数据结构----算法--排序算法
数据结构----算法–排序算法
一.冒泡排序(BubbleSort)
1.冒泡排序的核心思想
相邻两个元素进行大小比较,如果前一个比后一个大,就交换
注意:
在冒泡排序的过程中,促进了大的数往后去,小的数往前去
2.冒泡排序的实现步骤
1.从头开始将相邻两个元素进行大小比较,如果前一个比后一个大,就交换,直到全部比较完成,固定最右边的值(此时固定的就是最大的值)
2.重复操作1,直到最后剩一个元素了,排序结束
3.看下图冒泡排序的过程,加深理解

4.冒泡排序的代码实现如下
void BubbleSort(int a[],int length) {if (a == NULL || length <= 0) return;for (int i = 0; i < length -1; i++) {for (int j = 0; j < length -1-i; j++) {if (a[j] > a[j + 1]) {a[j] = a[j] ^ a[j + 1];a[j + 1] = a[j] ^ a[j + 1];a[j] = a[j] ^ a[j + 1];}}}
}void Print(int a[], int length) {if (a == NULL || length <= 0) return;for (int i = 0; i < length; i++) {cout << a[i] << " ";}cout << endl;
}int main() {int a[] = { 3,11,9,2,16,8,20,28,31,44 };BubbleSort(a,sizeof(a)/sizeof(a[0]));//将排好序的数组进行输出Print(a,sizeof(a)/sizeof(a[0]));cout << endl;return 0;
}
5.冒泡排序的优化

