[Machine Learning][Part 6]Cost Function代价函数和梯度正则化
目录
拟合
欠拟合
过拟合
正确的拟合
解决过拟合的方法:正则化
线性回归模型和逻辑回归模型都存在欠拟合和过拟合的情况。
拟合
来自百度的解释:
数据拟合又称曲线拟合,俗称拉曲线,是一种把现有数据透过数学方法来代入一条数式的表示方式。科学和工程问题可以通过诸如采样、实验等方法获得若干离散的数据,根据这些数据,我们往往希望得到一个连续的函数(也就是曲线)或者更加密集的离散方程与已知数据相吻合,这过程就叫做拟合(fitting)。
个人理解,拟合就是根据已有数据来建立的一个数学模型,这个数据模型能最大限度的包含现有的数据。这样预测的数据就能最大程度的符合现有情况。
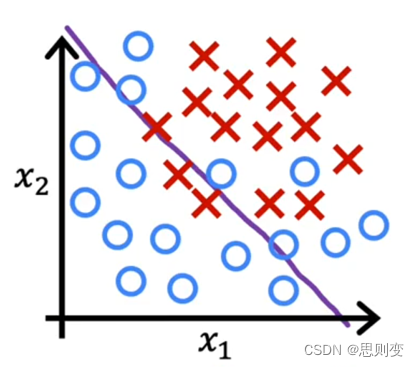
欠拟合
所建立的模型与现有数据匹配度较低如下图的分类模型,决策边界并不能很好的区分目前的数据
当训练数据的特征值较少的时候会出现欠拟合
过拟合
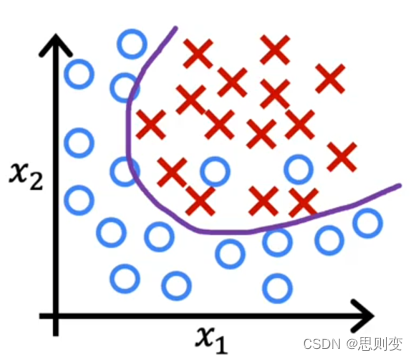
模型过于匹配现有数据,导致模型不能推广应用到更多数据中去。当训练数据的特征值太多的时候会出现这种情况。

