Hadoop3教程(十三):MapReduce中的分区
文章目录
- (96) 默认HashPartitioner分区
- (97) 自定义分区案例
- (98)分区数与Reduce个数的总结
- 参考文献
(96) 默认HashPartitioner分区
分区,是Shuffle里核心的一环,不同分区的数据最终会被送进不同的ReduceTask去处理。之前的几个小节里也都讲过分区。
Hadoop里默认的分区方式是HashPartitioner分区,核心代码:
public class HashPartitioner<K, V> extends Partitioner<K, V> {public int getPartition(K key, V value, iint numReduceTasks) {return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;}
}
在HashPartitioner里,每个key分到哪个ReduceTask(可以理解成Key属于哪个分区),是根据每个key的hashCode对ReduceTask的个数取模得到的,用户是没法控制的。
这里是为什么还要& Integer.MAX_VALUE呢?
主要是为了防止溢写,通过& Integer.MAX_VALUE,将key的hash值控制在Integer.MAX_VALUE及之下。
从代码里看,在往环形缓冲区写的时候,如果识别到numReduceTasks > 1,则启用HashPartitioner分区,如果numReduceTasks = 1,那就不启用了,直接return numReduceTasks - 1。
我们也可以自定义Partitioner,自定义类需要继承Partitioner类,并重写里面的getPartition()方法。
public class CustomPartitioner extendsPartitioner<Text, FlowBean>{@overridepublic int getPartition(Text key, FlowBean value, int numPartitions){//控制分区代码逻辑。。。。。。return partition;}}
然后在驱动类里,设置上写好的自定义Partitioner:
job.setPartitionerClass(CustomPartitioner.class);
最后再设置上ReduceTask的数量:
job.setNumReduceTasks(5);
如果不设置ReduceTask的数量,那分区数默认是1,直接return 0,不会启用自定义分区。
(97) 自定义分区案例
首先抛出一个需求:将一堆手机号按照归属地的省份输出到不同的文件里。
已有一个phone_data.txt文件。
所以期望的输出数据是什么样子的呢?
手机号136/137/138/139开头的分别放进4个独立的文件里,然后其他的手机号放到一个文件里。最终形成5个文件。
显而易见,这个需求的核心在于自定义分区上。
所以我们需要写一个自定义分区类,假设它叫ProvincePartitioner,我们希望它能做到以下分配:
136 分区0
137 分区1
138 分区2
139 分区3
其他 分区4
等分区类建好后,别忘记在驱动里注册上这个类,并定义好ReduceTask数量。
job.setPartitionerClass(ProvincePartitioner.class);
job.setNumReduceTasks(5);
展示一下ProvincePartitioner类的代码:
package com.atguigu.mapreduce.partitioner;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;public class ProvincePartitioner extends Partitioner<Text, FlowBean> {@Overridepublic int getPartition(Text text, FlowBean flowBean, int numPartitions) {//获取手机号前三位prePhoneString phone = text.toString();String prePhone = phone.substring(0, 3);//定义一个分区号变量partition,根据prePhone设置分区号int partition;if("136".equals(prePhone)){partition = 0;}else if("137".equals(prePhone)){partition = 1;}else if("138".equals(prePhone)){partition = 2;}else if("139".equals(prePhone)){partition = 3;}else {partition = 4;}//最后返回分区号partitionreturn partition;}
}
(98)分区数与Reduce个数的总结
思考这么一个问题,如果自定义Partitioner中定义了5个分区,但是驱动类里注册的时候,只声明了4个分区,即job.setNumReduceTask=4,那这时候代码会正常运行么?
不会,会报java.io.IOException。
至于为什么报IO异常,自然是MapTask中,在往环形缓冲器Collector里写的时候,发现没有第5个分区,写不进去当然就报IO异常。
但是,设置job.setNumReduceTask=1,代码是可以跑的,这是为什么呢?
原因其实之前提过,这是因为设置为1后,MapTask里,Collector在collect数据的时候,分区就不走我们自定义的Partitioner,而是直接return 0了,到最后Reduce阶段也只会生成一个文件。
这里是有点反直觉的,需要注意。
那我如果job.setNumReduceTask=6呢,代码还能跑吗?
可以跑,且会生成6个文件,只不过第6个文件是空的。
总结一下:
- 当NumReduceTask > getPartition()里定义的分区数量,可以正常运行,但是相应的,会多余生成一些空的文件,浪费计算资源和存储资源;
- 当 1 < NumReduceTask < getPartition()分区量,会报IO异常,因为少的那一部分分区的数据会无法写入;
- 当NumReduceTask = 1时,不会调用自定义分区器,而是会将所有的数据都交付给一个ReduceTask,最后也只会生成一个文件。
- 自定义分区类时,分区号必须从0开始,且必须是连续的,即是逐一累加的。
最后一条比较重要,即必须是0/1/2/3/4/5/…这种形式,而不能是0/10/11/20这种。
2023-7-24 17:08:08 我有个小问题,就是驱动类里设置setNumReduceTask的时候,能不能设置成动态的,就是根据输入数据调整的呢?
查了一下,确实是有这种取巧的方式,比如说使用自定义的InputFormat,在读取数据的同时,获取数据量的情况,并根据这些信息动态调整ReduceTask的数量。这里就不多讲了,有兴趣可以查查。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
:MapReduce中的分区)
Hadoop3教程(十三):MapReduce中的分区
文章目录 (96) 默认HashPartitioner分区(97) 自定义分区案例(98)分区数与Reduce个数的总结参考文献 (96) 默认HashPartitioner分区 分区,是Shuffle里核心的一环…...
笔记本Win10系统一键重装操作方法
笔记本电脑已经成为大家日常生活和工作中必不可少的工具之一,如果笔记本电脑系统出现问题了,那么就会影响到大家的正常操作。这时候就可以考虑给笔记本电脑重装系统了。接下来小编给大家介绍关于一键重装Win10笔记本电脑系统的详细步骤方法。 推荐下载 系…...

