深入理解强化学习——学习(Learning)、规划(Planning)、探索(Exploration)和利用(Exploitation)
分类目录:《深入理解强化学习》总目录
学习
学习(Learning)和规划(Planning)是序列决策的两个基本问题。 如下图所示,在强化学习中,环境初始时是未知的,智能体不知道环境如何工作,它通过不断地与环境交互,逐渐改进策略。
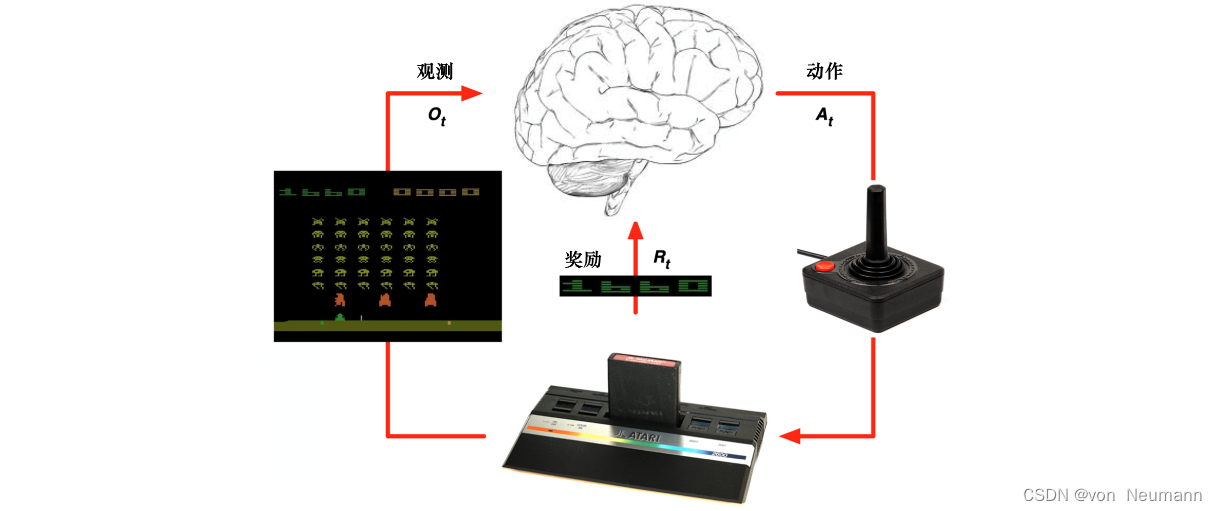
规划
如下图图所示,在规划中,环境是已知的,智能体被告知了整个环境的运作规则的详细信息。智能体能够计算出一个完美的模型,并且在不需要与环境进行任何交互的时候进行计算。智能体不需要实时地与环境交互就能知道未来环境,只需要知道当前的状态,就能够开始思考,来寻找最优解。
在下图所示的游戏中,规则是确定的,我们知道选择左之后环境将会产生什么变化。我们完全可以通过已知的规则,来在内部模拟整个决策过程,无需与环境交互。 一个常用的强化学习问题解决思路是,先学习环境如何工作,也就是了解环境工作的方式,即学习得到一个模型,然后利用这个模型进行规划。

