MSQL系列(四) Mysql实战-索引分析Explain命令详解
Mysql实战-索引分析Explain命令详解
前面我们讲解了索引的存储结构,我们知道了B+Tree的索引结构,也了解了索引最左侧匹配原则,到底最左侧匹配原则在我们的项目中有什么用?或者说有什么影响?今天我们来实战操作一下,讲解下如何进行SQL分析及优化
1.联合索引
比如我搜身份证号,查某个人的姓名
- 首先想到的是我新建一个cardId的唯一索引
- 然后我先搜cardId的索引树,找到该cardId对应的主键id
- 然后根据主键id,然后再去主键索引上搜索这个人的姓名
这种查询方式代价是昂贵的,因为他检索了两个B+树,第一个是cardId的索引树,第二个是主键id的索引树,如果树的高度是3,那么两次就是6,去除两次根节点,需要IO检索的就是4次,这就是回表
为了解决主键索引回表查询的问题,尽量不用某个要搜索的列作为索引,这就引出了我们要使用的联合索引
联合索引
就是一个表中,使用多个列来作为索引的方式,也就是说联合索引可以让我们在查询时根据多个列的值来进行筛选
针对上面的搜身份证号,查名字的场景,我们可以创建一个 cardId + name的联合索引, 在查到cardId的同时,就能够取出name的信息,避免回表查询
联合索引有一个最左侧匹配原则
最左匹配原则指的是,当使用联合索引进行查询时,MySQL会优先使用最左边的列进行匹配,然后再依次向右匹配。
假设我们有一个表,包含三个列:A、B、C
- 我们使用(A,B,C)这个联合索引进行查询时,MySQL会先根据列A进行匹配
- 再根据列B进行匹配,最后再根据列C进行匹配。
- 如果我们只查询了(A,B)这两个列,而没有查询列C,那么MySQL只会使用(A,B)这个前缀来进行索引匹配,而不会使用到列C
- 如果我们要查询 了(B,C)这两个列,而没有查询列A,那么MySQL索引就会失效,导致找不到索引,因为最左侧匹配原理
- 所以 我们应该尽量把最常用的列放在联合索引的最左边,这样可以提高查询效率
2.实战
新建表结构 user, user_info
#新建表结构 user
CREATE TABLE `user` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',`id_card` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '身份证ID',`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户名字',`age` int NOT NULL COMMENT '年龄',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'#创建另一个测试表,用于连表结构
CREATE TABLE `user_info` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',`user_id` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户ID',`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户ID',`age` int NOT NULL COMMENT '年龄',`address` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '地址',`order_ids` json DEFAULT NULL COMMENT '用户id的json数组',`goods` json DEFAULT NULL COMMENT '用户商品信息 商品对象',`sort_order` int DEFAULT '0' COMMENT '排序字段',`is_del` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否删除',`is_del2` tinyint NOT NULL COMMENT '测试',`addtime` bigint NOT NULL DEFAULT '0' COMMENT '创建时间',`modtime` bigint NOT NULL DEFAULT '0' COMMENT '修改时间',PRIMARY KEY (`id`),KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=24 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'- id 主键id列
- id_card 身份证id
- user_name 用户姓名
- age 年龄
先插入测试数据, 插入 5条测试数据
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (1, '11', 'aa', 10);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (2, '22', 'bb', 20);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (3, '33', 'cc', 30);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (4, '44', 'dd', 40);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (5, '55', 'ee', 50);
2.1 创建 id_card,user_name,age的索引列
alter table user add index idx_card_name_age(id_card,user_name,age);
创建索引成功
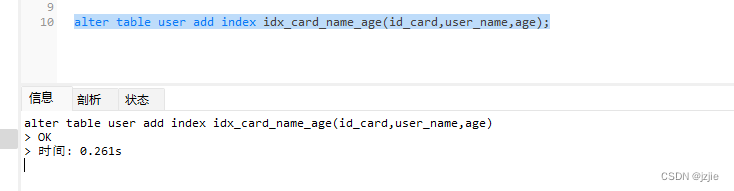
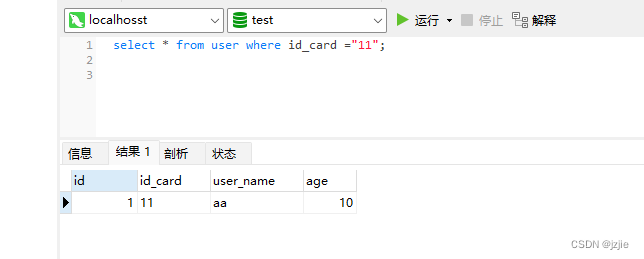
执行语句 ,可以看到 数据存在于表中,我们查询的是id_card,现在我们来分析下这条查询语句
select * from user where id_card ="11";
3 explain 分析SQL语句
分析上面的查询语句
EXPLAIN SELECT * FROM `user` where id_card = "11";
可以看到执行结果
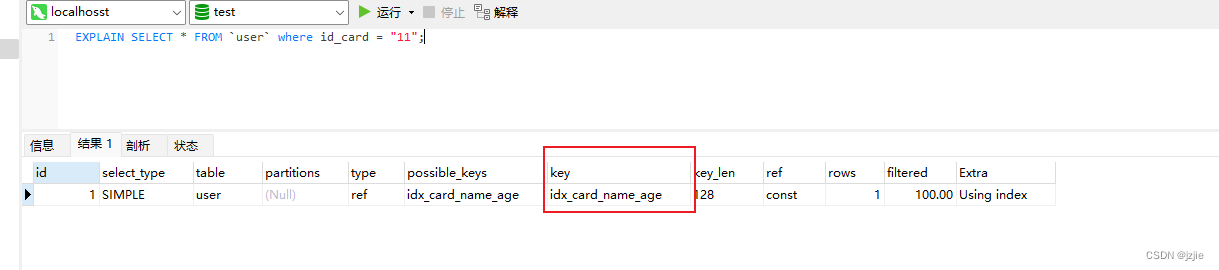
下面我们一 一讲解下这部分结果代表的含义
我先来介绍下图3中sql在expalin执行计划后得一些参数
| 列名 | 含义 |
|---|---|
| id | 选择标识符 |
| select_type | 表示查询的类型,SIMPLE表示简单的select,没有union和子查询。 还有一些 比如 UNION 表示第二个SELECT语句 或者PRIMARY 表示最外层 select 等等 |
| table | 查询sql的表名 |
| partitions | 匹配的分区 |
| type | 连接类型, 重点,重点,重点 如果要有优化sql,一般都是看这个标识 |
| key | 实际选择的索引 |
| key_len | 所选密钥的长度 |
| ref | 显示哪些列或常量与key列中命名的索引进行比较,以便从表中选择行。 |
| rows | 扫描行 表示MySQL认为必须检查才能执行查询的行数 |
| filtered | 过滤的百分比,越高说明过滤的越多,命中率越高 |
| extra | 其他信息,重要,重要,重要,告诉你是否使用了临时表?是否使用内存排序等等,都是优化点 |
我们来着重讲下Explain的用法及如何优化SQL
3.1 select_type 查询类型
select_type表示查询类型,主要分为一下几种
- SIMPLE 简单的select查询
- 查询中不包含子查询或者UNION,上面我们查询的EXPLAIN SELECT * FROM
userwhere id_card = “11”; 不包含任何子查询就是简单类型查询
- 查询中不包含子查询或者UNION,上面我们查询的EXPLAIN SELECT * FROM
- PRIMARY 查询中若包含任何复杂的子查询,最外层查询标记为该标识
- 比如我们查询 explain SELECT * FROM user WHERE user_name IN (SELECT user_name FROM user_info) or user_name=“1”; 外层是 复杂查询,嵌套子查询, 外层查询就是PRIMARY,内层子查询就是SUBQUERY