FilterRegistrationBean能不能排除指定url
文章目录 什么是FilterRegistrationBean举个栗子但是如果我想要排除某些uri方法总结FilterRegistrationBean只能设置指定的url进行过滤,而不能指定排除uri,只能使用OncePerRequestFilter的shouldNotFilter方法,排除uri 什么是FilterRegistrationBean FilterRegistrationBean是…...
【LeetCode】36. 有效的数独
1 问题 请你判断一个 9 x 9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。 数字 1-9 在每一行只能出现一次。 数字 1-9 在每一列只能出现一次。 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图&…...
华为---PPP协议简介及示例配置
PPP协议简介 PPP是Point-to-Point Protocol的简称,中文翻译为点到点协议。与以太网协议一样,PPP也是一个数据链路层协议。以太网协议定义了以太帧的格式,PPP协议也定义了自己的帧格式,这种格式的帧称为PPP帧。 利用PPP协议建立的二层网络称为…...
asp.net老年大学信息VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio计算机毕业设计
一、源码特点 asp.net老年大学信息管理系统是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver2008,使用c# 语言开发 asp.net老年大学信息管理系统…...
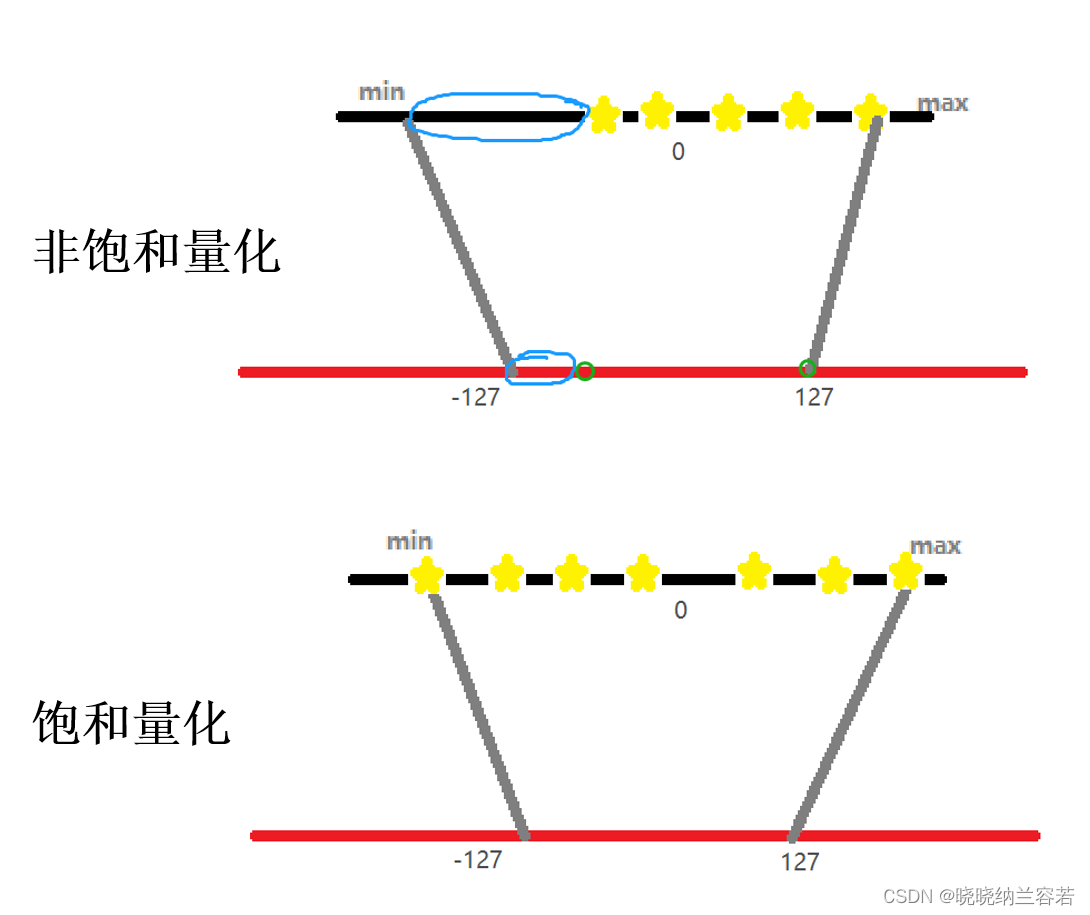
模型量化笔记--对称量化和非对称量化
1–量化映射 量化映射的通用公式为: r S ( q − Z ) r S(q - Z) rS(q−Z) 其中r表示量化前数据的真实值,S表示缩放因子,q表示量化后的数值,Z表示零点 2–非对称量化 非对称量化需要一个偏移量Z来完成零点的映射,即量化前的零…...

