MSQL系列(五) Mysql实战-索引最左侧匹配原则分析及实战
Mysql实战-索引最左侧匹配原则分析及实战
前面我们讲解了索引的存储结构,B+Tree的索引结构,以及索引最左侧匹配原则,Explain的用法,今天我们来实战一下 最左侧匹配原则
1.联合索引最左侧匹配原则
联合索引有一个最左侧匹配原则
最左匹配原则指的是,当使用联合索引进行查询时,MySQL会优先使用最左边的列进行匹配,然后再依次向右匹配。
假设我们有一个表,包含三个列:A、B、C
创建联合索引(A,B,C) 等同于创建了索引 A, 索引 (A,B), 索引 (A,B,C)
- 我们使用(A,B,C)这个联合索引进行查询时,MySQL会先根据列A进行匹配
- 再根据列B进行匹配,最后再根据列C进行匹配。
- 如果我们只查询了(A,B)这两个列,而没有查询列C,那么MySQL只会使用(A,B)这个前缀来进行索引匹配,而不会使用到列C
- 如果我们要查询 了(B,C)这两个列,而没有查询列A,那么MySQL索引就会失效,导致找不到索引,因为最左侧匹配原理
- 所以 我们应该尽量把最常用的列放在联合索引的最左边,这样可以提高查询效率
2.实战
新建表结构 user, user_info
#新建表结构 user
CREATE TABLE `user` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',`id_card` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '身份证ID',`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户名字',`age` int NOT NULL COMMENT '年龄',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'
- id 主键id列
- id_card 身份证id
- user_name 用户姓名
- age 年龄
先插入测试数据, 插入 5条测试数据
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (1, '11', 'aa', 10);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (2, '22', 'bb', 20);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (3, '33', 'cc', 30);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (4, '44', 'dd', 40);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (5, '55', 'ee', 50);
2.1 创建 id_card,user_name,age的索引列
alter table user add index idx_card_name_age(id_card,user_name,age);
创建索引成功
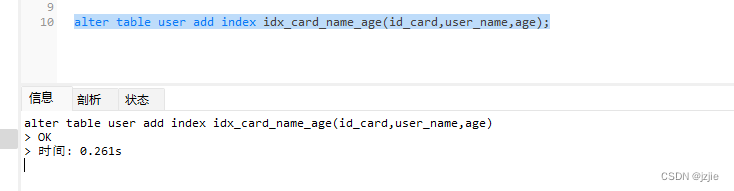
我们现在user表只有一个新建的索引

2.2. 查B,C列信息
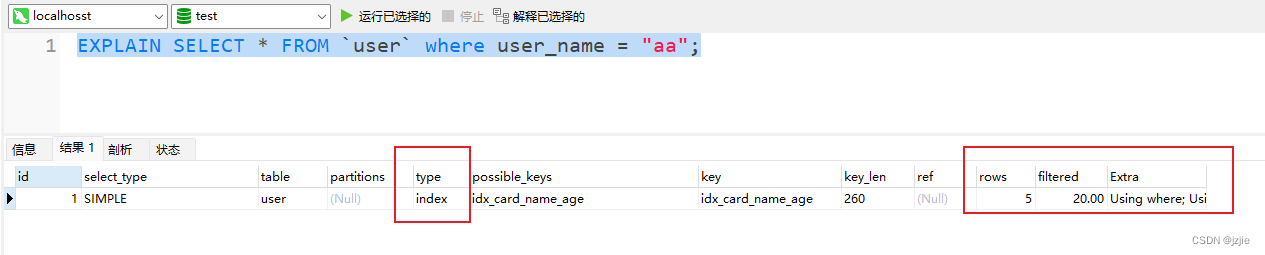
- (A,B,C)的联合索引, 单纯的查B, 或者查BC是无法用到索引的,走的是全部索引扫描type=index类型
查询user_name, 查询语句中没有id_card
EXPLAIN SELECT * FROM `user` where user_name = "aa";
执行结果
- (A,B,C)的联合索引, 单纯的查C,同样的结果,走的是全部索引扫描type=index类型
查询age,查询语句中没有id_card
EXPLAIN SELECT * FROM `user` where age = 10;
执行结果