探索和利用
在强化学习里面,探索和利用是两个很核心的问题。 探索即我们去探索环境,通过尝试不同的动作来得到最佳的策略(带来最大奖励的策略)。 利用即我们不去尝试新的动作,而是采取已知的可以带来很大奖励的动作。 在刚开始的时候,强化学习智能体不知道它采取了某个动作后会发生什么,所以它只能通过试错去探索,所以探索就是通过试错来理解采取的动作到底可不可以带来好的奖励。利用是指我们直接采取已知的可以带来很好奖励的动作。所以这里就面临一个权衡问题,即怎么通过牺牲一些短期的奖励来理解动作,从而学习到更好的策略。
下面举一些探索和利用的例子。 以选择餐馆为例,利用是指我们直接去我们最喜欢的餐馆,因为我们去过这个餐馆很多次了,所以我们知道这里面的菜都非常可口。 探索是指我们用手机搜索一个新的餐馆,然后去尝试它的菜到底好不好吃。我们有可能对这个新的餐馆感到非常不满意,这样钱就浪费了。 以做广告为例,利用是指我们直接采取最优的广告策略。探索是指我们换一种广告策略,看看这个新的广告策略可不可以得到更好的效果。 以挖油为例,利用是指我们直接在已知的地方挖油,这样可以确保挖到油。 探索是指我们在一个新的地方挖油,这样就有很大的概率可能不能发现油田,但也可能有比较小的概率可以发现一个非常大的油田。 以玩游戏为例,利用是指我们总是采取某一种策略。比如,我们玩《街头霸王》游戏的时候,采取的策略可能是蹲在角落,然后一直出脚。这个策略很可能可以奏效,但可能遇到特定的对手就会失效。 探索是指我们可能尝试一些新的招式,有可能我们会放出“大招”来,这样就可能“一招毙命”。
与监督学习任务不同,强化学习任务的最终奖励在多步动作之后才能观察到,这里我们不妨先考虑比较简单的情形:最大化单步奖励,即仅考虑一步动作。需注意的是,即便在这样的简单情形下,强化学习仍与监督学习有显著不同,因为智能体需通过试错来发现各个动作产生的结果,而没有训练数据告诉智能体应当采取哪个动作。
想要最大化单步奖励需考虑两个方面:一是需知道每个动作带来的奖励,二是要执行奖励最大的动作。若每个动作对应的奖励是一个确定值,那么尝试遍所有的动作便能找出奖励最大的动作。然而,更一般的情形是,一个动作的奖励值是来自一个概率分布,仅通过一次尝试并不能确切地获得平均奖励值。
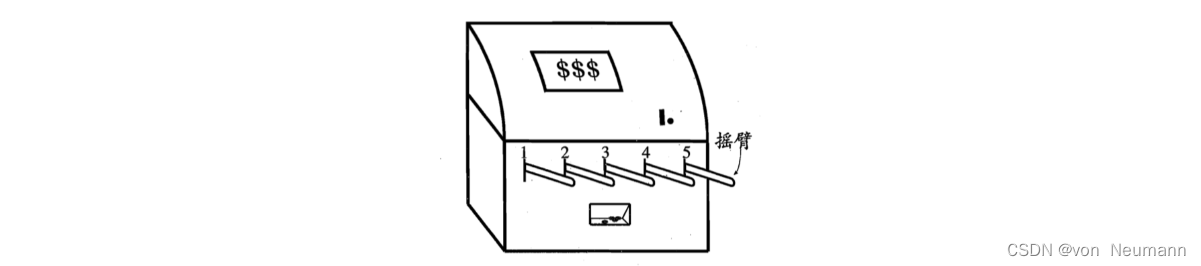
实际上,单步强化学习任务对应于一个理论模型,即K-臂赌博机(K-armed Bandit)。 K-臂赌博机也被称为多臂赌博机(Multi-armed Bandit,MAB) 。如下图所示,K-臂赌博机有K个摇臂,赌徒在投入一个硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币,但这个概率赌徒并不知道。赌徒的目标是通过一定的策略最大化自己的奖励,即获得最多的硬币。 若仅为获知每个摇臂的期望奖励,则可采用仅探索(Exploration-only)法:将所有的尝试机会平均分配给每个摇臂(即轮流按下每个摇臂),最后以每个摇臂各自的平均吐币概率作为其奖励期望的近似估计。若仅为执行奖励最大的动作,则可采用仅利用(Exploitation-only)法:按下目前最优的(即到目前为止平均奖励最大的)摇臂,若有多个摇臂同为最优,则从中随机选取一个。
显然,仅探索法能很好地估计每个摇臂的奖励,却会失去很多选择最优摇臂的机会;仅利用法则相反,它没有很好地估计摇臂期望奖励,很可能经常选不到最优摇臂。因此,这两种方法都难以使最终的累积奖励最大化。
事实上,探索(估计摇臂的优劣)和利用(选择当前最优摇臂)这两者是矛盾的,因为尝试次数(总投币数)有限,加强了一方则自然会削弱另一方,这就是强化学习所面临的探索-利用窘境(Exploration-Exploitation Dilemma)。显然,想要累积奖励最大,则必须在探索与利用之间达成较好的折中。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022
相关文章:
深入理解强化学习——学习(Learning)、规划(Planning)、探索(Exploration)和利用(Exploitation)
分类目录:《深入理解强化学习》总目录 学习 学习(Learning)和规划(Planning)是序列决策的两个基本问题。 如下图所示,在强化学习中,环境初始时是未知的,智能体不知道环境如何工作&a…...

