docker load and build过程的一些步骤理解
docker load 命令执行原理
“docker load” command, the following steps are followed to load an image from a specified tar file to the local image repository:
- Parsing the tar file: Docker first parses the tar file to check its integrity and verify the format.
- Extracting the files: If the parsing is successful, Docker will extract the layers of the image and its metadata to a local temporary directory.
- Importing the image: After extraction, Docker reads the metadata from the tar file, including the configuration information of the image and the contents of each layer.
- Creating and loading the image layers: Based on the metadata, Docker creates each layer of the image one by one and loads them into the local image repository.
- Creating the image and applying labels: Once all the layers of the image are loaded, Docker creates the image based on the configuration information in the metadata and applies corresponding labels to the image.
- Cleaning up temporary files: After loading is complete, Docker cleans up the extracted files in the local temporary directory.
基本说明
"docker load"命令用于将本地文件中的镜像加载到Docker中。它接受一个tar文件作为参数,该文件包含了Docker镜像的所有层和元数据信息。
文件的分层处理指的是Docker镜像的构建过程中,每个步骤都会生成一个层(layer)。每个层都包含了文件系统的一部分,例如文件、目录和权限等。这些层构成了Docker镜像的文件系统。在加载镜像时,Docker会根据文件的顺序将这些层解压并组合在一起,以构建完整的镜像文件系统。
文件校验和是用于验证镜像文件的完整性的一种保证机制。每个层在构建时都会计算并生成一个校验和(checksum),用于表示该层的内容是否完整且无误。当使用"docker load"命令加载镜像时,Docker会比较镜像文件中的每个层的校验和和实际的文件内容,以确保文件的完整性和正确性。
总结起来,"docker load"命令将通过文件分层处理的方式将Docker镜像的文件系统解压并组合在一起,同时使用文件校验和来验证镜像文件的完整性和正确性。这样可以确保在加载镜像时获得完整、正确的镜像文件系统。
docker build 命令执行原理
The Docker build process is designed and integrated around the concept of file system abstraction. Docker provides a layered file system architecture that allows for efficient storage and retrieval of images and containers.
The file system abstraction in Docker is based on layers. Each layer represents a specific modification or addition to the file system. Layers can be created from a base image or from other layers, allowing for incremental changes and reusability.
During the Docker build process, a Dockerfile is used to define the steps required to build an image. Each step in the Dockerfile can modify or add files to the file system. Docker uses a technology called Union File System (UFS) to overlay these modifications on top of each other, creating a layered file system.
When building an image, Docker starts with a base image that serves as the initial layer. Each subsequent step in the Dockerfile will add a new layer on top of the previous ones. This layered approach allows for efficient image sharing and reuse, as layers that are already present in the system can be reused when building new images.
Docker also uses a copy-on-write strategy to optimize the use of storage. When a container is created from an image, only the differences between the container and the image are stored, rather than creating a complete copy. This allows for efficient use of disk space and faster container startup times.
docker --platform 参数说明
使用–platform参数可以构建跨平台的Docker镜像。
–platform参数接受一个格式为os/arch的字符串,例如linux/arm表示ARM架构。您可以使用这个参数来指定要构建的镜像支持的操作系统和架构。
