6.6 图的应用

思维导图:



6.6.1 最小生成树
### 6.6 图的应用
#### 主旨:图的概念可应用于现实生活中的许多问题,如网络构建、路径查询、任务排序等。
---
#### 6.6.1 最小生成树
**概念**:要在n个城市中建立通信联络网,则最少需要n-1条线路。目标是如何在最少的费用下建立这个通信网络。
- **关键概念**:最小代价生成树 (Minimum Cost Spanning Tree),简称最小生成树。
- **性质(MST的性质)**:在一个连通网中,总会存在一条边,它是连接两个顶点集合的最小权值边,并且这条边属于最小生成树。
---
**普里姆(Prim)算法**
- **思想**:从一个初始顶点开始,每次选择一个最小边连接未连接的顶点。
1. **算法步骤**:
- ①: 初始选择一个顶点放入集合U,初始化closedge,保存每个点到集合U的最短距离。
- ②: 重复n-1次,每次从closedge中选择最小边,加入结果集,并更新U和closedge。
2. **实现**:
- 初始化:从给定的顶点u开始,初始化closedge。
- 主循环:重复选择最小的边,并更新closedge直到所有的顶点都被加入。
3. **注意点**:
- 当存在多个相同权值的边时,选择任何一个都可以。
- 普里姆算法的时间复杂度是O(n^2),适合于稠密网。
---
#### 笔记总结:
- **重点**:最小生成树是建立最小费用网络的关键,其目标是选择边,使得总权值最小。
- **难点**:理解MST性质并应用于普里姆算法的实现。
- **易错点**:
1. 在更新closedge时,要确保只考虑未被选择的顶点。
2. 在存在多个最小权值边时,要能正确处理。
普里姆算法是求解最小生成树问题的一种有效方法,它从一个顶点开始,每次选择一个最小的边扩展,直到所有的顶点都被包括在内。
---
**6.1 最小生成树的构建方法**
**1. 普里姆算法 (Prim's Algorithm):**
- 初始状态: U={v}
- 过程:
1. 找到权值最小的边 (v, v₃) 作为生成树的第一条边。
2. 顶点 v₃ 并入集合 U 中。
3. 更新辅助数组的值。
4. 重复上述过程,直到 U=V。
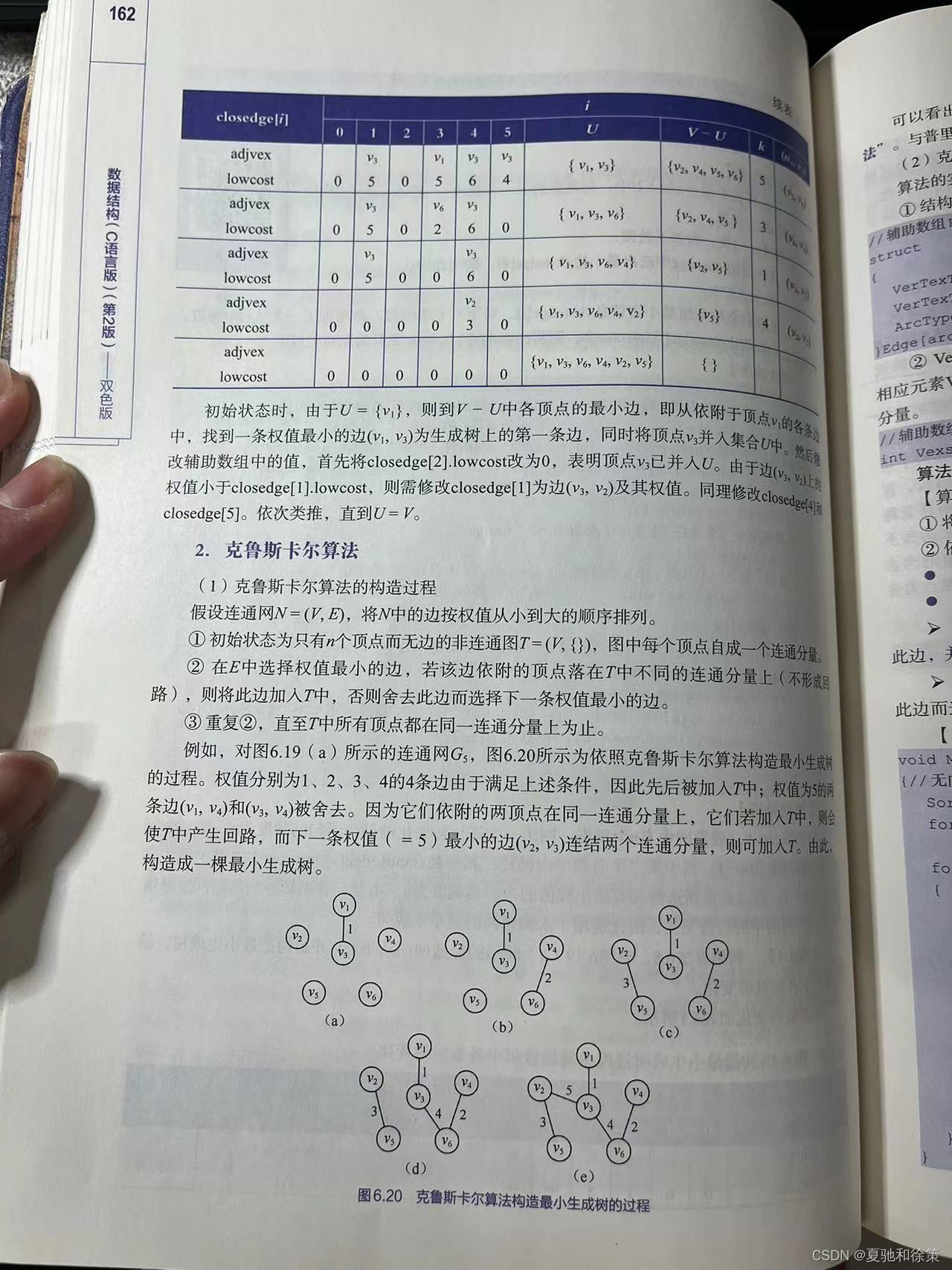
**2. 克鲁斯卡尔算法 (Kruskal's Algorithm):**
- 初始状态: 有 n 个顶点但无边的非连通图 T=(V,{})
- 过程:
1. 将 N 中的边按权值从小到大排序。
2. 选择权值最小的边。如果这条边的两个顶点在不同的连通分量上,加入 T 中;否则选择下一个最小权值的边。
3. 重复上述步骤,直到 T 中所有的顶点都在同一个连通分量上。
**克鲁斯卡尔算法的实现:**
- 使用结构体数组 Edge 来存储边的信息。
- 使用辅助数组 Vexset 来标识各个顶点所属的连通分量。
**算法描述:**
1. 对数组 Edge 中的元素按权值进行排序。
2. 查看数组 Edge 中的边,并对每条边执行以下操作:
1. 从已排序的数组中选择一条边。
2. 在 Vexset 中查找该边两端的顶点所在的连通分量,并进行比较。
**算法分析:**
- 克鲁斯卡尔算法适合稀疏网的最小生成树构建。
- 克鲁斯卡尔算法的时间复杂度与网中的边数有关。
---
我的理解:
让我们尝试使用图像和比喻来解释最小生成树和普利姆算法。
### 最小生成树
**比喻**:想象一个岛屿上有若干个村庄,这些村庄之间要铺设道路使得所有村庄都相互连通。但由于资金有限,我们希望用最少的路程来实现这一目标。
在这张图中,红色的圈代表村庄,线代表道路。这些道路形成了一个最小生成树,使得所有村庄都连通,且总的路程最短。
### 普利姆算法
**比喻**:你正在为村庄铺设道路。你选择一个村庄作为起点,并查看与它相连的所有道路。你选择最短的道路并铺设它,然后再选择下一个与已铺设道路相连的最短道路,依此类推,直到所有村庄都与至少一条道路相连。
**图像描述**:
在这张图中,我们首先选择左上角的村庄。虚线代表考虑铺设的道路,而实线代表已经铺设的道路。按照普利姆算法,我们首先选择左上和右上两个村庄之间的道路(因为它是最短的),
 6.6.2最短路径
6.6.2最短路径
**6.6.2 最短路径**
**定义**:在图结构中,最短路径问题是为了找出两个节点之间的最优路径,这可以是最短的、最快的、成本最少的等等。
**示例**:交通咨询系统可以采用图的结构来表示实际的交通网。其中,顶点代表城市,而边代表城市间的交通联系。例如,如果一个旅客想从A城市到达B城市并选择中转次数最少的路线,则可以通过广度优先搜索找到从A到B所含边数最少的路径。
- 带权图:为了在图上表示例如距离、所需时间或交通费用等信息,可以对边赋予权值。此时,路径的长度度量不再是路径上的边的数量,而是路径上的边的权值之和。
- 有向图:考虑到例如上山和下山的汽车或顺水和逆水的轮船所花费的时间或费用不同,交通网通常用带权有向网表示。在这样的图中,路径上的第一个顶点称为源点,而最后一个称为终点。
本节主要讨论两种常见的最短路径问题:
1. **单源点的最短路径问题**:从指定的源点到图中的其他所有顶点的最短路径。
- **Dijkstra算法**:由Dijkstra提出,它可以按路径长度递增的次序生成最短路径。
- **算法过程**:
1. 将图的顶点分为两组:
- S: 已经找到最短路径的终点集合(开始时只包含源点v₀)。
- V-S: 尚未找到最短路径的顶点集合(开始时为V-{v₀})。
2. 算法将逐渐将V-S中的顶点按与v₀之间的最短路径长度递增的次序加入S集合。在此过程中,始终保持从v₀到S中各顶点的路径长度不超过到V-S中各顶点的路径长度。
2. **所有顶点对的最短路径问题**:求出图中每对顶点之间的最短路径。
**总结**:最短路径问题是图论中的一个经典问题,对于实际应用如交通咨询系统、网络路由等都有很大的实用价值。不同的算法适用于不同的场景和需求,如Dijkstra算法适用于求解单源点的最短路径问题。
我的理解:
---
**1. 最短路径问题的比喻:**
**比喻**:想象一个大城市的地铁系统。你现在处于A站,想要到达B站。这个城市的地铁系统就像是一个大型图,每个地铁站就是图中的一个顶点,每条地铁线路则是图中的一条边。
在这个城市中,有些地铁线路非常快,有些则非常慢。你的任务是找到从A站到B站的最短路径,不仅仅是经过的站数最少的路径,还可能是时间最短的、或成本最低的路径。
---
**2. 带权图:**
**比喻**:回到地铁系统的例子,不同的地铁线可能需要不同的时间。例如,从A站到C站可能需要10分钟,而从A站到D站可能需要20分钟。这个时间就是"权值"。
---
**3. 单源点的最短路径问题:**
**比喻**:你在一个大商场的入口处(源点),想要找到到达所有其他店铺(顶点)的最快路径。
**Dijkstra算法**就像是一个智能助手,它先告诉你到达最近的店铺的最快路径,然后是第二近的,以此类推,直到你知道到达所有店铺的最快路径。
---
**4. 所有顶点对的最短路径问题:**
**比喻**:想象你正在为一个送货公司工作,公司的任务是将包裹从一个城市送到另一个城市。你需要为每一对城市之间找到最短的送货路径,以节省时间和成本。
这就像拥有一个全城的地图,而不仅仅是从一个特定地点到其他地点的地图。你的目标是找到每对城市之间的最优路径。
---
总的来说,最短路径问题就像是在复杂的网络中找到最优的路径,这个网络可以是地铁系统、城市、商场或任何其他实际生活中的场景。而Dijkstra算法等工具就像是帮助你在这些网络中导航的智能助手。

