35 机器学习(三):混淆矩阵|朴素贝叶斯|决策树|随机森林
文章目录
- 分类模型的评估
- 混淆矩阵
- 精确率和召回率
- 接口介绍
- 其他的补充
- 朴素贝叶斯
- 基础原理介绍
- 拉普拉斯平滑
- 下面给出应用的例子
- 朴素贝叶斯的思辨
- 决策树
- 基础使用
- 基本原理
- 信息熵
- 信息增益
- 信息增益率
- Gini指数
- 剪枝
- api介绍
- 随机森林------集成学习初识
- 基本使用
- api介绍
分类模型的评估
一般最常见使用的是准确率,即预测结果正确的百分比,我们之前写的那个KNN所使用的就是准确率,但是实际上在很多的别的使用场景上,我们关注的并不只有准确性,比如后面会举一个个人理解的例子,进行分析。
混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵。
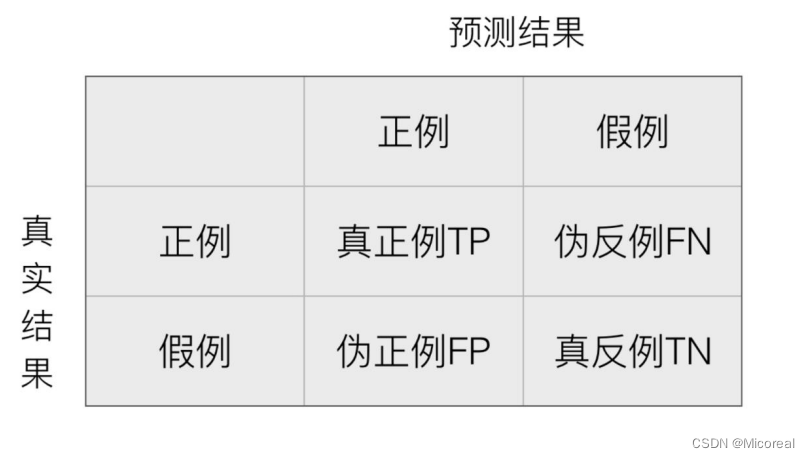
这边的理解我们带入例子,进行理解,并理解一下为什么只有准确度并不能完全说明这个模型预测的好坏,我们把这个带入医生系统,去判断病人是否有病
TP:病人有病,被你预测成有病。
TN:病人没病,被你预测成没病。
FP:病人没病,被你预测成有病。
FN:病人有病,被你预测成没病。
明显对于医生预测系统来说,我们除了关注准确度来说,FN也是一个关键值,对于一个病人有病,却被诊断为没病,这是非常致命的缺陷,我们甚至希望牺牲掉部分准确性,去提升这一事故的发生。
精确率和召回率
精确率:预测结果为正例样本中真实为正例的比例(查得准):TP/TP+FP
召回率:真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力):TP/TP+FN
接口介绍
这个只是做接口介绍,具体的使用放在下面的朴素贝叶斯进行使用。
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )y_true:真实目标值
y_pred:估计器预测目标值
labels:指定类别对应的数字
target_names:目标类别名称
return:每个类别精确率与召回率
其他的补充
参考链接:链接1
链接2
朴素贝叶斯
基础原理介绍
在学习概率论的时候,我们已经学习过了朴素贝叶斯,这是一个后验概率。
详细见链接
下面讲点,自己的理解:
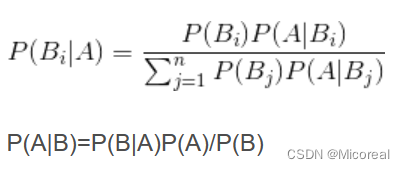
即我们对于这个公式的分类理解:
我们现在想要做一个根据文章出现的关键词,进行判断这篇文章是不是属于科技类的新闻,那么概率就是P(科技|‘云计算’ ‘高帧’ ‘计算机’···),但这个概率明显是没有办法进行求取的,但是我们可以根据这个贝叶斯公式进行转化
直接变成(P(云计算|科技) * P(科技) * ···)/ P(‘云计算’ ‘高帧’ ‘计算机’···)
这明显都可以根据已有的条件进行推出,这也就是这个公式的意义。
朴素贝叶斯的实现API:
sklearn.naive_bayes.MultinomialNB
拉普拉斯平滑
在求取概率的时候,有时候由于每个参数出现的次数太少,然后根据我们上面的公式一个为0之后,那么之后所有的样本都不用进行计算,直接全为0了,所以我们这边采用拉普拉斯平滑进行处理,让其脱离0的局限。
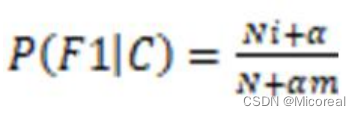
处理就是在求条件概率的时候,上方加上一个alpha,下方加上alpha*样本数目。
实现接口:
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
下面给出应用的例子
数据就是20类新闻的那个数据。
# 朴素贝叶斯进行文本分类 以及使用检测那个混淆矩阵的 精确率和回归率
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report,roc_auc_score# 数据准备 sklearn就是好啊,直接给的都不需要进行数据处理
news = fetch_20newsgroups(subset='all', data_home='dataset')
print(len(news.data)) # 看一下共有多少条新闻# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=1)# 开始特征工程的工作 对数据集进行特征抽取 这一部分之前也讲解过,不细看,由于这个数据是纯英文的,所以不需要进行jieba分词
tfidef = TfidfVectorizer()
x_train = tfidef.fit_transform(x_train)
x_test = tfidef.transform(x_test)# 训练 准备开始训练
# 进行朴素贝叶斯算法的预测,alpha是拉普拉斯平滑系数,分子和分母加上一个系数,分母加alpha*特征词数目
mlt = MultinomialNB(alpha=1.0)# 开始训练
mlt.fit(x_train, y_train)# 训练结束 开始预测
y_predict = mlt.predict(x_test)# 得出准确率,这个是很难提高准确率,为什么呢?
