实现mnist手写数字识别
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/Nb93582M_5usednAKp_Jtw) 中的学习记录博客**
>- **🍖 原作者:[K同学啊 | 接辅导、项目定制](https://mtyjkh.blog.csdn.net/)**
>- **🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mingtian-fkmxf/zxwb45)**
一、 前期准备
1. 设置CPU
如果设备上支持GPU就使用GPU,否则使用CPU
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvisiondevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(device)由于我的是笔记本电脑intel集成显卡,故会输出 :cpu
2. 导入数据
使用dataset下载MNIST数据集,并划分好训练集与测试集
使用dataloader加载数据,并设置好基本的batch_size
⭐ torchvision.datasets.MNIST详解
torchvision.datasets是Pytorch自带的一个数据库,我们可以通过代码在线下载数据,这里使用的是torchvision.datasets中的MNIST数据集。
函数原型:
torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
参数说明:
- root (string) :数据地址
- train (string) :
True-训练集,False-测试集
- download (bool,optional) : 如果为
True,从互联网上下载数据集,并把数据集放在root目录下。
- transform (callable, optional ):这里的参数选择一个你想要的数据转化函数,直接完成数据转化
- target_transform (callable,optional) :接受目标并对其进行转换的函数/转换。
train_ds = torchvision.datasets.MNIST('data', train=True, transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensordownload=True)test_ds = torchvision.datasets.MNIST('data', train=False, transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensordownload=True)torch.utils.data.DataLoader详解
torch.utils.data.DataLoader是Pytorch自带的一个数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。
函数原型:
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False, pin_memory_device='')
参数说明:
- dataset(string) :加载的数据集
- batch_size (int,optional) :每批加载的样本大小(默认值:1)
- shuffle(bool,optional) : 如果为
True,每个epoch重新排列数据。 - sampler (Sampler or iterable, optional) : 定义从数据集中抽取样本的策略。 可以是任何实现了 __len__ 的 Iterable。 如果指定,则不得指定 shuffle 。
- batch_sampler (Sampler or iterable, optional) : 类似于sampler,但一次返回一批索引。与 batch_size、shuffle、sampler 和 drop_last 互斥。
- num_workers(int,optional) : 用于数据加载的子进程数。 0 表示数据将在主进程中加载(默认值:0)。
- pin_memory (bool,optional) : 如果为 True,数据加载器将在返回之前将张量复制到设备/CUDA 固定内存中。 如果数据元素是自定义类型,或者collate_fn返回一个自定义类型的批次。
- drop_last(bool,optional) : 如果数据集大小不能被批次大小整除,则设置为 True 以删除最后一个不完整的批次。 如果 False 并且数据集的大小不能被批大小整除,则最后一批将保留。 (默认值:False)
- timeout(numeric,optional) : 设置数据读取的超时时间 , 超过这个时间还没读取到数据的话就会报错。(默认值:0)
- worker_init_fn(callable,optional) : 如果不是 None,这将在步长之后和数据加载之前在每个工作子进程上调用,并使用工作 id([0,num_workers - 1] 中的一个 int)的顺序逐个导入。 (默认:None)
batch_size = 32train_dl = torch.utils.data.DataLoader(train_ds, batch_size=batch_size, shuffle=True)test_dl = torch.utils.data.DataLoader(test_ds, batch_size=batch_size)# 取一个批次查看数据格式
# 数据的shape为:[batch_size, channel, height, weight]
# 其中batch_size为自己设定,channel,height和weight分别是图片的通道数,高度和宽度。
imgs, labels = next(iter(train_dl))
imgs.shape输出:
torch.Size([32, 1, 28, 28])3. 数据可视化
squeeze()函数的功能是从矩阵shape中,去掉维度为1的。例如一个矩阵是的shape是(5, 1),使用过这个函数后,结果为(5, )。
import numpy as np# 指定图片大小,图像大小为20宽、5高的绘图(单位为英寸inch)
plt.figure(figsize=(20, 5))
for i, imgs in enumerate(imgs[:20]):# 维度缩减npimg = np.squeeze(imgs.numpy())# 将整个figure分成2行10列,绘制第i+1个子图。plt.subplot(2, 10, i+1)plt.imshow(npimg, cmap=plt.cm.binary)plt.axis('off')
二、构建简单的CNN网络
对于一般的CNN网络来说,都是由特征提取网络和分类网络构成,其中特征提取网络用于提取图片的特征,分类网络用于将图片进行分类。
- nn.Conv2d为卷积层,用于提取图片的特征,传入参数为输入channel,输出channel,池化核大小
- nn.MaxPool2d为池化层,进行下采样,用更高层的抽象表示图像特征,传入参数为池化核大小
- nn.ReLU为激活函数,使模型可以拟合非线性数据
- nn.Linear为全连接层,可以起到特征提取器的作用,最后一层的全连接层也可以认为是输出层,传入参数为输入特征数和输出特征数(输入特征数由特征提取网络计算得到,如果不会计算可以直接运行网络,报错中会提示输入特征数的大小,下方网络中第一个全连接层的输入特征数为1600)
- nn.Sequential可以按构造顺序连接网络,在初始化阶段就设定好网络结构,不需要在前向传播中重新写一遍
网络结构图(可单击放大查看):

