Datawhale学习笔记AI +新能源:电动汽车充电站充电量预测
赛题介绍
建立站点充电量预测模型,根据充电站的相关信息和历史电量数据,准确预测未来某段时间内充电站的充电量需求。
在赛题数据中,我们提供了电动汽车充电站的场站编号、位置信息、历史电量等基本信息。我们鼓励参赛选手在已有数据的基础上补充或构造额外的特征,以获得更好的预测性能
赛题任务
根据赛题提供的电动汽车充电站多维度脱敏数据,构造合理特征及算法模型,预估站点未来一周每日的充电量。(以天为单位),属于典型的回归问题。
数据集
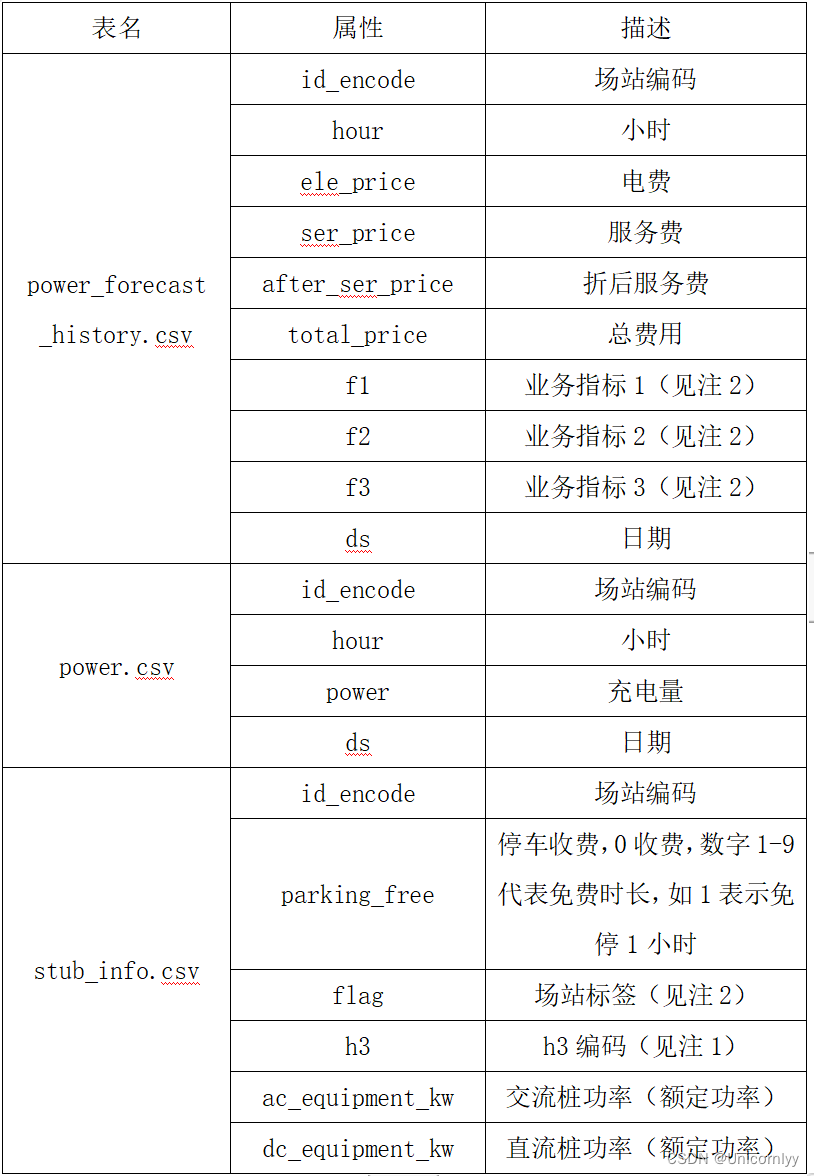
本赛题提供的数据集包含三张数据表。
其中,power_forecast_history.csv 为站点运营数据,power.csv为站点充电量数据,stub_info.csv为站点静态数据,训练集为历史一年的数据,测试集为未来一周的数据。
以下是本次赛题数据集的字段说明:
数据集下载