- 比如我们查询 explain SELECT * FROM user WHERE user_name IN (SELECT user_name FROM user_info) or user_name=“1”; 外层是 复杂查询,嵌套子查询, 外层查询就是PRIMARY,内层子查询就是SUBQUERY
- SUBQUERY 在SELECT 或 WHERE 列表中包含了子查询
- 这个SUBQUERY我们在PRIMARY中已经将结果,就是内层的子查询
- DERIVED 在FROM 列表中包含的子查询
- UNION 若第二个SELECT出现在UNION之后,则标记为UNION ; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为 : DERIVED
- UNION RESULT 从UNION表获取结果的SELECT
- UNION,UNION RESULT都是联合查询才会出现的,比如 EXPLAIN SELECT user_name FROM user UNION SELECT user_name FROM user_info; 就出现了这两种类型 -

- UNION,UNION RESULT都是联合查询才会出现的,比如 EXPLAIN SELECT user_name FROM user UNION SELECT user_name FROM user_info; 就出现了这两种类型 -
3.2 type 表示连接类型
type 又称访问类型 或者连接类型,即这里的type
比如,type是ref,表名mysql将使用ref方法对改行记录的表进行查询。type字段有着完整的效率高低关系,如下:
null> system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > all,越靠前代表效率越高
我们来看下这几种分别代表什么
- null 表示当前的查询语句不需要访问表,我们直接从索引中就可以取出数据,效率最高
- 比如 explain select id from user where id is null; 我们要查id, where 语句 id is null, 所以他不用查询mysql表,直接通过语句就可以执行处结果,这种type就是null

