BERT变体(1):ALBERT、RoBERTa、ELECTRA、SpanBERT
Author:龙箬
Computer Application Technology
Change the World with Data and Artificial Intelligence !
CSDN@weixin_43975035
*天下之大,虽离家万里,何处不可往!何事不可为!
1. ALBERT
\qquad ALBERT的英文全称为A Lite version of BERT,意思是BERT模型的精简版。ALBERT模型对BERT的架构做了一些改变,以尽量缩短训练时间。
\qquad 与BERT相比,ALBERT的参数更少。它使用以下两种技术减少参数的数量。
·跨层参数共享
\qquad 在跨层参数共享的情况下,不是学习所有编码器层的参数,而是只学习第一层编码器的参数,然后将第一层编码器的参数与其他所有编码器层共享。在应用跨层参数共享时有以下几种方式。
全共享: 其他编码器的所有子层共享编码器1的所有参数。
共享前馈网络层: 只将编码器1的前馈网络层的参数与其他编码器的前馈网络层共享。
共享注意力层: 只将编码器1的多头注意力层的参数与其他编码器的多头注意力层共享。
默认情况下,ALBERT使用全共享选项,也就是说,所有层共享编码器1的参数
·嵌入层参数因子分解
\qquad 我们用 V V V 表示词表的大小。BERT的词表大小为30000。我们用 V V V 表示隐藏层嵌入的大小,用 E E E 表示WordPiece嵌入的大小。
\qquad 我们将独热编码向量投射到低维嵌入空间 ( V ∗ E ) (V*E) (V∗E),然后将这个低维嵌入投射到隐藏空间 ( E ∗ H ) (E*H) (E∗H),而不是直接将词表的独热编码向量投射到隐藏空间 ( V ∗ H ) (V*H) (V∗H)。也就是说,我们不是直接投射 ( V ∗ H ) (V*H) (V∗H),而是将这一步分解为 ( V ∗ E ) (V*E) (V∗E) 和 ( E ∗ H ) (E*H) (E∗H)。
\qquad ALBERT模型是使用掩码语言模型构建任务进行预训练的,但ALBERT没有使用下句预测任务,而是使用句序预测(sentence order prediction, SOP)这一新任务。
from transformers import AlbertModel, AlbertTokenizermodel = AlbertModel.from_pretrained(pretrained_model_name_or_path='/code/AlbertModel/')
tokenizer = AlbertTokenizer.from_pretrained(pretrained_model_name_or_path='/code/AlbertModel/spiece.model')
# 模型下载地址 https://huggingface.co/albert-base-v2/tree/main
sentence = "Beijing is a beautiful city"
inputs = tokenizer(sentence, return_tensors = "pt")
print(inputs)
ALBERT模型存储路径及目录如下:
#输出结果:
{'input_ids': tensor([[ 2, 6579, 25, 21, 1632, 136, 3]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
# 获取模型的输出
outputs = model(**inputs) # hidden_rep包含最后一个编码器层的所有标记的隐藏状态特征
hidden_rep = outputs.last_hidden_state # cls_head通常是用于分类任务的输出,这里假设你的模型有这样一个输出
cls_head = outputs.pooler_outputprint(hidden_rep, cls_head)
# [CLS] BeiJing is a beautiful city [SEP]
print(hidden_rep[0][0]) # [CLS]标记的上下文嵌入
print(hidden_rep[0][1]) # Paris标记的上下文嵌入
print(hidden_rep[0][2]) # is标记的上下文嵌入
print(hidden_rep[0][6]) # [SEP]标记的上下文嵌入
2. RoBERTa
\qquad RoBERTa模型,它是Robustly Optimized BERT Pretraining Approach(稳健优化的BERT预训练方法)的简写。RoBERTa是目前最流行的BERT变体之一,它被应用于许多先进的系统。
RoBERTa本质上是BERT,它只是在预训练中有以下变化。
·在掩码语言模型构建任务中使用动态掩码而不是静态掩码。
\qquad RoBERTa使用的是动态掩码,每个句子都有不同的标记被掩盖
·不执行下句预测任务,只用掩码语言模型构建任务进行训练。
