python案例:六大主流小说平台小说下载
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取
很多小伙伴学习Python的初衷就是为了爬取小说,方便又快捷~
辣么今天咱们来分享6个主流小说平台的爬取教程~
一、流程步骤
流程基本都差不多,只是看网站具体加密反爬,咱们再进行解密。
实现爬虫的第一步?
1、去抓包分析,分析数据在什么地方。
-
打开开发者工具
-
刷新网页
-
找数据 --> 通过关键字搜索
2、获取小说内容
-
目标网址
-
获取网页源代码请求小说链接地址,解析出来
-
请求小说内容数据包链接:
-
获取加密内容 --> ChapterContent
-
进行解密 --> 分析加密规则 是通过什么样方式 什么样代码进行加密
3、获取响应数据
response.text 获取文本数据 字符串
response.json() 获取json数据 完整json数据格式
response.content 获取二进制数据 图片 视频 音频 特定格式文件
二、案例
1、书旗
环境使用:
-
Python 3.8
-
Pycharm
模块使用:
- requests
- execjs
- re
源码展示:
# 导入数据请求模块
import requests
# 导入正则模块
import re
import execjs
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
# 模拟浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.3'
}
# 请求链接 -> 目录页面链接
html = '网址屏蔽了,不然过不了'
# 发送请求
html_ = requests.get(url=html, headers=headers).text
# 小说名字
name = re.findall('<title>(.*?)-书旗网</title>', html_)[0]
# 提取章节名字 / 章节ID
info = re.findall('data-clog="chapter\$\$chapterid=(\d+)&bid=8826245">\d+\.(.*?)</a>', html_, re.S)
print(name)
# for 循环遍历
for chapter_id, index in info:title = index.strip()print(chapter_id, title)# 请求链接url = f'https://网址屏蔽了,不然过不了/reader?bid=8826245&cid={chapter_id}'# 发送请求 <Response [200]> 响应对象response = requests.get(url=url, headers=headers)# 获取响应数据html_data = response.text# 正则匹配数据data = re.findall('contUrlSuffix":"\?(.*?)","shelf', html_data)[0].replace('amp;', '')# 构建小说数据包链接地址link = 'https://c13.网址屏蔽了,不然过不了.com/pcapi/chapter/contentfree/?' + data# 发送请求json_data = requests.get(url=link, headers=headers).json()# 键值对取值, 提取加密内容ChapterContent = json_data['ChapterContent']# 解密内容 --> 通过python调用JS代码, 解密f = open('书旗.js', encoding='utf-8')# 读取JS代码text = f.read()# 编译JS代码js_code = execjs.compile(text)# 调用Js代码函数result = js_code.call('_decodeCont', ChapterContent).replace('<br/><br/>', '\n').replace('<br/>', '')# 保存数据with open(f'{name}.txt', mode='a', encoding='utf-8') as v:v.write(title)v.write('\n')v.write(result)v.write('\n')print(json_data)print(ChapterContent)print(result)
效果展示:

2、塔读
环境使用:
-
Python 3.8
-
Pycharm
模块使用:
- requests --> pip install requests
源码
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
# 导入数据请求模块
import requests
# 导入正则表达式模块
import re
# 导入读取JS代码
import execjs# 模拟浏览器
headers = {'Host': '网址屏蔽了,以免不过','Referer': '网址屏蔽了,以免不过','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36',
}
# 请求链接
link = '网址屏蔽了,以免不过'
# 发送请求
link_data = requests.get(url=link, headers=headers).text
# 小说名字
name = re.findall('book_name" content="(.*?)">', link_data)[0]
# 章节ID 和 章节名字
info = re.findall('href="/book/\d+/(\d+)/" target="_blank">(.*?)</a>', link_data)[9:]
page = 1
# for 循环遍历
for chapter_id, title in info:print(chapter_id, title)# 获取广告 data-limit 参数j = open('塔读.js', encoding='utf-8')# 读取JS代码text = j.read()# 编译JS代码js_code = execjs.compile(text)# 调用js代码函数data_limit = js_code.call('o', chapter_id)print(data_limit)# 请求链接url = f'网址屏蔽了,以免不过/{page}'# 发送请求 <Response [200]> 响应对象 表示请求成功response = requests.get(url=url, headers=headers)# 获取响应json数据 --> 字典数据类型json_data = response.json()# 解析数据 -> 键值对取值 content 获取下来content = json_data['data']['content']# 处理小说内容广告 初级版本 --> 后续需要升级content_1 = re.sub(f'<p data-limit="{data_limit}">.*?</p>', '', content)# 提取小说内容 -> 1. 正则表达式提取数据 2. css/xpath 提取result = re.findall('<p data-limit=".*?">(.*?)</p>', content_1)# 把列表合并成字符串string = '\n'.join(result)# 保存数据with open(f'{name}.txt', mode='a', encoding='utf-8') as f:f.write(title)f.write('\n')f.write(string)f.write('\n')print(string)page += 1
效果展示

