如何使用pytorch定义一个多层感知神经网络模型——拓展到所有模型知识
# 导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
import torchvision.transforms as transforms
import torchvision.datasets as datasets# 定义MLP模型
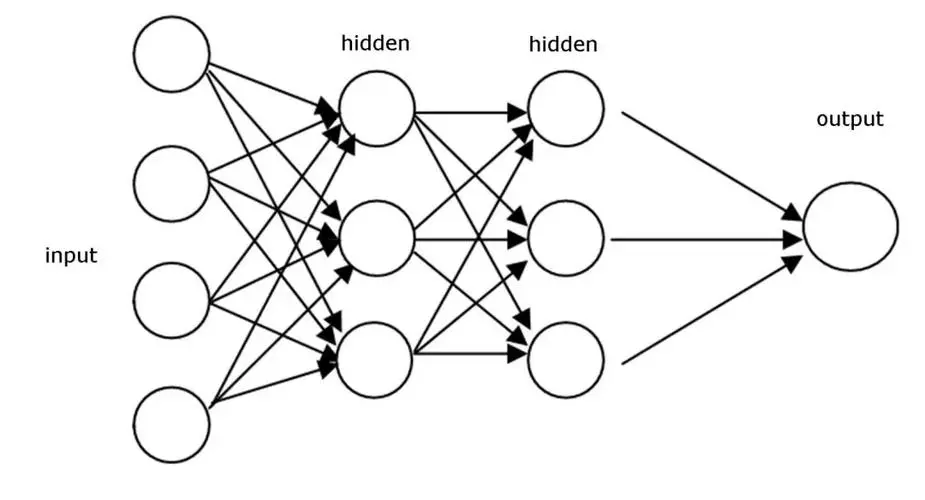
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()# 创建一个顺序的层序列:包括一个扁平化层、两个全连接层和ReLU激活self.layers = nn.Sequential(nn.Flatten(), # 将28x28的图像扁平化为784维向量nn.Linear(28 * 28, 512), # 第一个全连接层,784->512nn.ReLU(), # ReLU激活函数nn.Linear(512, 256), # 第二个全连接层,512->256nn.ReLU(), # ReLU激活函数nn.Linear(256, 10) # 第三个全连接层,256->10 (输出10个类别))def forward(self, x):return self.layers(x) # 定义前向传播# 加载FashionMNIST数据集
# 定义图像的预处理:转换为Tensor并标准化
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# 下载FashionMNIST数据并应用转换
dataset = datasets.FashionMNIST(root="./data", train=True, transform=transform, download=True)# 划分数据集为训练集和验证集
train_len = int(0.8 * len(dataset)) # 计算80%的长度作为训练数据
val_len = len(dataset) - train_len # 剩下的20%作为验证数据
train_dataset, val_dataset = random_split(dataset, [train_len, val_len])# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 训练数据加载器,批量大小64,打乱数据
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False) # 验证数据加载器,批量大小64,不打乱# 初始化模型、损失函数和优化器
model = MLP() # 创建MLP模型实例
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器# 训练模型
epochs = 5 # 定义训练5个epochs
for epoch in range(epochs):model.train() # 将模型设置为训练模式for inputs, labels in train_loader: # 从训练加载器中获取批次数据outputs = model(inputs) # 前向传播loss = criterion(outputs, labels) # 计算损失optimizer.zero_grad() # 清除之前的梯度loss.backward() # 反向传播,计算梯度optimizer.step() # 更新权重# 在每个epoch结束时验证模型性能model.eval() # 将模型设置为评估模式total_correct = 0with torch.no_grad(): # 不计算梯度,节省内存和计算量for inputs, labels in val_loader: # 从验证加载器中获取批次数据outputs = model(inputs) # 前向传播_, predicted = outputs.max(1) # 获取预测的类别total_correct += (predicted == labels).sum().item() # 统计正确的预测数量accuracy = total_correct / val_len # 计算验证准确性print(f"Epoch {epoch + 1}/{epochs} - Validation accuracy: {accuracy:.4f}") # 打印验证准确性nn.Flatten() 是一个特殊的层,它将多维的输入数据“展平”为一维数据。这在处理图像数据时尤为常见,因为图像通常是多维的(例如,一个大小为28x28的灰度图像在PyTorch中会有一个形状为[28, 28]的张量)。
在神经网络的某些层,特别是全连接层(如nn.Linear)之前,通常需要对数据进行扁平化处理。因为全连接层期望其输入是一维的(或者更准确地说,它期望输入的最后一个维度对应于特征,其他维度对应于数据的批次)。
为了更具体,让我们看一个例子:
考虑一个大小为[batch_size, 28, 28]的张量,这可以看作是一个batch_size数量的28x28图像的批次。当我们传递这个批次的图像到一个nn.Linear(28*28, 512)层时,我们需要先将图像展平。也就是说,每个28x28的图像需要转换为长度为784的一维向量。因此,输入数据的形状会从[batch_size, 28, 28]变为[batch_size, 784]。
nn.Flatten()就是做这个转换的。在这个特定的例子中,它会将[batch_size, 28, 28]的形状转换为[batch_size, 784]。
总结一下:nn.Flatten()用于将多维输入数据转换为一维,从而使其可以作为全连接层(如nn.Linear)的输入。
-
transforms.Compose:
这是一个简单的方式来链接(组合)多个图像转换操作。它会按照提供的顺序执行列表中的每个转换。 -
transforms.ToTensor():
这个转换将PIL图像或NumPy的ndarray转换为FloatTensor。并且它将图像的像素值范围从0-255变为0-1。简言之,它为我们完成了数据类型和值范围的转换。 -
transforms.Normalize((0.5,), (0.5,)):
这个转换标准化张量图像。给定的参数是均值和标准差。在这里,均值和标准差都是0.5。
使用给定的均值和标准差,这会将值范围从[0,1]转换为[-1,1]。
整个transform的目的是:
- 将图像数据从PIL格式转换为PyTorch张量格式。
- 将像素值从[0,255]范围转换为[0,1]范围。
- 使用给定的均值和标准差进一步标准化像素值,使其范围为[-1,1]。
初始化模型、损失函数和优化器
-
model = MLP():
- 这里我们实例化了我们之前定义的MLP类,从而创建了一个多层感知器(MLP)模型。
-
criterion = nn.CrossEntropyLoss():
- 在分类任务中,交叉熵损失函数 (CrossEntropyLoss) 是最常用的损失函数之一。它衡量真实标签和预测之间的差异。
- 注意:CrossEntropyLoss在内部执行softmax操作,因此模型输出应该是未经softmax处理的原始分数(logits)。
-
