Python- JSON使用初探
JSON
在JSON格式中,{} 和 [] 是两种主要的数据结构,分别表示对象(或称为字典、哈希、map)和数组(或称为列表、序列)。
-
{} - 对象
在JSON中,对象是一组
"key": value对的集合。这些键必须是字符串,而值可以是有效的JSON数据类型(字符串、数字、对象、数组、true、false或null)。示例:
{"name": "John","age": 30,"is_student": false }这个JSON对象有三个键值对:
"name","age", 和"is_student"。 -
[] - 数组
在JSON中,数组是有序的值的集合。这些值可以是任何有效的JSON数据类型。
示例:
["apple", "banana", "cherry"]这个JSON数组有三个字符串值。
数组中的值也可以是对象或其他数组,这样可以创建复杂的嵌套结构。例如:
[{"name": "John","age": 30},{"name": "Jane","age": 25} ]在这个例子中,JSON数组包含两个对象。
总结:在JSON中,{}用于表示对象,而[]用于表示数组。这两种结构可以嵌套和组合,以创建复杂的数据表示。这些结构与Python中的字典(dict)和列表(list)非常相似,因此在Python和JSON之间进行数据转换时,这两种结构通常会相互映射。
在 JSON 中,除了对象 {} 和数组 [] 这两种主要的数据结构外,没有其他的复杂数据结构。
JSON 支持的基本数据类型有:
-
字符串 (String): 由双引号括起来的字符集合。例如:
"Hello, World!" -
数字 (Number): 可以是整数或浮点数。例如:
123,3.14,-42,0.001 -
布尔值 (Boolean): 有两个值:
true和false。 -
null: 表示一个空值或缺失值。
这些基本数据类型可以与对象 {} 和数组 [] 结合使用,形成复杂的数据结构。
例如:
{"name": "John","age": 30,"is_student": false,"scores": [95, 87, 78],"address": {"city": "New York","zip": "10001"},"friends": null
}
在这个 JSON 数据中:
"name"的值是一个 字符串。"age"的值是一个 数字。"is_student"的值是一个 布尔值。"scores"的值是一个 数组,其中包含三个数字。"address"的值是一个 对象,其中包含两个键值对。"friends"的值是 null。
这些基本数据类型和数据结构使得 JSON 能够表示大多数常见的数据结构,从简单的标量值到复杂的嵌套对象和数组。
json.loads()
json.loads() 是 Python 标准库中 json 模块提供的一个函数,它用于将一个 JSON 编码的字符串转换为一个 Python 对象。loads 是 “load string” 的缩写。
函数签名
json.loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
参数
- s - 这是要解析的 JSON 编码的字符串。
以下参数是可选的:
- encoding - 这个参数是已弃用的,因为 JSON 数据默认为 UTF-8。
- cls - 自定义的 JSON 解码器。
- object_hook - 如果指定了此参数,它应该是一个函数,用于将一个字典转换为另一个对象。
- parse_float - 使用此参数可以指定一个函数来解析浮点数(默认情况下使用 Python 的内置
float()函数)。 - parse_int - 使用此参数可以指定一个函数来解析整数(默认情况下使用 Python 的内置
int()函数)。 - parse_constant - 使用此参数可以指定一个函数来解析以下字符串:
-Infinity,Infinity,NaN。 - object_pairs_hook - 使用此参数可以指定一个函数,该函数接受一个键值对列表,然后返回一个对象。例如,它可以用于创建有序字典。
示例
import jsonjson_string = '{"name": "Alice", "age": 25, "is_student": false}'# 使用 json.loads() 转换字符串为字典
data = json.loads(json_string)print(type(data)) # <class 'dict'>