大模型LLM相关面试题整理-训练集-训练经验-微调
3 大模型(LLMs)微调 3.1 如果想要在某个模型基础上做全参数微调,究竟需要多少显存? 要确定全参数微调所需的显存量,需要考虑以下几个因素: 模型的大小:模型的大小是指模型参数的数量。通常&…...
qt 实现pdf阅读器
文章目录 概要方案一方案二一、介绍二、编译三、用法本项目代码 概要 在qt程序中,要实现PDF文件浏览,从网上目前找到了两种解决方案,本文主要介绍下着两种方案和适用性。 方案一 这种方法是从https://github.com/develtar/qt-pdf-viewer-l…...
从培训班出来之后找工作的经历,教会了我五件事.....
我是非计算机专业,由于专业不好实习急着就业有过一些失败的工作经历后,跑去参加培训进入IT这行的。 之前在报名学习软件测试之前我也很纠结,不知道怎么选择机构。后面看到有同学在知乎上分享自己的学习经历,当时对我的帮助很大。…...

idea中还原dont ask again
背景 在使用idea打开另外一个项目的时候,一不小心勾选为当前项目而且是不在下次询问,导致后面每次打开新的项目都会把当前项目关闭,如下图所示 下面我们就一起看一下如何把这个询问按钮还原回来 preferences/settings->Appearance&…...

Unity之ShaderGraph如何实现光边溶解
前言 今天我们来实现一个最常见的随机溶剂效果。如下图所示: 光边溶解效果: 无光边效果 主要节点 Simple Noise:根据输入UV生成简单噪声或Value噪声。生成的噪声的大小由输入Scale控制。 Step:对于每个组件,如果输…...

Go语言和Python语言哪个比较好?
目录 1、性能 2、开发效率和易用性 3、社区支持 4、语法 5、其他因素 总结 Go语言和Python语言都是非常优秀的编程语言,它们各自具有不同的优势和适用场景。在选择哪种语言更适合您的项目时,需要考虑多个方面,包括性能、开发效率、可读…...

MAYA教程之模型的UV拆分与材质介绍
什么是UV 模型制作完成后,需要给模型进行贴图,就需要用到UV功能 UV编译器介绍 打开UI编译器 主菜单有一个 UV->UV编译器,可以点击打开 创建一个模型,可以看到模型默认的UV UV编译器功能使用 UV模式的选择 在UV编译器中…...
)
vscode调试container(进行rocksdb调试)
vscode调试container(进行rocksdb调试) 参考链接: https://blog.csdn.net/qq_29809823/article/details/128445308#t5 https://blog.csdn.net/qq_29809823/article/details/121978762#t7 使用vscode中的插件dev containners->点击左侧的…...