Starting from Docker 19.03 version, the --platform parameter is supported. This parameter is used to specify on which platform the container should run. With the --platform parameter, you can specify that a container should run on a specific operating system architecture, such as linux/arm64 (ARM architecture) or linux/amd64 (x86 architecture).
The --platform flag is useful when you are working with multi-architecture environments or when you want to ensure that a container runs on a specific hardware platform. By specifying the platform with --platform, Docker will select the appropriate image or build context for that platform and run the container accordingly.
For example, if you have a Dockerfile that has specific instructions for ARM-based systems, you can specify --platform linux/arm64 when building the image. This tells Docker to select the appropriate base image and ensure that the resulting container runs on ARM64 architecture.
To summarize, the --platform flag in Docker allows you to specify on which platform your containers should run, ensuring compatibility and portability across different architectures.
Docker 构建过程的分层
Docker 构建过程的分层设计思想源于 Linux 内核的 union fs(联合文件系统),它将多个文件系统合并为一个单一的文件系统,从而实现对多个文件系统的管理。在 Docker 中,这种分层设计可以有效地管理和组织镜像的各个层次,使得镜像的大小得到优化,同时也提高了镜像的构建和加载速度。
在 Docker 构建过程中,每个指令都会创建一个新的镜像层,并添加到基础镜像中。这些层可以被看作是镜像的一个个切片,每个切片都包含了一组文件和目录。这种分层设计使得镜像的构建过程更加灵活和可扩展,因为我们可以根据需要添加或删除层,而不需要重新构建整个镜像。
在 Docker 镜像加载过程中,Docker 会从底层开始,依次加载每一层。每一层都会被加载到一个独立的文件系统中,这些文件系统会被合并为一个单一的文件系统,然后挂载到容器的根文件系统中。这样,我们就可以在容器内部访问到镜像中的所有文件和目录。
这种分层设计和加载过程使得 Docker 镜像具有很高的灵活性。我们可以根据需要修改或删除镜像的任何部分,而不需要重新构建整个镜像。同时,由于每个层都被加载到一个独立的文件系统中,因此即使某个层出现问题,也不会影响到其他层,从而确保了镜像的完整性。
Linux 内核的 union fs(联合文件系统)
Linux内核的union fs(联合文件系统)是一种特殊的文件系统,它可以将多个目录结合起来,形成一个单一的逻辑目录。每个目录可以是一个独立的文件系统,称为原始文件系统。联合文件系统会将这些原始文件系统层叠在一起,并提供一个单一的视图。
联合文件系统的主要功能是将不同的目录树合并为一个统一的目录。当用户在联合文件系统的目录中进行读写操作时,实际上是对底层原始文件系统进行读写操作。这使得用户可以在单一的目录结构中同时访问不同的文件系统,而不需要切换到不同的目录。
联合文件系统的核心思想是使用层叠挂载(stacked mount)来实现。在创建联合文件系统时,可以指定多个原始文件系统,并指定它们在层次结构中的顺序。各个原始文件系统按照指定的顺序进行挂载,形成一棵层次结构的目录树。当进行文件操作时,联合文件系统会按照层次结构从上到下逐层搜索对应的文件。
联合文件系统还提供了一些特殊的操作方式,如只读模式挂载、白名单挂载和黑名单挂载。这些操作方式可以根据用户的需求来控制对原始文件系统的读写权限。
总体而言,联合文件系统是一种非常有用的文件系统技术,可以简化文件系统的管理和使用。它在容器技术中得到广泛应用,可以将多个容器的文件系统层叠在一起,实现资源隔离和快速部署。
层叠挂载(stacked mount)
层叠挂载(stacked mount)是指在计算机系统中将一个文件系统挂载到另一个文件系统上的过程。这种挂载方式允许将多个文件系统层叠在一起,形成一个逻辑上统一的文件系统层级结构。
通过层叠挂载,可以将不同类型的文件系统组合在一起,使其共同作为一个整体可访问的文件系统。这样做的一个常见应用是将一个网络文件系统(NFS、CIFS等)挂载到本地文件系统上,使远程文件系统中的文件和目录在本地文件系统中以普通文件和目录的形式可见。
在层叠挂载中,挂载的文件系统称为上层文件系统,被挂载的文件系统称为下层文件系统。上层文件系统中的访问操作会经过上层文件系统的处理,然后传递到下层文件系统中进行具体的操作。这样,上层文件系统就可以给下层文件系统提供额外的功能,如加密、压缩、快照等。
层叠挂载的一个重要特性是透明性,即上层文件系统对下层文件系统的存在是透明的,上层文件系统的用户无需关注下层文件系统的细节。用户只需要在上层文件系统中进行操作,而无需关心实际文件和目录所在的具体位置。
层叠挂载还可以通过挂载选项进行灵活配置。例如,可以选择以只读模式挂载下层文件系统,或者将下层文件系统的某个子目录挂载到上层文件系统的特定位置等。
总之,层叠挂载提供了一种灵活和强大的文件系统管理方式,允许在计算机系统中灵活组合和扩展文件系统,提供更高级别的文件系统功能。
SHA256 在docker中的设计和集成思想
The primary design and integration principles of SHA256 in Docker are as follows:
- Security: SHA256 is a cryptographic hash function that ensures data integrity and security. It is used to generate a unique hash value for the contents of a Docker image or a layer. This makes it easier to verify the authenticity and integrity of the image or layer.
- Content Addressing: Docker uses SHA256 as a content addressing mechanism. Each layer of an image is identified by its SHA256 hash, which means if the content of a layer changes, the hash will change as well. This allows Docker to quickly determine if any changes have been made to an image or a layer.