- (A,B,C)的联合索引, 查BC,同样的结果,走的是全部索引扫描type=index类型
查询user_name 和 age,查询语句中没有id_card
EXPLAIN SELECT * FROM `user` where user_name = "aa" and age = 10;
执行结果

2.3查询A列的相关信息
上面我们看到了只要查询语句中不包含A的字段信息,所有的索引全都不生效,扫描全部索引信息,这不是我们想要的
这也就是最左侧匹配原则导致的,所以我们在查询的时候,一定要从最左侧开始查询,也就是查询语句一定要有A查询条件,否则索引不生效
- (A,B,C)的联合索引, 查A,type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=100%,过滤占比百分百,效率很高
只查询 id_card 字段
EXPLAIN SELECT * FROM `user` where id_card = "11" ;
执行结果

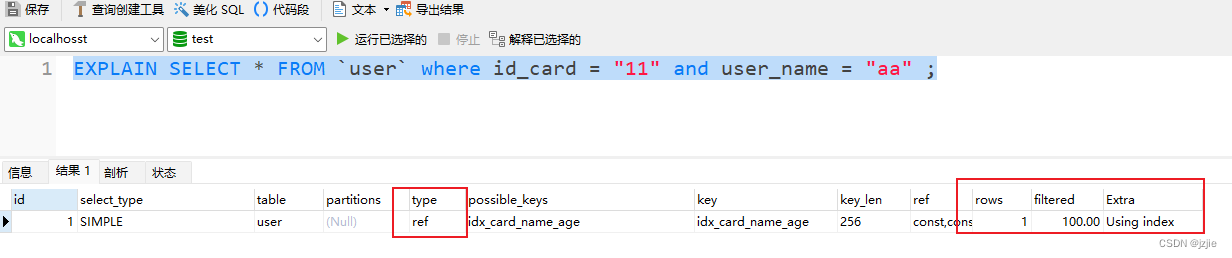
- (A,B,C)的联合索引, 查A,B列,相同的结果, type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=100%,过滤占比百分百,效率很高
查询 id_card 及 user_name 字段
EXPLAIN SELECT * FROM `user` where id_card = "11" and user_name = "aa" ;
执行结果
- (A,B,C)的联合索引, 查A,C列,相同的结果, type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=20% ,过滤占比 20%,意思是所有的5索引数据,找到了1条数据
效率不算高,也不建议这样使用
查询 id_card 及 age 字段
EXPLAIN SELECT * FROM `user` where id_card = "11" and user_name = "aa" ;
执行结果

- (A,B,C)的联合索引, 查A,B,C 列,相同的结果, type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=100%,过滤占比百分百,效率很高
查询 id_card 及 user_name 及age 字段
EXPLAIN SELECT * FROM `user` where id_card = "11" and user_name = "aa" and age =10 ;
执行结果

- (A,B,C)的联合索引, 查C,A,B 列,查询语句乱序, 看下查询结果,依旧是相同的结果, type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=100%,过滤占比百分百,效率很高
查询 id_card 及 user_name 及age 字段, 查询条件的乱序,不会影响到索引的信息
EXPLAIN SELECT * FROM `user` where age =10 and user_name = "aa" and id_card = "11" ;
执行结果

- (A,B,C)的联合索引, 查C,A,B 列,查询语句乱序, 看下查询结果,依旧是相同的结果, type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=100%,过滤占比百分百,效率很高
查询 id_card 及 user_name 及age 字段, 查询条件的乱序,不会影响到索引的信息
EXPLAIN SELECT * FROM `user` where age =10 and user_name = "aa" and id_card = "11" ;
执行结果
3. 如何知道具体用了那个索引?
我们可以通过 explain key_len计算到底使用了那个索引字段
通过刚才的验证,我们了解不同的索引,使用的ken_len长度不同,到底这个key_len如何计算,我们如何知道到底用了那个索引?
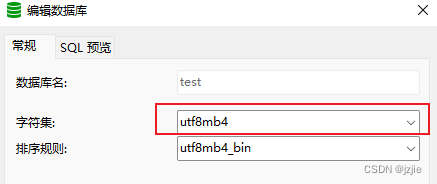
首先看下数据库编码类型 utf8mb4 编码方式
然后 看下表结构
id_card notNull
user_name 允许null
age 允许null

