网络库OKHTTP(2)面试题
序、慢慢来才是最快的方法。
背景
OkHttp 是一套处理 HTTP 网络请求的依赖库,由 Square 公司设计研发并开源,目前可以在 Java 和 Kotlin 中使用。对于 Android App 来说,OkHttp 现在几乎已经占据了所有的网络请求操作。
OKHttp源码官网

问1:OKHttp有哪些拦截器,分别起什么作用
必考题,头两年没考,今年必考。
OKHTTP的拦截器是把所有的拦截器放到一个list里,然后每次依次执行拦截器,并且在每个拦截器分成三部分:
- 预处理拦截器内容
- 通过
proceed方法把请求交给下一个拦截器- 下一个拦截器处理完成并返回,后续处理工作。
这样依次下去就形成了一个链式调用,看看源码,具体有哪些拦截器:
getResponseWithInterceptorChain()
@Throws(IOException::class)internal fun getResponseWithInterceptorChain(): Response {// Build a full stack of interceptors.val interceptors = mutableListOf<Interceptor>()interceptors += client.interceptorsinterceptors += RetryAndFollowUpInterceptor(client)interceptors += BridgeInterceptor(client.cookieJar)interceptors += CacheInterceptor(client.cache)interceptors += ConnectInterceptorif (!forWebSocket) {interceptors += client.networkInterceptors}interceptors += CallServerInterceptor(forWebSocket)val chain = RealInterceptorChain(call = this,interceptors = interceptors,index = 0,exchange = null,request = originalRequest,connectTimeoutMillis = client.connectTimeoutMillis,readTimeoutMillis = client.readTimeoutMillis,writeTimeoutMillis = client.writeTimeoutMillis)var calledNoMoreExchanges = falsetry {val response = chain.proceed(originalRequest)if (isCanceled()) {response.closeQuietly()throw IOException("Canceled")}return response} catch (e: IOException) {calledNoMoreExchanges = truethrow noMoreExchanges(e) as Throwable} finally {if (!calledNoMoreExchanges) {noMoreExchanges(null)}}}
根据源码可知,一共七个拦截器:
addInterceptor(Interceptor),这是由开发者设置的,会按照开发者的要求,在所有的拦截器处理之前进行最早的拦截处理,比如一些公共参数,Header都可以在这里添加。RetryAndFollowUpInterceptor,这里会对连接做一些初始化工作,以及请求失败的充实工作,重定向的后续请求工作。跟他的名字一样,就是做重试工作还有一些连接跟踪工作。BridgeInterceptor,这里会为用户构建一个能够进行网络访问的请求,同时后续工作将网络请求回来的响应Response转化为用户可用的Response,比如添加文件类型,content-length计算添加,gzip解包。CacheInterceptor,这里主要是处理cache相关处理,会根据OkHttpClient对象的配置以及缓存策略对请求值进行缓存,而且如果本地有了可⽤的Cache,就可以在没有网络交互的情况下就返回缓存结果。ConnectInterceptor,这里主要就是负责建立连接了,会建立TCP连接或者TLS连接,以及负责编码解码的HttpCodecnetworkInterceptors,这里也是开发者自己设置的,所以本质上和第一个拦截器差不多,但是由于位置不同,所以用处也不同。这个位置添加的拦截器可以看到请求和响应的数据了,所以可以做一些网络调试。CallServerInterceptor,这里就是进行网络数据的请求和响应了,也就是实际的网络I/O操作,通过socket读写数据。
问2:OKHttp请求的流程?
我们知道Okhttp中通过okhttpClient对象是通过Builder对象初始化出来的,此处Builder的用法是建造者模式,建造者模式主要是分离出外部类的属性初始化,而初始化属性交给了内部类Buidler类,这么做的好处是外部类不用关心属性的初始化。 而在初始化的时候有
interceptors、networkInterceptors两种拦截器的初始化,还有dispatcher(分发器)的初始化,以及后面需要讲到的cache(缓存)初始化等。
初始化完了后通过builder的build方法构造出
okhttpClient对象,该类被称作客户端类,通过它的newCall方法返回RealCall对象,在newCall过程的过程中需要request的信息,request信息包装了url、method、headers、body等信息。最后通过RealCall的同步或异步方法交给了okhttpClient的dispatcher来处理,在处理同步或异步之前都会判断有没有正在executed,所以我们不能对同一个RealCall调用异步或同步方法。
在异步的时候会把RealCall给包装成一个
AsyncCall,它是一个runnable对象。接着就来到了分发器异步处理部分,首先会把AsyncCall加入到readyAsyncCalls的集合中,该集合表示准备阶段的请求集合,紧接着从runningAsyncCalls(该集合装的都是要即将请求的集合)和readyAsyncCalls集合中找相同host的AsyncCall,如果找到了会把当中记录的相同host的个数给该AsyncCall。注意这里保存host个数用的原子性的AtomicInteger来记录的
接着会去判断最大的请求是否大于64以及相同host是否大于5个,这里也是okhttp面试高频知识点,如果都通过的话,会把当前的
AsyncCall的相同host记录数加一,接着会加入到runningAsyncCalls集合中,接着循环遍历刚符合条件的AsyncCall,通过线程池去执行AsyncCall,注意此处的线程池的配置是没有核心线程,总的线程个数是没有限制的,也就是说都是非核心线程,并且个数没有限制,非核心线程等待的时间是60秒,并且使用的任务队列是SynchronousQueue,它是一个没有容量的阻塞队列,只会当里面没有任务的时候,才能往里面放任务,当放完之后,只能等它的任务被取走才能放,这不就是jdk里面提供的Executors.newCachedThreadPool线程池吗,可能是okhttp想自己定义线程工厂的参数吧,定义线程的名字。
所以到这里才会进入到子线程,由于
AsyncCall是一个runnable,因此最终执行来到了它的run方法吧,run方法最终会走到execute方法,该方法来到了okhttp最有意思的单链表结构的拦截器部分,它会把所有的拦截器组装成一个集合,然后传给RealInterceptorChain的process方法,在该方法中,会先把下一个RealInterceptorChain初始化出来,然后把下一个RealInterceptorChain传给当前Interceptor的intercept方法,最终一个个的response返回到AsyncCall的execute方法。
处理完当前的
AsyncCall后,会交给dispatcher,它会将该AsyncCall的host数减一,并且把它从runningAsyncCalls集合中移除,接着再从readyAsyncCalls集合中拿剩下的AsyncCall继续执行,直到执行完readyAsyncCalls里面的AsyncCall。
问3:OkHttp怎么实现连接池?
总结
连接池部分主要是在
RealConnectionPool类中,该类用connections(双端队列)存储所有的连接,cleanupRunnable是专门用来清除超时的RealConnection,既然有清除的任务,那肯定有清除的线程池,没错,该线程池(executor)跟okhttp处理异步时候的线程池是一样的,keepAliveDurationNs表示每一个连接keep-alive的时间,默认是5分钟,maxIdleConnections连接池的最大容量,默认是5个。RealConnection中有transmitters字段,用来保存该连接的transmitter个数,通过里面的transmitter个数来标记该RealConnection有没有在使用中。
连接池的意义?
- 频繁的进行建立Sokcet连接(TCP三次握手)和断开Socket(TCP四次分手)是非常消耗网络资源和浪费时间的,HTTP中的keepalive连接对于 降低延迟和提升速度有非常重要的作用。
- 复用连接就需要对连接进行管理,这里就引入了连接池的概念。
- Okhttp支持5个并发KeepAlive,默认链路生命为5分钟(链路空闲后,保持存活的时间),连接池有ConectionPool实现,对连接进行回收和管理。
为什么需要连接池?
频繁的进行建立Sokcet连接和断开Socket是非常消耗网络资源和浪费时间的,所以HTTP中的keepalive连接对于降低延迟和提升速度有非常重要的作用。
keepalive机制是什么呢?
也就是可以在一次TCP连接中可以持续发送多份数据而不会断开连接。所以连接的多次使用,也就是复用就变得格外重要了,而复用连接就需要对连接进行管理,于是就有了连接池的概念。
OkHttp中使用ConectionPool实现连接池,默认支持5个并发KeepAlive,默认链路生命为5分钟。
怎么实现的?
1,首先,ConectionPool中维护了一个双端队列Deque,也就是两端都可以进出的队列,用来存储连接。
2.然后在ConnectInterceptor,也就是负责建立连接的拦截器中,首先会找可用连接,也就是从连接池中去获取连接,具体的就是会调用到ConectionPool的get方法。
RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {assert (Thread.holdsLock(this));for (RealConnection connection : connections) {if (connection.isEligible(address, route)) {streamAllocation.acquire(connection, true);return connection;}}return null;}也就是遍历了双端队列,如果连接有效,就会调用acquire方法计数并返回这个连接。
3.如果没找到可用连接,就会创建新连接,并会把这个建立的连接加入到双端队列中,同时开始运行线程池中的线程,其实就是调用了ConectionPool的put方法。
public final class ConnectionPool {void put(RealConnection connection) {if (!cleanupRunning) {//没有连接的时候调用cleanupRunning = true;executor.execute(cleanupRunnable);}connections.add(connection);}
}
4.其实这个线程池中只有一个线程,是用来清理连接的,也就是上述的cleanupRunnable
private final Runnable cleanupRunnable = new Runnable() {@Overridepublic void run() {while (true) {//执行清理,并返回下次需要清理的时间。long waitNanos = cleanup(System.nanoTime());if (waitNanos == -1) return;if (waitNanos > 0) {long waitMillis = waitNanos / 1000000L;waitNanos -= (waitMillis * 1000000L);synchronized (ConnectionPool.this) {//在timeout时间内释放锁try {ConnectionPool.this.wait(waitMillis, (int) waitNanos);} catch (InterruptedException ignored) {}}}}}};这个runnable会不停的调用cleanup方法清理线程池,并返回下一次清理的时间间隔,然后进入wait等待。
怎么清理的呢?看看源码:
long cleanup(long now) {synchronized (this) {//遍历连接for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) {RealConnection connection = i.next();//检查连接是否是空闲状态,//不是,则inUseConnectionCount + 1//是 ,则idleConnectionCount + 1if (pruneAndGetAllocationCount(connection, now) > 0) {inUseConnectionCount++;continue;}idleConnectionCount++;// If the connection is ready to be evicted, we're done.long idleDurationNs = now - connection.idleAtNanos;if (idleDurationNs > longestIdleDurationNs) {longestIdleDurationNs = idleDurationNs;longestIdleConnection = connection;}}//如果超过keepAliveDurationNs或maxIdleConnections,//从双端队列connections中移除if (longestIdleDurationNs >= this.keepAliveDurationNs|| idleConnectionCount > this.maxIdleConnections) { connections.remove(longestIdleConnection);} else if (idleConnectionCount > 0) { //如果空闲连接次数>0,返回将要到期的时间// A connection will be ready to evict soon.return keepAliveDurationNs - longestIdleDurationNs;} else if (inUseConnectionCount > 0) {// 连接依然在使用中,返回保持连接的周期5分钟return keepAliveDurationNs;} else {// No connections, idle or in use.cleanupRunning = false;return -1;}}closeQuietly(longestIdleConnection.socket());// Cleanup again immediately.return 0;}也就是当如果空闲连接maxIdleConnections超过5个或者keepalive时间大于5分钟,则将该连接清理掉。
这里有个问题,怎样属于空闲连接?
public void acquire(RealConnection connection, boolean reportedAcquired) {assert (Thread.holdsLock(connectionPool));if (this.connection != null) throw new IllegalStateException();this.connection = connection;this.reportedAcquired = reportedAcquired;connection.allocations.add(new StreamAllocationReference(this, callStackTrace));}在RealConnection中,有一个StreamAllocation虚引用列表allocations。每创建一个连接,就会把连接对应的StreamAllocationReference添加进该列表中,如果连接关闭以后就将该对象移除。
5.连接池的工作就这么多,并不复杂,主要就是管理双端队列Deque<RealConnection>,可以用的连接就直接用,然后定期清理连接,同时通过对StreamAllocation的引用计数实现自动回收。
最后
- 连接池是为了解决频繁的进行建立Sokcet连接(TCP三次握手)和断开Socket(TCP四次分手)。
- Okhttp的连接池支持最大5个链路的keep-alive连接,并且默认keep-alive的时间是5分钟。
- 连接池实现的类是RealConnectionPool,它负责存储与清除的工作,存储是通过ArrayDeque的双端队列存储,删除交给了线程池处理cleanupRunnable的任务。
- 在每次创建RealConnection或从连接池中拿一次RealConnection会给RealConnection的 transmitters集合添加一个若引用的transmitter对象,添加它主要是为了后面判断该连接是否在使用中
- 在连接池中找连接的时候会对比连接池中相同host的连接。
- 如果在连接池中找不到连接的话,会创建连接,创建完后会存储到连接池中。
- 在把连接放入连接池中时,会把清除操作的任务放入到线程池中执行,删除任务中会判断当前连接有没有在使用中,有没有正在使用通过RealConnection的transmitters集合的size是否为0来判断,如果不在使用中,找出空闲时间最长的连接,如果空闲时间最长的连接超过了keep-alive默认的5分钟或者空闲的连接数超过了最大的keep-alive连接数5个的话,会把存活时间最长的连接从连接池中删除。保证keep-alive的最大空闲时间和最大的连接数。
问4:OkHttp里面用到了什么设计模式
责任链模式
可以说是okhttp的精髓所在了,主要体现就是拦截器的使用,具体代码可以看看上述的拦截器介绍。
建造者模式
在Okhttp中,建造者模式也是用的挺多的,主要用处是将对象的创建与表示相分离,用Builder组装各项配置。
工厂模式
工厂模式和建造者模式类似,区别就在于工厂模式侧重点在于对象的生成过程,而建造者模式主要是侧重对象的各个参数配置。
例子有CacheInterceptor拦截器中又个CacheStrategy对象:
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();public Factory(long nowMillis, Request request, Response cacheResponse) {this.nowMillis = nowMillis;this.request = request;this.cacheResponse = cacheResponse;if (cacheResponse != null) {this.sentRequestMillis = cacheResponse.sentRequestAtMillis();this.receivedResponseMillis = cacheResponse.receivedResponseAtMillis();Headers headers = cacheResponse.headers();for (int i = 0, size = headers.size(); i < size; i++) {String fieldName = headers.name(i);String value = headers.value(i);if ("Date".equalsIgnoreCase(fieldName)) {servedDate = HttpDate.parse(value);servedDateString = value;} else if ("Expires".equalsIgnoreCase(fieldName)) {expires = HttpDate.parse(value);} else if ("Last-Modified".equalsIgnoreCase(fieldName)) {lastModified = HttpDate.parse(value);lastModifiedString = value;} else if ("ETag".equalsIgnoreCase(fieldName)) {etag = value;} else if ("Age".equalsIgnoreCase(fieldName)) {ageSeconds = HttpHeaders.parseSeconds(value, -1);}}}}
观察者模式
关于Okhttp中websocket的使用,由于webSocket属于长连接,所以需要进行监听,这里是用到了观察者模式:
final WebSocketListener listener;@Override public void onReadMessage(String text) throws IOException {listener.onMessage(this, text);}
单例模式
每个项目都会有。
问5:论如何优雅地知道OkHttp的请求时间
OkHttp如何进行各个请求环节的耗时统计呢?
OkHttp 版本提供了EventListener接口,可以让调用者接收一系列网络请求过程中的事件,例如DNS解析、TSL/SSL连接、Response接收等。通过继承此接口,调用者可以监视整个应用中网络请求次数、流量大小、耗时(比如dns解析时间,请求时间,响应时间等等)情况。
public abstract class EventListener {// 按照请求顺序回调public void callStart(Call call) {}// 域名解析public void dnsStart(Call call, String domainName) {}public void dnsEnd(Call call, String domainName, List<InetAddress> inetAddressList) {}// 释放当前Transmitter的RealConnectionpublic void connectionReleased(Call call, Connection connection) {}public void connectionAcquired(call, result){};// 开始连接public void connectStart(call, route.socketAddress(), proxy){}// 请求public void requestHeadersStart(@NotNull Call call){}public void requestHeadersEnd(@NotNull Call call, @NotNull Request request) {}// 响应public void requestBodyStart(@NotNull Call call) {}public void requestBodyEnd(@NotNull Call call, long byteCount) {}// 结束public void callEnd(Call call) {}// 失败public void callFailed(Call call, IOException ioe) {}
}请求开始结束监听
inal class RealCall implements Call {@Override public Response execute() throws IOException {eventListener.callStart(this);client.dispatcher().executed(this);Response result = getResponseWithInterceptorChain();if (result == null) throw new IOException("Canceled");return result; }@Override public void enqueue(Callback responseCallback) {eventListener.callStart(this);client.dispatcher().enqueue(new AsyncCall(responseCallback));}
}如何消耗记录时间
在OkHttp库中有一个EventListener类。该类是网络事件的侦听器。扩展这个类以监视应用程序的HTTP调用的数量、大小和持续时间。所有启动/连接/获取事件最终将接收到匹配的结束/释放事件,要么成功(非空参数),要么失败(非空可抛出)。
比如,可以在开始链接记录时间;dns开始,结束等方法解析记录时间,可以计算dns的解析时间。
比如,可以在开始请求记录时间,记录connectStart,connectEnd等方法时间,则可以计算出connect连接时间。
代码如下所示:
Eventlistener只适用于没有并发的情况,如果有多个请求并发执行我们需要使用Eventlistener. Factory来给每个请求创建一个Eventlistener。这个mRequestId是唯一值,可以选择使用AtomicInteger自增+1的方式设置id,这个使用了cas保证多线程条件下的原子性特性。
/*** <pre>* @author yangchong* email : yangchong211@163.com* time : 2019/07/22* desc : EventListener子类* revise:* </pre>*/