- Immutable Images: Docker promotes the use of immutable images, meaning that their contents cannot be modified once they are built. SHA256 plays a key role in enforcing immutability by ensuring that the hash of an image or a layer remains consistent.
- Layered Architecture: Docker uses a layered architecture, where each layer represents a change or modification to an existing image. The SHA256 hash is used to uniquely identify and reference each layer, allowing Docker to efficiently utilize caching and deduplication techniques.
- Integrating with Container Runtime: Docker integrates SHA256 with its container runtime to ensure that the image being run is the same as the one that was built. The runtime checks the hash of the image and its layers before execution to validate its integrity and prevent any tampering.
SHA-256在Docker中的设计思想主要包括以下几个方面:
- 安全性:SHA-256是一种加密哈希算法,它具有很高的安全性。在Docker中,每个镜像和容器都有一个唯一的SHA-256标识符,该标识符是使用镜像内容计算得出的哈希值。通过SHA-256标识符,可以确保镜像和容器的内容完整性,并防止篡改。
- 基于内容寻址:Docker中的镜像都是通过内容寻址来访问的,这意味着每个镜像的位置和访问方式都是根据其SHA-256标识符来确定的。这种设计使得镜像可以追溯到其原始内容,而不是依赖于特定的位置或名称。
- 冗余删除:SHA-256标识符可以用于确定镜像是否存在于本地,并在不同的Docker主机之间进行镜像的复制和分享。当多个Docker主机之间存在相同的镜像时,只需在其中一个主机上保存一份镜像,其他主机可以通过SHA-256标识符来引用该镜像,避免了冗余的存储。
- 版本控制:由于每个镜像都有唯一的SHA-256标识符,Docker可以轻松管理和控制镜像的版本。当对一个镜像进行更改时,会生成一个新的SHA-256标识符,并与原始版本进行区分。这使得可以方便地进行版本回滚和管理。
Docker image ID
Docker image ID is generated based on the image’s content and metadata using a cryptographic hash function called SHA256.
When a new Docker image is created, Docker examines the content and metadata of the image, including the filesystem layers, the image configuration, and any other information relevant to the image. It then applies the SHA256 algorithm to this data to generate a unique 64-character hexadecimal identifier.
This process ensures that each image has a unique identifier that effectively represents its content. Any changes made to the content or metadata will result in a different image ID. This allows Docker to efficiently identify and track images, as well as determine if two images are identical or different.
Docker Image ID 是由 Docker 根据镜像的描述文件在本地计算生成的,用于在 imagedb 数据库中作为目录名称。Docker 镜像 ID 保存在 /var/lib/docker/image/overlay2/imagedb/content/sha256 目录下,以 sha256sum 计算文件内容得出的哈希值命名。
具体而言,Image ID 是根据镜像的配置信息(config)计算得出的,该信息包含在镜像的 JSON 描述文件中。Docker 使用这些配置信息来计算 Image ID,以确保每个镜像都有唯一的 ID。计算 Image ID 的具体步骤并未明确,但可以确定的是,它是基于镜像内容(包括配置信息和各层的 diffID)进行哈希计算的结果。因此,即使镜像的内容完全相同,计算出的 Image ID 也会相同。
当拉取新的镜像时,Docker 会重新计算 Image ID,如果本地已经存在相同的 Image ID,则会直接使用本地已有的镜像,而不会再次下载。这样可以提高效率并避免重复下载相同的镜像。
总之,Docker Image ID 是根据镜像的配置信息和各层内容通过哈希算法计算得到的唯一标识符,用于在 Docker 中管理镜像。
docker 中的安全机制和参数
Docker内置了一系列安全机制,这些机制有助于保护容器和宿主机的安全。在设计--security参数时,Docker考虑了以下几个内置的安全机制:
- 命名空间隔离:Docker使用命名空间来隔离容器的进程、网络、文件系统和其他资源,以避免容器之间的相互影响。
- 控制组(cgroups):Docker利用cgroups来限制容器对系统资源的访问和使用,通过设置资源限制,可以防止容器过度消耗主机资源。
- 安全标签:Docker通过安全标签(SELinux或AppArmor)来控制容器的访问权限,防止容器越权访问主机上的敏感资源。
- 用户命名空间:Docker使用用户命名空间,将容器内的特权用户映射到宿主机上的非特权用户,从而减少特权容器对主机的影响。
- 容器镜像验证:Docker支持通过签名和校验镜像的手段,以确保镜像的完整性和来源的真实性。这样可以避免运行恶意或被篡改的镜像。
综上所述,--security参数的设计考虑了Docker内置的一些安全机制,以提供额外的灵活性和控制,以满足特定场景下的需求。用户可以根据自身情况,权衡安全性和便利性,并选择相应的安全配置。
相关文章:

docker load and build过程的一些步骤理解
docker load 命令执行原理 “docker load” command, the following steps are followed to load an image from a specified tar file to the local image repository: Parsing the tar file: Docker first parses the tar file to check its integrity and verify the form…...

批量处理图像模板
以下是一个Python模板,用于批量处理图像并将处理后的图像保存在另一个文件夹中。在此示例中,将使用Pillow库来处理图像,可以使用其他图像处理库,根据需要进行修改。 首先,确保已经安装了Pillow库,可以使…...
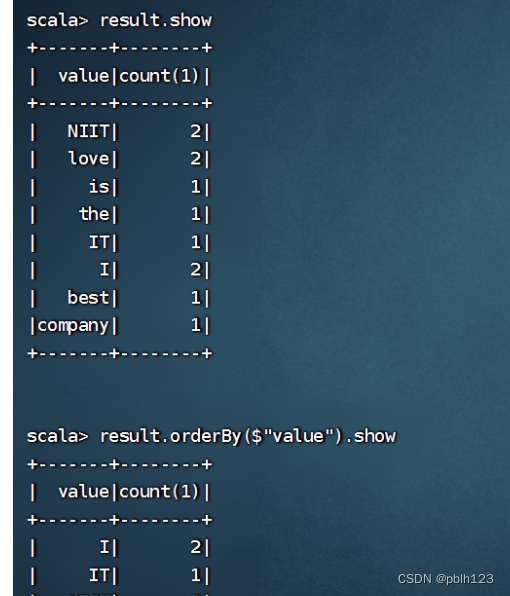
2023_Spark_实验十四:SparkSQL入门操作
1、将emp.csv、dept.csv文件上传到分布式环境,再用 hdfs dfs -put dept.csv /input/ hdfs dfs -put emp.csv /input/ 将本地文件put到hdfs文件系统的input目录下 2、或者调用本地文件也可以。区别:sc.textFile("file:///D:\\temp\\emp.csv&qu…...
如何将几个模型合并成一个
1、什么时候需要合并模型? 组装和装配:当你需要将多个零件或组件组装成一个整体时,可以合并它们成为一个模型。例如,在制造业中,当需要设计和展示一个完整的机械装置或产品时,可以将各个零部件合并成一个模…...