从恐怖到商机:2023万圣节跨境电商如何打造鬼魅消费体验?
又到了一年一度的糖果、恐怖装扮和万圣节派对的时候!随着10月底的日子临近,人们开始为庆祝万圣节做各种各样的准备。而对于跨境电商来说,这个节日也是一个独特的商机,能够在全球市场上推广各种各样的节日相关商品。Adobe Digital …...
修炼k8s+flink+hdfs+dlink(五:安装dockers,cri-docker,harbor仓库,k8s)
一:安装docker。(所有服务器都要安装) 安装必要的一些系统工具 sudo yum install -y yum-utils device-mapper-persistent-data lvm2添加软件源信息 sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/cent…...
从实时数据库转战时序数据库,他陪伴 TDengine 从 1.0 走到 3.0
关于采访嘉宾 在关胜亮的学生时代,“神童”这个称号如影随形,很多人初听时会觉得这个称谓略显夸张,有些人还会认为这是不是就是一种调侃,但是如果你听说过他的经历,就会理解这一称号的意义所在了。 受到教师母亲的影…...
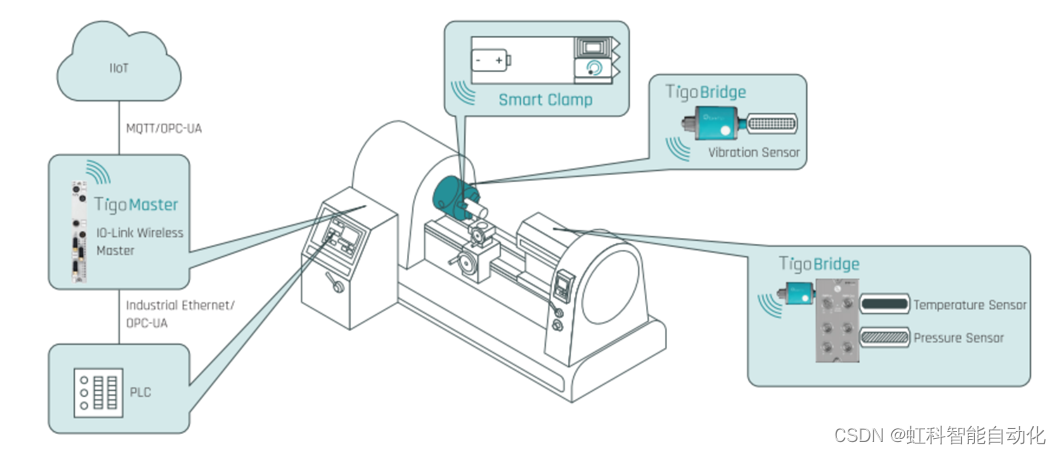
颠覆传统有线通讯,虹科IO-Link wireless解决方案让智能机床的旋转部件实现可靠低延迟无线通信
作为新工业革命的一部分,传统机床正迅速发展成为智能机床。在工业4.0技术的推动下,新的创新应用使机床的效率和功能达到了更高的水平。要实现这些功能,需要在机床上集成传感器和执行器,以提供实时数据和自动化控制。然而ÿ…...
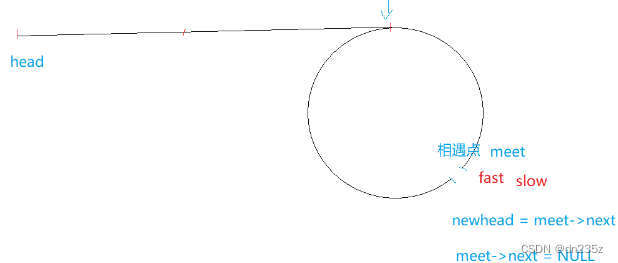
链表 oj2 (7.31)
206. 反转链表 - 力扣(LeetCode) 我们通过头插来实现 将链表上的节点取下来(取的时候需要记录下一个节点),形成新的链表,对新的链表进行头插。 /*** Definition for singly-linked list.* struct ListNode…...

python案例:六大主流小说平台小说下载
嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 很多小伙伴学习Python的初衷就是为了爬取小说,方便又快捷~ 辣么今天咱们来分享6个主流小说平台的爬取教程~ 一、流程步骤 流程基本都差不多&#x…...

