怎么让英文大语言模型支持中文?--构建中文tokenization--继续预训练--指令微调
1 构建中文tokenization
参考链接:https://zhuanlan.zhihu.com/p/639144223
1.1 为什么需要 构建中文tokenization?
原始的llama模型对中文的支持不太友好,接下来本文将讲解如何去扩充vocab里面的词以对中文进行token化。
1.2 如何对 原始数据预处理?
每一行为一句或多句话。保存为语料corpus
1.3 如何构建中文的词库?
一般的,目前比较主流的是使用sentencepiece训练中文词库。
运行后会得到tokenizer.model和tokenizer.vocab两个文件。
1.4 如何使用transformers库加载sentencepiece模型?
它可以用transformers库里面的tokenizer对象加载读取。
1.5 如何合并英文词表和中文词表?
将原始词表中没有的新加入进去vocab.model。
for p in chinese_spm.pieces:piece = p.pieceif piece not in llama_spm_tokens_set:new_p = sp_pb2_model.ModelProto().SentencePiece()new_p.piece = piecenew_p.score = 0llama_spm.pieces.append(new_p)
1.6 怎么使用修改后的词表?
如果我们重新从头开始训练,那么其实使用起来很简单:
config = AutoConfig.from_pretrained(…)
tokenizer = LlamaTokenizer.from_pretrained(…)
model = LlamaForCausalLM.from_pretrained(…, config=config)
model_vocab_size = model.get_output_embeddings().weight.size(0)
model.resize_token_embeddings(len(tokenizer))但是如果我们想要保留原始模型embedding的参数,那么我们可以这么做:
- 找到新词表和旧词表id之间的映射关系。
- 将模型里面新词表里面包含的旧词表用原始模型的embedding替换。
- 如果新词在旧词表里面没有出现就进行相应的初始化再进行赋值。
具体怎么做可以参考一下这个:https://github.com/yangjianxin1/LLMPruner
1.7 总结一下 构建中文tokenization?
1、使用sentencepiece训练一个中文的词表。
2、使用transformers加载sentencepiece模型。
3、怎么合并中英文的词表,并使用transformers使用合并后的词表。
4、在模型中怎么使用新词表。
2 继续预训练篇
2.1 为什么需要进行继续预训练?
我们新增加了一些中文词汇到词表中,这些词汇是没有得到训练的,因此在进行指令微调之前我们要进行预训练。预训练的方式一般都是相同的,简单来说,就是根据上一个字预测下一个字是什么。
2.2 如何对 继续预训练 数据预处理?
先使用tokenizer()得到相关的输入,需要注意的是可能会在文本前后添加特殊的标记,比如bos_token_id和eos_token_id,针对于不同模型的tokneizer可能会不太一样。这里在input_ids前后添加了21134和21133两个标记。
然后将所有文本的input_ids、attention_mask, token_type_ids各自拼接起来(展开后拼接,不是二维数组之间的拼接),再设定一个最大长度block_size,这样得到最终的输入。
2.3 如何 构建模型?
我们可以使用同样的英文原模型,但是tokenizer换成我们新的tokenizer.由于tokenizer词表个数发生了变化,我们需要将模型的嵌入层和lm_head层的词表数目进行重新设置:
model_vocab_size = model.get_output_embeddings().weight.size(0)
model.resize_token_embeddings(len(tokenizer))
2.4 如何 使用模型?
按照transformer基本的使用模型的方法即可。可以用automodel, automodelforcasualLm等方法
3 对预训练模型进行指令微调
3.1 为什么需要对预训练模型进行指令微调?
如果需要模型能够进行相应的下游任务,我们就必须也对模型进行下游任务的指令微调。
只经过上面的继续与训练,模型能够获得基本的知识,但是更加领域的,特别的精细的指令还需要指令微调来获得。
对数据处理到训练、预测的整个流程有所了解,其实,基本上过程是差不多的。我们在选择好一个大语言模型之后。比如chatglm、llama、bloom等,要想使用它,得了解三个方面:输入数据的格式、tokenization、模型的使用方式。
3.2 对预训练模型进行指令微调 数据 如何处理?
指令微调的数据处理和继续与训练的数据处理相同。
需要注意的是根据微调任务不同,
将原本的分类或者预测任务,直接转变为特定单词或者句子的生成任务。并且添加特殊的标记。来区分不同的任务以及不同的结果。
3.3 对预训练模型进行指令微调 tokenization 如何构建?
与与训练的基本一致。
如果有针对某些特殊的字或者语言需要扩充语料库。可以使用保留字符,或者重新进行上面的【构建tokenization】任务
3.4 对预训练模型进行指令微调 模型 如何构建?
使用原有的模型,进行全参数微调。
也可以使用adapter的结构,将模型固定住,只训练少量参数
还可以使用prompt等其他的方式。不进行参数调整。只改变输入数据的信息
3.5 是否可以结合 其他库 使用?
可以
其它的一些就是结合一些库的使用了,比如:
deepspeed
transformers
peft中使用的lora
datasets加载数据
需要注意的是, 我们可以把数据拆分为很多小文件放在一个文件夹下,然后遍历文件夹里面的数据,用datasets加载数据并进行并行处理后保存到磁盘上。如果中间发现处理数据有问题的话要先删除掉保存的处理后的数据,再重新进行处理,否则的话就是直接加载保存的处理好的数据。
在SFT之后其实应该还有对齐这部分,就是对模型的输出进行规范,比如使用奖励模型+基于人类反馈的强化学习等,这里就不作展开了。
相关文章:

怎么让英文大语言模型支持中文?--构建中文tokenization--继续预训练--指令微调
1 构建中文tokenization 参考链接:https://zhuanlan.zhihu.com/p/639144223 1.1 为什么需要 构建中文tokenization? 原始的llama模型对中文的支持不太友好,接下来本文将讲解如何去扩充vocab里面的词以对中文进行token化。 1.2 如何对 原始数…...
)
笙默考试管理系统-MyExamTest----codemirror(35)
笙默考试管理系统-MyExamTest----codemirror(35) 目录 一、 笙默考试管理系统-MyExamTest 二、 笙默考试管理系统-MyExamTest 三、 笙默考试管理系统-MyExamTest 四、 笙默考试管理系统-MyExamTest 五、 笙默考试管理系统-MyExamTest 笙默考试…...
)
MMKV(2)
API 初始化和实例获取: MMKV.initialize(Context context): 初始化MMKV库。通常在应用程序的入口点调用此方法。 MMKV.defaultMMKV(): 获取默认的MMKV实例。默认实例使用默认的存储路径和加密方式。 MMKV.mmkvWithID(String mmapID): 根据给定的ID获取MMKV实例。…...
Spring Boot项目中使用 TrueLicense 生成和验证License(附源码)
1、Linux 在客户linux上新建layman目录,导入license.sh文件, [rootlocalhost layman]# mkdir -p /laymanlicense.sh文件内容: #!/bin/bash # 1.获取要监控的本地服务器IP地址 IPifconfig | grep inet | grep -vE inet6|127.0.0.1 | awk {p…...

ES6 Iterator 和 for...of 循环
1.iterator 概念 ES6 添加了Map和Set。这样就有了四种数据集合,需要一种统一的接口机制来处理所有不同的数据结构。遍历器(Iterator)就是这样一种机制。它是一种接口,为各种不同的数据结构提供统一的访问机制。任何数据结构只要部…...
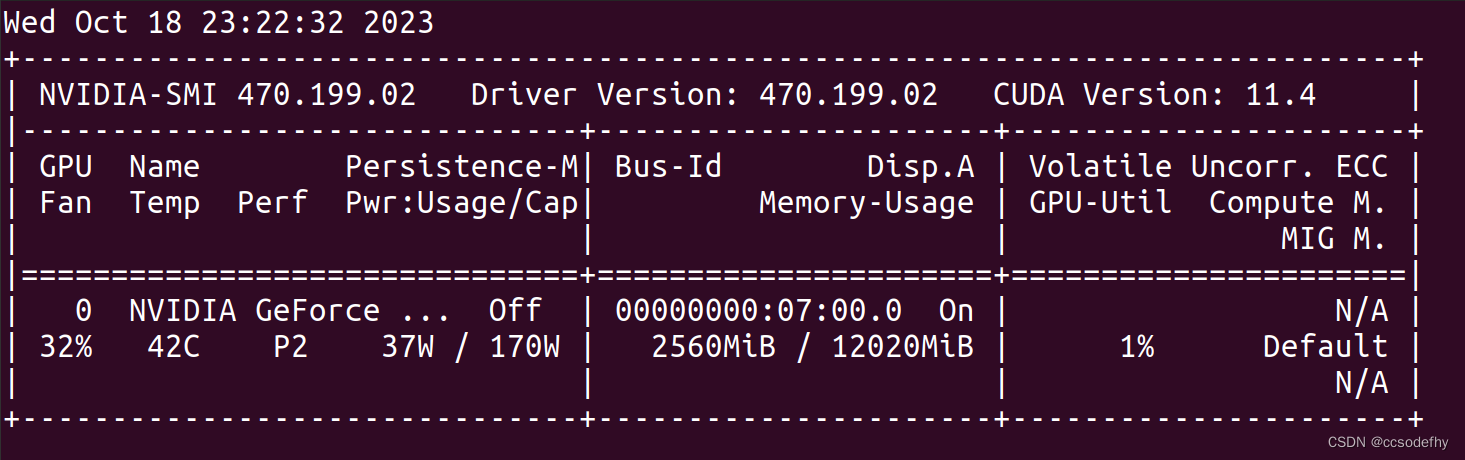
ubuntu20.04 nvidia显卡驱动掉了,变成开源驱动,在软件与更新里选择专有驱动,下载出错,调整ubuntu镜像源之后成功修复
驱动配置好,环境隔了一段时间,打开Ubuntu发现装好的驱动又掉了,软件与更新 那里,附加驱动,显示开源驱动,命令行输入 nvidia-smi 命令查找不到驱动。 点击上面的 nvidia-driver-470(专有&#x…...