我们发现第二趟完事之后,这个数组就已经有序了,我们就不需要再进行下面几次的操作了
1.优化的思路
我们在进行冒泡排序时,每一趟都找到最后交换的位置,那下一趟的右端范围到最后交换位置之前就可以了(用这种方法优化之后冒泡排序所需要的次数一般都会大幅减少),如果没有交换发生,就说明此数组已经有序了
2.对上面优化方法的两种实现方式
方式一:通过改变总趟数(改变总趟数的同时每一次的范围也会进行改变)来进行代码的优化(此方法需要用到数学进行计算),下面为方法一要注意的一些问题
当缩小范围(减少趟数)的时候,也就是对第一个循环进行的操作,我们控制的是左端点,右端点不动,并且通过数学的计算得出每次左端点要变为 数组长度 - 最后交换的位置在数组中的下标所得的值
方式二:通过直接对范围进行修改(不用管趟数,因为当当前范围中没有发生交换,那么冒泡排序就会结束)
3.优化的代码如下(这里用方法一实现)
#include<iostream>
using namespace std;void BubbleSort(int a[],int length) {if (a == NULL || length <= 0) return;int flag = 0;for (int i = 0; i < length -1; i++) {//总趟数flag = 0;for (int j = 0; j < length -1-i; j++) {//每趟的范围if (a[j] > a[j + 1]) {a[j] = a[j] ^ a[j + 1];a[j + 1] = a[j] ^ a[j + 1];a[j] = a[j] ^ a[j + 1];flag = j + 1;}}if (flag == 0) break;//如果没有交换发生,就说明此数组已经有序了,结束操作i = length - flag - 1;//这里多减了一个一是因为每一次循环i都会自增1}
}void Print(int a[], int length) {if (a == NULL || length <= 0) return;for (int i = 0; i < length; i++) {cout << a[i] << " ";}cout << endl;
}int main() {int a[] = { 3,9,2,11,8,16,20,28,31,44 };BubbleSort(a, sizeof(a) / sizeof(a[0]));//将排好序的数组进行输出Print(a, sizeof(a) / sizeof(a[0]));return 0;
}
二.选择排序(SelectSort)
1.选择排序的核心思想
每趟找最值放入到对应位置上(整体要保持一致性要找最大就只能找最大,反则亦然)
2.选择排序的实现步骤
1.假设数组的第一个元素就是最大值,此时最大值的下标为0,然后依次进行比较,如果遇到大的数,那么最大值的下标进行更新,直到所有的元素都比较完成了,将最大值与数组最右边的数进行互换(如果最大值的下标就是数组最右边元素的下标,那么就不交换),固定数组最右边的元素(之后此位置就不参与比较了)
2.重复操作1,直到数组中只剩一个元素了,排序结束
3.选择排序的代码实现如下
#include<iostream>
using namespace std;void SelectSort(int a[], int length) {if (a == NULL || length <= 0) return;int i;int j;for ( i= 0; i < length - 1; i++) {int MaxIndex = 0;for (j = 0; j < length - i-1; j++) {//与最值进行比较if (a[MaxIndex] <= a[j]) {MaxIndex = j;}}//将最值放到数组的最右边(通过交换实现的)if (MaxIndex != j-1) {//如果最大值的下标不是数组最右边元素的下标,进行交换a[MaxIndex] = a[j-1] ^ a[MaxIndex];a[j-1] = a[j-1] ^ a[MaxIndex];a[MaxIndex] = a[j-1] ^ a[MaxIndex];}}
}void Print(int a[], int length) {if (a == NULL || length <= 0) return;for (int i = 0; i < length; i++) {cout << a[i] << " ";}cout << endl;
}int main() {int a[] = { 9,1,3,7,98,58,15,4,45,5,2131,23 };SelectSort(a, sizeof(a) / sizeof(a[0]));//将排好序的数组进行输出Print(a, sizeof(a) / sizeof(a[0]));return 0;
}
三.插入排序(InsertSort)
1.插入排序的核心思想
将待排序数据分为两部分,一部分无序,一部分有序,将无序元素依次插入到有序中去,完成排序
2.插入排序的适用场合
1.元素很少的时候(元素小于16时就认为元素很少)
2.每个元素在排序前的位置距排好序的最终位置不远的时候
3.插入排序的实现步骤
注意:插入排序过程中没有交换
1.申请两个标记变量,一个指向有序的最后一个,另一个指向无序的第一个元素(最开始时我们把数组第一个元素看成是有序的,其他的元素是无序的,所以最开始有序的标记变量指向的是数组的第一个元素,无序的标记变量指向的是数组的第二个元素),再申请一个临时变量,临时变量用来存每一次要进行操作的无序元素(防止无序的这个元素被覆盖)
2.插入无序元素
(1)遍历无序的元素
(2)插入每一个无序的元素时进行倒叙遍历有序数组
如果遍历到的元素的值小于无序值,那么无序值就放到当前元素的下一个位置上继续遍历无序的元素(此时无序的标记变量向后移一位,有序元素的标记指向的位置变为无序标记的指向的位置的前一位,)
如果遍历到的元素的值大于无序值,那么当前元素后向右移一位,继续倒叙遍历有序数组
如果遍历到了边界(也就是数组的起始元素),那么该无序元素变为有序元素的第一个,继续倒叙遍历有序数组
4.插入排序的代码实现如下
#include<iostream>
using namespace std;void InsertSort(int a[],int length) {int yesIndex = 0;int noIndex = 1;int temp = a[noIndex];//依次插入无序while (noIndex < length&& yesIndex>=-1) {if (yesIndex == -1) {a[0] = temp;noIndex++;yesIndex = noIndex - 1;temp = a[noIndex];}if (a[yesIndex] > temp) {a[yesIndex+1] = a[yesIndex];yesIndex--;}else {a[yesIndex+1] = temp;noIndex++;yesIndex = noIndex - 1;temp = a[noIndex];}}}int main() {int a[] = { 5,1,856,6,32,14,7,9,77 };InsertSort(a, sizeof(a) / sizeof(a[0]));for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++) {cout << a[i] << " ";}return 0;
}
四.希尔排序(ShellSort)(也叫缩小增量排序)
希尔排序可以理解成放大版的插入排序
1.希尔排序的实现步骤
1.定间隔(造图时用的时二分,实际生产应用中会和斐波那契数列有关系这里我们用二分来确定间隔)
