21-数据结构-内部排序-交换排序
简介:主要根据两个数据进行比较从而交换彼此位置,以此类推,交换完全部。主要有冒泡和快速排序两种。
目录
一、冒泡排序
1.1简介:
1.2代码:
二、快速排序
1.1简介:
1.2代码:
一、冒泡排序
1.1简介:
冒泡,即每次给表中一个数据,弄到最前面或者最后面,以此类推。其主要思想为:外循环是趟数,内循环是比较次数,两两比较,一点点往后冒。从第1趟比较开始比较,比较n-1次,第2趟比较,比较n-2次,以此类推,所以比较次数为
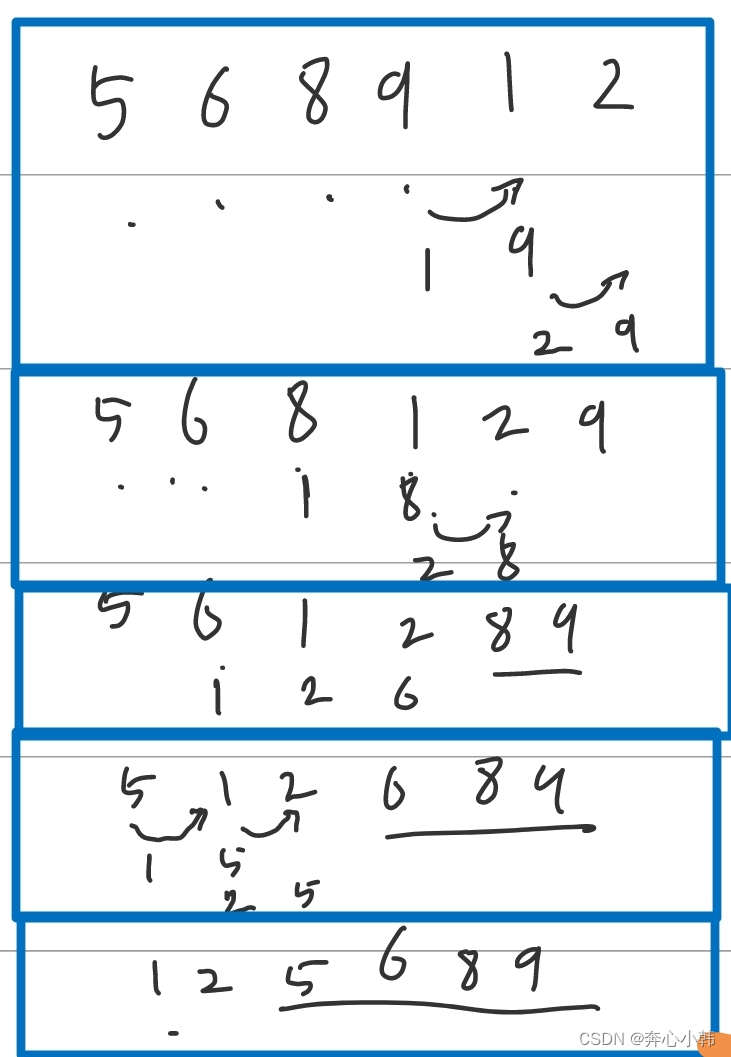 每个框框表示一趟的比较,从头,两两比较。后面我设置了flag验证是否还需要再跑趟次了,避免做无用功,如果有序了,则不需要比较
每个框框表示一趟的比较,从头,两两比较。后面我设置了flag验证是否还需要再跑趟次了,避免做无用功,如果有序了,则不需要比较
空间复杂度O(1)
时间复杂度O()
稳定性:两两交换,很稳定。
1.2代码:
#include <stdio.h>
void BubbleSort(int *a,int n)
{int i,j,flag;for(i=0;i<n-1;i++)//比较趟数,每趟都从头到尾(n-1-i)进行比较遍历,给一个数冒到后面,冒完的,下一轮就不参与比较了 {flag=1;//避免做无用功,有序的话就不用再接着比较了 for(j=0;j<n-1-i;j++){int temp=0;if(a[j]>a[j+1])//要求递增 {temp=a[j+1];a[j+1]=a[j];a[j]=temp;flag=0;}}if(flag==1)//如果没有交换,则不要调整了,直接退出循环即可。 break;}}
void PrintSort(int *a,int n)
{int i;for(i=0;i<n;i++){printf("%d ",a[i]);}printf("\n");
}
int main()
{int a[6]={5,6,8,9,1,2};BubbleSort(a,6);PrintSort(a,6);return 0;} 二、快速排序
1.1简介:
快速排序类似于前序遍历二叉树,每次选第一个元素作为基准元素,每进行一次快排,找到其基准元素位置后,从该位置左右划分成两部分,左边比基准小,右边比基准大。随后进入左边进行快排,左边都结束了,再去右边。是个递归操作。
快排的时候,选一个基准元素,定左右两个low和high标记量,low标记的位置都应该比基准小于等于,high标记的都应该大于等于。先是标记处非空数据(逻辑上给开始基准元素处变为空。存到一个pivot基准变量中)的位置进行移动判断,往中间移动。如果high处大于等于基准,则--hgh,如果不满足,则给该处值赋值给low处,即a[low]=a[high]。这样high处变为空了,开始从low处判断.

