【 OpenGauss源码学习 —— 列存储(CU)(二)】
列存储(CU)(二)
- 概述
- GetCUHeaderSize 函数
- Compress 函数
- CU::FillCompressBufHeader 函数
- CU::CompressNullBitmapIfNeed 函数
- CU::CompressData 函数
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》一书以及OpenGauss社区学习文档和一些学习资料
概述
在【OpenGauss源码学习 —— 列存储(CU)(一)】中我们初步认识了 CU 的结构和作用,本文我们接着来学习列存储数据的压缩和解压缩操作。本文所要学习的函数如下表所示:
| 函 数 | 作 用 |
|---|---|
| GetCUHeaderSize | 用于获取一个压缩单元(CU)头部的大小。 |
| Compress | 用于压缩数据。它接受要压缩的数据数量 (valCount)、压缩模式 (compress_modes) 和对齐大小 (align_size) 作为参数,然后对数据进行压缩操作。 |
| FillCompressBufHeader | 用于填充压缩缓冲区的头部信息。这些信息通常包括元数据和描述压缩数据的头部。 |
| CompressNullBitmapIfNeed | 如果需要压缩空值位图,则这个函数会对其进行压缩。它接受一个指向字符缓冲区 (buf) 的指针作为参数,然后执行相应的压缩操作。 |
| CompressData | 用于压缩数据。它接受一个输出缓冲区 (outBuf),要压缩的数据数量 (nVals),压缩选项 (compressOption) 和对齐大小 (align_size) 作为参数,并将压缩后的数据存储在 outBuf 中。 |
这几个函数用于在数据库系统中进行列存储数据的压缩和解压缩操作,包括获取压缩头部信息大小、对数据进行压缩、填充压缩数据的头部信息、以及在需要时压缩 NULL 位图和解压缩数据,以有效地存储和检索压缩的列存储数据。
GetCUHeaderSize 函数
该函数用于计算列存储数据单元(Column Unit)头部的大小,该头部包括用于数据校验和解析的信息,如 CRC、魔术数字、信息模式、压缩的 NULL 位图大小、未压缩数据大小和压缩数据大小。这些信息在存储和检索列存储数据时起到关键作用,以确保数据的完整性和正确性。其函数源码如下所示:(路径:src/gausskernel/storage/cstore/cu.cpp)
// 获取列存储数据单元(Column Unit)头部的大小
int16 CU::GetCUHeaderSize(void) const
{// 返回头部大小,包括以下部分:return sizeof(m_crc) + // CRC,用于数据完整性检查sizeof(m_magic) + // 魔术数字,用于标识数据单元类型sizeof(m_infoMode) + // 信息模式,包含元组和压缩元组的信息// 如果存在压缩的NULL位图,包括其大小(HasNullValue() ? sizeof(m_bpNullCompressedSize) : 0) +sizeof(m_srcDataSize) + // 未压缩数据大小sizeof(int); // 压缩后数据的大小
}
这个函数用于确定列存储数据单元头部的大小,该头部包含了用于数据校验和信息描述的各个字段。注释提供了对每个字段和计算过程的解释。
Compress 函数
Compress 函数用于压缩一个列存储数据单元(Column Unit),它首先分配一个用于存储压缩后数据的缓冲区,然后依次执行以下步骤:初始化缓冲区大小,填充 NULL 位图(如果需要),压缩数据,如果数据无法压缩则保留未压缩的数据,加密压缩后的数据,填充缓冲区头部,最后标记数据单元为已压缩并释放原始数据缓冲区。其函数源码如下所示:(路径:src/gausskernel/storage/cstore/cu.cpp)
/** @Description: 压缩一个列存储数据单元(Column Unit)* @IN compress_modes: 压缩模式* @IN valCount: 值的数量* @See also: 另请参阅*/
void CU::Compress(int valCount, int16 compress_modes, int align_size)
{errno_t rc;// 步骤 1: 初始化分配压缩缓冲区的大小// 源数据大小 + NULL位图大小 + 头部大小// 我们保证压缩数据大小不会超过这个大小m_compressedBufSize = CUAlignUtils::AlignCuSize(m_srcDataSize + m_bpNullRawSize + sizeof(CU), align_size);m_compressedBuf = (char*)CStoreMemAlloc::Palloc(m_compressedBufSize, !m_inCUCache);int16 headerLen = GetCUHeaderSize();char* buf = m_compressedBuf + headerLen;// 步骤 2: 填充压缩的NULL位图buf = CompressNullBitmapIfNeed(buf);// 步骤 3: 压缩数据bool compressed = false;if (COMPRESS_NO != heaprel_get_compression_from_modes(compress_modes))compressed = CompressData(buf, valCount, compress_modes, align_size);// 情况 1: 用户定义不应压缩输入数据。// 情况 2: 即使用户定义压缩数据,但压缩后的数据大小// 大于未压缩数据的大小,因此使用未压缩数据而不是压缩数据。