正确的拟合
介于欠拟合和过拟合之间
解决过拟合的方法:正则化
解决过拟合的方法是将模型正则化,就是说把不是主要特征的w_j调整为无限接近于0,然后训练模型,这样来寻找最优的模型。这样存在一个问题,怎么分辨特征是不是主要特征呢?这个是不好分辨的,因此是把所有的特征都正则化,正则化的公式为:
线性回归cost function:
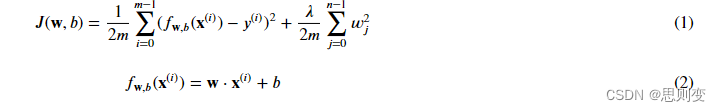
逻辑回归cost function:
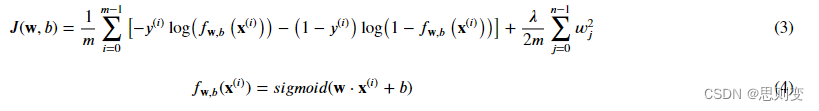
适用于线性回归和逻辑回归的梯度下降函数:
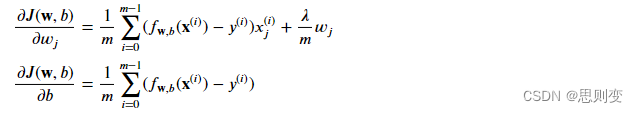
实现代码:
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
from plt_overfit import overfit_example, outputnp.set_printoptions(precision=8)def sigmoid(z):"""Compute the sigmoid of zArgs:z (ndarray): A scalar, numpy array of any size.Returns:g (ndarray): sigmoid(z), with the same shape as z"""g = 1/(1+np.exp(-z))return gdef compute_cost_linear_reg(X, y, w, b, lambda_ = 1):"""Computes the cost over all examplesArgs:X (ndarray (m,n): Data, m examples with n featuresy (ndarray (m,)): target valuesw (ndarray (n,)): model parameters b (scalar) : model parameterlambda_ (scalar): Controls amount of regularizationReturns:total_cost (scalar): cost """m = X.shape[0]n = len(w)cost = 0.for i in range(m):f_wb_i = np.dot(X[i], w) + b #(n,)(n,)=scalar, see np.dotcost = cost + (f_wb_i - y[i])**2 #scalar cost = cost / (2 * m) #scalar reg_cost = 0for j in range(n):reg_cost += (w[j]**2) #scalarreg_cost = (lambda_/(2*m)) * reg_cost #scalartotal_cost = cost + reg_cost #scalarreturn total_cost #scalarnp.random.seed(1)
X_tmp = np.random.rand(5,6)
y_tmp = np.array([0,1,0,1,0])
w_tmp = np.random.rand(X_tmp.shape[1]).reshape(-1,)-0.5
b_tmp = 0.5
lambda_tmp = 0.7
cost_tmp = compute_cost_linear_reg(X_tmp, y_tmp, w_tmp, b_tmp, lambda_tmp)print("Regularized cost:", cost_tmp)def compute_cost_logistic_reg(X, y, w, b, lambda_ = 1):"""Computes the cost over all examplesArgs:Args:X (ndarray (m,n): Data, m examples with n featuresy (ndarray (m,)): target valuesw (ndarray (n,)): model parameters b (scalar) : model parameterlambda_ (scalar): Controls amount of regularizationReturns:total_cost (scalar): cost """m,n = X.shapecost = 0.for i in range(m):z_i = np.dot(X[i], w) + b #(n,)(n,)=scalar, see np.dotf_wb_i = sigmoid(z_i) #scalarcost += -y[i]*np.log(f_wb_i) - (1-y[i])*np.log(1-f_wb_i) #scalarcost = cost/m #scalarreg_cost = 0for j in range(n):reg_cost += (w[j]**2) #scalarreg_cost = (lambda_/(2*m)) * reg_cost #scalartotal_cost = cost + reg_cost #scalarreturn total_cost #scalarnp.random.seed(1)
X_tmp = np.random.rand(5,6)
y_tmp = np.array([0,1,0,1,0])
w_tmp = np.random.rand(X_tmp.shape[1]).reshape(-1,)-0.5
b_tmp = 0.5
lambda_tmp = 0.7
cost_tmp = compute_cost_logistic_reg(X_tmp, y_tmp, w_tmp, b_tmp, lambda_tmp)print("Regularized cost:", cost_tmp)def compute_gradient_linear_reg(X, y, w, b, lambda_): """Computes the gradient for linear regression Args:X (ndarray (m,n): Data, m examples with n featuresy (ndarray (m,)): target valuesw (ndarray (n,)): model parameters b (scalar) : model parameterlambda_ (scalar): Controls amount of regularizationReturns:dj_dw (ndarray (n,)): The gradient of the cost w.r.t. the parameters w. dj_db (scalar): The gradient of the cost w.r.t. the parameter b. """m,n = X.shape #(number of examples, number of features)dj_dw = np.zeros((n,))dj_db = 0.for i in range(m): err = (np.dot(X[i], w) + b) - y[i] for j in range(n): dj_dw[j] = dj_dw[j] + err * X[i, j] dj_db = dj_db + err dj_dw = dj_dw / m dj_db = dj_db / m for j in range(n):dj_dw[j] = dj_dw[j] + (lambda_/m) * w[j]return dj_db, dj_dwnp.random.seed(1)
X_tmp = np.random.rand(5,3)
y_tmp = np.array([0,1,0,1,0])
w_tmp = np.random.rand(X_tmp.shape[1])
b_tmp = 0.5
lambda_tmp = 0.7
dj_db_tmp, dj_dw_tmp = compute_gradient_linear_reg(X_tmp, y_tmp, w_tmp, b_tmp, lambda_tmp)print(f"dj_db: {dj_db_tmp}", )
print(f"Regularized dj_dw:\n {dj_dw_tmp.tolist()}", )def compute_gradient_logistic_reg(X, y, w, b, lambda_): """Computes the gradient for linear regression Args:X (ndarray (m,n): Data, m examples with n featuresy (ndarray (m,)): target valuesw (ndarray (n,)): model parameters b (scalar) : model parameterlambda_ (scalar): Controls amount of regularizationReturnsdj_dw (ndarray Shape (n,)): The gradient of the cost w.r.t. the parameters w. dj_db (scalar) : The gradient of the cost w.r.t. the parameter b. """m,n = X.shapedj_dw = np.zeros((n,)) #(n,)dj_db = 0.0 #scalarfor i in range(m):f_wb_i = sigmoid(np.dot(X[i],w) + b) #(n,)(n,)=scalarerr_i = f_wb_i - y[i] #scalarfor j in range(n):dj_dw[j] = dj_dw[j] + err_i * X[i,j] #scalardj_db = dj_db + err_idj_dw = dj_dw/m #(n,)dj_db = dj_db/m #scalarfor j in range(n):dj_dw[j] = dj_dw[j] + (lambda_/m) * w[j]return dj_db, dj_dw np.random.seed(1)
X_tmp = np.random.rand(5,3)
y_tmp = np.array([0,1,0,1,0])
w_tmp = np.random.rand(X_tmp.shape[1])
b_tmp = 0.5
lambda_tmp = 0.7
dj_db_tmp, dj_dw_tmp = compute_gradient_logistic_reg(X_tmp, y_tmp, w_tmp, b_tmp, lambda_tmp)print(f"dj_db: {dj_db_tmp}", )
print(f"Regularized dj_dw:\n {dj_dw_tmp.tolist()}", )plt.close("all")
display(output)
ofit = overfit_example(True)逻辑回归输出为:
相关文章:
[Machine Learning][Part 6]Cost Function代价函数和梯度正则化
目录 拟合 欠拟合 过拟合 正确的拟合 解决过拟合的方法:正则化 线性回归模型和逻辑回归模型都存在欠拟合和过拟合的情况。 拟合 来自百度的解释: 数据拟合又称曲线拟合,俗称拉曲线,是一种把现有数据透过数学方法来代入一条…...