(1)初始定间隔:我们用数组的总长度除以2得到的结果向下取整,然后我们以此结果作为间隔,执行第二步
(2)重新定间隔:间隔变为间隔减半的结果向下取整(这里除2了,但是真正使用的时候不是除2的)执行第二步
2.将数组中的元素根据间隔进行分组(例如如果所得的间距为6,那么下标为0的就和下标为6的一组,下标为1的就和下标为7的一组)
3.各组内进行插入排序
4.如果排序还没有完成的话,(我们需要重新定间隔,重新分组),从第一步的(2)重新开始
如果排序完成,结束
2.希尔排序的时间复杂度
希尔排序的时间复杂度是无法计算的,一般会有一个范围在n的1.2次方到n的1.5次方,我们一般取n的1.3次方
五.计数排序(CountingSort)
1.计数排序的核心思想
核心思想基于非比较
2.计数排序的使用场合
数据是有范围的(分配比较密集),数据重复出现次数比较多
3.计数排序的实现步骤
1.先遍历一遍数组找到该数组的最大值和最小值
2.申请一个计数数组,它的长度是上一步找的最大值和最小值的差值+1,并将计数数组所有元素初始化为0
3.遍历原数组,进行计数
遍历到的每一个元素的值减去步骤1中获得的最小值作为计数数组的下标,然后计数数组的对应下标进行+1操作,以此实现计数
4.放回操作
遍历计数数组,当遍历到的计数数组的元素不为0时,将当前元素所在的下标加上步骤1中获得的最小值得到的值依次放回到原数组中(覆盖操作)
4.计数排序的代码如下
#include<iostream>using namespace std;void CountingSort(int a[],int length) {//找到最大值和最小值int min = a[0];int max = a[0];for (int i = 0; i < length; i++) {if (min > a[i]) {min = a[i];}if (max < a[i]) {max = a[i];}}//申请array数组用来计数int* array = (int*)malloc(sizeof(int) * (max - min + 1));memset(array, 0, sizeof(int)*(max - min+1));//用array数组进行计数for (int i = 0; i < length; i++) {array[a[i] - min]++;}//开始排序,放回int t = 0;for (int i = 0; i < max - min + 1 ; i++) {while (array[i]) {a[t] = i + min;t++;array[i]--;}}
}void Print(int a[], int length) {if (a == NULL || length <= 0) return;for (int i = 0; i < length; i++) {cout << a[i] << " ";}cout << endl;
}int main() {int a[] = { 2,9,4,1,8,9,3,1,4,7,6,9,4 };CountingSort(a, sizeof(a) / sizeof(a[0]));Print(a, sizeof(a) / sizeof(a[0]));return 0;
}
5.计数排序的优化
1.为什么要进行优化
因为如果元素是结构体的话,比如学生这个结构体,包括学生分数,学生姓名,学号等等,那么我们没进行优化之前只能把学生分数进行排序,那么就会出现信息不匹配的问题,所以我们要进行优化,优化的方法就是再申请一个数组,在这个数组中进行排序(此数组复制了一份原来数组中的元素),然后将排好序的元素放回到原数组中
2.优化的计数排序实现的步骤
1.先遍历一遍数组找到该数组的最大值和最小值
2.申请一个计数数组,它的长度是上一步找的最大值和最小值的差值+1,并将计数数组所有元素初始化为0
3.遍历原数组,进行计数
遍历到的每一个元素的值减去步骤1中获得的最小值作为计数数组的下标,然后计数数组的对应下标进行+1操作,以此实现计数
4.遍历一遍计数数组,计算名次
计数数组中的每一个元素都跟前一个元素相加,依次来得到名次
(同分并列的,记录的名次是最后一次出现的名次)
5.申请一个新数组,在这个新数组中进行排序
倒叙遍历原数组,遍历到的每一个元素减去第一步中的最小值获得的值以找到每一个元素在计数数组中的位置,然后获得该元素的名次,从而找到它在新数组中的位置,最后复制这个元素到该位置(注意,每次获得名次后,该名次应进行减1操作,为了下一次有相同值的元素,能够继续成功排序)
6.排好序的元素,放回到原数组中
7.释放申请的空间
3.优化的计数排序的代码如下
#include<iostream>
using namespace std;void CountingSort(int a[],int length) {//找到最大值和最小值int min = a[0];int max = a[0];for (int i = 0; i < length; i++) {if (min > a[i]) {min = a[i];}if (max < a[i]) {max = a[i];}}//申请array数组用来计数int* array = (int*)malloc(sizeof(int) * (max - min + 1));memset(array, 0, sizeof(int)*(max - min+1));//用array数组进行计数for (int i = 0; i < length; i++) {array[a[i] - min]++;}//排名次for (int i = 1; i < max - min + 1; i++) {array[i] += array[i - 1];}//申请一个新空间int* Temp = (int*)malloc(sizeof(int) * length);memset(Temp, 0, sizeof(int) * (max - min + 1));//倒叙遍历原数组,进行排序for (int i = length - 1; i >= 0; i--) {Temp[array[a[i] - min] - 1] = a[i];array[a[i] - min]--;}//放回for (int i = 0; i < length; i++) {a[i] = Temp[i];}//释放free(Temp);Temp = NULL;free(array);array = NULL;
}int main() {int a[] = { 2,9,4,1,8,9,3,1,4,7,6,9,4 };CountingSort(a, sizeof(a) / sizeof(a[0]));for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++) {cout << a[i] << " ";}return 0;
}
六.快速排序(QuickSort)
1.快速排序的核心思想
找一个标准值,将比标准值小的都放在其左侧,比标准值大的,都放在其右侧,根据标准值将数据分割成两部分,两部分分别重复以上操作
2.快速排序实现的方法是挖坑填补法
操作步骤如下:
1.选定标准值(标准值在某些算法里也叫枢轴),然后保存一下标准值,此处变为坑(注意这里我们选择数组的首元素作为标准值)
2.从右向左找比标准值小的,找到填入到前面的坑中,此处变为坑
从左向右找比标准值大的,找到之后填到后面的坑中,此处变为坑
直到从右向左和从左向右相遇的时候,此操作结束,此位置就是标准值的位置,放入标准值
3.根据标准值的部分,将这组数据分为两部分,左部分从起始位置到标准值左边的位置,右部分从标识值右边的位置到结束位置,然后将这两部分重新进行操作(注意如果某一部分只有一个元素或者没有元素那么就不用进行操作了,因为如果只有一个元素那它一定是有序的,而如果没有元素那就根本不需要进行排序)