if (compressed == false) {rc = memcpy_s(buf, m_srcDataSize, m_srcData, m_srcDataSize);securec_check(rc, "\0", "\0");m_cuSizeExcludePadding = headerLen + m_bpNullCompressedSize + m_srcDataSize;m_cuSize = CUAlignUtils::AlignCuSize(m_cuSizeExcludePadding, align_size);PADDING_CU(buf + m_srcDataSize, m_cuSize - m_cuSizeExcludePadding);}// 压缩后加密数据单元CUDataEncrypt(buf);// 步骤 4: 填充压缩缓冲区的头部FillCompressBufHeader();m_cache_compressed = true;// 步骤 5: 释放源缓冲区FreeSrcBuf();
}
函数执行过程解释:假设有一个列存储数据单元(CU),其中包含多个列的数据,需要将该 CU 进行压缩。首先,函数分配一个缓冲区,该缓冲区的大小由源数据大小、NULL 位图大小和头部信息大小组成,确保足够容纳压缩后的数据。接着,它检查是否有 NULL 值,如果有,则填充 NULL 位图到缓冲区。然后,它尝试对数据进行压缩,如果压缩后的数据大小小于未压缩数据大小,将压缩后的数据存入缓冲区。如果数据无法压缩或者压缩后的大小更大,它将保留未压缩的数据。接下来,对压缩后的数据进行加密,并填充缓冲区头部信息。最后,将该 CU 标记为已压缩状态,并释放原始数据缓冲区。这个函数用于减小存储空间并提高数据传输效率。
CU::FillCompressBufHeader 函数
CU::FillCompressBufHeader 函数用于填充压缩缓冲区(m_compressedBuf)的头部信息。以下是该函数的详细解释:该函数的主要功能是在压缩缓冲区中设置头部信息,包括魔术标识、信息模式、NULL 位图压缩大小、未压缩数据大小、压缩数据大小以及 CRC 校验值。这些信息用于描述和校验压缩后的数据。这个过程有助于确保数据的完整性和可靠性。
其中,CU::FillCompressBufHeader 函数在 Compress 函数中调用。其函数源码如下所示:(路径:src/gausskernel/storage/cstore/cu.cpp)
void CU::FillCompressBufHeader(void)
{errno_t rc;// m_crc将在压缩结束时设置char* buf = m_compressedBuf;int pos = sizeof(m_crc);// 将m_magic(魔术标识)复制到压缩缓冲区rc = memcpy_s(buf + pos, sizeof(m_magic), &m_magic, sizeof(m_magic));securec_check(rc, "\0", "\0");pos += sizeof(m_magic);// 设置m_infoMode(信息模式)为CU_CRC32C,表示使用CRC32C校验m_infoMode |= CU_CRC32C;// 将m_infoMode(信息模式)复制到压缩缓冲区rc = memcpy_s(buf + pos, sizeof(m_infoMode), &m_infoMode, sizeof(m_infoMode));securec_check(rc, "\0", "\0");pos += sizeof(m_infoMode);// 如果CU中包含NULL值,将m_bpNullCompressedSize(NULL位图压缩大小)复制到压缩缓冲区if (HasNullValue()) {rc = memcpy_s(buf + pos, sizeof(m_bpNullCompressedSize), &m_bpNullCompressedSize, sizeof(m_bpNullCompressedSize));securec_check(rc, "\0", "\0");pos += sizeof(m_bpNullCompressedSize);}// 将m_srcDataSize(未压缩数据大小)复制到压缩缓冲区rc = memcpy_s(buf + pos, sizeof(m_srcDataSize), &m_srcDataSize, sizeof(m_srcDataSize));securec_check(rc, "\0", "\0");pos += sizeof(m_srcDataSize);// 计算压缩数据的大小(cmprDataSize)并复制到压缩缓冲区int cmprDataSize = m_cuSizeExcludePadding - GetCUHeaderSize() - m_bpNullCompressedSize;rc = memcpy_s(buf + pos, sizeof(cmprDataSize), &cmprDataSize, sizeof(cmprDataSize));securec_check(rc, "\0", "\0");pos += sizeof(cmprDataSize);// 断言检查头部数据的位置是否正确Assert(pos == GetCUHeaderSize());// 最后,计算CRC校验值(m_crc)并将其存储在压缩缓冲区的开头m_crc = GenerateCrc(m_infoMode);*(uint32*)m_compressedBuf = m_crc;
}
CU::CompressNullBitmapIfNeed 函数
