Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件
Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件
- 版本号
- 步骤
- hadoop
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- slaves
- workers
- yarn-site.xml
- hive
- hive-site.xml
- spark-defaults.conf
- spark
- hdfs-site.xml
- hive-site.xml
- slaves
- yarn-site.xml
- spark-env.sh
版本号
apache-hive-3.1.3-bin.tar
spark-3.0.0-bin-hadoop3.2.tgz
hadoop-3.1.3.tar.gz
步骤
在hdfs上新建
spark-history(设置权限777),spark-jars文件夹
上传jar到hdfs
hdfs dfs -D dfs.replication=1 -put ./* /spark-jars
hadoop
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><!--指定hadoop集群在zookeeper上注册的节点名--><property><name>fs.defaultFS</name><value>hdfs://hacluster</value></property><!--指定hadoop运行时产生的临时文件--><property><name>hadoop.tmp.dir</name><value>file:///opt/hadoop-3.1.3/tmp</value></property><!--设置缓存大小 默认4KB--> <property><name>io.file.buffer.size</name><value>4096</value></property><!--指定zookeeper的存放地址--><property><name>ha.zookeeper.quorum</name><value>node15:2181,node16:2181,node17:2181,node18:2181</value></property><!--配置允许root代理访问主机节点--><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!--配置该节点允许root用户所属的组--><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property><!-- 配置HDFS网页登录使用的静态用户为summer--><property><name>hadoop.http.staticuser.user</name><value>root</value></property>
</configuration>hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><property> <!--数据块默认大小128M--> <name>dfs.block.size</name> <value>134217728</value> </property> <property><name>dfs.nameservices</name><value>activeNode</value></property> <property> <!--副本数量 不配置默认为3--> <name>dfs.replication</name> <value>3</value> </property> <property> <!--namenode节点数据(元数据)的存放位置--> <name>dfs.name.dir</name> <value>file:///opt/hadoop-3.1.3/dfs/namenode_data</value> </property><property> <!--datanode节点数据(元数据)的存放位置--> <name>dfs.data.dir</name> <value>file:///opt/hadoop-3.1.3/dfs/datanode_data</value> </property><property><!--开启hdfs的webui界面--> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <!--datanode上负责进行文件操作的线程数--> <name>dfs.datanode.max.transfer.threads</name> <value>4096</value> </property> <property> <!--指定hadoop集群在zookeeper上的注册名--> <name>dfs.nameservices</name> <value>hacluster</value> </property> <property> <!--hacluster集群下有两个namenode分别是nn1,nn2--> <name>dfs.ha.namenodes.hacluster</name> <value>nn1,nn2</value> </property> <!--nn1的rpc、servicepc和http通讯地址 --> <property> <name>dfs.namenode.rpc-address.hacluster.nn1</name> <value>node15:9000</value> </property><property> <name>dfs.namenode.servicepc-address.hacluster.nn1</name> <value>node15:53310</value> </property> <property> <name>dfs.namenode.http-address.hacluster.nn1</name> <value>node15:50070</value> </property> <!--nn2的rpc、servicepc和http通讯地址 --> <property> <name>dfs.namenode.rpc-address.hacluster.nn2</name> <value>node16:9000</value> </property> <property> <name>dfs.namenode.servicepc-address.hacluster.nn2</name> <value>node16:53310</value> </property> <property> <name>dfs.namenode.http-address.hacluster.nn2</name> <value>node16:50070</value> </property> <property> <!--指定Namenode的元数据在JournalNode上存放的位置--> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node15:8485;node16:8485;node17:8485;node18:8485/hacluster</value> </property> <property> <!--指定JournalNode在本地磁盘的存储位置--> <name>dfs.journalnode.edits.dir</name> <value>/opt/hadoop-3.1.3/dfs/journalnode_data</value> </property> <property> <!--指定namenode操作日志存储位置--> <name>dfs.namenode.edits.dir</name> <value>/opt/hadoop-3.1.3/dfs/edits</value> </property> <property> <!--开启namenode故障转移自动切换--> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <!--配置失败自动切换实现方式--> <name>dfs.client.failover.proxy.provider.hacluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <!--配置隔离机制--> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <!--配置隔离机制需要SSH免密登录--> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value></property> <property> <!--hdfs文件操作权限 false为不验证--> <name>dfs.premissions</name> <value>false</value> </property> </configuration>mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><!-- 指定mapreduce使用yarn资源管理器--><property> <name>mapred.job.tracker</name> <value>node15:9001</value> </property><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 配置作业历史服务器的地址--><property><name>mapreduce.jobhistory.address</name><value>node15:10020</value></property><!-- 配置作业历史服务器的http地址--><property><name>mapreduce.jobhistory.webapp.address</name><value>node15:19888</value></property><property><name>yarn.application.classpath</name><value>/opt/hadoop-3.1.3/etc/hadoop:/opt/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/hadoop-3.1.3/share/hadoop/common/*:/opt/hadoop-3.1.3/share/hadoop/hdfs:/opt/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/hadoop-3.1.3/share/hadoop/yarn:/opt/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/hadoop-3.1.3/share/hadoop/yarn/*</value></property><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.map.memory.mb</name><value>1500</value><description>每个Map任务的物理内存限制</description></property><property><name>mapreduce.reduce.memory.mb</name><value>3000</value><description>每个Reduce任务的物理内存限制</description></property><property><name>mapreduce.map.java.opts</name><value>-Xmx1200m</value></property><property><name>mapreduce.reduce.java.opts</name><value>-Xmx2600m</value></property><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>slaves
node15
node16
node17
node18
workers
node15
node16
node17
node18
yarn-site.xml
<?xml version="1.0"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