PA2019 Terytoria
洛谷P5987 [PA2019] Terytoria 题目大意 在一个平面直角坐标系上,有一个长度为 X X X,宽度为 Y Y Y的地图,这个地图的左边界和右边界是连通的,下边界和上边界也是连通的。 在地图中,有 X Y X\times Y XY个格子以及…...

内容分发网络CDN分布式部署真的可以加速吗?原理是什么?
Cdn快不快?她为什么会快?同样的带宽为什么她会快?原理究竟是什么,同学们本着普及知识的想法,我了解的不是很深入,适合小白来看我的帖子,如果您是大佬还请您指正错误的地方,先谢谢大佬…...
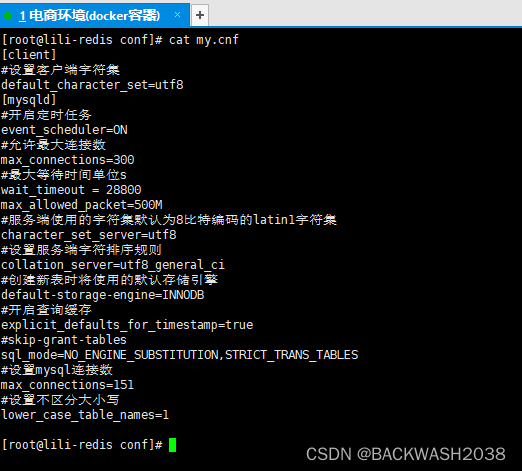
微服务docker部署实战
docker基础和进阶(*已掌握的可以跳过 *) 基础 docker基础 进阶 docker进阶 准备工作 提前准备好mysql和redis的配置,如下 在/zzq/mysql/conf目录下配置mysql配置文件my.cnf [client] #设置客户端字符集 default_character_setutf8 [mysqld] #开启定时任务 event_s…...

js实现拖拽功能
基于onMouseDown 、onMouseMove 、onMouseUp 使用 mousedown、mousemove 和 mouseup 事件来实现拖拽的基本思路是: 在 mousedown 事件中,开始追踪拖拽操作并记录鼠标按下的位置。 在 mousemove 事件中,根据鼠标的移动,更新被拖拽…...

数据库主从切换过程中Druid没法获取连接错误
背景: 今天dba在进行DB的主从切换,导致应用一直报错,获取不到DB连接,druid的错误信息如下: Could not open JDBC Connection for transaction; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutExc…...
【iOS】Mac M1安装iPhone及iPad的app时设置问题
【iOS】Mac M1安装iPhone及iPad的app时设置问题 简介一,设置问题二,适配问题 简介 由于 苹果M1芯片的Mac可用安装iPhone以及iPad应用,因为开发者并没有适配Mac,因此产生了很多奇怪问题,这里总结归纳Mac M1安装iPhone和…...
Springboot 启动报错@spring.active@解析错误
Caused by: org.yaml.snakeyaml.scanner.ScannerException: while scanning for the next token found character that cannot start any token. (Do not use for indentation)in reader, line 10, column 13:active: spring.active^查看是否勾选...