### 图中的最短路径问题:
1. **假设与证明**:
- 假设集合S为已求得最短路径的终点。
- 下一条最短路径的终点为x,路径要么是边(v.x),要么经过S中的顶点后到达x。
- 用反证法证明:如果路径上的顶点不在S中,则存在更短的不在S中的路径,这与算法是递增求最短路径的方式矛盾。
2. **示例**:图6.22为带权有向图G₆,表6.2显示从v₀到其它顶点的最短路径。
3. **迪杰斯特拉算法**:
- **实现方式**:
- 使用带权的邻接矩阵arcs表示有向网G,G.arcs[i][j]表示弧<vᵢ,vⱼ>上的权值。
- 辅助数据结构:
1. 数组S[i]:标记从源点v₀到终点vᵢ的最短路径是否已确定。
2. 数组Path[i]:记录从v₀到vᵢ的最短路径上vᵢ的前驱顶点序号。
3. 数组D[i]:记录从v₀到vᵢ的当前最短路径长度。
- **算法步骤**:
1. 初始化:
- 将源点v₀加入S,设置S[v₀]=true。
- 设置源点到各点的最短路径长度D[i]。
- 设置前驱节点Path[i]。
2. 主循环:
- 循环n-1次,选择最短路径的终点v,加入S。
- 更新从v₀到集合V-S的所有顶点的最短路径长度。
- 若找到更短的路径,更新前驱节点和路径长度。
- **算法描述**:
- 函数ShortestPath DIJ(AMGraph G,int vo)使用Dijkstra算法计算从v₀到其它顶点的最短路径。
- 初始化部分:包括设置源点、初始化最短路径长度和前驱节点。
- 主循环:寻找最短路径并更新相关数据。
---
### 迪杰斯特拉(Dijkstra)算法
**目的**:求解从给定源点到所有其他顶点的最短路径。
**主要思想**:
1. 初始化:选择源点v₀,设置距离数组D和路径数组Path。
2. 重复n-1次:每次找到一个离v₀最近的未访问过的顶点,并更新其邻接点的距离。
3. 结果:D数组记录了从v₀到所有其他顶点的最短距离,Path数组记录了最短路径信息。
**时间复杂度**:O(n²)
**注意**:即使你只想求解从源点到某一个特定顶点的最短路径,该问题仍然需要与求解源点到所有其他顶点的最短路径一样的时间。
---
### 弗洛伊德(Floyd)算法
**目的**:求解图中任意两点之间的最短路径。
**主要思想**:
1. 初始化:用带权的邻接矩阵arcs表示有向网G,设置距离矩阵D和路径矩阵Path。
2. 通过引入中间顶点的方法,对所有顶点对的路径进行n次比较和更新。
3. 结果:D矩阵记录了所有顶点对的最短距离,Path矩阵记录了最短路径信息。
**时间复杂度**:O(n³)
**注意**:尽管有两种方法来求解每一对顶点之间的最短路径(一是多次调用迪杰斯特拉算法,二是使用弗洛伊德算法),但弗洛伊德算法在形式上较为简洁。
---
基于您提供的文本,以下是该段内容的整理:
---
**弗洛伊德算法及其应用**
**定义**:
图中所有顶点对之间的最短路径长度可以表示为一个n阶方阵D。随着算法的执行,这个方阵的值会不断变化,构成一个n阶方阵序列,可以表示为:D(-1), D(0), D(1), …, D(n-1)。
公式:
1. D[i][j] = G.arcs[i][j]
2. D[i][j] = min {D[i][k] + D[k][j]} (其中,0≤k≤n-1)
含义:
- D[i][j] 是从顶点 i 到顶点 j,中间顶点序号不大于 k 的最短路径的长度。
- D"_[JU] 是从顶点 v 到顶点 v 的最短路径的长度。
**弗洛伊德算法**:
算法的时间复杂度是 O(n³)。算法描述如下:
void ShortestPath_Floyd(AMGraph G) {// 初始化路径和距离for(int i = 0; i < G.vexnum; ++i)for(int j = 0; j < G.vexnum; ++j) {D[i][j] = G.arcs[i][j];if(D[i][j] < MaxInt && i != j)Path[i][j] = i; // 如果 i 和 j 之间有弧,则将 j 的前驱置为 ielsePath[i][j] = -1; // 如果 i 和 j 之间无弧,则将 i 的前驱置为 -1}// 更新路径和距离for(int k = 0; k < G.vexnum; ++k)for(int i = 0; i < G.vexnum; ++i)for(int j = 0; j < G.vexnum; ++j)if(D[i][k] + D[k][j] < D[i][j]) {D[i][j] = D[i][k] + D[k][j];Path[i][j] = Path[k][j];}
}**示例**:
图6.24表示带权有向图G,其邻接矩阵在图6.25中给出。对此图应用弗洛伊德算法得到的各顶点对之间的最短路径及其路径长度的变化在表6.5中显示。
**如何从表6.5中读取两个顶点之间的最短路径**:
以Path³)为例,从D³)知,顶点1到顶点2的最短路径长度为8,最短路径中顶点2的前驱是顶点3;再查看Path[1][3]得知,顶点3的前驱是顶点1。所以,从顶点1到顶点2的最短路径为 {<1,3>,<3,2>}。
---

