从入门到进阶 之 ElasticSearch 文档、分词器 进阶篇
🌹 以上分享 ElasticSearch 文档、分词器 进阶篇,如有问题请指教写。🌹🌹 如你对技术也感兴趣,欢迎交流。🌹🌹🌹 如有需要,请👍点赞💖收藏🐱🏍分享 核心概念
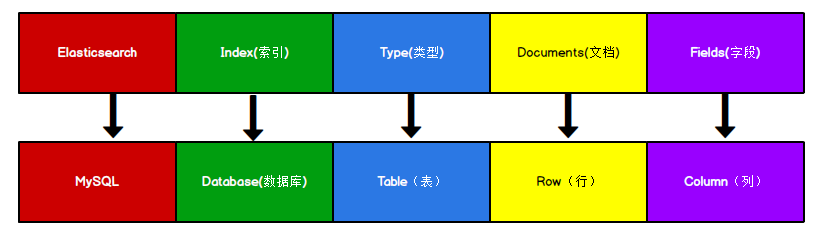 索引
索引
一个拥有几分相似特征的文档的集合。一个索引由一个名字来标识(必须全部是小写字母),对索引文档进行索引、搜索、更新和删除(CRUD)时,使用该索引名。可以定义任意多的索引。
搜索的数据必须索引,可以提高查询速度
Elasticsearch 索引
一切设计都是为了提高搜索的性能。
类型
在一个索引中,你可以定义一种或多种类型。
| 版本 | Type |
|---|---|
| 5.x | 支持多种 type |
| 6.x | 只能有一种 type |
| 7.x | 默认不再支持自定义索引类型(默认类型为: _doc) |
文档
一个文档是一个可被索引的基础信息单元,也就是一条数据。
字段
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
映射
mapping 是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引,都是映射里面可以设置的,按着最优规则处理数据对性能提高很大,建立映射需要思考如何建立映射才能对性能更好。
分片
分片是 Elasticsearch 最小的工作单元。 单个索引可存储超出单个节点硬件限制的大量数据。Elasticsearch 提供了将索引分片划分成多份的能力。当创建一个索引,指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
- 允许水平分割 / 扩展你的内容容量。
- 允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
副本
Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
- 在分片/节点失败的情况下,提供了高可用性。
- 注意到复制分片从不与原/主要(original/primary)分片置于同一节点上。
- 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
分配
将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由 master 节点完成的。
架构

单节点集群
#PUT http://127.0.0.1:1001/goods
{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}
}


