基于深度优先搜索的图遍历
这里写目录标题
- 基于深度优先搜索的无向图遍历
- 算法流程图
- Python实现
- Java实现
- 基于深度优先搜索的有向图遍历
- Python实现
基于深度优先搜索的无向图遍历
使用深度优先搜索遍历无向图,将无向图用邻接表存储:
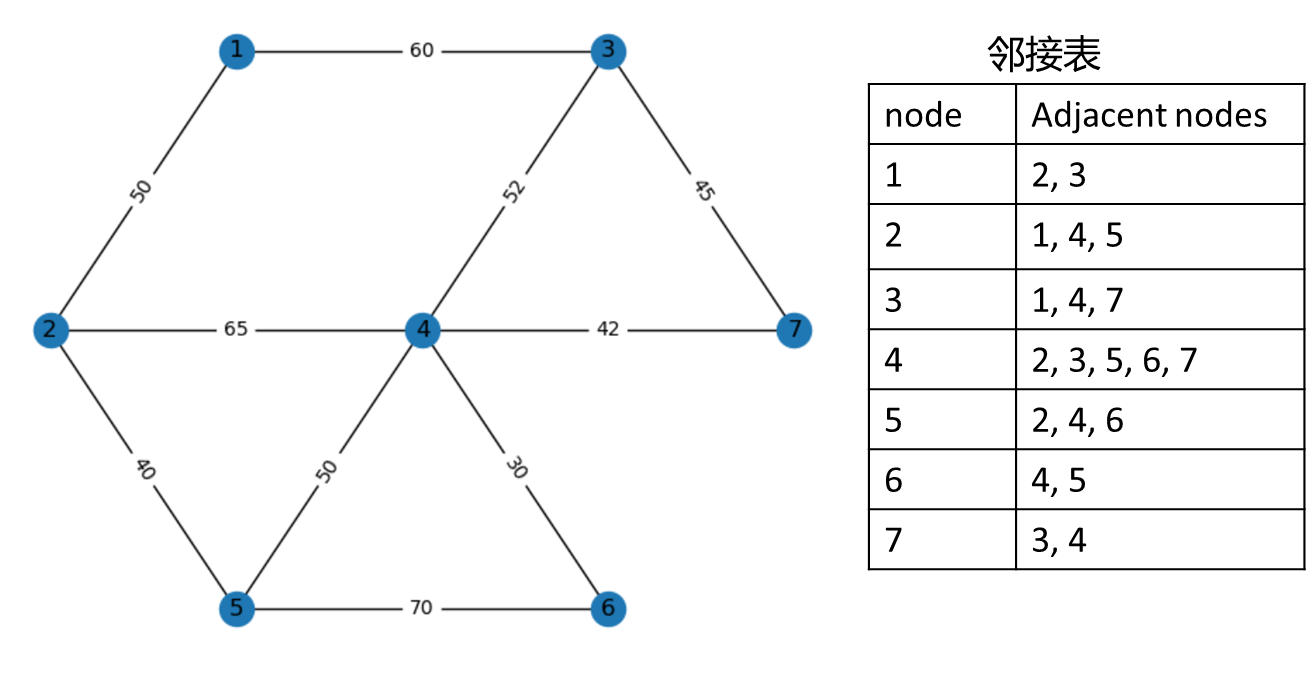
算法流程图
- 初始化起点 source,当前节点v为起点,终点 target,路径path为空,路径集合 paths 为空
- 将当前节点v添加到 path 中
- 判断当前节点v是否为终点,是转step4,否转step5
- 保存 path 至 paths 中,转step7
- 获取当前节点的所有邻接点,用集合N表示
- 遍历N,若 N_i 不在 path 中,令v=N_i ,转step2;若N_i 在path 中,i +=1。
- 删除 path 中最后一个节点,令v=path中最后一个节点,转step5
- 以上步骤遍历了所有每一个点的邻接点,算法结束,输出起点到终点的所有路径paths
Python实现
from typing import Listdef dfs(adjacent_list, source, target):""":param adjacent_list: 邻接表:param source: 起点:param target: 终点:return: 起点-终点的所有路径"""def dfs_helper(adjacent_list, source, current_node, target):path.append(current_node) # 压栈if current_node == target:paths.append(path.copy())else:neighbors = adjacent_list[current_node]for neighbor in neighbors:if neighbor not in path:dfs_helper(adjacent_list, source, neighbor, target)path.pop() # 弹栈paths = []path = []dfs_helper(adjacent_list, source, source, target)return pathsif __name__ == "__main__":# 邻接表adjacent_list = {1: [2, 3],2: [1, 4, 5],3: [1, 4, 7],4: [2, 3, 5, 6, 7],5: [2, 4, 6],6: [4, 5],7: [3, 4]}# 深搜paths: List[List] = dfs(adjacent_list, 1, 6)[print(path) for path in paths]Java实现
package org.example;import java.util.*;public class DepthFirstSearch {// List<Integer> path = new ArrayList<>();Stack<Integer> path = new Stack<>();List<List<Integer>> paths = new ArrayList<>();void dfs(Map<Integer, List<Integer>> adjacent_list, int source, int current_node, int target) {path.push(current_node);if (current_node == target) {paths.add(new ArrayList<>(path));path.remove(path.size() - 1);} else {List<Integer> neighbors = adjacent_list.get(current_node);for (Integer neighbor : neighbors) {if (!path.contains(neighbor)) {dfs(adjacent_list, source, neighbor, target);}}path.pop();}}public static void main(String[] args) {Map<Integer, List<Integer>> adjacent_list = new HashMap<>();adjacent_list.put(1, Arrays.asList(2, 3));adjacent_list.put(2, Arrays.asList(1, 4, 5));adjacent_list.put(3, Arrays.asList(1, 4, 7));adjacent_list.put(4, Arrays.asList(2, 3, 5, 6, 7));adjacent_list.put(5, Arrays.asList(2, 4, 6));adjacent_list.put(6, Arrays.asList(4, 5));adjacent_list.put(7, Arrays.asList(3, 4));System.out.println(adjacent_list);DepthFirstSearch dfs = new DepthFirstSearch();dfs.dfs(adjacent_list, 1, 1, 6);for (List<Integer> path : dfs.paths) {System.out.println(path);}}