print(data) # {'name': 'Alice', 'age': 25, 'is_student': False}
注意事项
json.loads()只接受合法的 JSON 字符串。如果提供的字符串不是有效的 JSON,它会引发json.JSONDecodeError。- JSON 的
true,false, 和null在 Python 中分别对应为True,False, 和None。 - 从不受信任的源获取 JSON 数据时,使用
json.loads()是安全的,因为它不会执行任何潜在的危险代码。这与某些其他语言的解析器不同,这些解析器可能会执行嵌入在数据中的代码。
总的来说,json.loads() 是 Python 中处理 JSON 数据的基本工具,它简单、高效、安全。
json.dumps()
json.dumps() 是 Python 标准库中 json 模块提供的一个函数。它用于将 Python 对象序列化为 JSON 格式的字符串。dumps 是 “dump string” 的缩写。
函数签名
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
参数
- obj - 要序列化的 Python 对象。
以下参数是可选的:
- skipkeys - 默认为
False。如果设置为True,则字典的键不是基本类型 (str,int,float,bool,None) 将被跳过,而不是引发TypeError。 - ensure_ascii - 默认为
True。如果为True,则输出保证仅包含 ASCII 字符。如果 Python 对象包含非ASCII字符,它们将被转义。如果为False,则这些字符将以UTF-8编码输出。 - check_circular - 默认为
True。检查循环引用。 - allow_nan - 默认为
True。指定是否允许序列化非数值的浮点值(例如:Infinity,-Infinity,NaN)。 - cls - 自定义的 JSON 编码器。
- indent - 可以是整数或字符串,指定缩进级别以美化输出的JSON。例如,
indent=4会使输出具有 4 个空格的缩进。 - separators - 一个元组,指定用于分隔项目和键值对的字符串。
- default - 指定一个函数,用于序列化那些不能默认序列化的 Python 对象。
- sort_keys - 默认为
False。如果为True,则输出的 JSON 字符串的字典键将被排序。
示例
import jsondata = {"name": "Alice","age": 25,"is_student": False
}# 使用 json.dumps() 将字典转换为字符串
json_string = json.dumps(data, indent=4)print(json_string)
输出:
{"name": "Alice","age": 25,"is_student": false
}
注意事项
- Python 的字典顺序在 Python 3.7+ 中是有保证的,但在此之前的版本中并不保证。如果需要保证键的顺序,可以使用
sort_keys=True。 - 并非所有的 Python 对象都可以被序列化为 JSON。例如,Python 的
set类型或自定义对象默认是不能被序列化的。但可以提供一个default函数来自定义这些类型的序列化方法。 - 在将数据序列化为 JSON 时,请注意大小写。JSON 键通常为小写,而 Python 的命名惯例可能与之不同。
总的来说,json.dumps() 是 Python 中处理 JSON 数据的基本工具,允许开发者以灵活和可控的方式将 Python 对象转换为 JSON 格式的字符串。
综合案例
下面这个例子展示了如何结合使用 json.dumps() 和 json.loads() 在 Python 对象和 JSON 格式的字符串之间进行转换,以及如何将 JSON 数据保存到文件和从文件中读取。
让我们考虑一个简单的场景:有一个 Python 字典,其中包含用户的一些信息,我们想将其保存到一个 JSON 文件中,并从该文件中读取信息。
首先,我们使用 json.dumps() 将字典转换为 JSON 格式的字符串并将其写入文件。然后,我们从文件中读取 JSON 字符串并使用 json.loads() 将其解析回 Python 对象。
示例
import json# 定义一个字典,其中包含用户的信息
user_data = {"name": "John Doe","age": 30,"email": "johndoe@example.com","is_member": True