故障转移
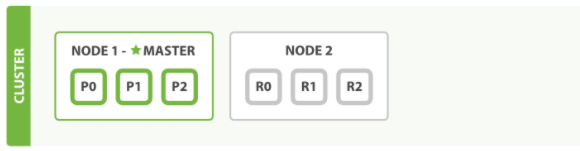
水平扩容



路由计算
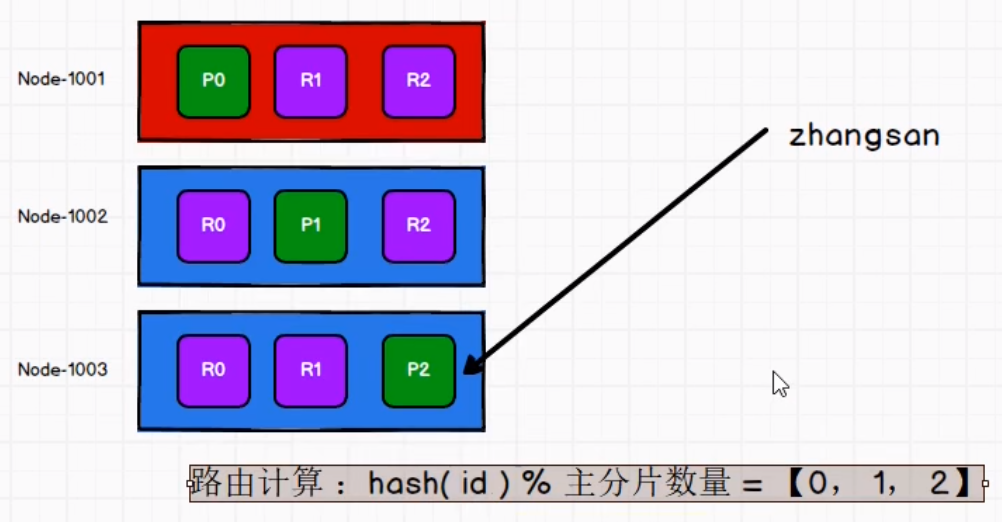
分片控制

数据流程
写

读
 更新
更新
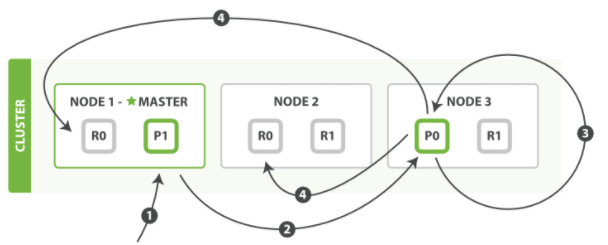
1. 客户端向Node 1 发送更新请求
2. 将请求转发到主分片所在的Node 3上
多文档操作

mget 和 bulk API 的模式类似于单文档模式。
区别在于协调节点知道每个文档存在于哪个分片中。它将整个多文档请求分解成 每个分片 的多文档请求,并且将这些请求并行转发到每个参与节点。
协调节点一旦收到来自每个节点的应答,就将每个节点的响应收集整理成单个响应,返回给客户端
倒排索引
Elasticsearch使用一种称为倒排索引的结构,它适用于快速的全文搜索。
正向索引:就是搜索引擎会将待搜索的文件都对应一个文件ID,搜索时将这个ID和搜索关键字进行对应,形成K-V对,然后对关键字进行统计计数 。
倒排索引:一个倒排索引由文档中所有不重复词的列表构成,用其中的不重复的词跟文档唯一标识关联。(涉及到分词:分词器)
keyword : 不能拆分
text:可拆分(根据分词器的算法进行拆分)

文档操作
文档搜索
倒排索引被写入磁盘后是 不可改变 的:它永远不会修改
不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
一旦索引被读入内核的文件系统缓存,由于其不变性。只要文件系统缓存中还有足够的空间,大部分读请求会直接请求内存,不会命中磁盘。很大的性能提升。
其它缓存(像 filter 缓存),在索引的生命周期内始终有效。不需要在每次数据改变时被重建,因数据不会变化。
写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和 需要被缓存到内存的索引的使用量
动态更新索引
按段搜索
通过增加新的补充索引来反映新近的修改,不直接重写整个倒排索引。每一个倒排索引都会被轮流查询到,从最早的开始查询完后再对结果进行合并。

- 新文档被收集到内存索引缓存
- 不时地, 缓存被提交
- 一个新的段,一个追加的倒排索引,被写入磁盘。
- 一个新的包含新段名字的提交点被写入磁盘。
- 磁盘进行同步,所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件
- 新的段被开启,让它包含的文档可见以被搜索
- 内存缓存被清空,等待接收新的文档

逻辑删除:当一个查询被触发,已知的段按顺序被查询。词项统计会对所有段的结果进行聚合,以保证每个词和每个文档的关联都被准确计算。用相对较低的成本将新文档添加到索引。
段是不可改变的,既不能从把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。每个提交点会包含一个.del 文件,文件中会列出这些被删除文档的段信息。
物理删除:当一个文档被更新时,旧版本文档被标记删除,文档的新版本被索引到一个新的段中。可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除。
刷新、刷写、合并