\qquad 研究人员发现,下句预测任务对于预训练BERT模型并不是真的有用,因此只需用掩码语言模型构建任务对RoBERTa模型进行预训练。
·以大批量的方式进行训练。
\qquad 用较大的批量进行训练可以提高模型的速度和性能。
·使用字节级字节对编码作为子词词元化算法
from transformers import RobertaConfig, RobertaModel, RobertaTokenizermodel = RobertaModel.from_pretrained('/code/roberta-base/')
tokenizer = RobertaTokenizer.from_pretrained('/code/roberta-base/')
# 模型下载地址 https://huggingface.co/roberta-base/tree/main
RoBERTa模型存储路径及目录如下:
model.config#RoBERTa模型输出参数:
RobertaConfig {"_name_or_path": "/code/roberta-base/","architectures": ["RobertaForMaskedLM"],"attention_probs_dropout_prob": 0.1,"bos_token_id": 0,"classifier_dropout": null,"eos_token_id": 2,"hidden_act": "gelu","hidden_dropout_prob": 0.1,"hidden_size": 768,"initializer_range": 0.02,"intermediate_size": 3072,"layer_norm_eps": 1e-05,"max_position_embeddings": 514,"model_type": "roberta","num_attention_heads": 12,"num_hidden_layers": 12,"pad_token_id": 1,"position_embedding_type": "absolute","transformers_version": "4.34.0","type_vocab_size": 1,"use_cache": true,"vocab_size": 50265
}
tokenizer.tokenize('It was a great day') # Ġ表示一个空格,RoBERTa词元分析器将所有空格替换为Ġ字符# 输出结果:
['It', 'Ġwas', 'Ġa', 'Ġgreat', 'Ġday']
tokenizer.tokenize('I had a sudden epiphany')
# 因为epiphany不存在于词表中,所以它被分割成子词ep和iphany。我们也可以看到空格被替换成了Ġ字符# 输出结果:
['I', 'Ġhad', 'Ġa', 'Ġsudden', 'Ġep', 'iphany']
3. ELECTRA
\qquad ELECTRA模型,它的英文全称为Efficiently Learning an Encoder that Classifies Token Replacements Accurately(高效训练编码器如何准确分类替换标记)。与其他BERT变体不同,ELECTRA使用一个生成器(generator)和一个判别器(discriminator),并使用替换标记检测这一新任务进行预训练。
\qquad ELECTRA没有使用掩码语言模型构建任务作为预训练目标,而是使用一个叫作替换标记检测的任务进行预训练。替换标记检测任务与掩码语言模型构建任务非常相似,但它不是用[MASK]标记来掩盖标记,而是用另一个标记来替换,并训练模型判断标记是实际标记还是替换后的标记。
\qquad 由于掩码语言模型构建任务在预训练时使用了[MASK]标记,但在针对下游任务的微调过程中,[MASK]标记并不存在,这导致了预训练和微调之间的不匹配。在替换标记检测任务中,我们不使用[MASK]来掩盖标记,而是用不同的标记替换另一个标记,并训练模型来判断给定的标记是实际标记还是替换后的标记。这就解决了预训练和微调之间不匹配的问题。
from transformers import ElectraModel, ElectraTokenizermodel = ElectraModel.from_pretrained('/code/ElectraModel/electra-small-discriminator/')
tokenizer = ElectraTokenizer.from_pretrained('/code/ElectraModel/electra-small-discriminator/')
# 模型下载地址
# https://huggingface.co/google/electra-small-discriminator/tree/main
# https://huggingface.co/google/electra-small-generator/tree/main
ELECTRA模型存储路径及目录如下:

model.config# ELECTRA模型输出参数:
ElectraConfig {"_name_or_path": "/code/ElectraModel/electra-small-discriminator/","architectures": ["ElectraForPreTraining"],"attention_probs_dropout_prob": 0.1,"classifier_dropout": null,"embedding_size": 128,"hidden_act": "gelu","hidden_dropout_prob": 0.1,"hidden_size": 256,"initializer_range": 0.02,"intermediate_size": 1024,"layer_norm_eps": 1e-12,"max_position_embeddings": 512,"model_type": "electra","num_attention_heads": 4,"num_hidden_layers": 12,"pad_token_id": 0,"position_embedding_type": "absolute","summary_activation": "gelu","summary_last_dropout": 0.1,"summary_type": "first","summary_use_proj": true,"transformers_version": "4.34.0","type_vocab_size": 2,"use_cache": true,"vocab_size": 30522
}
tokenizer('It was a great day', return_tensors="pt")# 输出结果:
{'input_ids': tensor([[ 101, 2009, 2001, 1037, 2307, 2154, 102]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
4. SpanBERT
\qquad SpanBERT,它被普遍应用于问答任务和关系提取任务。在SpanBERT中,我们不再随机地掩盖标记并替换为[MASK],而是将连续标记段替换为[MASK]。如下所示:
tokens = [ you, are, expected, to, know, [MASK], [MASK], [MASK], [MASK], country ]
from transformers import pipelineqa_pipeline = pipeline(task="question-answering",model='/code/SpanBERT/spanbert-finetuned-squadv2/', tokenizer='/code/SpanBERT/spanbert-finetuned-squadv2/')
# 模型下载地址 https://huggingface.co/mrm8488/spanbert-base-finetuned-squadv2/tree/main
result = qa_pipeline({'question': "What is Maching Learning?", 'context': "Machine Learning is a subset of Artifical Intelligence. It is widely for creating a variety of applications such as email filtering and computer vision"})
print(result['answer'])# 输出结果:
a subset of Artifical Intelligence
SpanBERT模型存储路径及目录如下:
\qquad 为了预测[MASK]所代表的标记,我们用掩码语言模型构建目标和区间边界目标(span boundary objective, SBO)来训练SpanBERT模型。在区间边界目标中,为了预测任何一个掩码标记,只使用区间边界中的标记特征,而不使用相应的掩码标记的特征。区间边界包括区间开始之前的标记和区间结束之后的标记。除了区间边界标记特征,模型还使用了[MASK]的位置嵌入。位置嵌入表示掩码标记的相对位置。
\qquad 因此,SpanBERT使用两个目标:一个是掩码语言模型构建目标,另一个是区间边界目标。在掩码语言模型构建目标中,为了预测掩码标记,我们只使用相应标记的特征。在区间边界目标中,为了预测掩码标记,我们只使用区间边界标记特征和掩码标记的位置嵌入。
参考致谢:
[1]. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
[2]. RoBERTa: A Robustly Optimized BERT Pretraining Approach
[3]. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
[4]. SpanBERT: Improving Pre-training by Representing and Predicting Spans
[5]. BERT基础教程:Transformer大模型实战. 苏达哈拉桑 · 拉维昌迪兰
如有侵权,请联系侵删
需要本实验源数据及代码的小伙伴请联系QQ:2225872659
相关文章:
BERT变体(1):ALBERT、RoBERTa、ELECTRA、SpanBERT
Author:龙箬 Computer Application Technology Change the World with Data and Artificial Intelligence ! CSDNweixin_43975035 *天下之大,虽离家万里,何处不可往!何事不可为! 1. ALBERT \qquad ALBERT的英文全称为A Lite versi…...
域控操作二:设置域用户使用简单密码
过程太多简单 直接写出路径更改即可 组策略—计算机配置----策略—Windows设置–安全设置----账户策略–密码策略 按自己想法改就行了 注意一点!!!!! 要么自己设置策略,要么从默认策略改!&am…...
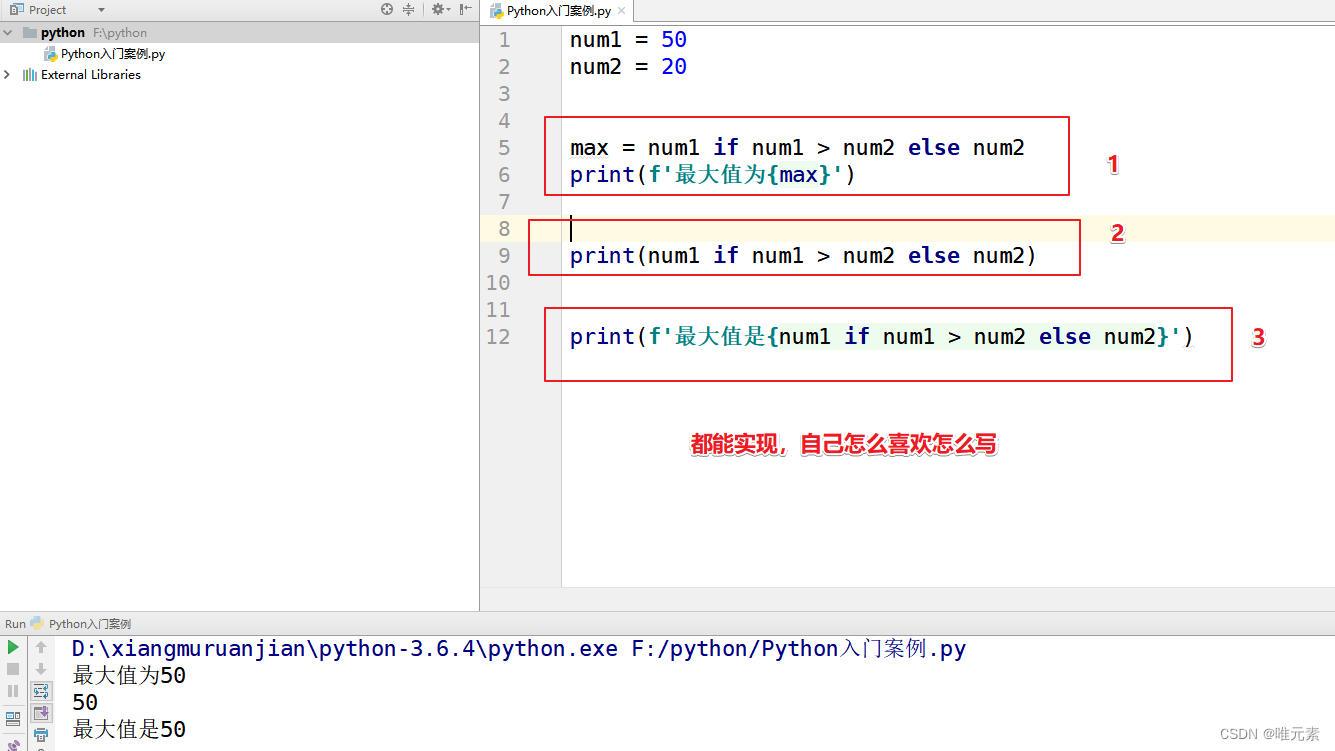
python---三目运算符
在Python中三目运算符也叫三元运算符,其主要作用:就是用于 简化if...else...语句。 基本语法: 原 if 条件判断: # 语句段1 else: # 语句段2 新-----三目运算符/三元运算符 语句段1 if 条件判断 else 语句段2 案例 输入两个数…...