6.6.3 拓扑排序
**6.6.3 拓扑排序**
---
**1. AOV-网与有向无环图**
- **定义**:无环的有向图称作有向无环图(Directed Acyclic Graph),简称DAG图。
- **应用**:DAG图是描述一项工程或系统进行过程的有效工具,如计划、施工、生产流程和程序流。
- **活动与约束**:工程通常分为若干子工程(称作活动),子工程间存在优先关系。例如,某些子工程开始前需要另一些子工程完成。
*示例*:软件专业学生需要学习一系列课程,其中部分课程要在先修课程后学习。
如:课程之间的关系可以用有向图表示。
- **AOV-网定义**:有向图中,顶点表示活动,有向弧表示活动间的优先关系称为AOV-网。若存在有向环,则表示存在逻辑错误(如工程中某活动以自己为先决条件,或程序中存在死循环)。
**2. 拓扑排序定义与过程**
- **定义**:拓扑排序是将AOV-网中的所有顶点排成线性序列,满足:如果从顶点v到顶点v'有路径,则v必定在v'之前。
- **拓扑排序步骤**:
1. 选择一个无前驱的顶点并输出。
2. 删除该顶点及所有以它为尾的弧。
3. 重复步骤1和2,直至所有顶点都输出。
4. 若输出的顶点数小于有向图中的顶点数,说明存在环。
*示例*:图6.27展示了一个有向图的拓扑排序过程,得到拓扑有序序列为 Vs,V₁,V₄,V₃,Vz,Vs。
**3. 拓扑排序的实现**
- **数据结构**:
1. **邻接表**:用于存储有向图。
2. **一维数组indegree[]**:存放每个顶点的入度。无前驱的顶点入度为0。
- **算法**:
1. 初始化所有顶点的入度。
2. 找到入度为0的顶点,输出。
3. 删除该顶点及与其相关的弧,即将所有与该顶点相邻的顶点入度减1。
4. 重复步骤2和3,直到所有顶点都输出或不存在入度为0的顶点。
*注意*:在实际操作中,不需要真正删除顶点或弧,只需调整相关顶点的入度。
---
**总结**:拓扑排序是对有向无环图进行排序的方法,确保每个活动在其前驱活动之后。这对于任务调度、项目计划和课程规划等应用都是非常有用的。
我的理解:
我们可以使用“修建一座城堡”作为比喻来解释这一节的内容。
---
**修建一座城堡:拓扑排序的比喻**
想象你要修建一座宏伟的城堡。城堡不是一下子就修好的,你需要按照特定的步骤和顺序完成,例如先挖地基、然后建墙、接着建塔楼等等。这些步骤就像是你所学习的各个课程,某些步骤是其他步骤的前提。
1. **城堡的各个部分 = DAG图中的活动**
- 城墙、塔楼、大门、护城河等每个部分都是一个活动,有些部分需要在其他部分之前完成。例如,你不能在没有地基的情况下建墙。
2. **先决条件 = 活动间的优先关系**
- 你不能在护城河还没挖好的情况下建桥。同样地,你不能在地基还没打好的情况下建墙。这些都是先决条件或优先关系。
3. **拓扑排序 = 建筑计划**
- 当你开始建造城堡时,你需要一个清晰的计划,告诉你哪一部分应该首先建造,接下来是什么,直到整个城堡完成。拓扑排序就像是这个建筑计划,确保你不会因为顺序错误而陷入困境。
4. **找出无前驱的活动 = 选择可以立即开始的工作**
- 在整个建筑计划中,首先找到哪些部分是可以立即开始的(比如挖地基)。这就像找到一个没有先修课程要求的新课程。
5. **删除某活动及其连接 = 完成某部分工作并前进**
- 当你完成了某部分(比如地基),你就可以考虑下一步要做什么,并且确定你已经完成的工作不会再次干扰你。在拓扑排序中,这就是删除一个顶点及其相关的弧。
6. **环的存在 = 逻辑错误**
- 如果你发现在建筑计划中某个部分依赖于它自身或形成了一个循环依赖,那就意味着计划中有一个逻辑错误。这就像在DAG中发现了一个环。
---
所以,拓扑排序就像是修建城堡的步骤,确保每个部分都在正确的时间和顺序中建造,使整个城堡稳固且宏伟。
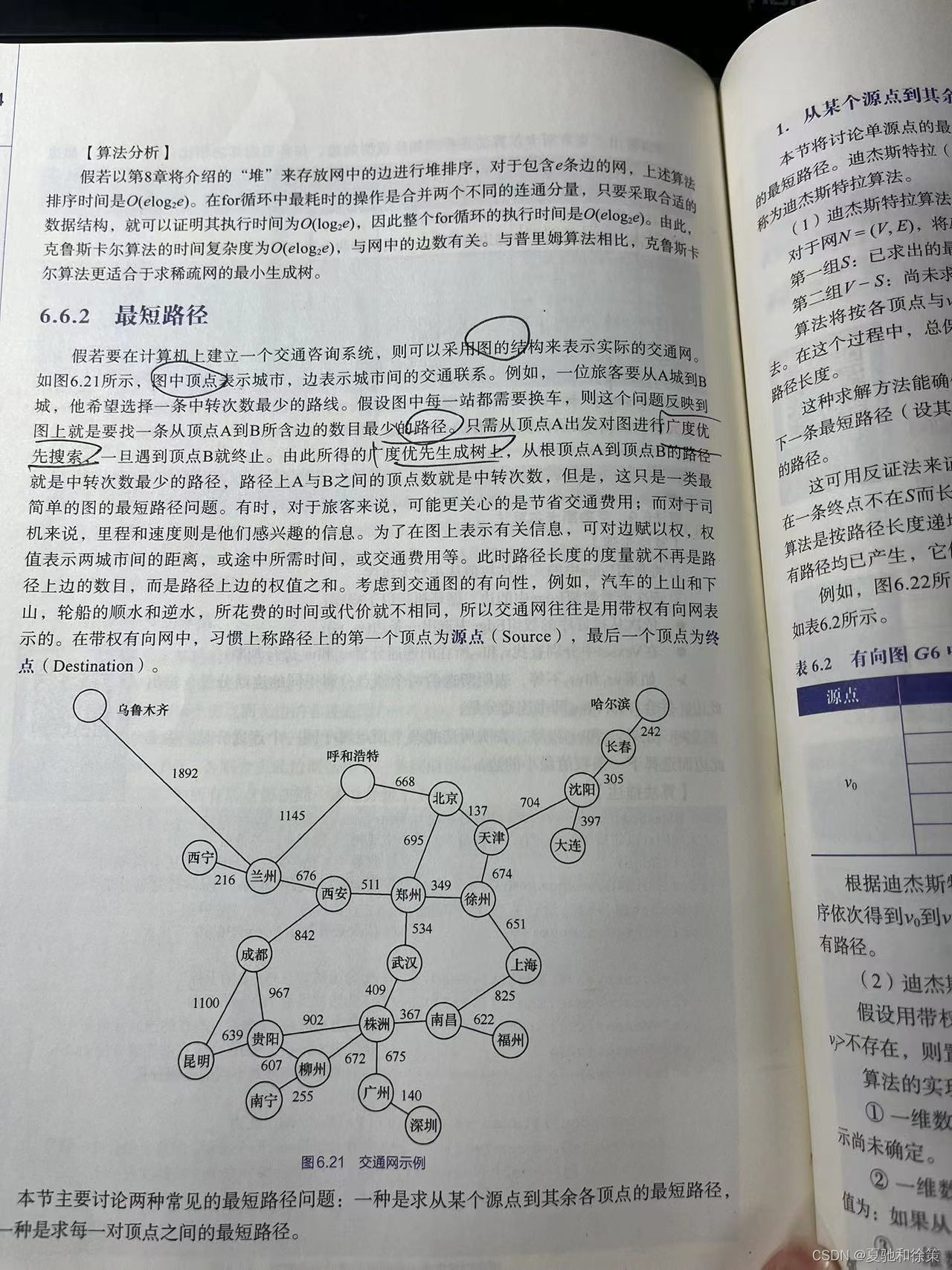 拓扑排序及算法**
拓扑排序及算法**
- **定义与工具**:
- **栈S**: 暂存所有入度为0的顶点。避免重复查找数组indegree[],提高效率。
- **一维数组topo[i]**: 记录拓扑序列的顶点序号。
- **算法6.12**: 拓扑排序算法描述。
- **算法步骤**:
1. 求出各顶点的入度并存入数组indegree[],使入度为0的顶点入栈。
2. 当栈不空时重复以下操作:
- 使栈顶顶点v出栈并保存在拓扑序列数组topo中;
- 对顶点v的每个邻接点v的入度减1,如果v的入度变为0,则使v入栈。
3. 如果输出顶点个数少于AOV-网的顶点个数,则网中存在有向环,无法进行拓扑排序,否则拓扑排序成功。
- **算法描述**:
1. 初始化一个空的栈S。
2. 求各顶点入度并存入数组indegree中。
3. 入度为0的顶点入栈。
4. 当栈非空时,重复以下操作:
- 栈顶顶点v出栈并保存在数组topo中;
- 遍历顶点v的所有邻接点,并对其入度减1;
- 如果邻接点入度减为0,则入栈。
5. 如果输出顶点个数不等于AOV-网的顶点个数,则返回错误;否则,返回成功。
- **算法分析**:
- 对于有n个顶点和e条边的有向图:
- 建立求各顶点入度的时间复杂度为O(e)。
- 建立零入度顶点栈的时间复杂度为O(n)。
