reuse::return:"""with tf.variable_scope(name_or_scope=name, reuse=reuse):# centerlized datainputdata = tf.divide(inputdata, 255.0)#1.特征提取阶段# first apply the cnn feature extraction stagecnn_out = self._feature_sequence_extraction(inputdata=inputdata, name='feature_extraction_module')#2.第二步, batch*1*25*512 变成 batch * 25 * 512# second apply the map to sequence stagesequence = self._map_to_sequence(inputdata=cnn_out, name='map_to_sequence_module')#第三步,应用序列标签阶段# third apply the sequence label stage# net_out width, batch, n_classes# raw_pred width, batch, 1net_out, raw_pred = self._sequence_label(inputdata=sequence, name='sequence_rnn_module')return net_out
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛 深度学习OCR中文识别 - opencv python
文章目录 0 前言1 课题背景2 实现效果3 文本区域检测网络-CTPN4 文本识别网络-CRNN5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习OCR中文识别系统 ** 该项目较为新颖,适合作为竞赛课题方向,…...

XTU-OJ 1331-密码
题目描述 Eric喜欢使用数字1,2,3,4作为密码,而且他有个怪癖,相邻数字不能相同,且相差不能超过2。当然只用数字做密码,会比较弱,Eric想知道当长度为n时,这样的密码有多少种? 输入 第一行是一个整…...

【docker】ubuntu下安装
ubuntu下安装docker 卸载原生docker更新软件包安装依赖Docker官方GPG密钥添加软件来源仓库安装docker添加用户组运行docker安装工具重启dockerhelloworld 卸载原生docker $ apt-get remove docker docker-engine docker.io containerd runc更新软件包 apt-get update apt-get…...

Linux- 命名信号量和无名信号量的区别
命名信号量和无名信号量之间的区别主要在于它们的可见性、生命周期以及如何在进程或线程之间共享。根据这些特点,它们各自更适合不同的应用场景: 命名信号量: 可见性:命名信号量由一个与其关联的名称标识,通常在某种文…...
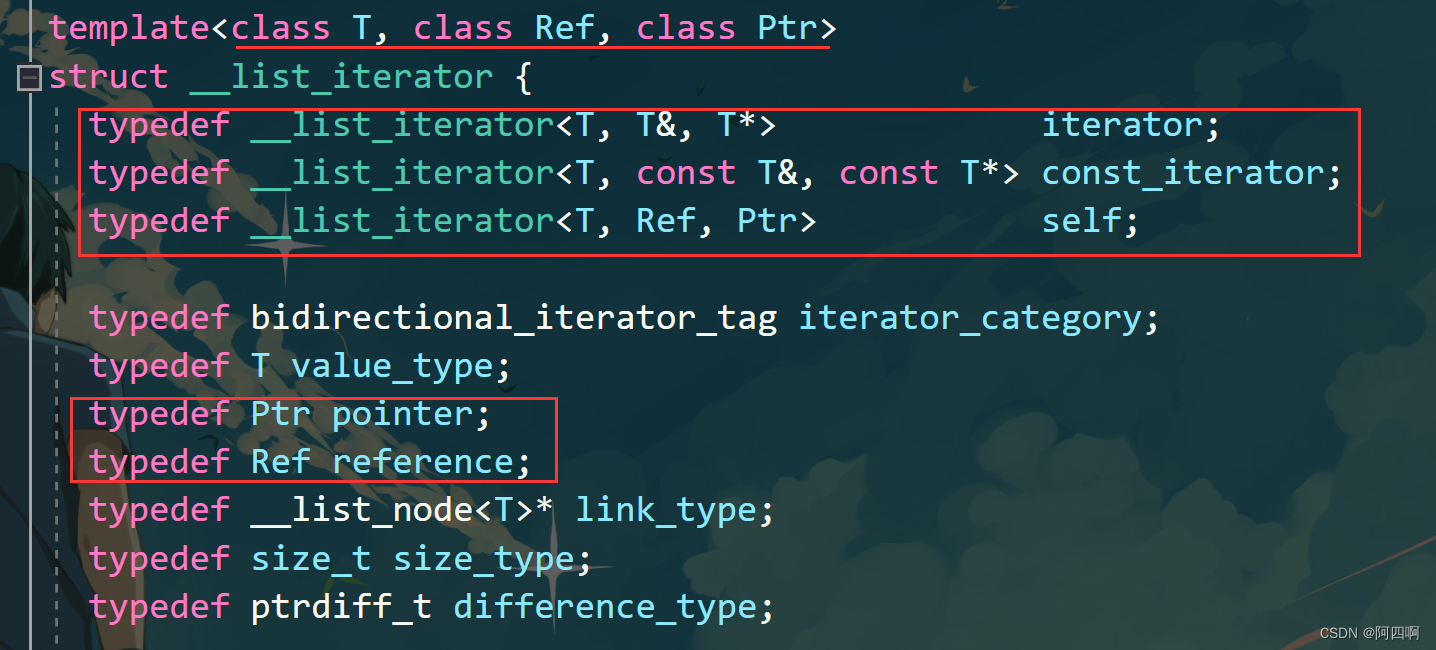
【C/C++】STL——深度剖析list容器
👻内容专栏: C/C编程 🐨本文概括:list的介绍与使用、深度剖析及模拟实现。 🐼本文作者: 阿四啊 🐸发布时间:2023.10.12 一、list的介绍与使用 1.1 list的介绍 cpluplus网站中有关…...