工业自动化编程与数字图像处理技术
工业自动化编程与数字图像处理技术 编程是计算机领域的基础技能,对于从事软件开发和工程的人来说至关重要。在工业自动化领域,C/C仍然是主流的编程语言,特别是用于工业界面(GUI)编程。工业界面是供车间操作员使用的,使用诸如Hal…...

JY61P.C
/** File Name : JY61P.cDescription : attention © Copyright (c) 2020 STMicroelectronics. All rights reserved.This software component is licensed by ST under Ultimate Liberty licenseSLA0044, the “License”; You may not use this file except in complian…...

Go编程:使用 Colly 库下载Reddit网站的图像
概述 Reddit是一个社交新闻网站,用户可以发布各种主题的内容,包括图片。本文将介绍如何使用Go语言和Colly库编写一个简单的爬虫程序,从Reddit网站上下载指定主题的图片,并保存到本地文件夹中。为了避免被目标网站反爬,…...

高性能日志脱敏组件:已支持 log4j2 和 logback 插件
项目介绍 日志脱敏是常见的安全需求。普通的基于工具类方法的方式,对代码的入侵性太强,编写起来又特别麻烦。 sensitive提供基于注解的方式,并且内置了常见的脱敏方式,便于开发。 同时支持 logback 和 log4j2 等常见的日志脱敏…...

一文读懂PostgreSQL中的索引
前言 索引是加速搜索引擎检索数据的一种特殊表查询。简单地说,索引是一个指向表中数据的指针。一个数据库中的索引与一本书的索引目录是非常相似的。 拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录…...

windows的批量解锁
场景 场景是我从github上拉了一个c#项目启动的时候报错, 1>C:\Program Files\Microsoft Visual Studio\2022\Community\MSBuild\Current\Bin\amd64\Microsoft.Common.CurrentVersion.targets(3327,5): error MSB3821: 无法处理文件 UI\Forms\frmScriptBuilder.…...

Nginx配置微服务避免actuator暴露
微服务一般在扫漏洞的情况下,需要屏蔽actuator健康检查 # 避免actuator暴露 if ($request_uri ~ "/actuator") { return 403; }...

GEE——在GEE中计算地形位置指数TPI
简介: DEM中的TPI计算是指通过计算每个像元高程与其邻域高程的差值来计算地形位置指数(Topographic Position Index)。TPI 是描述地形起伏度和地形形态的一个重要指标,可以用于地貌分类、土壤侵蚀、植被分布等领域。 地形位置指数(Topographic Position Index,TPI)是用…...

树的基本操作(数据结构)
树的创建 //结构结点 typedef struct Node {int data;struct Node *leftchild;struct Node *rightchild; }*Bitree,BitNode;//初始化树 void Create(Bitree &T) {int d;printf("输入结点(按0为空结点):");scanf("%d",&d);if(d!0){T (Bitree)ma…...