}# 将 Python 字典转换为 JSON 字符串并写入文件
with open("user_data.json", "w") as file:json_string = json.dumps(user_data, indent=4)file.write(json_string)# 从文件中读取 JSON 字符串并转换为 Python 对象
with open("user_data.json", "r") as file:data = file.read()parsed_data = json.loads(data)print(parsed_data)print(f"User's name: {parsed_data['name']}")
运行结果如下:
majn@tiger:~$ python3 json_demo.py
{'name': 'Mario', 'age': 30, 'email': 'mario@example.com', 'is_member': True}
User's name: Mario
自定义序列化函数
case 1
当我们尝试将一些不能被直接序列化为JSON的Python对象(例如自定义对象或Python的set类型)转换为JSON时,可以使用default参数来指定如何处理这些对象。
下面的例子演示如何使用default参数来序列化一个包含自定义对象的Python列表:
import jsonclass Person:def __init__(self, name, age):self.name = nameself.age = agedef person_encoder(obj):"""自定义函数,将Person对象转换为可序列化的字典"""if isinstance(obj, Person):return {"name": obj.name, "age": obj.age}raise TypeError("Object of type 'Person' is not JSON serializable")# 创建一个Person对象列表
people = [Person("Alice", 30), Person("Bob", 25)]# 使用json.dumps()和default参数将列表转换为JSON字符串
people_json = json.dumps(people, default=person_encoder, indent=4)print(people_json)
输出:
[{"name": "Alice","age": 30},{"name": "Bob","age": 25}
]
在这个例子中,我们定义了一个person_encoder函数,用于将Person对象转换为可以序列化为JSON的字典。当json.dumps()遇到Person对象时,它会调用person_encoder函数进行处理。
这种方法允许开发者为任何不可以直接序列化为JSON的Python对象定义自定义的序列化逻辑。
case 2
当我们尝试将Python的set类型转换为JSON时,默认情况下是不支持的,因为JSON格式没有与集合相对应的数据类型。但是,我们可以使用default参数来自定义set的序列化方式。
一个常见的方法是将set转换为列表,因为列表是JSON支持的数据类型。下面是如何使用default参数将set类型转换为JSON的示例:
import jsondef set_encoder(obj):"""自定义函数,将set对象转换为列表"""if isinstance(obj, set):return list(obj)raise TypeError(f"Object of type '{type(obj).__name__}' is not JSON serializable")# 创建一个set
fruits = {"apple", "banana", "cherry"}# 使用json.dumps()和default参数将set转换为JSON字符串
fruits_json = json.dumps(fruits, default=set_encoder, indent=4)print(fruits_json)
输出:
["banana","cherry","apple"
]
注意:由于集合是无序的,所以转换为列表后的元素顺序可能会与原始集合中的顺序不同。
在这个例子中,我们定义了一个set_encoder函数,用于将set对象转换为列表。当json.dumps()遇到set对象时,它会调用set_encoder函数进行处理。这样,我们就可以将set类型成功转换为JSON字符串。
相关文章:

Python- JSON使用初探
JSON 在JSON格式中,{} 和 [] 是两种主要的数据结构,分别表示对象(或称为字典、哈希、map)和数组(或称为列表、序列)。 {} - 对象 在JSON中,对象是一组"key": value对的集合。这些键必…...

vim的配置文件
用户级别配置文件 ~/.vimrc 修改用户级别的配置文件只会影响当前用户, 不会影响其他的用户. 例如: 在用户的家目录下的.vimrc文件中添加 set tabstop4 ----设置缩进4个空格 set nu ----设置行号 set shiftwidth4 —设置ggG缩进4个空格, 默认是缩进8个空格 系统级别配置文件 /e…...
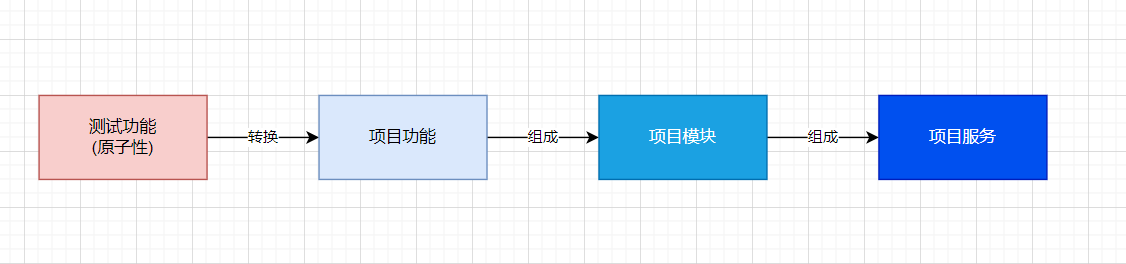
[python] pytest
在写一个项目前, 可以先编写测试模块 测试模块中包含了一个个最小的功能 当每一个功能都完善正确时 再将这些功能转换成项目运行的功能 多个项目运行的功能就组成了一个模块 多个模块就组成了一个项目服务 pytest 是一个 Python 测试框架,它提供了简单易用的语…...