然后开始计算 ken_len的长度
- 字符集编码: 字符 如 utf8mb4 = 4 ,utf8 = 3, gbk = 2, latin1 = 1, 数字int =4位
- 列是否为空: NULL(+1),NOT NULL(+0)
- 列类型为字符: varchar(+2), char(+0)
到底如何计算key_len呢? key_len = (字段长度)* 编码格式 + (notNull/null)+ 列类型, 我们看下是否真的是这样
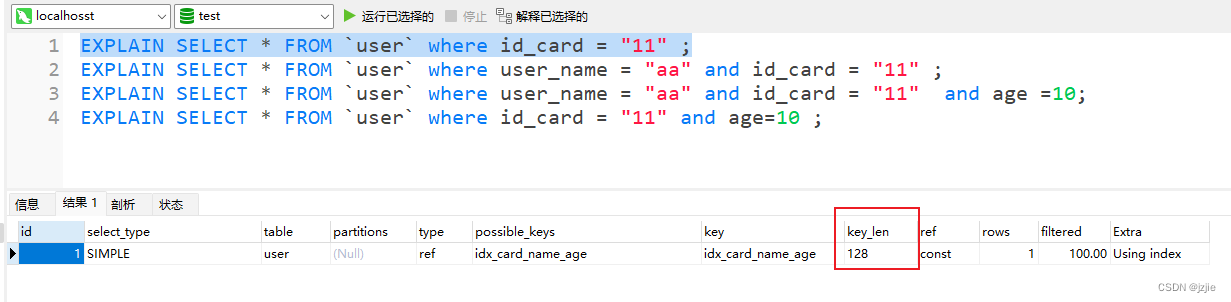
EXPLAIN SELECT * FROM `user` where id_card = "11" ;
使用了 id_card 单个字段的索引
key_len
= (char(32)) 4 + (notNull)0 + (char)0
= 324 +0 +0 = 128
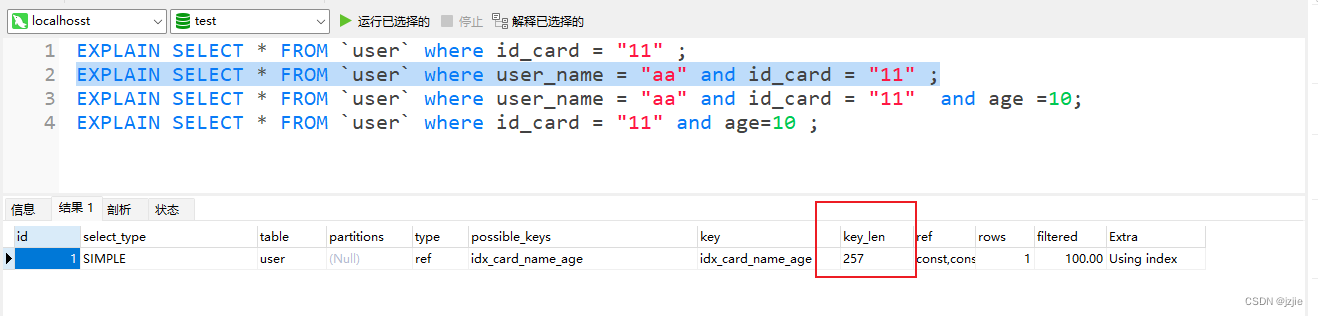
EXPLAIN SELECT * FROM `user` where user_name = "aa" and id_card = "11" ;
使用了 id_card 和 user_name 2个字段的索引, user_name允许为null +1,
key_len
= (char(32)) * 4 + (notNull)0 + (char)0 + (char(32)) 4 + (Null)1 + (char)0
= 324 + 32*4 +1 = 257
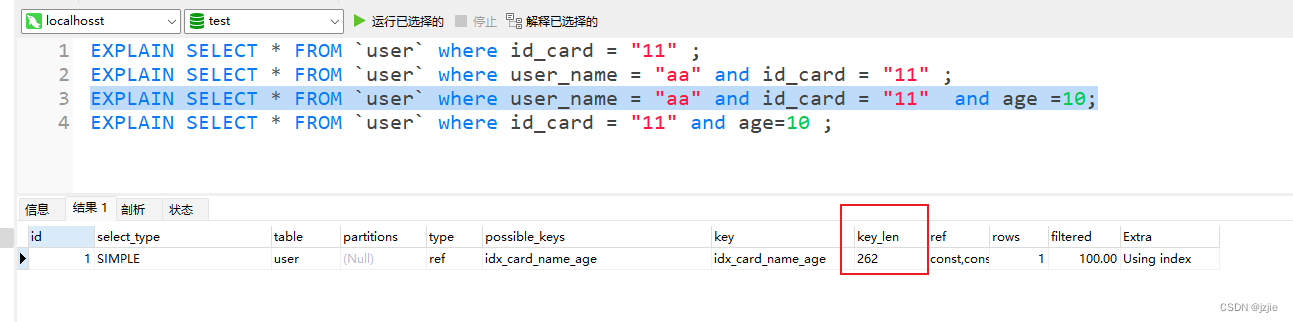
EXPLAIN SELECT * FROM `user` where user_name = "aa" and id_card = "11" and age =10;