【算法挨揍日记】day15——560. 和为 K 的子数组、974. 和可被 K 整除的子数组
560. 和为 K 的子数组 560. 和为 K 的子数组 题目描述: 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的连续子数组的个数 。 子数组是数组中元素的连续非空序列。 解题思路: 我们可以很容易想到暴力解法…...

数字时代的探索与革新:Socks5代理的引领作用
在当今快速发展的数字时代,技术创新推动着社会的变革与进步。Socks5代理作为一项重要的网络技术,正引领着跨界电商、爬虫数据分析、企业全球化和游戏体验优化等领域的发展。本文将深入探讨Socks5代理技术在这些领域中的引领作用,以及它如何塑…...
算法-堆/归并排序-排序链表
算法-堆/归并排序-排序链表 1 题目概述 1.1 题目出处 https://leetcode.cn/problems/sort-list/description/?envTypestudy-plan-v2&envIdtop-interview-150 1.2 题目描述 2 优先级队列构建大顶堆 2.1 思路 优先级队列构建小顶堆链表所有元素放入小顶堆依次取出堆顶…...
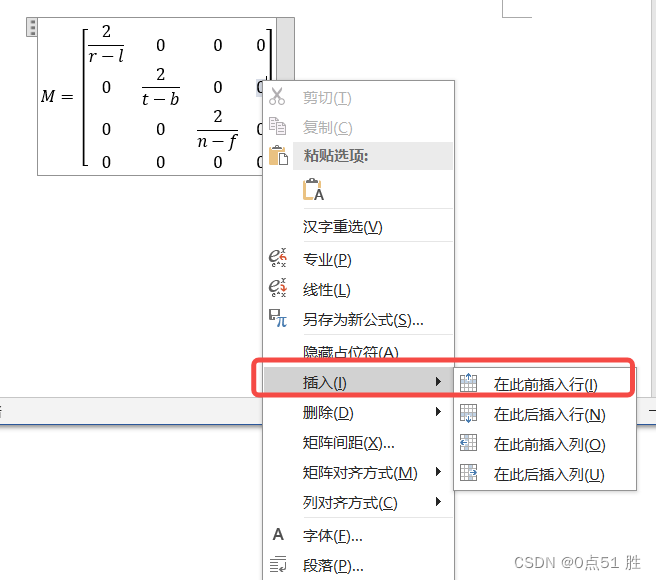
word 如何编写4x4矩阵
百度上给的教程,打印出来没有对齐 https://jingyan.baidu.com/article/6b182309995f8dba58e159fc.html 百度上的方式试了一下,不会对齐。导致公式看起来很奇怪。 下面方式会自动对齐 摸索了一下发现可以用下面这种方式编写 4x4 矩阵。先创建一个 3x3…...
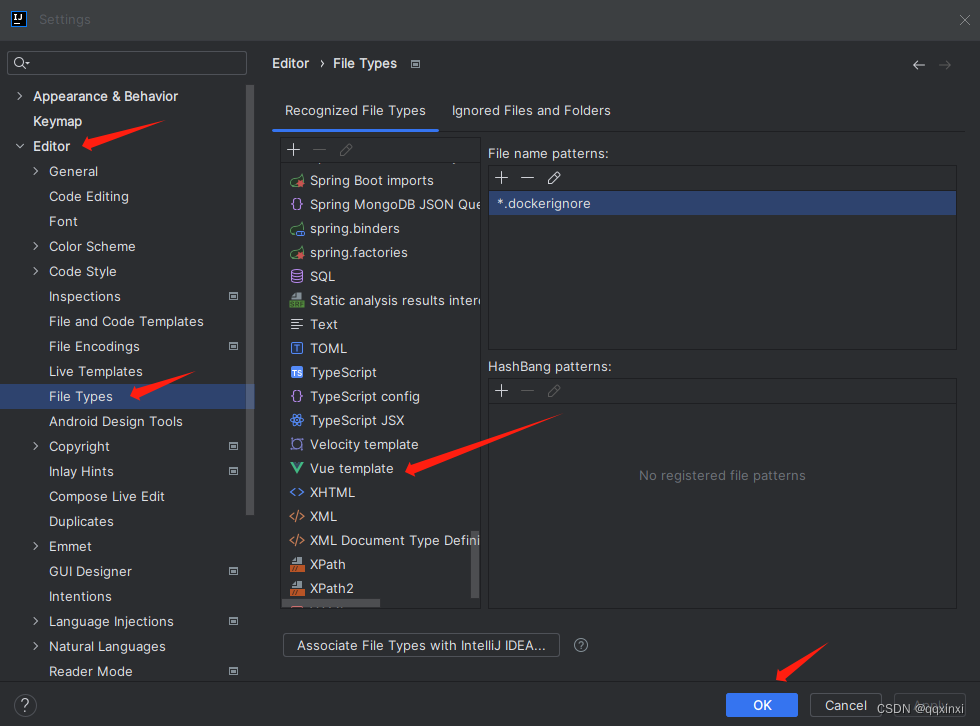
INTELlij IDEA编辑VUE项目
菜单中选择setting–>Plugins 或者快捷键 ctrlalts 搜索vue,但有些情况会搜索不出来,先说搜索到的情况 如下图所示: 如果没有vue.js则说明过去已经安装了。 搜索到了后点击Install安装即可, 但即使搜索成功了,也不…...
linux进程间通讯--信号量
1.认识信号量 方便理解:信号量就是一个计数器。当它大于0能用,小于等于0,用不了,这个值自己给。 2.特点: 信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。信号量基于操作系统的 PV 操作&am…...