华为FAT模式无线AP配置实例
硬件:AP3010DN 软件版本:VRP software, Version 5.170 (AP3010DN-V2 FAT V200R010C00SPCf02) [Huawei]dis ver Huawei Versatile Routing Platform Software VRP (R) software, Version 5.170 (AP3010DN-V2 FAT V200R010C00SPCf02) Copyright (C) 2011…...
nodejs基于vue 学生论坛设计与实现
随着网络技术的不断成熟,带动了学生论坛,它彻底改变了过去传统的管理方式,不仅使服务管理难度变低了,还提升了管理的灵活性。 是本系统的开发平台 系统中管理员主要是为了安全有效地存储和管理各类信息, 这种个性化的平…...

017 基于Spring Boot的食堂管理系统
部分代码地址: https://github.com/XinChennn/xc017-stglxt 基于Spring Boot的食堂管理系统 项目介绍 本项目是基于Java的管理系统。采用前后端分离开发。前端基于bootstrap框架实现,后端使用Java语言开发,技术栈包括但不限于SpringBoot、…...
-C++)
常用的二十种设计模式(下)-C++
设计模式 C中常用的设计模式有很多,设计模式是解决常见问题的经过验证的最佳实践。以下是一些常用的设计模式: 单例模式(Singleton):确保一个类只有一个实例,并提供一个全局访问点。工厂模式(…...
C#桶排序算法
前言 桶排序是一种线性时间复杂度的排序算法,它将待排序的数据分到有限数量的桶中,每个桶再进行单独排序,最后将所有桶中的数据按顺序依次取出,即可得到排序结果。 实现原理 首先根据待排序数据,确定需要的桶的数量。…...
快速了解服务器单CPU与双CPU
在当今快节奏的技术环境中,用户们对功能强大且高效的服务器配置需求不断增长。CPU作为构成任何计算基础设施的骨干,服务器的“大脑”,负责执行计算、控制数据流并协调各个组件之间的任务,是服务器选择硬件中的重要一环。因此…...

c# Dictionary、ConcurrentDictionary的使用
Dictionary Dictionary 用于存储键-值对的集合。如果需要高效地存储键-值对并快速查找,请使用 Dictionary。 注意,键必须是唯一的,值可以重复。 using System; using System.Collections.Generic; using System.Linq;class Program {stati…...
大数据中间件——Kafka
Kafka安装配置 首先我们把kafka的安装包上传到虚拟机中: 解压到对应的目录并修改对应的文件名: 首先我们来到kafka的config目录,我们第一个要修改的文件就是server.properties文件,修改内容如下: # Licensed to the …...
HarmonyOS/OpenHarmony原生应用-ArkTS万能卡片组件Slider
滑动条组件,通常用于快速调节设置值,如音量调节、亮度调节等应用场景。该组件从API Version 7开始支持。无子组件 一、接口 Slider(options?: {value?: number, min?: number, max?: number, step?: number, style?: SliderStyle, direction?: Ax…...

SpringCloud: sentinel链路限流
一、配置文件要增加 spring.cloud.sentinel.webContextUnify: false二、在要限流的业务方法上使用SentinelResource注解 package cn.edu.tju.service;import com.alibaba.csp.sentinel.annotation.SentinelResource; import com.alibaba.csp.sentinel.slots.block.BlockExcept…...