百度地图定位BMap.GeolocationControl的用法
BMap.GeolocationControl 是百度地图API中的一个类,用于添加地理定位控件到地图上,以便用户可以通过该控件获取自己的当前位置。以下是 BMap.GeolocationControl 的用法示例: 首先,确保已经加载了百度地图API,并且创建…...
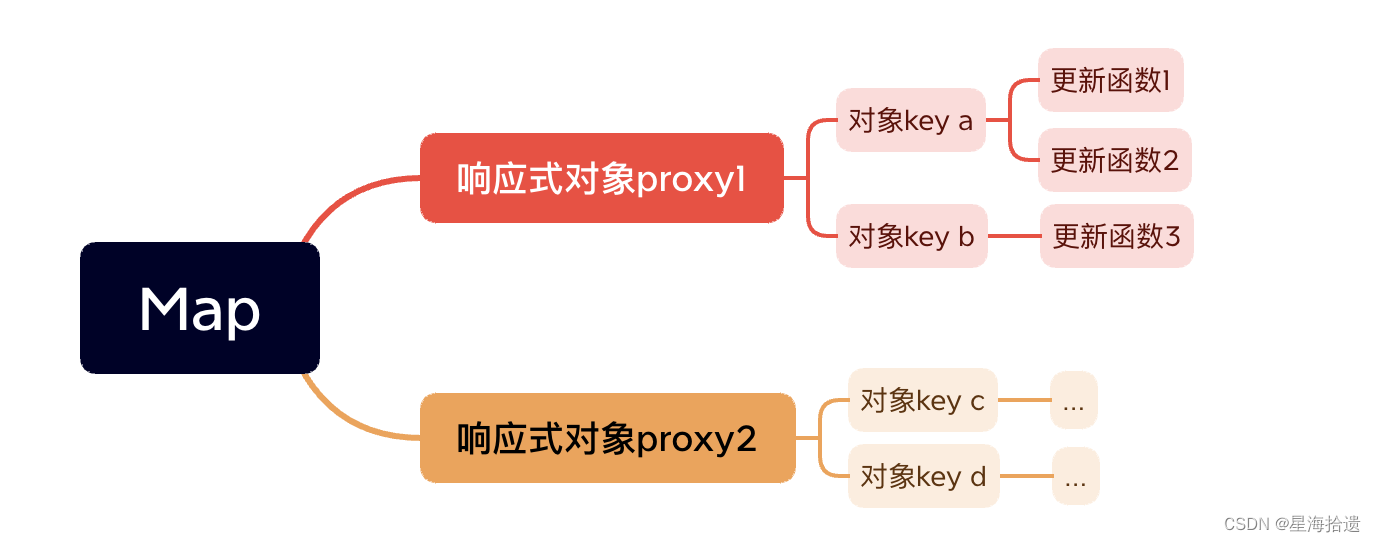
Vue3响应式原理初探
vue3响应式原理初探 为什么要使用proxy取代defineProperty使用proxy如何完成依赖收集呢? 为什么要使用proxy取代defineProperty 原因1:defineproperty无法检测到原本不存在的属性。打个🌰 new Vue({data(){return {name:wxs,age:25}}})在vue…...