时间复杂度:O()
空间复杂度:树的深度
稳定性:不稳定,一次移动好多数据
递归深度:树的高度
递归次数:树的总结点数
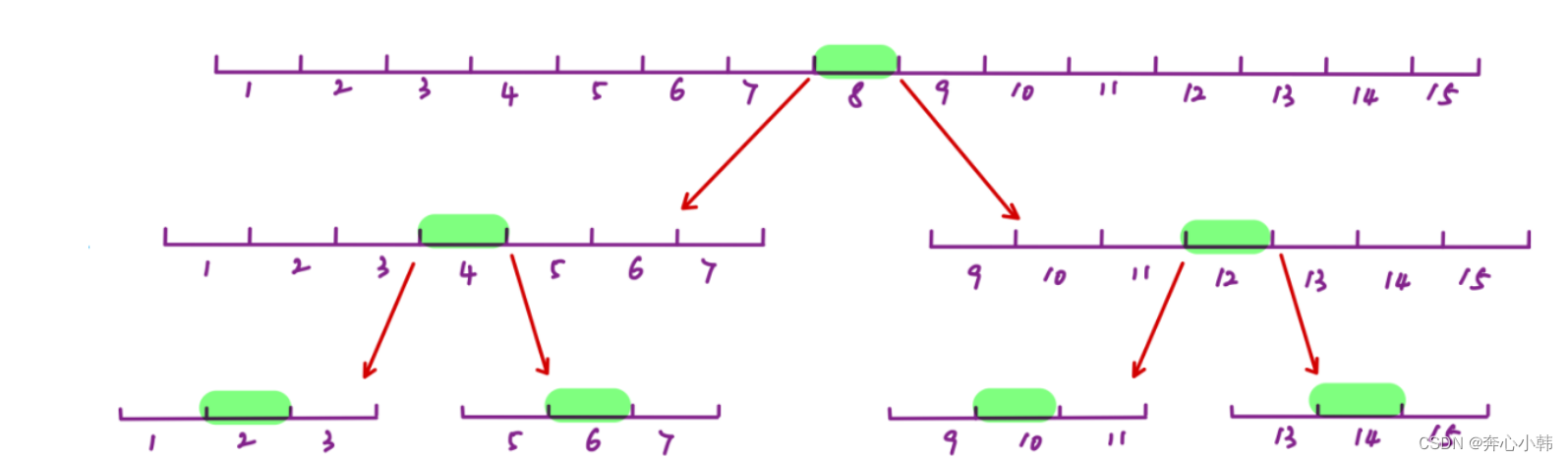
n个数据,快速排序至少比较多少次?正好平分,次数最少。
如15个数据,第一次有一个基准元素,分成左右两块长度为7的,此时比较2*7=14,;两个7随后又分成两个长度为3的,四个3最后分成左右长度为1的。因此为2*7+2*2*3+4*2=14+12+8=34
1.2代码:
#include <stdio.h>
void PrintSort(int *a,int n)
{int i;for(i=0;i<n;i++){printf("%d ",a[i]);}printf("\n");
}
//快速排序
//一次快排
int Partition(int *a,int low,int high)
{int pivot =a[low];//定义基准元素变量 while(low<high)//进入比较 {while(low<high&&a[high]>=pivot) --high; //最开始标记处为非空开始移动,因此先判断右边high情况,应该high标记处比基准大于等于,满足,往中间移动--。 a[low]=a[high];//不满足high标记处大于等于基准元素,则给该high处值赋值给low标记处while(low<high&&a[low]<=pivot) ++low;a[high]=a[low];//不满足low标记处小于等于基准元素,则给该low处值赋值给high标记处}a[low]=pivot;//当low和high相等时,找到基准元素位置,给该处赋值 return low; //返回基准元素下标
}