public class NetworkListener extends EventListener {private static final String TAG = "NetworkEventListener";private static AtomicInteger mNextRequestId = new AtomicInteger(0);private String mRequestId ;public static Factory get(){Factory factory = new Factory() {@NotNull@Overridepublic EventListener create(@NotNull Call call) {return new NetworkListener();}};return factory;}@Overridepublic void callStart(@NotNull Call call) {super.callStart(call);//mRequestId = mNextRequestId.getAndIncrement() + "";//getAndAdd,在多线程下使用cas保证原子性mRequestId = String.valueOf(mNextRequestId.getAndIncrement());ToolLogUtils.i(TAG+"-------callStart---requestId-----"+mRequestId);saveEvent(NetworkTraceBean.CALL_START);saveUrl(call.request().url().toString());}@Overridepublic void dnsStart(@NotNull Call call, @NotNull String domainName) {super.dnsStart(call, domainName);ToolLogUtils.d(TAG, "dnsStart");saveEvent(NetworkTraceBean.DNS_START);}@Overridepublic void dnsEnd(@NotNull Call call, @NotNull String domainName, @NotNull List<InetAddress> inetAddressList) {super.dnsEnd(call, domainName, inetAddressList);ToolLogUtils.d(TAG, "dnsEnd");saveEvent(NetworkTraceBean.DNS_END);}@Overridepublic void connectStart(@NotNull Call call, @NotNull InetSocketAddress inetSocketAddress, @NotNull Proxy proxy) {super.connectStart(call, inetSocketAddress, proxy);ToolLogUtils.d(TAG, "connectStart");saveEvent(NetworkTraceBean.CONNECT_START);}@Overridepublic void secureConnectStart(@NotNull Call call) {super.secureConnectStart(call);ToolLogUtils.d(TAG, "secureConnectStart");saveEvent(NetworkTraceBean.SECURE_CONNECT_START);}@Overridepublic void secureConnectEnd(@NotNull Call call, @Nullable Handshake handshake) {super.secureConnectEnd(call, handshake);ToolLogUtils.d(TAG, "secureConnectEnd");saveEvent(NetworkTraceBean.SECURE_CONNECT_END);}@Overridepublic void connectEnd(@NotNull Call call, @NotNull InetSocketAddress inetSocketAddress,@NotNull Proxy proxy, @Nullable Protocol protocol) {super.connectEnd(call, inetSocketAddress, proxy, protocol);ToolLogUtils.d(TAG, "connectEnd");saveEvent(NetworkTraceBean.CONNECT_END);}@Overridepublic void connectFailed(@NotNull Call call, @NotNull InetSocketAddress inetSocketAddress, @NotNull Proxy proxy, @Nullable Protocol protocol, @NotNull IOException ioe) {super.connectFailed(call, inetSocketAddress, proxy, protocol, ioe);ToolLogUtils.d(TAG, "connectFailed");}@Overridepublic void requestHeadersStart(@NotNull Call call) {super.requestHeadersStart(call);ToolLogUtils.d(TAG, "requestHeadersStart");saveEvent(NetworkTraceBean.REQUEST_HEADERS_START);}@Overridepublic void requestHeadersEnd(@NotNull Call call, @NotNull Request request) {super.requestHeadersEnd(call, request);ToolLogUtils.d(TAG, "requestHeadersEnd");saveEvent(NetworkTraceBean.REQUEST_HEADERS_END);}@Overridepublic void requestBodyStart(@NotNull Call call) {super.requestBodyStart(call);ToolLogUtils.d(TAG, "requestBodyStart");saveEvent(NetworkTraceBean.REQUEST_BODY_START);}@Overridepublic void requestBodyEnd(@NotNull Call call, long byteCount) {super.requestBodyEnd(call, byteCount);ToolLogUtils.d(TAG, "requestBodyEnd");saveEvent(NetworkTraceBean.REQUEST_BODY_END);}@Overridepublic void responseHeadersStart(@NotNull Call call) {super.responseHeadersStart(call);ToolLogUtils.d(TAG, "responseHeadersStart");saveEvent(NetworkTraceBean.RESPONSE_HEADERS_START);}@Overridepublic void responseHeadersEnd(@NotNull Call call, @NotNull Response response) {super.responseHeadersEnd(call, response);ToolLogUtils.d(TAG, "responseHeadersEnd");saveEvent(NetworkTraceBean.RESPONSE_HEADERS_END);}@Overridepublic void responseBodyStart(@NotNull Call call) {super.responseBodyStart(call);ToolLogUtils.d(TAG, "responseBodyStart");saveEvent(NetworkTraceBean.RESPONSE_BODY_START);}@Overridepublic void responseBodyEnd(@NotNull Call call, long byteCount) {super.responseBodyEnd(call, byteCount);ToolLogUtils.d(TAG, "responseBodyEnd");saveEvent(NetworkTraceBean.RESPONSE_BODY_END);}@Overridepublic void callEnd(@NotNull Call call) {super.callEnd(call);ToolLogUtils.d(TAG, "callEnd");saveEvent(NetworkTraceBean.CALL_END);generateTraceData();NetWorkUtils.timeoutChecker(mRequestId);}@Overridepublic void callFailed(@NotNull Call call, @NotNull IOException ioe) {super.callFailed(call, ioe);ToolLogUtils.d(TAG, "callFailed");}private void generateTraceData(){NetworkTraceBean traceModel = IDataPoolHandleImpl.getInstance().getNetworkTraceModel(mRequestId);Map<String, Long> eventsTimeMap = traceModel.getNetworkEventsMap();Map<String, Long> traceList = traceModel.getTraceItemList();traceList.put(NetworkTraceBean.TRACE_NAME_TOTAL,NetWorkUtils.getEventCostTime(eventsTimeMap,NetworkTraceBean.CALL_START, NetworkTraceBean.CALL_END));traceList.put(NetworkTraceBean.TRACE_NAME_DNS,NetWorkUtils.getEventCostTime(eventsTimeMap,NetworkTraceBean.DNS_START, NetworkTraceBean.DNS_END));traceList.put(NetworkTraceBean.TRACE_NAME_SECURE_CONNECT,NetWorkUtils.getEventCostTime(eventsTimeMap,NetworkTraceBean.SECURE_CONNECT_START, NetworkTraceBean.SECURE_CONNECT_END));traceList.put(NetworkTraceBean.TRACE_NAME_CONNECT,NetWorkUtils.getEventCostTime(eventsTimeMap,NetworkTraceBean.CONNECT_START, NetworkTraceBean.CONNECT_END));traceList.put(NetworkTraceBean.TRACE_NAME_REQUEST_HEADERS,NetWorkUtils.getEventCostTime(eventsTimeMap,NetworkTraceBean.REQUEST_HEADERS_START, NetworkTraceBean.REQUEST_HEADERS_END));traceList.put(NetworkTraceBean.TRACE_NAME_REQUEST_BODY,NetWorkUtils.getEventCostTime(eventsTimeMap,NetworkTraceBean.REQUEST_BODY_START, NetworkTraceBean.REQUEST_BODY_END));traceList.put(NetworkTraceBean.TRACE_NAME_RESPONSE_HEADERS,NetWorkUtils.getEventCostTime(eventsTimeMap,NetworkTraceBean.RESPONSE_HEADERS_START, NetworkTraceBean.RESPONSE_HEADERS_END));traceList.put(NetworkTraceBean.TRACE_NAME_RESPONSE_BODY,NetWorkUtils.getEventCostTime(eventsTimeMap,NetworkTraceBean.RESPONSE_BODY_START, NetworkTraceBean.RESPONSE_BODY_END));}private void saveEvent(String eventName){NetworkTraceBean networkTraceModel = IDataPoolHandleImpl.getInstance().getNetworkTraceModel(mRequestId);Map<String, Long> networkEventsMap = networkTraceModel.getNetworkEventsMap();networkEventsMap.put(eventName, SystemClock.elapsedRealtime());}private void saveUrl(String url){NetworkTraceBean networkTraceModel = IDataPoolHandleImpl.getInstance().getNetworkTraceModel(mRequestId);networkTraceModel.setUrl(url);}}
参考
网络库OKHttp(1)流程+拦截器-CSDN博客
谈谈OKHttp的几道面试题 - 简书
面试官:Okhttp连接池是咋实现的? - 掘金
论如何优雅地知道OkHttp的请求时间
相关文章:
网络库OKHTTP(2)面试题
序、慢慢来才是最快的方法。 背景 OkHttp 是一套处理 HTTP 网络请求的依赖库,由 Square 公司设计研发并开源,目前可以在 Java 和 Kotlin 中使用。对于 Android App 来说,OkHttp 现在几乎已经占据了所有的网络请求操作。 OKHttp源码官网 问1…...