#力扣:136. 只出现一次的数字@FDDLC
136. 只出现一次的数字 - 力扣(LeetCode) 一、Java class Solution {public int singleNumber(int[] nums) {int ans 0;for(int num: nums) ans ^ num;return ans;} } 二、C class Solution { public:int singleNumber(vector<int>& nums…...
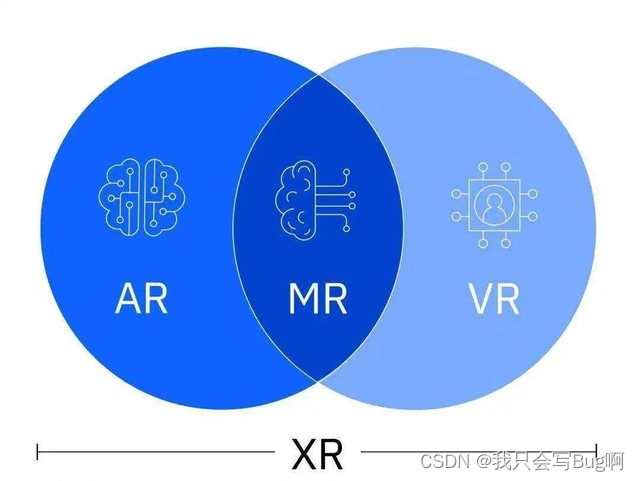
VR、AR、MR、XR到底都是什么?有什么区别
目录 VRARMRXRAR、VR、MR、XR的区别 VR 英:Virtual Reality 中文翻译:虚拟现实 又称计算机模拟现实。是指由计算机生成3D内容,为用户提供视觉、听觉等感官来模拟现实,具有很强的“临场感”和“沉浸感”。我们可以使用耳机、控制器…...
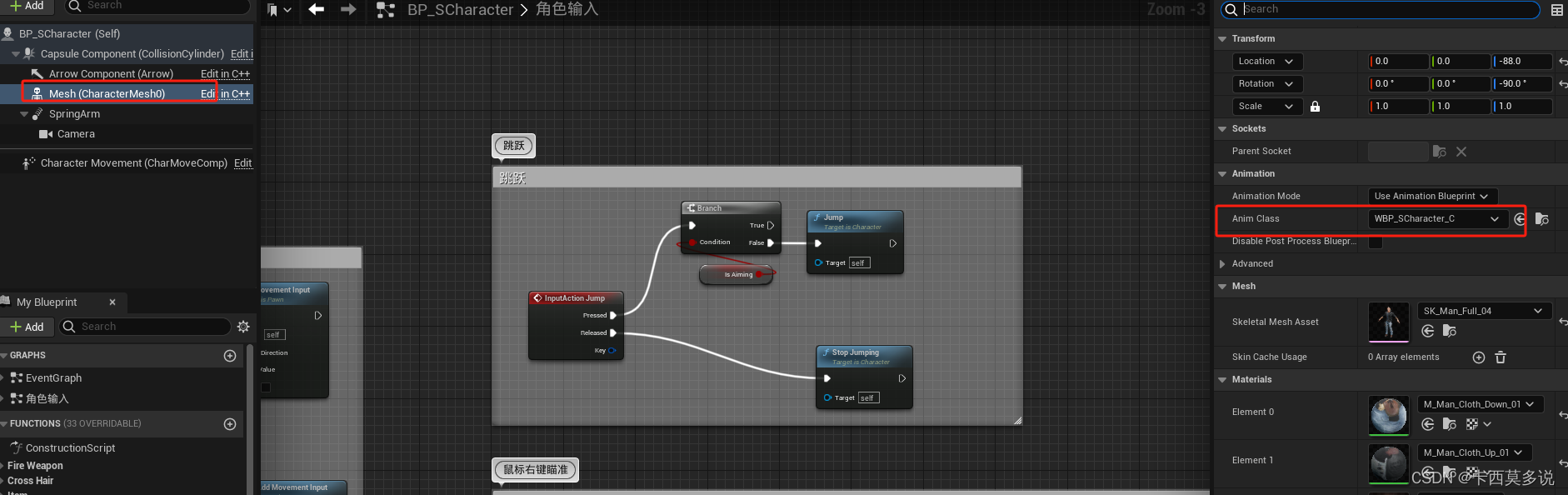
UE5射击游戏案例蓝图篇(一)
一、使用到的资源 1.小白人动画包 2.基础武器包 3.虚幻商城免费的模型包 二、角色创建 1.以Character为基类创建出需要的角色,双击打开之后并在已有组件的基础上,添加摄像机臂和摄像机两个组件。添加完成之后可以根据自己的需要调整摄像机臂的位置&…...
excel管理接口测试用例
闲话休扯,上需求:自动读取、执行excel里面的接口测试用例,测试完成后,返回错误结果并发送邮件通知。 分析: 1、设计excel表格 2、读取excel表格 3、拼接url,发送请求 4、汇总错误结果、发送邮件 开始实现…...