void QuickSort(int *a,int low,int high)
{ //类似于前序遍历,一个二叉树。 if(low<high)//递归跳出条件 {int pivot =Partition(a,low,high);//根 QuickSort(a,low,pivot-1); //左 QuickSort(a,pivot+1,high); //右 }}int main()
{int a[6]={5,6,8,9,1,2};//BubbleSort(a,6);QuickSort(a,0,5); PrintSort(a,6);return 0;} 相关文章:
21-数据结构-内部排序-交换排序
简介:主要根据两个数据进行比较从而交换彼此位置,以此类推,交换完全部。主要有冒泡和快速排序两种。 目录 一、冒泡排序 1.1简介: 1.2代码: 二、快速排序 1.1简介: 1.2代码: 一、冒泡排序…...
5-k8s-探针介绍
文章目录 一、探针介绍二、探针类型三、探针定义方式四、探针实例五、启动探针测试六、存活探针测试七、就绪探针测试 一、探针介绍 概念 在 Kubernetes 中 Pod 是最小的计算单元,而一个 Pod 又由多个容器组成,相当于每个容器就是一个应用,应…...
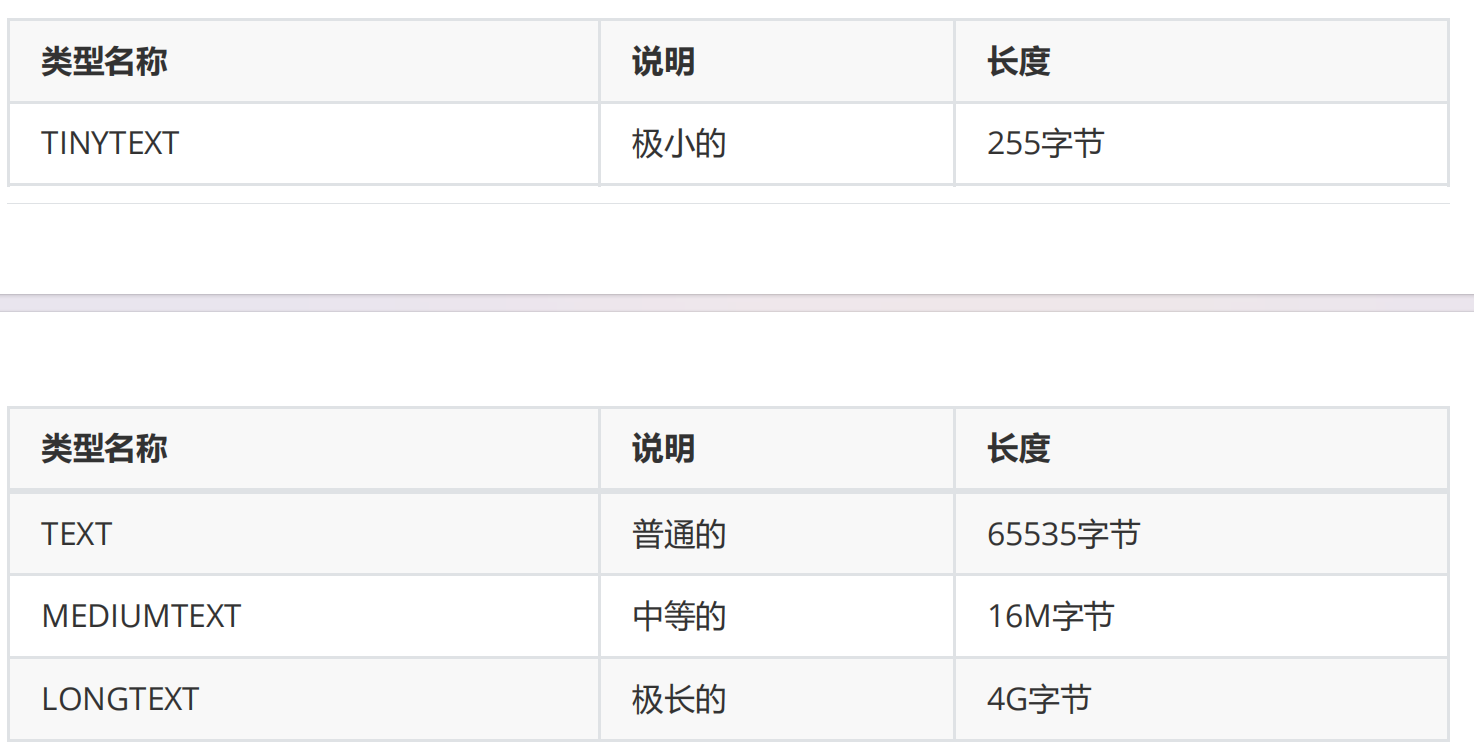
【网络安全 --- MySQL数据库】网络安全MySQL数据库应该掌握的知识,还不收藏开始学习。
四,MySQL 4.1 mysql安装 #centos7默认安装的是MariaDB-5.5.68或者65, #查看版本的指令:[rootweb01 bbs]# rpm -qa| grep mariadb #安装mariadb的最新版,只是更新了软件版本,不会删除之前原有的数据。 #修改yum源的配…...