- 在拓扑排序中,每个顶点进栈、出栈一次,入度减1的操作总共执行e次。总的时间复杂度为O(n+e)。
- **应用**:
- 该拓扑排序算法是求关键路径算法的基础。
---
6.6.4 关键路径
---
**2. 关键路径求解过程**
- **步骤概述:**
1. 对顶点排序并计算每个事件的最早发生时间 \( ve(i) \)。
2. 依据逆拓扑序列计算每个事件的最迟发生时间 \( vl(i) \)。
3. 计算每个活动 \( a \) 的最早开始时间 \( e(i) \)。
4. 计算每个活动 \( a \) 的最晚开始时间 \( l(i) \)。
5. 确定关键活动和关键路径。
- **计算详解:**
1. **计算最早发生时间**:
- \( Ve(0) = 0 \)
- \( ve(1) = max\{ve(0) + wa_1\} \)
- \( ve(2) = max\{ve(0) + wo_2\} \)
- ...
2. **计算最迟发生时间**:
- \( vl(8) = ve(8) \)
- \( vl(7) = min\{vl(8) - w_7s\} \)
- ...
3. **计算最早开始时间**:
- \( e(a_1) = ve(0) \)
- \( e(a_2) = ve(0) \)
- ...
4. **计算最晚开始时间**:
- \( l(a_1) = vl(8) - w_7s \)
- \( l(a_2) = vl(8) - w_6g \)
- ...
5. **确定关键活动和关键路径**:
- 通过比较每个活动的最早开始时间和最晚开始时间来确定关键活动。关键路径是由关键活动组成的路径,从源点到汇点。
- **实例分析:** 通过图6.28的AOE网来确定关键路径。
1. **关键路径结果:**
- 图6.28的AOE网有两条关键路径,如图6.29所示。
- **关键路径算法的实现:**
1. **前提**:关键路径算法是基于拓扑排序算法。
2. **数据结构**:
- 一维数组 \( ve[i] \) 表示事件 \( v_i \) 的最早发生时间。
- 一维数组 \( vl[i] \) 表示事件 \( v_i \) 的最迟发生时间。
- 一维数组 \( topo[i] \) 记录拓扑序列的顶点序号。
3. **算法步骤**:
1. 调用拓扑排序算法。
2. 初始化每个事件的最早发生时间为0。
3. 根据拓扑序列,计算每个事件的最早发生时间。
4. 初始化每个事件的最迟发生时间为汇点的最早发生时间。
5. 根据逆拓扑序列,计算每个事件的最迟发生时间。
---
【笔记】
**关键路径算法笔记**
1. **目标**: 判断某一活动是否为关键活动。
2. **步骤**:
- 调用拓扑排序算法。
- 使用拓扑次序求每个事件的最早发生时间。
- 使用逆拓扑次序求每个事件的最迟发生时间。
- 判断每一活动是否为关键活动。
3. **核心代码解析**:
- 初始化:对于每个事件的最早发生时间置初值为0。
- 使用拓扑次序更新每个事件的最早发生时间。
- 对于每个事件的最迟发生时间置初值为最后一个事件的最早发生时间。
- 使用逆拓扑次序更新每个事件的最迟发生时间。
- 判断活动的最早和最迟开始时间是否相等,相等则为关键活动,并输出。
4. **算法分析**:
- 时度为O(n+e),其中n是顶点数,e是边数。
5. **实际应用**:
- AOE网在估算工程完成时间上很有用。
- 活动时间的调整可能会影响关键路径,所以在调整时需要重新计算关键路径。
- 若有多条关键路径,提高一条关键路径上活动的进度不能保证整个工程的工期缩短。
**六度空间理论**:
1. **概念**: 六度空间理论提出,在人际关系网络中,任何两个人之间都可以通过五个或更少的中间人联系在一起。
2. **实验**:
- 由美国哥伦比亚大学社会学系的登肯·瓦兹(Duncan J.Watts)主持。
- 166个国家,6万多名志愿者参与。
- 志愿者选择目标并发送邮件给可能知道目标的亲友。
- 结果显示邮件平均通过5-7个人达到目标。
3. **结论**: 虽然该理论未得到严格证明,但多次实验验证了其合理性。
---
**六度空间理论的研究方法局限性**
1. **电子邮件研究的局限性**:
- **人群局限性**: 仅有部分人群使用电子邮件保持社交关系。
- **研究工程量大**: 需要跟踪和记录所有电子邮件的走向,需要大量的人力和时间。
- **依赖志愿者**: 验证过程与志愿者的积极性有关,可能会遗漏某些相识的人。
2. **现代通信方式**:
- 电话和短信是现代人主要的联系方式,其使用频率远高于电子邮件。
- 相对于电子邮件,电话和短信的通信更易于跟踪,因为都有运营商记录。
- 可以设定条件定义“认识”的关系,例如一年内电话或短信往返两次及以上。
- 由于通信数据保密,我们不能获取实际的通信数据,所以只能理论上分析。
3. **六度空间理论的图论模型**:
- 将人际关系网络图抽象成不带权值的无向图G。
- 在图G中,一个顶点代表一个人,一条边代表两个人之间的“认识”关系。
---
这部分笔记主要强调了研究六度空间理论时使用电子邮件的局限性,并提到了现代通信方式如何可能更好地验证这一理论。然后简要描述了将人际关系转化为图论模型的方式。