3.快速排序的代码如下
#include<iostream>
using namespace std;int Sort(int arr[],int begin, int end) {int temp = arr[begin];while (begin< end) {//从右向左找比标记值小的元素while (begin < end) {if (arr[end] < temp) {//填入左侧坑arr[begin] = arr[end];begin++;break;}end--;}//从左向右找比标记值大的元素while (begin < end) {if (arr[begin] > temp) {//填入右侧坑arr[end] = arr[begin];end--;break;}begin++;}}//将标准值放入arr[begin] = temp;return begin;}void QuickSort(int arr[], int begin, int end) {if (arr == NULL || begin >= end) return;//标准值int standard;standard = Sort(arr, begin, end);//拆分QuickSort(arr, begin, standard - 1);QuickSort(arr, standard + 1, end);
}void Print(int a[], int length) {if (a == NULL || length <= 0) return;for (int i = 0; i < length; i++) {cout << a[i] << " ";}cout << endl;
}int main() {int a[] = { 5,6,9,74,5,2,3,84,39,6,21,65,1,77 };int begin = 0;int end = sizeof(a) / sizeof(a[0]);QuickSort(a, begin, end - 1);//遍历Print(a, sizeof(a) / sizeof(a[0]));return 0;
}4.快速排序的另一种实现方法区间分割法
1.此方法的好处
较于挖空填补法能够使程序编译期的所用时间变短
2.此方法的操作步骤如下:
1.选定标准值(标准值在某些算法里也叫枢轴),然后保存一下标准值(注意这里我们选择数组的尾元素作为标准值)
2.申请一个小空间变量,存的是小于标准值元素(小空间)的最后的那个下标(最开始的值是起始位置-1所得到的值)
3.从小空间最后的那个下标的下一个元素,遍历,如果遍历到的元素比标准值小的话,那么元素与小空间最后的那个元素的下一个元素进行交换,小空间变量进行+1操作,当遍历完所有元素(除最后的那个元素)之后,最后的那个元素(标准值)与小空间最后的那个元素的下一个元素进行交换,小空间变量进行+1操作
4.根据标准值的部分,将这组数据分为两部分,左部分从起始位置到标准值左边的位置,右部分从标识值右边的位置到结束位置,然后将这两部分重新进行操作(注意如果某一部分只有一个元素或者没有元素那么就不用进行操作了,因为如果只有一个元素那它一定是有序的,而如果没有元素那就根本不需要进行排序)
3.此方法代码如下
#include<iostream>
using namespace std;int Sort(int arr[], int begin, int end) {int small = begin - 1;//遍历for (begin; begin < end; begin++) {//比较if (arr[begin] < arr[end]) {//小区间扩张if (++small != begin) {arr[small] = arr[small] ^ arr[begin];arr[begin] = arr[small] ^ arr[begin];arr[small] = arr[small] ^ arr[begin];}}}//放入if (++small != end) {arr[small] = arr[small] ^ arr[end];arr[end] = arr[small] ^ arr[end];arr[small] = arr[small] ^ arr[end];}return small;
}void QuickSort(int arr[], int begin, int end) {if (arr == NULL || begin >= end) return;//标准值int standard;standard = Sort(arr, begin, end);//拆分QuickSort(arr, begin, standard - 1);QuickSort(arr, standard + 1, end);
}int main() {int a[] = { 5,6,9,74,5,2,3,84,39,6,21,65,1,77 };int begin = 0;int end = 14;QuickSort(a, begin, end - 1);//遍历for (int i = 0; i < 14; i++) {cout << a[i] << " ";}return 0;
}
5.快速排序的的优化(基于挖坑填补法和区间分割法的优化)
1.标准值选取的优化
1.如何进行标准值的选取
方法一
3选1(选起始位置,中间位置,结束位置,然后找到三者中的中间值作为标准值)
方法二(适用于数据量大的)
9选1(选九个位置,然后每三个再选一个中间值,然后得到的这三个中间值作为一组再在其中选一个中间值作为标准值)
2.针对于数据比较大,且标准值重复率很高时使用的优化
1.如何进行优化
将标准值进行聚集
2.如何进行聚集
如果遍历到的元素的值和标准值一样大的话,就放在最前面/最后面的位置上,最后确定完标准值的位置之后,将这些元素放到标准值左侧/右侧,形成聚集
3.当数据元素分割到较少的时候使用插入排序(元素<16时认为元素较少)
6.快速排序的再次优化
1.采用循环+额外存储空间的方式取代快排时的递归
2.使用尾递归(了解)
7.数据有序对于快排来说是最坏的场合
七.归并排序(MergeSort)
1.归并排序的核心思想
将多个有序数组进行合并
2.归并排序的实现步骤
1.找到数组中间位置
2.根据中间位置进行拆分,使其变成有序的
左半部分从起始部分到中间位置
右半部分从中间向右一位的位置到结束位置
注意:某一部分中的元素只有一个时,那这一部分就是有序的
3.将两个有序的部分合并
注意:这里我们会申请数组,进行元素的处理,当全部处理完成后,我们把处理完的元素放入到原数组中
(1)从头开始遍历两个部分,进行比较,谁小谁先放进申请的数组中
(2)当有一个部分遍历完成后,看另外一部分是否遍历完成,没完成就将还没遍历的部分放进数组中
(3)把在申请的数组中处理完的元素放入到原数组中
3.代码如下
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