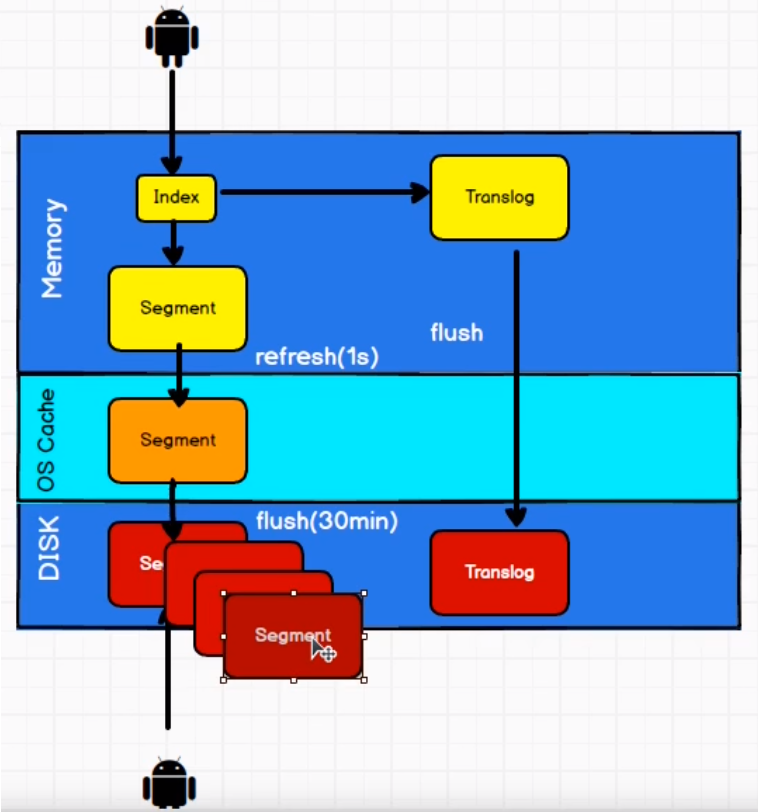
一个文档被索引之后,就会被添加到内存缓冲区,并且追加到了 translog
刷新(refresh)使分片每秒被刷新(refresh)一次
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行fsync操作。
- 这个段被打开,使其可被搜索。
- 内存缓冲区被清空。
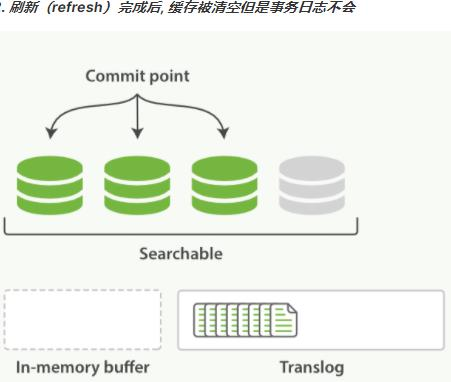
这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志。
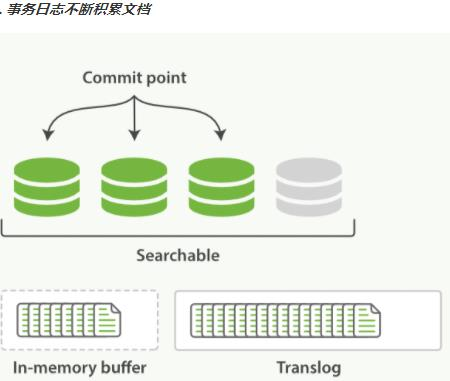
每隔一段时间—例如translog变得越来越大,索引被刷新(flush)
一个新的translog被创建,并且一个全量提交被执行。
-
所有在内存缓冲区的文档都被写入一个新的段。
-
缓冲区被清空。
-
一个提交点被写入硬盘。
-
文件系统缓存通过fsync被刷新(flush) 。
-
老的translog被删除。
translog 提供所有还没有被刷到磁盘的操作的一个持久化纪录。当Elasticsearch启动的时候,它会从磁盘中使用最后一个提交点去恢复己知的段,并且会重放translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时CRUD。通过ID查询、更新、删除一个文档,它会在尝试从相应的段中检索之前,首先检查 translog任何最近的变更。能够实时地获取到文档的最新版本。

