yolov7改进优化之蒸馏(一)
最近比较忙,有一段时间没更新了,最近yolov7用的比较多,总结一下。上一篇yolov5及yolov7实战之剪枝_CodingInCV的博客-CSDN博客 我们讲了通过剪枝来裁剪我们的模型,达到在精度损失不大的情况下,提高模型速度的目的。上一篇是从速度的角度,这一篇我们从检测性能的角度来改进yolov7(yolov5也类似)。
对于提高检测器的性能,我们除了可以从增加数据、修改模型结构、修改loss等模型本身的角度出发外,深度学习领域还有一个方式—蒸馏。简单的说,蒸馏就是让性能更强的模型(teacher, 参数量更大)来指导性能更弱student模型,从而提高student模型的性能。
蒸馏的方式有很多种,比较简单暴力的比如直接让student模型来拟合teacher模型的输出特征图,当然蒸馏也不是万能的,毕竟student模型和teacher模型的参数量有差距,student模型不一定能很好的学习teacher的知识,对于自己的任务有没有作用也需要尝试。
本篇选择的方法是去年CVPR上的针对目标检测的蒸馏算法:
yzd-v/FGD: Focal and Global Knowledge Distillation for Detectors (CVPR 2022) (github.com)
针对该方法的解读可以参考:FGD-CVPR2022:针对目标检测的焦点和全局蒸馏 - 知乎 (zhihu.com)
本篇暂时不涉及理论,重点在把这个方法集成到yolov7训练。步骤如下。
载入teacher模型
蒸馏首先需要有一个teacher模型,这个teacher模型一般和student同样结构,只是参数量更大、层数更多。比如对于yolov5,可以尝试用yolov5m来蒸馏yolov5s。
train.py增加一个命令行参数:
parser.add_argument("--teacher-weights", type=str, default="", help="initial weights path")
在train函数中载入teacher weights,过程与原有的载入过程类似,注意,DP或者DDP模型也要对teacher模型做对应的处理。
# teacher modelif opt.teacher_weights:teacher_weights = opt.teacher_weights# with torch_distributed_zero_first(rank):# teacher_weights = attempt_download(teacher_weights) # download if not found locallyteacher_model = Model(teacher_weights, ch=3, nc=nc).to(device) # create # load state_dictckpt = torch.load(teacher_weights, map_location=device) # load checkpointstate_dict = ckpt["model"].float().state_dict() # to FP32teacher_model.load_state_dict(state_dict, strict=True) # load#set to evalteacher_model.eval()#set IDetect to train mode# teacher_model.model[-1].train()logger.info(f"Load teacher model from {teacher_weights}") # report# DP modeif cuda and rank == -1 and torch.cuda.device_count() > 1:model = torch.nn.DataParallel(model)if opt.teacher_weights:teacher_model = torch.nn.DataParallel(teacher_model)# SyncBatchNormif opt.sync_bn and cuda and rank != -1:model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)logger.info("Using SyncBatchNorm()")if opt.teacher_weights:teacher_model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(teacher_model).to(device)
teacher模型不进行梯度计算,因此:
if opt.teacher_weights:for param in teacher_model.parameters():param.requires_grad = False
蒸馏Loss
蒸馏loss是计算teacher模型的一层或者多层与student的对应层的相似度,监督student模型向teacher模型靠近。对于yolov7,可以去监督三个特征层。
参考FGD的开源代码,我们在loss.py中增加一个FeatureLoss类, 参数暂时使用默认:
class FeatureLoss(nn.Module):"""PyTorch version of `Feature Distillation for General Detectors`Args:student_channels(int): Number of channels in the student's feature map.teacher_channels(int): Number of channels in the teacher's feature map. temp (float, optional): Temperature coefficient. Defaults to 0.5.name (str): the loss name of the layeralpha_fgd (float, optional): Weight of fg_loss. Defaults to 0.001beta_fgd (float, optional): Weight of bg_loss. Defaults to 0.0005gamma_fgd (float, optional): Weight of mask_loss. Defaults to 0.0005lambda_fgd (float, optional): Weight of relation_loss. Defaults to 0.000005"""def __init__(self,student_channels,teacher_channels,temp=0.5,alpha_fgd=0.001,beta_fgd=0.0005,gamma_fgd=0.001,lambda_fgd=0.000005,):super(FeatureLoss, self).