 总结:
总结:
**图的应用总结**
---
**重点**:
1. **表示与存储**:
- 邻接矩阵、邻接表、边数组等是常用的图的存储结构。
2. **遍历**:
- 深度优先搜索(DFS)和广度优先搜索(BFS)是两种基本的图遍历算法。
3. **最短路径**:
- Dijkstra算法和Floyd-Warshall算法常用于求解加权图的最短路径问题。
4. **最小生成树**:
- Prim算法和Kruskal算法用于求无向加权图的最小生成树。
5. **拓扑排序**:
- 用于有向无环图(DAG),可帮助确定任务执行的顺序。
6. **强连通分量**:
- Kosaraju和Tarjan算法用于找有向图的强连通分量。
7. **网络流**:
- Ford-Fulkerson和Edmonds-Karp算法用于求最大流。
---
**难点**:
1. **算法的理解与实现**:
- 例如Dijkstra的贪心思想,Floyd-Warshall的动态规划思想。
2. **复杂数据结构的应用**:
- 如优先队列在Dijkstra中,不相交集数据结构在Kruskal中。
3. **无向图与有向图**:
- 对于某些问题,如最小生成树,仅限于无向图。
4. **边界情况的处理**:
- 如带权图中的负权边。
---
**易错点**:
1. **未初始化**:
- 如在Dijkstra中,需要初始化源顶点的距离为0,其他顶点的距离为无穷大。
2. **循环条件忽视**:
- 在BFS和DFS中,可能未正确检查节点是否已访问。
3. **误解数据结构**:
- 错误地将邻接表用于需要邻接矩阵的场景,反之亦然。
4. **忽略负权边**:
- 使用Dijkstra算法时,负权边可能导致错误的结果。
5. **拓扑排序中的环**:
- 如果图中存在环,则无法进行拓扑排序,但容易忽略这点检查。
6. **空间与时间复杂度**:
- 选择不合适的算法或数据结构可能导致效率低下。
---