Python复刻游戏《贪吃蛇大作战》
入门教程、案例源码、学习资料、读者群 请访问: python666.cn 大家好,欢迎来到 Crossin的编程教室 ! 曾经有一款小游戏刷屏微信朋友圈,叫做《贪吃蛇大作战》。一个简单到不行的游戏,也不知道怎么就火了,还上…...
SpringCloud之Gateway整合Sentinel服务降级和限流
1.下载Sentinel.jar可以图形界面配置限流和降级规则 地址:可能需要翻墙 下载jar文件 2.引入maven依赖 <!-- spring cloud gateway整合sentinel的依赖--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-s…...
深度学习——深度卷积神经网络(AlexNet)
深度学习——深度卷积神经网络(AlexNet) 文章目录 前言一、学习表征二、AlexNet实现2.1. 模型设计2.2. 激活函数2.3. 容量控制与预处理2.4. 训练模型 总结 前言 在前面学习了卷积神经网络的基本原理,之后将继续学习现代卷积神经网络架构。而本章将学习其…...
提高编程效率-Vscode实用指南
您是否知道全球73%的开发人员依赖同一个代码编辑器? 是的,2023 年 Stack Overflow 开发者调查结果已出炉,Visual Studio Code 迄今为止再次排名第一最常用的开发环境。 “Visual Studio Code 仍然是所有开发人员的首选 IDE,与专业…...

ES 数据库
ES 数据库 通过 API 查询通过 JSON 查询 熟悉 es 的同学都知道 es 一般有两种查询方式 1,在 java 中构建查询对象,调用 es 提供的 api 做查询 2,使用 json 调用接口做查询 查询语句无非是将足够的信息丢给数据库,但是它却和 SQL …...

面试经典150题——Day14
文章目录 一、题目二、题解 一、题目 134. Gas Station There are n gas stations along a circular route, where the amount of gas at the ith station is gas[i]. You have a car with an unlimited gas tank and it costs cost[i] of gas to travel from the ith stati…...

Pika v3.5.1发布!
Pika 社区很高兴宣布,我们今天发布已经过我们生产环境验证 v3.5.1 版本,https://github.com/OpenAtomFoundation/pika/releases/tag/v3.5.1 。 该版本不仅做了很多优化工作,还引入了多项新功能。这些新功能包括 动态关闭 WAL、ReplicationID…...