【王道代码】【2.2顺序表】d1
关键字: 删除最小值最后位补齐;逆置;删除所有x;删除值为s到t区间的元素...

【Linux】【创建文件】Linux系统下在命令行中创建文件的方法
🐚作者简介:花神庙码农(专注于Linux、WLAN、TCP/IP、Python等技术方向)🐳博客主页:花神庙码农 ,地址:https://blog.csdn.net/qxhgd🌐系列专栏:Linux技术&…...

Pytorch之MobileViT图像分类
文章目录 前言一、Transformer存在的问题二、MobileViT1.MobileViT网络结构🍓 Vision Transformer结构🍉MobileViT结构 2.MV2(MobileNet v2 block)3.MobileViT block🥇Local representations🥈Transformers as Convolutions (glob…...

03在命令行环境中创建Maven版的Java工程,了解pom.xml文件的结构,了解Java工程的目录结构并编写代码,执行Maven相关的构建命令
创建Maven版的Java工程 Maven工程的坐标 数学中使用x、y、z三个向量可以在空间中唯一的定位一个点, Maven中也可以使用groupId,artifactId,version三个向量在Maven的仓库中唯一的定位到一个jar包 groupId: 公司或组织域名的倒序, 通常也会加上项目名称代表公司或组织开发的一…...
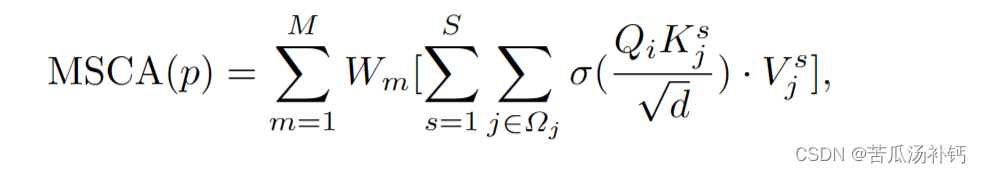
论文阅读:CenterFormer: Center-based Transformer for 3D Object Detection
目录 概要 Motivation 整体架构流程 技术细节 Multi-scale Center Proposal Network Multi-scale Center Transformer Decoder Multi-frame CenterFormer 小结 论文地址:[2209.05588] CenterFormer: Center-based Transformer for 3D Object Detection (arx…...
)
Arduino驱动BNO055九轴绝对定向传感器(惯性测量传感器篇)
目录 1、传感器特性 2、硬件原理图 3、控制器和传感器连线图 4、驱动程序 BNO055是实现智能9轴绝对定向的新型传感器IC,它将整个传感器系统级封装在一起,集成了三轴14位加速度计,三轴16位陀螺仪,三轴地磁传感器和一个自带算法处理的32位微控制器。...

MQTT测试工具及使用教程
一步一步来:MQTT服务器搭建、MQTT客户端使用-CSDN博客 MQTT X 使用指南_mqttx使用教程-CSDN博客...

yolov7改进优化之蒸馏(一)
最近比较忙,有一段时间没更新了,最近yolov7用的比较多,总结一下。上一篇yolov5及yolov7实战之剪枝_CodingInCV的博客-CSDN博客 我们讲了通过剪枝来裁剪我们的模型,达到在精度损失不大的情况下,提高模型速度的目的。上一…...