__init__()self.temp = tempself.alpha_fgd = alpha_fgdself.beta_fgd = beta_fgdself.gamma_fgd = gamma_fgdself.lambda_fgd = lambda_fgdif student_channels != teacher_channels:self.align = nn.Conv2d(student_channels, teacher_channels, kernel_size=1, stride=1, padding=0)else:self.align = Noneself.conv_mask_s = nn.Conv2d(teacher_channels, 1, kernel_size=1)self.conv_mask_t = nn.Conv2d(teacher_channels, 1, kernel_size=1)self.channel_add_conv_s = nn.Sequential(nn.Conv2d(teacher_channels, teacher_channels//2, kernel_size=1),nn.LayerNorm([teacher_channels//2, 1, 1]),nn.ReLU(inplace=True), # yapf: disablenn.Conv2d(teacher_channels//2, teacher_channels, kernel_size=1))self.channel_add_conv_t = nn.Sequential(nn.Conv2d(teacher_channels, teacher_channels//2, kernel_size=1),nn.LayerNorm([teacher_channels//2, 1, 1]),nn.ReLU(inplace=True), # yapf: disablenn.Conv2d(teacher_channels//2, teacher_channels, kernel_size=1))self.reset_parameters()def forward(self,preds_S,preds_T,gt_bboxes,img_metas):"""Forward function.Args:preds_S(Tensor): Bs*C*H*W, student's feature mappreds_T(Tensor): Bs*C*H*W, teacher's feature mapgt_bboxes(tuple): Bs*[nt*4], pixel decimal: (tl_x, tl_y, br_x, br_y)img_metas (list[dict]): Meta information of each image, e.g.,image size, scaling factor, etc."""assert preds_S.shape[-2:] == preds_T.shape[-2:], 'the output dim of teacher and student differ'device = gt_bboxes.deviceself.to(device)if self.align is not None:preds_S = self.align(preds_S)N,C,H,W = preds_S.shapeS_attention_t, C_attention_t = self.get_attention(preds_T, self.temp)S_attention_s, C_attention_s = self.get_attention(preds_S, self.temp)Mask_fg = torch.zeros_like(S_attention_t)# Mask_bg = torch.ones_like(S_attention_t)wmin,wmax,hmin,hmax = [],[],[],[]img_h, img_w = img_metasbboxes = gt_bboxes[:,2:6]#xywh2xyxybboxes = xywh2xyxy(bboxes)new_boxxes = torch.ones_like(bboxes)new_boxxes[:, 0] = torch.floor(bboxes[:, 0]*W)new_boxxes[:, 2] = torch.ceil(bboxes[:, 2]*W)new_boxxes[:, 1] = torch.floor(bboxes[:, 1]*H)new_boxxes[:, 3] = torch.ceil(bboxes[:, 3]*H)#to intnew_boxxes = new_boxxes.int()for i in range(N):new_boxxes_i = new_boxxes[torch.where(gt_bboxes[:,0]==i)]wmin.append(new_boxxes_i[:, 0])wmax.append(new_boxxes_i[:, 2])hmin.append(new_boxxes_i[:, 1])hmax.append(new_boxxes_i[:, 3])area = 1.0/(hmax[i].view(1,-1)+1-hmin[i].view(1,-1))/(wmax[i].view(1,-1)+1-wmin[i].view(1,-1))for j in range(len(new_boxxes_i)):Mask_fg[i][hmin[i][j]:hmax[i][j]+1, wmin[i][j]:wmax[i][j]+1] = \torch.maximum(Mask_fg[i][hmin[i][j]:hmax[i][j]+1, wmin[i][j]:wmax[i][j]+1], area[0][j])Mask_bg = torch.where(Mask_fg > 0, 0., 1.)Mask_bg_sum = torch.sum(Mask_bg, dim=(1,2))Mask_bg[Mask_bg_sum>0] /= Mask_bg_sum[Mask_bg_sum>0].unsqueeze(1).unsqueeze(2)fg_loss, bg_loss = self.get_fea_loss(preds_S, preds_T, Mask_fg, Mask_bg, C_attention_s, C_attention_t, S_attention_s, S_attention_t)mask_loss = self.get_mask_loss(C_attention_s, C_attention_t, S_attention_s, S_attention_t)rela_loss = self.get_rela_loss(preds_S, preds_T)loss = self.alpha_fgd * fg_loss + self.beta_fgd * bg_loss \+ self.gamma_fgd * mask_loss + self.lambda_fgd * rela_lossreturn loss, loss.detach()def get_attention(self, preds, temp):""" preds: Bs*C*W*H """N, C, H, W= preds.shapevalue = torch.abs(preds)# Bs*W*Hfea_map = value.mean(axis=1, keepdim=True)S_attention = (H * W * F.softmax((fea_map/temp).view(N,-1), dim=1)).view(N, H, W)# Bs*Cchannel_map = value.mean(axis=2,keepdim=False).mean(axis=2,keepdim=False)C_attention = C * F.softmax(channel_map/temp, dim=1)return S_attention, C_attentiondef get_fea_loss(self, preds_S, preds_T, Mask_fg, Mask_bg, C_s, C_t, S_s, S_t):loss_mse = nn.MSELoss(reduction='sum')Mask_fg = Mask_fg.unsqueeze(dim=1)Mask_bg = Mask_bg.unsqueeze(dim=1)C_t = C_t.unsqueeze(dim=-1)C_t = C_t.unsqueeze(dim=-1)S_t = S_t.unsqueeze(dim=1)fea_t= torch.mul(preds_T, torch.sqrt(S_t))fea_t = torch.mul(fea_t, torch.sqrt(C_t))fg_fea_t = torch.mul(fea_t, torch.sqrt(Mask_fg))bg_fea_t = torch.mul(fea_t, torch.sqrt(Mask_bg))fea_s = torch.mul(preds_S, torch.sqrt(S_t))fea_s = torch.mul(fea_s, torch.sqrt(C_t))fg_fea_s = torch.mul(fea_s, torch.sqrt(Mask_fg))bg_fea_s = torch.mul(fea_s, torch.sqrt(Mask_bg))fg_loss = loss_mse(fg_fea_s, fg_fea_t)/len(Mask_fg)bg_loss = loss_mse(bg_fea_s, bg_fea_t)/len(Mask_bg)return fg_loss, bg_lossdef get_mask_loss(self, C_s, C_t, S_s, S_t):mask_loss = torch.sum(torch.abs((C_s-C_t)))/len(C_s) + torch.sum(torch.abs((S_s-S_t)))/len(S_s)return mask_lossdef spatial_pool(self, x, in_type):batch, channel, width, height = x.size()input_x = x# [N, C, H * W]input_x = input_x.view(batch, channel, height * width)# [N, 1, C, H * W]input_x = input_x.unsqueeze(1)# [N, 1, H, W]if in_type == 0:context_mask = self.conv_mask_s(x)else:context_mask = self.conv_mask_t(x)# [N, 1, H * W]context_mask = context_mask.view(batch, 1, height * width)# [N, 1, H * W]context_mask = F.softmax(context_mask, dim=2)# [N, 1, H * W, 1]context_mask = context_mask.unsqueeze(-1)# [N, 1, C, 1]context = torch.matmul(input_x, context_mask)# [N, C, 1, 1]context = context.view(batch, channel, 1, 1)return contextdef get_rela_loss(self, preds_S, preds_T):loss_mse = nn.MSELoss(reduction='sum')context_s = self.spatial_pool(preds_S, 0)context_t = self.spatial_pool(preds_T, 1)out_s = preds_Sout_t = preds_Tchannel_add_s = self.channel_add_conv_s(context_s)out_s = out_s + channel_add_schannel_add_t = self.channel_add_conv_t(context_t)out_t = out_t + channel_add_trela_loss = loss_mse(out_s, out_t)/len(out_s)return rela_lossdef last_zero_init(self, m):if isinstance(m, nn.Sequential):constant_init(m[-1], val=0)else:constant_init(m, val=0)def reset_parameters(self):kaiming_init(self.conv_mask_s, mode='fan_in')kaiming_init(self.conv_mask_t, mode='fan_in')self.conv_mask_s.inited = Trueself.conv_mask_t.inited = Trueself.last_zero_init(self.channel_add_conv_s)self.last_zero_init(self.channel_add_conv_t)
实例化FeatureLoss
在train.py中,实例化我们定义的FeatureLoss,由于我们要蒸馏三层,所以需要定一个蒸馏损失的数组:
if opt.teacher_weights:student_kd_layers = hyp["student_kd_layers"]teacher_kd_layers = hyp["teacher_kd_layers"]dump_image = torch.zeros((1, 3, imgsz, imgsz), device=device)targets = torch.Tensor([[0, 0, 0, 0, 0, 0]]).to(device)_, features = model(dump_image, extra_features = student_kd_layers) # forward_, teacher_features = teacher_model(dump_image,extra_features=teacher_kd_layers)kd_losses = []for i in range(len(features)):feature = features[i]teacher_feature = teacher_features[i]_, student_channels, _ , _ = feature.shape_, teacher_channels, _ , _ = teacher_feature.shapekd_losses.append(FeatureLoss(student_channels,teacher_channels))
其中hyp[‘xxx_kd_layers’]是用于指定我们要蒸馏的层序号。
为了提取出我们需要的层的特征图,我们还需要对模型推理的代码进行修改,这个放在下一篇,这一篇先把主要流程过一遍。
蒸馏训练
与普通loss一样,在训练中,首先计算蒸馏loss, 然后进行反向传播,区别只是计算蒸馏loss时需要使用teacher模型也对数据进行推理。
if opt.teacher_weights:pred, features = model(imgs, extra_features = student_kd_layers) # forward_, teacher_features = teacher_model(imgs, extra_features = teacher_kd_layers)if "loss_ota" not in hyp or hyp["loss_ota"] == 1 and epoch >= ota_start:loss, loss_items = compute_loss_ota(pred, targets.to(device), imgs)else:loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size# kd lossloss_items = torch.cat((loss_items[0].unsqueeze(0), loss_items[1].unsqueeze(0), loss_items[2].unsqueeze(0), torch.zeros(1, device=device), loss_items[3].unsqueeze(0)))loss_items[-1]*=imgs.shape[0]for i in range(len(features)):feature = features[i]teacher_feature = teacher_features[i]kd_loss, kd_loss_item = kd_losses[i](feature, teacher_feature, targets.to(device), [imgsz,imgsz])loss += kd_lossloss_items[3] += kd_loss_itemloss_items[4] += kd_loss_item
在这里,我们将kd_loss累加到了loss上。计算出总的loss,其他就与普通训练一样了。
结语
这篇文章简述了一下yolov7的蒸馏过程,更多细节将在下一篇中讲述。