Kotlin中的数组
数组是一种常见的数据结构,用于存储相同类型的多个元素。在 Kotlin 中,我们可以使用不同的方式声明、初始化和操作数组。 在 Kotlin 中,有多种方式可以定义和操作数组。我们将通过以下示例代码来展示不同的数组操作: fun main()…...
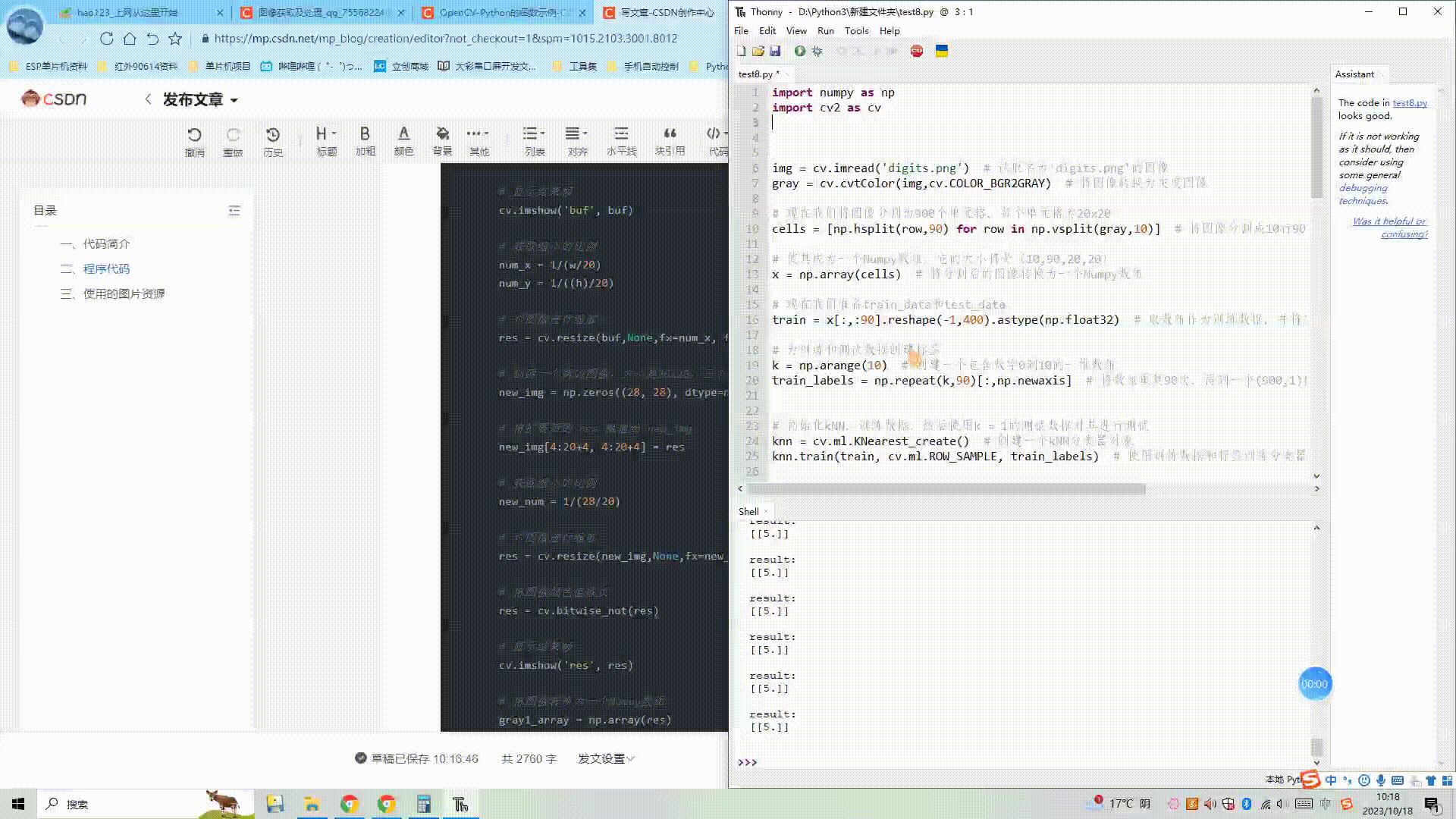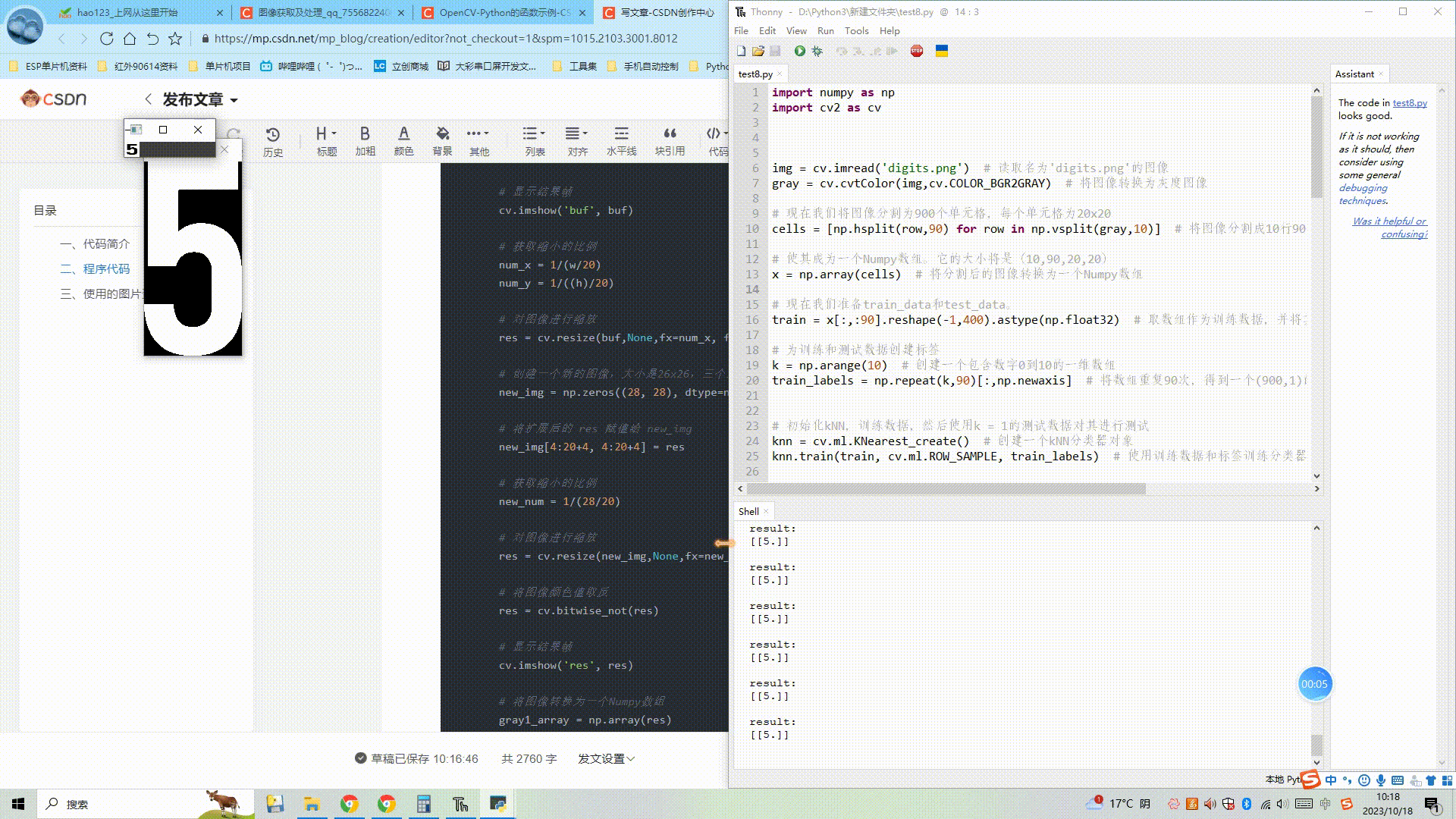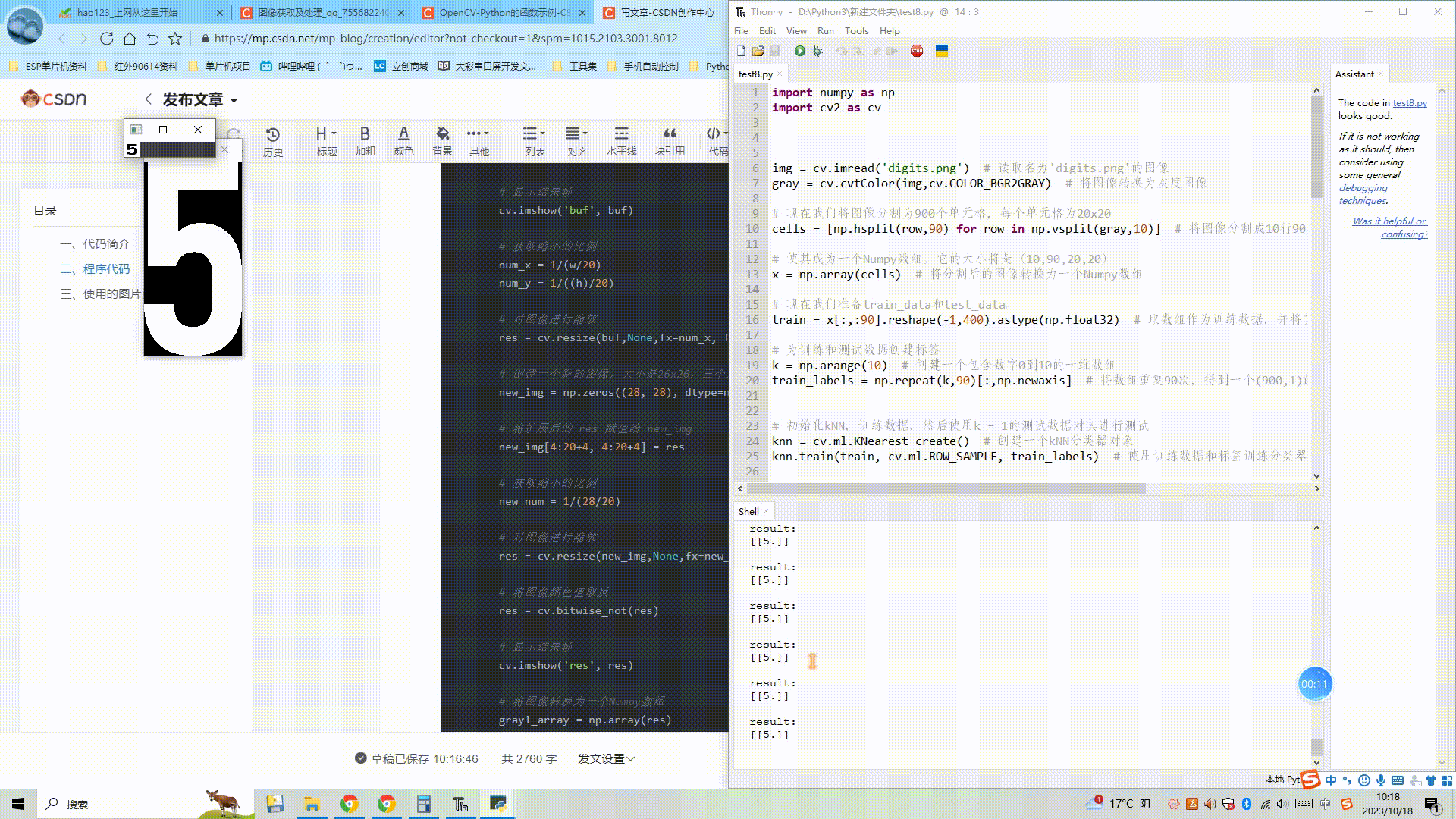