【MyBatis系列】- 什么是MyBatis
【MyBatis系列】- 什么是MyBatis 文章目录 【MyBatis系列】- 什么是MyBatis一、学习MyBatis知识必备1.1 学习环境准备1.2 学习前掌握知识二、什么是MyBatis三、持久层是什么3.1 为什么需要持久化服务3.2 持久层四、Mybatis的作用五、MyBatis的优点六、参考文档一、学习MyBatis知…...

【Linux】Ubuntu美化bash【教程】
【Linux】Ubuntu美化bash【教程】 文章目录 【Linux】Ubuntu美化bash【教程】1. 查看当前环境中是否有bash2. 安装Synth-Shell3. 配置Synth-Shell4. 取消greeterReference 1. 查看当前环境中是否有bash 查看当前使用的bash echo $SHELL如下所示 sjhsjhR9000X:~$ echo $SHELL…...

微信小程序仿苹果负一屏由弱到强的高斯模糊
进入下面小程序可以体验效果,然后进入更多。查看模糊效果 一、创建小程序组件 二、代码 wxml: <view class"topBar-15"></view> <view class"topBar-14"></view> <view class"topBar-13"></view&…...

js中的new方法
new方法的作用:创建一个实例对象,并继承原对象的属性和方法; new对象内部操作: 1,创建一个新对象,将新对象的proto属性指向原对象的prototype属性; 2,构造函数执行环境中的this指向…...