相关文章:
yolov7改进优化之蒸馏(一)
最近比较忙,有一段时间没更新了,最近yolov7用的比较多,总结一下。上一篇yolov5及yolov7实战之剪枝_CodingInCV的博客-CSDN博客 我们讲了通过剪枝来裁剪我们的模型,达到在精度损失不大的情况下,提高模型速度的目的。上一…...

视频美颜SDK,提升企业视频通话质量与形象
在今天的数字时代,视频通话已经成为企业与客户、员工之间不可或缺的沟通方式。然而,由于网络环境、设备性能等因素的影响,视频通话中的画面质量往往难以达到预期效果。为了提升视频通话的质量与形象,美摄美颜SDK应运而生ÿ…...
webmin远程命令执行漏洞
文章目录 漏洞编号:漏洞描述:影响版本:利用方法(利用案例):安装环境漏洞复现 附带文件:加固建议:参考信息:漏洞分类: Webmin 远程命令执行漏洞(CV…...
docker离线安装和使用
通过修改daemon配置文件/etc/docker/daemon.json来使用加速器sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-EOF {"registry-mirrors": ["https://ullx9uta.mirror.aliyuncs.com"] } EOF sudo systemctl daemon-reload sudo syste…...
解决 MyBatis 一对多查询中,出现每组元素只有一个,总组数与元素数总数相等的问题
文章目录 问题简述场景描述问题描述问题原因解决办法 问题简述 笔者在使用 MyBatis 进行一对多查询的时候遇到一个奇怪的问题。对于笔者的一对多的查询结果,出现了这样的一个现象:原来每个组里有多个元素,查询目标是查询所查的组,…...
这应该是关于回归模型最全的总结了(附原理+代码)
本文将继续修炼回归模型算法,并总结了一些常用的除线性回归模型之外的模型,其中包括一些单模型及集成学习器。 保序回归、多项式回归、多输出回归、多输出K近邻回归、决策树回归、多输出决策树回归、AdaBoost回归、梯度提升决策树回归、人工神经网络、随…...