使用了 id_card 和 user_name 及 age 三个字段的索引, user_name允许为null +1, age允许为null +1, age类型为int,占4位
key_len
= (char(32)) * 4 + (notNull)0 + (char)0 + (char(32)) 4 + (Null)1 + (char)0 + (int)4 + (Null)1 + (int)0
= 324 + 32*4 +1 + 5= 262
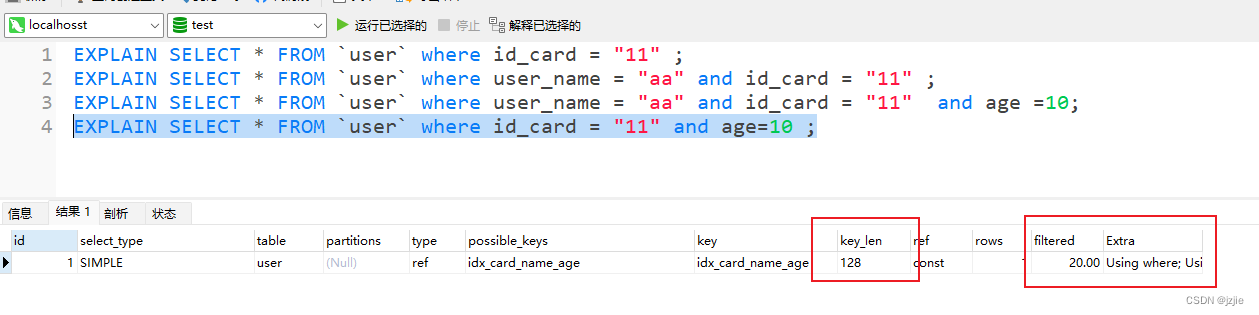
没有用到某个字段的索引,ken_len不会计算它的长度,比如A,C列的查询 id_card和age的查询,不会用到age的索引,只用到了id_card,key_len只会计算 id_card的长度
EXPLAIN SELECT * FROM `user` where id_card = "11" and age=10 ;
key_len = (char(32)) * 4 + (notNull)0 + (char)0 = 128, 只用到了id_card的索引信息
至此,我们了解了联合索引的最左侧匹配原则,也知道了如何去优化查询语句,才能使用到索引,并且知道了key_len分析具体使用了那些索引
相关文章:
MSQL系列(五) Mysql实战-索引最左侧匹配原则分析及实战
Mysql实战-索引最左侧匹配原则分析及实战 前面我们讲解了索引的存储结构,BTree的索引结构,以及索引最左侧匹配原则,Explain的用法,今天我们来实战一下 最左侧匹配原则 1.联合索引最左侧匹配原则 联合索引有一个最左侧匹配原则 …...