探索Java NIO:究竟在哪些领域能大显身手?揭秘原理、应用场景与官方示例代码
一、NIO简介 Java NIO(New IO)是Java SE 1.4引入的一个新的IO API,它提供了比传统IO更高效、更灵活的IO操作。与传统IO相比,Java NIO的优势在于它支持非阻塞IO和选择器(Selector)等特性,能够更…...

论文阅读 Memory Enhanced Global-Local Aggregation for Video Object Detection
Memory Enhanced Global-Local Aggregation for Video Object Detection Abstract 人类如何识别视频中的物体?由于单一帧的质量低下,仅仅利用一帧图像内的信息可能很难让人们在这一帧中识别被遮挡的物体。我们认为人们识别视频中的物体有两个重要线索&…...

Java 常用类(包装类)
目录 八大Wrapper类包装类的分类 装箱和拆箱包装类和基本数据类型之间的转换常见面试题 包装类方法包装类型和String类型的相互转换包装类常用方法(以Integer类和Character类为例)Integer类和Character类的常用方法 Integer创建机制(面试题&a…...
ES|QL:Elasticsearch的 新一代查询语言
作者:李捷 “学会选择很难。学会正确选择更难。而在一个充满无限可能的世界里学会正确选择则更难,也许是太难了。” 巴里-施瓦茨(Barry Schwartz)在《选择的悖论--多就是少》(The Paradox of Choice -More is Less&…...
C语言实现句子中的单词颠倒排序
一、运行结果 二、源代码 # define _CRT_SECURE_NO_WARNINGS # include <stdio.h> # include <assert.h>//实现逆转函数; void reverse(char* left, char* right) {//断言left和right都不能为空;assert(left);assert(right);//循环逆转字母…...

MySQL学习(八)——锁
文章目录 1. 锁概述2. 全局锁2.1 全局锁的必要性2.2 语法2.3 全局锁的特点 3. 表级锁3.1 表锁3.2 元数据锁3.3 意向锁3.4 自增锁 4. 行级锁4.1 介绍4.2 记录锁4.3 间隙锁4.4 临键锁 1. 锁概述 锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,除传…...