3、飞卢
环境使用:
-
Python 3.8
-
Pycharm
模块使用:
- requests >>> 数据请求模块
parsel >>> 数据解析模块
re 正则表达式
源码展示
# 数据请求模块
import requests
# 数据解析模块
import parsel
# 正则表达式模块
import re
import base64def get_content(img):url = "https://aip.网址屏蔽,不然不过审.com/oauth/2.0/token"params = {"grant_type": "client_credentials","client_id": "","client_secret": ""}access_token = str(requests.post(url, params=params).json().get("access_token"))content = base64.b64encode(img).decode("utf-8")url_ = "网址屏蔽,不然不过审" + access_tokendata = {'image': content}headers = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}response = requests.post(url=url_, headers=headers, data=data)words = '\n'.join([i['words'] for i in response.json()['words_result']])return words# 模拟伪装
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}
# 请求链接
link = '网址屏蔽,不然不过审'
# 发送请求
link_response = requests.get(url=link, headers=headers)
# 获取响应文本数据
link_data = link_response.text
# 把html文本数据, 转成可解析对象
link_selector = parsel.Selector(link_data)
# 提取书名
name = link_selector.css('#novelName::text').get()
# 提取链接
href = link_selector.css('.DivTr a::attr(href)').getall()
# for循环遍历
for index in href[58:]:# 请求链接url = 'https:' + indexprint(url)# 发送请求 <Response [200]> 响应对象response = requests.get(url=url, headers=headers)# 获取响应文本数据html_data = response.text# 把html文本数据, 转成可解析对象 <Selector xpath=None data='<html xmlns="http://www.w3.org/1999/x...'>selector = parsel.Selector(html_data)# 解析数据, 提取标题title = selector.css('.c_l_title h1::text').get() # 根据数据对应标签直接复制css语法即可# 提取内容content_list = selector.css('div.noveContent p::text').getall() # get提取第一个# 列表元素大于2 --> 能够得到小说内容if len(content_list) > 2:# 把列表合并成字符串content = '\n'.join(content_list)# 保存数据with open(name + '.txt', mode='a', encoding='utf-8') as f:f.write(title)f.write('\n')f.write(content)f.write('\n')
效果展示:
因为这玩意爬下来是图片,所以还要进行文字识别,

'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
else:# 提取图片内容info = re.findall("image_do3\((.*?)\)", html_data)[0].split(',')img = 'https://read.faloo.com/Page4VipImage.aspx'img_data = {'num': '0','o': '3','id': '724903','n': info[3],'ct': '1','en': info[4],'t': '0','font_size': '16','font_color': '666666','FontFamilyType': '1','backgroundtype': '0','u': '15576696742','time': '','k': info[6].replace("'", ""),}img_content = requests.get(url=img, params=img_data, headers=headers).content# 文字识别, 提取图片中文字内容content = get_content(img=img_content)# 保存数据with open(name + '.txt', mode='a', encoding='utf-8') as f:f.write(title)f.write('\n')f.write(content)f.write('\n')
识别效果
4、纵横中文
环境模块
-
解释器: python 3.8
-
编辑器: pycharm 2022.3
-
crypto-js
-
requests
源码展示:
import execjs
import requests
import recookies = {
}headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control': 'no-cache','Connection': 'keep-alive','Pragma': 'no-cache','Referer': '网址屏蔽了,不过审','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'same-site','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36','sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}response = requests.get('网址屏蔽了,不过审', cookies=cookies, headers=headers)html_data = response.text
i = re.findall('<div style="display:none" id="ejccontent">(.*?)</div>', html_data)[0]
f = open('demo.js', mode='r', encoding='utf-8').read()
ctx = execjs.compile(f)
result = ctx.call('sdk', i)
print(result)
5、笔趣阁
相关模块:
<第三方模块>
-
requests >>> pip install requests
-
parsel
<内置模块>
- re
开发环境:
-
环 境: python 3.8
-
编辑器:pycharm 2021.2
源码展示:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import requests # 第三方模块 pip install requests
import parsel # 第三方模块
import re # 内置模块 url = 'https://网址屏蔽/book/88109/'
# 伪装
headers = {# 键值对 键 --》用户代理 模拟浏览器的基本身份'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# 发送请求 response 响应体
response = requests.get(url=url, headers=headers)
print(response)selector = parsel.Selector(response.text)
title = selector.css('.zjlist dd a::text').getall()# 章节链接
link = selector.css('.zjlist dd a::attr(href)').getall()
# print(link)
# replace re.sub()# zip()
zip_data = zip(title, link)
for name, p in zip_data:# print(name)# print(p)passage_url = '网址屏蔽'+ p# print(passage_url)# 发送请求response_1 = requests.get(url=passage_url, headers=headers)# print(response_1.text)# 解析数据 content 二进制 图片 视频# re # 查找所有re_data = re.findall('<div id="content"> (.*?)</div>', response_1.text)[0]# print(re_data)# replace 替换text = re_data.replace('笔趣阁 www.网址屏蔽.net,最快更新<a href="https://网址屏蔽/book/88109/">盗墓笔记 (全本)</a>', '')text = text.replace('最新章节!<br><br>', '').replace(' ', '')# print(text)text = text.replace('<br /><br />', '\n')print(text)passage = name + '\n' + textwith open('盗墓笔记.txt',mode='a') as file:file.write('')
6、起点
环境模块
python3.8 解释器版本
pycharm 代码编辑器
requests 第三方模块
代码展示
import reimport requests # 第三方模块 额外安装
import subprocess
from functools import partial
# 处理execjs编码报错问题, 需在 import execjs之前
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
import execjsheaders = {'cookie': 用自己的,我的删了
}
ctx = execjs.compile(open('起点.js', mode='r', encoding='utf-8').read())
url = 'https://网址屏蔽/chapter/1035614679/755998264/'
response = requests.get(url=url, headers=headers)html_data = response.textarg1 = re.findall('"content":"(.*?)"', html_data)[0]
arg2 = url.split('/')[-2]
arg3 = '0'
arg4 = re.findall('"fkp":"(.*?)"', html_data)[0]
arg5 = '1'
result = ctx.call('sdk', arg1, arg2, arg3, arg4, arg5)
print(result)text = re.findall('"content":"(.*?)","riskInfo"', html_data)[0]
text = text.replace('\\u003cp>', '\n')f = open('1.txt', mode='w', encoding='utf-8')
f.write(text)
源码我都打包好了,还有详细视频讲解,文末名片自取,备注【6】快速通过。
尾语
最后感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。