评估指标
评估指标:RMSE(均方根误差)
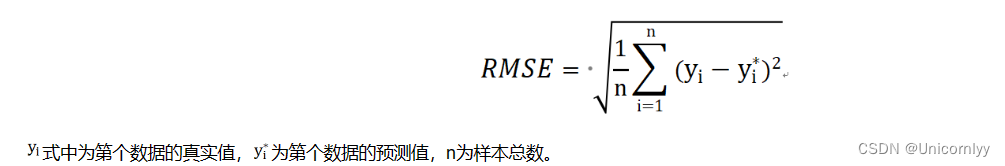
均方根误差是预测值与真实值偏差的平方与观测次数n比值的平方根。
衡量的是预测值与真实值之间的偏差,并且对数据中的异常值较为敏感,受异常值的影响更大,所以要想好如何处理异常值上分。
常用于评测回归任务,常用来作为机器学习模型预测结果衡量的标准。
与MSE的区别
MSE是真实值与预测值的差值的平方然后求和平均。通过平方的形式便于求导,所以常被用作线性回归的损失函数。
MAE对异常值不敏感,但它不能反映预测误差的分布情况。
RMSE放大了较大误差之间的差距,此外,RMSE计算后的结果与实际值的单位相同,而MSE的结果是实际值单位的平方。因此,如果我们要直观地了解模型的预测误差,通常会使用RMSE作为指标。
提交示例
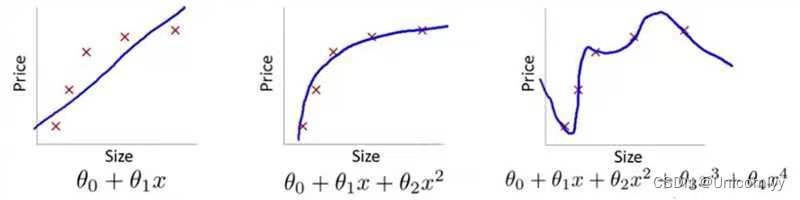
过拟合与欠拟合
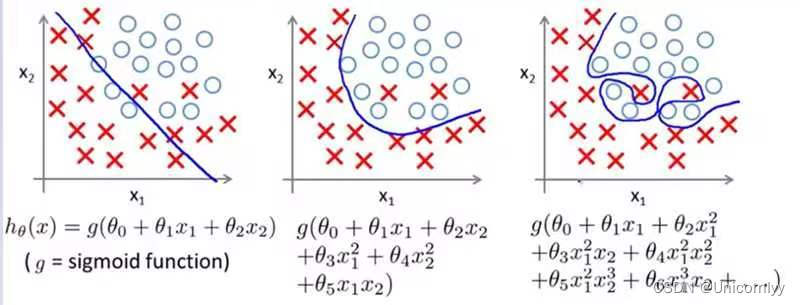
第一个欠拟合,第二个正常,第三个过拟合
欠拟合:欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在训练集上就表现很差,没法学习到数据背后的规律。
如何解决欠拟合?
欠拟合基本上都会发生在训练刚开始的时候,经过不断训练之后欠拟合应该不怎么考虑了。但是如果真的还是存在的话,可以通过增加网络复杂度或者在模型中增加特征,这些都是很好解决欠拟合的方法。
过拟合:过拟合是指训练误差和测试误差之间的差距太大。换句换说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差。模型对训练集"死记硬背"(记住了不适用于测试集的训练集性质或特点),没有理解数据背后的规律,泛化能力差
为什么会出现过拟合现象?
造成原因主要有以下几种:
- 训练数据集样本单一,样本不足。如果训练样本只有负样本,然后那生成的模型去预测正样本,这肯定预测不准。所以训练样本要尽可能的全面,覆盖所有的数据类型。
- 训练数据中噪声干扰过大。噪声指训练数据中的干扰数据。过多的干扰会导致记录了很多噪声特征,忽略了真实输入和输出之间的关系。
- 模型过于复杂。模型太复杂,已经能够“死记硬背”记下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的模型都有稳定的输出。模型太复杂是过拟合的重要因素。
如何解决过拟合?
要想解决过拟合问题,就要显著减少测试误差而不过度增加训练误差,从而提高模型的泛化能力。我们可以使用正则化(Regularization)方法。
常用的正则化方法根据具体的使用策略不同可分为:(1)直接提供正则化约束的参数正则化方法,如L1/L2正则化;(2)通过工程上的技巧来实现更低泛化误差的方法,如提前终止(Early stopping)和Dropout;(3)不直接提供约束的隐式正则化方法,如数据增强等。
正常拟合:模型的正常拟合是指训练得到的模型,可以从训练数据集上学习得到了泛化能力强、预测误差小的模型,同时该模型还可以针对待测试的数据进行良好的预测,获得令人满意的预测效果。
三种情况在训练数据集上的预测误差的表现形式为:欠拟合>正常拟合>过拟合;而在测试集上的预测误差形式为:欠拟合>过拟合>正常拟合。
所以下面这张也是第一个欠拟合,第二个正常拟合,第三个过拟合
在机器学习中,以下哪些技术是数据清洗的相关技术?
A去除重复数据
B处理缺失数据
C异常值处理
D数据标准化/归一化
数据清洗是将重复、多余的数据筛选清除,将缺失的数据补充完整,将错误的数据纠正或者删除,最后整理成为我们可以进一步加工、使用的数据。
数据清洗的一般步骤:分析数据、缺失值处理、异常值处理、去重处理、噪音数据处理。在大数据生态圈,有很多来源的数据ETL工具,但是对于公司内部来说,稳定性、安全性和成本都是必须考虑的。
baseline解读
对于常见的时序问题,我们可以采用历史平移、滑窗统计,尽可能的提取时间特征等方法进行特征工程。
增加工作日非工作日特征
df['weekday'] = df_copy[col].dt.weekday
df['is_weekend'] = df['weekday'].isin([5, 6]).astype(int)
df['is_workday'] = (df['weekday'] < 5).astype(int)
增加小时,分钟特征
df_copy[prefix + 'hour'] = df_copy[col].dt.hour
df_copy[prefix + 'minute'] = df_copy[col].dt.minute
相对时间差特征
df['diff_from_start'] = (df_copy[col] - df_copy[col].iloc[0]).dt.days
df['diff_to_end'] = (df_copy[col].iloc[-1] - df_copy[col]).dt.days
构建了历史平移特征、差分特征、和窗口统计特征
(1)历史平移特征:通过历史平移获取上个阶段的信息;
(2)差分特征:可以帮助获取相邻阶段的增长差异,描述数据的涨减变化情况。在此基础上还可以构建相邻数据比值变化、二阶差分等;
(3)窗口统计特征:窗口统计可以构建不同的窗口大小,然后基于窗口范围进统计均值、最大值、最小值、中位数、方差的信息,可以反映最近阶段数据的变化情况。
# 合并训练数据和测试数据
df = pd.concat([train_df, test_df], axis=0).reset_index(drop=True)# 历史平移
for i in range(7,36):df[f'power_shift{i}'] = df.groupby('id_encode')['power'].shift(i)window_size = 7# 历史平移 + 差分特征
for i in range(1,4):df[f'power_shift7_diff{i}'] = df.groupby('id_encode')['power_shift7'].diff(i)# 窗口统计