UML 中的关系
种类 继承、实现、组合、聚合、关联、依赖 理解 继承和实现的关系强度最大。组合代表着实体之间共同构成一个主体内部的组成部分无法单独支撑,聚合则代表层级更高的一种关联涉及的实体都是独立的个体共同组合起来构成一个主体 个体之间是可以单独工作的。 组合和…...

ChatGPT技术或加剧钓鱼邮件攻击
我们对ChatGPT这一新技术并不陌生,也早就听闻ChatGPT可以通过某种方式绕过安全机制,对目标进行入侵。 ChatGPT的“越狱”技术已经迭代数次,甚至有了先进的“邪恶GPT”WormGPT和FraudGPT,两者都能快速实现钓鱼邮件骗局。 安全分析…...
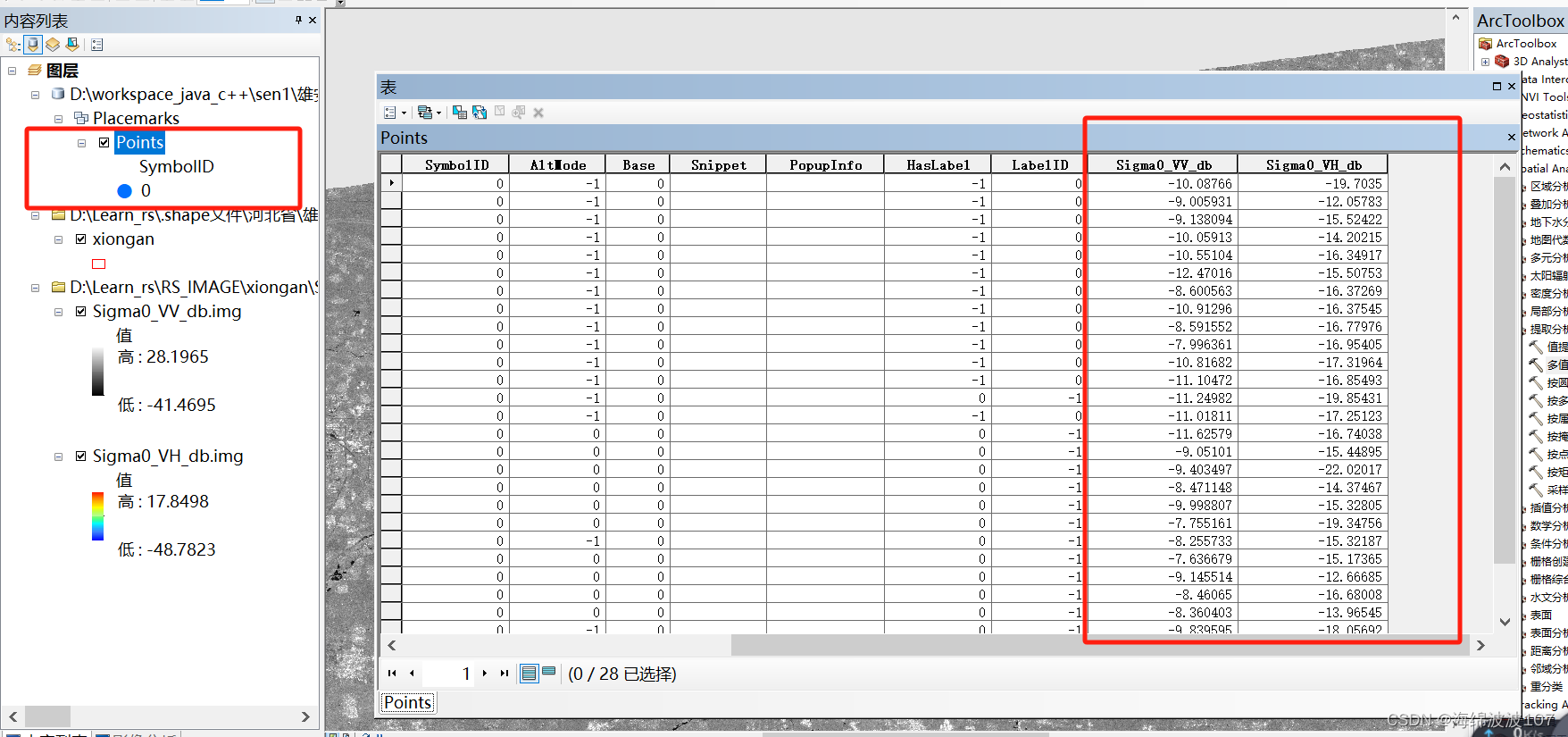
哨兵1号后向散射系数土壤水分反演
哨兵1号后向散射系数土壤水分反演 数据导入 打开之前预处理之后的VH和VV极化的后向散射系数转存的tiff文件 导入实测点 选择KML转图层 kml文件是由奥维地图导出的.ovkml格式改后缀名得到的 提取采样点的后向散射系数 选择多值提取至点 右键打开点图层的属性表,发现…...