CU::CompressNullBitmapIfNeed 函数用于检查是否需要压缩 NULL 位图数据,然后在压缩缓冲区中进行相应的处理。以下是该函数的详细解释:该函数用于处理 NULL 位图数据的压缩,但当前的实现中,它并没有执行任何实际的压缩操作。在注释中标明了 “FUTURE CASE”,表示将来可能会加入对 NULL 位图数据的压缩和解压缩支持。所以,这个函数目前只是将原始的 NULL 位图数据复制到压缩缓冲区中,并将压缩后的大小设置为原始大小。其函数源码如下所示:(路径:src/gausskernel/storage/cstore/cu.cpp)
// FUTURE CASE: null bitmap data should be compressed and decompressed
// 注意:应该同时修改CompressNullBitmapIfNeed()和UnCompressNullBitmapIfNeed()函数。
char* CU::CompressNullBitmapIfNeed(_in_ char* buf)
{errno_t rc;if (HasNullValue()) {Assert(m_bpNullRawSize > 0);// FUTURE CASE: 延迟压缩NULL位图数据// 将NULL位图数据复制到压缩缓冲区中rc = memcpy_s(buf, m_bpNullRawSize, m_nulls, m_bpNullRawSize);securec_check(rc, "\0", "\0");m_bpNullCompressedSize = m_bpNullRawSize;}return (buf + m_bpNullCompressedSize);
}
CU::CompressData 函数
CU::CompressData 函数的作用是对列存储数据进行压缩。以下是该函数的详细解释:
这个函数执行以下操作:
- 根据压缩模式选择适当的压缩方法,对数据进行压缩。
- 如果支持时序数据类型(TIMESTAMP 或 FLOAT),可能执行特殊的时序压缩。
- 如果压缩成功,计算压缩后 CU 的大小并设置相应的压缩信息。
- 如果采样尚未完成,对样本进行采样并设置采纳的压缩方法。
- 返回一个布尔值,指示是否成功压缩。
这个函数用于在列存储中对数据进行压缩,以减小存储占用空间。根据数据类型和压缩模式,它可能使用不同的压缩算法。如果数据成功压缩,将设置压缩后 CU 的大小和相应的元信息。这有助于在存储和检索数据时提高性能和减少存储成本。其函数源码如下所示:(路径:src/gausskernel/storage/cstore/cu.cpp)
/** @Description: 压缩一个CU(列存储单元)数据。* @IN compress_modes: 压缩模式* @IN nVals: 值的数量* @OUT outBuf: 输出缓冲区* @Return: 布尔值,表示是否成功压缩* @See also:*/
bool CU::CompressData(_out_ char* outBuf, _in_ int nVals, _in_ int16 compress_modes, int align_size)
{int compressOutSize = 0; // 用于存储压缩后的数据大小bool beDelta2Compressed = false; // 用于表示是否使用了特殊的时序压缩方法,例如Delta压缩bool beXORCompressed = false; // 用于表示是否使用了XOR压缩方法/* 从压缩模式获取压缩值 */int8 compression = heaprel_get_compression_from_modes(compress_modes);// 准备输入参数CompressionArg2 output = {0};output.buf = outBuf;output.sz = (m_compressedBuf + m_compressedBufSize) - outBuf;CompressionArg1 input = {0};input.sz = m_srcDataSize;input.buf = m_srcData;input.mode = compress_modes;// 获取压缩过滤器compression_options* ref_filter = (compression_options*)m_tmpinfo->m_options;// 检查是否支持时序数据类型,例如TIMESTAMP或FLOATif (g_instance.attr.attr_common.enable_tsdb && (ATT_IS_TIMESTAMP(m_atttypid) || ATT_IS_FLOAT(m_atttypid))) {// 使用特殊的时序压缩方法SequenceCodec sequenceCoder(m_eachValSize, m_atttypid);compressOutSize = sequenceCoder.compress(input, output);if (ATT_IS_TIMESTAMP(m_atttypid)) {beDelta2Compressed = true;} else if (ATT_IS_FLOAT(m_atttypid)) {beXORCompressed = true;}}// 如果没有进行时序压缩或时序压缩失败,继续以下操作if (compressOutSize < 0 || (!beDelta2Compressed && !beXORCompressed)) {// 重置输出参数output = {0};output.buf = outBuf;output.sz = (m_compressedBuf + m_compressedBufSize) - outBuf;// 检查是否使用整型压缩模式if (m_infoMode & CU_IntLikeCompressed) {if (ATT_IS_CHAR_TYPE(m_atttypid)) {// 对CHAR类型使用整数压缩IntegerCoder intCoder(8);/* 设置最小/最大值 */if (m_tmpinfo->m_valid_minmax) {intCoder.SetMinMaxVal(m_tmpinfo->m_min_value, m_tmpinfo->m_max_value);}/* 提供RLE编码的提示 */intCoder.m_adopt_rle = ref_filter->m_adopt_rle;compressOutSize = intCoder.Compress(input, output);} else if (ATT_IS_NUMERIC_TYPE(m_atttypid)) {if (compression > COMPRESS_LOW) {/// 数值数据类型压缩。