for win in [7,14,28,35,50,70]:df[f'power_win{win}_mean'] = df.groupby('id_encode')['power'].rolling(window=win, min_periods=3, closed='left').mean().valuesdf[f'power_win{win}_median'] = df.groupby('id_encode')['power'].rolling(window=win, min_periods=3, closed='left').median().valuesdf[f'power_win{win}_max'] = df.groupby('id_encode')['power'].rolling(window=win, min_periods=3, closed='left').max().valuesdf[f'power_win{win}_min'] = df.groupby('id_encode')['power'].rolling(window=win, min_periods=3, closed='left').min().valuesdf[f'power_win{win}_std'] = df.groupby('id_encode')['power'].rolling(window=win, min_periods=3, closed='left').std().values# 历史平移 + 窗口统计
for win in [7,14,28,35,50,70]:df[f'power_shift7_win{win}_mean'] = df.groupby('id_encode')['power_shift7'].rolling(window=win, min_periods=3, closed='left').mean().valuesdf[f'power_win{win}_median'] = df.groupby('id_encode')['power'].rolling(window=win, min_periods=3, closed='left').median().valuesdf[f'power_shift7_win{win}_max'] = df.groupby('id_encode')['power_shift7'].rolling(window=win, min_periods=3, closed='left').max().valuesdf[f'power_shift7_win{win}_min'] = df.groupby('id_encode')['power_shift7'].rolling(window=win, min_periods=3, closed='left').min().valuesdf[f'power_shift7_win{win}_sum'] = df.groupby('id_encode')['power_shift7'].rolling(window=win, min_periods=3, closed='left').sum().valuesdf[f'power_shift7_win{win}_std'] = df.groupby('id_encode')['power_shift7'].rolling(window=win, min_periods=3, closed='left').std().values
lgbm参数详解
# 定义lightgbm参数params = {'boosting_type': 'gbdt',#提升树的类型。值为 'gbdt' 表示梯度提升决策树'objective': 'regression',#损失函数。这里是回归问题,所以选用回归损失函数,即 'regression'。'metric': 'rmse',#评价指标。衡量模型性能的指标,这里使用均方根误差(RMSE)作为评价指标。'min_child_weight': 5,#一个叶子节点最小的样本权重和。用来控制过拟合。如果这个值过高,则会导致欠拟合,反之则会导致过拟合。'num_leaves': 2 ** 5,#决策树上的叶子节点数。这个参数通常比较敏感,其值越大,模型越复杂,容易过拟合。'lambda_l2': 10,#L2 正则化系数。增加这个值可以减少模型的复杂度,防止过拟合。'feature_fraction': 0.8,#训练每棵树时,使用的特征比例。设置该参数可以防止过拟合,提高模型的泛化能力。'bagging_fraction': 0.8,#构造每棵树所使用的数据比例,通常选取比较小的值,和 feature_fraction 一起使用,可以控制模型的复杂度。'bagging_freq': 4,#执行 bagging 操作的频率。设置为 0 表示不使用 bagging 操作。'learning_rate': 0.05,#学习率。控制每次迭代调整的步长。如果设置的学习率过大,则可能无法收敛,如果设置的学习率过小,则可能需要较长时间才能得到最终结果。'seed': 2023,#随机种子。设定一个随机种子,可以保证结果的可重复性。'nthread' : 16,#线程数。LGBM 中多线程并行计算提高了训练速度,该参数用来指定线程数。'verbose' : -1,#是否打印调试信息。设置为 -1 时不打印任何信息。# 'device':'gpu'}lgbm参数详解
pandas_profiling简介
python库:pandas_profiling,这个库只需要一行代码就可以生成数据EDA报告。
基于pandas的DataFrame数据类型,可以简单快速地进行探索性数据分析
对于数据集的每一列,pandas_profiling会提供以下统计信息:
1、概要:数据类型,唯一值,缺失值,内存大小
2、分位数统计:最小值、最大值、中位数、Q1、Q3、最大值,值域,四分位
3、描述性统计:均值、众数、标准差、绝对中位差、变异系数、峰值、偏度系数
4、最频繁出现的值,直方图/柱状图