- 比如 explain select id from user where id is null; 我们要查id, where 语句 id is null, 所以他不用查询mysql表,直接通过语句就可以执行处结果,这种type就是null
- system/const 当表中只有1条记录匹配时,那么时 system/const,效率很高
- 比如 explain select * from user where id =1;根据主键id只能找到1条记录, type就是const

- 比如 explain select * from user where id =1;根据主键id只能找到1条记录, type就是const
- eq_ref 表示唯一索引,对于连接的表结构,如果是主表和附表通过唯一索引进行联合匹配,那么附表的访问方式就是 eq_ref
- 比如访问2个表结构, user表 存在唯一索引 user_name, 附表 user_info 只有主键id索引,没有其他索引字段,现在 连接两个表进行访问

- 我们来看下访问结果, user表,有唯一索引字段user_name的走的就是eq_ref连接索引,但是user_info附表,没有索引字段,走的时全表扫描ALL
- EXPLAIN SELECT * from user INNER JOIN user_info WHERE user.user_name = user_info.user_name;

- 比如访问2个表结构, user表 存在唯一索引 user_name, 附表 user_info 只有主键id索引,没有其他索引字段,现在 连接两个表进行访问
- ref 就是非唯一性索引扫描,很实用的正常索引,也就是我们平时用到的最多的
- 我们的user表中有个age的Normal索引,现在对age进行查询搜索,返回匹配age的行,就是最普通的查询请求

- explain select * from user where age=10;

- 我们的user表中有个age的Normal索引,现在对age进行查询搜索,返回匹配age的行,就是最普通的查询请求
- range 表示使用了范围查找 ,where 之后出现 between , < , > , in 等操作。
- index 表示遍历了整个索引树,比ALL强一丢丢,但是也是不行的
- ALL别说了,扫描全表,来匹配需要的数据
从 ref后面的,我们就不详细介绍了,因为一旦出现这些就是你的SQL有问题,就需要优化SQL
3.3 possible_key 和 key
possible_key : 表示这次查询中可能会用到的索引,一般有些字段会创建多个索引,但是本次查询如果涉及到了该字段,那么possible_key中就会出现,只表示 本次可能会用到这个索引,但是真正用到的是不是它,不一定
key: 表示经过查询优化器计算使用不同索引的查询成本之后,最终确定使用的索引
比如 explain select * from user where age=10;
user 表中存在联合索引 idx_card_name_age,又存在唯一索引 indx_age,当查询age=xx的时候,都会涉及到该字段的索引,所以 possible_key :idx_card_name_age,idx_age
真正使用索引key: idx_age