让iPhone用电脑的网络上网
让iPhone用电脑的网络上网,可以按照以下步骤操作: 在iPhone上找到并点击“设置”选项,进入“蜂窝移动网络”。打开“个人热点”选项。此时下方的弹出对话框会显示“仅USB”。用数据线将你的iPhone与电脑相连,并在电脑上打开“控制…...
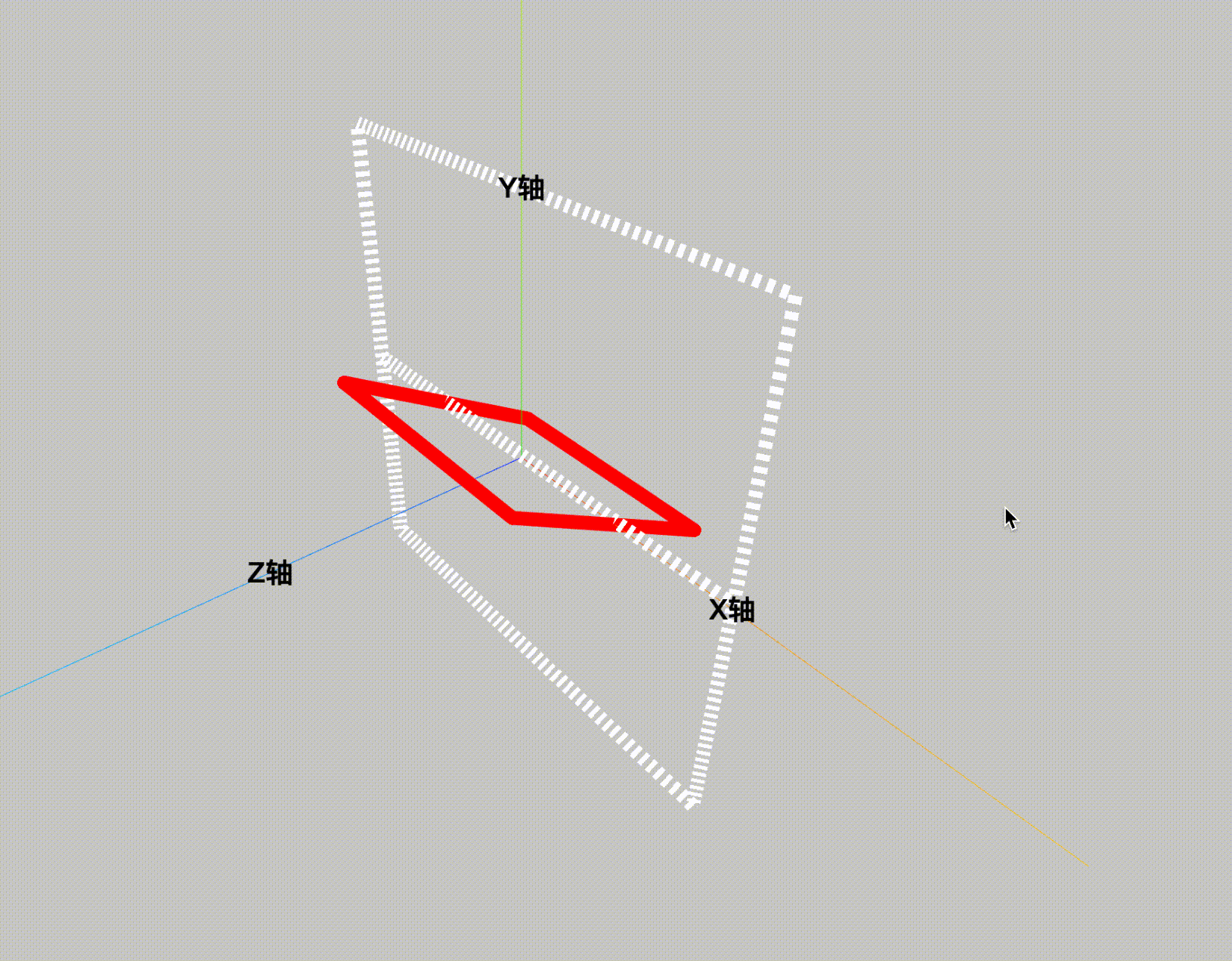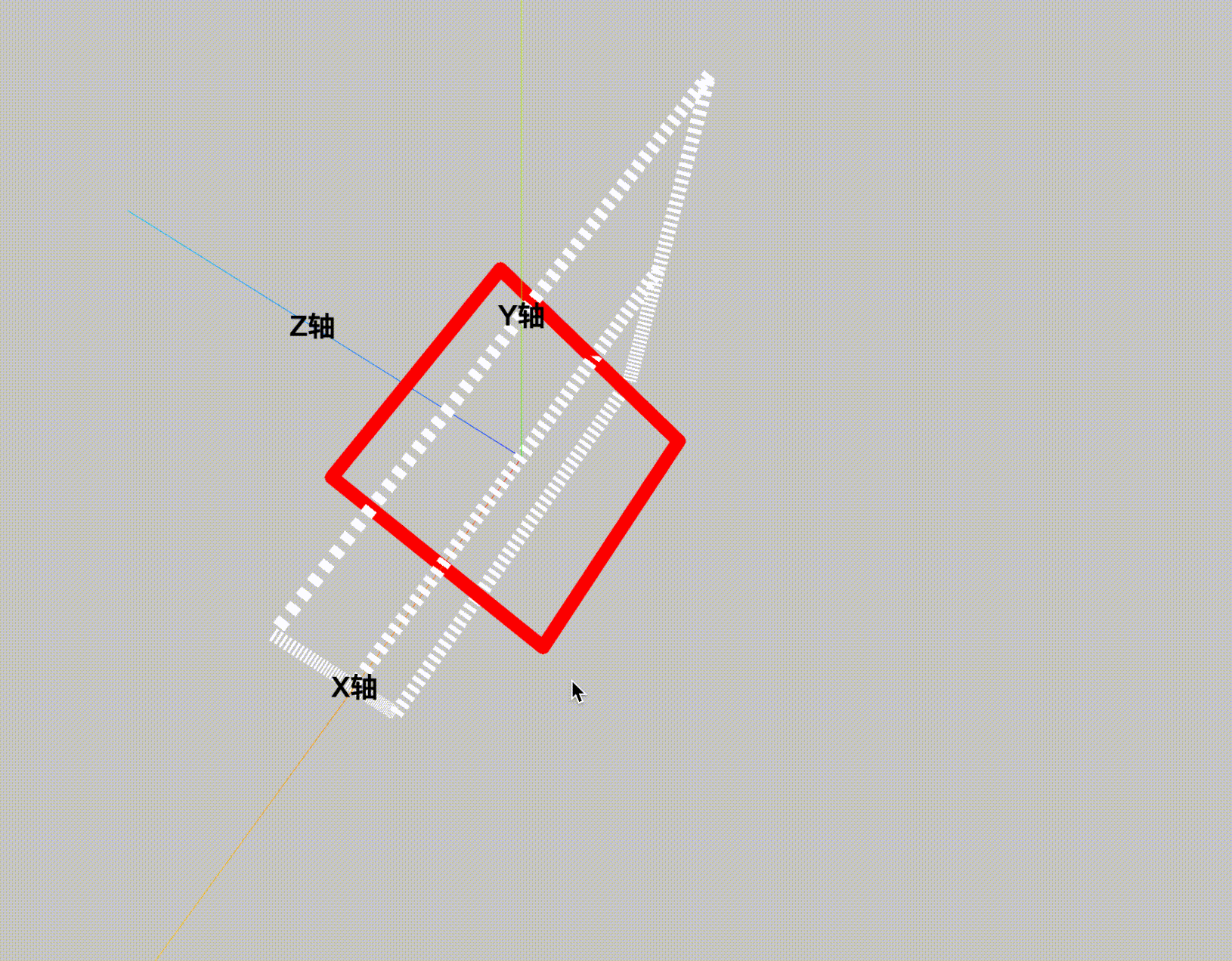