day3:Node.js 基础知识
day3:Node.js 基础知识 文章目录 day3:Node.js 基础知识创建第一个应用事件循环机制异步编程模块系统函数与回调函数路由和全局对象创建第一个应用 实例如下,在你项目的根目录下创建一个叫 helloworld.js 的文件,并写入以下代码: var http = require(http);http.cre…...

igel高级功能解析:交叉验证与模型评估最佳实践
igel高级功能解析:交叉验证与模型评估最佳实践 【免费下载链接】igel a delightful machine learning tool that allows you to train, test, and use models without writing code 项目地址: https://gitcode.com/gh_mirrors/ig/igel igel是一个让机器学习变…...

SMUDebugTool终极指南:快速掌握AMD Ryzen系统调试与优化技巧
SMUDebugTool终极指南:快速掌握AMD Ryzen系统调试与优化技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: http…...

别再只盯着运放了:用跨阻放大器搞定光电传感器信号调理的完整指南
光电传感器信号调理实战:跨阻放大器设计与避坑指南 当你在昏暗的灯光下测试光电传感器时,是否曾被微弱的电流信号折磨得焦头烂额?作为嵌入式工程师,我曾在凌晨三点的实验室里,面对闪烁不定的示波器波形,才…...

让 TDengine 在 JetBrains IDEs 里更像“原生数据库”一点
让 TDengine 在 JetBrains IDEs 里更像“原生数据库”一点 Author: ChangJin Wei (魏昌进) 最近我做了一个小插件,把 TDengine 接入到了 JetBrains IDEs 的数据库工具链里。 先埋个小提示:文末有彩蛋。 项目地址: GitHub: https://github.…...
)
SVN检出报错大全:从E170011到E120106的实战解决手册(附cleanup的正确用法)
SVN检出报错实战指南:从E170011到E120106的深度解析与解决方案 引言:SVN检出报错的常见场景与应对思路 在团队协作开发中,版本控制系统扮演着至关重要的角色。作为集中式版本控制的代表,SVN(Subversion)至今…...

学术探险家的秘密武器:书匠策AI,解锁课程论文新宇宙!
在学术的浩瀚星空中,每一位学子都是勇敢的探险家,怀揣着对知识的渴望,踏上探索未知的征途。而课程论文,则是这场探险中不可或缺的“星际导航图”,指引着我们穿越知识的迷雾,抵达真理的彼岸。但你是否曾遇到…...

RexUniNLU硬件加速:TensorRT推理优化实践
RexUniNLU硬件加速:TensorRT推理优化实践 想让你的RexUniNLU模型推理速度飞起来吗?尤其是在T4这类消费级显卡上,看着模型慢悠悠地吐出结果,是不是有点着急?今天咱们就来聊聊怎么用TensorRT给RexUniNLU“打一针强心剂”…...

MySQL 数据恢复利器:my2sql 实战解析与应用场景
1. my2sql 是什么?为什么你需要它? 如果你负责过MySQL数据库运维,肯定遇到过这样的场景:开发同事不小心执行了DELETE FROM users WHERE id1,然后慌慌张张跑过来问你能不能恢复数据。这时候如果只有全量备份binlog的传统…...

终极指南:简单快速解决C盘爆红的Windows清理工具
终极指南:简单快速解决C盘爆红的Windows清理工具 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你的C盘是不是又红了?电脑卡得像蜗牛爬&a…...
)
手把手教你用NEWLab搭建智能温控系统(附完整代码)
手把手教你用NEWLab搭建智能温控系统(附完整代码) 在智能家居和工业自动化领域,温度控制始终是核心需求之一。无论是保持室内舒适环境,还是确保精密设备的稳定运行,一套可靠的温控系统都不可或缺。对于物联网初学者和…...