firewalld常用的基础配置
firewalld防火墙是centos7系统默认的防火墙管理工具,取代了之前的iptables防火墙,也是工作在网络层,属于包过滤防火墙。 支持IPv4、IPv6防火墙设置以及以太网桥支持服务或应用程序直接添加防火墙规则接口拥有两种配置模式:临时模…...

功率放大器如何驱动超声波换能器
驱动超声波换能器的功率放大器在超声波应用中起着至关重要的作用。它能够提供足够的功率和精确的信号控制,使换能器能够有效地将电能转换为超声波能量。下面安泰电子将介绍功率放大器如何驱动超声波换能器的原理和关键要点。 首先,让我们了解一下超声波换…...
LiveGBS流媒体平台GB/T28181常见问题-安全控制HTTP接口鉴权勾选流地址鉴权后401Unauthorized如何播放调用接口
LiveGBS流媒体平台GB/T28181常见问题-安全控制HTTP接口鉴权勾选流地址鉴权后401 Unauthorized如何播放调用接口? 1、安全控制1.1、HTTP接口鉴权1.2、流地址鉴权 2、401 Unauthorized2.1、携带token调用接口2.1.1、获取鉴权token2.1.2、调用其它接口2.1.2.1、携带 Co…...

红帽认证笔记2
文章目录 1.配置系统以使用默认存储库1.调试selinux2.创建用户账户3.配置cron4. 创建写作目录5. 配置NTP6.配置autofs配置文件权限容器解法1.修改journal配置文件2.重启服务3.拷贝文件到指定目录4.修改拥有人所属组5.修改umask6.切换elovodo用户7.登录容器仓库8.拉取镜像9.运行…...

程序开发中表示密码时使用 password 还是 passcode?
password 和 passcode 是两个经常在计算机和网络安全中使用的术语,两者都是用于身份验证的机制,但它们之间还是存在一些区别的。 password password 通常是指用户自己设置的一串字符,用于保护自己的账户安全。密码通常是静态的,…...