optimizer = optim.Adam(model.parameters(), lr=0.001):
- 优化器负责更新模型的权重,基于计算的梯度来减少损失。
- Adam是一种流行的优化器,它结合了两种扩展的随机梯度下降:Adaptive Gradients 和 Momentum。
- model.parameters()是传递给优化器的,它告诉优化器应该优化/更新哪些权重。
- lr=0.001定义了学习率,这是一个超参数,表示每次权重更新的步长大小。
常见的相关资料解答
- 模型 (在torch.nn中):
除了基本的MLP外,PyTorch提供了很多预定义的层和模型,常见的包括:
Convolutional Neural Networks (CNNs):nn.Conv2d: 2D卷积层,常用于图像处理。nn.Conv3d: 3D卷积层,常用于视频处理或医学图像。nn.MaxPool2d: 最大池化层。Recurrent Neural Networks (RNNs):nn.RNN: 基本的RNN层。nn.LSTM: 长短时记忆网络。nn.GRU: 门控循环单元。Transformer Architecture:nn.Transformer: 用于自然语言处理任务的Transformer模型。Batch Normalization, Dropout等:nn.BatchNorm2d: 批量归一化。nn.Dropout: 防止过拟合的正则化方法。
- 损失函数 (在torch.nn中):
常见的损失函数有:
Classification:nn.CrossEntropyLoss: 用于分类任务的交叉熵损失。nn.BCEWithLogitsLoss: 用于二分类任务的二元交叉熵损失,包括内部的sigmoid操作。nn.MultiLabelSoftMarginLoss: 用于多标签分类任务。Regression:nn.MSELoss: 均方误差,用于回归任务。nn.L1Loss: L1误差。Generative models:nn.KLDivLoss: Kullback-Leibler散度,常用于生成模型。
- 优化器 (在torch.optim中):
常见的优化器有:
optim.SGD: 随机梯度下降。
optim.Adam: 一个非常受欢迎的优化器,结合了AdaGrad和RMSProp的特点。
optim.RMSprop: 常用于深度学习任务。
optim.Adagrad: 自适应学习率优化器。
optim.Adadelta: 类似于Adagrad,但试图解决其快速降低学习率的问题。
optim.AdamW: Adam的变种,加入了权重衰减。
每文一语
学习是不断的发展的
相关文章:
如何使用pytorch定义一个多层感知神经网络模型——拓展到所有模型知识
# 导入必要的库 import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, random_split import torchvision.transforms as transforms import torchvision.datasets as datasets# 定义MLP模型 class MLP(nn.Module):def __…...
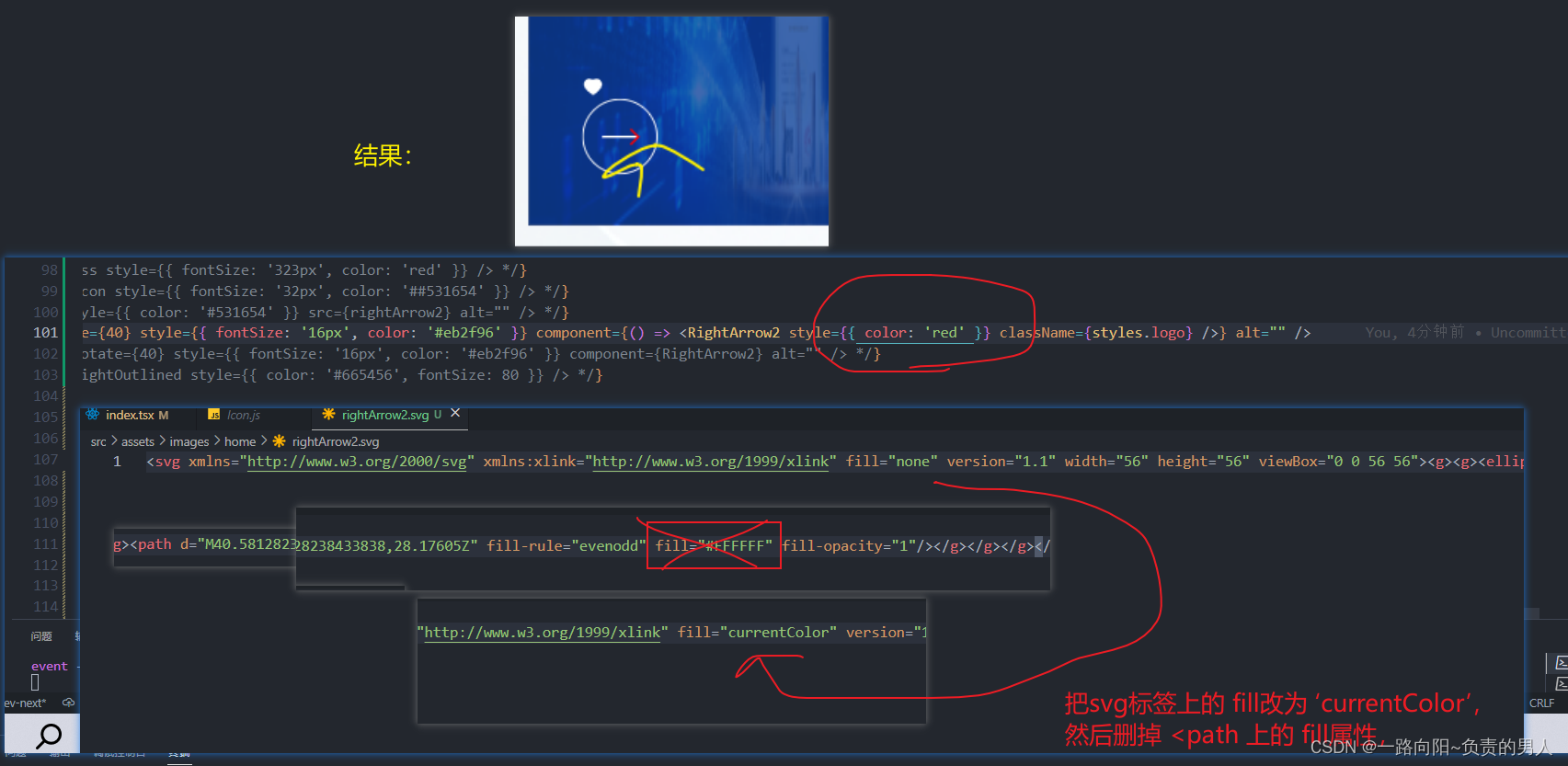
为什么引入SVG文件,给它定义属性不生效原理分析
背景: 我使用antd 的Icon组件引入SVG图片,但给svg图片定义styles样式时,不生效,为什么呢? 我们平时用antd组件库的 < ArrowRightOutlined style{{color: red }}>时为什么会生效呢,但我图一这样定义就…...