相关文章:
python案例:六大主流小说平台小说下载
嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 很多小伙伴学习Python的初衷就是为了爬取小说,方便又快捷~ 辣么今天咱们来分享6个主流小说平台的爬取教程~ 一、流程步骤 流程基本都差不多&#x…...

前端已死!转行网络安全,挖漏洞真香!
最近,一个做运维的朋友在学渗透测试。他说,他公司请别人做渗透测试的费用是 2w/人天,一共2周。2周 10w 的收入,好香~ 于是,我也对渗透测试产生了兴趣。开始了探索之路~ 什么是渗透测试 渗透测试这名字听起来有一种敬畏…...

【AI】了解人工智能、机器学习、神经网络、深度学习
深度学习、神经网络的原理是什么? 深度学习和神经网络都是基于对人脑神经系统的模拟。下面将分别解释深度学习和神经网络的原理。深度学习的原理:深度学习是一种特殊的机器学习,其模型结构更为复杂,通常包括很多隐藏层。它依赖于神…...
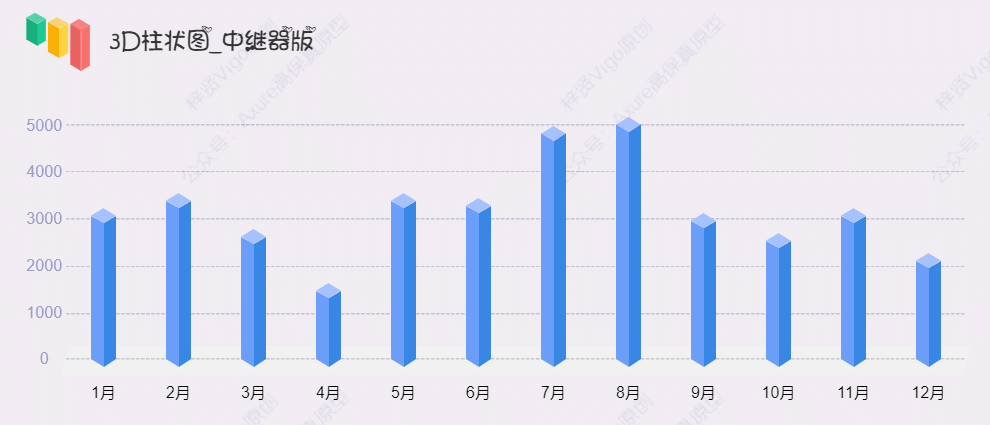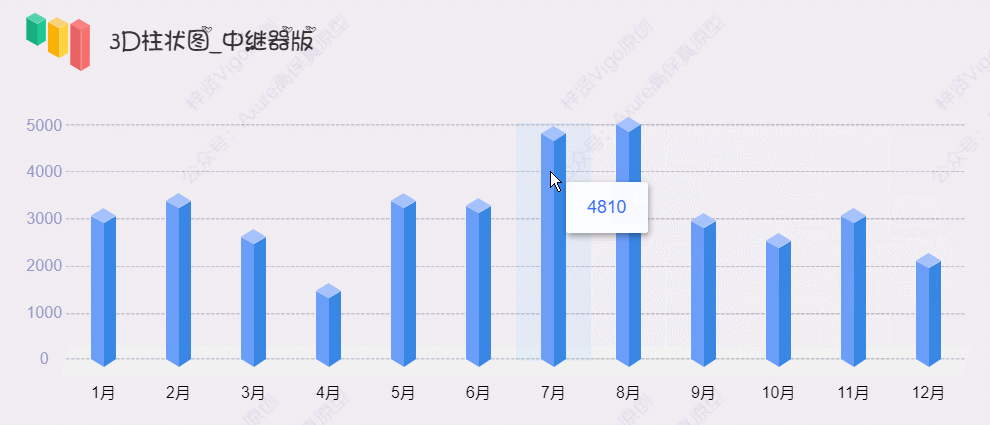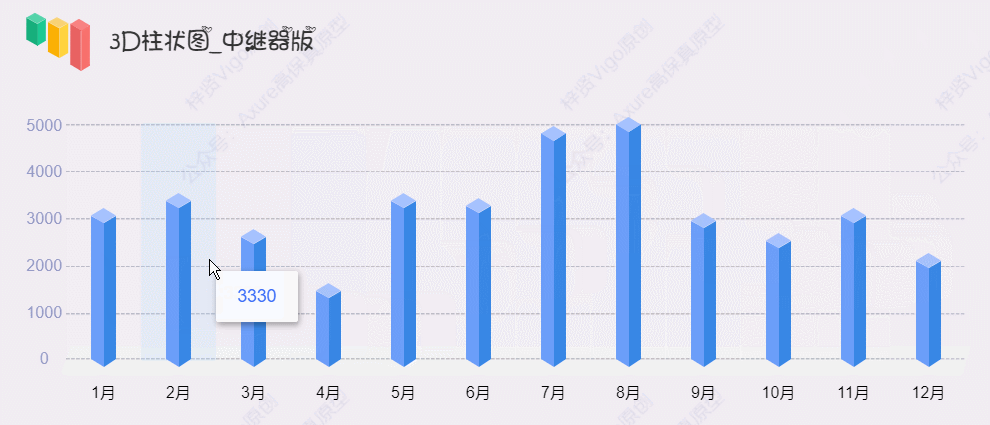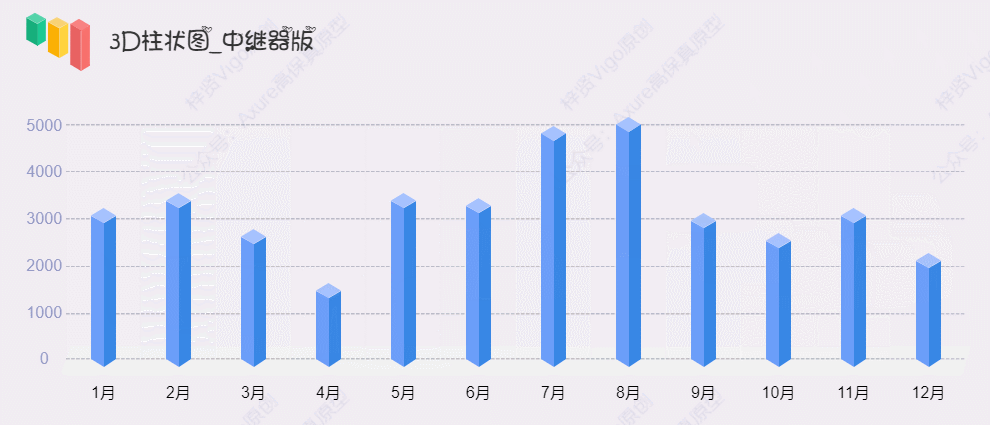
【Axure高保真原型】3D柱状图_中继器版
今天和大家分享3D柱状图_中继器版的原型模板,图表在中继器表格里填写具体的数据,调整坐标系后,就可以根据表格数据自动生成对应高度的柱状图,鼠标移入时,可以查看对应圆柱体的数据……具体效果可以打开下方原型地址体验…...