import torch.nn.functional as Fnum_classes = 10 # 图片的类别数class Model(nn.Module):def __init__(self):super().__init__()# 特征提取网络self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 第一层卷积,卷积核大小为3*3self.pool1 = nn.MaxPool2d(2) # 设置池化层,池化核大小为2*2self.conv2 = nn.Conv2d(32, 64, kernel_size=3) # 第二层卷积,卷积核大小为3*3 self.pool2 = nn.MaxPool2d(2) # 分类网络self.fc1 = nn.Linear(1600, 64) self.fc2 = nn.Linear(64, num_classes)# 前向传播def forward(self, x):x = self.pool1(F.relu(self.conv1(x))) x = self.pool2(F.relu(self.conv2(x)))x = torch.flatten(x, start_dim=1)x = F.relu(self.fc1(x))x = self.fc2(x)return x加载并打印模型
from torchinfo import summary
# 将模型转移到CPU中(我们模型运行均在CPU中进行)
model = Model().to(device)summary(model)=================================================================
Layer (type:depth-idx) Param #
=================================================================
Model --
├─Conv2d: 1-1 320
├─MaxPool2d: 1-2 --
├─Conv2d: 1-3 18,496
├─MaxPool2d: 1-4 --
├─Linear: 1-5 102,464
├─Linear: 1-6 650
=================================================================
Total params: 121,930
Trainable params: 121,930
Non-trainable params: 0
=================================================================三、 训练模型
1. 设置超参数
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-2 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)2. 编写训练函数
1. optimizer.zero_grad()
函数会遍历模型的所有参数,通过内置方法截断反向传播的梯度流,再将每个参数的梯度值设为0,即上一次的梯度记录被清空。
2. loss.backward()
PyTorch的反向传播(即tensor.backward())是通过autograd包来实现的,autograd包会根据tensor进行过的数学运算来自动计算其对应的梯度。
具体来说,torch.tensor是autograd包的基础类,如果你设置tensor的requires_grads为True,就会开始跟踪这个tensor上面的所有运算,如果你做完运算后使用tensor.backward(),所有的梯度就会自动运算,tensor的梯度将会累加到它的.grad属性里面去。
更具体地说,损失函数loss是由模型的所有权重w经过一系列运算得到的,若某个w的requires_grads为True,则w的所有上层参数(后面层的权重w)的.grad_fn属性中就保存了对应的运算,然后在使用loss.backward()后,会一层层的反向传播计算每个w的梯度值,并保存到该w的.grad属性中。
如果没有进行tensor.backward()的话,梯度值将会是None,因此loss.backward()要写在optimizer.step()之前。
3. optimizer.step()
step()函数的作用是执行一次优化步骤,通过梯度下降法来更新参数的值。因为梯度下降是基于梯度的,所以在执行optimizer.step()函数前应先执行loss.backward()函数来计算梯度。