视频美颜SDK,提升企业视频通话质量与形象
在今天的数字时代,视频通话已经成为企业与客户、员工之间不可或缺的沟通方式。然而,由于网络环境、设备性能等因素的影响,视频通话中的画面质量往往难以达到预期效果。为了提升视频通话的质量与形象,美摄美颜SDK应运而生ÿ…...
webmin远程命令执行漏洞
文章目录 漏洞编号:漏洞描述:影响版本:利用方法(利用案例):安装环境漏洞复现 附带文件:加固建议:参考信息:漏洞分类: Webmin 远程命令执行漏洞(CV…...
docker离线安装和使用
通过修改daemon配置文件/etc/docker/daemon.json来使用加速器sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-EOF {"registry-mirrors": ["https://ullx9uta.mirror.aliyuncs.com"] } EOF sudo systemctl daemon-reload sudo syste…...
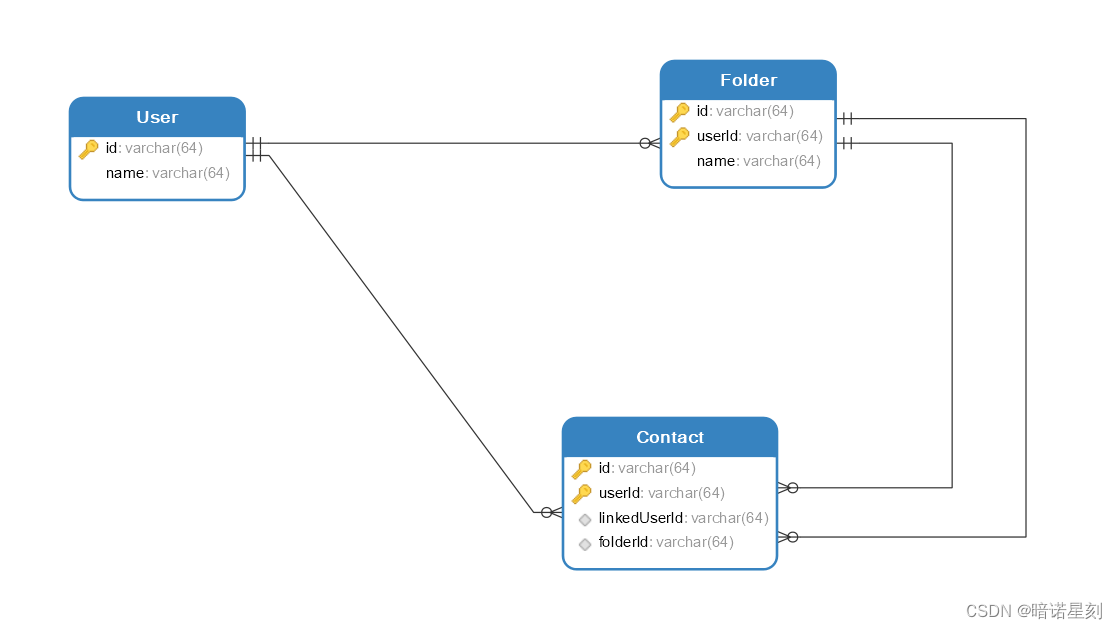
解决 MyBatis 一对多查询中,出现每组元素只有一个,总组数与元素数总数相等的问题
文章目录 问题简述场景描述问题描述问题原因解决办法 问题简述 笔者在使用 MyBatis 进行一对多查询的时候遇到一个奇怪的问题。对于笔者的一对多的查询结果,出现了这样的一个现象:原来每个组里有多个元素,查询目标是查询所查的组,…...
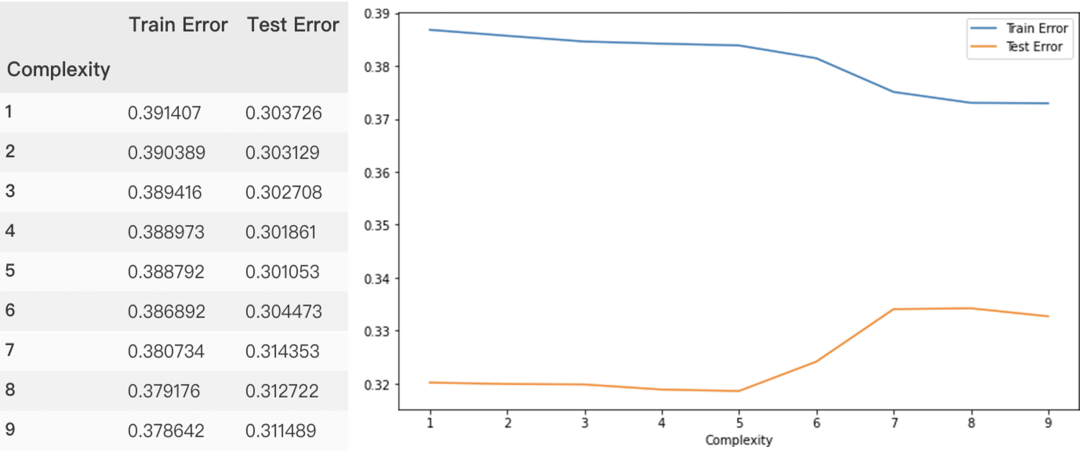
这应该是关于回归模型最全的总结了(附原理+代码)
本文将继续修炼回归模型算法,并总结了一些常用的除线性回归模型之外的模型,其中包括一些单模型及集成学习器。 保序回归、多项式回归、多输出回归、多输出K近邻回归、决策树回归、多输出决策树回归、AdaBoost回归、梯度提升决策树回归、人工神经网络、随…...