基于闪电连接过程优化的BP神经网络(分类应用) - 附代码
基于闪电连接过程优化的BP神经网络(分类应用) - 附代码 文章目录 基于闪电连接过程优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.闪电连接过程优化BP神经网络3.1 BP神经网络参数设置3.2 闪电连接过程算…...
Linux性能优化--性能工具:网络
7.0 概述 本章介绍一些在Linux上可用的网络性能工具。我们主要关注分析单个设备/系统网络流量的工具,而非全网管理工具。虽然在完全隔离的情况下评估网络性能通常是无意义的(节点不会与自己通信),但是,调查单个系统在网络上的行为对确定本地配置和应用程…...
【Linux】线程互斥与同步
文章目录 一.Linux线程互斥1.进程线程间的互斥相关背景概念2互斥量mutex3.互斥量的接口4.互斥量实现原理探究 二.可重入VS线程安全1.概念2.常见的线程不安全的情况3.常见的线程安全的情况4.常见的不可重入的情况5.常见的可重入的情况6.可重入与线程安全联系7.可重入与线程安全区…...
敏捷开发中,Sprint回顾会的目的
Sprint回顾会的主要目的是促进Scrum团队的学习和持续改进。在每个Sprint结束后,团队聚集在一起进行回顾,以达到以下目标: 识别问题: 回顾会允许团队识别在Sprint(迭代)期间遇到的问题、挑战和障碍。这有助于…...
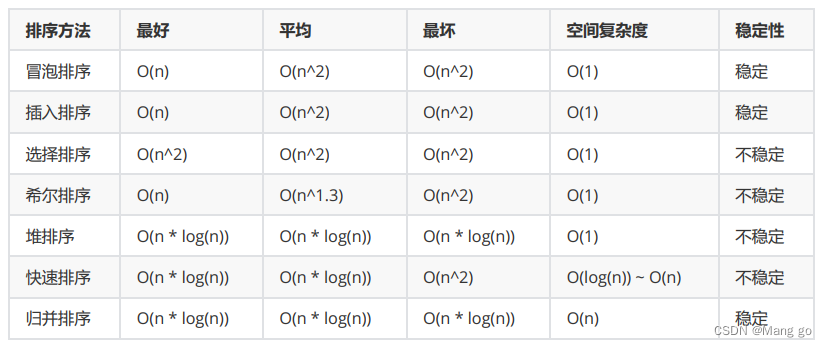
排序【七大排序】
文章目录 1. 排序的概念及引用1.1 排序的概念1.2 常见的排序算法 2. 常见排序算法的实现2.1 插入排序2.1.1基本思想:2.1.2 直接插入排序2.1.3 希尔排序( 缩小增量排序 ) 2.2 选择排序2.2.1基本思想:2.2.2 直接选择排序:2.2.3 堆排序 2.3 交换排序2.3.1冒…...