NoFences桌面整理工具:5步打造高效整洁的Windows桌面
NoFences桌面整理工具:5步打造高效整洁的Windows桌面 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上杂乱无章的图标而烦恼吗?NoF…...

独角数卡支付系统:如何构建高可用的自动售货支付解决方案
独角数卡支付系统:如何构建高可用的自动售货支付解决方案 【免费下载链接】dujiaoka 🦄独角数卡(自动售货系统)-开源站长自动化售货解决方案、高效、稳定、快速!🚀🚀🎉🎉 项目地址: https://g…...

2026年238个好发CCF-A的强化学习idea全面汇总!
最近强化学习领域迎来重磅进展!强化学习之父R.S.Sutton 提出了一种全新的范式:Intentional Updates机制!其不再盲目预设步长,而是先设定一个预期的输出改变目标,实现了内存消耗降低10-100倍的同时,性能依然…...

CANN/asc-devkit asc_any函数
asc_any 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

从Wi-Fi信号到降噪耳机:聊聊‘相位’在工程师日常调试中的那些事儿
从Wi-Fi信号到降噪耳机:聊聊‘相位’在工程师日常调试中的那些事儿 调试设备时突然出现的信号干扰,或是降噪耳机里挥之不去的底噪,往往让工程师们头疼不已。这些看似无关的问题背后,其实都藏着一个共同的关键因素——相位。不同于…...

c# 简单记录一下我学习的过程 2026.5.20
这一节有几个内容, 分别为方法返回值,方法值传递 ref out in 参数 以及params 参数列表。 接下来我会记录我对他们的理解。1.方法返回值 return有了return 你就可以把方法里面的值拿出来继续用 2.方法值传递分为两种 一个是值传递 一…...

51单片机IO口不够用?试试用PCF8574模块驱动LCD1602,I2C接口省下6个引脚
51单片机IO资源紧张?PCF8574模块驱动LCD1602的实战指南 当你用51单片机开发项目时,是否遇到过这样的困境:传感器、按键、通信接口已经占用了大部分IO口,而显示模块却无处安放?传统驱动LCD1602需要6-8个IO引脚ÿ…...

Tauri + GitHub Actions 自动化打包指南:如何为你的桌面应用配置跨平台自动更新
Tauri GitHub Actions 自动化打包与更新体系构建指南 当你的Tauri应用从开发阶段进入产品化阶段时,如何确保用户能够无缝获取最新功能和安全更新,成为影响产品体验的关键因素。本文将带你构建一个完整的自动化打包与更新体系,从签名机制到发…...

当 SpringBoot 请求踏上“七层之旅”:OSI 模型与你的每一行代码
你在 Controller 里写了一个 GetMapping,浏览器敲下回车,数据就回来了。 可你有没有想过,这短短几十毫秒里,你的数据经历了多少次“变装”和“安检”? 从 HTTP 报文到 TCP 段,再到 IP 包、以太网帧——每一…...

YOLOv8模型家族全解析:P2、P6、标准版到底该选哪个?一张图帮你搞定选择困难症
YOLOv8模型家族全解析:P2、P6、标准版到底该选哪个? 在计算机视觉项目的初期,模型选型往往是最令人头疼的环节。面对GitHub仓库中琳琅满目的YAML配置文件,即便是经验丰富的工程师也难免陷入选择困难。YOLOv8作为当前最先进的目标检…...