根文件系统制作并启动 Linux
根文件系统制作并启动 Linux busybox 下载链接:https://busybox.net/ 下载 wget https://busybox.net/downloads/busybox-1.36.1.tar.bz2解压 tar -vxf busybox-1.36.1.tar.bz2 并进入其根目录 export ARCHarm export CROSS_COMPILEarm-none-linux-gnueabihf- m…...

JSKarel教学编程机器人使用介绍
JSKarel教学编程机器人使用介绍 为了避免被编程语言固有的复杂性所困扰,有一个被称为卡雷尔(Karel)机器人的微型世界(microworld)的简化环境,可以让编程初学者从中学习理解编程的基本概念,而不…...

换低挡装置(Kickdown, ACM/ICPC NEERC 2006, UVa1588)rust解法
给出两个长度分别为n1,n2(n1,n2≤100)且每列高度只为1或2的长条。需要将它们放入一个高度为3的容器(如图3-8所示),问能够容纳它们的最短容器长度。 样例 2112112112 2212112 1012121212 2121…...
Windows10用Navicat 定时备份报错80070057
直接按照网上的教程配置定时任务发现报错,提示参数非法之类的,80070057。 搜索加自己测试发现是用户权限问题。 设置任务计划的时候,我用了用户组,选了administors,在勾选上run with hightest privileges。 查找用户…...
JimuReport 积木报表 v1.6.4 稳定版本正式发布 — 开源免费的低代码报表
项目介绍 一款免费的数据可视化报表,含报表和大屏设计,像搭建积木一样在线设计报表!功能涵盖,数据报表、打印设计、图表报表、大屏设计等! Web 版报表设计器,类似于excel操作风格,通过拖拽完成报…...

为什么要把 String 设计为不可变?
将字符串设计为不可变具有多个重要的原因: 线程安全性: 不可变字符串可以在多线程环境中共享而无需额外的同步措施。因为字符串不会改变,多个线程可以同时访问它而不会导致竞态条件或数据不一致性。 缓存和性能优化: 字符串不可变…...

华为OD机考算法题:服务器广播
题目部分 题目服务器广播难度难题目说明服务器连接方式包括直接相连,间接连接。A 和 B 直接连接,B 和 C 直接连接,则 A 和 C 间接连接。直接连接和间接连接都可以发送广播。 给出一个 N * N 数组,代表 N 个服务器,mat…...

Android ViewBinding和DataBinding功能作用区别
简述 ViewBinding和DataBinding都是用于在 Android 应用程序中处理视图的工具,但它们有不同的作用和用途。 ViewBinding: ViewBinding 是 Android Studio 的一个工具,用于生成一个绑定类,能够轻松访问 XML 布局文件中的视图。ViewBinding 为…...