5、相关性分析可视化:突出强相关的变量,Spearman, Pearson矩阵相关性色阶图
并且这个报告可以导出为HTML,非常方便查看。对不太熟悉python数据分析的新手来说十分友好。
安装:
pip install pandas-profiling
使用pandas_profiling生成数据探索报告:
report = pp.ProfileReport(data)
report
导出为html文件
report.to_file('report.html')
“H3” 是一个用于地理空间索引和网格系统的开源库。它将地球表面划分为一系列分辨率逐渐变粗的六边形单元格,每个单元格都有唯一的标识符,称为 H3 地址。H3 地址可以表示不同级别的地理区域,例如国家、城市、街区等。
要将 H3 地址转换为地理坐标(经度和纬度),可以使用 H3 库中的函数
安装
pip install h3-python
示例代码
import h3h3_address = '8928308280fffff' # 示例 H3 地址coordinates = h3.h3_to_geo(h3_address)latitude = coordinates[0]
longitude = coordinates[1]print("Latitude:", latitude)
print("Longitude:", longitude)
数据探索
fromDatawhale直播一禧助教
df['new_date'] = pd.to_datetime(df['ds']* 100 + df['ds_hour'].astype(int), format='%Y%m%d%H')
df['ds_date'] = df['new_date'].dt.date
############################ 绘图函数
def my_plot(df, id_encode, start_date, end_date, groupby, predict=False): # 绘制折线图fig = plt.figure(figsize=(20,10))df = df.loc[(df['ds'] >= start_date) & (df['ds'] <= end_date)]if id_encode > -1:df = df.loc[df['id_encode'] == id_encode]else:passif groupby == 'hour':plt.plot(df['new_date'], df['power'], color = 'blue')if predict == True:plt.plot(df['new_date'], df['power_pre'], color = 'red')try:plt.plot(df['new_date'], df['temp_max'], color = 'brown')plt.plot(df['new_date'], df['temp_min'], color = 'green')except:passelif groupby == 'day':df_power = df.groupby(by = 'ds_date')['power'].sum().reset_index()plt.plot(df_power['ds_date'], df_power['power'], color = 'blue')if predict == True:df_power_pre = df.groupby(by = 'ds_date')['power_pre'].sum().reset_index()plt.plot(df_power_pre['ds_date'], df_power_pre['power_pre'], color = 'red')# 添加标题和轴标签plt.title('Power vs Date')plt.xlabel('Date')plt.ylabel('Power')# 显示图形plt.show()
我这里按照助教说的画了两个图
my_plot(df, id_encode=-1, start_date=20220401, end_date=20230610, groupby='day')
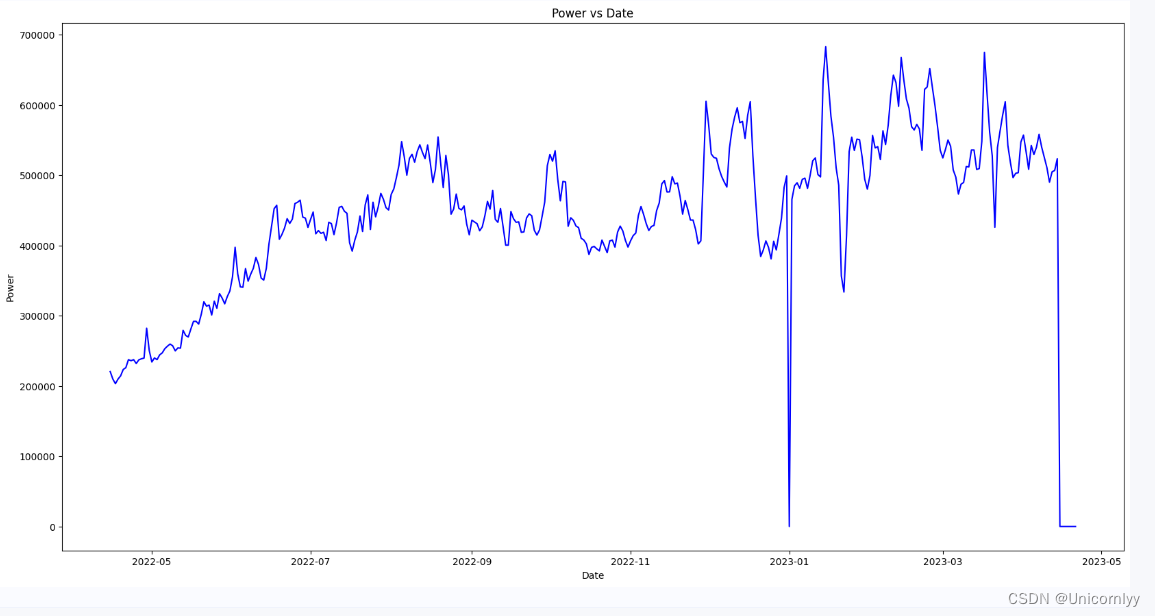
202301应该是春节期间大年30大家都回乡下城市的充电量下降
my_plot(df, id_encode=-1, start_date=20230301, end_date=20230610, groupby='day')
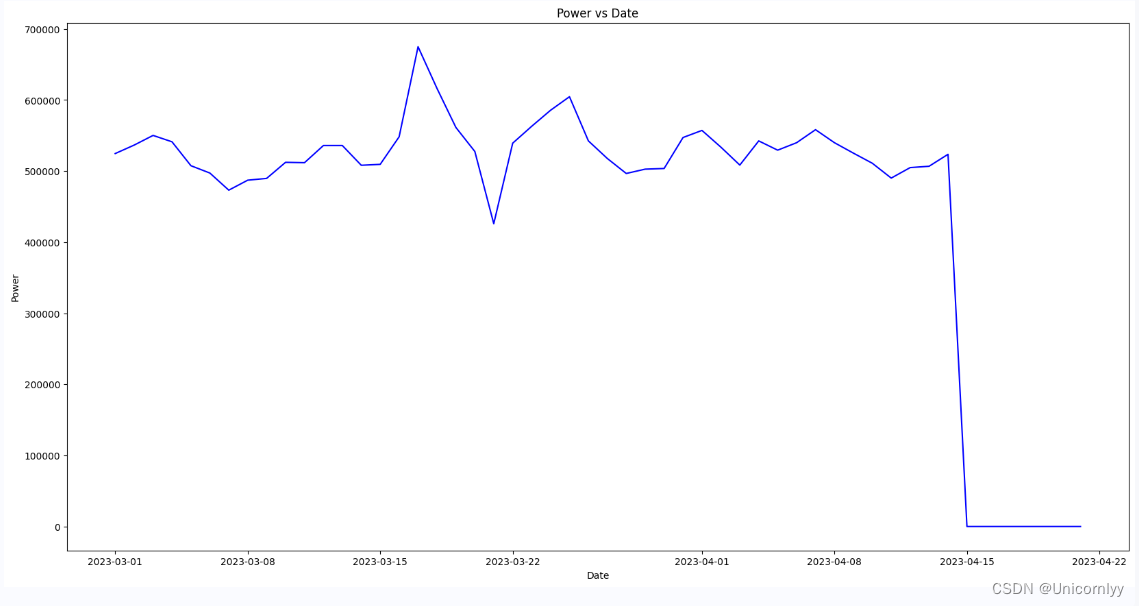
20230322是因为寒潮所以有所下降
然后助教还说了可以将h3转换为经纬度,但因为我这边不太懂暂时还没有尝试这种方法
我这边使用sklearn库中的LabelEncoder类来对数据进行标签编码(Label Encoding)操作
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
train_df['h3'] = le.fit_transform(train_df['h3'])
test_df['h3'] = le.fit_transform(test_df['h3'])
但是似乎效果不是特别好
相关文章:
Datawhale学习笔记AI +新能源:电动汽车充电站充电量预测
赛题介绍 建立站点充电量预测模型,根据充电站的相关信息和历史电量数据,准确预测未来某段时间内充电站的充电量需求。 在赛题数据中,我们提供了电动汽车充电站的场站编号、位置信息、历史电量等基本信息。我们鼓励参赛选手在已有数据的基础上…...
记一次fineBI的增量删除更新BUG
官方文档链接是https://help.fanruan.com/finebi/doc-view-1663.html 按照官方文档,增量删除不能使用select * ,且需要指定分区建 但实际指定分区键有时候也会报错,因为表设置的字段有时候会比数据源少,此时会报错,提…...