注意:optimizer只负责通过梯度下降进行优化,而不负责产生梯度,梯度是tensor.backward()方法产生的。
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共60000张图片num_batches = len(dataloader) # 批次数目,1875(60000/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_losspred.argmax(1)返回数组pred在第一个轴(即行)上最大值所在的索引。这通常用于多类分类问题中,其中pred是一个包含预测概率的二维数组,每行表示一个样本的预测概率分布。
(pred.argmax(1) == y)是一个布尔值,其中等号是否成立代表对应样本的预测是否正确(True 表示正确,False 表示错误)。
.type(torch.float)是将布尔数组的数据类型转换为浮点数类型,即将 True 转换为 1.0,将 False 转换为 0.0。
.sum()是对数组中的元素求和,计算出预测正确的样本数量。
.item()将求和结果转换为标量值,以便在 Python 中使用或打印。
(pred.argmax(1) == y).type(torch.float).sum().item()表示计算预测正确的样本数量,并将其作为一个标量值返回。这通常用于评估分类模型的准确率或计算分类问题的正确预测数量。
3. 编写测试函数
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss4. 正式训练
1. model.train()
model.train()的作用是启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train()。model.train()是保证BN层能够用到每一批数据的均值和方差。对于Dropout,model.train()是随机取一部分网络连接来训练更新参数。
2. model.eval()
model.eval()的作用是不启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。
训练完train样本后,生成的模型model要用来测试样本。在model(test)之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有BN层和Dropout所带来的的性质。
epochs = 5
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')运行结果:
Epoch: 1, Train_acc:77.6%, Train_loss:0.744, Test_acc:91.1%,Test_loss:0.284
Epoch: 2, Train_acc:94.1%, Train_loss:0.196, Test_acc:96.2%,Test_loss:0.128
Epoch: 3, Train_acc:96.2%, Train_loss:0.123, Test_acc:97.5%,Test_loss:0.089
Epoch: 4, Train_acc:97.1%, Train_loss:0.094, Test_acc:97.4%,Test_loss:0.078
Epoch: 5, Train_acc:97.5%, Train_loss:0.078, Test_acc:98.0%,Test_loss:0.062
Done四、 结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
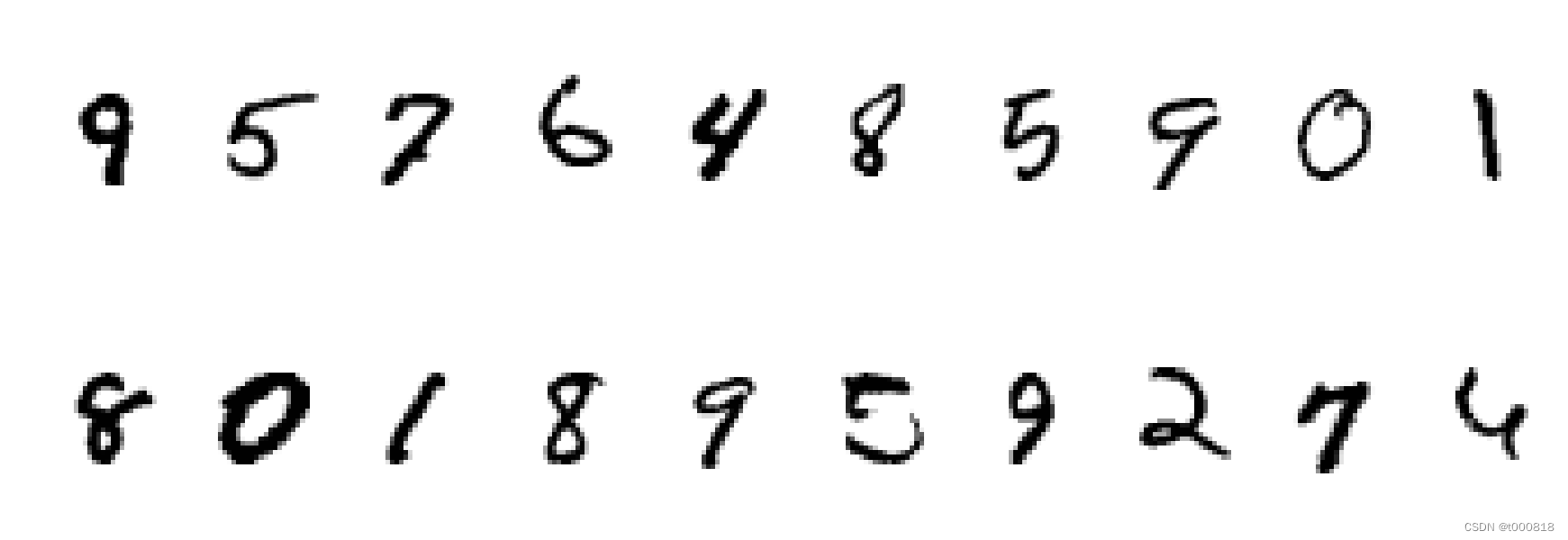
五、知识点详解
本文使用的是最简单的CNN模型,如果是第一次接触深度学习的话,可以先试着把代码跑通,然后再尝试去理解其中的代码。
1. MNIST手写数字数据集介绍
MNIST手写数字数据集来源于是美国国家标准与技术研究所,是著名的公开数据集之一。数据集中的数字图片是由250个不同职业的人纯手写绘制,数据集获取的网址为:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges(下载后需解压)。我们一般会采用(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()这行代码直接调用,这样就比较简单
MNIST手写数字数据集中包含了70000张图片,其中60000张为训练数据,10000为测试数据,70000张图片均是28*28,数据集样本如下:

如果我们把每一张图片中的像素转换为向量,则得到长度为28*28=784的向量。因此我们可以把训练集看成是一个[60000,784]的张量,第一个维度表示图片的索引,第二个维度表示每张图片中的像素点。而图片里的每个像素点的值介于0-1之间。

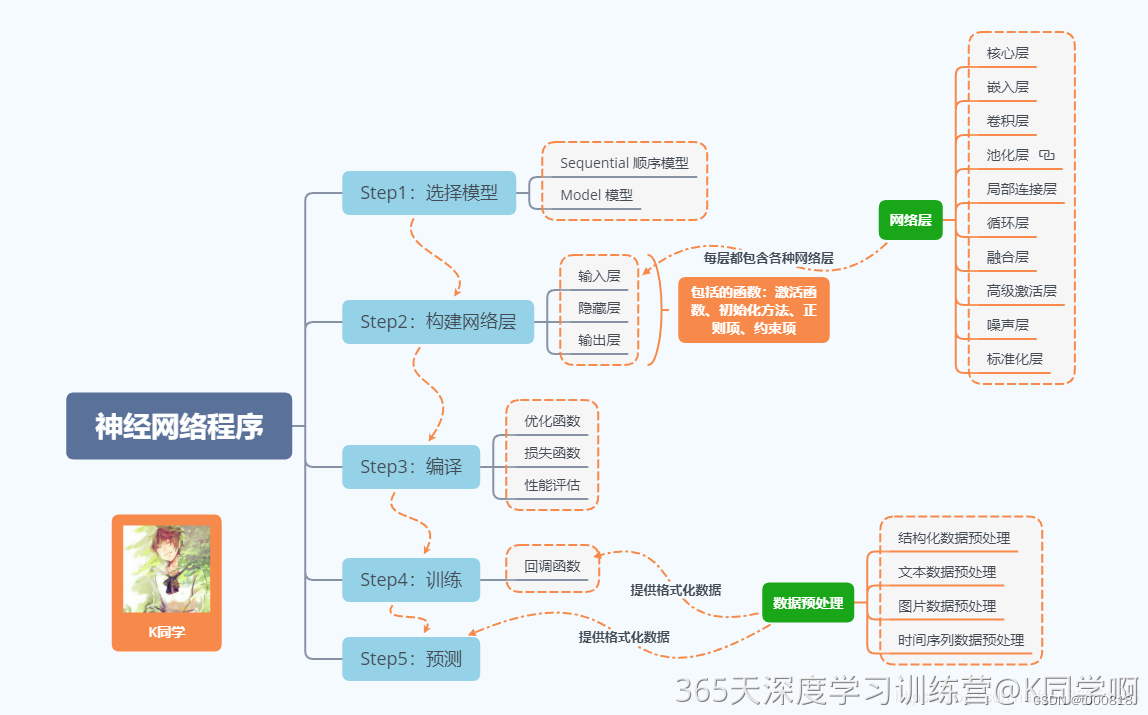
2. 神经网络程序说明
神经网络程序可以简单概括如下:
相关文章:
实现mnist手写数字识别
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/Nb93582M_5usednAKp_Jtw) 中的学习记录博客** >- **🍖 原作者:[K同学啊 | 接辅导、项目定制](https://mtyjkh.blog.csdn.net/)** >- **🚀…...
Camera BSP之GPIO/I2C/PMIC简介
和你一起终身学习,这里是程序员Android 经典好文推荐,通过阅读本文,您将收获以下知识点: 一、GPIO介绍二、IC 总线概括三、PMIC 概括四、思考 一、GPIO介绍 GPIO:General Purpose Input Output (通用输入/输出…...