机器学习-无监督算法之降维
降维:将训练数据中的样本从高维空间转换到低维空间,降维是对原始数据线性变换实现的。为什么要降维?高维计算难,泛化能力差,防止维数灾难优点:减少冗余特征,方便数据可视化,减少内存…...
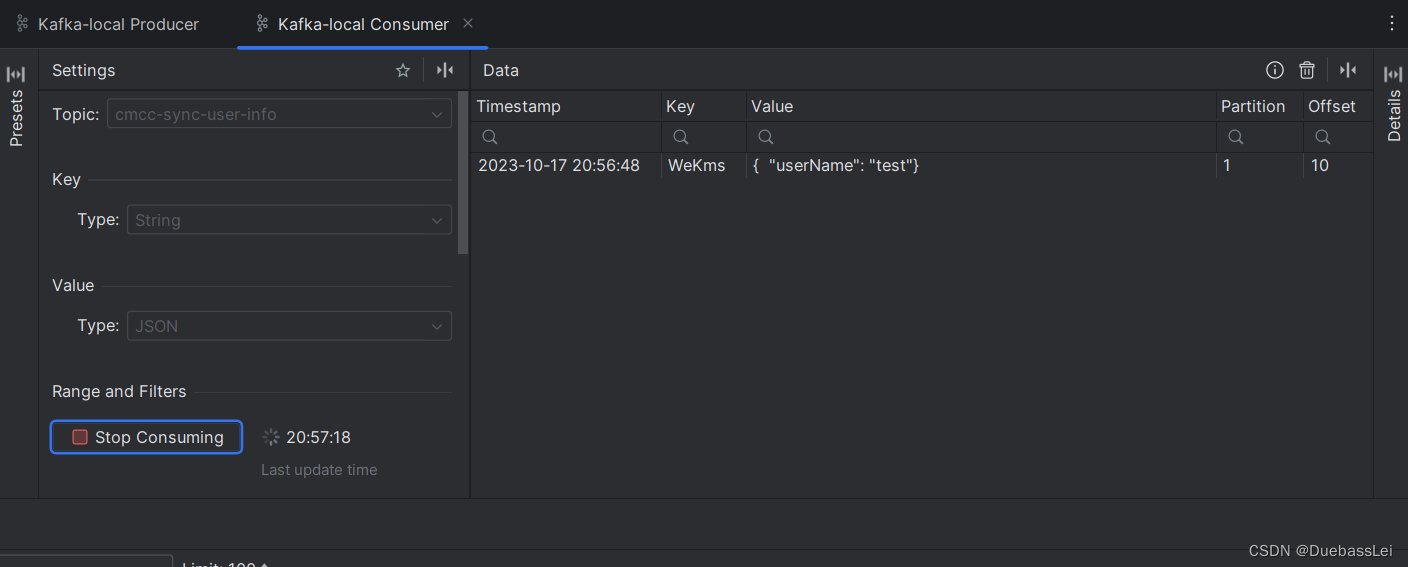
ubuntu20.04下Kafka安装部署及基础使用
Ubuntu安装kafka基础使用 kafka 安装环境基础安装下载kafka解压文件修改配置文件启动kafka创建主题查看主题发送消息接收消息 工具测试kafka Assistant 工具连接测试基础连接连接成功查看topic查看消息查看分区查看消费组 Idea 工具测试基础信息配置信息当前消费组发送消息消费…...

汉得欧洲x甄知科技 | 携手共拓全球化布局,助力出海中企数智化发展
HAND Europe 荣幸获得华为云颁发的 GrowCloud 合作伙伴奖项,进一步巩固了其在企业数字化领域的重要地位。于 2023 年 10 月 5 日,HAND Europe 参加了华为云荷比卢峰会,并因其在全球拓展方面的杰出贡献而荣获 GrowCloud 合作伙伴奖项的认可。 …...

【Javascript保姆级教程】显示类型转换和隐式类型转换
文章目录 前言一、显式类型转换1.1 字符串转换1.2 数字转换1.3 布尔值转换 二、隐式类型转换2.1 数字与字符串相加2.2 布尔值与数字相乘 总结 前言 JavaScript是一种灵活的动态类型语言,这意味着变量的数据类型可以在运行时自动转换,或者通过显式类型转…...