}基于深度优先搜索的有向图遍历
和无向图遍历一样,建立邻接矩阵即可。
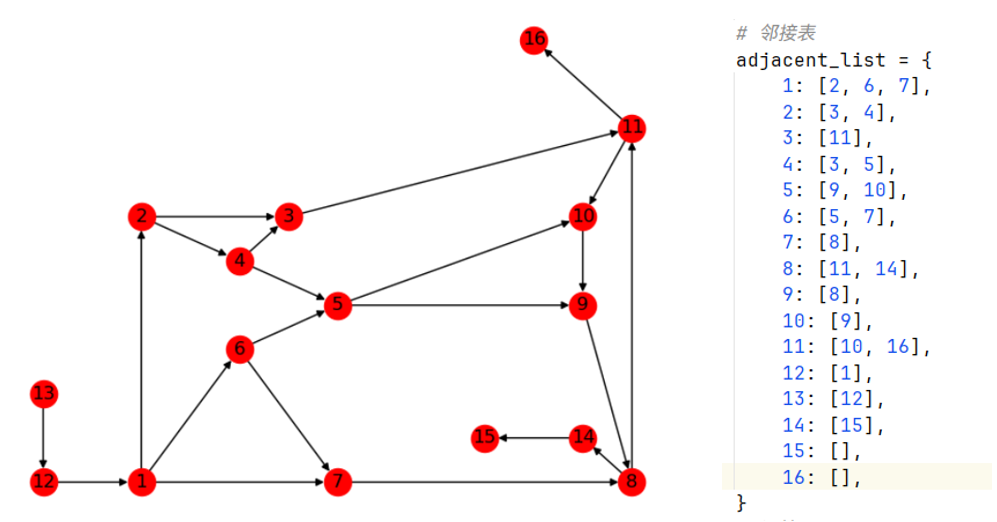
Python实现
from typing import List, Tuple, Any, Dict
import networkx
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from typing import Listdef paint_topological_graph(nodes,edges: List[Tuple],coordinates: Dict[Any, Tuple] = None,directed=False):print(nodes)print(edges)print(coordinates)graph = networkx.DiGraph() if directed else networkx.Graph() # 全连通 有向图graph.add_nodes_from(nodes)graph.add_edges_from(edges)networkx.draw(graph, pos=coordinates, with_labels=True, node_color='red', )plt.show()print(networkx.has_path(graph, 1, 12))return graphdef dfs(adjacent_list, source, target):""":param adjacent_list: 邻接表:param source: 起点:param target: 终点:return: 起点-终点的所有路径"""def dfs_helper(adjacent_list, source, current_node, target):path.append(current_node)if current_node == target:paths.append(path.copy())path.pop()else:neighbors = adjacent_list[current_node]for neighbor in neighbors:if neighbor not in path:dfs_helper(adjacent_list, source, neighbor, target)path.pop()paths = []path = []dfs_helper(adjacent_list, source, source, target)return pathsif __name__ == "__main__":# 点坐标node_coord = {1: (1, 0), 2: (1, 3), 3: (2.5, 3), 4: (2, 2.5), 5: (3, 2), 6: (2, 1.5), 7: (3, 0), 8: (6, 0), 9: (5.5, 2),10: (5.5, 3), 11: (6, 4), 12: (0, 0), 13: (0, 1), 14: (5.5, 0.5), 15: (4.5, 0.5), 16: (5, 5),}edges = [(13, 12), (1, 2), (2, 4), (2, 3), (4, 3), (4, 5), (1, 6), (1, 7), (6, 7), (6, 5), (7, 8), (5, 9), (5, 10),(3, 11), (11, 10), (9, 8), (10, 9), (8, 11), (14, 15), (8, 14), (12, 1), (11, 16),]# 画图paint_topological_graph(nodes=np.arange(1, 17, 1),edges=edges,directed=True,coordinates=node_coord)# 邻接表adjacent_list = {1: [2, 6, 7],2: [3, 4],3: [11],4: [3, 5],5: [9, 10],6: [5, 7],7: [8],8: [11, 14],9: [8],10: [9],11: [10, 16],12: [1],13: [12],14: [15],15: [],16: [],}# 深搜paths: List[List] = dfs(adjacent_list, 1, 11)[print(path) for path in paths]相关文章:
基于深度优先搜索的图遍历
这里写目录标题 基于深度优先搜索的无向图遍历算法流程图Python实现Java实现 基于深度优先搜索的有向图遍历Python实现 基于深度优先搜索的无向图遍历 使用深度优先搜索遍历无向图,将无向图用邻接表存储: 算法流程图 初始化起点 source,当…...