分析
- 将一块文本分成适合于倒排索引的独立的 词条
- 将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
分析器
字符过滤器
字符串按顺序通过每个字符过滤器 。在分词前整理字符串。一个字符过滤器可以用来去掉 HTML,或者将 & 转化成 and。
分词器
字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点可能会将文本拆分成词条。
Token 过滤器
词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像 jump和 leap 这种同义词)
内置分析器
标准分析器
标准分析器是 Elasticsearch 默认使用的分析器。它是分析各种语言文本最常用的选择。它根据 Unicode 联盟 定义的 单词边界 划分文本。删除绝大部分标点。将词条小写.
set, the, shape, to, semi, transparent, by, calling, set trans, 5
简单分析器
简单分析器在任何不是字母的地方分隔文本,将词条小写。
set, the, shape, to, semi, transparent, by, calling, set, trans
空格分析器
空格分析器在空格的地方划分文本。
Set, the, shape, to, semi-transparent, by, calling, set trans(5)
语言分析器
特定语言分析器可用于 很多语言。它们可以考虑指定语言的特点。
测试分析器
内置分析器
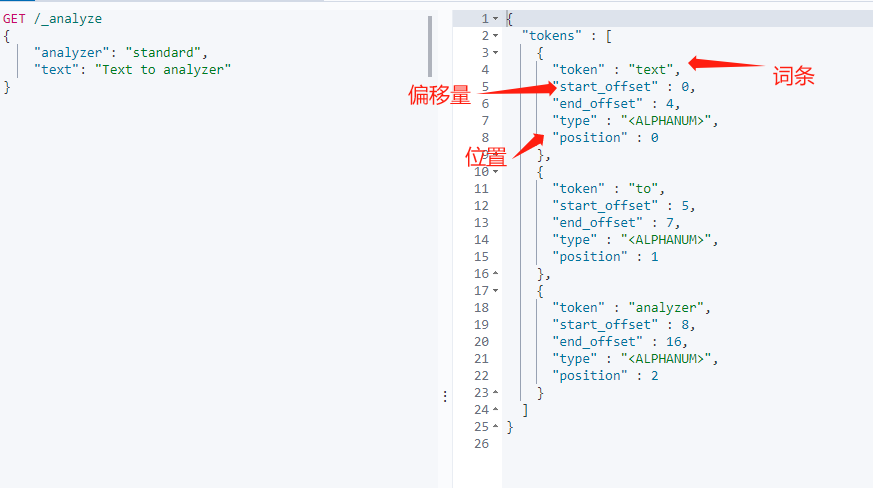 IK 分词器
IK 分词器
# GET http://localhost:9201/_analyze
{"text":"测试单词","analyzer":"ik_max_word"
}{"tokens": [{"token": "测试", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0}, {"token": "单词", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 1}]
}
- 首先进入 ES 根目录中的 plugins 文件夹下的 ik 文件夹,进入 config 目录,创建 custom.dic文件,写入“小老儿最帅”。
- 同时打开 IKAnalyzer.cfg.xml 文件,将新建的 custom.dic 配置其中。
- 重启 ES 服务器 。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">custom.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
自定义分析器
#PUT http://localhost:9200/my_index{"settings": {"analysis": {"char_filter": {"&_to_and": {"type": "mapping", "mappings": ["&=> and "]}}, "filter": {"my_stopwords": {"type": "stop", "stopwords": ["the", "a"]}}, "analyzer": {"my_analyzer": {"type": "custom", "char_filter": ["html_strip", "&_to_and"], "tokenizer": "standard", "filter": ["lowercase", "my_stopwords"]}}}}
}
# GET http://127.0.0.1:9200/my_index/_analyze
{"text":"The quick & brown fox","analyzer": "my_analyzer"
}
文档控制
乐观锁机制:加入version版本号判断
新增数据测试

查询数据

 更新数据
更新数据

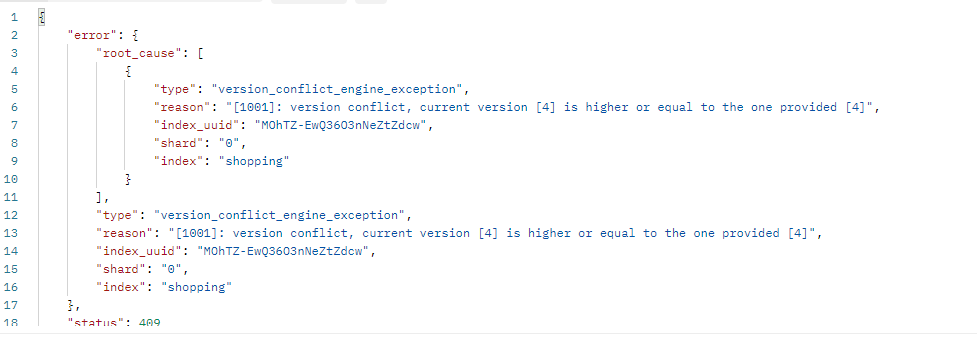
 再次更新时,版本号还是4时提示如下错误,需要将版本号大于当前版本号
再次更新时,版本号还是4时提示如下错误,需要将版本号大于当前版本号
相关文章:
从入门到进阶 之 ElasticSearch 文档、分词器 进阶篇
🌹 以上分享 ElasticSearch 文档、分词器 进阶篇,如有问题请指教写。🌹🌹 如你对技术也感兴趣,欢迎交流。🌹🌹🌹 如有需要,请👍点赞💖收藏&#…...