html5 文字自动省略,html中把多余文字转化为省略号的实现方法方法
单行文本: .box{width: 200px;background-color: aqua;text-overflow: ellipsis;overflow: hidden;white-space: nowrap; }多行文本 1.利用-webkit-line-clamp属性 .box{width: 200px;overflow : hidden;text-overflow: ellipsis;display: -webkit-box;-webkit-l…...
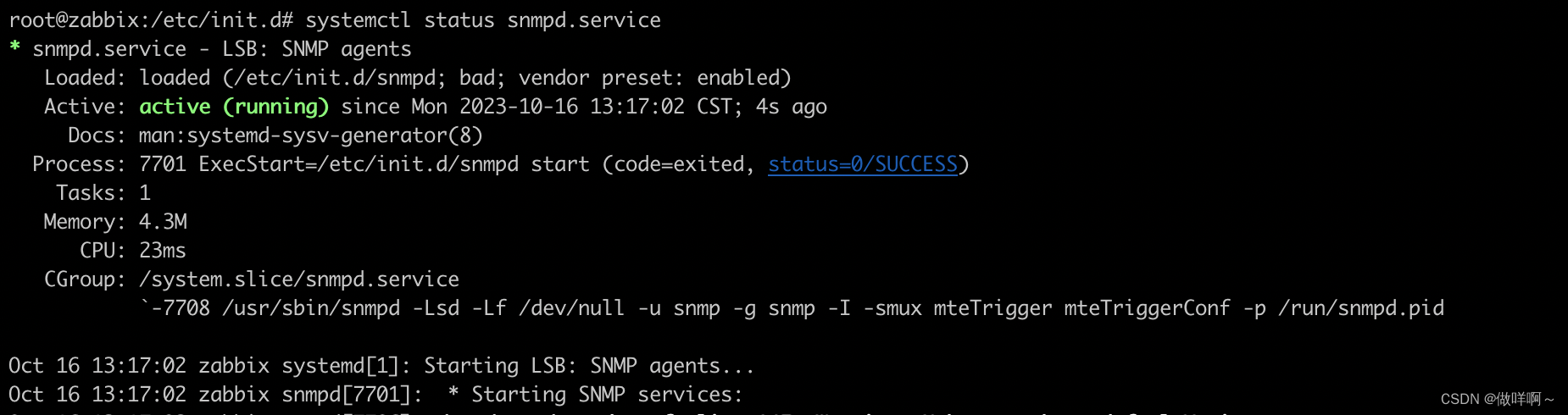
6.SNMP报错-Error opening specified endpoint “udp6:[::1]:161“处理
启动SNMP服务 /etc/init.d/snmpd start 出现以下报错信息 [....] Starting snmpd (via systemctl): snmpd.serviceJob for snmpd.service failed because the control process exited with error code. See "systemctl status snmpd.service" and "journalctl…...

集合的进阶
不可变集合 创建不可变的集合 在创建了之后集合的长度内容都不可以变化 静态集合的创建在list ,set ,map接口当中都可以获取不可变集合 方法名称说明static list of(E …elements)创建一个具有指定元素集合list集合对象staticlist of(E…elements)创…...

【LeetCode刷题(数据结构与算法)】:数据结构中的常用排序实现数组的升序排列
现在我先将各大排序的动图和思路以及代码呈现给大家 插入排序 直接插入排序是一种简单的插入排序法,其基本思想是: 把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为 止,得到一个…...