Web3D虚拟人制作简明指南
如何在线创建虚拟人? 虚拟人,也称为数字化身、虚拟助理或虚拟代理,是一种可以通过各种在线平台与用户进行逼真交互的人工智能人。 在线创建虚拟人变得越来越流行,因为它为个人和企业带来了许多好处。 通过虚拟助理或代理,您可以以更具吸引力和个性化的方式与客户或受众进…...
:基本概念、创建表)
【大数据 - Doris 实践】数据表的基本使用(一):基本概念、创建表
数据表的基本使用(一):基本概念、创建表 1.创建用户和数据库2.Doris 中数据表的基本概念2.1 Row & Column2.2 Partition & Tablet 3.建表实操3.1 建表语法3.2 字段类型3.3 创建表3.3.1 Range Partition3.3.2 List Partition 1.创建用…...
剑指Offer || 038.每日温度
题目 请根据每日 气温 列表 temperatures ,重新生成一个列表,要求其对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 1: 输入: temperatures…...
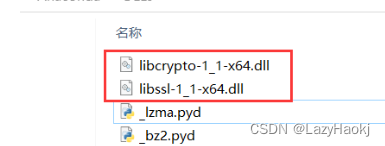
URL because the SSL module is not available
Could not fetch URL https://pypi.org/simple/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host‘pypi.org’, port443): Max retries exceeded with url: /simple/pip/ (Caused by SSLError(“Can’t connect to HTT PS URL because the…...
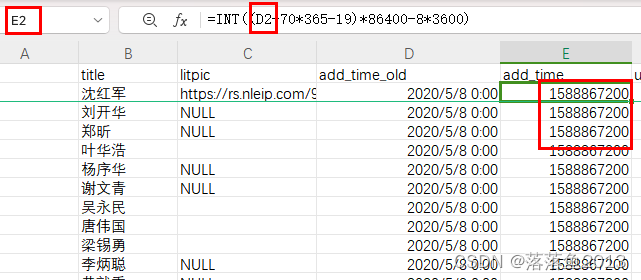
excel 日期与时间戳的相互转换
1、日期转时间戳:B1INT((A1-70*365-19)*86400-8*3600)*1000 2、时间戳转日期:A1TEXT((B1/10008*3600)/8640070*36519,"yyyy-mm-dd hh:mm:ss") 以上为精确到毫秒,只精确到秒不需要乘或除1000。 使用以上方法可以进行excel中日期…...