-->
<configuration><property><!-- 是否对容器强制执行虚拟内存限制 --><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description>Whether virtual memory limits will be enforced for containers</description></property><property><!-- 为容器设置内存限制时虚拟内存与物理内存之间的比率 --><name>yarn.nodemanager.vmem-pmem-ratio</name><value>4</value><description>Ratio between virtual memory to physical memory when setting memory limits for containers</description></property><property> <!--开启yarn高可用--> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <!-- 指定Yarn集群在zookeeper上注册的节点名--> <name>yarn.resourcemanager.cluster-id</name> <value>hayarn</value> </property> <property> <!--指定两个resourcemanager的名称--> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <!--指定rm1的主机--> <name>yarn.resourcemanager.hostname.rm1</name> <value>node15</value> </property><property> <!--指定rm2的主机--> <name>yarn.resourcemanager.hostname.rm2</name> <value>node16</value> </property> <property><!-- RM HTTP访问地址 默认:${yarn.resourcemanager.hostname}:8088--><name>yarn.resourcemanager.webapp.address.rm1</name><value>node15:8088</value></property><property><!-- RM HTTP访问地址 默认:${yarn.resourcemanager.hostname}:8088--><name>yarn.resourcemanager.webapp.address.rm2</name><value>node16:8088</value></property><property> <!--配置zookeeper的地址--> <name>yarn.resourcemanager.zk-address</name> <value>node15:2181,node16:2181,node17:2181</value> </property> <property> <!--开启yarn恢复机制--> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <!--配置执行resourcemanager恢复机制实现类--> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <!--指定主resourcemanager的地址--> <name>yarn.resourcemanager.hostname</name> <value>node18</value> </property> <property> <!--nodemanager获取数据的方式--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <!--开启日志聚集功能--> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <!--配置日志保留7天--> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <property><name>yarn.log.server.url</name><value>http://node15:19888/jobhistory/logs</value></property>
</configuration>hive
hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://node15:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>hadoop</value></property><!-- Hive默认在HDFS的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><!-- Hive元数据存储的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property><!-- 元数据存储授权 --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property><!-- 指定hiveserver2连接的host --><property><name>hive.server2.thrift.bind.host</name><value>node15</value></property><!-- 指定hiveserver2连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property><property><name>spark.yarn.jars</name><value>hdfs://node15:9000/spark-jars/*</value></property><!--Hive执行引擎--><property><name>hive.execution.engine</name><value>spark</value></property><property><name>spark.home</name><value>/opt/spark-3.0.0-bin-hadoop3.2/</value></property>
</configuration>spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node15:9000/spark-history
spark.executor.memory 600m
spark.driver.memory 600m
spark
hdfs-site.xml
链接hadoop中的文件
ln -s 源文件名 新文件名
hive-site.xml
链接hive中的文件
ln -s 源文件名 新文件名
slaves
node15
node16
node17
node18
yarn-site.xml
链接hadoop中的文件
ln -s 源文件名 新文件名
spark-env.sh
#!/usr/bin/env bash#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#export SCALA_HOME=/usr/share/scala
export JAVA_HOME=/usr/java/jdk1.8.0_241-amd64
export SPARK_HOME=/opt/spark-3.0.0-bin-hadoop3.2
export SPARK_MASTER_IP=192.168.206.215
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=7080 #spark的web访问端口默认是8080,防止可能存在端口冲突,可以修
改端口号为其他的export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_EXECUTOR_MEMORY=512M
export SPARK_WORKER_MEMORY=1G
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-3.1.3/bin/hadoop classpath)
export HADOOP_CONF_DIR=/opt/hadoop-3.1.3/etc/hadoop# This file is sourced when running various Spark programs.
# Copy it as spark-env.sh and edit that to configure Spark for your site.# Options read when launching programs locally with
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program# Options read by executors and drivers running inside the cluster
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos# Options read in YARN client/cluster mode
# - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)# Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_HOST, to bind the master to a different IP address or hostname
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2
g)# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
# - SPARK_WORKER_DIR, to set the working directory of worker processes
# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")
# - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default:
1g).# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y
")# - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y")
# - SPARK_DAEMON_CLASSPATH, to set the classpath for all daemons
# - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers# Options for launcher
# - SPARK_LAUNCHER_OPTS, to set config properties and Java options for the launcher (e.g. "-Dx=y")# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
# - SPARK_NO_DAEMONIZE Run the proposed command in the foreground. It will not output a PID file.
# Options for native BLAS, like Intel MKL, OpenBLAS, and so on.
# You might get better performance to enable these options if using native BLAS (see SPARK-21305).
# - MKL_NUM_THREADS=1 Disable multi-threading of Intel MKL
# - OPENBLAS_NUM_THREADS=1 Disable multi-threading of OpenBLAS相关文章:

Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件
Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件 版本号步骤hadoopcore-site.xmlhdfs-site.xmlmapred-site.xmlslavesworkersyarn-site.xml hivehive-site.xmlspark-defaults.conf sparkhdfs-site.xmlhive-site.xmlslavesyarn-site.xmlspark-env.sh 版本号 apache-hive-3.1.3-…...

Hutool工具类参考文章
Hutool工具类参考文章 日期: 身份证:...

【 Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全】
Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全 本文主要介绍了Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值&#x…...

eclipse 配置selenium环境
eclipse环境 安装selenium的步骤 配置谷歌浏览器驱动 Selenium安装-如何在Java中安装Selenium chrome驱动下载 eclipse 启动配置java_home: 在eclipse.ini文件中加上一行 1 配置java环境,网上有很多教程 2 下载eclipse,网上有很多教程 ps&…...
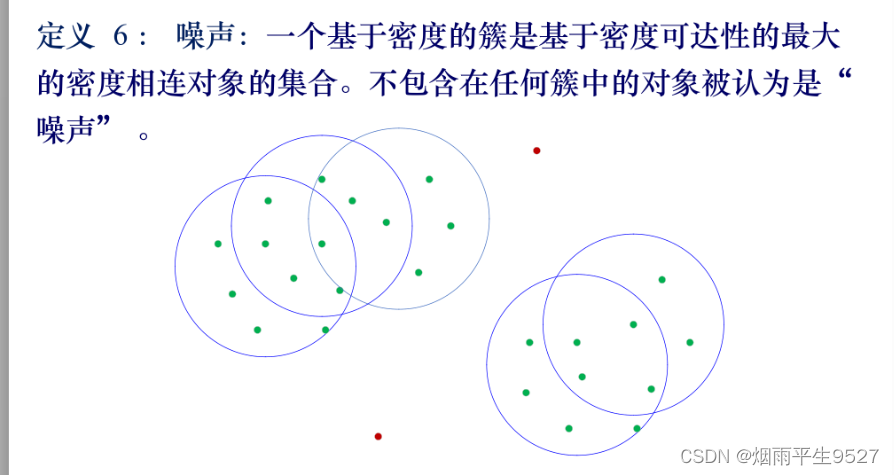
数据挖掘(6)聚类分析
一、什么是聚类分析 1.1概述 无指导的,数据集中类别未知类的特征: 类不是事先给定的,而是根据数据的相似性、距离划分的聚类的数目和结构都没有事先假定。挖掘有价值的客户: 找到客户的黄金客户ATM的安装位置 1.2区别 二、距离和相似系数 …...
在启智平台上安装anconda
安装Anaconda3-5.0.1-Linux-x86_64.sh python版本是3.6 在下面的网站上找到要下载的anaconda版本,把对应的.sh文件下载下来 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 把sh文件压缩成.zip文件,拖到启智平台的调试页面 上传到平台上 un…...