C++算法前缀和的应用:分割数组的最大值的原理、源码及测试用例
分割数组的最大值 相关知识点 C算法:前缀和、前缀乘积、前缀异或的原理、源码及测试用例:付视频课程 二分 过些天整理基础知识 题目 给定一个非负整数数组 nums 和一个整数 m ,你需要将这个数组分成 m 个非空的连续子数组。 设计一个算法…...
gitlab自编译 源码下载
网上都是怎么用 gitlab,但是实际开发中有需要针对 gitlab 进行二次编译自定义实现功能的想法。 搜索了网上的资料以及在官网的查找,查到了如下 gitlab 使用 ruby 开发。 gitlab 下载包 gitlab/gitlab-ce - Packages packages.gitlab.com gitlab/gitl…...
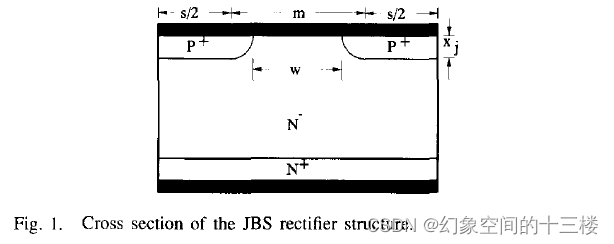
SBD(Schottky Barrier Diode)与JBS(Junction Barrier Schottky)
SBD和JBS二极管都是功率二极管,具有单向导电性,在电路中主要用于整流、箝位、续流等应用。两者的主要区别在于结构和性能。 结构 SBD是肖特基二极管的简称,其结构由一个金属和一个半导体形成的金属-半导体结构成。 JBS是结势垒肖特基二极…...
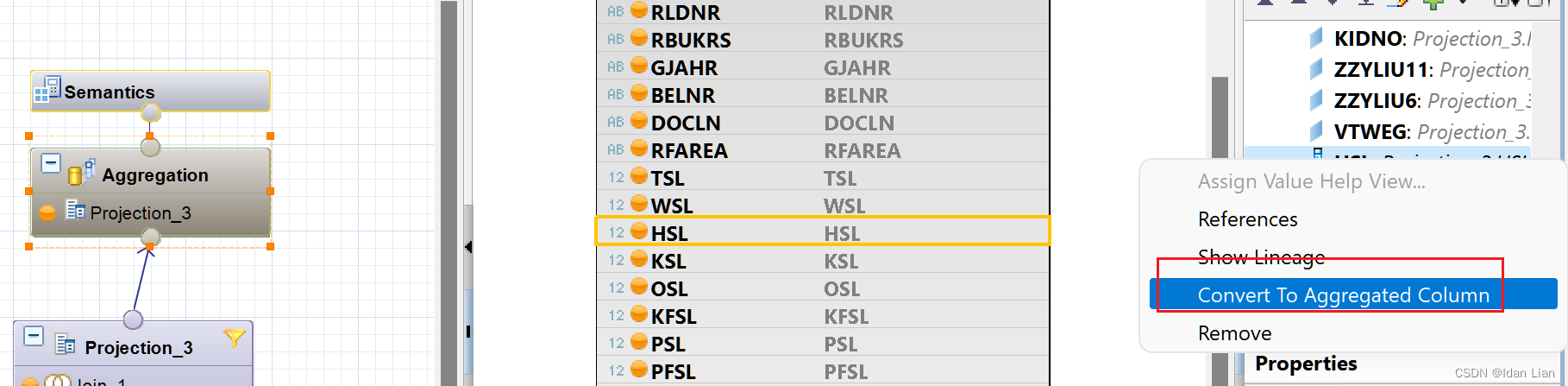
HANA:计算视图-图形化Aggregation组件-踩坑小记(注意事项)
今天遇到在做HANA视图开发的时候,遇到一个事,一直以为是个BUG,可把我气坏了,具体逻辑是这样的,是勇图形化处理的,ACDOCA innerjoin 一个时间维度表,就这么简单,完全按照ACDOCA的主键…...
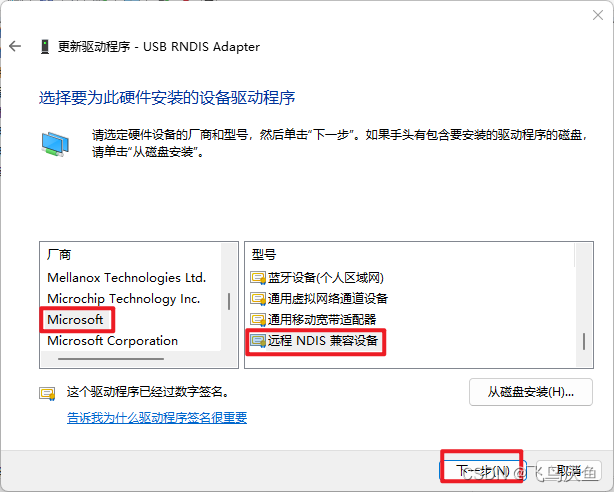
【milkv】更新rndis驱动
问题 由于windows升级到了11,导致rndis驱动无法识别到。 解决 打开设备管理器,查看网络适配器,没有更新会显示黄色的图标。 右击选择更新驱动...