前端已死!转行网络安全,挖漏洞真香!
最近,一个做运维的朋友在学渗透测试。他说,他公司请别人做渗透测试的费用是 2w/人天,一共2周。2周 10w 的收入,好香~ 于是,我也对渗透测试产生了兴趣。开始了探索之路~ 什么是渗透测试 渗透测试这名字听起来有一种敬畏…...

【AI】了解人工智能、机器学习、神经网络、深度学习
深度学习、神经网络的原理是什么? 深度学习和神经网络都是基于对人脑神经系统的模拟。下面将分别解释深度学习和神经网络的原理。深度学习的原理:深度学习是一种特殊的机器学习,其模型结构更为复杂,通常包括很多隐藏层。它依赖于神…...
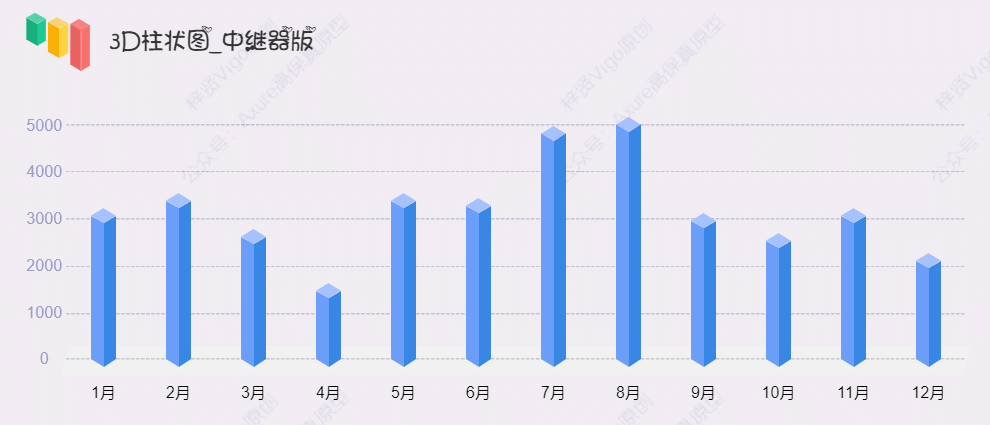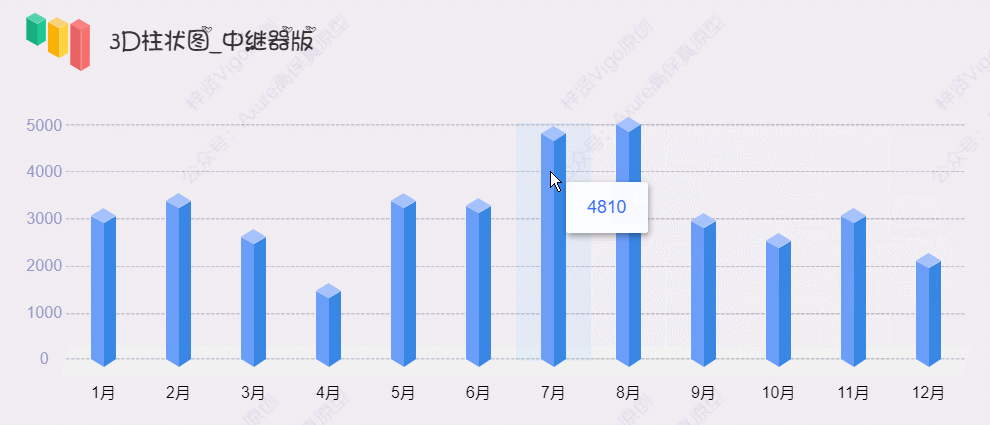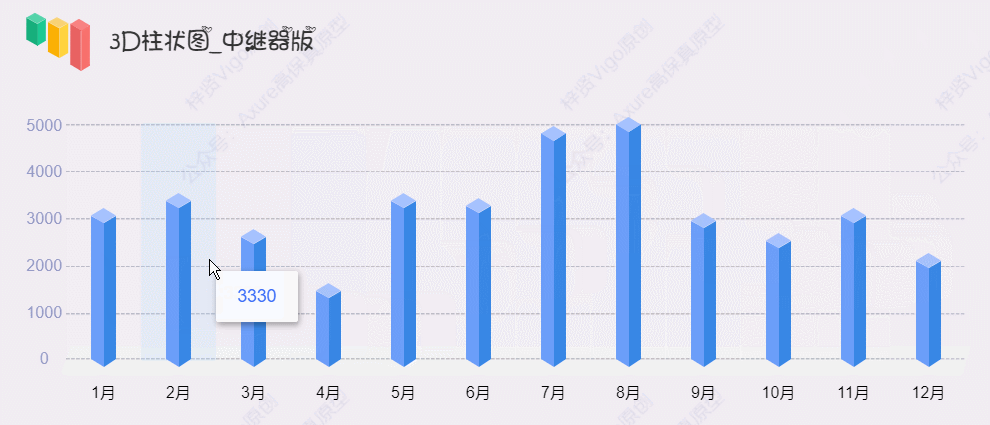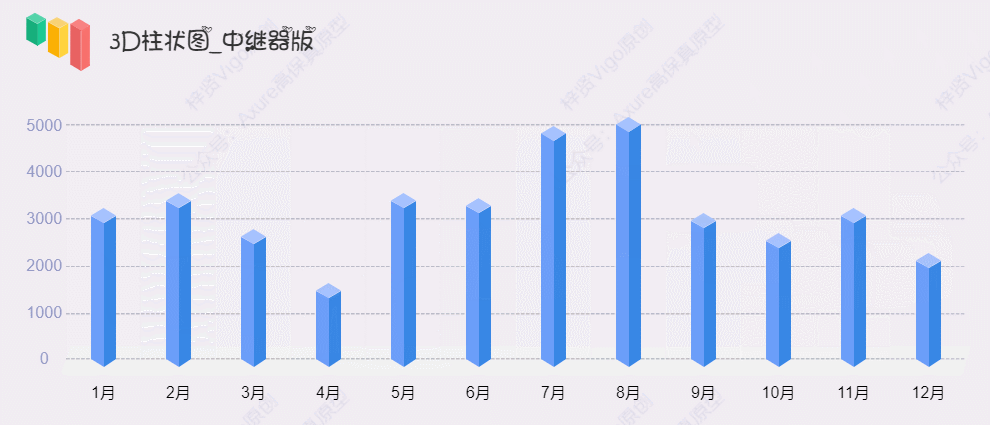
【Axure高保真原型】3D柱状图_中继器版
今天和大家分享3D柱状图_中继器版的原型模板,图表在中继器表格里填写具体的数据,调整坐标系后,就可以根据表格数据自动生成对应高度的柱状图,鼠标移入时,可以查看对应圆柱体的数据……具体效果可以打开下方原型地址体验…...
【word技巧】word页眉,如何禁止他人修改?
我们设置了页眉内容之后,不想其他人修改自己的页眉内容,我们可以设置加密的,设置方法如下: 先将页眉设置好,退出页眉设置之后,我们选择布局功能,点击分隔符 – 连续 设置完之后页面分为上下两节…...
Python 机器学习入门之逻辑回归
系列文章目录 第一章 Python 机器学习入门之线性回归 第一章 Python 机器学习入门之梯度下降法 第一章 Python 机器学习入门之牛顿法 第二章 Python 机器学习入门之逻辑回归 逻辑回归 系列文章目录前言一、逻辑回归简介二、逻辑回归推导1、问题2、Sigmoid函数3、目标函数3.1 让…...