Integer包装类常用方法和属性
包装类 什么是包装类Integer包装类常用方法和属性 什么是包装类 Java 包装类是指为了方便处理基本数据类型而提供的对应的引用类型。Java 提供了八个基本数据类型(boolean、byte、short、int、long、float、double、char),每个基本数据类型对…...

基于Spring boot轻松实现一个多数据源框架
Spring Boot 提供了 Data JPA 的包,允许你使用类似 ORM 的接口连接到 RDMS。它很容易使用和实现,只需要在 pom.xml 中添加一个条目(如果使用的是 Maven,Gradle 则是在 build.gradle 文件中)。 <dependencies>&l…...

vue前端实现打印功能并约束纸张大小---调用浏览器打印功能打印页面部分元素并固定纸张大小
需求是打印指定div实现小票打印功能。调用浏览器的自带打印功能只能实现打印可视区域,所以这里采用截图新窗口打开打印去实现此需求。 1.安装html2canvas库实现截图功能 npm install html2canvas --save2.在需要进行截图和打印的组件中,引入html2canvas…...

音乐播放器蜂鸣器ROM存储歌曲verilog,代码/视频
名称:音乐播放器蜂鸣器ROM存储歌曲 软件:Quartus 语言:Verilog 代码功能: 设计音乐播放器,要求至少包含2首歌曲,使用按键切换歌曲,使用开发板的蜂鸣器播放音乐,使用Quartus内的RO…...
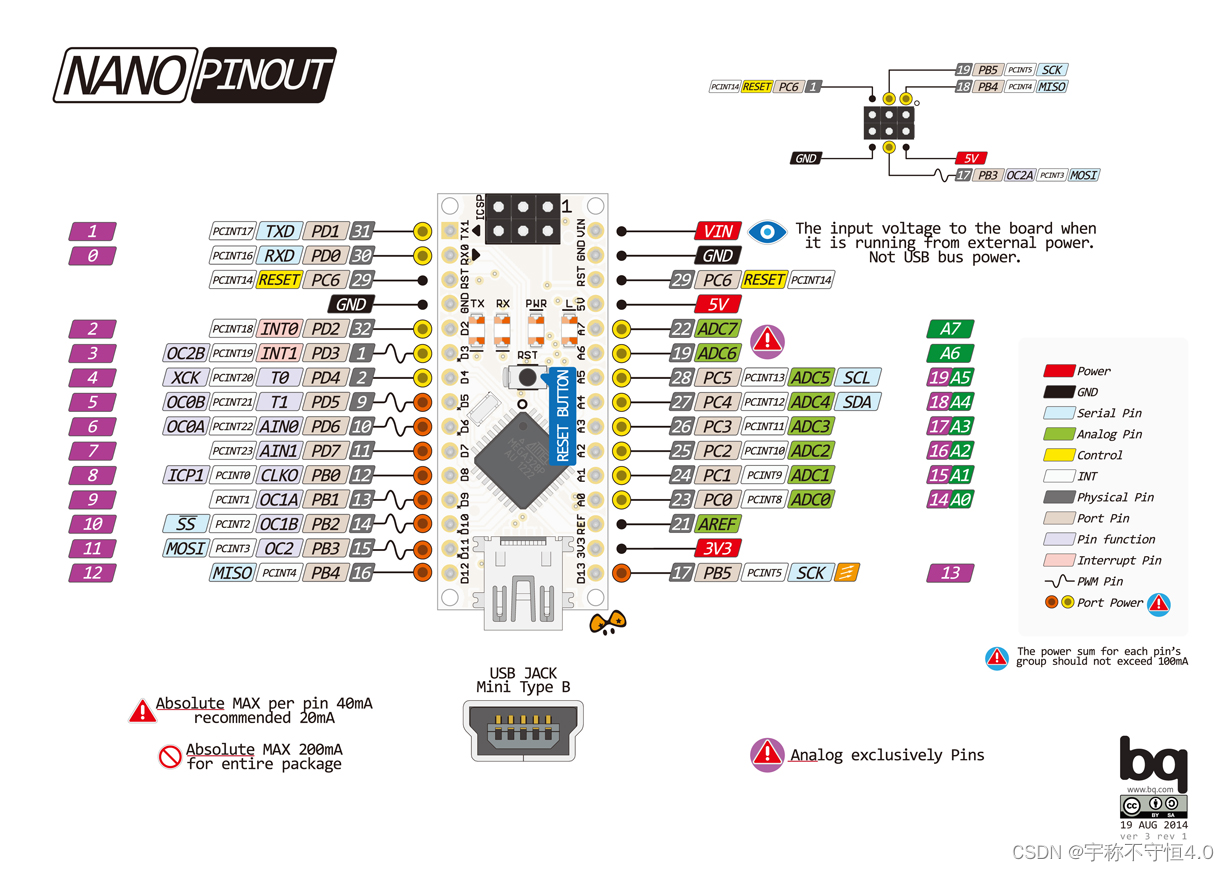
Arduino Nano 引脚复用分析
近期开发的项目为气体传感器采集仪,综合需求,选取NANO作为主控,附属设备有 oled、旋转编码器、H桥板、蠕动泵、开关、航插等,主要是用现有接口怎么合理配置实现功能。 不管stm32 还是 Arduino 都要看清引脚图 D2 D3 引脚是两个外…...

Go 函数多返回值错误处理与error 类型介绍
Go 函数多返回值错误处理与error 类型介绍 文章目录 Go 函数多返回值错误处理与error 类型介绍一、error 类型与错误值构造1.1 Error 接口介绍1.2 构造错误值的方法1.2.1 使用errors包1.2.2 自定义错误类型 二、error 类型的好处2.1 第一点:统一了错误类型2.2 第二点…...

数论分块
本质就是利用取整分数值的块状分布。 UVA11526 H(n) 题意: 求 ∑ i 1 n n i \sum_{i1}^{n} \frac {n}{i} ∑i1nin。 解析: ⌊ n i ⌋ \lfloor \frac{n}{i} \rfloor ⌊in⌋ 只有 O ( n ) O(\sqrt n) O(n ) 种取值,考虑将相同值同…...