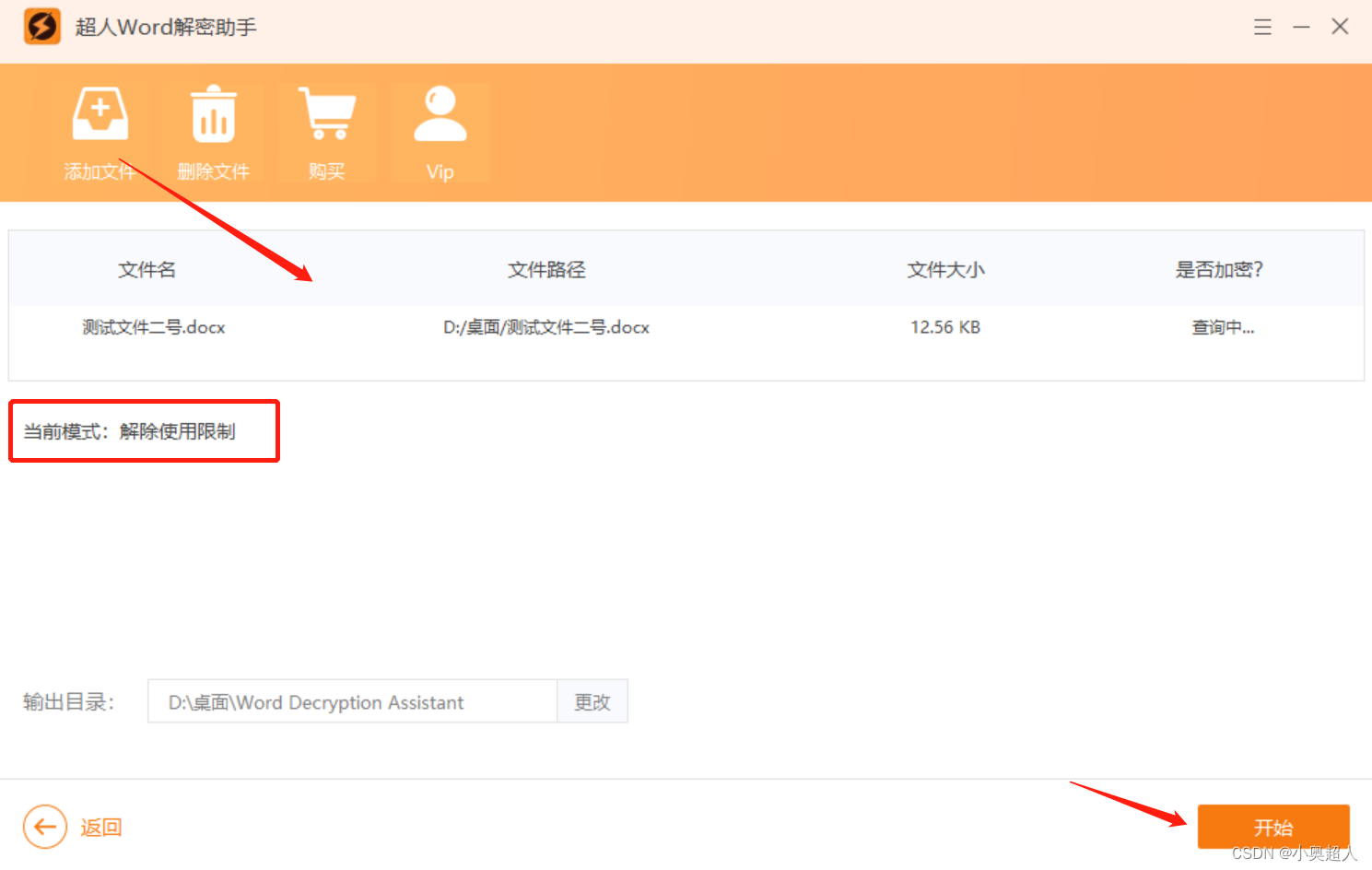
【word技巧】word页眉,如何禁止他人修改?
我们设置了页眉内容之后,不想其他人修改自己的页眉内容,我们可以设置加密的,设置方法如下: 先将页眉设置好,退出页眉设置之后,我们选择布局功能,点击分隔符 – 连续 设置完之后页面分为上下两节…...
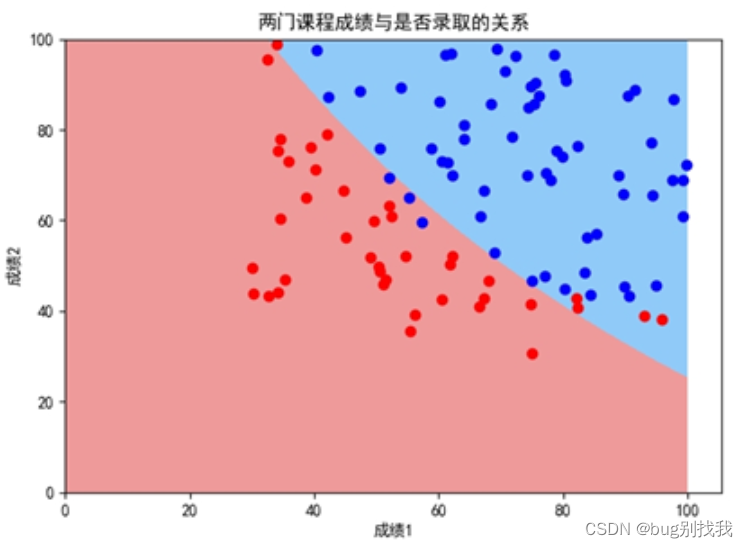
Python 机器学习入门之逻辑回归
系列文章目录 第一章 Python 机器学习入门之线性回归 第一章 Python 机器学习入门之梯度下降法 第一章 Python 机器学习入门之牛顿法 第二章 Python 机器学习入门之逻辑回归 逻辑回归 系列文章目录前言一、逻辑回归简介二、逻辑回归推导1、问题2、Sigmoid函数3、目标函数3.1 让…...