rsync+inotify实时同步+双向同步
准备主机 192.168.1.247 (源) /home/appdata 192.168.1.248 (目的) /home/appdata 实现效果: 1.用rsync手动将192.168.1.247 的/home/appdata同步到192.168.1.248的/home/appdata目录。 2.用inotify组件实现文件的…...
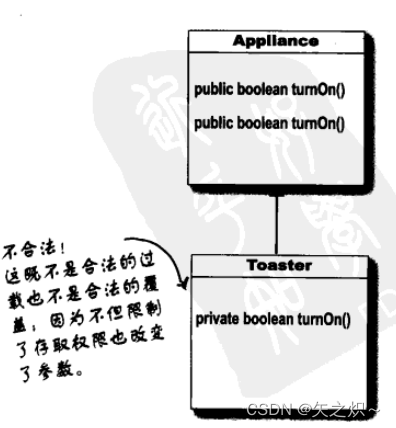
7.继承与多态 对象村的优质生活
7.1 民法亲属篇:继承(inheritance) 了解继承 在设计继承时,你会把共同的程序代码放在某个类中,然后告诉其他的类说此类是它们的父类。当某个类继承另一个类的时候,也就是子类继承自父类。以Java的方式说&…...
机器视觉、图像处理和计算机视觉:概念和区别
机器视觉、图像处理和计算机视觉:概念和区别 机器视觉、图像处理和计算机视觉是相关但有区别的概念。 机器视觉主要应用于工业领域,涉及图像感知、图像处理、控制理论和软硬件的结合,旨在实现高效的运动控制或实时操作。 图像处理是指利用…...