void Sort(int arr[],int res[],int begin, int end) {if (begin == end) {res[0] = arr[begin];return;}int mid = (begin + end) >> 1;int* res1 = (int*)malloc(sizeof(int) * (mid - begin + 1));memset(res1, 0, sizeof(int) * (mid - begin + 1));int* res2 = (int*)malloc(sizeof(int) * (end - mid));memset(res1, 0, sizeof(int) * (end - mid));Sort(arr, res1, begin, mid);Sort(arr, res2, mid+1, end);//合并int i = 0;int index1 = 0;int index2 = 0;int mid1 = mid;while (begin <= mid1 && end >= mid + 1) {if (res1[index1] < res2[index2]) {res[i] = res1[index1];i++;begin++;index1++;}else {res[i] = res2[index2];i++;mid++;index2++;}}if (begin > mid1) {for (int j = index2; j <= end-mid1+1; j++) {res[i] = res2[j];i++;}}if (mid + 1 > end) {for (int j = index1; j <= mid1; j++) {res[i] = res1[j];i++;}}//释放空间free(res1);free(res2);
}void MergeSort(int arr[],int begin,int end) {if (arr == NULL||begin >= end) return;//申请一个数组int* a = (int*)malloc(sizeof(int) * (end - begin + 1));memset(a, 0, sizeof(int) * (end - begin + 1));//排序Sort(arr,a,begin,end);for (int i = begin; i <= end; i++) {arr[i] = a[i];}free(a);
}void Print(int a[], int length) {if (a == NULL || length <= 0) return;for (int i = 0; i < length; i++) {printf("%d ", a[i]);}printf("\n");
}int main() {int a[] = { 1,57,56,3,23,4,65,123,19,46,88,5};int begin = 0;int end = sizeof(a) / sizeof(a[0]);MergeSort(a, begin, end-1);Print(a, end);return 0;
}
八.堆排序(HeapSort)
1.堆排序的功能
堆排序可以动态维护一组数据内的最值
2.堆的分类
1.大顶堆
定义
在整棵二叉树中,父亲和左右孩子三者中,父亲都是最大值,就被称为大顶堆
2.小顶堆
定义
在整棵二叉树中,父亲和左右孩子三者中,父亲都是最小值,就被称为小顶堆
3.堆排序的实现步骤
注意:
堆排序中我们用到了完全二叉树的一些逻辑,一颗完全二叉树按照从上到下从左至右从0开始编号(0~n-1),编号为i的节点
如果满足2*i+1<=n-1,则其有左孩子,否则没有
如果满足2*i+2<=n-1,则其有右孩子,否则没有
父亲节点的编号是0~2分之n-1
操作步骤:
1.建初始堆(这里建大堆)
从数组的n/2-1到0依次调整各个父亲节点
每个父亲节点调整的方式:看父亲节点和左右孩子中的最大值进行比较,如果比最大值小的话,父亲节点的值就和左右孩子中那个较大的那个进行交换,然后那个进行交换的孩子节点变为新的父亲节点继续讨论,如果新的父亲节点没有左右孩子或者没有发生交换那么结束
2.进行排序
(1)堆顶元素与末尾元素进行交换
(2)调整堆顶
调整堆顶的方式和上面的调整方式相同
4.堆排序的代码如下
#include<stdio.h>void adjust(int arr[], int index, int length) {if (index * 2 + 1 >= length && index * 2 + 2 >=length) {return;}int weizhi = 0;//看当前节点左孩子,和右孩子,取它们大的那个int Max = 0;//如果有左孩子和右孩子if (index * 2 + 1 < length&& index * 2 + 2 < length) {if (arr[index * 2 + 1] > arr[index * 2 + 2]) {Max = arr[index * 2 + 1];weizhi = index * 2 + 1;}else {Max = arr[index * 2 + 2];weizhi = index * 2 + 2;}}//如果只有左孩子if (index * 2 + 1 <= length && index * 2 + 2 > length) {Max = arr[index * 2 + 1];weizhi = index * 2 + 1;}//看这个值是否比当前节点大,大的话进行交换,然后讨论交换的那个节点if (Max > arr[index]) {arr[index] = arr[index] ^ arr[weizhi];arr[weizhi] = arr[index] ^ arr[weizhi];arr[index] = arr[index] ^ arr[weizhi];adjust(arr, weizhi, length);}}void HeapSort(int arr[],int length) {if (arr == NULL || length <= 0) return;//1.建初始堆for (int i = length / 2 - 1; i >=0 ; i--) {adjust(arr, i, length);}//2.排序for (int i = length-1; i > 0; i--) {//进行交换arr[0] = arr[0] ^ arr[i];arr[i] = arr[0] ^ arr[i];arr[0] = arr[0] ^ arr[i];adjust(arr, 0, i );}
}void Print(int a[], int length) {if (a == NULL || length <= 0) return;for (int i = 0; i < length; i++) {printf("%d ", a[i]);}printf("\n");
}int main() {int arr[] = { 4, 6, 2, 1, 8, 78, 2123, 48, 49, 58, 11, 9 };int length = sizeof(arr) / sizeof(arr[0]);HeapSort(arr, length);Print(arr, length);return 0;
}
九.桶排序(BucketSort)
1.桶排序的实现步骤
1.找到这组数据的最大值和最小值
2.确定分组方式
3.申请一个指针数组
4.进行入组(头插法放入节点)
5.组内进行排序(其实是进行单向链表的排序,可以使用冒泡排序,选择排序,插入排序(创建链表时使用),快速排序,归并排序)
6.放回到原数组中
7.释放
十.基数排序(RadixSort)
1.基数排序分为两种
1.MSD(高位优先)
2.LSD (低位优先)
2.基数排序的实现步骤
1.找到这组数据中的最大值
2.计算最大值的位数
3.按位处理(这是个循环,循环的次数取决于位数)(这里用的是LSD)
(1)申请组(申请10组,因为十进制是0~9)
(2)拆位(第一次是个位,然后十位,然后百位…)
(3)数据进行入组操作(数据根据 当前拆位(个位,十位,百位等)的值进行分组)
(4)将数据放回到原数组中
(5)释放申请组的空间
十一.关于排序的时间复杂度,空间复杂度,稳定性
1.排序稳定性
1.稳定性的概念
数值相同的元素,在排序前后,其相对位置未发生改变
2.关于排序的时间复杂度,空间复杂度,稳定性的表格如下