亚马逊云科技多项新功能与服务,助力各种规模的组织拥抱生成式 AI
从初创企业到大型企业,各种规模的组织都纷纷开始接触生成式 AI 技术。这些企业希望充分利用生成式 AI,将自身在测试版、原型设计以及演示版中的畅想带到现实场景中,实现生产力的大幅提升并大力进行创新。但是,组织要怎样才能在企业…...

网站布局都有哪些?
网站布局是指网页中各元素的布局方式,以下是一些常见的网站布局: 栅格布局:将页面分成一个个小格子,再把内容放到对应的格子中。这种布局有利于提高网页的视觉一致性和用户体验,是网站设计中最常用的布局方式之一。流…...
)
第17章 MQ(一)
17.1 谈谈你对MQ的理解 难度:★ 重点:★★ 白话解析 MQ也要有一跟主线,先理解它是什么,从三个方面去理解就好了:1、概念;2、核心功能;3、分类。 1、概念:MQ(Message Queue),消息队列,是基础数据结构中“先进先出”的一种数据结构。指把要传输的数据(消息)放在队…...
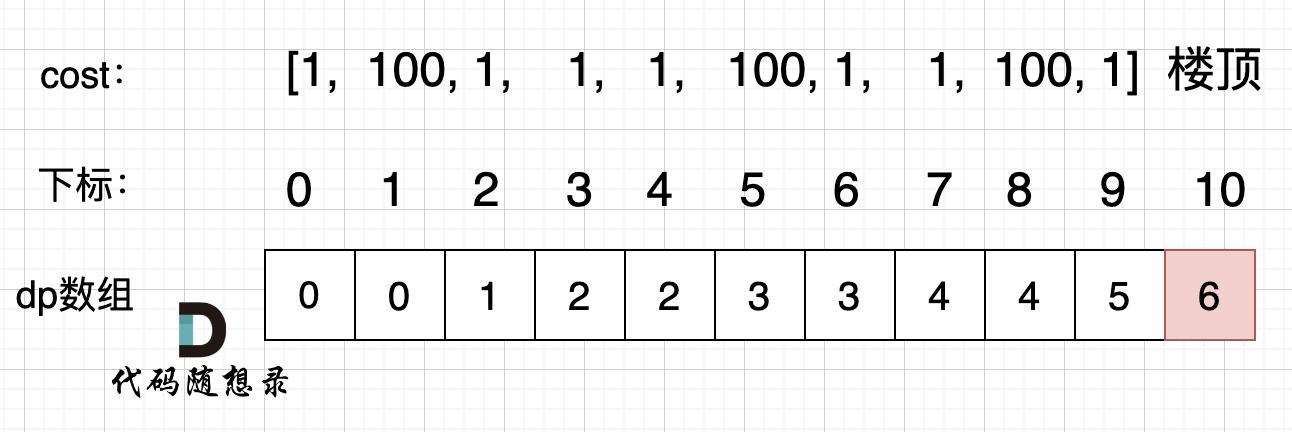
LeetCode算法刷题(python) Day41|09动态规划|理论基础、509. 斐波那契数、70. 爬楼梯、746. 使用最小花费爬楼梯
目录 动规五部曲LeetCode 509. 斐波那契数LeetCode 70. 爬楼梯LeetCode 746. 使用最小花费爬楼梯 动规五部曲 确定dp数组以及下标的含义确定递归公式dp数组如何初始化确定遍历顺序举例推导dp数组 LeetCode 509. 斐波那契数 力扣题目链接 本题最直观是用递归方法 class Sol…...