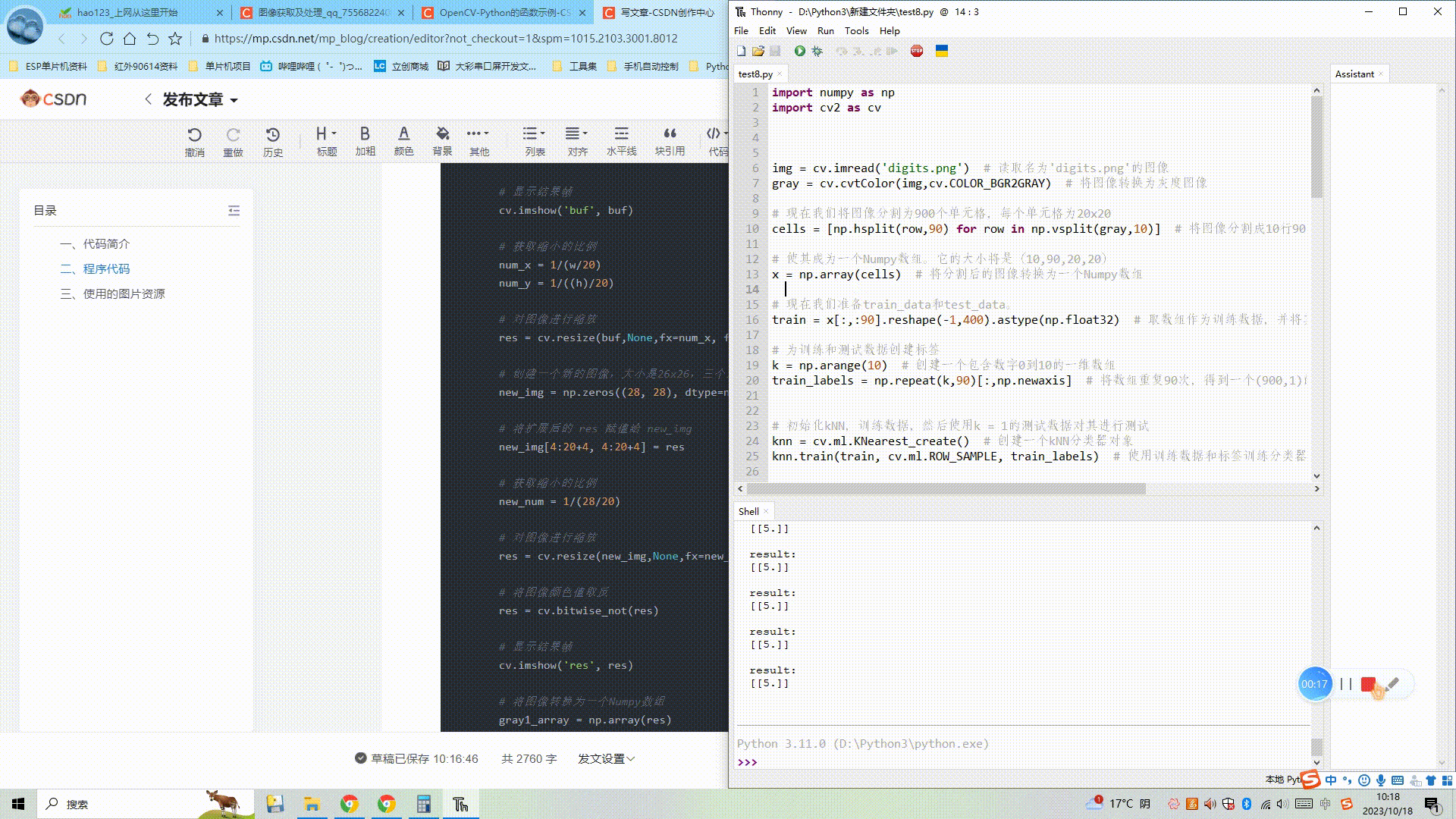
(3) OpenCV图像处理kNN近邻算法-识别摄像头数字
目录 一、代码简介 二、程序代码 三、使用的图片资源 1、图片digits.png...