相关文章:
数据结构----算法--排序算法
数据结构----算法–排序算法 一.冒泡排序(BubbleSort) 1.冒泡排序的核心思想 相邻两个元素进行大小比较,如果前一个比后一个大,就交换 注意: 在冒泡排序的过程中,促进了大的数往后去,小的数…...
Unity3D 基础——使用 Mathf.SmoothDamp 函数制作相机的缓冲跟踪效果
使用 Mathf.SmoothDamp 函数制作相机的缓冲跟踪效果,让物体的移动不是那么僵硬,而是做减速的缓冲效果。将以下的脚本绑定在相机上,然后设定好 target 目标对象,即可看到相机的缓动效果。通过设定 smoothTime 的值,可以…...

leetcode-200. 岛屿数量
1. 题目 leetcode题目链接 2. 解答 思路: 需要循环遍历每个节点;找到陆地,基于陆地开始遍历陆地的上下左右;数组dirm dirn就可以表示某个区域的上下左右;标记遍历过的节点;设计循环的退出条件…...
python的搜索引擎系统设计与实现 计算机竞赛
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 python的搜索引擎系统设计与实现 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:5分创新点:3分 该项目较为新颖ÿ…...

Unity随笔:在Unity中使用多线程需要注意什么
Unity3D 支持多线程编程,但是在 Unity 中使用多线程需要注意一些限制和注意事项。以下是在 Unity 中使用多线程时需要注意的事项: 1. Unity 主线程限制: Unity 中的大部分操作必须在主线程进行,包括场景的修改、资源的加载、渲染…...
 语法)
SQL Select(选择) 语法
SQL SELECT 语法 SELECT 语法用于从数据库中选择数据。 返回的数据存储在结果表中,称为结果集。 基本语法:SELECT和FROM 在任何SQL查询语句中都:SELECT和FROM他们必须按顺序排列。SELECT指示要查看哪些列,FROM标识它们所在的表。…...