Spring(四)
1、Spring6整合JUnit 1、JUnit4 User类: package com.songzhishu.spring.bean;import org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Component;/*** BelongsProject: Spring6* BelongsPackage: com.songzhishu.spring.bean*…...
)
2023-10-8讯飞大模型部署2024秋招后端一面(附详解)
1 mybatis的mapper是什么东西 在MyBatis中,mapper是一个核心概念,它起到了桥梁的作用,连接Java对象和数据库之间的数据。具体来说,mapper可以分为以下两个部分: Mapper XML文件: 这是一个XML文件ÿ…...
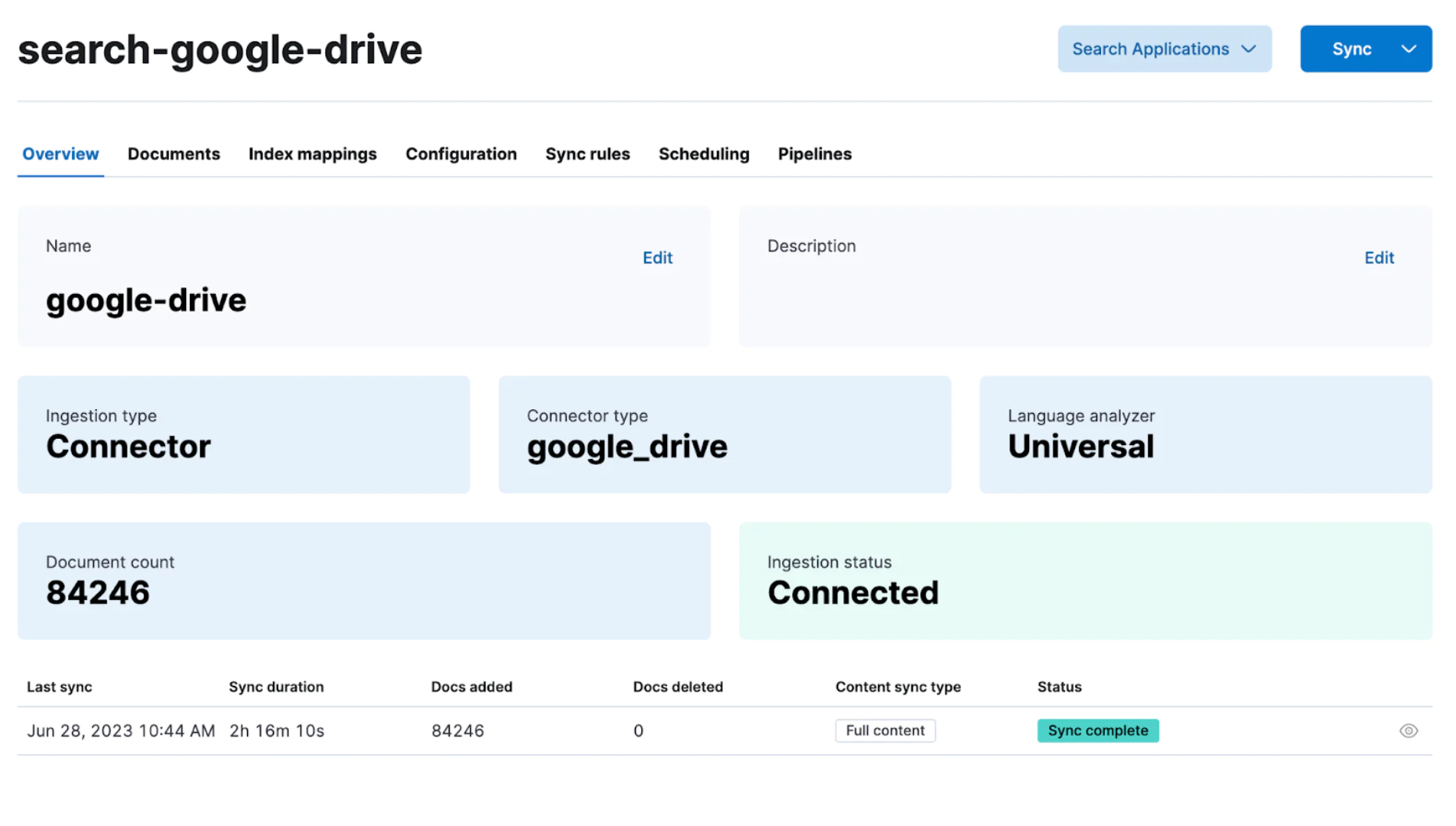
如何为 Elasticsearch 创建自定义连接器
了解如何为 Elasticsearch 创建自定义连接器以简化数据摄取过程。 作者:JEDR BLASZYK Elasticsearch 拥有一个摄取工具库,可以从多个来源获取数据。 但是,有时你的数据源可能与 Elastic 现有的提取工具不兼容。 在这种情况下,你可…...