从零开始的C语言学习第二十课:数据在内存中的存储
目录 1. 整数在内存中的存储 2. 大小端字节序和字节序判断 2.1 什么是大小端? 2.2 为什么有大小端? 3. 浮点数在内存中的存储 3.1 浮点数存的过程 3.2 浮点数取的过程 1. 整数在内存中的存储 在讲解操作符的时候,我们就讲过了下⾯的内容&#x…...

分布式内存计算Spark环境部署与分布式内存计算Flink环境部署
目录 分布式内存计算Spark环境部署 1. 简介 2. 安装 2.1【node1执行】下载并解压 2.2【node1执行】修改配置文件名称 2.3【node1执行】修改配置文件,spark-env.sh 2.4 【node1执行】修改配置文件,slaves 2.5【node1执行】分发 2.6【node2、no…...

am权限系统对接笔记
文章目录 角色如何对应机构如何对应 am需要提供的接口机构、角色、人员查关系 消息的交互方式方式1 接口查询方式2 mq推送消息到业务系统 am是一套通用权限管理系统。 为什么要接入am呢? 举例,甲方有10个供方,每个供方都有单独的权限系统,不…...

回首往昔,初学编程那会写过的两段愚蠢代码
一、关于判断两个整数是否能整除的GW BASIC创意代码 记得上大学时第一个编程语言是BASIC,当时Visual Basic还没出世,QBASIC虽然已经在1991年随MS-DOS5.0推出了,但我们使用的还是 GW-BASIC, 使用的教材是谭浩强、田淑清编著的《BA…...

《Java面向对象程序设计》学习笔记——Java程序填空题
笔记汇总:《Java面向对象程序设计》学习笔记 这些题其实都非常滴简单,相信大伙能够立刻就秒了吧😎 文章目录 题目答案 题目 以下程序要求从键盘输入一个整数, 判别该整数为几位数, 并且输出结果, 请将下…...

Chrome跨域访问网络请求Cookies丢失的解决办法
为了保障网络安全,Chrome对跨域访问有一定的限制。一般分为三级: cookies带有“SameSite=Strict”时,只允许访问同一个域名下的网络请求;cookies带有“SameSite=Lax”时,允许访问同一个域名下的网络请求和同一个根域名下的网络请求;cookies带有“SameSite=None”时,允许…...