棒球省队建设实施办法·棒球1号位
棒球省队建设实施办法 1. 建设目标与原则 提升棒球省队整体竞技水平 为了提升棒球省队整体竞技水平,我们需要采取一系列有效的措施。 首先,我们应该加强对棒球运动的投入和关注。各级政府和相关部门应加大对棒球运动的经费投入,提高球队的…...

架构案例2017(五十二)
第5题 阅读以下关于Web系统架构设计的叙述,在答题纸上回答问题1至问题3.【说明】某电子商务企业因发展良好,客户量逐步增大,企业业务不断扩充,导致其原有的B2C商品交易平台己不能满足现有业务需求。因此,该企业委托某…...

给四个点坐标计算两条直线的交点
文章目录 1 chatgpt42、文心一言3、星火4、Bard总结 我使用Chatgpt4和文心一言、科大讯飞星火、google Bard 对该问题进行搜索,分别给出答案。先说结论,是chatgpt4和文心一言给对了答案, 另外两个部分正确。 问题是:python 给定四…...

从入门到进阶 之 ElasticSearch SpringData 继承篇
🌹 以上分享 从入门到进阶 之 ElasticSearch SpringData 继承篇,如有问题请指教写。🌹🌹 如你对技术也感兴趣,欢迎交流。🌹🌹🌹 如有需要,请👍点赞…...
中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例
中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例 中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例 中文编程系统化教程,不需英语基础。学习链接 https://edu.csdn.net/course/detail/39036...

YOLOv7改进:动态蛇形卷积(Dynamic Snake Convolution),增强细微特征对小目标友好,实现涨点 | ICCV2023
💡💡💡本文独家改进:动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱的局部结构特征与复杂多变的全局形态特征,对小目标检测很适用 Dynamic Snake Convolution | 亲测在多个数据集能够实现大幅涨点 收录: YOLOv7高阶自研专栏介绍: http://t.csdnimg.…...

从文心大模型4.0与FuncGPT:用AI为开发者打开新视界
今天,在百度2023世界大会上,文心大模型4.0正式发布,而在大洋的彼岸,因为大模型代表ChatGPT之类的AI编码工具来势汹汹,作为全世界每个开发者最爱的代码辅助网站,Stack Overflow的CEO Prashanth Chandrasekar…...
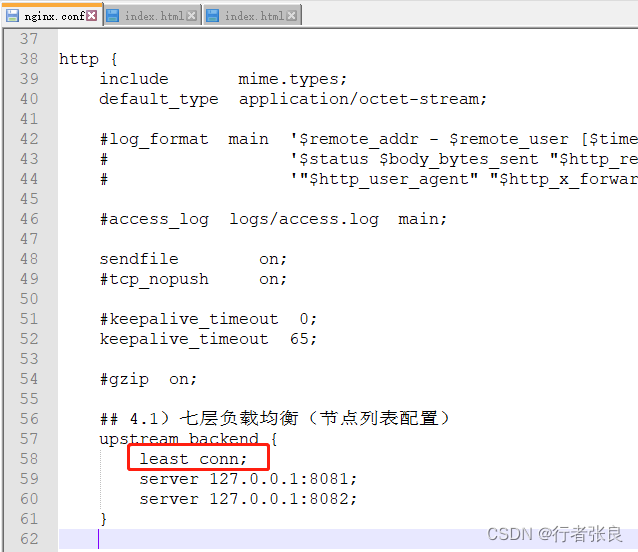
Nginx集群负载均衡配置完整流程
今天,良哥带你来做一个nginx集群的负载均衡配置的完整流程。 一、准备工作 本次搭建的操作系统环境是win11,linux可配置类同。 1)首先,下载nginx。 下载地址为:http://nginx.org/en/download.html 良哥下载的是&am…...