react|redux状态管理
react|redux状态管理 参考官网:https://cn.redux-toolkit.js.org/tutorials/quick-start 状态管理使用流程 1、安装: npm install react-redux reduxjs/toolkit2、创建store.js 通过configureStore的hook对reducer(或slice)进行…...

Python之旅----判断语句
布尔类型和比较运算符 布尔类型 布尔类型的定义 布尔类型的字面量: True 表示真(是、肯定) False 表示假 (否、否定) 也就是布尔类型进行判断,只会有2个结果:是或否 定义变量存储布尔类型…...

【JavaEE】文件操作和IO
1 什么是文件? 针对硬盘这种持久化存储的I/O设备,当我们想要进行数据保存时,往往不是保存成一个整体,而是独立成一个个的单位进行保存,这个独立的单位就被抽象成文件的概念 2 文件路径 文件路径就是指咱们文件系统中…...
python使用dataset快速使用SQLite
目录 一、官网地址 二、安装 三、 快速使用 一、官网地址 GitHub - pudo/dataset: Easy-to-use data handling for SQL data stores with support for implicit table creation, bulk loading, and transactions. 二、安装 pip install dataset 如果是mysql,则…...

Python 练习100实例(21-40)
Python 练习实例21 题目:猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不瘾,又多吃了一个第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半零一个。到第10天…...

“创新启变 聚焦增长”极狐(GitLab)媒体沟通会,共话智能时代软件开发新生态
10 月 18 日 北京 昨日,全球领先 AI 赋能 DevSecOps 一体化平台极狐(GitLab) 在北京举办了主题为“创新启变 聚焦增长”的媒体沟通会。极狐(GitLab) CEO 柳钢就“中国企业数字化转型、软件研发、技术自主可控等热点问题,以及 AI 大模型时代下,…...
【ChatGLM2-6B】在只有CPU的Linux服务器上进行部署
简介 ChatGLM2-6B 是清华大学开源的一款支持中英双语的对话语言模型。经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,具有62 亿参数的 ChatGLM2-6B 已经能生成相当符合人类偏好的回答。结合模型量化技术,用户可以在消费级的显卡上进行本地部署&…...

Xilinx IP 10 Gigabit Ethernet Subsystem IP
Xilinx IP 10 Gigabit Ethernet Subsystem IP 10 Gb 以太网子系统在 10GBASE-R/KR 模式下提供 10 Gb 以太网 MAC 和 PCS/PMA,以提供 10 Gb 以太网端口。发送和接收数据接口使用 AXI4 流接口。可选的 AXI4-Lite 接口用于内部寄存器的控制接口。 • 设计符合 10 Gb 以太网规范…...

ubuntu下yolox tensorrt模型部署
TensorRT系列之 Windows10下yolov8 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov8 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov7 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov6 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov5 tensorrt模型加速…...

外汇天眼:外汇投资入门必看!做好3件事,任何人都能提高交易胜率
近年来外汇市场愈来愈热络,许多投资人看准世界金融变化的趋势,纷纷开始入场布局,期望把握行情大赚一笔。 如果你之前没有做过外汇交易,建议最好先透过「外汇天眼学院」学习各种相关的知识与技术分析,等到对外汇有一定的…...

idea dubge 详细
目录 一、概述 二、debug操作分析 1、打断点 2、运行debug模式 3、重新执行debug 4、让程序执行到下一次断点后暂停 5、让断点处的代码再加一行代码 6、停止debug程序 7、显示所有断点 8、添加断点运行的条件 9、屏蔽所有断点 10、把光标移到当前程序运行位置 11、单步跳过 12、…...
短视频矩阵系统/pc、小程序版独立原发源码开发搭建上线
短视频剪辑矩阵系统开发源码----源头搭建 矩阵系统源码主要有三种框架:Spring、Struts和Hibernate。Spring框架是一个全栈式的Java应用程序开发框架,提供了IOC容器、AOP、事务管理等功能。Struts框架是一个MVC架构的Web应用程序框架,用于将数…...

Linux不同格式的文件怎么压缩和解压
Linux不同格式的文件怎么压缩和解压 tar介绍不同格式文件压缩和解压 tar介绍 tar(tape archive)是一个在Unix和类Unix操作系统中用于文件打包和归档的命令行工具。它通常与其他工具(例如gzip、bzip2、xz)一起使用来创建归档文件并…...

Java 领域模型之失血、贫血、充血、胀血模型
1.失血模型 失血模型仅仅包含数据的定义和getter/setter方法,业务逻辑和应用逻辑都放到服务层中。这种类在Java中叫POJO。 action service: 核心业务(复杂度:重) model:简单Set Get dao :数据持…...

ifndef是什么,如何使用?
引言 使用HbuilderX uni-ui模板创建的uni-app项目,main.js文件中看到有如下的注释: // #ifndef VUE3 ...... // #endif // #ifdef VUE3 ...... // #endif 相信很多没有uini-app项目开发经验的朋友,初次接触uni-app项目,可…...