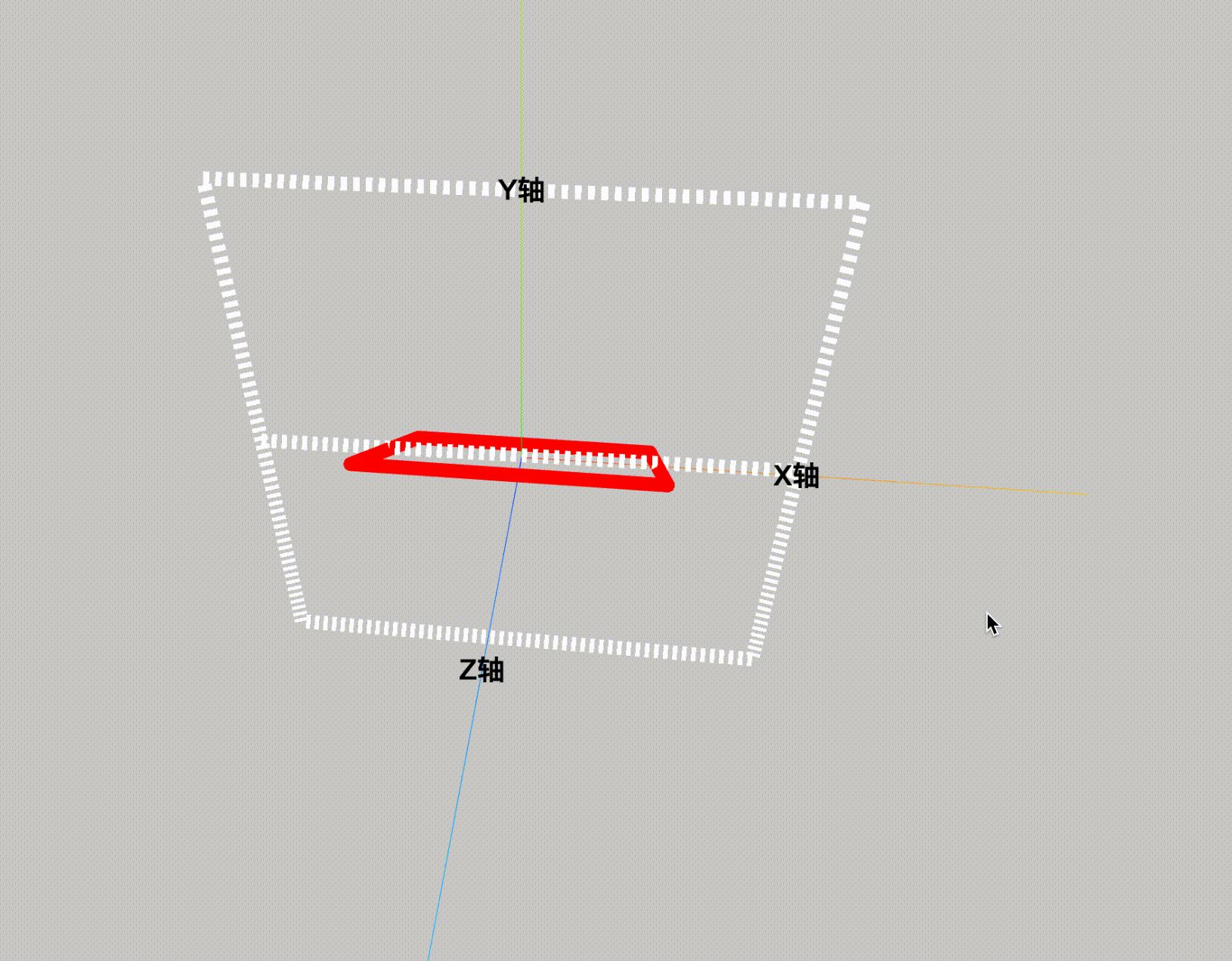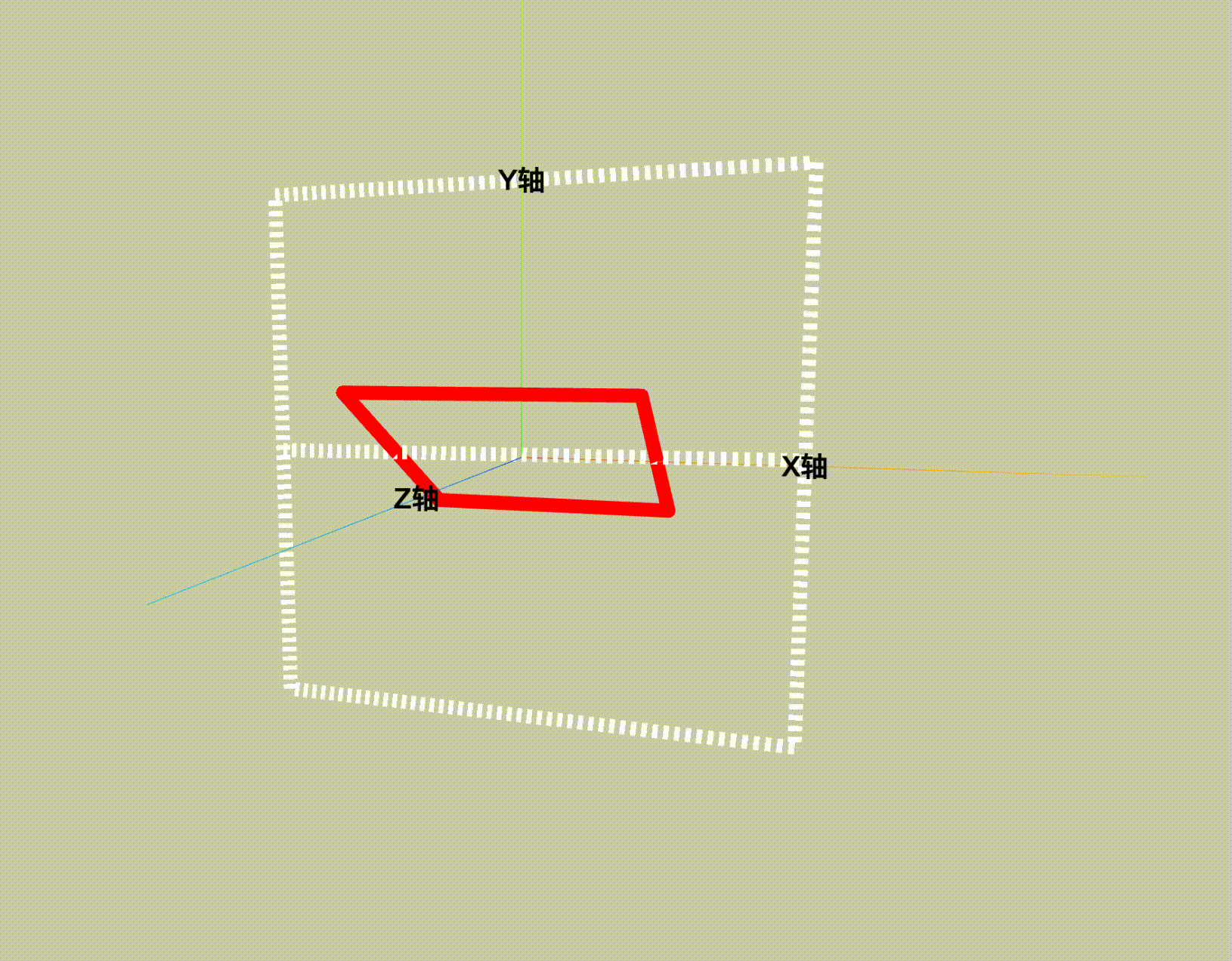
ThreeJS-3D教学十-有宽度的line
webgl中线是没有宽度的,现实的应用中一般做法都是将线拓宽成面来绘制。默认threejs的线宽是无法调节的,需要用有厚度的线 THREE.Line2。 先看效果图: 看下代码: <!DOCTYPE html> <html lang"en"> <he…...