3.4 key_len 表示索引长度
key_ken 表示 实际使用到的索引的长度(即字节数),用来查看是否充分利用了索引,key_len的值越大越好,因为主要是针对的联合索引,因为利用联合索引的长度越大,查询需要读入的数据页就越少,效率也就越高
我们上面 执行 explain select * from user where user_name=“aa”;, 可以看到 key_len长度到达128
3.5 rows 表示扫描行,filtered表示过滤后剩余记录的百分比
rows表示这次SQL查询 扫描的行数,值越小越好,值越小,说明扫描很少行,就找到了数据,效率越高
我们上面 执行 explain select * from user where user_name=“aa”;, rows=1,表示一行就找到了要查询的数据
filtered 表示某个表经过条件过滤之后,剩余记录条数的百分比,值越大越好, 100%表示过滤后100%全都是符合要求的
3.6 extra 表示其他信息,很重要
extra表示 其他的额外的执行计划信息,这里面如果出现了 using filesort和 using temporary表示SQL使用了内存排序及使用了临时表,效率一般都不太行,需要优化
- using filesort
这条语句执行会对数据使用外部的索引排序,而不是按照表内的索引顺序进行读取,表示该SQL无法利用索引完成的排序操作, 称为 “文件排序”, 效率低下,需要优化 - using temporary
这条语句执行会使用了临时表保存中间结果,常见于使用 order by 和 group by;效率低下,需要优化
- using index
表示相应的select操作使用了覆盖索引, 直接从索引中过滤掉不需要的结果,无需回表, 效率不错。
- using index condition
查找使用了索引,但是需要回表查询数据,因为索引列的字段不全,没有完全包含查询列,需要回表操作查询其他字段,效率不错
至此,我们从最左侧匹配引入了Explain的SQL分析,并且指明了如何分析SQL,如何对SQL进行优化,下一篇,我们主要来实践一下 最左侧匹配原则
相关文章:
MSQL系列(四) Mysql实战-索引分析Explain命令详解
Mysql实战-索引分析Explain命令详解 前面我们讲解了索引的存储结构,我们知道了BTree的索引结构,也了解了索引最左侧匹配原则,到底最左侧匹配原则在我们的项目中有什么用?或者说有什么影响?今天我们来实战操作一下&…...
FPGA软件【紫光】
软件:编程软件。 注册账号需要用到企业邮箱 可以使用【企业微信】的邮箱 注册需要2~3天,会收到激活邮件 授权: 找到笔记本网卡的MAC, 软件授权选择ADS 提交申请后,需要2~3天等待邮件通知。 使用授权: 文…...
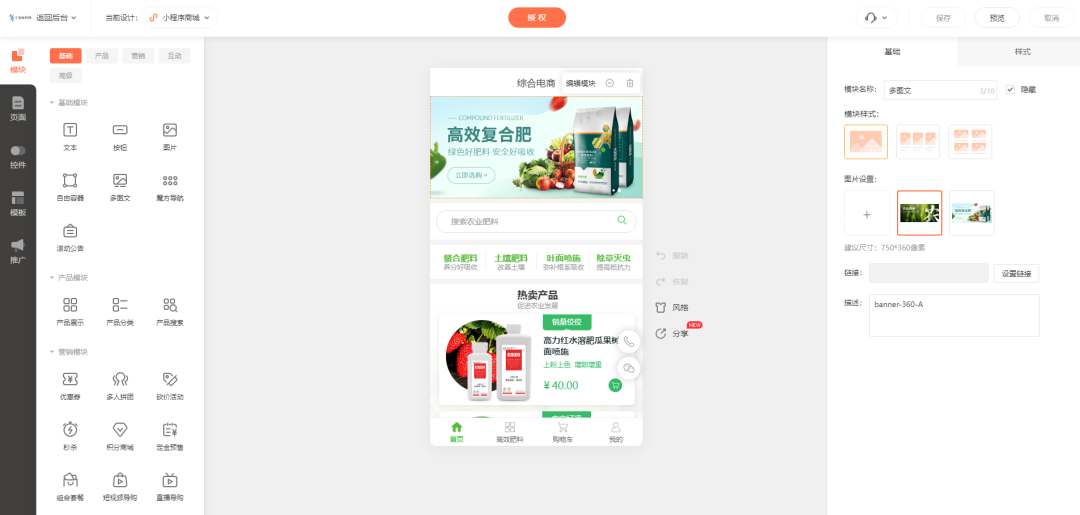
饲料化肥经营商城小程序的作用是什么
我国农牧业规模非常高,各种农作物和养殖物种类多,市场呈现大好趋势,随着近些年科学生产养殖逐渐深入到底层,专业的肥料及饲料是不少从业者需要的,无论城市还是农村都有不少经销店。 但在实际经营中,经营商…...
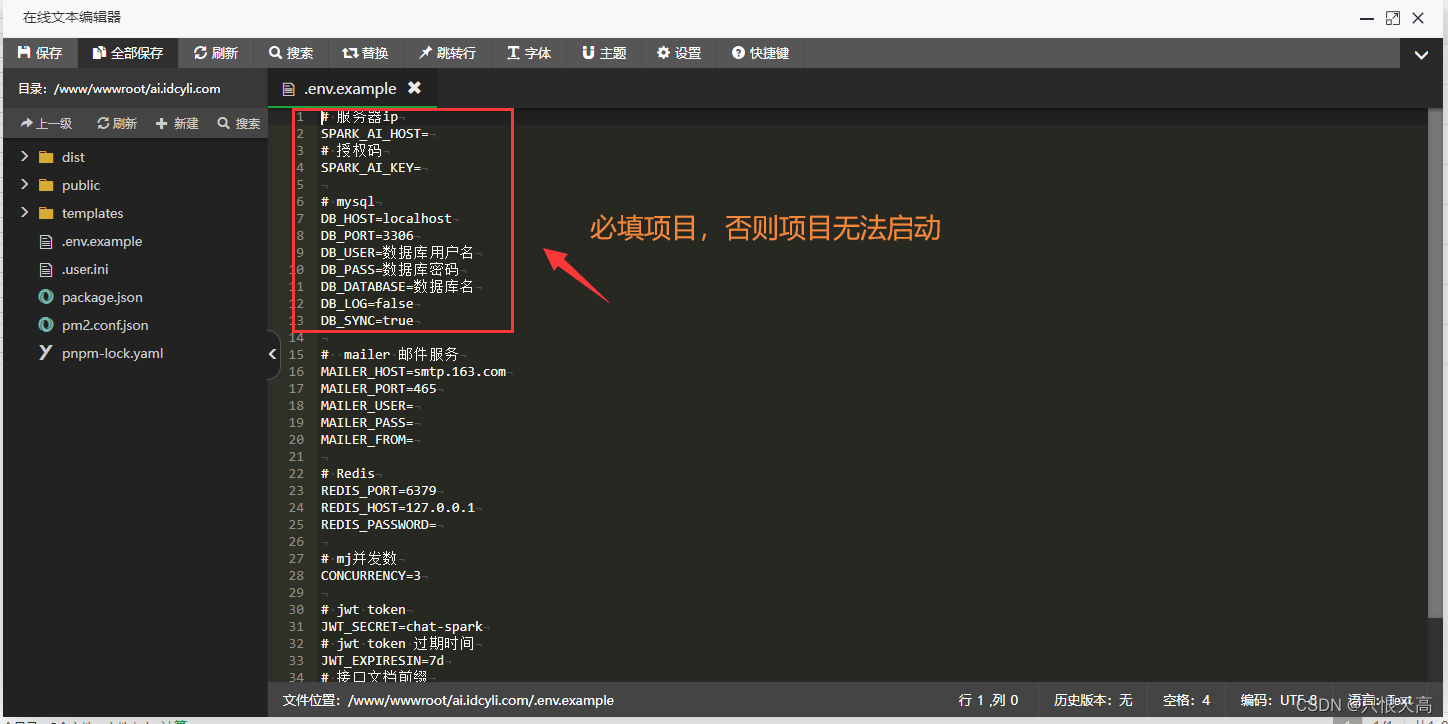
AI系统ChatGPT源码+详细搭建部署教程+支持GPT4.0+支持ai绘画(Midjourney)/支持OpenAI GPT全模型+国内AI全模型
一、AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统AI绘画系统,支持OpenAI GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署…...