宏任务与微任务,代码执行顺序
js引擎工作进程是同步的。事件循环机制,事件队列。 脚本代码执行顺序,是先执行同步代码,遇到微任务,就把它推进任务队列中。每个宏任务完成后,再执行下一个宏任务。 宏任务有哪些: i/o读写 定时器setTi…...

正方形(Squares, ACM/ICPC World Finals 1990, UVa201)rust解法
有n行n列(2≤n≤9)的小黑点,还有m条线段连接其中的一些黑点。统计这些线段连成了多少个正方形(每种边长分别统计)。 行从上到下编号为1~n,列从左到右编号为1~n。边用H i j和V i j表示…...

【算法设计与分析qwl】伪码——顺序检索,插入排序
伪代码: 例子: 改进的顺序检索 Search(L,x)输入:数组L[1...n],元素从小到大排序,数x输出:若x在L中,输出x位置下标 j ,否则输出0 j <- 1 while j<n and x>L[j] do j <- j1 if x<…...

Uniapp路由拦截-自定义路由白名单
步骤一:新建routerIntercept.js文件 步骤二:routerIntercept文件中写入:(根据自己需要修改whiteList白名单中的页面路径和自己的逻辑处理) import Vue from vue // 白名单 const whiteList = [/pages/public/login,/pages/public/privacyAgreement, ]export default asy…...
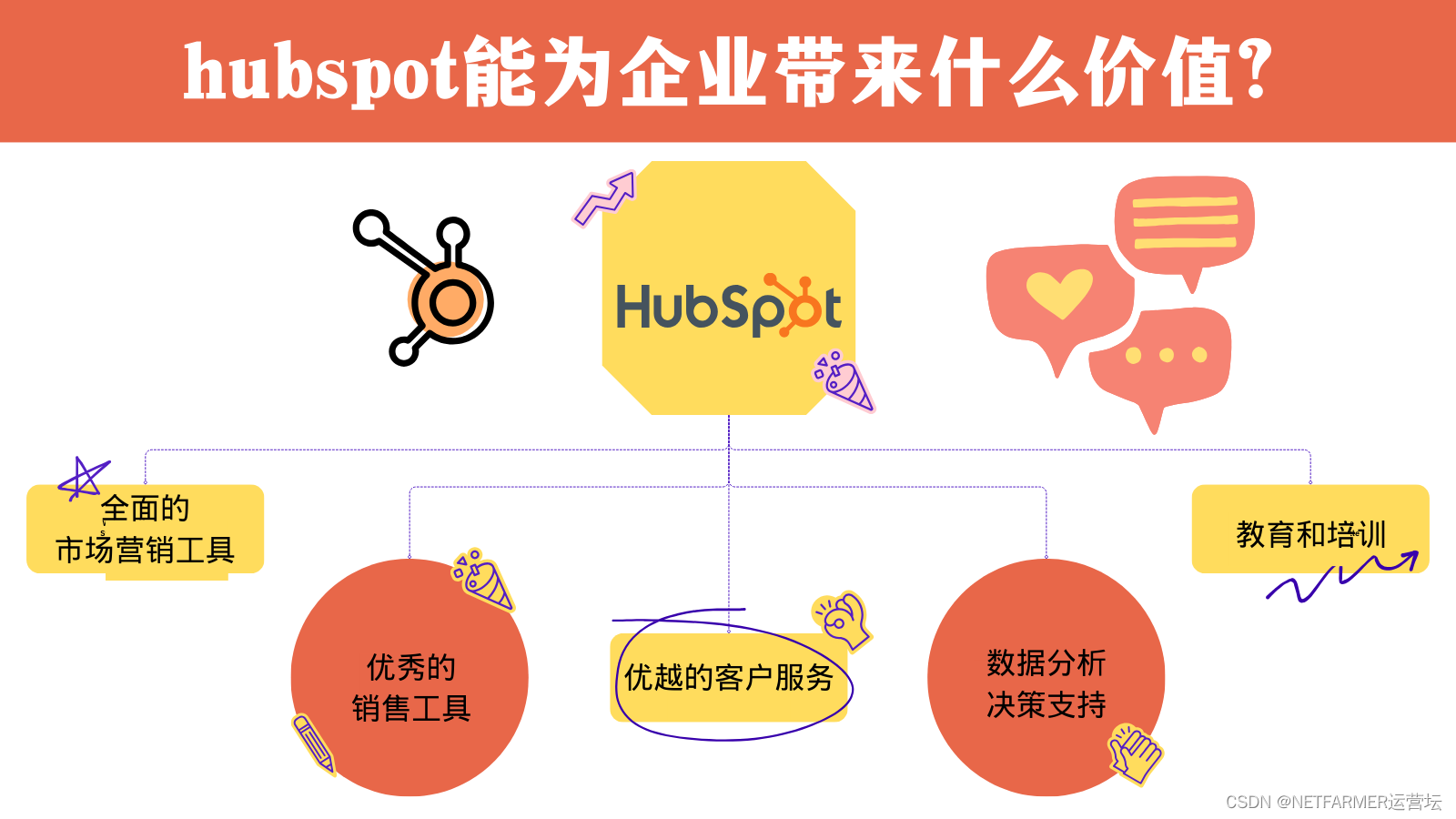
在中国可以使用 HubSpot 吗?
当谈到市场营销和客户关系管理工具时,HubSpot通常是一家企业的首选。然而,对于许多中国的企业来说,一个重要的问题是:在中国可以使用HubSpot吗?这个问题涉及到不同的方面,包括政策法规、社交媒体平台、语言…...