Spring 数据校验:Validation
文章目录 Spring Validation概述实验一:通过Validator接口实现实验二:Bean Validation注解实现实验三:基于方法实现校验实验四:实现自定义校验 Spring Validation概述 在开发中,我们经常遇到参数校验的需求࿰…...
网页构造与源代码
下载google浏览器 设置打开特定网址:www.baidu.com 查看网页或元素源代码 网页右键选择“检查”查看源代码 网页源代码 元素源代码...
-NOA领航辅助系统-集度)
辅助驾驶功能开发-功能对标篇(14)-NOA领航辅助系统-集度
1.横向对标参数 厂商集度车型ROBO-01上市时间2023方案12V5R2L+1DMS摄像头前视摄像头3侧视摄像头4后视摄像头1环视摄像头4DMS摄像头1雷达毫米波雷达54D毫米波雷达/超声波雷达12激光雷达</...

论坛介绍 | COSCon'23 云计算(C)
众多开源爱好者翘首期盼的开源盛会:第八届中国开源年会(COSCon23)将于10月28-29日在四川成都市高新区菁蓉汇举办。本次大会的主题是:“开源:川流不息、山海相映”!各位新老朋友们,欢迎到成都&am…...
Spring 国际化:i18n
文章目录 i18n概述Java国际化Spring6国际化MessageSource接口使用Spring6国际化 i18n概述 国际化也称作i18n,其来源是英文单词 internationalization的首末字符i和n,18为中间的字符数。由于软件发行可能面向多个国家,对于不同国家的用户&…...
【APP源码】基于Typecho博客程序开发的博客社区资讯APP源码
全新博客社区资讯APP源码 Typecho后端 一款功能全面,用户交互良好,数据本地缓存,集成邮箱验证,在线投稿,(内置Mardown编辑器), 快捷评论的的博客资讯APP。同时兼容H5和微信小程序。 …...
Spring Security登录表单配置(3)
1、登录表单配置 1.1、快速入门 理解了入门案例之后,接下来我们再来看一下登录表单的详细配置,首先创建一个新的Spring Boot项目,引入Web和Spring Security依赖,代码如下: <dependency><groupId>org.sp…...