异常气体识别与飘移
Olfactory Target/Background Odor Detection via Self-expression Model 解决非目标气体检测 摘要:提出了SeELM模型(自表达ELM模型) 分为两步:1.对获得的数据集进行建模,计算出自我表达系数矩阵,2.对于异…...

分类预测 | Matlab实现WOA-BiLSTM鲸鱼算法优化双向长短期记忆神经网络的数据多输入分类预测
分类预测 | Matlab实现WOA-BiLSTM鲸鱼算法优化双向长短期记忆神经网络的数据多输入分类预测 目录 分类预测 | Matlab实现WOA-BiLSTM鲸鱼算法优化双向长短期记忆神经网络的数据多输入分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现WOA-BiLSTM鲸鱼算法…...
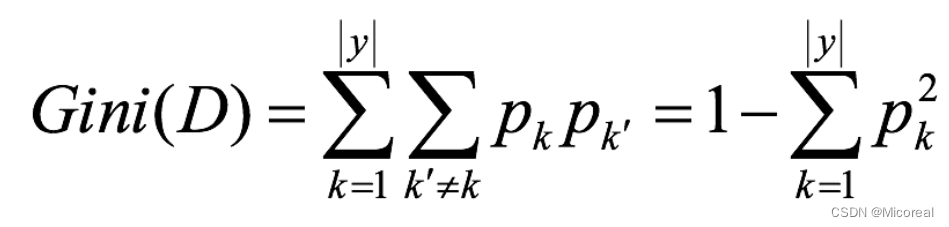
35 机器学习(三):混淆矩阵|朴素贝叶斯|决策树|随机森林
文章目录 分类模型的评估混淆矩阵精确率和召回率 接口介绍其他的补充 朴素贝叶斯基础原理介绍拉普拉斯平滑下面给出应用的例子朴素贝叶斯的思辨 决策树基础使用基本原理信息熵信息增益信息增益率Gini指数 剪枝api介绍 随机森林------集成学习初识基本使用api介绍 分类模型的评估…...

ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+
该错误提示表示您的 OpenSSL 版本过低,无法兼容 urllib3 v2.0。 解决此问题的方法是升级您的 OpenSSL 版本至 1.1.1 或以上。具体操作如下: 方法一: 检查您的 OpenSSL 版本,使用以下命令: openssl version 如果您的…...

webrtc gcc算法(1)
老的webrtc gcc算法,大概流程: 这两个拥塞控制算法分别是在发送端和接收端实现的, 接收端的拥塞控制算法所计算出的估计带宽, 会通过RTCP的remb反馈到发送端, 发送端综合两个控制算法的结果得到一个最终的发送码率,并以…...

2022年亚太杯APMCM数学建模大赛C题全球变暖与否全过程文档及程序
2022年亚太杯APMCM数学建模大赛 C题 全球变暖与否 原题再现: 加拿大的49.6C创造了地球北纬50以上地区的气温新纪录,一周内数百人死于高温;美国加利福尼亚州死亡谷是54.4C,这是有史以来地球上记录的最高温度;科威特53…...

苹果开发者 Xcode发布TestFlight全流程
打包前注意事项 使用Xcode导出安装包之前,必须先确认账户的所有合约是否全部同意,如果有不同意的,在出包的时候会弹出报错 这是什么意思 这意味着您有一些需要在应用商店连接上验证的协议(protocol)/契约(Contract)。解决方案 连接到应用商店…...
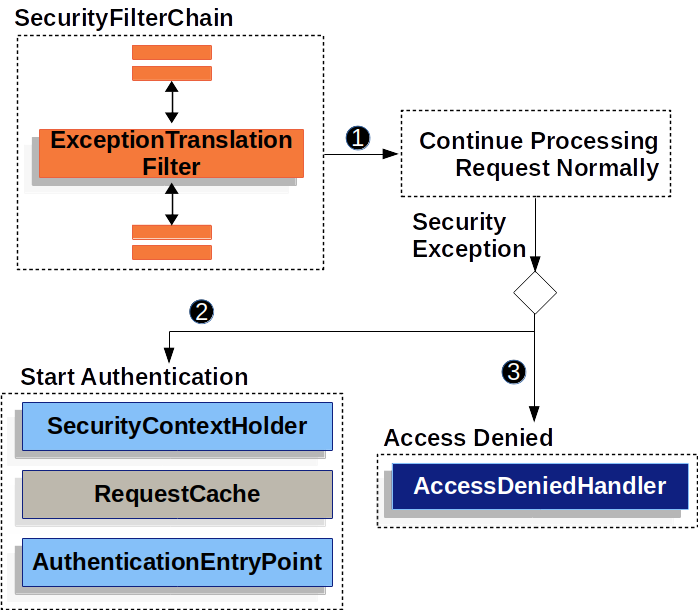
Spring Security—Servlet 应用架构
目录 一、Filter(过滤器)回顾 二、DelegatingFilterProxy 三、FilterChainProxy 四、SecurityFilterChain 五、Security Filter 六、打印出 Security Filter 七、添加自定义 Filter 到 Filter Chain 八、处理 Security 异常 九、保存认证之间的…...
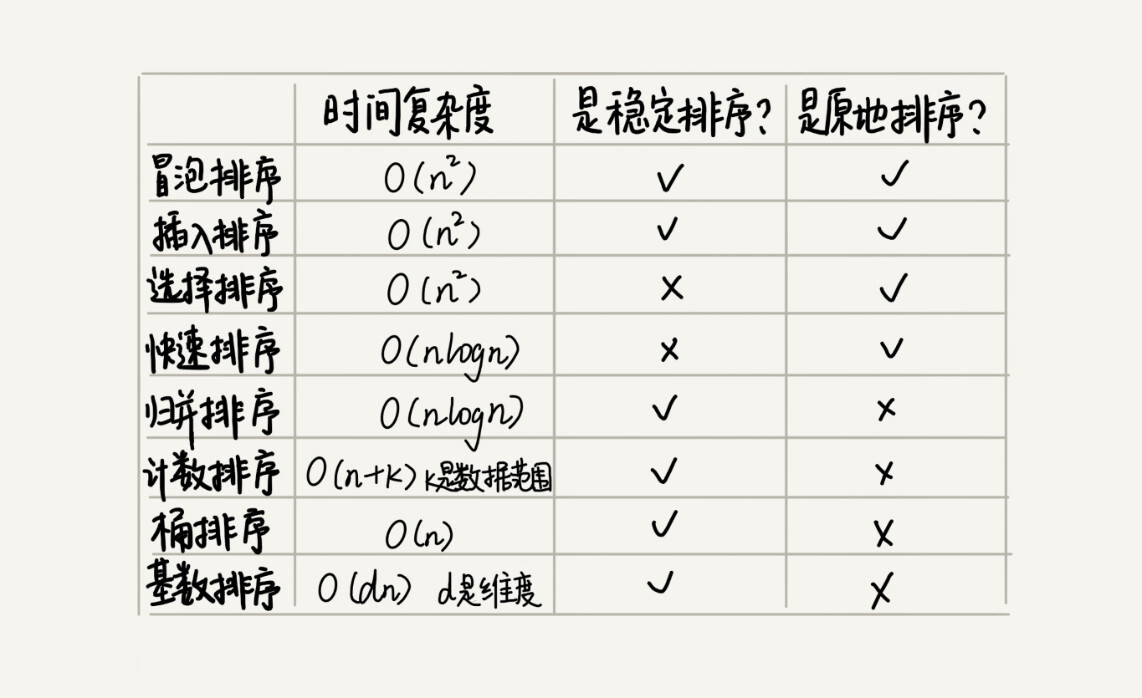
排序优化:如何实现一个通用的、高性能的排序函数?
文章来源于极客时间前google工程师−王争专栏。 几乎所有的编程语言都会提供排序函数,比如java中的Collections.sort()。在平时的开发中,我们都是直接使用,这些排序函数是如何实现的?底层都利用了哪种排序算法呢? 问题…...
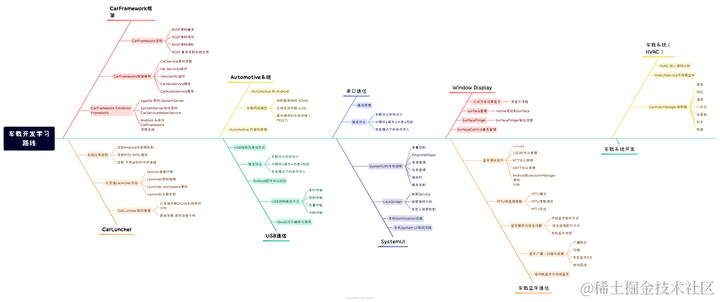
车载开发学习——CAN总线
CAN总线又称为汽车总线,全程为“控制器局域网(Controller Area Network)”,即区域网络控制器,它将区域内的单一控制单元以某种形式连接在一起,形成一个系统。在这个系统内,大家以一种大家都认可…...