【云计算网络安全】DDoS 攻击类型:什么是 ACK 洪水 DDoS 攻击
文章目录 一、什么是 ACK 洪水 DDoS 攻击?二、什么是数据包?三、什么是 ACK 数据包?四、ACK 洪水攻击如何工作?五、SYN ACK 洪水攻击如何工作?六、文末送书《AWD特训营》内容简介读者对象 一、什么是 ACK 洪水 DDoS 攻…...

springboot 导出word模板
一、安装依赖 <dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.12.1</version></dependency>二、定义工具类 package com.example.springbootmp.utils;import com.deepoove.poi.XWP…...
Angular安全专辑之五 —— 防止URL中敏感信息泄露
URL 中的敏感数据是指在网址上的机密或者个人信息,包括 UserId, usernames, passwords, session, token 等其他认证信息。 由于URL 可能会被第三方拦截和查看(比如互联网服务商、代理或者其他监视网络流量的攻击者),所以URL中的敏…...

别再为OSGB数据导入SuperMap iDesktop发愁了!手把手教你搞定倾斜摄影配置文件生成与常见报错
三维GIS实战:从OSGB到SuperMap iDesktop的完整避坑指南 当无人机航拍的倾斜摄影数据第一次在SuperMap iDesktop中成功加载时,那种从二维平面跃入三维空间的震撼感,是每个GIS从业者都难忘的体验。然而,这份喜悦往往被配置文件生成失…...

别再乱买手机了!这 3 个坑 90% 的人都踩过,看完立省千元
救命!谁还没在买手机上交过 “智商税”?😭明明花了三四千,到手却卡顿发烫、拍照模糊、续航拉胯;销售吹得天花乱坠的 “旗舰配置”,用半年就后悔想砸手机!作为换过 5 台手机、踩遍所有雷的过来人…...
的完整旅程)
Zephyr 启动流程:从复位向量到main()的完整旅程
1. 从复位向量开始的奇妙旅程 当你按下嵌入式设备的电源按钮时,芯片内部就开始了一场精心编排的启动芭蕾。对于使用Zephyr RTOS的系统来说,这个旅程从复位向量(Reset Vector)开始,就像火车从始发站出发一样。Cortex-M架…...

【基于Xilinx ZYNQ7000与PYNQ的嵌入式AI实践】从零构建实时人脸识别系统
1. 项目背景与核心价值 最近在折腾嵌入式AI项目时,发现Xilinx ZYNQ7000系列开发板真是个宝藏硬件。它独特的PS(处理器系统)PL(可编程逻辑)双架构,配合PYNQ框架的Python生态,让算法部署变得异常灵…...

JiYuTrainer终极指南:三步解锁极域电子教室,恢复学习自由
JiYuTrainer终极指南:三步解锁极域电子教室,恢复学习自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 在数字化教学时代,极域电子教室为学生…...

STC-ISP软件隐藏技巧:一键添加头文件到Keil5,并手动验证芯片包是否真正生效
STC-ISP软件隐藏技巧:深度验证Keil5芯片包安装的底层逻辑 当你按照教程点击了STC-ISP的"添加型号和头文件到Keil中"按钮,看到成功提示后满心欢喜打开Keil5,却发现下拉列表里根本没有"STC MCU Database"选项——这种挫败…...
)
仅限本周开放|DeepSeek Chat V3.2功能测试黄金 checklist(含17个边界Case+响应时延基线数据)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat V3.2功能测试黄金 checklist 发布说明 DeepSeek Chat V3.2 已正式面向开发者开放灰度测试,本次版本聚焦多模态理解增强、长上下文稳定性优化及企业级安全策略集成。为保障测试…...

基于RAG的Obsidian智能知识库:本地部署与优化实战
1. 项目概述:当知识管理遇上大语言模型 如果你和我一样,是 Obsidian 的深度用户,同时又对大语言模型(LLM)的智能涌现能力感到着迷,那么你肯定也想过一个问题:能不能让我的知识库“活”起来&…...
!)
仅1月Accepted!恭喜北大学者独作发表Nature子刊(IF 10.1)!
源自风暴统计网:一键统计分析与绘图的AI网站 引言 非协作者且是独作,用GBD 2023发表顶刊Nature是什么概念?来看今天这篇由北大学者发表的硬核文章!GBD 2023发文依然很顶,郑老师团队的专属科研训练营帮你实现从0到1的…...

基于Adafruit Trinket的光控互动玩具:嵌入式系统入门实战
1. 项目概述:给毛绒玩具注入灵魂几年前,我女儿的一个旧毛绒玩具被冷落在角落,除了偶尔被当作抱枕,几乎失去了“玩具”的活力。这让我萌生了一个想法:能不能用一些简单的电子元件,让这些静态的玩偶重新“活”…...