vue项目优雅降级,es6降为es5,适应低版本浏览器渲染
非vue项目 ECMAScript 6(ES6)的发展速度非常之快,但现代浏览器对ES6新特性支持度不高,所以要想在浏览器中直接使用ES6的新特性就得借助别的工具来实现。 Babel是一个广泛使用的转码器,babel可以将ES6代码完美地转换为ES5代码,所…...
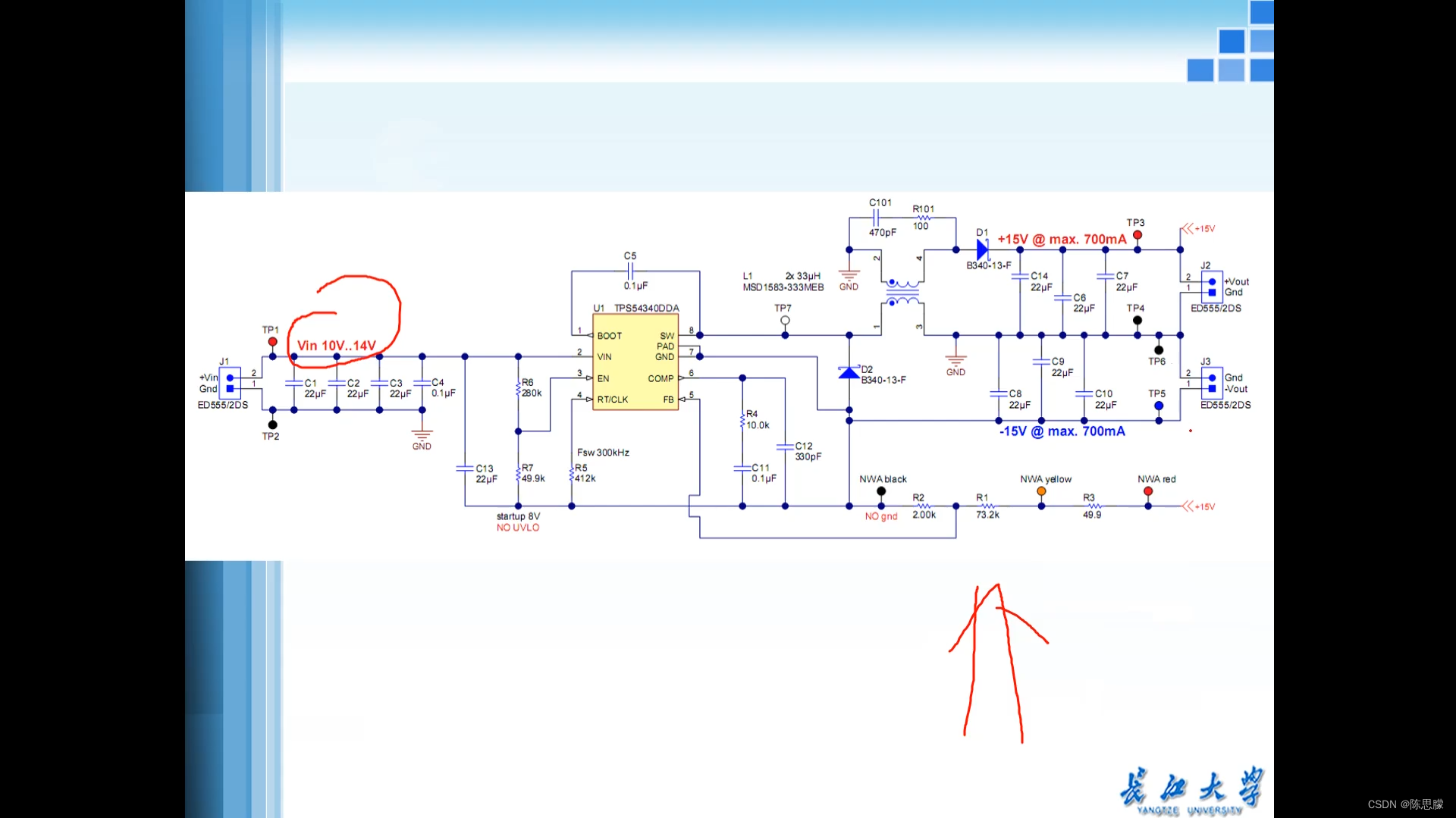
运放供电设计
文章目录 运放供电设计如何产生负电压BUCK电路BOOST电路产生负电压FLYBUCK产生负电压 运放供电设计 注:使用0.1u跟10u并联 如何产生负电压 问题:电流小,使用并联方式改善,缺点价格贵,淘宝上买的都是假货ICL7662多是用…...
vue2-org-tree 树型结构的使用
vue2-org-tree 用于创建和显示组织结构树状图,帮助开发者轻松地可视化组织结构,例如公司的层级、部门之间的关系、团队成员等。其主要功能有:自定义节点、可折叠节点、支持拖放、搜索、导航等功能。 这里我们主要使用 vue2-org-tree 进行多次…...
路由器与交换机的比较)
【计算机网络】(面试问题)路由器与交换机的比较
路由器与交换机比较 内容主要参考总结自《计算机网络自顶向下第七版》P315 两者均为存储-转发设备: 路由器: 网络层设备 (检测网络层分组首部) 交换机: 链路层设备 (检测链路层帧的首部) 二者均使用转发表: 路由器: 利用路由算法(路由协议)计算(设置), 依据IP地址 交换机…...
基于下垂控制的孤岛双机并联逆变器环流抑制模型(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