人大与加拿大女王大学金融硕士项目——立即行动,才是缓解焦虑的解药
!在这个经济飞速的发展的时代,我国焦虑症的患病率为7%,焦虑已经超越个体范畴,成为整个社会与时代的课题。焦虑,往往源于我们想要达到的,与自己拥有的所产生的差距。任何事情,开始做远比准备做更会给人带来成…...
)
老卫带你学---leetcode刷题(46. 全排列)
46. 全排列 问题: 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1:输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]示例 2&#x…...

6.6 图的应用
思维导图: 6.6.1 最小生成树 ### 6.6 图的应用 #### 主旨:图的概念可应用于现实生活中的许多问题,如网络构建、路径查询、任务排序等。 --- #### 6.6.1 最小生成树 **概念**:要在n个城市中建立通信联络网,则最少需…...

100问GPT4与大语言模型的关系以及LLMs的重要性
你现在是一个AI专家,语言学家和教师,你目标是让我理解语言模型的概念,理解ChatGPT 跟语言模型之间的关系。你的工作是以一种易于理解的方式解释这些概念。这可能包括提供 例子,提出问题或将复杂的想法分解成更容易理解的小块。现在…...
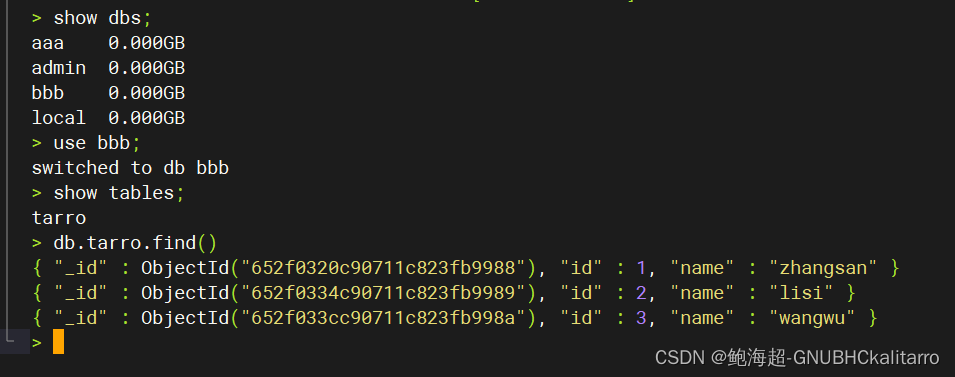
Linux:mongodb数据逻辑备份与恢复(3.4.5版本)
我在数据库aaa的里创建了一个名为tarro的集合,其中有三条数据 备份语法 mongodump –h server_ip –d database_name –o dbdirectory 恢复语法 mongorestore -d database_name --dirdbdirectory 备份 现在我要将aaa.tarro进行备份 mongodump --host 192.168.254…...