现货白银赚钱有风险吗?
跟现货黄金一样,现货白银市场是一个公平公正的市场,即使是中小投资者,也能拥有平等的获利机会,同样可以借助平台所给予的资金杠杆,实现个人财富的快速增值。 很多人都是冲着现货白银的财富效应而进入这个市场ÿ…...

Debian衍生桌面项目SpiralLinux12.231001发布
SpiralLinux 是一个从 Debian 衍生出来的桌面项目,其重点是在所有主要桌面环境中实现简洁性和开箱即用的可用性。 spiral Linux 是为刚接触 Linux 世界的人们量身定制的发行版。这是 GeckoLinux 开发人员的创意,他更喜欢保持匿名。尽管他不愿透露姓名&a…...

元宇宙在技术大爆炸时代迎来链游新世界
元宇宙是一个完全虚拟的世界,人们可以在其中互动,就像在现实世界中一样。 随着元宇宙概念不断的被深化,目前许多用户群体已经注意到并加入元宇宙领域。而元宇宙比较火的场景有社交、游戏、虚拟会议等,在许多方面,游戏一…...

9中间件-Redis、MQ---进阶
mq进阶 RabbitMQ 怎么避免消息丢失? 把消息持久化磁盘,保证服务器重启消息不丢失。 每个集群中至少有一个物理磁盘,保证消息落入磁盘。#RabbitMQ 的消息是怎么发送的? 首先客户端必须连接到 RabbitMQ 服务器才能发布和消费消息&…...

JVM(Java Virtual Machine)内存模型篇
前言 本文是JVM系列的内存模型篇,参考资料为《深入理解Java虚拟机》,本文章将会以HotSpot 虚拟机为介绍基础。 1.JVM简单介绍 Java Virtual Machine是运行Java程序的基础,JVM基于C、C实现,JVM有很多种类,但是这些虚…...

对地址解析协议ARP进一步探讨
之前在讨论MAC地址和IP地址时,顺便对ARP协议做了初步的总结 (计网第三章(数据链路层)(四)(MAC地址和IP地址、ARP协议、集线器和交换机)),但是当时对ARP请求的…...

java:java.util.StringTokenizer实现字符串切割
java:java.util.StringTokenizer实现字符串切割 1 前言 java.util工具包提供了字符串切割的工具类StringTokenizer,Spring等常见框架的字符串工具类(如Spring的StringUtils),常见此类使用。 例如Spring的StringUtil…...