Python武器库开发-基础篇(二)
基础篇(二) if 语句 编程时经常需要检查一系列条件,并据此决定采取什么措施。在Python中,if 语句让你能够检查程序的当前状态,并据此采取相应的措施 下面是一个简短的示例,演示了如何使用if 语句来正确地处理特殊情形。假设你有…...

在 CentOS 8.2 上安装 MySQL C/C++ 客户端库 libmysqlclient.so
添加 MySQL 官方 Yum 存储库: sudo dnf install https://dev.mysql.com/get/mysql80-community-release-el8-3.noarch.rpm 安装 MySQL C/C 客户端库: sudo dnf install mysql-devel 这将自动安装所需的依赖项,并将 libmysqlclient 库及其头…...

『C++ - STL』之优先级队列( priority_queue )
文章目录 前言优先级队列的结构优先级队列的模拟实现仿函数 最终代码 前言 什么是优先级队列,从该名中可以知道他一定有队列的一定属性,即先入先出(LILO),而这里的优先级则可以判断出它的另一个特点就是可以按照一定的条件将符合该条件的先进…...
?)
简述什么是服务端包含(Server Side Include)?
Server-side include(服务器端包括)是浏览器向服务器请求您的文档时并入您的文档的一个文件。 当访问者浏览器请求含有 include(包括)指令的文档时,服务器处理 include(包括)指令并创建新的文档,在新文档中 include(包括)指令被所包括的文件内容取代。然后服务器将此…...
领英如何注册?2023超全面详细教程
领英是一家面向商业用户的全球最大的职业社交网站,据统计,Linkedln用户每月与网页的交互次数超过10亿次。对于跨境人来说,他更是作为一个开发客户、广告营销的工具,被称为跨境的“风口”。 一、领英被封原因 1、IP、设备问题 1&…...

Spring Cloud Gateway 使用 Redis 限流使用教程
从本文开始,笔者将总结 spring cloud 相关内容的教程 版本选择 为了适应 java8,笔者选择了下面的版本,后续会出 java17的以SpringBoot3.0.X为主的教程 SpringBoot 版本 2.6.5 SpringCloud 版本 2021.0.1 SpringCloudAlibaba 版本 2021.0.1.…...
Qt事件系统 day7
Qt事件系统 day7 事件系统 在Qt中,事件是派生自抽象QEvent类的对象,它表示应用程序内发生的事情或应用程序需要知道的外部活动的结果。事件可以由QObject子类的任何实例接收和处理,但它们与小部件尤其相关。Qt程序需要在main()函数创建一个…...
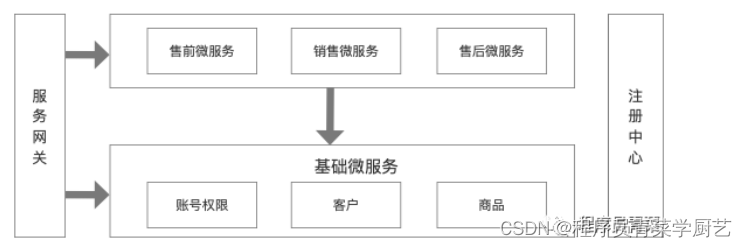
微服务拆分的思考
一、前言 前面几篇文章介绍了微服务核心的两个组件:注册中心和网关,今天我们来思考一下微服务如何拆分,微服务拆分难度在于粒度和层次,粒度太大拆分的意义不大,粒度太小开发、调试、运维会有很多坑。 二、微服务划分…...

DateUtil工具类记录
为支持日常工作需要,记录所用到的一些关于时间的工具类方法。随时进行补充。 /*** Description:获取两个日期之间的天数差* Author:hanyq* Date:2023/9/19 11:23*/public static int getDateDifference(Date startDate,Date endDate){int days 0;try {Calendar st…...

可信执行环境简介:ARM 的 TrustZone
目录 可信执行环境安全世界与普通世界 - 上下文切换机制ARMv7 中的异常处理ARMv8 中的异常处理 信任区商业实施TrustZone 本身的漏洞高通Trustonic 信任区强化的弱点结论声明 可信执行环境 具有信任区的 ARM 处理器实现了架构安全性每个物理处理器内核提供两个虚拟的扩展 核心…...
【音视频流媒体】 3、ffmpeg、ffplay、ffprobe 超详细介绍
文章目录 一、ffmpeg1.1 安装1.2 基本参数 二、ffprobe2.1 查编码格式2.2 查视频时长 五、视频转流5.1 MP4转H2645.2 H264转MP45.3 AVI转MP45.4 MP4转H265 六、视频文件6.1 播放6.2 filter 过滤器6.2.1 crop 6.3 视频截取6.4 视频拼接6.5 获取分辨率 七、视频和图7.1 视频抽帧7…...