基于闪电连接过程优化的BP神经网络(分类应用) - 附代码
基于闪电连接过程优化的BP神经网络(分类应用) - 附代码 文章目录 基于闪电连接过程优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.闪电连接过程优化BP神经网络3.1 BP神经网络参数设置3.2 闪电连接过程算…...
Linux性能优化--性能工具:网络
7.0 概述 本章介绍一些在Linux上可用的网络性能工具。我们主要关注分析单个设备/系统网络流量的工具,而非全网管理工具。虽然在完全隔离的情况下评估网络性能通常是无意义的(节点不会与自己通信),但是,调查单个系统在网络上的行为对确定本地配置和应用程…...
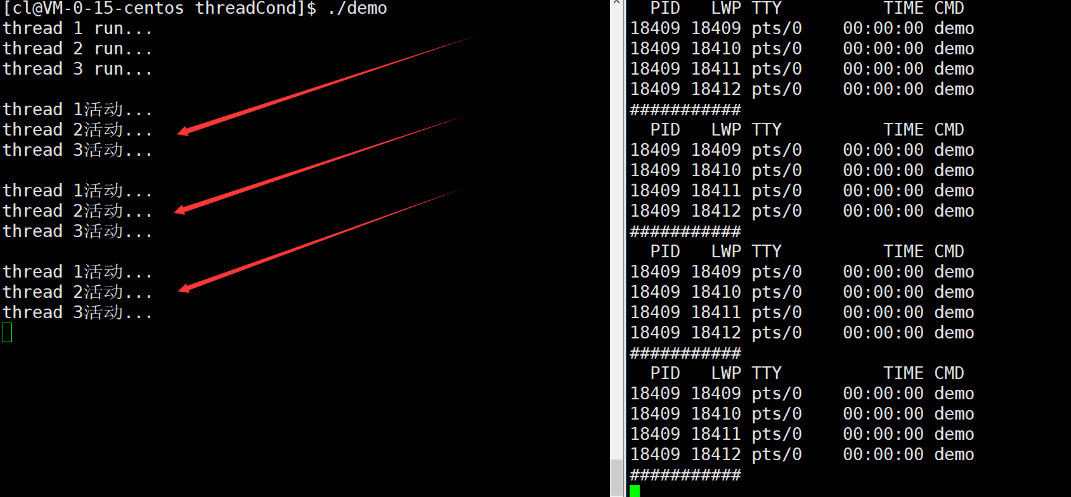
【Linux】线程互斥与同步
文章目录 一.Linux线程互斥1.进程线程间的互斥相关背景概念2互斥量mutex3.互斥量的接口4.互斥量实现原理探究 二.可重入VS线程安全1.概念2.常见的线程不安全的情况3.常见的线程安全的情况4.常见的不可重入的情况5.常见的可重入的情况6.可重入与线程安全联系7.可重入与线程安全区…...
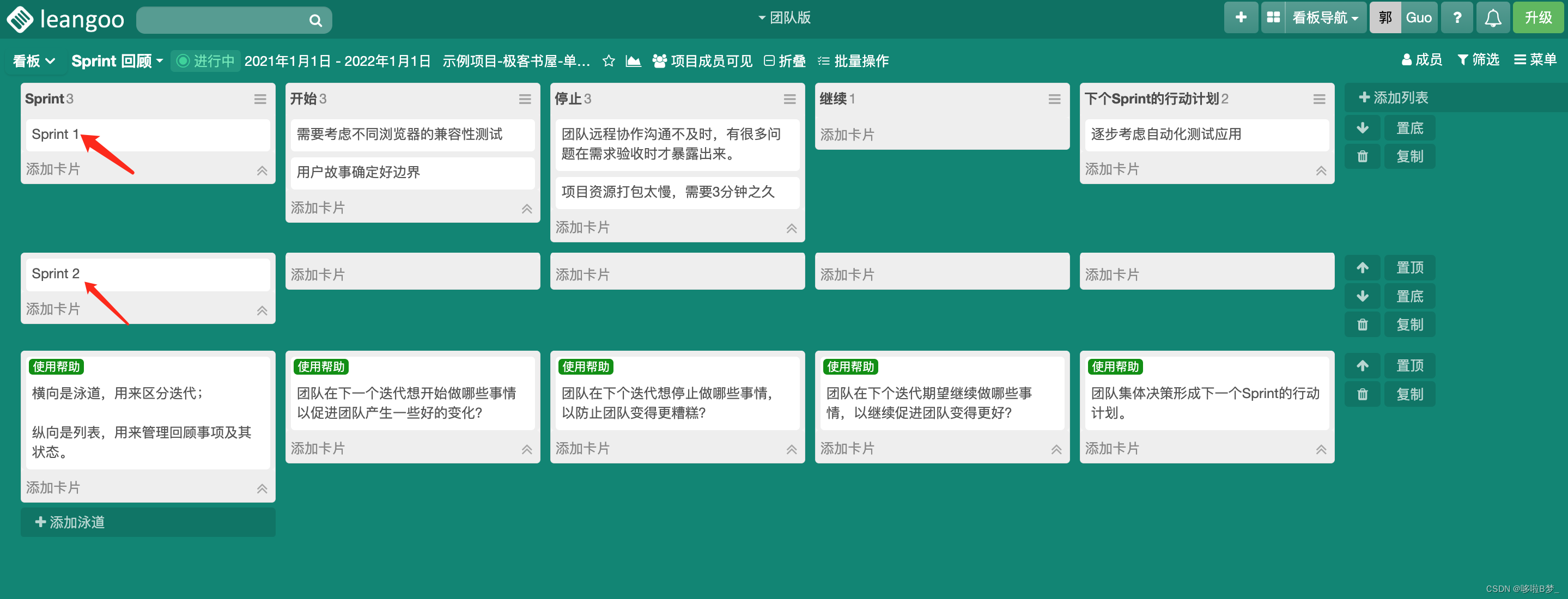
敏捷开发中,Sprint回顾会的目的
Sprint回顾会的主要目的是促进Scrum团队的学习和持续改进。在每个Sprint结束后,团队聚集在一起进行回顾,以达到以下目标: 识别问题: 回顾会允许团队识别在Sprint(迭代)期间遇到的问题、挑战和障碍。这有助于…...