/// 直接使用lz4/zlib。input.buildGlobalDict = false;input.useGlobalDict = false;input.globalDict = NULL;input.useDict = false;input.numVals = HasNullValue() ? (nVals - CountNullValuesBefore(nVals)) : nVals;StringCoder strCoder;compressOutSize = strCoder.Compress(input, output);}} else {// 未来,其他类型}} else if (m_eachValSize > 0 && m_eachValSize <= 8) {// 使用整数压缩IntegerCoder intCoder(m_eachValSize);/* 设置最小/最大值 */if (m_tmpinfo->m_valid_minmax) {intCoder.SetMinMaxVal(m_tmpinfo->m_min_value, m_tmpinfo->m_max_value);}/* 提供RLE编码的提示 */intCoder.m_adopt_rle = ref_filter->m_adopt_rle;compressOutSize = intCoder.Compress(input, output);} else {// 未来,其他情况Assert(-1 == m_eachValSize || m_eachValSize > 8);input.buildGlobalDict = false;input.useGlobalDict = false;input.globalDict = NULL;// 对于大小大于8的定长数据类型,// 直接使用lz4/zlib方法,不包括字典方法。// 对于大小为-1的可变长度数据类型,可以应用字典方法// 首先尝试使用字典方法。input.useDict = (m_eachValSize > 8) ? false : (COMPRESS_LOW != compression);// 值的数量不包括NULL值的数量。input.numVals = HasNullValue() ? (nVals - CountNullValuesBefore(nVals)) : nVals;// 使用StringCoder.CompressStringCoder strCoder;/* 提供关于RLE和字典编码的提示 */strCoder.m_adopt_rle = ref_filter->m_adopt_rle;strCoder.m_adopt_dict = ref_filter->m_adopt_dict;compressOutSize = strCoder.Compress(input, output);}}if (compressOutSize > 0) {// 压缩成功,计算CU大小并设置压缩信息Assert((uint32)compressOutSize < m_srcDataSize);Assert((0 == (output.modes & CU_INFOMASK2)) && (0 != (output.modes & CU_INFOMASK1)));m_infoMode |= (output.modes & CU_INFOMASK1);m_cuSizeExcludePadding = (outBuf - m_compressedBuf) + compressOutSize;m_cuSize = CUAlignUtils::AlignCuSize(m_cuSizeExcludePadding, align_size);Assert(m_cuSize <= m_compressedBufSize);PADDING_CU(m_compressedBuf + m_cuSizeExcludePadding, m_cuSize - m_cuSizeExcludePadding);if (!ref_filter->m_sampling_fihished) {/* 对样本进行采样并设置采纳的压缩方法 */ref_filter->set_common_flags(output.modes);}return true;}return false;
}
相关文章:
(二)】)
【 OpenGauss源码学习 —— 列存储(CU)(二)】
列存储(CU)(二) 概述GetCUHeaderSize 函数Compress 函数CU::FillCompressBufHeader 函数CU::CompressNullBitmapIfNeed 函数CU::CompressData 函数 声明:本文的部分内容参考了他人的文章。在编写过程中,我们…...
Java并发面试题:(四)synchronized和lock区别
synchronized 关键字 synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它 修饰的方法或者代码块在任意时刻只能有一个线程执行。 另外,在 Java 早期版本中, synchronized属于重量级锁,效率…...