如何生成SSH服务器的ed25519公钥SHA256指纹
最近搭建ubuntu服务器,远程登录让确认指纹,研究一番搞懂了,记录一下。 1、putty 第一次登录服务器,出现提示: 让确认服务器指纹是否正确。 其中:箭头指向的 ed25519 :是一种非对称加密的签名方法…...
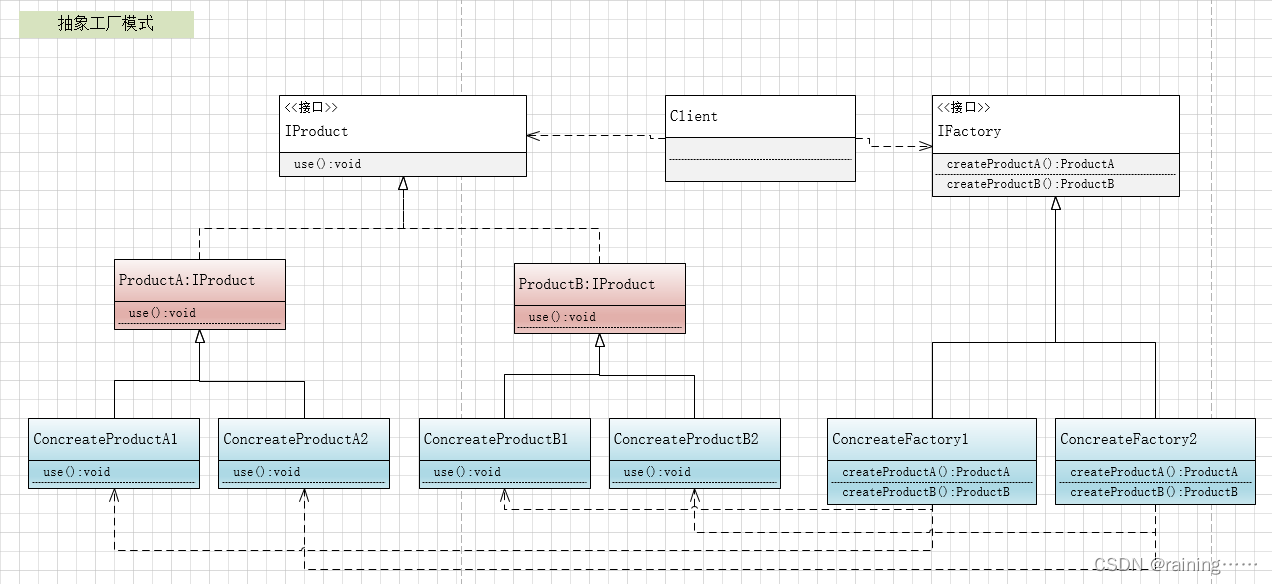
设计模式:抽象工厂模式(C#、JAVA、JavaScript、C++、Python、Go、PHP)
大家好!本节主要介绍设计模式中的抽象工厂模式。 简介: 抽象工厂模式,它是所有形态的工厂模式中最为抽象和最具一般性的一种形态。它用于处理当有多个抽象角色时的情况。抽象工厂模式可以向客户端提供一个接口,使客户端在不必指…...
ocpp-远程启动(RemoteStartTransaction)、远程停止(RemoteStopTransaction)
目录 1、介绍 2、远程启动-RemoteStartTransaction 3、远程停止-RemoteStopTransaction 4、代码 4.1 OcppRechongFeign 4.2 CmdController 4.3 CmdService 4.4 RemoteStartTransactionReq 4.5 接收报文-DataAnalysisController 4.6 接收报文实现类-DataAnalysisServi…...
【网络安全】安全的系统配置
系统配置是网络安全的重要组成部分。一个不安全的系统配置可能会使网络暴露在攻击者面前,而一个安全的系统配置可以有效地防止攻击者的入侵。在本文中,我们将详细介绍如何配置一个安全的系统,包括操作系统配置,网络服务配置&#…...