Debian11 安装 OpenJDK8
1. 下载安装包 wget http://snapshot.debian.org/archive/debian-security/20220210T090326Z/pool/updates/main/o/openjdk-8/openjdk-8-jdk_8u322-b06-1~deb9u1_amd64.deb wget http://snapshot.debian.org/archive/debian-security/20220210T090326Z/pool/updates/main/o/op…...
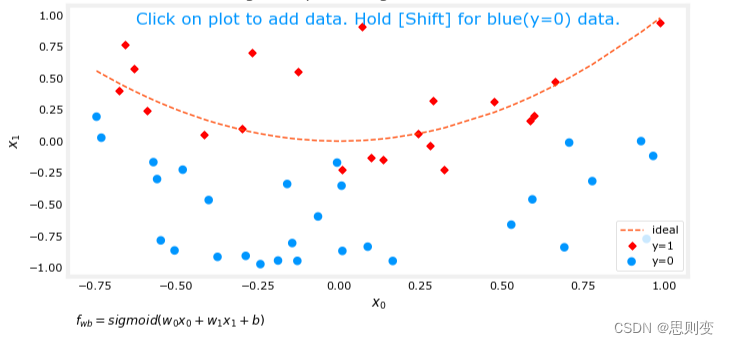
[Machine Learning][Part 6]Cost Function代价函数和梯度正则化
目录 拟合 欠拟合 过拟合 正确的拟合 解决过拟合的方法:正则化 线性回归模型和逻辑回归模型都存在欠拟合和过拟合的情况。 拟合 来自百度的解释: 数据拟合又称曲线拟合,俗称拉曲线,是一种把现有数据透过数学方法来代入一条…...

工业自动化编程与数字图像处理技术
工业自动化编程与数字图像处理技术 编程是计算机领域的基础技能,对于从事软件开发和工程的人来说至关重要。在工业自动化领域,C/C仍然是主流的编程语言,特别是用于工业界面(GUI)编程。工业界面是供车间操作员使用的,使用诸如Hal…...

JY61P.C
/** File Name : JY61P.cDescription : attention © Copyright (c) 2020 STMicroelectronics. All rights reserved.This software component is licensed by ST under Ultimate Liberty licenseSLA0044, the “License”; You may not use this file except in complian…...

Go编程:使用 Colly 库下载Reddit网站的图像
概述 Reddit是一个社交新闻网站,用户可以发布各种主题的内容,包括图片。本文将介绍如何使用Go语言和Colly库编写一个简单的爬虫程序,从Reddit网站上下载指定主题的图片,并保存到本地文件夹中。为了避免被目标网站反爬,…...

高性能日志脱敏组件:已支持 log4j2 和 logback 插件
项目介绍 日志脱敏是常见的安全需求。普通的基于工具类方法的方式,对代码的入侵性太强,编写起来又特别麻烦。 sensitive提供基于注解的方式,并且内置了常见的脱敏方式,便于开发。 同时支持 logback 和 log4j2 等常见的日志脱敏…...

一文读懂PostgreSQL中的索引
前言 索引是加速搜索引擎检索数据的一种特殊表查询。简单地说,索引是一个指向表中数据的指针。一个数据库中的索引与一本书的索引目录是非常相似的。 拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录…...

windows的批量解锁
场景 场景是我从github上拉了一个c#项目启动的时候报错, 1>C:\Program Files\Microsoft Visual Studio\2022\Community\MSBuild\Current\Bin\amd64\Microsoft.Common.CurrentVersion.targets(3327,5): error MSB3821: 无法处理文件 UI\Forms\frmScriptBuilder.…...

Nginx配置微服务避免actuator暴露
微服务一般在扫漏洞的情况下,需要屏蔽actuator健康检查 # 避免actuator暴露 if ($request_uri ~ "/actuator") { return 403; }...

GEE——在GEE中计算地形位置指数TPI
简介: DEM中的TPI计算是指通过计算每个像元高程与其邻域高程的差值来计算地形位置指数(Topographic Position Index)。TPI 是描述地形起伏度和地形形态的一个重要指标,可以用于地貌分类、土壤侵蚀、植被分布等领域。 地形位置指数(Topographic Position Index,TPI)是用…...

树的基本操作(数据结构)
树的创建 //结构结点 typedef struct Node {int data;struct Node *leftchild;struct Node *rightchild; }*Bitree,BitNode;//初始化树 void Create(Bitree &T) {int d;printf("输入结点(按0为空结点):");scanf("%d",&d);if(d!0){T (Bitree)ma…...