使用Nginx实现采集端和数据分析平台的数据加密传输
1. 需求描述 目前鸿鹄暴露出来的重要ports如下表: 在实际的生产环境中,结合我司的使用场景,需要在鸿鹄前端安装proxy,用以解决如下两个问题: 1.1 实现http到https的强制跳转 企业环境中,一般会关闭http 80端…...

appium---如何判断原生页面和H5页面
目前app中存在越来越多的H5页面了,对于一些做app自动化的测试来说,要求也越来越高,自动化不仅仅要支持原生页面,也要可以H5中进行操作自动化, webview是什么 webview是属于android中的一个控件,也相当于一…...

【WIFI】【WPS】如何从log角度判断WPS 已经连接上
在Android项目中,由于WPS在Framework 接口中已经remove了 只能通过wpa-supplicant 代码中去判断是否连接上了 这段代码log 表示 PBC模式下没有激活 09-21 22:42:16.221503 3782 3782 D wpa_supplicant: wlan0: 0: 04:cf:4b:21:a0:3e ssid=Openwrt-WPS-tp wpa_ie_len=0 rsn…...

[正式学习java①]——java项目结构,定义类和创建对象,一个标准javabean的书写
目录 一、创建第一个java文件 二、 初始类和对象 三、符合javabean规范的类 一、创建第一个java文件 要想写代码,你得有文件啊 以前的创建方式: 右键新建文本文档,开始写代码,写完改后缀名,保存……这样文件一旦多了…...

day36
今日内容概要 进程基础(操作系统中的概念) 进程调度算法(四种算法) 进程的并行和并发的概念 同步异步阻塞非阻塞的概念 创建进程(进程类Process) Process类的参数 Process类的方法 如何开启多进程 基于TCP协议的高并发程序 进程基础 进程它是操作系统中最重要的概念…...