MongoDB中的嵌套List操作
前言 MongoDB区别Mysql的地方,就是MongoDB支持文档嵌套,比如最近业务中就有一个在音频转写结果中进行对话场景,一个音频中对应多轮对话,这些音频数据和对话信息就存储在MongoDB中文档中。集合结构大致如下 {"_id":234…...
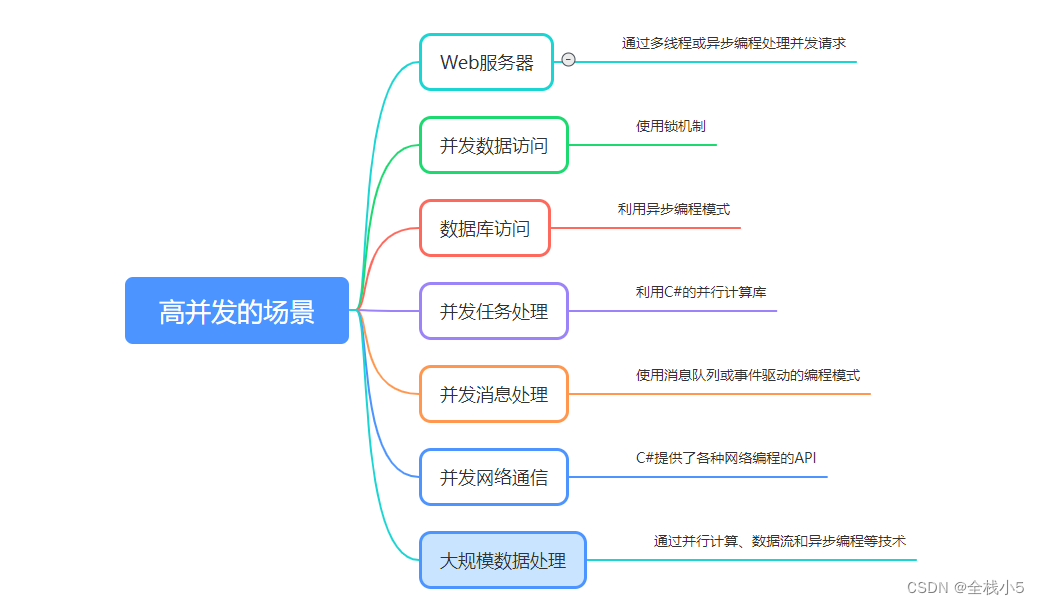
【C#】什么是并发,C#常规解决高并发的基本方法
给自己一个目标,然后坚持一段时间,总会有收获和感悟! 