第十九章 文件操作
程序运行时产生的数据都属于临时数据,程序一旦运行结束都会被释放 通过文件可以将数据持久化 C中对文件操作需要包含头文件 < fstream > 文件类型分为两种: 文本文件 - 文件以文本的ASCII码形式存储在计算机中 二进制文件 - 文件以文本的二进制…...

防火墙管理工具增强网络防火墙防御
防火墙在网络安全中起着至关重要的作用。现代企业具有多个防火墙,如:电路级防火墙、应用级防火墙和高级下一代防火墙(NGFW)的复杂网络架构需要自动化防火墙管理和集中式防火墙监控工具来确保边界级别的安全。 网络防火墙安全和日…...

34 机器学习(二):数据准备|knn
文章目录 数据准备数据下载数据切割转换器估计器 kNN正常的流程网格多折交叉训练原理讲解距离度量欧式距离(Euclidean Distance)曼哈顿距离(Manhattan Distance)切比雪夫距离 (Chebyshev Distance)还有一些自定义的距离 就请读者自行研究 再识K-近邻算法API选择n邻居的思辨总结…...

企业工厂车间台式电脑经常有静电导致开不开机,如何彻底解决?
环境: HP 480G7 Win10 专业版 问题描述: 企业工厂车间台式电脑经常有静电导致开不开机,如何彻底解决? 开机电源指示灯闪,显示器黑屏没有画面开不了机,一般是把主机电源断了,把主机盖打开 把内存条拔了之后长按开机按键10秒以上然后插上内存条开机正常 相对与有些岗…...