基于混沌博弈优化的BP神经网络(分类应用) - 附代码
基于混沌博弈优化的BP神经网络(分类应用) - 附代码 文章目录 基于混沌博弈优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.混沌博弈优化BP神经网络3.1 BP神经网络参数设置3.2 混沌博弈算法应用 4.测试结果…...
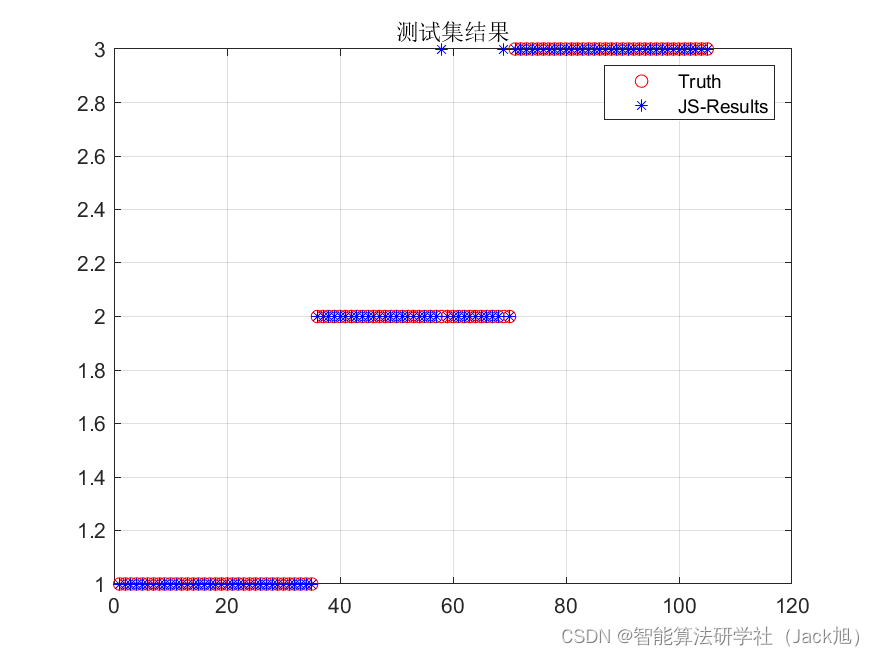
基于人工水母优化的BP神经网络(分类应用) - 附代码
基于人工水母优化的BP神经网络(分类应用) - 附代码 文章目录 基于人工水母优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.人工水母优化BP神经网络3.1 BP神经网络参数设置3.2 人工水母算法应用 4.测试结果…...

【C++】哈希学习
哈希学习 unordered系列关联式容器哈希结构除留余数法哈希冲突闭散列线性探测二次探测 负载因子开散列开散列增容 闭散列 VS 开散列字符串哈希算法 线性探测 & 二次探测实现拉链法实现 unordered系列关联式容器 unordered系列关联式容器是从C11开始,STL提供的。…...
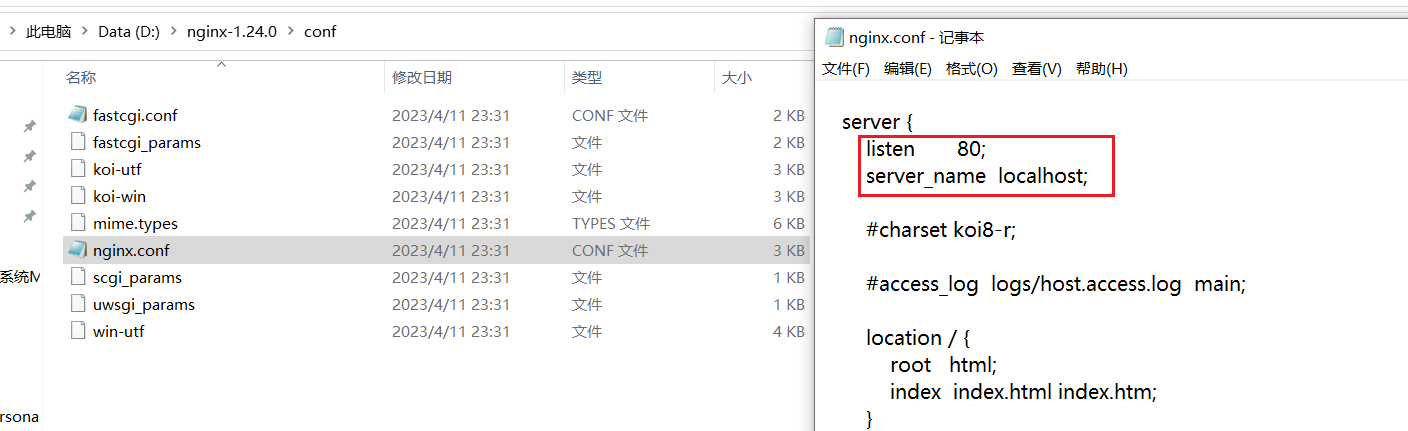
Nginx的安装——window环境
1、下载Nginx 在官网下载稳定版本: http://nginx.org/en/download.html 以nginx/Windows-1.24.0为例,直接下载 nginx-1.24.0.zip。 下载后解压,解压后如下: 2、启动nginx 在window环境下启动nginx的方法有以下两种: …...