在实际项目开发中,多少都会遇到高并发的情况,有可能是网络问题,连续点击鼠标无反应快速发起了N多次调用接口, 导致极短时间内重复调用了多次…...
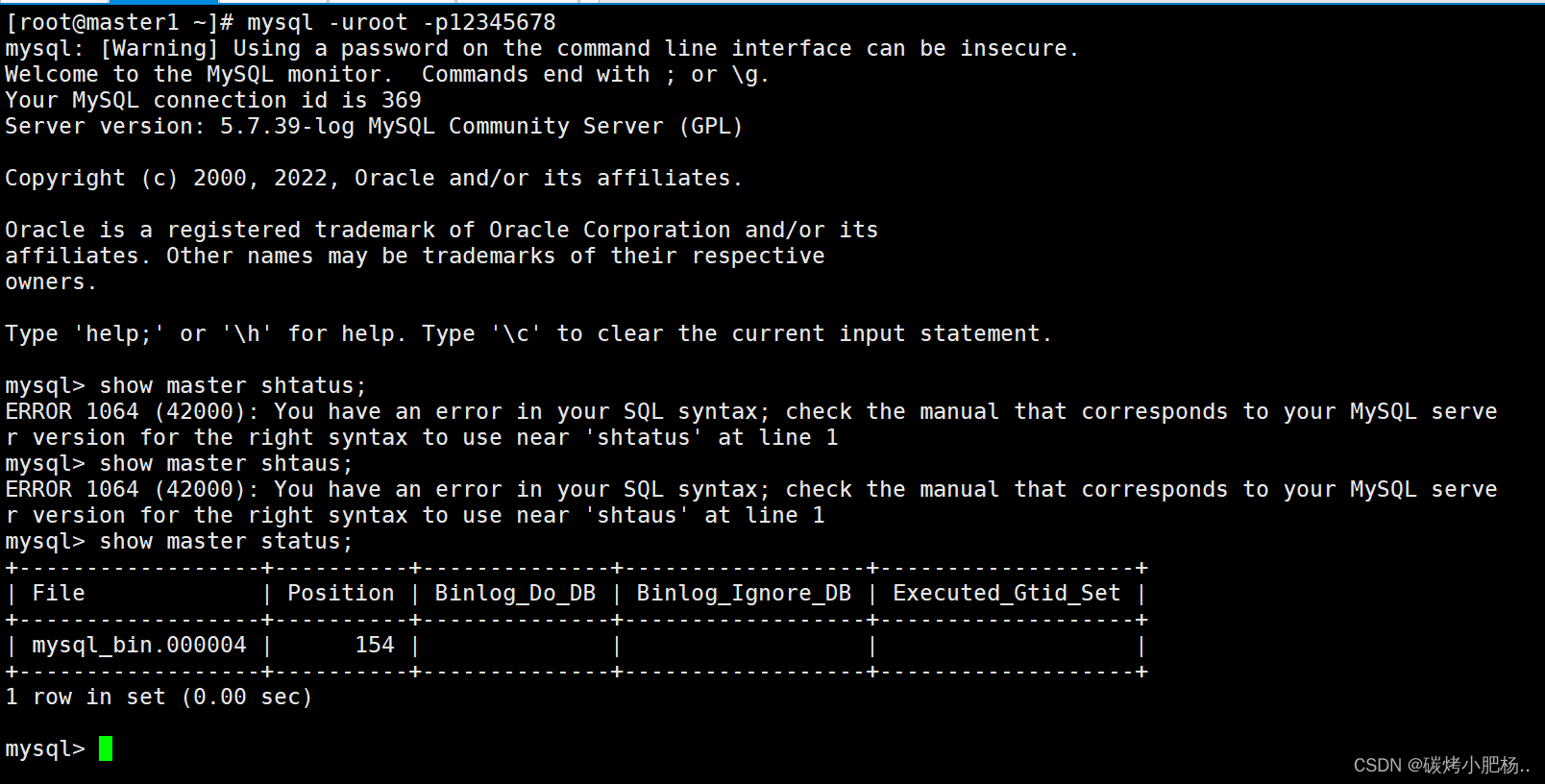
MySQL双主一从高可用
MySQL双主一从高可用 文章目录 MySQL双主一从高可用环境说明1.配置前的准备工作2.配置yum源 1.在部署NFS服务2.安装主数据库的数据库服务,并挂载nfs3.初始化数据库4.配置两台master主机数据库5.配置m1和m2成为主数据库6.安装、配置keepalived7.安装部署从数据库8.测…...