IPV6 ND协议--源码解析【根源分析】
ND协议介绍 ND介绍请阅读上一篇文章:IPv6知识 - ND协议【一文通透】11.NDP协议分析与实践_router solicitation报文中不携带source link-layer address-CSDN博客 ND协议定义了5种ICMPv6报文类型,如下表所示: NS/NA报文主要用于地址解析RS/…...
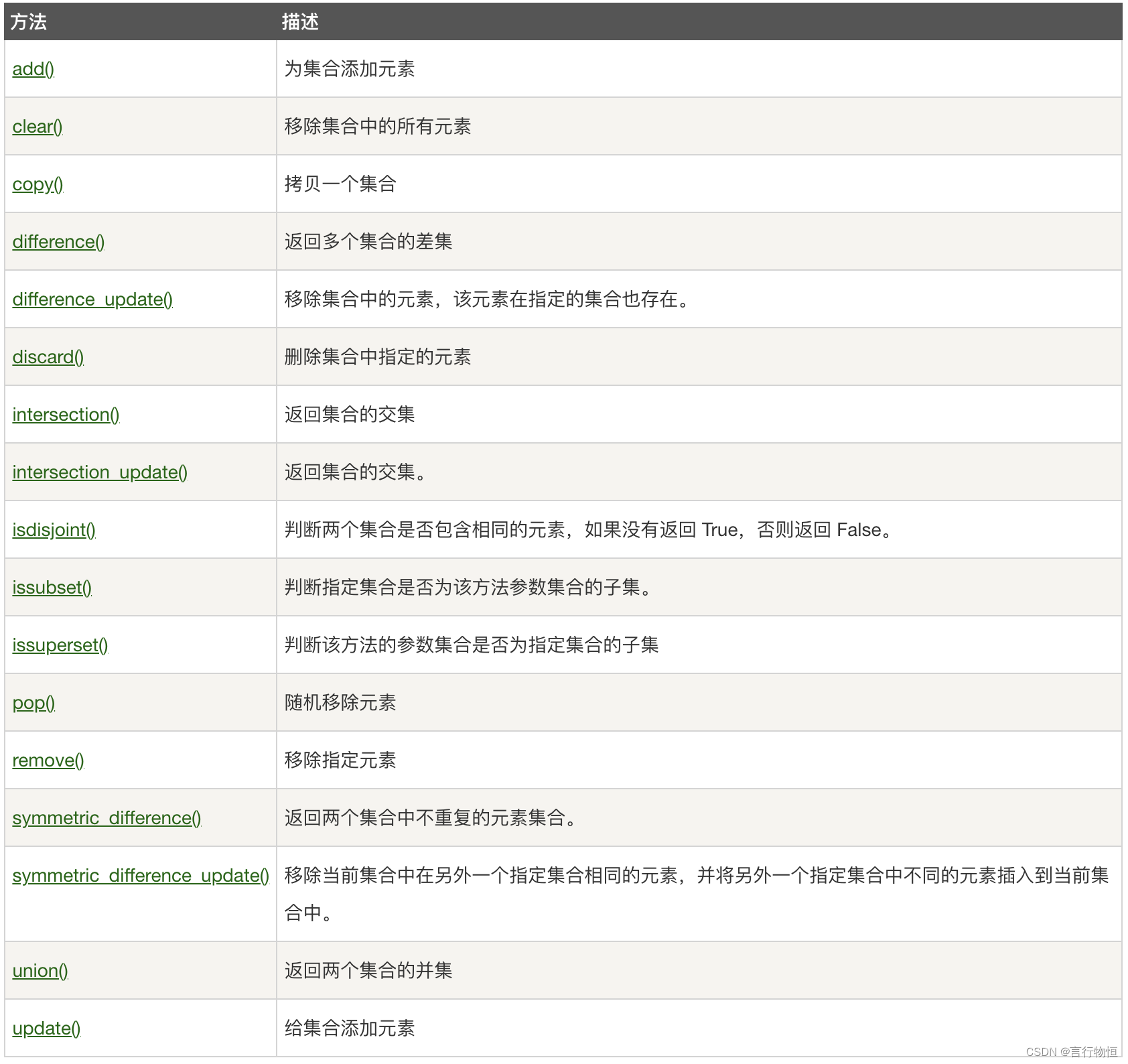
Python学习笔记——存储容器
食用说明:本笔记适用于有一定编程基础的伙伴们。希望有助于各位! 列表 列表类似数组,其中可以包含不同类型的元素,写法如下: list1 [Google, Runoob, 1997, 2000] list2 [1, 2, 3, 4, 5 ] list3 ["a", …...
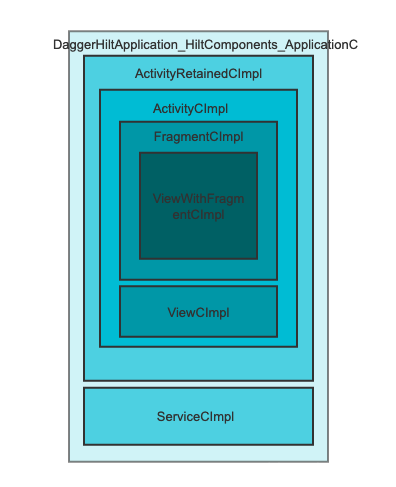
Android DI框架-Hilt
到底该如何理解<依赖注入> 模版代码:食之无味,弃之可惜 public class MainActivity extends Activity {Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);TextView mTextView(TextView) findVi…...

基于寄生捕食优化的BP神经网络(分类应用) - 附代码
基于寄生捕食优化的BP神经网络(分类应用) - 附代码 文章目录 基于寄生捕食优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.寄生捕食优化BP神经网络3.1 BP神经网络参数设置3.2 寄生捕食算法应用 4.测试结果…...

【Java常见的几种设计模式】
Java常见的几种设计模式 1. 单例模式(Singleton Pattern)2. 工厂模式(Factory pattern)3. 抽象工厂模式(Abstract Factory Pattern)4. 建造者模式(Builder Pattern)5. 原型模式&…...