上海亚商投顾:沪指震荡调整 转基因概念股逆势大涨
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指昨日低开低走,深成指、创业板指均跌超1%,双双创出年内新低。转基因概念股逆势大涨…...

Mermaid在线编辑器:开源可视化工具的图表创作革命
Mermaid在线编辑器:开源可视化工具的图表创作革命 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-editor …...

UG模型转STP后总出问题?可能是STEP 203和214版本没选对
UG模型转STP格式的深度选择指南:STEP 203与214版本差异解析 在工业设计领域,UG NX与STP格式的转换堪称日常操作,但许多工程师都曾遭遇这样的困境:明明转换过程一切顺利,接收方打开文件时却出现面片丢失、PMI信息异常甚…...

通义千问3-Reranker-0.6B优化升级:调整批处理大小和自定义指令,性能再提升5%
通义千问3-Reranker-0.6B优化升级:调整批处理大小和自定义指令,性能再提升5% 1. 为什么需要优化重排序模型性能? 在信息检索和问答系统中,重排序模型扮演着至关重要的角色。它负责对初步检索得到的文档进行二次排序,…...

如何用3步实现Jable视频高效下载?开源工具jable-download的完整解决方案
如何用3步实现Jable视频高效下载?开源工具jable-download的完整解决方案 【免费下载链接】jable-download 方便下载jable的小工具 项目地址: https://gitcode.com/gh_mirrors/ja/jable-download jable-download是一款专为普通用户设计的Jable视频下载工具&am…...

3.25 复试练习
OJ改错填空strcpy--strcpy(dest, src); // 将src复制到deststrcmp--strcmp(s1, s2);返回值含义0两个字符串相等> 0s1 大于 s2< 0s1 小于 s2矩阵质因数问题描述将一个正整数N(1<N<32768)分解质因数。例如,输入90,打印出902*3*3*5。输入说明输…...

Qwen3-32B-Chat API优化:降低OpenClaw任务Token消耗的5个技巧
Qwen3-32B-Chat API优化:降低OpenClaw任务Token消耗的5个技巧 1. 为什么需要关注Token消耗? 当我第一次在本地部署OpenClaw对接Qwen3-32B-Chat模型时,最让我震惊的不是它的推理能力,而是执行简单自动化任务后Token消耗的速度。一…...

系统焕新:Win11Debloat工具让Windows性能提升51%的全方位优化方案
系统焕新:Win11Debloat工具让Windows性能提升51%的全方位优化方案 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更…...

杰理之人声消除额外保留部分频率声音办法【篇】
将原始声音分为两份,一份走原先的人声消除,另一份走EQ调节 最后输出声音 原先人声消除效果(左-右) EQ调节后声音...

新手指南:掌握3MF格式实现Blender高效3D打印工作流
新手指南:掌握3MF格式实现Blender高效3D打印工作流 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 副标题:从格式解析到自动化处理的完整应用方案…...

Charticulator:数据可视化的自由创作平台与技术革命
Charticulator:数据可视化的自由创作平台与技术革命 【免费下载链接】charticulator Interactive Layout-Aware Construction of Bespoke Charts 项目地址: https://gitcode.com/gh_mirrors/ch/charticulator 当数据分析师面对预设模板无法表达复杂数据关系时…...