2023年知名国产数据库厂家汇总
随着信创国产化的崛起,大家纷纷在寻找可替代的国产数据库厂家。这里小编就给大家汇总了一些国内知名数据库厂家,仅供参考哦! 2023年知名国产数据库厂家汇总 1、人大金仓 2、瀚高 3、高斯 4、阿里云 5、华为云 6、浪潮 7、达梦 8、南大…...

【ARM Coresight SoC-400/SoC-600 专栏导读】
文章目录 1. ARM Coresight SoC-400/SoC-600 专栏导读目录1.1 Coresight 专题1.1.1 Performance Profiling1.1.2 ARM Coresight DS-5 系列 1. ARM Coresight SoC-400/SoC-600 专栏导读目录 本专栏全面介绍 ARM Coresight 系统 及SoC-400, SoC-600 中的各个组件。 1.1 Coresigh…...

在Go中创建自定义错误
引言 Go提供了两种在标准库中创建错误的方法,[errors.New和fmt.Errorf],当与用户交流更复杂的错误信息时,或在调试时与未来的自己交流时,有时这两种机制不足以充分捕获和报告所发生的情况。为了传达更复杂的错误信息并实现更多的…...
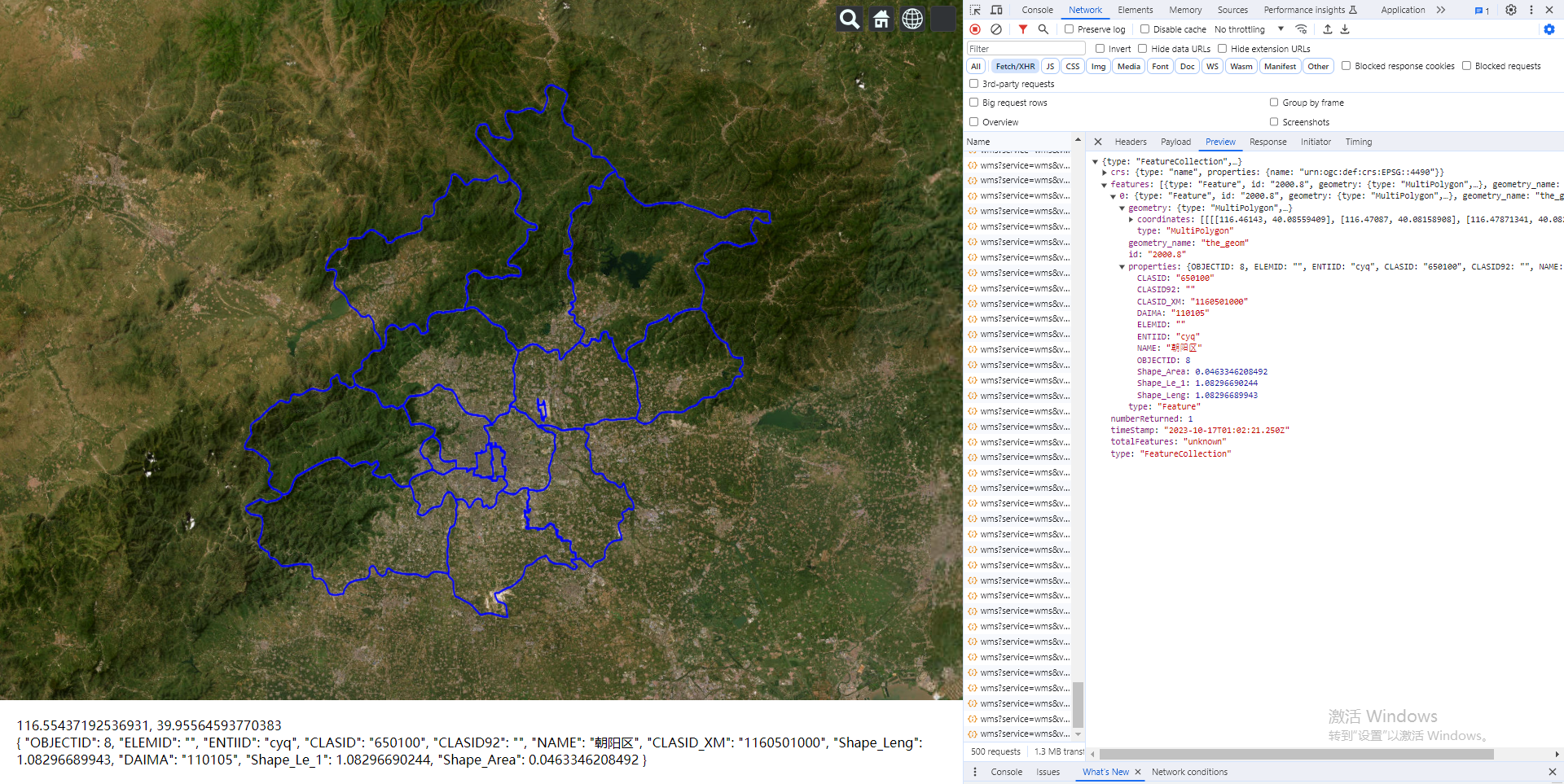
Vue.js2+Cesium1.103.0 十三、通过经纬度查询 GeoServer 发布的 wms 服务下的 feature 对象的相关信息
Vue.js2Cesium1.103.0 十三、通过经纬度查询 GeoServer 发布的 wms 服务下的 feature 对象的相关信息 Demo <template><divid"cesium-container"style"width: 100%; height: 100%;"><div style"position: absolute;z-index: 999;bott…...
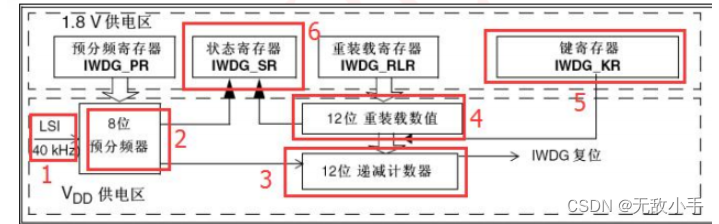
使用STM32怎么喂狗 (IWDG)
STM32F1 的独立看门狗(以下简称 IWDG)。 STM32F1内部自带了两个看门狗,一个是独立看门狗 IWDG,另一个是窗口看门狗 WWDG, 本章只介绍独立看门狗 IWDG,窗口看门狗 WWDG 会在后面章节介绍。 本章要实现的功能…...
GEE:计算和打印GEE程序的执行时间
作者:CSDN @ _养乐多_ 本文记录了计算和打印程序的执行时间的Google Earth Engine (GEE)代码,并举例说明。 大家在执行GEE代码的时候,有时候为了对比两个不同的脚本,不知道代码执行花费了多少时间。本文记录了打印代码执行时间的函数,并举了一个应用案例说明。可以知道…...