五. 激光雷达建图和定位方案-开源SLAM
前面内容: 一. 器件选型心得(系统设计)--1_goldqiu的博客-CSDN博客 一. 器件选型心得(系统设计)--2_goldqiu的博客-CSDN博客 二. 多传感器时间同步方案(时序闭环)--1 三. 多传感器标定方案&a…...
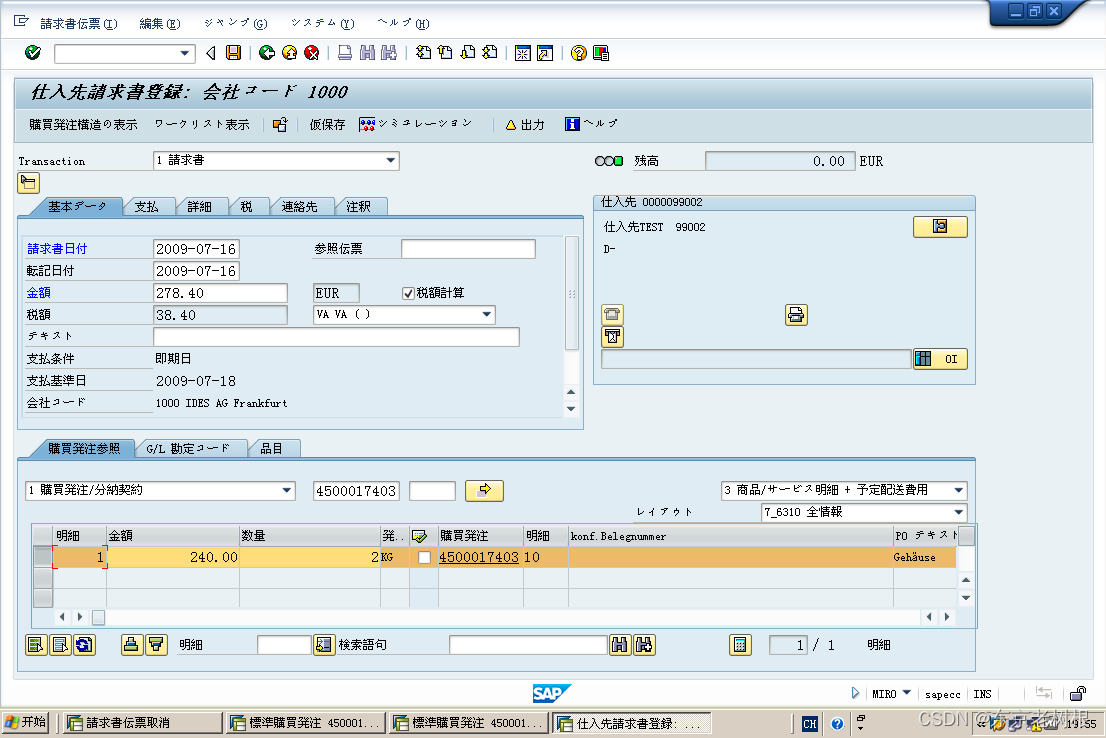
SAP MM学习笔记37 - 请求书照合中的 追加请求/追加Credit 等概念/ 请求书的取消
有关请求书照合,之前学习了一部分,现在再来学其中的一些概念。 其实这些概念也许并不常用,但是你又不能不知道,因为客户会问。 有关请求书,贴一些以前学习的文章,以方便阅读。 SAP MM学习笔记33 - 请求书…...

【C#】Winform实现轮播图
复制后,需要修改的代码: 1、图片文件夹路劲:string folderPath "C:\\Users\\Administrator\\Desktop\\images"; 2、项目命名空间:namespace BuildAction 全窗口代码: using System; using System.Colle…...
MyBatisPlus(十九)自动填充
说明 自动填充指的是,当数据被 插入 或者 更新 的时候,会为指定字段进行一些默认的数据填充。 比如,插入时,会自动填充数据的创建时间和更新时间;更新时,会自动填充数据的更新时间。 实现方式 配置处理器…...
设计模式_命令模式
命令模式 介绍 定义案例问题堆积在哪里解决办法 行为形设计模式 就是把 “发布命令 执行命令”细化为多个角色 每个角色又能继续细化 发布命令 1 打印1-9 a 打印A-G 如果有更多的命令 命令处理方式更加多样性 更复杂 处理命令的顺序拆分角色:降低耦合度 命令类&am…...