凉鞋的 Godot 笔记 109. 专题一 小结
109. 专题一 小结 在这一篇,我们来对第一个专题做一个小的总结。 到目前为止,大家应该能够感受到此教程的基调。 内容的难度非常简单,接近于零基础的程度,不过通过这些零基础内容所介绍的通识内容其实是笔者好多年的时间一点点…...
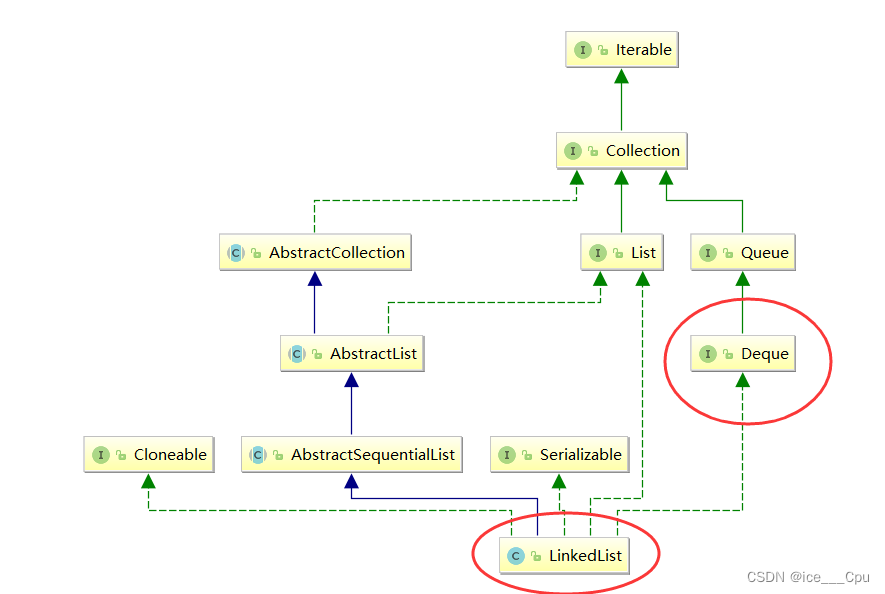
数据结构 - 4(栈和队列6000字详解)
一:栈 1.1 栈的概念 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原…...
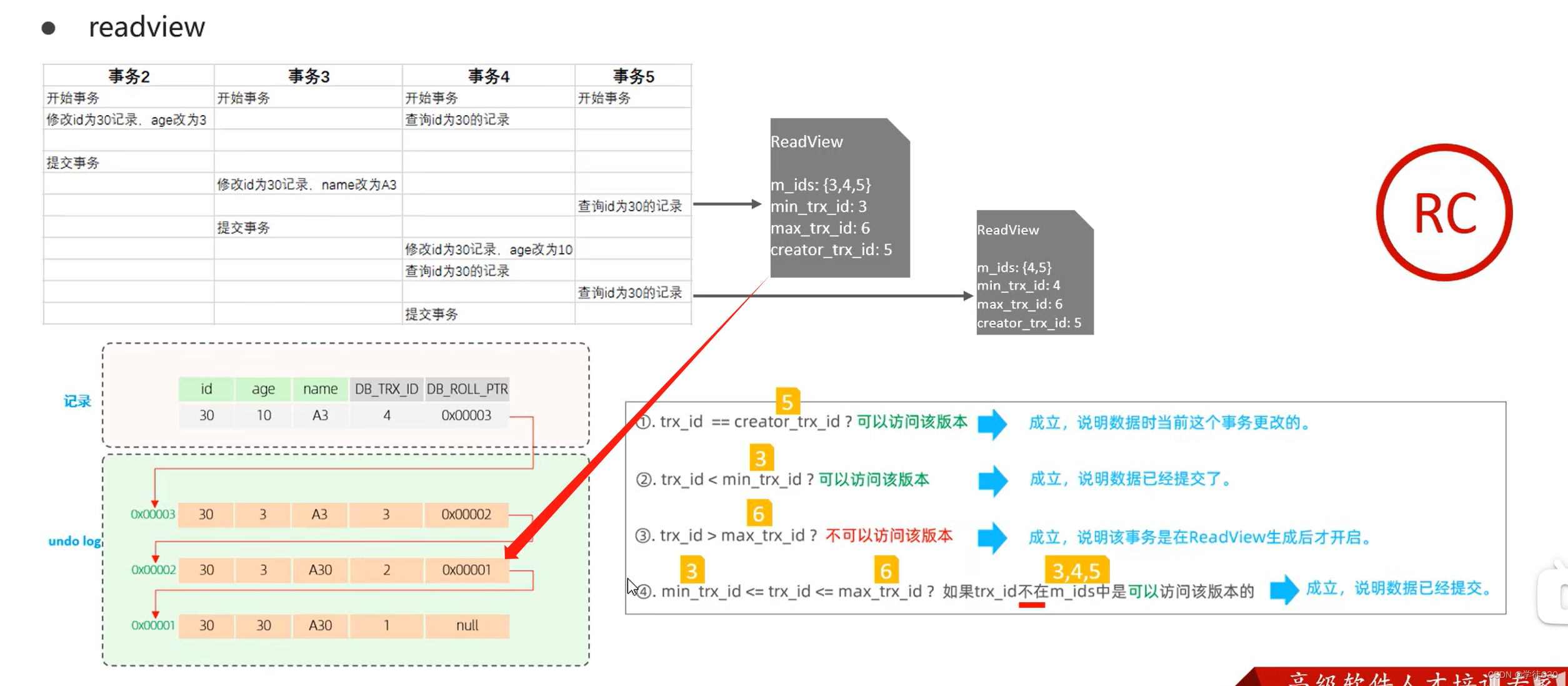
MySQL InnoDB引擎深入学习的一天(InnoDB架构 + 事务底层原理 + MVCC)
目录 逻辑存储引擎 架构 概述 内存架构 Buffer Pool Change Buffe Adaptive Hash Index Log Buffer 磁盘结构 System Tablespace File-Per-Table Tablespaces General Tablespaces Undo Tablespaces Temporary Tablespaces Doublewrite Buffer Files Redo Log 后台线程 事务原…...
TX Text Control .NET Server for ASP.NET 32.0 Crack
TX Text Control .NET Server for ASP.NET 是VISUAL STUDIO 2022、ASP.NET CORE .NET 6 和 .NET 7 支持,将文档处理集成到 Web 应用程序中,为您的 ASP.NET Core、ASP.NET 和 Angular 应用程序添加强大的文档处理功能。 客户端用户界面 文档编辑器 将功能…...