【数之道 05】走进神经网络模型、机器学习的世界
神经网络 神经网络(ANN)神经网络基础激活函数 神经网络如何通过训练提高预测准确度逆向参数调整法 (BackPropagation)梯度下降法链式法则增加一层 b站视频连接 神经网络(ANN) 最简单的例子,视…...
笔记——基本类型)
C现代方法(第7章)笔记——基本类型
文章目录 第7章 基本类型7.1 整数类型7.1.1 C99中的整数类型7.1.2 整型常量7.1.3 C99中的整型常量7.1.4 整数溢出7.1.5 读/写整数 7.2 浮点类型7.2.1 浮点常量7.2.2 读/写浮点数 7.3 字符类型7.3.1 字符操作7.3.2 有符号字符和无符号字符7.3.3 算术类型7.3.4 转义序列7.3.5 字符…...

ON DUPLICATE KEY UPDATE 导致自增ID跳跃式增长
1. 语法 INSERT INTO table_name VALUES(null,param,..) ON DUPLICATE KEY UPDATE param_name VALUES(param_name);2. 介绍 ON DUPLICATE KEY UPDATE 会根据主键或唯一索引检索当前记录是否已经存在,存在更新,不存在插入; 优先级ÿ…...

python学习笔记5-堆
题目链接 heapify(q) 初始化一个列表q成为小根堆这道题取反使之成为大根堆heappop(q) 弹出堆顶heappush(q, e) 将e插入堆中 class Solution:def maxKelements(self, nums: List[int], k: int) -> int:q [-x for x in nums]heapify(q)ans 0for _ in range(k):x heappop(…...
【微服务 SpringCloud】实用篇 · Eureka注册中心
微服务(3) 文章目录 微服务(3)1. Eureka的结构和作用2. 搭建eureka-server2.1 创建eureka-server服务2.2 引入eureka依赖2.3 编写启动类2.4 编写配置文件2.5 启动服务 3. 服务注册1)引入依赖2)配置文件3&am…...
WebSocket学习笔记
一篇文章理解WebSocket原理 1.HTTP协议(半双工通信): HTTP是客户端向服务器发起请求,服务器返回响应给客户端的一种模式。 特点: 1.只能是客户端向服务器发起请求,是单向的。 2.服务器不能主动发送数据给客户端。 半双工通信…...
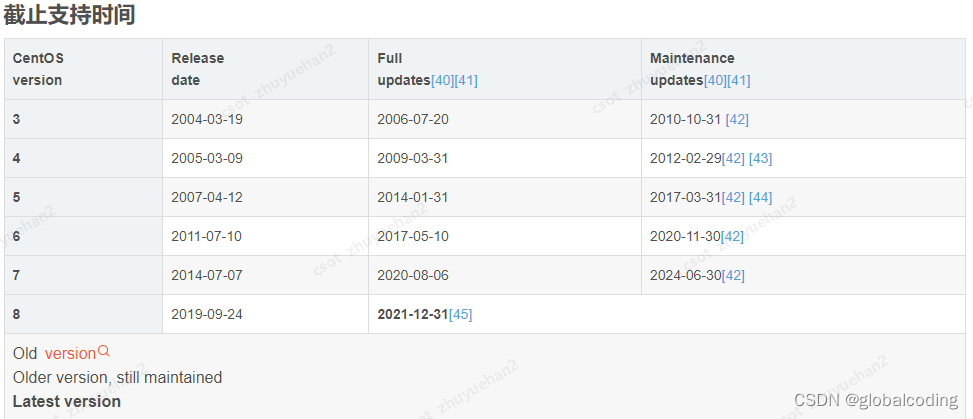
centos 内核对应列表 内核升级 linux
近期服务器频繁出现问题,找运维同事排查,说是系统版本和内核版本和官方不一致,如下: Release 用的是7.8, kernal 用的是 5.9 我一查确实如此: 内核: Linux a1messrv1 5.9.8-1.el7.elrepo.x86_64 发行版 Cen…...

技术解析 | 【ECCV2022】MuLUT:多级查找表协同优化在图像超分中的高效实践
1. MuLUT技术背景与核心价值 图像超分辨率(Super-Resolution)技术一直是计算机视觉领域的热门研究方向,简单来说就是让低分辨率图像变清晰的过程。传统基于卷积神经网络(CNN)的方法虽然效果不错,但计算量大…...
)
Python原生AOT编译实战指南(2026 LTS版正式启用倒计时)
第一章:Python原生AOT编译的演进脉络与2026 LTS战略意义Python长期以来以解释执行和字节码(.pyc)为核心运行范式,而原生AOT(Ahead-of-Time)编译的探索始于2010年代中期的Nuitka、Cython等工具,但…...
)
EcomGPT-7B镜像免配置实操:Docker Compose一键编排(含Redis缓存服务)
EcomGPT-7B镜像免配置实操:Docker Compose一键编排(含Redis缓存服务) 你是不是也遇到过这样的烦恼?想试试最新的AI电商大模型,结果光是环境配置就折腾了大半天。各种Python版本、PyTorch版本、依赖库冲突,…...