#力扣:2894. 分类求和并作差@FDDLC
2894. 分类求和并作差 - 力扣(LeetCode) 一、Java class Solution {public int differenceOfSums(int n, int m) {return (1n)*n/2-n/m*(mn/m*m)/2;} } 二、C class Solution { public:int differenceOfSums(int n, int m) {return (1n)*n/2-n/m*(mn…...
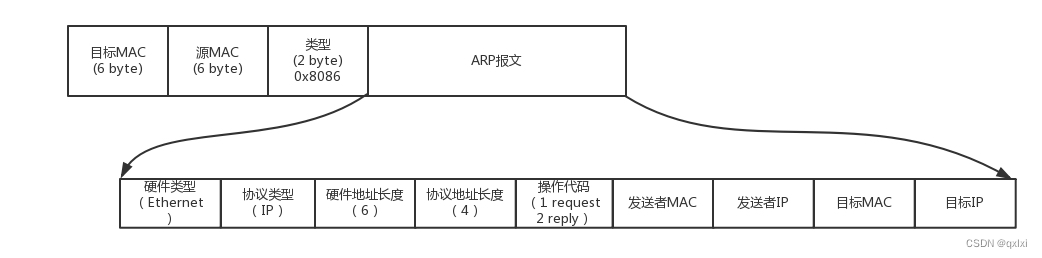
【网络协议】聊聊从物理层到MAC层 ARP 交换机
物理层 物理层其实就是电脑、交换器、路由器、光纤等。组成一个局域网的方式可以使用集线器。可以将多台电脑连接起来,然后进行将数据转发给别的端口。 数据链路层 Hub其实就是广播模式,如果A电脑发出一个包,B、C电脑也可以收到。那么数据…...
WordPress插件 WP-PostViews 汉化语言包
WP-PostViews汉化语言包 WP-PostViews是一款很受欢迎的文章浏览次数统计插件,记录每篇文章展示次数、根据展示次数显示历史最热或最衰的文章排行、展示范围可以是全部文章和页面,也可以是某些目录下的文章和页面。本文还介绍了一些隐藏的功能࿰…...
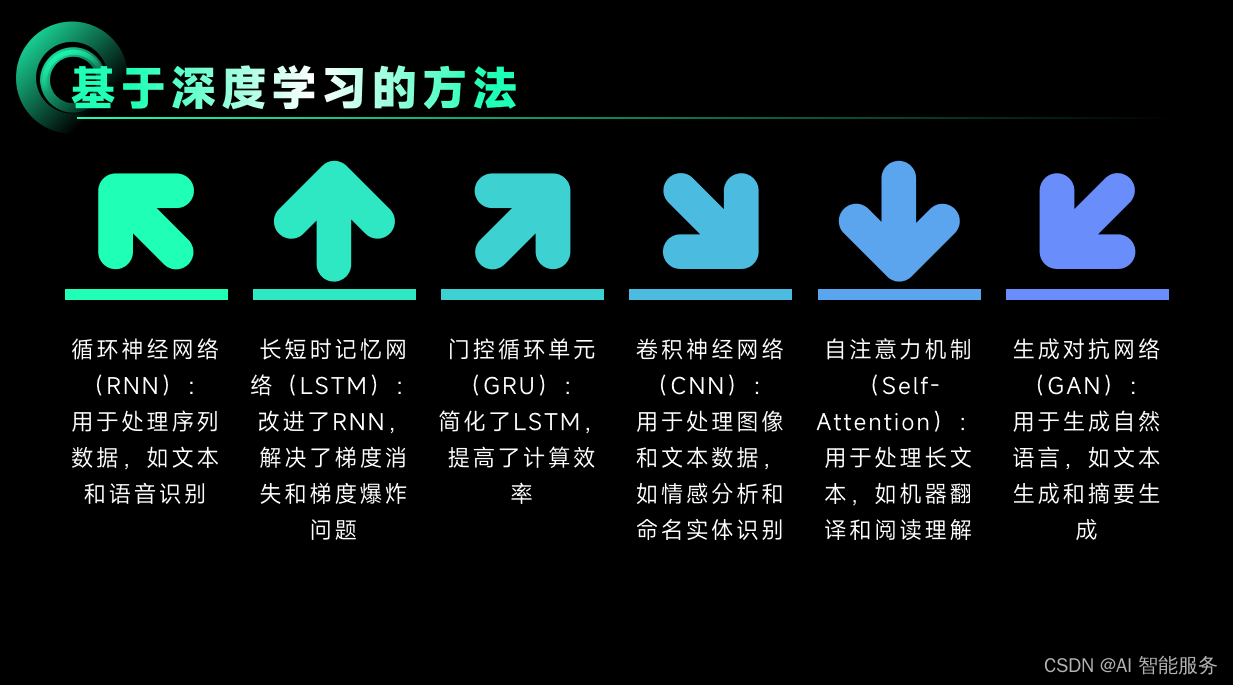
基础课2——自然语言处理
1.概念 自然语言处理(Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。 自然语言处理的主要研究方向包括: 语言学研究&…...