从创业者的角度告诉你AI问答机器人网页的重要性
在数字化时代,创业者面临着越来越多的挑战。而AI问答机器人网页正成为创业者们的必备工具。它可以提供即时客户支持、降低运营成本,并实现全天候服务。接下来,我将从创业者的角度阐述一下,AI问答机器人网页为什么那么重要…...

大数据Flink(九十七):EXPLAIN、USE和SHOW 子句
文章目录 EXPLAIN、USE和SHOW 子句 一、EXPLAIN 子句 二、USE 子句...

浏览器中的网络钓鱼防护
网络钓鱼防护是一项功能,可保护用户免受旨在窃取其敏感信息的网络钓鱼攻击,网络钓鱼是网络犯罪分子常用的技术,这是一种社会工程攻击,诱使用户单击指向受感染网页的恶意链接,用户在该网页中感染了恶意软件或其敏感信息…...
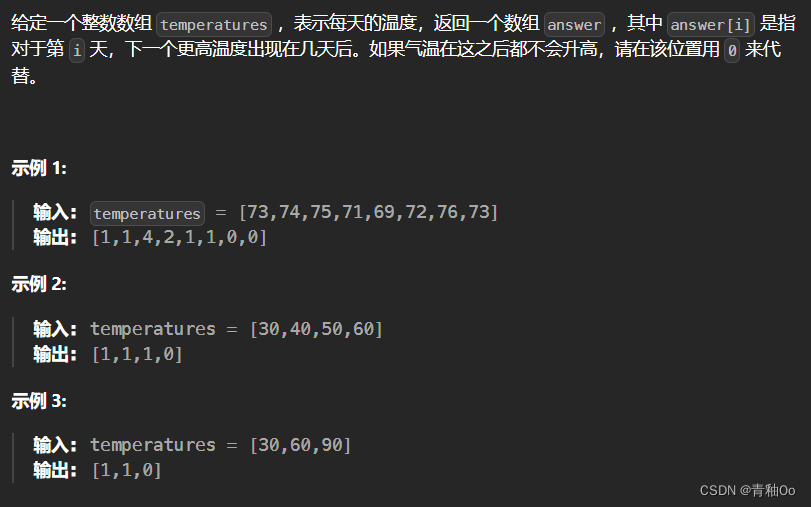
每日温度00
题目链接 每日温度 题目描述 注意点 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后如果气温在这之后都不会升高,请在该位置用 0 来代替1 < temperatures.length < 100000 解答思路 使用单调栈解决本题,思路为:…...
【JVM】JVM的垃圾回收机制
JVM的垃圾回收机制 对象死亡判断方法引用计数算法可达性分析算法 垃圾回收算法标记清除法复制算法标记整理算法分代算法 Java运行时内存的各个区域,对于程序计数器,虚拟机栈,本地方法栈这三个部分区域而言,其生命周期与相关线程有关,随线程而生,随线程而灭,并且这三个区域的内存…...
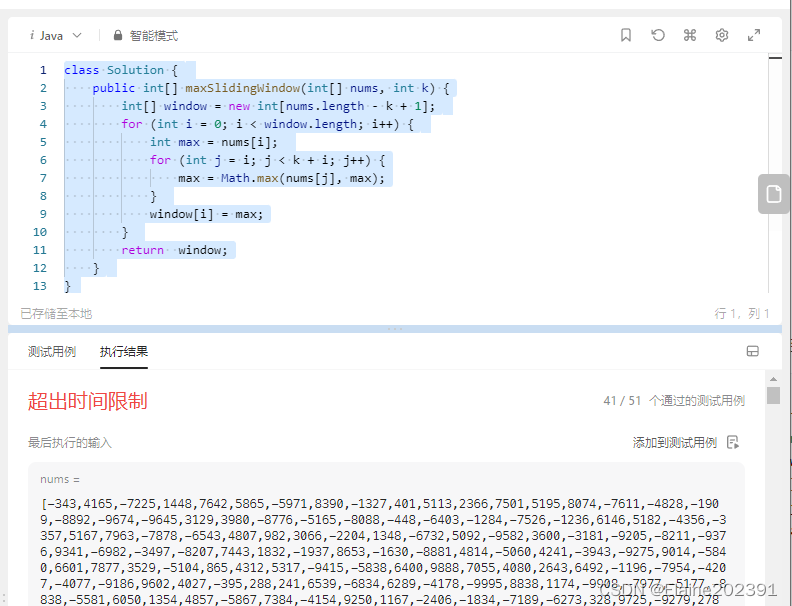
28栈与队列-单调队列
目录 LeetCode之路——239. 滑动窗口最大值 解法一:暴力破解 解法二:单调队列 LeetCode之路——239. 滑动窗口最大值 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k …...

qt软件崩溃的分析方法-定位源文件和行号
软件(debug版exe或者release版exe)在正常运行状态下(不是gdb调试运行),如果软件崩掉,那么会直接闪退,软件什么也做不了,此时无法保存软件中的状态信息,此外,也…...