python接口自动化测试(六)-unittest-单个用例管理
前面五节主要介绍了环境搭建和requests库的使用,可以使用这些进行接口请求的发送。但是如何管理接口案例?返回结果如何自动校验?这些内容光靠上面五节是不行的,因此从本节开始我们引入python单元测试框架 unittest,用它…...

tomcat 服务器
tomcat 服务器 tomcat: 是一个开源的web应用服务器。区别nginx,nginx主要处理静态页面,那么动态请求(连接数据库,动态页面)并不是nginx的长处,动态的请求会交给tomcat进行处理。 nginx-----转发动态请求-…...

如果你有一次自驾游的机会,你会如何准备?
常常想来一次说走就走的自驾游,但是光是想想就觉得麻烦的事情好多:漫长的公路缺少娱乐方式、偏僻拗口的景点地名难以导航、不熟悉的城市和道路容易违章…… 也因为如此,让我发现了HUAWEI HiCar这个驾驶人的宝藏! 用HUAWEI HiCar…...
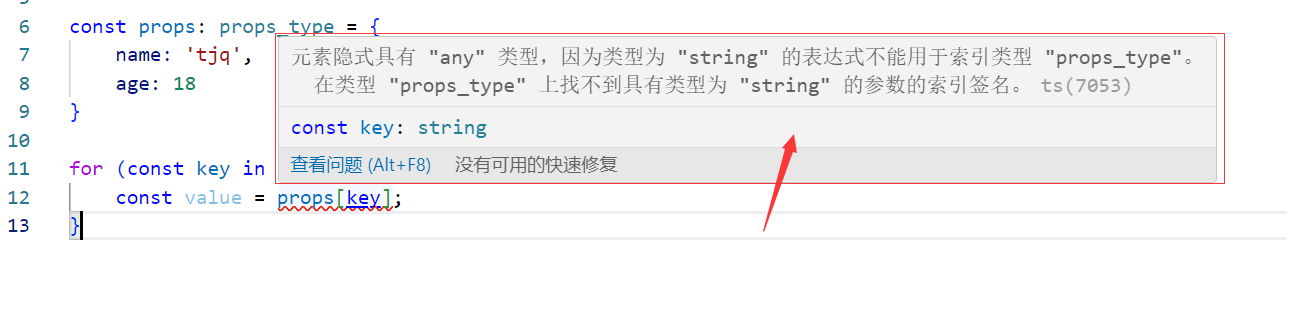
关于ts的keyof
type props_type {name: string,age: number }const props: props_type {name: tjq,age: 18 }for (const key in props) { //props[key]出现红色波浪线const value props[key]; }why? 经过我查阅多方资料,在网上看到一个比较合适的例子 地址…...
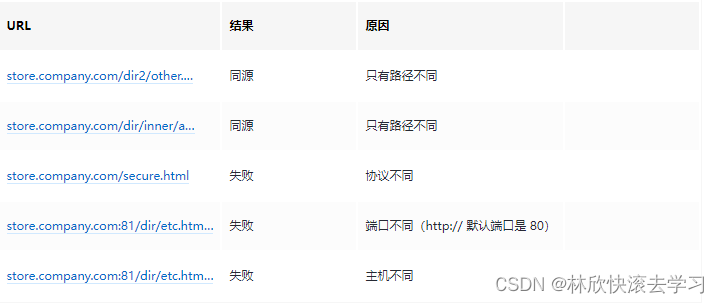
Go实现CORS(跨域)
引言 很多时候,需要允许Web应用程序在不同域之间(跨域)实现共享资源。本文将简介跨域、CORS的概念,以及如何在Golang中如何实现CORS。 什么是跨域 如果两个 URL 的协议、端口(如果有指定的话)和主机都相…...