有趣的GPT指令
1 从现在开始,你的回答必须把所有字替换emoji,并保持原来的含义。你不能使用任何汉字或英文。如果有不适当的词语,将它们替换成对应的emoji。下面是一个例子: 原文:爷吐啦 翻译:👴ὃ…...

小样本学习--(1)概论
目录 一、概述 二、小样本学习的数据集 1、Omniglot 2、MiniimageNet 三、孪生网络 四、三元组损失函数 一、概述 小样本学习用于处理训练数据集中样本数量少的情况,一般来说,小样本学习流程是这样的,从一个多种类少量样本的巨大数据集…...
数据结构之手撕顺序表(讲解➕源代码)
0.引言 在本章之后,就要求大家对于指针、结构体、动态开辟等相关的知识要熟练的掌握,如果有小伙伴对上面相关的知识还不是很清晰,要先弄明白再过来接着学习哦! 那进入正题,在讲解顺序表之前,我们先来介绍…...

小微企业是怎样从客户管理系统中获益的?
大企业普遍拥有成熟的客户管理系统,而对小微企业而言,客户管理系统的重要性更为突出。这是因为小微企业管理相对薄弱,资源有限,人力资金需要更加精细化的管理。那么,小微企业如何从客户管理系统中获益? 一…...

mysql整库备份表结构和数据
命令 mysqldump -P 端口 -h 主机 -u 用户名 -p 数据库 > xxxxbak.sql 将导出数据库的表结构及数据(建表语句和insert语句) 举例 mysqldump -P 3306 -h 100.120.56.23 -u my_username-p sys > system-230510.sql...
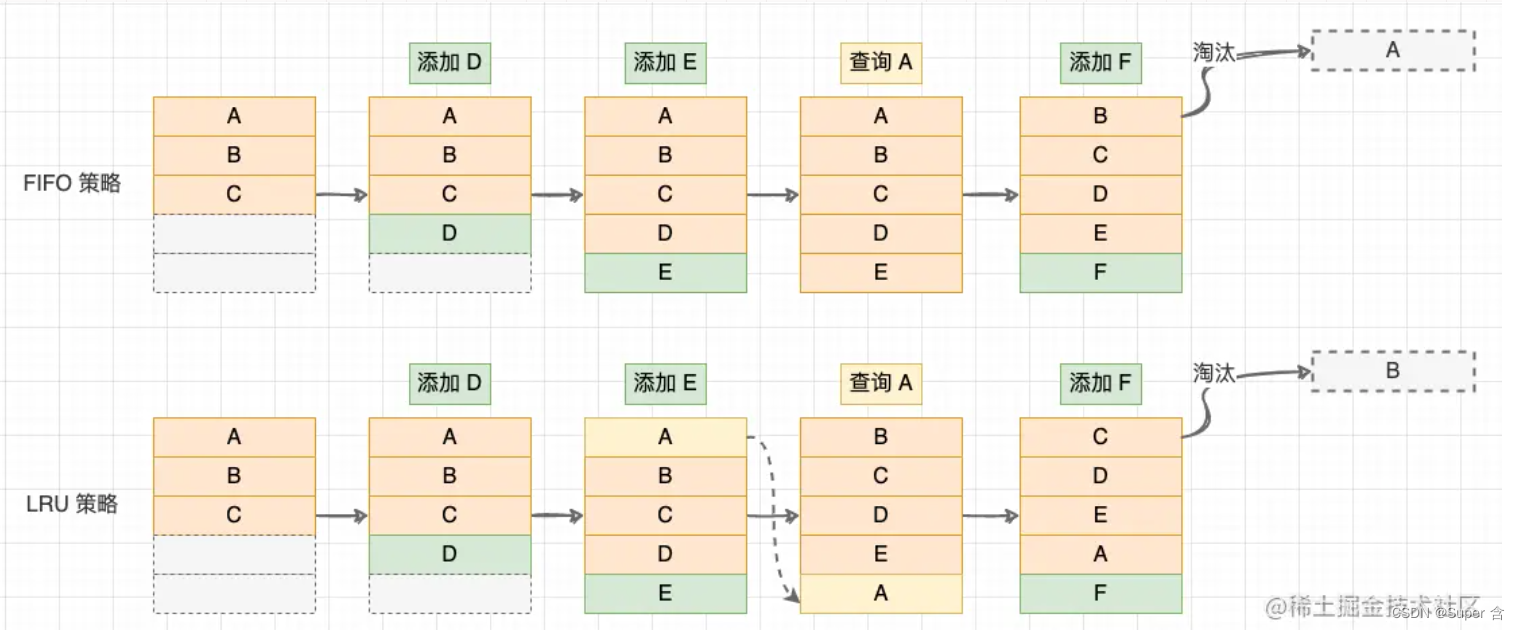
LinkedHashMap与LRU缓存
序、慢慢来才是最快的方法。 背景 LinkedHashMap 是继承于 HashMap 实现的哈希链表,它同时具备双向链表和散列表的特点。事实上,LinkedHashMap 继承了 HashMap 的主要功能,并通过 HashMap 预留的 Hook 点维护双向链表的逻辑。 1.缓存淘汰算法…...