安装Elasticsearch步骤(包含遇到的问题及解决方案)
注:笔者是在centos云服务器环境下安装的Elasticsearch 目录 1.安装前准备 2.下载Elasticsearch 3.启动Elasticsearch 非常容易出问题 第一次运行时,可能出现如下错误: 一、内存不足原因启动失败 二、使用root用户启动问题 三、启动ES自…...

网络编程面试笔试真题
网络编程笔试面试真题 1、关于Linux系统中多线程的信号处理,说法中不正确的是? A:在线程环境霞,产生的信号是传递给整个进程的 B:一般情况下,信号会随机给进程的一个线程 C:对某个信号处理函数…...
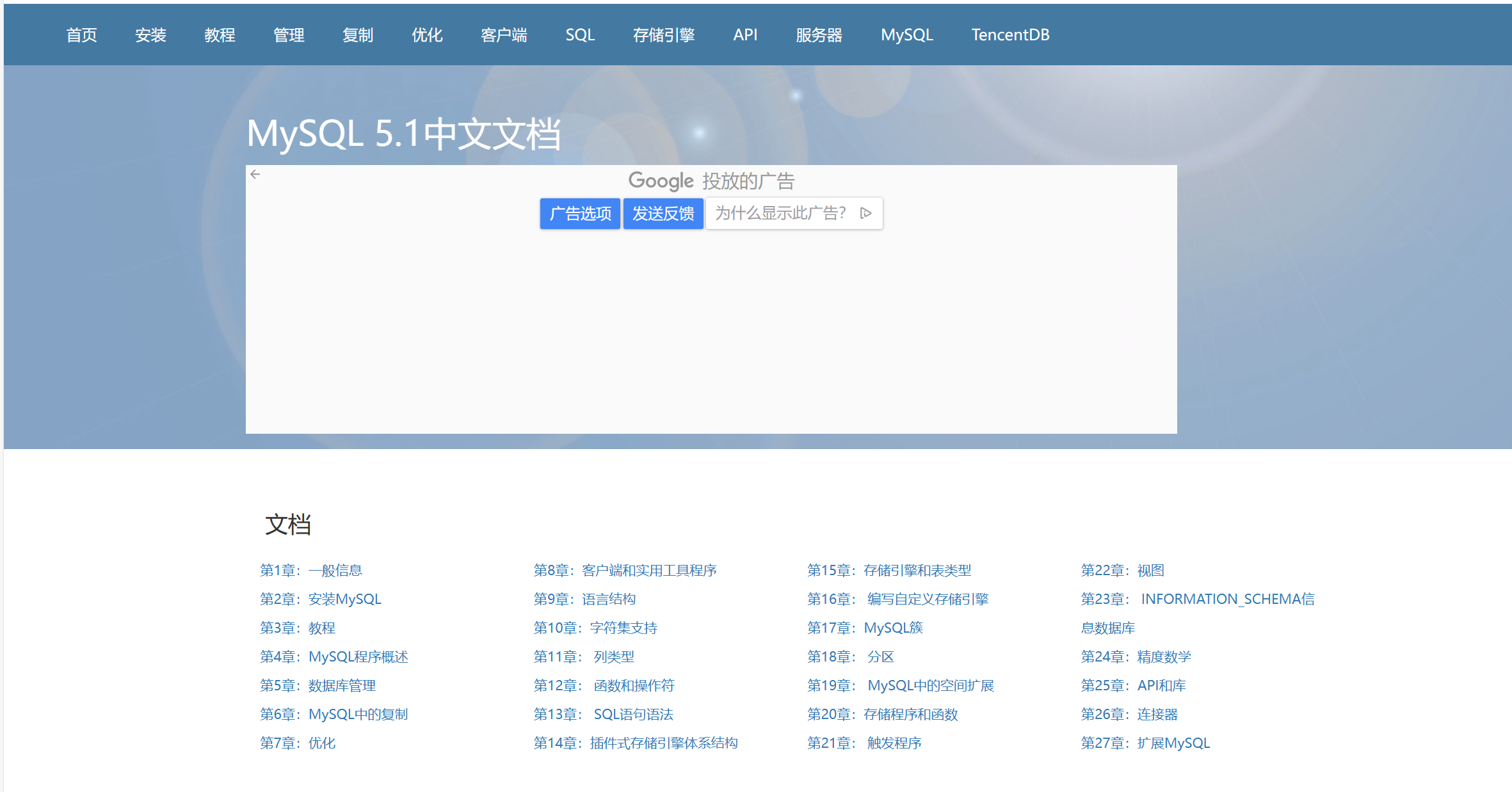
MySQL官方文档如何查看,MySQL中文文档
这里写自定义目录标题 MySQL官方文档如何查看MySQL中文文档 MySQL官方文档如何查看 MySQL官网地址:https://dev.mysql.com/doc/ 比如这里我要找InnoDB架构 MySQL中文文档 MySQL 5.1中文文档地址:https://www.mysqlzh.com/...
)
第七章:最新版零基础学习 PYTHON 教程—Python 列表(第四节 -如何在 Python 中查找列表的长度)
列表是 Python 日常编程不可或缺的一部分,所有 Python 用户都必须学习,了解其实用程序和操作是必不可少的,而且总是有好处的。因此,本文讨论了找到第一个这样的实用程序。使用Python 的列表中的元素。 目录 在 Python 中查找列表的长度...