相关文章:
6.6 图的应用
思维导图: 6.6.1 最小生成树 ### 6.6 图的应用 #### 主旨:图的概念可应用于现实生活中的许多问题,如网络构建、路径查询、任务排序等。 --- #### 6.6.1 最小生成树 **概念**:要在n个城市中建立通信联络网,则最少需…...

100问GPT4与大语言模型的关系以及LLMs的重要性
你现在是一个AI专家,语言学家和教师,你目标是让我理解语言模型的概念,理解ChatGPT 跟语言模型之间的关系。你的工作是以一种易于理解的方式解释这些概念。这可能包括提供 例子,提出问题或将复杂的想法分解成更容易理解的小块。现在…...
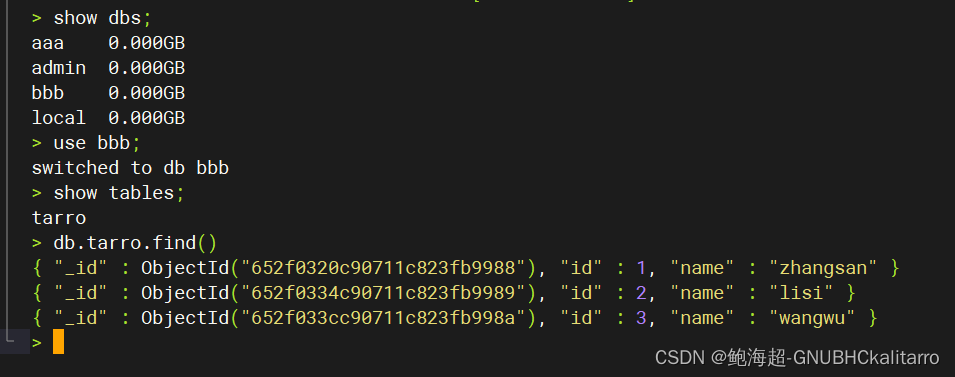
Linux:mongodb数据逻辑备份与恢复(3.4.5版本)
我在数据库aaa的里创建了一个名为tarro的集合,其中有三条数据 备份语法 mongodump –h server_ip –d database_name –o dbdirectory 恢复语法 mongorestore -d database_name --dirdbdirectory 备份 现在我要将aaa.tarro进行备份 mongodump --host 192.168.254…...
凉鞋的 Godot 笔记 109. 专题一 小结
109. 专题一 小结 在这一篇,我们来对第一个专题做一个小的总结。 到目前为止,大家应该能够感受到此教程的基调。 内容的难度非常简单,接近于零基础的程度,不过通过这些零基础内容所介绍的通识内容其实是笔者好多年的时间一点点…...
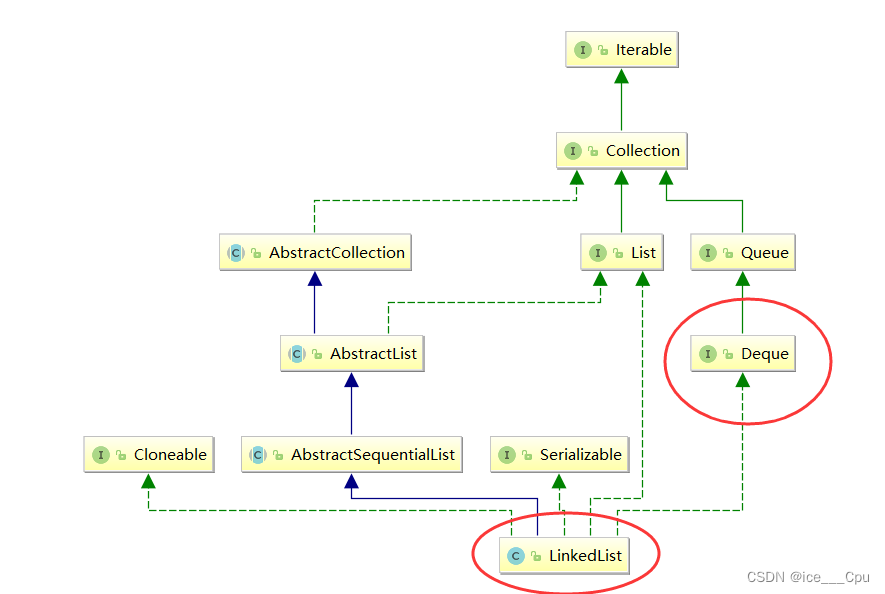
数据结构 - 4(栈和队列6000字详解)
一:栈 1.1 栈的概念 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原…...
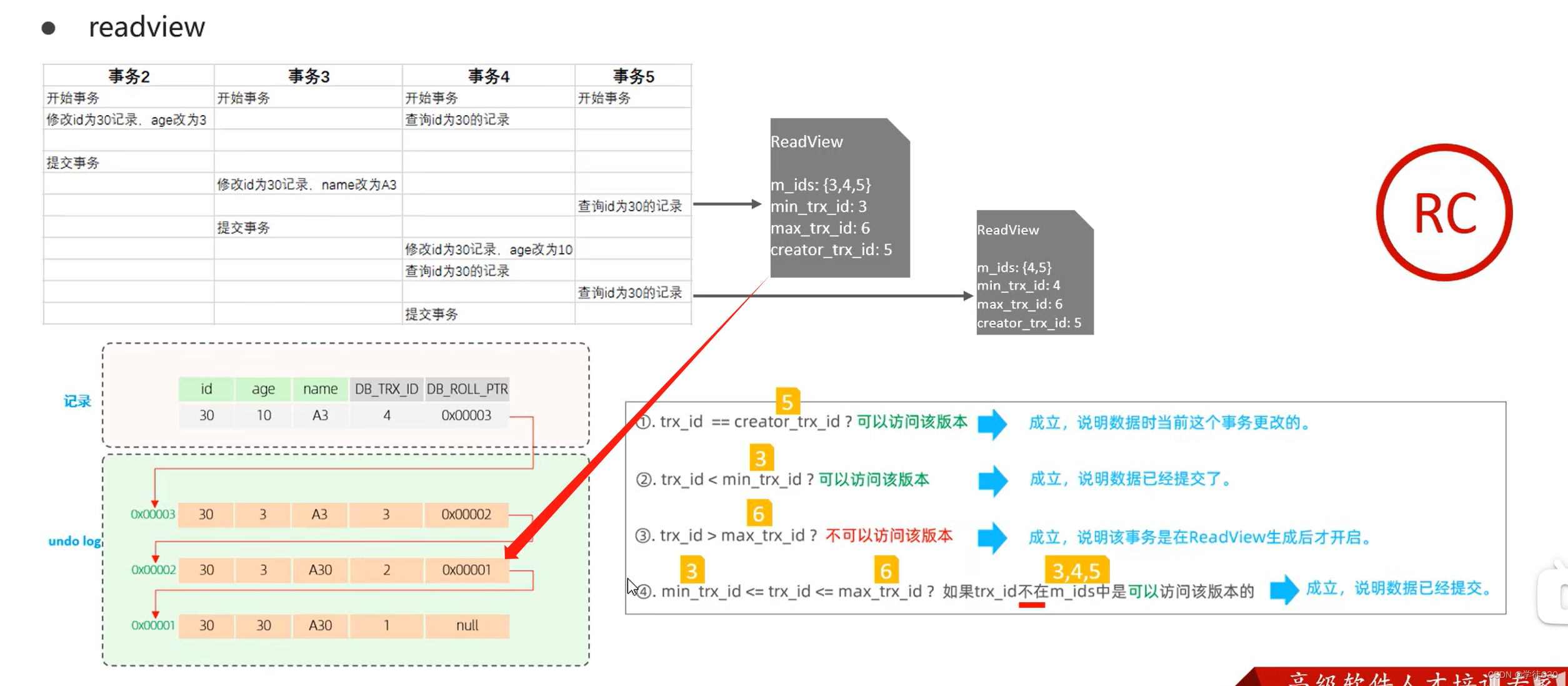
MySQL InnoDB引擎深入学习的一天(InnoDB架构 + 事务底层原理 + MVCC)
目录 逻辑存储引擎 架构 概述 内存架构 Buffer Pool Change Buffe Adaptive Hash Index Log Buffer 磁盘结构 System Tablespace File-Per-Table Tablespaces General Tablespaces Undo Tablespaces Temporary Tablespaces Doublewrite Buffer Files Redo Log 后台线程 事务原…...
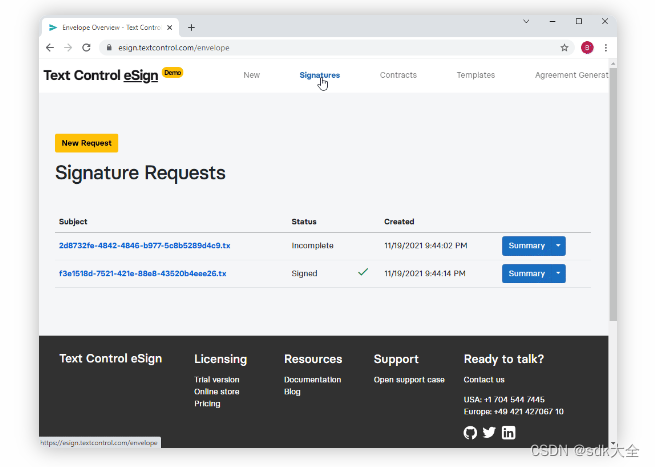
TX Text Control .NET Server for ASP.NET 32.0 Crack
TX Text Control .NET Server for ASP.NET 是VISUAL STUDIO 2022、ASP.NET CORE .NET 6 和 .NET 7 支持,将文档处理集成到 Web 应用程序中,为您的 ASP.NET Core、ASP.NET 和 Angular 应用程序添加强大的文档处理功能。 客户端用户界面 文档编辑器 将功能…...
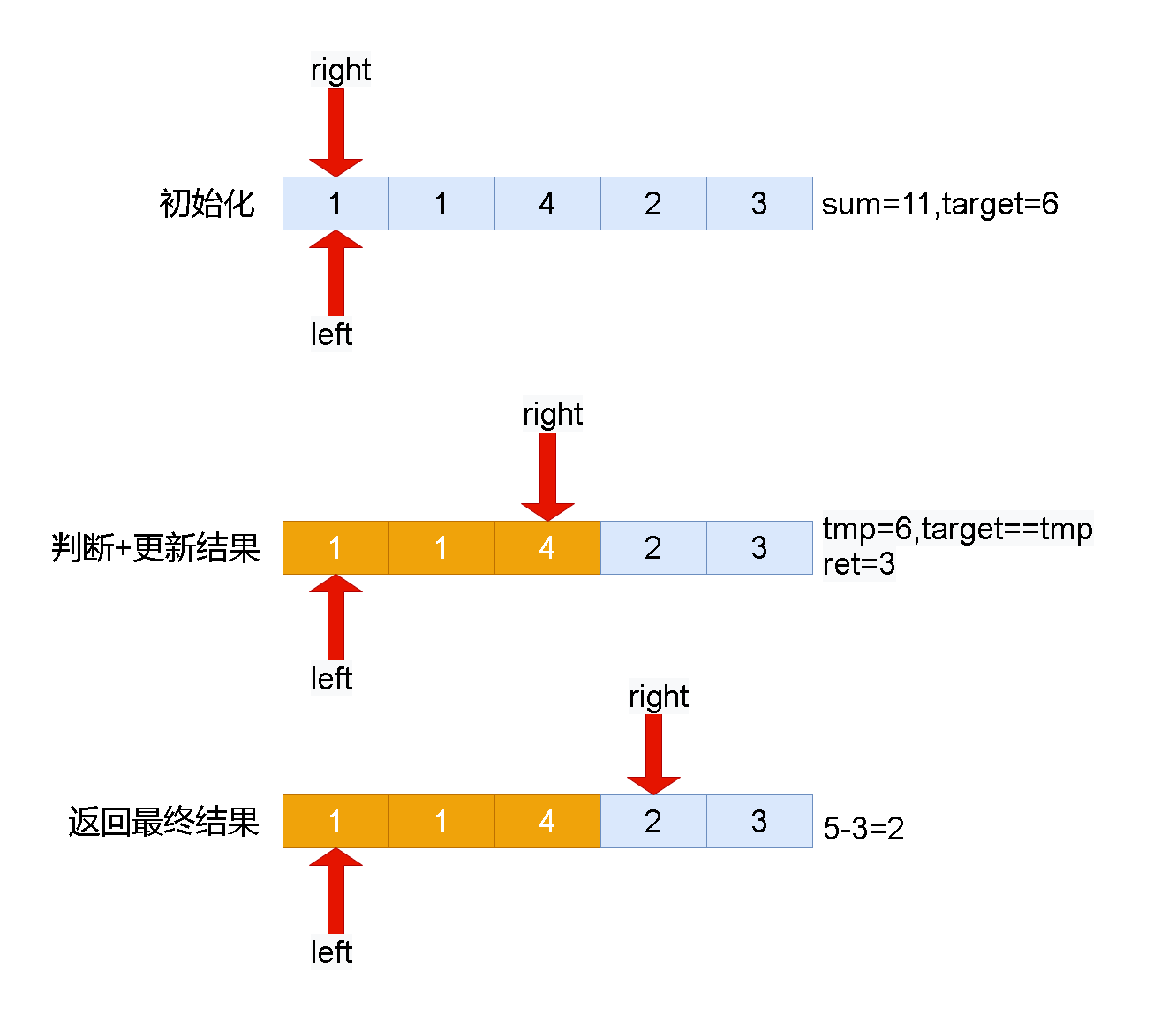
Leetcode刷题详解——将x减到0的最小操作数
1. 题目链接:1658. 将 x 减到 0 的最小操作数 2. 题目描述: 给你一个整数数组 nums 和一个整数 x 。每一次操作时,你应当移除数组 nums 最左边或最右边的元素,然后从 x 中减去该元素的值。请注意,需要 修改 数组以供接下来的操作…...