PXIE板卡,4口QSFP+,PCIE GEN3 X8,XILINX FPGA XCVU3P设计
PXIE板卡,4口QSFP,PCIE GEN3 X8,基于XILINX FPGA XCVU3P设计。 1:电路拓扑 ● 支持利用 EEPROM 存储数据; ● 电源时序控制和总功耗监控; 2:电路调试 3:测试 PCIE gen3 x8&#…...
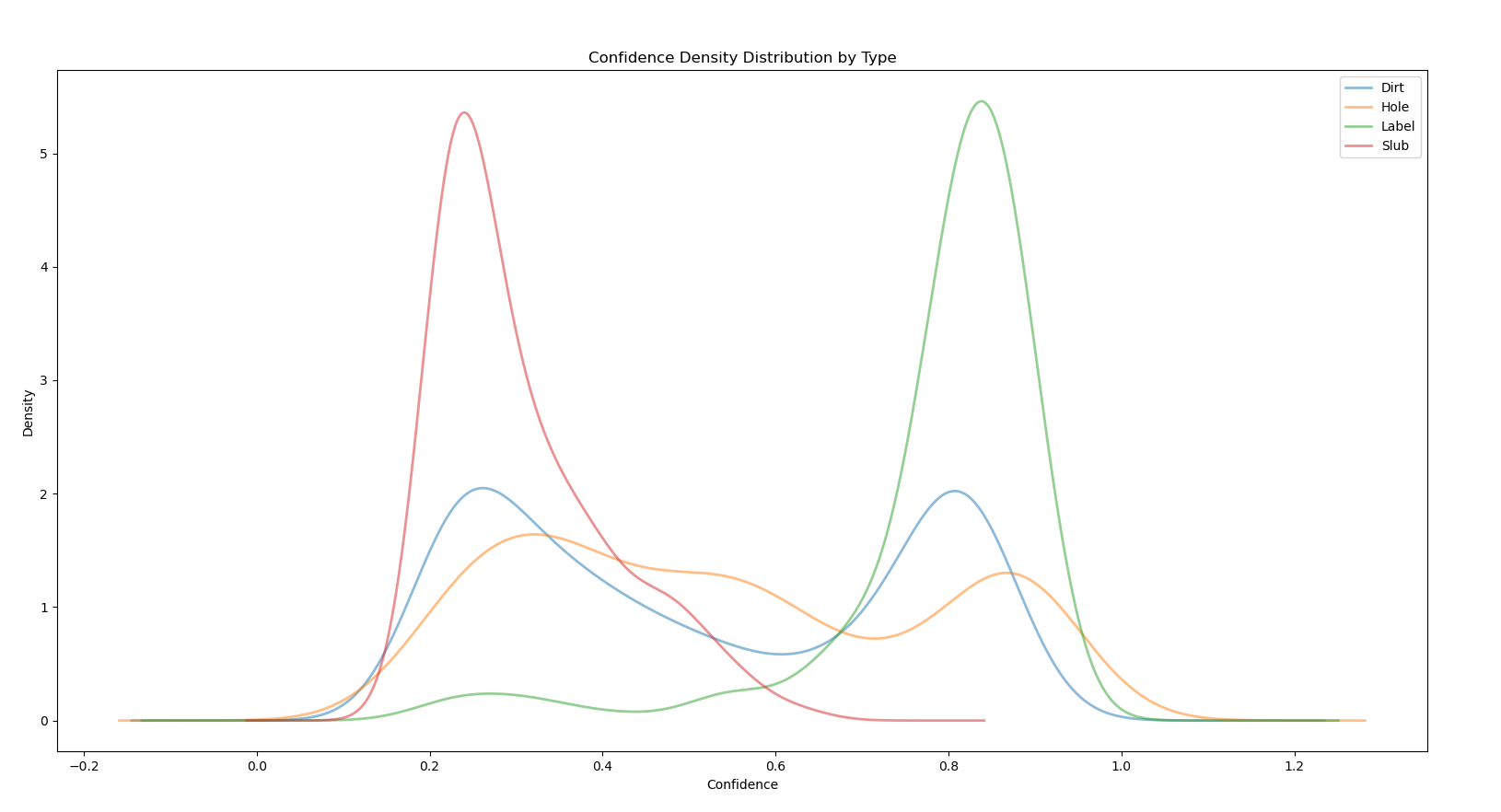
数据分析:密度图
目前拥有的数据如图,三列分别对应瑕疵种类,对应的置信 度,x方向坐标。 现在想要做的事是观看瑕疵种类和置信度之间的关系。 要显示数据分布的集中程度,可以使用以下几种常见的图形来观察: 1、箱线图(Box P…...

docker load and build过程的一些步骤理解
docker load 命令执行原理 “docker load” command, the following steps are followed to load an image from a specified tar file to the local image repository: Parsing the tar file: Docker first parses the tar file to check its integrity and verify the form…...