conda使用一般步骤
Terminal:conda create --name myenv python3.7 如果环境不行的话 1.source /opt/anaconda3/bin/activate 2.可能是没有源 vim ~/.condarc将需要的源装上 conda clean -i将原先的源删除 3.然后再conda create即可 4.需要激活环境 conda activate numpy 5.pycharm配置…...
如何做好需求收集?方法和步骤
需求收集是理解你想要构建什么以及为什么要构建它的过程。需求收集通常被视为开发软件应用,或开发硬件产品的一部分。其重要性不言而喻。据调查显示50%以上产品在市场上失败的原因,是由于忽视了用户需求。 一、需求收集为什么会困难? 困扰项…...

当我们谈论“防治养”时,我们谈论的是一种生活方式的重构
一、重新审视“健康”的定义在现代生活的快节奏中,健康常常被简化为一个医学指标,或是年度体检报告上的一串数字。然而,当我们谈论肿瘤“防治养”时,我们谈论的远不止于此。这不是三个孤立的概念,而是一个完整的循环—…...

四大路径!CS保研生冲刺南京大学如何精准定位?
1. 南京大学计算机保研全景地图 对于计算机专业的保研生来说,南京大学就像一座蕴藏着丰富矿藏的山脉,不同院系代表着不同的矿脉。作为国内顶尖高校,南大计算机相关学科分布在四个主要院系:计算机科学与技术系(传统强系…...

5 分钟快速上手 hoist-non-react-statics:提升组件静态属性的完整教程
5 分钟快速上手 hoist-non-react-statics:提升组件静态属性的完整教程 【免费下载链接】hoist-non-react-statics Copies non-react specific statics from a child component to a parent component 项目地址: https://gitcode.com/gh_mirrors/ho/hoist-non-reac…...

Discourse Docker持续集成:自动化构建与部署完整指南 [特殊字符]
Discourse Docker持续集成:自动化构建与部署完整指南 🚀 【免费下载链接】discourse_docker A Docker image for Discourse 项目地址: https://gitcode.com/gh_mirrors/dis/discourse_docker Discourse Docker持续集成是现代论坛部署的最佳实践&a…...

RISC-V开发板VisionFive 2 UEFI固件移植与启动实战指南
1. 项目概述:当RISC-V单板机拥抱UEFI 对于玩惯了x86平台或者树莓派的开发者来说,给一块单板计算机(SBC)刷写固件、配置启动项,可能已经轻车熟路。但当你把目光投向RISC-V架构,特别是像赛昉科技的VisionFiv…...

Linux常用命令之文件操作命令零基础教程
前言 本文整理了目录创建、文件创建/写入/查看/删除、重命名剪切复制、压缩解压、权限修改全套常用命令,完全零基础友好,逐条讲解、附带语法和实操用法。 一、目录创建命令 mkdir 1. 基础语法 mkdir 目录名称作用:创建单个空目录 2. 查看帮助…...

Obsidian Quiz Generator:用AI与间隔重复打造动态知识库
1. 项目概述:当笔记遇上主动回忆如果你和我一样,是 Obsidian 的用户,并且对知识管理、学习效率有追求,那么你一定遇到过这个困境:笔记越记越多,知识库越来越庞大,但真正能“记住”并“调用”的知…...

CUDA编程书籍大汇总:涵盖入门到高级,2022 - 2026年最新版本全收录!
跳过内容导航菜单 切换导航 [ ](/) [ 登录 ](/login?return_tohttps%3A%2F%2Fgithub.com%2Falternbits%2Fawesome-cuda-books) 外观设置 - **平台** - **AI 代码创作** - [GitHub Copilot:借助 AI 编写更优质代码](https://github.com/features/copilot) -…...

基于NirDiamant/agents-towards-production项目的LangSmith可观测性实践指南
基于NirDiamant/agents-towards-production项目的LangSmith可观测性实践指南 【免费下载链接】agents-towards-production End-to-end, code-first tutorials for building production-grade GenAI agents. From prototype to enterprise deployment. 项目地址: https://gitc…...

FanControl传感器检测失败?从新手到专家的完整修复指南
FanControl传感器检测失败?从新手到专家的完整修复指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...