Python复刻游戏《贪吃蛇大作战》
入门教程、案例源码、学习资料、读者群 请访问: python666.cn 大家好,欢迎来到 Crossin的编程教室 ! 曾经有一款小游戏刷屏微信朋友圈,叫做《贪吃蛇大作战》。一个简单到不行的游戏,也不知道怎么就火了,还上…...

五大赛道齐亮相!第四届世界科学智能大赛启动报名,首设人文科学赛道
随着人工智能深入科研实践,它不仅在各领域课题的预测、计算等方面屡创新高,也正介入曾被认为高度依赖人类直觉与经验的文化阐释工作。继第四届世界科学智能大赛的创新赛道“AI4S智能体CNS挑战赛”在一个月前率先发布,吹响了自主科研智能体的攻…...
)
[LaTeX] 使用minipage与subfigure实现高效多图排版(附代码型图片处理技巧)
1. 为什么需要minipage和subfigure? 写论文或者技术文档时,经常遇到需要把多张图片并排展示的情况。比如对比实验效果图、不同角度的产品展示、代码片段对比等。传统做法是每张图单独插入,但这样会导致图片间距不一致、对齐困难,最…...

别再只盯着Protobuf了!从DDS到Thrift,聊聊不同IDL在自动驾驶和机器人项目里的真实选型
自动驾驶与机器人系统中的IDL选型实战:从DDS到Thrift的深度解析 在自动驾驶和机器人系统的开发中,接口定义语言(IDL)的选择往往决定了整个通信架构的成败。当激光雷达每秒产生数十万点云数据,当多个传感器需要在毫秒级完成数据融合ÿ…...

微生物网络分析参数配置与结果验证:microeco中SpiecEasi的进阶应用指南
微生物网络分析参数配置与结果验证:microeco中SpiecEasi的进阶应用指南 【免费下载链接】microeco An R package for data analysis in microbial community ecology 项目地址: https://gitcode.com/gh_mirrors/mi/microeco 在微生物生态学研究中,…...

告别锁相误差!基于DSOGI的正负序分离在Simulink中的建模与仿真全攻略
告别锁相误差!基于DSOGI的正负序分离在Simulink中的建模与仿真全攻略 电力电子系统的核心挑战之一,是如何在电网电压不平衡条件下实现精确的相位同步。去年参与某微电网项目时,我们团队曾因传统锁相环在电压跌落时产生的相位抖动损失了关键数…...
)
别再到处找接口了!手把手教你用阿里云盘+Alist搭建自己的TVBox影视仓(附JSON配置模板)
私有影视仓搭建实战:用阿里云盘Alist打造专属TVBox资源库 每次打开TVBox却发现公共接口失效?第三方资源突然无法访问?与其在各大论坛反复搜索不稳定接口,不如用两小时搭建一个完全私有的影视管理系统。本文将彻底改变你获取影音资…...

Phi-4-mini-reasoning vLLM参数详解:context_length=131072配置与性能调优
Phi-4-mini-reasoning vLLM参数详解:context_length131072配置与性能调优 1. 模型概述 Phi-4-mini-reasoning 是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理能力。作为Phi-4模型家族的一员,它特别针对数学推理…...
与 MCP(模型 上下文协议)的本质区别与协同)
大模型开发避坑:彻底理清 Skill(技能)与 MCP(模型 上下文协议)的本质区别与协同
在目前的 AI 应用开发圈子里,各种新名词层出不穷:Skill(技能)、Plugin(插件)、Function Calling(函数调用)、Tool(工具)、MCP(模型上下文协议&…...

替代CM108|替代CM108B|替代HS100|SSS1629代理商|中文说明书|台湾鑫创
SSS1623,SSS1629全面兼容与替代台湾骅讯c-mediaCM108/CM108B/CM108AH/CM118B/CM119/CM119A/HS100/CM6120/CM6317A/CM6400/CM6200等型号, 全面兼容与替代台湾创舰Isoft IS817/IS821/IS828/IS820/IS807等型号,完美替代市面上所有主流USB耳机IC,USB喇叭IC, USB音箱IC, USB游戏耳机…...

告别重复造轮子:用快马AI为qclaw项目封装高效算法模板与优化工具
在量子计算领域,qclaw项目的开发往往需要处理大量重复性工作。每次从零开始编写量子算法不仅耗时耗力,还容易引入人为错误。最近我在开发一个量子化学模拟项目时,发现了一个能显著提升效率的方法——利用InsCode(快马)平台构建可复用的算法模…...