代理模式(初学)
代理模式 一、什么是代理模式 代理模式:为其他对象提供一种代理以控制对这个对象的访问 二、简单例子 这里面的骏骏就起到了代理的身份,而贵贵则是被代理的身份。 三、代码实现 1、用一个接口(GivingGifts)来保存送礼物的动作…...
Spring底层架构核心概念
BeanDefinition BeanDefinition表示Bean定义,BeanDefinition中存在很多属性用来描述一个Bean的特点。比如: class,表示Bean类型scope,表示Bean作用域,单例或原型等lazyInit:表示Bean是否是懒加载initMeth…...

为什么高精度机器人普遍使用谐波减速器而不是普通减速器?
机器人作为一种能够代替人类完成各种工作的智能设备,已经广泛应用于工业生产、医疗卫生、军事防卫等领域。其中,机器人的关节传动系统是机器人运动的核心,而减速器作为关节传动系统中的重要组成部分部分,对机器人的性能和技术水平…...

特殊类的设计
目录 一、设计一个类,不能被拷贝二、设计一个类,只能在堆上创建对象三、设计一个类,只能从栈上创建对象四、设计一个类,不能被继承五、设计一个类,只能创建一个对象(单例模式)5.1 饿汉模式5.2 懒…...
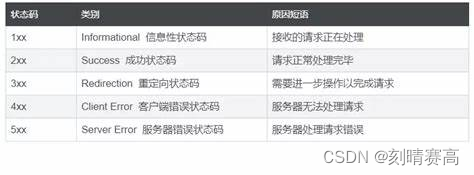
HTTP 协议的基本格式(部分)
要想了解HTTP,得先知道什么是HTTP,那么HTTP是什么呢?HTTP (全称为 "超文本传输协议") 是一种应用非常广泛的 应用层协议。那什么是超文本呢?那就是除了文本,还有图片,声音,视频等。 …...

Android 第三方app https 抓包
工具选择 Charles 或 Fiddler 都可以 在PC上安装工具并进行设置 Charles Fiddler 设置按官网说明设置一下好。 Charles设置 Fiddler设置 Android Api Level > 24 SSL特殊设置 当Android 的 Api Level > 24时需要修改一下app的一起配置 1.在项目中添加 Android/src/…...

Linux-gitlab常用命令
gitlab常用命令 1、查看gitlab状态2、gitlab启动3、gitlab关闭 1、查看gitlab状态 gitlab-ctl status2、gitlab启动 gitlab-ctl start3、gitlab关闭 gitlab-ctl stop...
)
android 13.0 Settings主页动态显示和隐藏设置项(一级菜单显示和隐藏)
1.前言 在13.0定制化开发Settings时,有产品需求要求对主页设置项需要动态控制显示和隐藏,这就需要用定义两个页面来区分加载不同settings页面 接下来分析下相关的实现流程 实现思路: 1.用系统变量控制显示和隐藏某些项 2.增加一个自定义页面来适配不同页面 2.Settings主页动态…...

Android MJPEG播放器
MJPEG Android MJPEG播放 支持http mjpeg直播流播放; 支持编码MP4保存视频; 资源 名字资源jar下载GitHub查看Gitee查看 Maven 1.build.grade allprojects {repositories {...maven { url https://jitpack.io }} }2./app/build.grade dependencies {implementation com.g…...