Java的基础应用
Java是一种广泛应用于软件开发的编程语言,基础应用涵盖了很多方面。以下是Java的一些基础应用方面的介绍: 1. 控制流语句:Java中的程序流程控制语句分为选择语句和循环语句。选择语句包括if-else语句和switch语句,循环语句包括fo…...
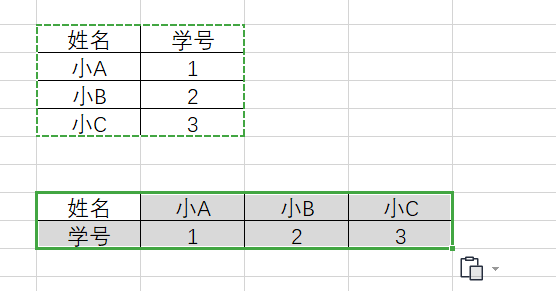
【excel】列转行
列转行 工作中有一些数据是列表,现在需要转行 选表格内容:在excel表格中选中表格数据区域。点击复制:在选中表格区域处右击点击复制。点击选择性粘贴:在表格中鼠标右击点击选择性粘贴。勾选转置:在选择性粘勾选转置选…...

用Bing绘制「V我50」漫画;GPT-5业内交流笔记;LLM大佬的跳槽建议;Stable Diffusion生态全盘点第一课 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🔥 美国升级AI芯片出口禁令,13家中国GPU企业被列入实体清单 nytimes.com/2023/10/05/technology/chip-makers-china-lobbying…...

Java身份证实名认证-阿里云API 【姓名、身份证号】
1. 阿里云API市场 https://market.aliyun.com/products/57126001/cmapi00053442.html?spm5176.2020520132.101.3.a6217218nxxEiy#skuyuncode47442000022 购买对应套餐 2. 复制AppCode https://market.console.aliyun.com/imageconsole/index.htm#/?_kl85e10 云市场-已购买服…...

ND协议——无状态地址自动配置 (SLAAC)
参考学习:计算机网络 | 思科网络 | 无状态地址自动配置 (SLAAC) | 什么是SLAAC_瘦弱的皮卡丘的博客-CSDN博客 与 IPv4 类似,可以手动或动态配置 IPv6 全局单播地址。但是,动态分配 IPv6 全局单播地址有两种方法: 如图所示&#…...

iOS开发UITableView的使用,区别Plain模式和Grouped模式
简单赘述一下 的创建步骤 // 创建UITableView self.tableView [[UITableView alloc] initWithFrame:self.view.bounds style:UITableViewStylePlain]; // 设置数据源和代理 self.tableView.dataSource self; self.tableView.delegate self; // 注册自定义UITableViewCe…...