精选免费热门api接口分享
IP归属地-IPv4城市级:根据IP地址查询归属地信息,支持到城市级,包含国家、省、市、和运营商等信息。IP归属地-IPv6城市级:根据IP地址(IPv6版本)查询归属地信息,支持到中国大陆地区(不…...
androidx.appcompat.widget.Toolbar最右边设置控件不能仅靠最右边
androidx.appcompat.widget.Toolbar最右边设置控件不能仅靠最右边 Android Toolbar左、中、右对齐-CSDN博客Android Toolbar左、中、右对齐默认的Android Toolbar中添加子元素view是从左到右依次添加。需要注意的是,Android Toolbar为自身的…...
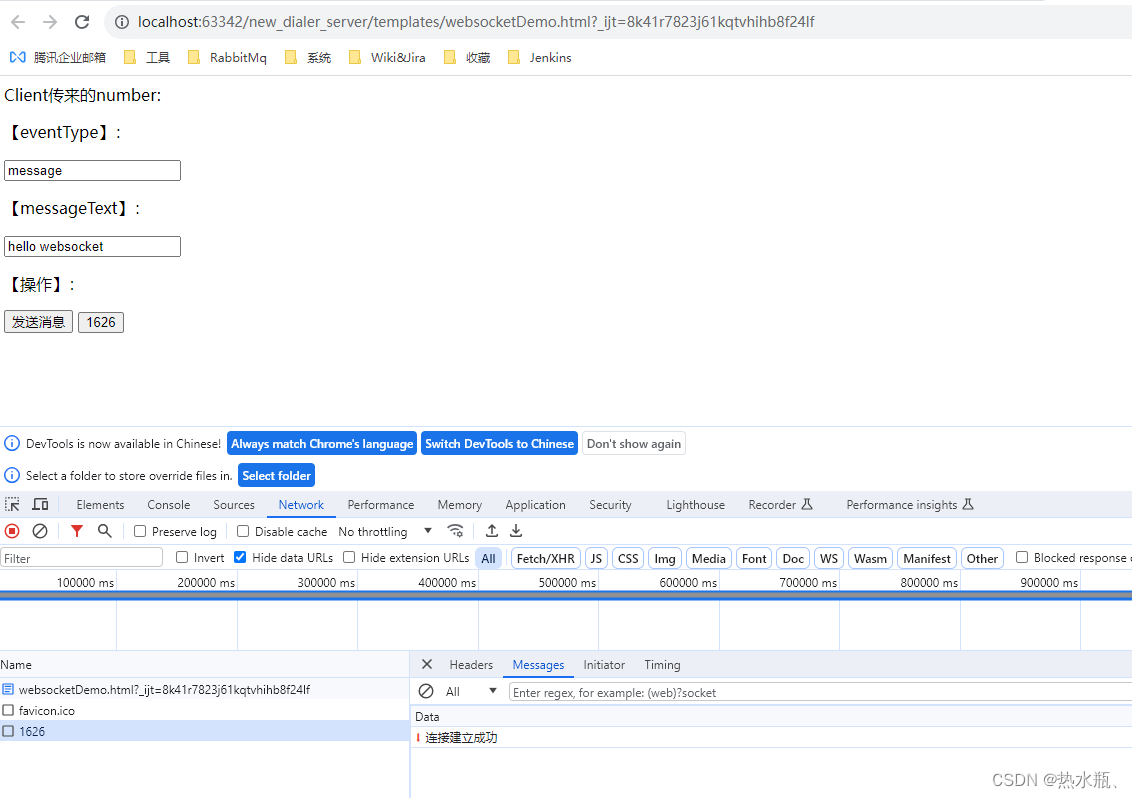
Springboot整合WebSocket实现浏览器和服务器交互
Websocket定义 代码实现 引入maven依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency>配置类 import org.springframework.context.annotation.Bean;i…...

这些 channel 用法你都用起来了吗?
channel 是什么? channel 是GO语言中一种特殊的类型,是连接并发goroutine的管道 channel 通道是可以让一个 goroutine 协程发送特定值到另一个 goroutine 协程的通信机制。 关于 channel 的原理,channel通道需要注意的地方,之前…...

纽交所上市公司安费诺宣布将以1.397亿美元收购无线解决方案提供商PCTEL
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,纽交所上市公司安费诺(APH)宣布将以每股7美元现金,总价格1.397亿美元收购无线解决方案提供商PCTEL(PCTI)。 该交易预计将在第四季度或2024年初完成。 Lake Street Capital Markets担任…...
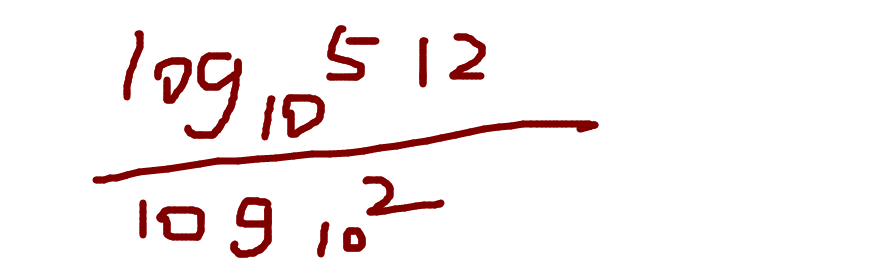
二分查找算法(Python)
目录 1、概念 2、思路 3、实现算法 1、概念 二分查找又称折半查找,它是一种效率较高的查找方法 原理:首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成…...

“第四十二天”
这个,之前用的b去存储a的总和和排名,后来在比较的过程中,只改变的b的值,却没有改变a的值,但在比较语文成绩的时候用的还是a,这个时候a和b同样是第i个对应的可能不是同一个对象了 ,因为上面b的值…...