Ubuntu - 安装 MySQL 8
以下是在 Ubuntu 上安装 MySQL 8 的完整步骤: 步骤 1:更新包列表 首先,打开终端并执行以下命令来确保包列表是最新的: sudo apt update 步骤 2:安装 MySQL 8 服务器 接下来,使用以下命令安装 MySQL 8 …...
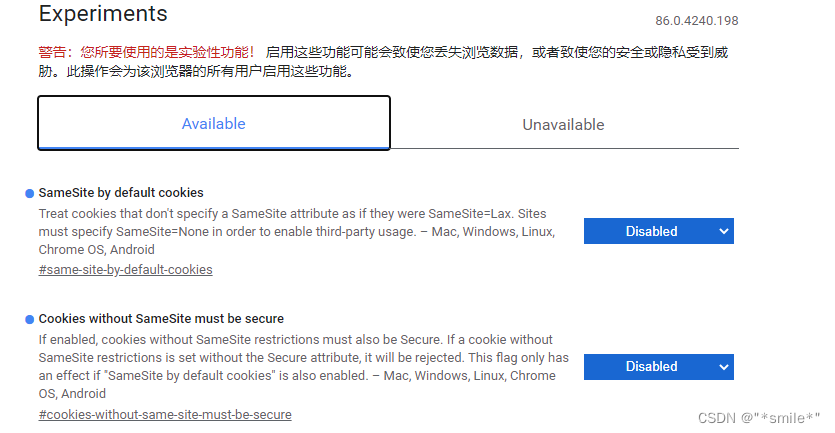
谷歌浏览器跨域及--disable-web-security无效解决办法
谷歌浏览器跨域设置 (1)创建一个目录,例如我在C盘创建MyChromeDevUserData文件夹 (2) 在桌面选择谷歌浏览器右键 -> 属性 -> 快捷方式 -> 目标,添加--disable-web-security --user-data-dirC:\M…...

MultiFunPlayer完整指南:3分钟学会设备与媒体完美同步,打造沉浸式娱乐体验
MultiFunPlayer完整指南:3分钟学会设备与媒体完美同步,打造沉浸式娱乐体验 【免费下载链接】MultiFunPlayer flexible application to synchronize various devices with media playback 项目地址: https://gitcode.com/gh_mirrors/mu/MultiFunPlayer …...

2025最权威的AI学术网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在人工智能技术迅猛快速发展的当下,各种各样的 AI 辅助论文写作工具不断地大量涌…...

通过curl命令快速测试Taotoken的API兼容性与连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken的API兼容性与连通性 在接入大模型服务时,开发者常常需要一个快速、轻量的方法来验证API…...

MPC-HC播放器:3步打造你的专属影院级视听体验
MPC-HC播放器:3步打造你的专属影院级视听体验 【免费下载链接】mpc-hc MPC-HCs main repository. For support use our Trac: https://trac.mpc-hc.org/ 项目地址: https://gitcode.com/gh_mirrors/mpc/mpc-hc MPC-HC(Media Player Classic Home …...

终极KMS激活指南:如何免费激活Windows和Office的完整教程
终极KMS激活指南:如何免费激活Windows和Office的完整教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office的激活问题烦恼吗?KMS_VL_ALL_AIO是一款开…...

SFT别急着接RL!你的多模态大模型可能一直在“带伤训练”
PRISM团队 投稿量子位 | 公众号 QbitAISFT之后,直接上强化学习就够了吗?小心,你做的可能不是“训练”,而是“还债”。在多模态大模型(MLLM)的后训练中,行业内长期遵循着一个看似天经地义的范式&…...

HttpOnly Cookie 深度解析
一、什么是 HttpOnly Cookie HttpOnly 是一个可以附加在 Set-Cookie 响应头上的标志位(flag)。当一个 Cookie 被标记为 HttpOnly 后,客户端脚本(如 JavaScript)将无法通过 document.cookie 等 API 访问该 Cookie&…...

ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch + CUDA环境配置与避坑
ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch CUDA环境配置与避坑 在深度学习模型部署领域,BFloat16数据类型正逐渐成为提升推理性能的新宠。这种16位浮点格式保留了与32位浮点相同的指数位,在保持数值范围的同时减少了内存占…...

Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程
Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾因为Adobe Creative Cloud高昂的订阅…...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...