KMS_VL_ALL_AIO:三步实现Windows和Office永久激活的完整指南
KMS_VL_ALL_AIO:三步实现Windows和Office永久激活的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出的激活提醒而烦恼吗?Office文档突…...

运维开发必备:5分钟搞定CentOS 7下ncurses库的安装与基础使用
运维开发必备:5分钟搞定CentOS 7下ncurses库的安装与基础使用 在服务器运维和自动化工具开发中,命令行界面(CLI)的高效交互能力往往决定了管理效率的上限。当我们需要在无GUI环境的Linux服务器上开发监控面板、配置向导或系统管理…...

腾讯混元调用代码实践
目录 查看资源是否用尽: ai3d的资源包,可以免费领取 api调用实例,亲测ok: 查看资源是否用尽: https://console.cloud.tencent.com/hunyuan/packages ai3d的资源包,可以免费领取 https://console.clou…...
)
NotebookLM辅助文献综述全链路拆解(2024最新版:支持arXiv/DOI/中文知网多源解析)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM文献综述辅助的范式变革 NotebookLM 是 Google 推出的基于用户自有文档的 AI 助手,其核心能力在于对上传 PDF、TXT 等学术文献进行语义索引与上下文感知问答,彻底重构…...
——run with profiler查看我们所运行程序的描述、计算指标、内存、峰值内存和数量)
Google Earth Engine(GEE)——run with profiler查看我们所运行程序的描述、计算指标、内存、峰值内存和数量
分析器显示有关特定算法和计算的其他部分消耗的资源(CPU 时间、内存)的信息。这有助于诊断脚本运行缓慢或由于内存限制而失败的原因。要使用探查器,请单击“运行”按钮下拉菜单中的“使用探查器运行”选项。作为快捷方式,按住 Alt(或 Mac 上的 Option)并单击运行,或按 C…...

STM32 PVD中断防数据丢失实战:手把手教你配置2.9V阈值与紧急保存逻辑
STM32 PVD中断防数据丢失实战:手把手教你配置2.9V阈值与紧急保存逻辑 当嵌入式设备在野外采集数据或进行关键操作时,突然断电可能导致数月积累的传感器数据毁于一旦。我曾在一个农业物联网项目中亲历这种灾难——某次田间设备因电池接触不良断电…...

Claude技能库开发指南:工具调用原理与模块化实践
1. 项目概述:一个为Claude模型量身定制的技能库最近在探索如何让Claude这类大型语言模型更好地融入我的日常工作流时,我遇到了一个非常有意思的项目——DhanushNehru/claude-skills。简单来说,这是一个专门为Anthropic的Claude模型设计的“技…...

5步解锁显卡隐藏性能:NVIDIA Profile Inspector全面指南
5步解锁显卡隐藏性能:NVIDIA Profile Inspector全面指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 想要让显卡发挥100%性能潜力吗?NVIDIA Profile Inspector作为一款专业的…...

ncmdump终极NCM解密转换完全指南
ncmdump终极NCM解密转换完全指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾遇到过这样的困扰?从网易云音乐下载的歌曲只能在特定播放器中播放,想要在其他设备上欣赏却束手无策。这种被格式限制的…...

DuckDuckGo AI本地代理服务:开源工具部署与API调用指南
1. 项目概述:一个为DuckDuckGo AI聊天功能提供本地化服务的开源工具如果你和我一样,是个重度搜索用户,同时又对AI聊天功能有高频需求,那你肯定对DuckDuckGo不陌生。作为一个主打隐私保护的搜索引擎,它最近也跟上了潮流…...