Qt/C++编写物联网组件/支持modbus/rtu/tcp/udp/websocket/mqtt/多线程采集
一、功能特点 支持多种协议,包括Modbus_Rtu_Com/Modbus_Rtu_Tcp/Modbus_Rtu_Udp/Modbus_Rtu_Web/Modbus_Tcp/Modbus_Udp/Modbus_Web等,其中web指websocket。支持多种采集通讯方式,包括串口和网络等,可自由拓展其他方式。自定义采…...
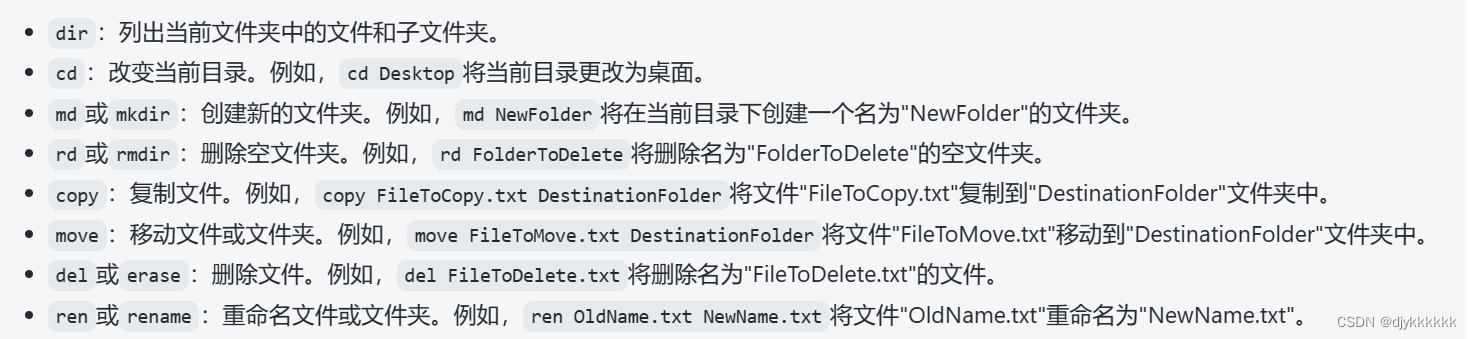
windows常用命令
一.文件操作 dir:查看文件当前路径目录列表 cd .. :返回上一级目录 cd 路径:进入路径...
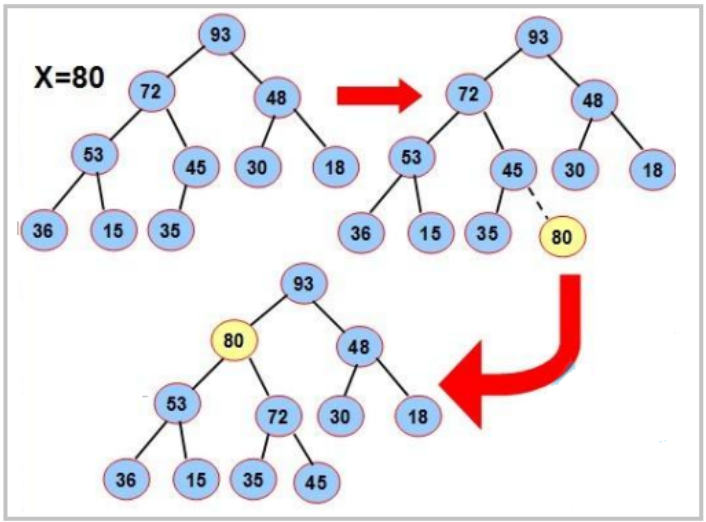
数据结构--堆
一. 堆 1. 堆的概念 堆(heap):一种有特殊用途的数据结构——用来在一组变化频繁(发生增删查改的频率较高)的数据集中查找最值。 堆在物理层面上,表现为一组连续的数组区间:long[] array &…...

Android12之报错 error: BUILD_COPY_HEADERS is obsolete(一百六十七)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...

vue前端中v-model与ref的区别
v-model <template><input type"text" v-model"message"> </template>作用:将输入框与message绑定,及将用户输入的内容绑定到message这个变量上,但是message是无法在script中获取到的,要想…...

Wayback Machine 浏览器扩展:一键穿越互联网历史的终极免费工具
Wayback Machine 浏览器扩展:一键穿越互联网历史的终极免费工具 【免费下载链接】wayback-machine-webextension A web browser extension for Chrome, Firefox, Edge, and Safari 14. 项目地址: https://gitcode.com/gh_mirrors/wa/wayback-machine-webextension…...

解决Redroid安卓12串流黑屏:修改SurfaceFlinger绕过Secure Flag的实战记录
解决Redroid安卓12串流黑屏:修改SurfaceFlinger绕过Secure Flag的实战记录 在RK3588开发板上运行Redroid容器时,许多开发者会遇到一个棘手问题:使用scrcpy等工具串流显示某些应用界面时,屏幕突然变黑。这并非硬件故障,…...

如何一键保存整个网页?告别滚动拼接的终极解决方案
如何一键保存整个网页?告别滚动拼接的终极解决方案 【免费下载链接】full-page-screen-capture-chrome-extension One-click full page screen captures in Google Chrome 项目地址: https://gitcode.com/gh_mirrors/fu/full-page-screen-capture-chrome-extensio…...

终极LuaJIT反编译指南:如何快速恢复丢失的Lua源代码
终极LuaJIT反编译指南:如何快速恢复丢失的Lua源代码 【免费下载链接】luajit-decompiler https://gitlab.com/znixian/luajit-decompiler 项目地址: https://gitcode.com/gh_mirrors/lu/luajit-decompiler 你是否曾面对编译后的LuaJIT字节码文件束手无策&…...

PrismLauncher-Cracked:如何通过代码修改实现Minecraft完全离线启动?
PrismLauncher-Cracked:如何通过代码修改实现Minecraft完全离线启动? 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a …...

10分钟快速上手:VSCode Cortex-Debug调试插件终极指南
10分钟快速上手:VSCode Cortex-Debug调试插件终极指南 【免费下载链接】cortex-debug Visual Studio Code extension for enhancing debug capabilities for Cortex-M Microcontrollers 项目地址: https://gitcode.com/gh_mirrors/co/cortex-debug 还在为嵌入…...

110页PPT的大数据产品设计和应用,含整体方案和多个行业案例,满分PPT
📘【文档介绍】🌐《大数据应用型产品设计方法及行业案例介绍》PPT共110页可编辑文档,它将是你招投标、行业解决方案的重要参考资料。 🔑【掌握大数据,引领企业未来】 作为企业管理者,需要的不仅是管理智慧&…...

从串口调试到上位机显示:手把手教你用Python写一个STM32 OV2640的JPEG图传接收端
从串口调试到上位机显示:Python实现STM32 OV2640的JPEG图传接收端全解析 当STM32成功通过OV2640摄像头捕获JPEG图像并通过串口发送后,如何稳定接收、解析并实时显示这些数据成为开发者面临的下一个挑战。本文将深入探讨如何用Python构建一个高效可靠的上…...

酷安UWP桌面客户端完整指南:大屏幕高效刷酷安的终极方案
酷安UWP桌面客户端完整指南:大屏幕高效刷酷安的终极方案 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 还在为手机小屏幕刷酷安而感到眼睛酸痛吗?想在27寸大屏幕上…...

又一个朋友0基础转行网安成功上岸了,但劝解所有想转行的人...
又一个朋友0基础转行网安成功上岸了,但劝解所有想转行的人… 数月之前,一位昔日同事主动来找我闲聊,坦言打算辞职转行投身网安行业。她从求学到入职工作,从来都没接触过编程相关内容,只是刷到网上传言这行入行简单、人…...