UMA Unity角色系统深度解析:运行时人体编译器架构与跨平台实践
1. 为什么UMA不是“装上就能用”的Avatar系统——从三个典型失败案例说起我第一次在项目里引入Unity Multipurpose Avatar(UMA)时,信心满满地拖进Package Manager,点完Import,打开Demo场景,结果角色模型直接…...

掌握Linux系统Realtek RTL8125 2.5GbE网卡驱动安装与性能优化的5个实战技巧
掌握Linux系统Realtek RTL8125 2.5GbE网卡驱动安装与性能优化的5个实战技巧 【免费下载链接】realtek-r8125-dkms A DKMS package for easy use of Realtek r8125 driver, which supports 2.5 GbE. 项目地址: https://gitcode.com/gh_mirrors/re/realtek-r8125-dkms 在L…...

从一次失败的App上线,看我们如何用PDCA循环在3个月内实现用户留存翻倍
从一次失败的App上线,看我们如何用PDCA循环在3个月内实现用户留存翻倍 去年夏天,我们的团队经历了一次刻骨铭心的产品滑铁卢——一款投入半年研发的社交类App在上线首周就遭遇了用户留存率暴跌至8%的危机。这个数字远低于行业平均25%的水平线,…...

Git使用问题汇总
参考资料 Git教程-廖雪峰的官方网站 Pro git,有简体中文翻译 下载指定版本号 git clone https://github.com/xx.git -b x.x.x更新到最新 git pull origin master当使用git clone --recursive下载中断时,使用下面的命令可以继续 git submodule update --init --recursive…...

告别claude code封号烦恼使用taotoken稳定密钥与聚合接口的配置指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 告别Claude Code封号烦恼使用Taotoken稳定密钥与聚合接口的配置指南 对于依赖Claude Code进行编程辅助的开发者而言,直…...

如何免费打造终极跨平台音乐播放器:一站式解决你的所有音乐需求
如何免费打造终极跨平台音乐播放器:一站式解决你的所有音乐需求 【免费下载链接】VutronMusic 高颜值的第三方网易云播放器;支持流媒体音乐,如navidrome、jellyfin、emby;支持本地音乐播放、离线歌单、逐字歌词、桌面歌词、Touch …...

Ladybug终极指南:专业气象数据分析与可视化工具
Ladybug终极指南:专业气象数据分析与可视化工具 【免费下载链接】ladybug 🐞 Core ladybug library for weather data analysis and visualization 项目地址: https://gitcode.com/gh_mirrors/lad/ladybug Ladybug是一个功能强大的Python库&#…...
)
ElevenLabs缅甸文语音准确率仅68.3%?实测对比5种预处理方案,第4种提升至92.7%(附Jupyter验证代码)
更多请点击: https://kaifayun.com 第一章:ElevenLabs缅甸文语音准确率实测基准与问题定位 为系统评估 ElevenLabs 对缅甸文(Burmese, my-MM)语音合成的准确性,我们在统一硬件环境(Intel i7-11800H 32GB …...

Steam Economy Enhancer:终极Steam市场与库存自动化管理指南
Steam Economy Enhancer:终极Steam市场与库存自动化管理指南 【免费下载链接】Steam-Economy-Enhancer 中文版:Enhances the Steam Inventory and Steam Market. 项目地址: https://gitcode.com/gh_mirrors/ste/Steam-Economy-Enhancer Steam Eco…...

多模态模型中图像生成器使用的扩散模型的组件
多模态模型中图像生成器使用的扩散模型组件 多模态模型中的图像生成器,通常不是一个单独网络,而是一套 条件扩散生成系统。典型输入是文本、图像、mask、bbox、姿态、深度图、边缘图、语义图、视频帧或多模态 embedding,输出是目标图像。 最常…...