解决kong部署自定义插件报 helloworld plugin is enabled but not installed
背景 我使用的是docker环境部署,使用的是自定义挂载plugins路径 -e "KONG_LUA_PACKAGE_PATH/plugins/?.lua" \ -v "/plugins:/plugins" \ -e "KONG_PLUGINSbundled,helloworld" \但是当我只需docker run的时候就报错 [error] 1#0:…...

动态数据源自定义SqlSessionFactoryBean时mybatis plus配置失效
环境: 动态数据源spring-boot 2.7.15mybatis-plus 3.5.2 yaml配置: spring:datasource:db100:username: xxxpassword: xxxjdbc-url: jdbc:kingbase8://xxx.xxx.xxx.xxx:54321/100driver-class-name: com.kingbase8.Driver# url: jdbc:postgresql://xxx…...

【Qt控件之QDialogButtonBox】概述及使用
概述 QDialogButtonBox类是一个小部件,它以适合当前小部件样式的布局呈现按钮。 对话框和消息框通常以符合该台界面指南的布局呈现按钮。不同的平台会有不同的对话框布局。QDialogButtonBox允许发人员向其添加按钮,并将自使用用户的桌面环境所适合的布局…...

阿里云服务器上fastText安装踩坑记:从C++11报错到模型量化压缩的完整避坑指南
阿里云ECS实战:fastText从编译报错到模型量化的全流程解决方案 当你在阿里云ECS上部署fastText模型时,是否遇到过那个令人头疼的"C11编译错误"?这仅仅是开始——内存占用过高、磁盘空间不足、推理速度慢等问题会接踵而至。本文将带…...

FPGA数学库设计:从定点数、CORDIC到AXI-Stream的硬件算法实现
1. 项目概述:为什么我们需要一个FPGA数学库?如果你在FPGA开发中做过信号处理、图像算法或者任何需要复杂数学运算的设计,大概率会面临一个共同的困境:如何高效、可靠地实现那些看似基础的数学函数?比如,计算…...
)
别再只画区间了!用ECharts的markArea实现单点高亮标注(附完整代码)
突破ECharts标记边界:用markArea实现单点高亮的高级技巧 在数据可视化领域,ECharts凭借其强大的功能和灵活的配置选项,已成为前端开发者和数据分析师的首选工具之一。当我们面对需要突出显示特定数据点的场景时,常规做法是使用mar…...

AUTOSAR Ea模块深度剖析:从原理到实战的EEPROM抽象层配置与优化
1. 项目概述:为什么我们需要深入理解Ea模块?在AUTOSAR的软件架构里,NVRAM管理器(NvM)负责非易失性数据的抽象管理,而Ea(EEPROM Abstraction,EEPROM抽象)模块,…...

华为升腾C92变身校园打铃器:从Linux到Win7的完整改造指南
1. 华为升腾C92硬件潜力解析 很多人第一次接触华为升腾C92时,都会被它小巧的机身误导,以为这只是一台性能有限的瘦客户机。我当初在学校见到这批预装Linux系统的设备时,也是这么想的。直到某天停电后需要手动打铃,才萌生了改造它的…...

Trillium中文版:破解企业数据治理困局,实现业务驱动数据质量
1. 项目概述:当数据治理遇上“本地化”浪潮最近,业内一个消息引起了我的注意:数据质量与数据集成领域的“老牌劲旅”Syncsort,正式推出了其核心产品Trillium软件系统的中文版。这个消息乍一看,可能只是又一个国际软件厂…...

ARM核心板存储选型实战:从DDR到eMMC的避坑指南
1. 项目概述:一个被低估的硬件选型难题在嵌入式系统开发,尤其是基于ARM架构的工控和核心板设计中,存储选型常常被新手甚至一些有经验的工程师视为一个“小问题”。不就是选个Flash和RAM吗?很多人会这么想。然而,在我十…...

Windows上运行安卓应用:APK安装器完整指南
Windows上运行安卓应用:APK安装器完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行安卓应用,却不想安装笨重的…...
)
用C++模拟流感传播:从信息学奥赛题到理解传染病模型(附完整代码)
用C模拟流感传播:从信息学奥赛题到理解传染病模型(附完整代码) 流感传播模型一直是计算机模拟和算法竞赛中的经典问题。这道来自信息学奥赛的题目不仅考察了递推算法的应用,更让我们得以一窥传染病传播的基本原理。本文将带你从零…...

全志D1s开发板RT-Smart环境搭建:从工具链到烧录的完整实践指南
1. 项目概述与核心价值最近在折腾一块搭载了全志D1s芯片的开发板,目标是在上面跑RT-Smart实时操作系统。这听起来像是一个标准的嵌入式开发流程,但实际操作下来,从环境搭建到第一个程序跑起来,中间踩的坑一个接一个,远…...