QMK Toolbox终极指南:从零开始掌握键盘固件刷写的完整教程
QMK Toolbox终极指南:从零开始掌握键盘固件刷写的完整教程 【免费下载链接】qmk_toolbox A Toolbox companion for QMK Firmware 项目地址: https://gitcode.com/gh_mirrors/qm/qmk_toolbox QMK Toolbox是机械键盘爱好者的必备神器,这款开源工具集…...

Ubuntu 20.04 下 LVI-SAM 复现全记录:从 gtsam 版本踩坑到 OpenCV 头文件修改
Ubuntu 20.04 下 LVI-SAM 复现实战:从 gtsam 版本适配到 OpenCV 接口升级全解析 在机器人感知与定位领域,LVI-SAM 作为融合激光雷达与视觉信息的 SLAM 系统,因其优异的实时性和鲁棒性备受关注。然而其复杂的依赖环境配置常常让开发者陷入&quo…...

测试右移的复仇:上线后bug如何让公司赔光融资
当质量防线在“最后一公里”失守在软件交付的终点线前,测试团队常被一种“虚假的安全感”所笼罩。测试环境用例全绿,性能压测数据达标,验收报告签字盖章,一切似乎都指向一个平稳的上线。然而,当代码被部署到生产环境&a…...

LangFlow问题解决:常见部署错误与连接Ollama配置详解
LangFlow问题解决:常见部署错误与连接Ollama配置详解 如果你正在尝试用LangFlow搭建自己的AI应用工作流,但卡在了部署和配置环节,这篇文章就是为你准备的。LangFlow作为一款低代码的可视化工具,理论上能让构建LangChain流水线变得…...
)
DOMPurify实战:如何在Node.js后端安全处理用户HTML输入(附最新jsdom配置)
DOMPurify实战:如何在Node.js后端安全处理用户HTML输入(附最新jsdom配置) 当用户提交的HTML内容直接进入数据库时,就像给黑客开了扇后门。去年某知名博客平台因未过滤富文本评论,导致攻击者通过精心构造的<img srcx…...
)
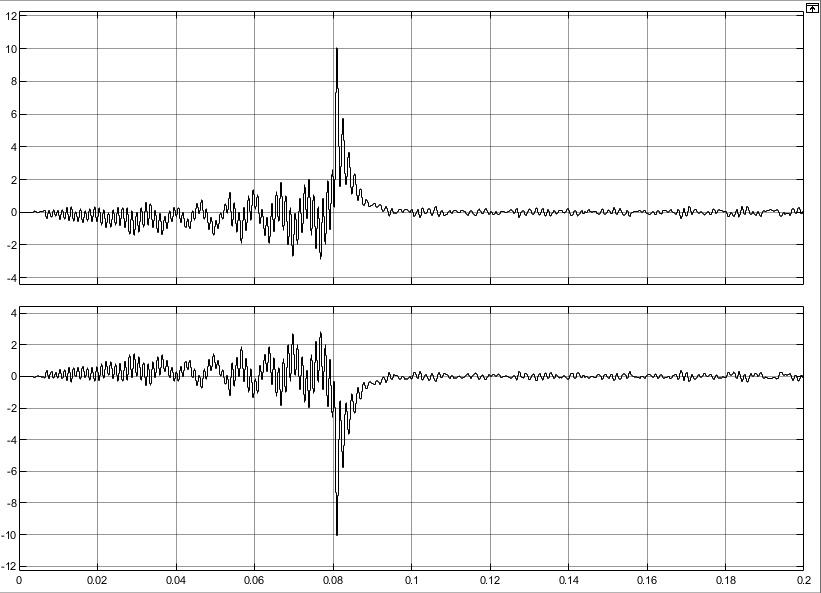
从移动平均到IIR滤波:用Matlab filter函数实现数据降噪的完整指南(附对比实验)
从移动平均到IIR滤波:用Matlab filter函数实现数据降噪的完整指南(附对比实验) 在数据分析与信号处理领域,噪声污染是影响结果准确性的常见挑战。无论是来自传感器的物理干扰,还是数据传输过程中的随机波动,…...

5分钟上手MouseClick:让重复点击自动化的3个核心技巧
5分钟上手MouseClick:让重复点击自动化的3个核心技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操…...