第一章:变量和简单的数据类型
第一节 变量 variable(变量),每个变量指向一个值————与该变量相关联的信息 message"hello python world!" print(message) 1.1变量的命名和使用 1.变量名只能包含数字(0~9)、字母(Aa~Zz)和下划线(_)。变量可以使用字母和下划线作为开头,…...

【初识Linux】:常见指令(2)
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关Linux的基础知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从入门到精通 数…...

“torch.load“中出现的“Unexpected key(s) in state_dict“报错问题
问题: 解决: 添加strictFalse,允许加载过程中出现不匹配的键。但请注意,仍然需要确保模型中的主要参数能够正确加载,以确保模型的有效性。 model.load_state_dict(state_dict) # 改为: model.load_state_dict(state…...

告别音频调试噩梦:AP-0316 DSP语音处理模组全解析与实战选型
在嵌入式产品开发中,语音处理往往是考验硬件工程师耐心的“深水区”。无论是智能门禁的对讲系统,还是会议终端的免提通话,只要涉及到麦克风阵列、回声消除(AEC)和环境降噪(ENC),往往…...
)
告别盲测!用Arduino UNO和VL6180X做个桌面防撞小助手(OLED实时显示距离)
用Arduino UNO和VL6180X打造智能桌面防撞系统 每次在办公桌上不小心碰倒水杯或手机从桌边滑落时,那种手忙脚乱的场景想必大家都不陌生。今天我们就来解决这个日常小烦恼——利用Arduino UNO开发板和VL6180X传感器,配合OLED显示屏,制作一个能实…...

如何快速清理Windows驱动垃圾:DriverStore Explorer终极使用指南
如何快速清理Windows驱动垃圾:DriverStore Explorer终极使用指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的C盘空间是不是总在不知不觉中变小?系统运行…...

如何免费打造终极跨平台音乐播放器:一站式解决你的所有音乐需求
如何免费打造终极跨平台音乐播放器:一站式解决你的所有音乐需求 【免费下载链接】VutronMusic 高颜值的第三方网易云播放器;支持流媒体音乐,如navidrome、jellyfin、emby;支持本地音乐播放、离线歌单、逐字歌词、桌面歌词、Touch …...

Clutch故障排查手册:常见问题及解决方案汇总
Clutch故障排查手册:常见问题及解决方案汇总 【免费下载链接】clutch Extensible platform for infrastructure management 项目地址: https://gitcode.com/gh_mirrors/clu/clutch Clutch是一个可扩展的基础设施管理平台,旨在简化运维操作并提升开…...
 函数详解】)
【Python range() 函数详解】
文章目录Python range() 函数详解 ✨什么是range()函数? 🤔range()的参数和用法 📊单参数形式:range(stop)双参数形式:range(start, stop)三参数形式:range(start, stop, step)range()对象的特点 …...

DeltaV私有协议逆向分析与流量识别实战
1. 这不是普通工控协议——DeltaV私有协议为何让安全团队彻夜难眠Emerson DeltaV,这个名字在石化、制药、精细化工等连续流程工业现场几乎等同于“控制系统心脏”。但真正让一线自动化工程师和网络安全人员同时皱眉的,从来不是它那套成熟稳定的DCS架构&a…...

Onekey Steam清单下载工具:快速获取游戏清单的完整指南
Onekey Steam清单下载工具:快速获取游戏清单的完整指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey Onekey是一款专业的开源Steam Depot清单下载工具,能够直接连接Ste…...

用MATLAB和Python搞定二维热传导仿真:从ADI算法到FFT快速求解器的保姆级对比
MATLAB与Python热传导仿真实战:从算法选择到性能调优 在工程仿真领域,热传导问题一直是个经典课题。无论是电子设备散热分析、建筑热工设计还是材料加工模拟,二维热传导方程的求解都是基础中的基础。对于需要在不同编程环境中实现这类仿真的工…...

SMUDebugTool:5个技巧掌握AMD Ryzen底层硬件调试的完整指南
SMUDebugTool:5个技巧掌握AMD Ryzen底层硬件调试的完整指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https…...