【HTML+CSS】零碎知识点
公告滚动条 <!DOCTYPE html> <html><head><title>动态粘性导航栏</title><style>.container {background: #00aeec;overflow: hidden;padding: 20px 0;}.title {float: left;font-size: 20px;font-weight: normal;margin: 0;margin-left:…...
嵌入式开发学习之STM32F407串口(USART)收发数据(三)
嵌入式开发学习之STM32F407串口(USART)收发数据(三) 开发涉及工具一、选定所使用的串口二、配置串口1.配置串口的I/O2.配置串口参数属性3.配置串口中断4.串口中断在哪里处理5.串口如何发送字符串 三、封装串口配置库文件1.创建头文…...
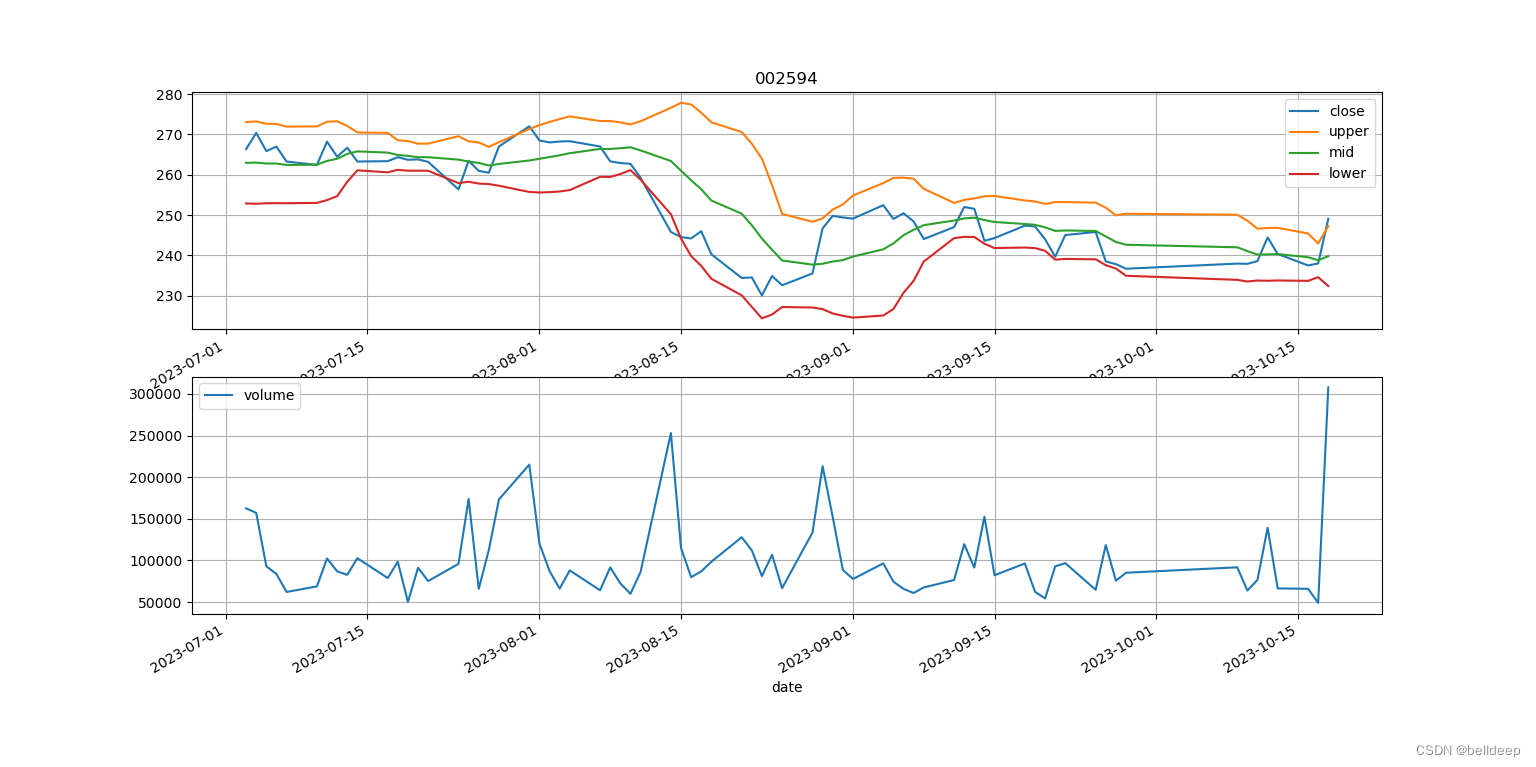
python:talib.BBANDS 画股价-布林线图
python 安装使用 TA_lib 安装主要在 http://www.lfd.uci.edu/~gohlke/pythonlibs/ 这个网站找到 TA_Lib-0.4.24-cp310-cp310-win_amd64.whl pip install /pypi/TA_Lib-0.4.24-cp310-cp310-win_amd64.whl 编写 talib_boll.py 如下 # -*- coding: utf-8 -*- import os impor…...

ESP32网络开发实例-自定义主机名称
自定义主机名称 文章目录 自定义主机名称1、软件准备2、硬件准备3、代码实现ESP32 的默认主机名是 expressif。 但是,如果正在使用多个 ESP32 设备,并且在某些时候希望在软接入点模式下使用它们时通过名称来区分设备。 例如,在基于物联网的项目中有多个节点,例如温度、湿度…...
【ELK 使用指南 3】Zookeeper、Kafka集群与Filebeat+Kafka+ELK架构(附部署实例)
EFLKK 一、Zookeeper1.1 简介1.2 zookeeper的作用1.3 Zookeeper的特点1.5 Zookeeper的数据结构1.6 Zookeeper的应用场景1.7 Zookeeper的选举机制(重要)1.7.1 第一次启动时1.7.2 非第一次启动时 二、Zookeeper集群部署2.1 安装前准备2.2 安装 ZookeeperSt…...