2026年AI文字做海报工具横评:6款实测对比,设计小白也能5分钟出图
摘要 2026年,AI做海报已经不是新鲜事,但"输入文字就能出海报"和"出一张能用的海报"之间,差距大得离谱。 我测了6款主流的可以AI文字做海报的工具,有的生成速度很快但排版像模板套娃,有的效果惊艳…...

从U-Net到DocUNet:一个图像分割经典架构如何“跨界”解决文档矫正难题?
从U-Net到DocUNet:经典分割架构如何重塑文档图像矫正技术 当你在咖啡馆随手拍下一张皱巴巴的收据时,是否想过手机镜头捕捉的二维图像如何还原成平整的文档?这个看似简单的需求背后,隐藏着计算机视觉领域一个极具挑战性的几何变换问…...

测试工程师必知的10个Linux命令:提升工作效率的利器
在软件测试领域,Linux系统是绕不开的重要工具。绝大多数应用后台都部署在Linux服务器上,从环境搭建、日志分析到性能监控,熟练掌握Linux命令能让测试工程师的工作效率大幅提升。不同职级的测试工程师对Linux的需求各有侧重:初级工…...

别再只会F10/F11了!Qt Creator调试实战:用条件断点和数据断点精准定位UI卡顿
Qt Creator高级调试实战:用条件断点和数据断点精准解决UI卡顿问题 在开发数据密集型Qt应用程序时,最令人头疼的莫过于那些难以复现的UI卡顿问题。当用户抱怨"点击按钮后界面会冻结几秒"时,传统的逐行调试(F10/F11)往往如同大海捞针…...

5分钟快速上手Vue FastAPI Admin:现代化前后端分离管理平台完整指南
5分钟快速上手Vue FastAPI Admin:现代化前后端分离管理平台完整指南 【免费下载链接】vue-fastapi-admin ⭐️ 基于 FastAPIVue3Naive UI 的现代化轻量管理平台 A modern and lightweight management platform based on FastAPI, Vue3, and Naive UI. 项目地址: h…...

树莓派命令行保姆级避坑指南:从sudo权限到安全关机,别再乱敲命令了
树莓派命令行深度避坑手册:从权限管理到系统维护的黄金法则 当你第一次拿到树莓派时,那种兴奋感可能让你迫不及待地想尝试各种命令。但很快,你会发现这个小小的设备背后隐藏着许多"陷阱"——一个错误的sudo命令可能导致系统崩溃&am…...

【Python自动化】PyAutoGUI构建游戏稳定性测试守护脚本
1. PyAutoGUI在游戏测试中的核心价值 游戏稳定性测试往往需要长时间运行,人工值守既低效又容易遗漏异常。PyAutoGUI作为Python的GUI自动化利器,能完美模拟鼠标键盘操作,配合进程监控和图像识别,构建724小时无人值守的测试环境。我…...

高端工程场景实测:OpenAI Codex CLI 在微服务重构中的 3 类能力边界
1. 微服务重构现场:Codex CLI 不是万能胶,但能精准补上三块关键拼图 我接手一个运行了四年的电商微服务集群时,它正卡在「订单履约链路」的重构临界点上。17个服务、32个跨服务调用点、4种异步消息协议、2套数据库分片策略——人工梳理接口契约要两周,写迁移脚本要三天,验…...

量子安全与后量子密码学:awesome-quantum-software中的加密工具
量子安全与后量子密码学:awesome-quantum-software中的加密工具 【免费下载链接】awesome-quantum-software Curated list of open-source quantum software projects. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-quantum-software 在后量子计算时…...

智能字幕革命:Open-Lyrics如何用AI重新定义音频内容处理
智能字幕革命:Open-Lyrics如何用AI重新定义音频内容处理 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。 项…...