XPS虽没流行,但还在使用!在Windows 10中打开XPS文件的最佳方法
当Windows Vista发布时,微软推出了XPS格式,这是PDF的替代品。XPS文件格式并不是什么新鲜事,但从未获得过多大的吸引力。 因此,XPS(XML Paper Specification)文件是微软对Adobe PDF文件的竞争对手。尽管XPS…...
23 种设计模式详解(C#案例)
🚀设计模式简介 设计模式(Design pattern)代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时…...

@SpringBootApplication配置了scanBasePackages导致请求一直404,分析下原因
出现RequestMapping注解的Controller类可能是因为SpringBootApplication注解中配置了scanBasePackages导致的请求一直返回404错误。 SpringBootApplication注解是Spring Boot的核心注解之一,它用于启动Spring Boot应用程序。这个注解实际上是一个组合注解ÿ…...
{大厂漏洞 } OA产品存在SQL注入
0x01 漏洞介绍 江苏叁拾叁-OA是由江苏叁拾叁信息技术有限公司开发的一款OA办公平台,主要有知识管理,工作流程,沟通交流,辅助办公,集成解决方案,应用支撑平台,基础支撑等功能。 该系统也与江苏叁…...

6-8 舞伴问题 分数 15
void DancePartner(DataType dancer[], int num) {LinkQueue maleQueue SetNullQueue_Link();LinkQueue femaleQueue SetNullQueue_Link();// 将男士和女士的信息分别加入对应的队列for (int i 0; i < num; i) {if (dancer[i].sex M){EnQueue_link(maleQueue, dancer[i]…...

samba服务器的功能是什么
Samba服务器是一个开源的网络文件共享服务,其主要功能是在不同操作系统之间实现文件和打印机共享。它最常用于将Linux/Unix系统与Windows系统互联,但也支持其他操作系统。 以下是Samba服务器的主要功能: 文件共享:Samba允许用户在…...
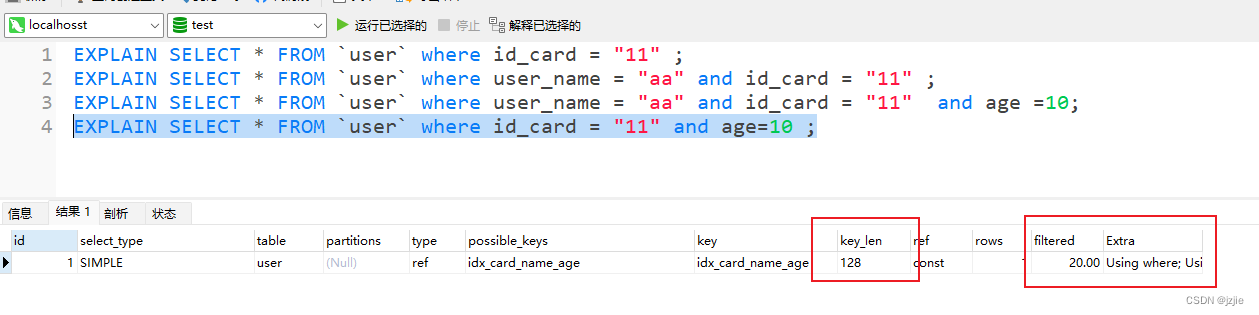
MSQL系列(五) Mysql实战-索引最左侧匹配原则分析及实战
Mysql实战-索引最左侧匹配原则分析及实战 前面我们讲解了索引的存储结构,BTree的索引结构,以及索引最左侧匹配原则,Explain的用法,今天我们来实战一下 最左侧匹配原则 1.联合索引最左侧匹配原则 联合索引有一个最左侧匹配原则 …...

多场景适配:ClearerVoice-Studio支持16K/48K采样率,会议直播都适用
多场景适配:ClearerVoice-Studio支持16K/48K采样率,会议直播都适用 1. 为什么音频采样率如此重要? 在语音处理领域,采样率选择直接影响最终效果。就像相机像素决定照片清晰度一样,音频采样率决定了声音的"分辨率…...

python协同过滤算法的基于python二手物品交易网站系统
目录同行可拿货,招校园代理 ,本人源头供货商协同过滤算法在二手物品交易网站中的应用用户行为数据收集基于用户的协同过滤基于物品的协同过滤混合推荐策略冷启动问题处理实时推荐更新推荐结果评估代码实现示例系统功能整合性能优化项目技术支持源码获取详细视频演示 ࿱…...

解决Canal 连接数据库超时问题
根本原因:DNS 反向解析导致超时Caused by: java.net.SocketTimeoutException: Timeout occurred, failed to read total 4 bytes in 5000 milliseconds, actual read only 0 bytesat com.alibaba.otter.canal.parse.driver.mysql.socket.BioSocketChannel.read(BioS…...

Phi-4-mini-reasoning实战教程:批量处理CSV数学题库生成标准答案
Phi-4-mini-reasoning实战教程:批量处理CSV数学题库生成标准答案 1. 引言 数学老师们经常面临一个共同挑战:批改大量数学作业和试卷需要花费大量时间。传统方法需要逐题检查,效率低下且容易出错。今天,我们将介绍如何利用Phi-4-…...

AI辅助架构设计:让快马平台智能规划trae状态管理方案
用AI辅助设计trae状态管理方案:以博客后台系统为例 最近在开发一个博客后台管理系统时,遇到了状态管理的难题。系统需要处理文章列表、编辑草稿、用户评论和系统设置等多种数据,如何合理组织这些状态让我头疼不已。幸运的是,在In…...

MySQL
我目前正在学习SQL语句,我所了解到的MySQL其实是一堆服务器,在下载服务器的时候,可以选择下载一些客户端,MySQL会自带一些客户端,像类似于终端的小黑框,还有什么bench;我还是喜欢外观好看的客户端 !我学SQL语句目前学到了数据类型,有数值型的,字符型的,二进制型的,值得一提的是…...

DeepSeek风格迁移降AI怎么用?从0到1完整操作教程
第一次操作的话,照着下面的步骤来,15分钟内搞定DeepSeek风格迁移降AI、降AI、降AIGC率。 工具选嘎嘎降AI(www.aigcleaner.com),达标率99.26%,有退款保障,操作也不复杂。 准备工作 需要准备的&…...

Kettle数据迁移实战:从CSV到MySQL的高效导入指南
1. 为什么选择Kettle进行CSV到MySQL的数据迁移 第一次接触数据迁移任务时,我试过用Python脚本逐行读取CSV写入MySQL,结果导入10万条数据花了近20分钟。后来发现Kettle这个神器,同样的数据量只需要2分钟就能搞定,效率提升简直惊人。…...

AppSpider 7.5.025 for Windows - Web 应用程序安全测试
AppSpider 7.5.025 for Windows - Web 应用程序安全测试 Rapid7 Dynamic Application Security Testing (DAST) released March 31, 2026 请访问原文链接:https://sysin.org/blog/appspider/ 查看最新版。原创作品,转载请保留出处。 作者主页…...

理解usearch的动态内存调整:实现高效向量搜索的终极指南
理解usearch的动态内存调整:实现高效向量搜索的终极指南 【免费下载链接】usearch Fast Open-Source Search & Clustering engine for Vectors & Arbitrary Objects in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang, and Wolfr…...