《实验细节》上手使用PEFT库方法和常见出错问题
《实验细节》上手使用PEFT库方法和常见出错问题 安装问题常用命令使用方法保存peft模型加载本地 peft 模型使用问题问题1 ValueError: Please specify target_modules in peft_config安装问题 首先给出用到的网站 更新NVIDIA网站https://www.nvidia.com/Download/index.aspx 2…...

软考高级系统架构论文 注意事项
目录 前言正文 前言 论文主要体现 分析问题的能力以及解决问题的能力 正文 论文必要的点: 虚构情节、文章中有较严重的不真实或者不可信的内容出现的论文;没有项目开发的实际经验、通篇都是浅层次纯理论的论文;所讨论的内容与方法过于陈|旧,或者项目…...

WaveTools深度解析:鸣潮性能调优与数据统计的技术实现
WaveTools深度解析:鸣潮性能调优与数据统计的技术实现 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 为什么传统游戏优化方法在鸣潮中失效? 我们在实际测试中发现,鸣潮…...

告别触摸漂移!手把手教你为ESP32和XPT2046电阻屏制作LVGL校准工具
ESP32电阻屏精准触控实战:从硬件校准到LVGL交互优化 电阻式触摸屏在嵌入式设备中广泛应用,但精度问题一直困扰着开发者。当你在ESP32上连接XPT2046触摸控制器时,是否遇到过点击位置漂移、响应不准确的烦恼?本文将带你深入解决这一…...

【免费下载】 美国各州区域图-shp格式
美国各州区域图-shp格式 【下载地址】美国各州区域图-shp格式 本资源库提供了一份详尽的美国各州区域图数据,以流行的Shapefile(shp格式)进行封装。Shapefile是一种广泛应用于地理信息系统(GIS)的矢量数据格式…...

别再只用if-else了!Matlab里switch/case的5个高效用法与避坑指南
别再只用if-else了!Matlab里switch/case的5个高效用法与避坑指南 在Matlab编程中,if-else语句几乎是每个开发者最先掌握的控制结构之一。但当你开始处理更复杂的条件逻辑时,一长串的if-elseif-else语句不仅让代码变得难以阅读,还可…...

终极指南:3分钟快速安装Windows官方包管理器Winget
终极指南:3分钟快速安装Windows官方包管理器Winget 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh_mirrors/wi/win…...

XNBCLI深度解析:掌握星露谷物语XNB文件解包打包的完全手册
XNBCLI深度解析:掌握星露谷物语XNB文件解包打包的完全手册 【免费下载链接】xnbcli A CLI tool for XNB packing/unpacking purpose built for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/xn/xnbcli 想要深度定制星露谷物语游戏体验…...

RDMA网络调试实战:当你的应用卡顿时,如何定位是哪种Error导致了重传?
RDMA网络性能调优实战:从重传Error定位到精准修复 RDMA(Remote Direct Memory Access)技术凭借其超低延迟和高吞吐量的特性,已经成为高性能计算、分布式存储和金融交易系统的核心网络架构。但在实际生产环境中,即使是经…...

Linux内核PCIe热插拔驱动开发实战:从IDT芯片到稳定运行
1. 项目概述与核心价值最近在搞一个嵌入式设备项目,需要实现PCIe设备的热插拔支持。这玩意儿在服务器、存储阵列和工业控制领域太常见了,但真要在Linux内核里把它做稳定、做可靠,里面的门道可不少。我这次折腾的,就是一个基于Linu…...

HLK-V20语音模块的智能家居实战:如何用STM32控制灯、电机并连接ESP8266上云
HLK-V20语音模块的智能家居实战:STM32联动控制与云端接入全解析 在智能家居DIY领域,语音控制早已从概念走向现实。HLK-V20作为一款高性价比的纯离线语音识别模块,配合STM32的丰富外设控制能力,可以构建出响应迅速、隐私安全的本地…...

观察使用TaotokenTokenPlan后项目月度AI成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用Taotoken TokenPlan后项目月度AI成本的变化趋势 对于许多采用按量计费模式的中小型项目而言,大模型API的月度支…...