2023大联盟6比赛总结
比赛链接 反思 A 为什么打表就我看不出规律!!! 定式思维太严重了T_T B 纯智障分块题,不知道为什么 B 100 B100 B100 比理论最优 B 300 B300 B300 更优(快了 3 倍),看来分块还是要学习一…...

OpenHTMLtoPDF:Java生态下的专业级HTML转PDF解决方案
OpenHTMLtoPDF:Java生态下的专业级HTML转PDF解决方案 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF…...
)
别再乱用sleep了!Linux C++高精度延时实战指南(从usleep到std::sleep_for的避坑总结)
Linux C高精度延时实战:从传统陷阱到现代方案 在开发高性能服务器、嵌入式实时系统或音视频处理程序时,精确控制时间延迟是保证系统稳定性和响应速度的关键。许多开发者在使用sleep、usleep等延时函数时,常常遇到CPU占用率飙升、时序漂移或信…...

3种简单方法解决Navicat Premium Mac试用期重置难题
3种简单方法解决Navicat Premium Mac试用期重置难题 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 你是否正在为Navicat Pre…...

高校生必备的AI论文写作软件有哪些?
国内高校学生普遍使用的AI论文写作工具,以功能全面的本土化软件为主,结合通用大模型与专业辅助工具,覆盖选题构思、框架搭建、初稿撰写、内容降重、查重检测、格式排版等关键环节,以下是主流工具详解与对比: 一、本土全…...

如何构建专业级电子签名:现代前端解决方案指南
如何构建专业级电子签名:现代前端解决方案指南 【免费下载链接】smooth-signature H5带笔锋手写签名,支持PC端和移动端,任何前端框架均可使用 项目地址: https://gitcode.com/gh_mirrors/smo/smooth-signature 在数字化办公时代&#…...

OpenHarmony 5.0.3兼容性认证实战:BQ3576HM开发板全栈移植与调优
1. 项目概述:一次关键的“兼容性认证”实战最近,我们团队基于贝启科技的BQ3576HM开发板套件,成功通过了OpenHarmony 5.0.3 Release版本的兼容性测评。这听起来像是一个简单的“通过测试”的新闻,但对于真正在一线做OpenHarmony设备…...

AI 编码循环验证关卡:结构背压比智能代理更优,Shen-Backpressure 来助力!
结构背压优于智能代理:用 Shen-Backpressure 为 AI 编码循环设验证关卡2026 年 5 月 18 日,一些最严重的软件漏洞往往不起眼,访问控制漏洞仍是 [OWASP 十大安全风险中的头号问题](https://owasp.org/Top10/2025/A01_2025-Broken_Access_Contr…...
)
软件工程师在智能体视觉时代的机遇(22)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

终极量化数据获取指南:3步掌握pywencai高效获取同花顺问财数据
终极量化数据获取指南:3步掌握pywencai高效获取同花顺问财数据 【免费下载链接】pywencai 获取同花顺问财数据 项目地址: https://gitcode.com/gh_mirrors/py/pywencai 在量化投资和金融数据分析领域,获取精准、实时的A股市场数据一直是技术开发者…...

Google I/O 2026发布Gemini 3.5 Flash:性能超越3.1 Pro,输出速度快4倍!
Google在I/O 2026上正式发布Gemini 3.5 Flash,这是其最新一代结合前沿智能与行动能力的模型系列,在多项基准测试中表现出色,输出token速度更是其他前沿模型的4倍。 性能卓越 3.5 Flash定位为迄今最强的Agentic和编程模型,在Termin…...