批量处理图像模板
以下是一个Python模板,用于批量处理图像并将处理后的图像保存在另一个文件夹中。在此示例中,将使用Pillow库来处理图像,可以使用其他图像处理库,根据需要进行修改。 首先,确保已经安装了Pillow库,可以使…...

ESP32-S3实战指南:SPI多设备管理与高效数据传输
1. ESP32-S3的SPI总线基础认知 第一次接触ESP32-S3的SPI总线时,我完全被各种专业术语搞懵了。后来在实际项目中反复折腾才发现,SPI本质上就是个"快递小哥",负责在芯片和外围设备之间搬运数据。ESP32-S3内置了4个这样的"快递站…...

千问3.5-2B科研助手应用:论文插图内容解析、实验数据图趋势简述生成
千问3.5-2B科研助手应用:论文插图内容解析、实验数据图趋势简述生成 1. 科研场景下的视觉语言模型应用 在科研工作中,论文插图和实验数据图是研究成果展示的重要载体。传统的人工解读和分析过程往往耗时费力,特别是当需要处理大量图表时。千…...

AI辅助架构设计:让快马平台智能规划trae状态管理方案
用AI辅助设计trae状态管理方案:以博客后台系统为例 最近在开发一个博客后台管理系统时,遇到了状态管理的难题。系统需要处理文章列表、编辑草稿、用户评论和系统设置等多种数据,如何合理组织这些状态让我头疼不已。幸运的是,在In…...

终极指南:如何用ImageToSTL将任何图片变成3D打印模型
终极指南:如何用ImageToSTL将任何图片变成3D打印模型 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from the left side. …...

英雄联盟智能工具League Akari:从效率提升到战术优化的全方位解决方案
英雄联盟智能工具League Akari:从效率提升到战术优化的全方位解决方案 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾在英…...

从零构建uWSGI-Nginx-Flask-Docker镜像的5个核心步骤
从零构建uWSGI-Nginx-Flask-Docker镜像的5个核心步骤 【免费下载链接】uwsgi-nginx-flask-docker Docker image with uWSGI and Nginx for Flask applications in Python running in a single container. Optionally with Alpine Linux. 项目地址: https://gitcode.com/gh_mi…...

深入解析CC Switch架构:构建AI开发工具统一管理引擎
深入解析CC Switch架构:构建AI开发工具统一管理引擎 【免费下载链接】cc-switch A cross-platform desktop All-in-One assistant tool for Claude Code, Codex, OpenCode, openclaw & Gemini CLI. 项目地址: https://gitcode.com/GitHub_Trending/cc/cc-swit…...

Phi-3-mini-4k-instruct-gguf作品展:面向开发者的技术文档摘要生成样例
Phi-3-mini-4k-instruct-gguf作品展:面向开发者的技术文档摘要生成样例 1. 模型简介 Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型GGUF版本。这个经过优化的模型特别适合处理问答、文本改写、摘要整理和简短创作等任务。作为开发者工具&…...

利用快马AI一键生成vmware虚拟机下载与配置脚本,快速搭建开发原型环境
今天想和大家分享一个快速搭建开发环境的实用技巧——利用AI工具自动生成VMware虚拟机下载与配置脚本。作为一个经常需要测试不同开发环境的程序员,我发现手动配置虚拟机实在太费时间了,直到尝试了InsCode(快马)平台的AI生成功能,整个过程变得…...

AI辅助开发:借助快马平台AI模型打造智能openclaw卸载分析工具
最近在整理开发环境时,遇到了一个棘手的问题:如何彻底卸载openclaw这个工具链。作为一个深度集成的开发套件,它会在系统各处留下各种依赖和配置文件。传统的手动卸载方式不仅效率低下,还容易遗漏关键项。于是我开始尝试用AI来优化…...