PeaZip:完全免费的跨平台压缩软件,支持200+格式的终极解决方案
PeaZip:完全免费的跨平台压缩软件,支持200格式的终极解决方案 【免费下载链接】PeaZip Free Zip / Unzip software and Rar file extractor. Cross-platform file and archive manager. Features volume spanning, compression, authenticated encryptio…...

为内部ai工具配置taotoken实现安全可控的api调用代理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部AI工具配置Taotoken实现安全可控的API调用代理 在企业内部开发AI工具或智能体(Agent)时,…...

MulimgViewer:高效多图像浏览与对比工具
MulimgViewer:高效多图像浏览与对比工具 【免费下载链接】MulimgViewer MulimgViewer is a multi-image viewer that can open multiple images in one interface, which is convenient for image comparison and image stitching. 项目地址: https://gitcode.com…...

别让格式毁了你的论文:一份给IEEE TII投稿者的Latex排版自查清单
IEEE TII投稿LaTeX排版终极自查指南:从格式合规到学术表达优化 第一次向IEEE Transactions on Industrial Informatics(TII)投稿的研究者,往往会在收到编辑的格式审查意见时感到措手不及。那些看似微不足道的标点空格、公式编号或…...

为什么你需要ZeroOmega:重新定义浏览器代理管理的新范式
为什么你需要ZeroOmega:重新定义浏览器代理管理的新范式 【免费下载链接】ZeroOmega Manage and switch between multiple proxies quickly & easily. 项目地址: https://gitcode.com/gh_mirrors/ze/ZeroOmega 在现代网络环境中,频繁切换代理…...

如何3步搭建你的私人游戏云:Sunshine游戏串流服务器终极指南
如何3步搭建你的私人游戏云:Sunshine游戏串流服务器终极指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款开源的自托管游戏串流服务器,专…...

2026黑科技对决:UWB硬件瓶颈 vs 镜像视界无感定位・跨镜追踪自由
2026黑科技对决:UWB硬件瓶颈 vs 镜像视界无感定位・跨镜追踪自由 一、UWB:厘米级精度,困在硬件里的“昂贵精准” UWB(超宽带)凭借短脉冲、宽频谱特性,在理想视距环境下可实现5–10厘米定位精度࿰…...

深入解析Ollama-for-amd:AMD GPU本地大模型部署实战指南
深入解析Ollama-for-amd:AMD GPU本地大模型部署实战指南 【免费下载链接】ollama-for-amd Get up and running with Llama 3, Mistral, Gemma, and other large language models.by adding more amd gpu support. 项目地址: https://gitcode.com/gh_mirrors/ol/ol…...

终极指南:如何用OpenHTMLtoPDF轻松生成专业级PDF文档
终极指南:如何用OpenHTMLtoPDF轻松生成专业级PDF文档 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF…...

视启未来[特殊字符]百度智能云:给大模型一双手,让AI真正触碰物理世界
如果说过去两年,大模型在数字世界里掀起了一场海啸;那么2026年,这场海啸正在以“具身智能”的形态,猛烈地拍击物理世界的海岸线。但这里却有一个“骨感”的现实:AI能写出拿普利策奖的文章,能画出媲美梵高的…...