Escornabot-lib:面向教育机器人的Arduino语义化控制库
1. Escornabot-lib 库概述Escornabot-lib 是一个专为 Escornabot 教育机器人设计的 Arduino C 类库,由 ROBOteach 团队维护,采用 GNU GPL v3.0 开源协议。该库并非仅提供抽象接口,而是完整封装了 Escornabot 硬件平台的全部底层驱动、状态管理…...

公司SEO推广有哪些常见的误区需要避免
公司SEO推广有哪些常见的误区需要避免 在数字化营销的时代,公司SEO推广已经成为提升网站流量和品牌知名度的重要手段。在实际操作中,许多企业在SEO推广过程中常常犯下一些常见的误区,这些误区不仅影响了SEO的效果,还可能导致资源…...

OpenClaw自动化简历投递:Qwen3-14B智能匹配职位要求
OpenClaw自动化简历投递:Qwen3-14B智能匹配职位要求 1. 为什么需要自动化简历投递? 去年秋天,当我开始寻找新的工作机会时,面对数百个招聘岗位,我陷入了"海投困境":每份简历都需要根据JD(职位描…...

【数据结构与算法】第19篇:树与二叉树的基础概念
一、什么是树1.1 树的定义树是 n(n ≥ 0)个节点的有限集合。当 n 0 时称为空树。任意非空树满足:有且仅有一个根节点其余节点可分为 m 个互不相交的子树现实中的例子:文件系统、公司组织架构、网页DOM树。1.2 树的术语画一棵树来…...

数据库运维与数据安全:备份恢复、日志分析与故障排查
下面的内容大家根据实际情况,公司的业务还有重点择机选择,不是所有的蓝翔都有挖掘机 如果说之前的索引优化是“飙车”,那么今天的主题就是“系安全带”和“买保险”。 在运维的世界里,没有“如果”,只有“万一”。当…...
)
Simulink双矢量MPC实战:从郭磊磊论文到可运行的Matlab Function代码(调制模型预测控制详解)
Simulink双矢量MPC实战:从理论到代码的完整实现路径 当我在实验室第一次尝试复现郭磊磊老师那篇经典论文时,面对12种矢量组合和复杂的PWM生成逻辑,完全不知从何下手。经过三个月的反复试验和代码调试,终于摸清了从论文公式到可运行…...

轻舟体重管理大模型:赋能减重全病程管理,构建智能体重健康生态
在“健康中国2030”战略深入推进的背景下,慢性病防控与全民体重管理已成为公共卫生体系的重要议题。随着肥胖及相关代谢性疾病发病率持续上升,传统的体重干预模式已难以满足全人群、全生命周期的健康管理需求。在此趋势下,基于人工智能技术的…...

Wan 3D Causal VAE:一篇讲清视觉 token、时间压缩、3D Causal 卷积
从 Emu3.5、Show-o2、Show-o、Chameleon,到 Wan 3D Causal VAE:一篇讲清视觉 token、时间压缩、3D Causal 卷积和数据量估算的入门分析 0. 先说这篇文章要解决什么问题 这篇文章想回答 6 个问题: Emu3.5、Show-o2、Show-o、Chameleon 这几类 UMM,到底是怎么表示图像和视频…...

AI营销SaaS榜单评测:原圈科技如何助力品牌客户破局增长?
本文深度探讨AI营销行业趋势与SaaS产品评选标准。在众多解决方案中,原圈科技的AI营销SaaS平台凭借其领先的技术底层能力、产品成熟度及客户成功案例,在市场适配度与服务落地性等多个维度下表现突出,被普遍视为企业实现精细化营销升级的有力选…...

【JupyterLab实战】构建跨平台AI算力监控仪表盘
1. 为什么需要跨平台AI算力监控? 在AI开发过程中,我们经常遇到这样的场景:模型训练到一半突然卡死,却不知道是GPU内存爆了还是CPU瓶颈;多卡并行时某张卡莫名其妙跑不满;昇腾芯片的温度报警频繁触发却找不到…...