手写redux的connect方法, 使用了subscribe获取最新数据
一. 公共方法文件 1. connect文件 import React, { useState } from "react"; import MyContext from "./MyContext"; import _ from "lodash";// 模拟react-redux的 connect高阶函数 const connect (mapStateToProps, mapDispatchToProps) &…...

亚马逊爆款选品:数据采集与三方服务商对接
一、核心选品数据采集渠道1. 官方免费数据源(合规权威)BSR畅销榜:查看类目热销品,定位头部爆款。新品榜:挖掘增速快、潜力大的新品。商机探测器:卖家后台直达,获取高搜索量、低竞争蓝海词。品牌…...

别再花钱买云API了!手把手教你用Docker+Ollama在本地免费跑通Strix渗透测试
零成本打造企业级渗透测试环境:DockerOllama本地化实战指南 当安全团队每月收到云服务商五位数的API账单时,当关键测试任务因网络抖动被迫中断时,越来越多的技术决策者开始重新审视渗透测试的基础架构。本文将揭示如何用消费级硬件构建媲美商…...

MRM-MOT4X3.6CAN电机驱动库:工业级CAN总线电机控制抽象层
1. 项目概述mrm-mot4x3.6can是一款面向工业级电机控制场景的专用 CAN 总线驱动库,专为 MRMS(Modular Robotic Motor Systems)公司推出的MRM-MOT4X3.6CAN 四通道直流电机控制器设计。该控制器集成 4 路独立 H 桥驱动单元,每路持续输…...

嵌入式 数据结构 线性表 学习笔记
线性表线性结构的特点是:1、存在唯一的一个被称作“第一个”的数据元素2、存在唯一的一个被称作“最后一个”的数据元素3、除第一个之外,集合中的每个元素均只有一个前驱4、除最后一个以外,集合中的每个数据元素均只有一个后继顺序表示和实现…...

AD21实战:3种方法搞定Keepout和机械层互转,最后一种能救急
AD21实战:3种高效解决Keepout与机械层互转难题的方法 在PCB设计过程中,Keepout层和机械层的正确使用与转换是确保设计准确性的关键环节。许多工程师都遇到过这样的困境:当设计文件中包含复杂图形元素时,简单的层切换或属性批量修…...

QT窗口特效实战:从透明到异形控件的全方位实现指南
1. 从零开始理解QT窗口特效 第一次接触QT窗口特效时,我被那些酷炫的透明和异形界面深深吸引。记得当时看到Mac OS X的Dock栏那种毛玻璃效果,就特别想在自己的QT应用中实现类似效果。经过多年实战,我发现QT实现这些特效其实比想象中简单得多。…...

Zotero插件Ethereal Style:打造高效文献管理新体验
Zotero插件Ethereal Style:打造高效文献管理新体验 【免费下载链接】zotero-style zotero-style - 一个 Zotero 插件,提供了一系列功能来增强 Zotero 的用户体验,如阅读进度可视化和标签管理,适合研究人员和学者。 项目地址: ht…...

Dramatron:AI驱动剧本创作的协同进化方法
Dramatron:AI驱动剧本创作的协同进化方法 【免费下载链接】dramatron Dramatron uses large language models to generate coherent scripts and screenplays. 项目地址: https://gitcode.com/gh_mirrors/dr/dramatron 问题:当代创作者的三重困境…...

新手福音:在快马平台零基础上手加速库,轻松提速深度学习训练
新手福音:在快马平台零基础上手加速库,轻松提速深度学习训练 作为一个刚接触深度学习的新手,最头疼的莫过于环境配置和性能优化。最近我在InsCode(快马)平台上发现了一个超实用的功能——预置加速库的深度学习项目模板,让我这个小…...

如何高效配置Unity插件框架:BepInEx完整实战指南
如何高效配置Unity插件框架:BepInEx完整实战指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款专为Unity游戏设计的插件框架和补丁工具,能够…...