jupyter崩溃进不去,报错module ‘mistune‘ has no attribute ‘BlockGrammar‘
是python包引起的问题 [E 2023-10-14 08:40:25.414 ServerApp] Uncaught exception GET /api/nbconvert?1697244025327 (127.0.0.1) HTTPServerRequest(protocol‘http’, host‘localhost:8090’, method‘GET’, uri‘/api/nbconvert?1697244025327’, version‘HTTP/1.1’…...
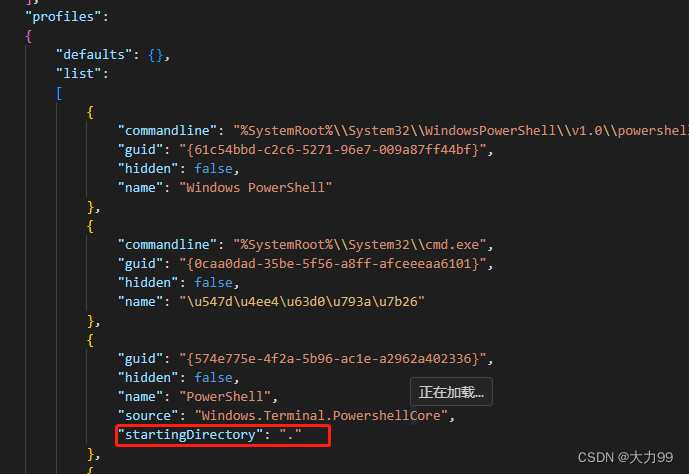
windows terminal鼠标右键打开
如果在官网上下载的是zip文件的 需要在注册表修改鼠标右键才能出来 注册表修改如下: 1.先windowsR,在命令框中输入regedit 打开注册表 2.在路径’计算机\HKEY_CLASSES_ROOT\directory\background\shell’下新建一个wt,wt下新建commond 这里…...

拒绝封闭技术栈绑架:MyEMS 开源能源管理平台的架构中立性与兼容性设计
在企业数字化转型的深水区,能源管理系统正从单一的计量工具演变为支撑生产运营的核心基础设施。然而,当我们审视这一领域的技术现状时,不难发现一个令人警惕的现象:大量商业能源管理软件正通过封闭的技术栈、私有的通信协议和紧耦…...

高并发下是先写数据库,还是先写缓存?
前言 数据库和缓存(比如:redis)双写数据一致性问题,是一个跟开发语言无关的公共问题。尤其在高并发的场景下,这个问题变得更加严重。 我很负责的告诉你,该问题无论在面试,还是工作中遇到的概率…...

国产ARM主板实战:从设计选型到性能优化的嵌入式开发指南
1. 项目概述:从“能用”到“好用”的国产ARM主板之路最近几年,如果你关注过硬件开发、嵌入式系统或者国产化替代的圈子,一定会频繁听到“国产ARM主板”这个词。它不再是实验室里的样品,而是越来越多地出现在工业控制、边缘计算、智…...

从USB转TTL到RS485:手把手教你用一颗CH342F芯片玩转三种串口通信
CH342F芯片实战指南:一芯三用的串口通信解决方案 在物联网和工业控制领域,串口通信依然是设备间可靠数据传输的基石。面对多样化的接口标准(TTL、RS232、RS485),工程师常常需要准备多种转换模块。而CH342F芯片以其独特…...
)
别再用时间机器了!用macOS恢复模式重装系统,保姆级图文教程(含抹盘避坑指南)
别再用时间机器了!用macOS恢复模式重装系统,保姆级图文教程(含抹盘避坑指南) 当你发现Mac运行速度明显变慢,或者准备转手出售设备时,彻底重装系统往往是最有效的解决方案。许多用户对macOS恢复模式存在本能…...

Electron应用上鸿蒙PC,安装包从180MB压到45MB,我做了哪些骚操作
Electron应用上鸿蒙PC,安装包从180MB压到45MB,我做了哪些骚操作 上个月老板丢给我一个任务:把现有的Electron应用搬到鸿蒙PC上。我花了两天把代码跑通了,build了一版安装包,一看体积——180MB。老板看了一眼࿰…...

初次接触Taotoken从注册到发出第一个API请求的全流程耗时
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次接触Taotoken从注册到发出第一个API请求的全流程耗时 本文记录了一名新用户从零开始,完成Taotoken平台注册、获取A…...

从Vue源码的preinstall钩子看团队包管理器规范:npx only-allow pnpm的工程实践
1. 为什么需要统一包管理器 最近在查看Vue源码时,发现package.json里有个有趣的配置:"preinstall": "npx only-allow pnpm"。这行看似简单的命令,背后隐藏着团队协作中一个非常重要的问题——包管理器的统一性。 想象一下…...

vue-fastapi-admin项目扩展与二次开发:插件化架构设计思路
vue-fastapi-admin项目扩展与二次开发:插件化架构设计思路 【免费下载链接】vue-fastapi-admin ⭐️ 基于 FastAPIVue3Naive UI 的现代化轻量管理平台 A modern and lightweight management platform based on FastAPI, Vue3, and Naive UI. 项目地址: https://gi…...

GitHub网络加速终极指南:如何实现10倍下载速度的智能优化方案
GitHub网络加速终极指南:如何实现10倍下载速度的智能优化方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否曾…...