CameraFileCopy:创新实现手机摄像头离线文件传输的完整解决方案
CameraFileCopy:创新实现手机摄像头离线文件传输的完整解决方案 【免费下载链接】cfc Demo/test android app for libcimbar. Copy files over the cell phone camera! 项目地址: https://gitcode.com/gh_mirrors/cfc/cfc 在无线网络无处不在的今天ÿ…...

5分钟上手Real-ESRGAN:让模糊图片瞬间清晰的AI图像增强神器
5分钟上手Real-ESRGAN:让模糊图片瞬间清晰的AI图像增强神器 【免费下载链接】Real-ESRGAN Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN 你是否曾为…...

RetinaFace实战:10个技巧教你高效检测和提取人脸
RetinaFace实战:10个技巧教你高效检测和提取人脸 【免费下载链接】retinaface RetinaFace: Deep Face Detection Library for Python 项目地址: https://gitcode.com/gh_mirrors/re/retinaface RetinaFace是一个基于深度学习的Python人脸检测库,专…...
)
【限时解密】Midjourney野兽派风格“原始态”生成协议:仅用/raw + 2个隐藏参数,绕过所有风格平滑化过滤(实测成功率提升67%)
更多请点击: https://codechina.net 第一章:Midjourney野兽派风格的美学本质与系统性失衡 野兽派(Fauvism)在视觉艺术中以高饱和色彩、粗犷笔触与主观情感压倒写实逻辑著称;当这一美学被Midjourney等扩散模型“转译”…...

海外渠道通知短信接口
在跨境业务体系中,企业常面临区域代理商分散、信息同步滞后、补货提醒不及时的问题,传统邮件、即时通讯易出现漏读、延迟,而国际渠道通知短信接口凭借触达稳定、实时性强的优势,成为跨境企业对接代理商的高效通信方案。本文从接口…...
)
别再手动敲代码了!用FastAdmin的CRUD一键生成后台页面(附自定义模板技巧)
FastAdmin自动化开发实战:CRUD生成与模板定制全攻略 1. 为什么选择自动化生成而非手动编码? 在快节奏的开发环境中,重复编写基础CRUD代码已成为效率杀手。我曾参与过一个电商后台项目,需要为30多个数据表开发管理界面。最初团队采…...

Perplexity生物检索黄金公式:[实体]+[关系]+[证据等级]+[时间窗]——经Nature子刊12篇方法论论文交叉验证
更多请点击: https://intelliparadigm.com 第一章:Perplexity生物检索黄金公式的提出与演进 Perplexity生物检索黄金公式(Perplexity-Bio Retrieval Golden Formula, PBRGF)并非源于单一论文,而是随着跨模态生物语义建…...

零 Python 依赖!用 JavaCV + ONNX Runtime 把 YOLO 塞进生产环境
上周五快下班的时候,运维老张突然冲进办公室,手里还拎着半杯凉透的枸杞茶。 “兄弟,客户那边又炸了!”他把杯子往桌上一墩,“那个 PCB 缺陷检测系统,Python 推理服务又崩了。这周第三次了,人家产…...

原子制造:从单原子操控到新材料创制的技术原理与应用
1. 原子制造:从宏观“锤子”到微观“镊子”的范式革命我们常说,人类文明史是一部材料史。从打磨石器的旧石器时代,到熔铸青铜的青铜时代,再到锻造钢铁的工业时代,每一次文明的跃迁,都伴随着我们对物质操控能…...
)
保姆级教程:在ROS2 Humble上,用Orbbec Astra Pro深度相机搞定单目标定(附常见镜像问题解决)
保姆级教程:ROS2 Humble与Orbbec Astra Pro深度相机单目标定实战指南 深度相机在机器人视觉、三维重建等领域扮演着关键角色,而精确的相机标定则是确保数据可靠性的第一步。本文将手把手带你完成Orbbec Astra Pro在ROS2 Humble环境下的单目标定全流程&am…...