print("准确率为:", mlt.score(x_test, y_test))# 计算精准率和召回率
print("每个类别的精确率和召回率:\n", classification_report(y_test, y_predict, target_names=news.target_names))# 把0-19总计20个分类,变为0和1 这个是计算AUC用的,AUC只能用于二分类
y_test = np.where(y_test == 0, 1, 0)
y_predict = np.where(y_predict == 0, 1, 0)
# roc_auc_score的y_test只能是二分类,针对多分类如何计算AUC
print("AUC指标:\n", roc_auc_score(y_test, y_predict))
输出:
18846
准确率为: 0.8518675721561969
每个类别的精确率和召回率:precision recall f1-score supportalt.atheism 0.91 0.77 0.83 199comp.graphics 0.83 0.79 0.81 242comp.os.ms-windows.misc 0.89 0.83 0.86 263
comp.sys.ibm.pc.hardware 0.80 0.83 0.81 262comp.sys.mac.hardware 0.90 0.88 0.89 234comp.windows.x 0.92 0.85 0.88 230misc.forsale 0.96 0.67 0.79 257rec.autos 0.90 0.87 0.88 265rec.motorcycles 0.90 0.95 0.92 251rec.sport.baseball 0.89 0.96 0.93 226rec.sport.hockey 0.95 0.98 0.96 262sci.crypt 0.76 0.97 0.85 257sci.electronics 0.84 0.80 0.82 229sci.med 0.97 0.86 0.91 249sci.space 0.92 0.96 0.94 256soc.religion.christian 0.55 0.98 0.70 243talk.politics.guns 0.76 0.96 0.85 234talk.politics.mideast 0.93 0.99 0.96 224talk.politics.misc 0.98 0.56 0.72 197talk.religion.misc 0.97 0.26 0.41 132accuracy 0.85 4712macro avg 0.88 0.84 0.84 4712weighted avg 0.87 0.85 0.85 4712AUC指标:0.8827602448315142
朴素贝叶斯的思辨
优点:
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
- 分类准确度高,速度快
缺点:
- 需要知道先验概率 P(F1,F2,…|C),因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
- 假设了文章当中一些词语另外一些是独立没关系—-如果有关系,会造成不太靠谱
- 训练集当中去进行统计词这些工作 文章收集的不好,比如有作弊文章,充斥某个词会对结果造成干扰
朴素贝叶斯常用于文本领域,但是现在神经网络的transformer做的更好,朴素贝叶斯也属于lazy learning的类型的。
决策树
基础使用
# 决策树
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier# 获取数据 观察数据的内容
titan = pd.read_csv("./dataset/titanic/titan_train.csv")# 确定特征值 目标值
x = titan[["Pclass", "Age", "Sex"]]
y = titan["Survived"]
print(x.info()) # 打印出来说明存在nan
print(x.shape)
print('-'*20)# 处理空值 直接平均值填写吧
im = SimpleImputer(missing_values=np.nan, strategy='mean')
x['Age'] = im.fit_transform(x[['Age']])# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)# 查看数据,存在字符串,所以需要转化为one-hot Dict顾名思义需要传入的是字典
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))# 决策树训练
estimator = DecisionTreeClassifier(criterion="entropy", max_depth=5)
estimator.fit(x_train, y_train)# 模型评估
print(estimator.score(x_test, y_test))
输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 3 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Pclass 891 non-null int64 1 Age 714 non-null float642 Sex 891 non-null object
dtypes: float64(1), int64(1), object(1)
memory usage: 21.0+ KB
None
(891, 3)
--------------------
0.7757847533632287
基本原理
决策树的基本原理:
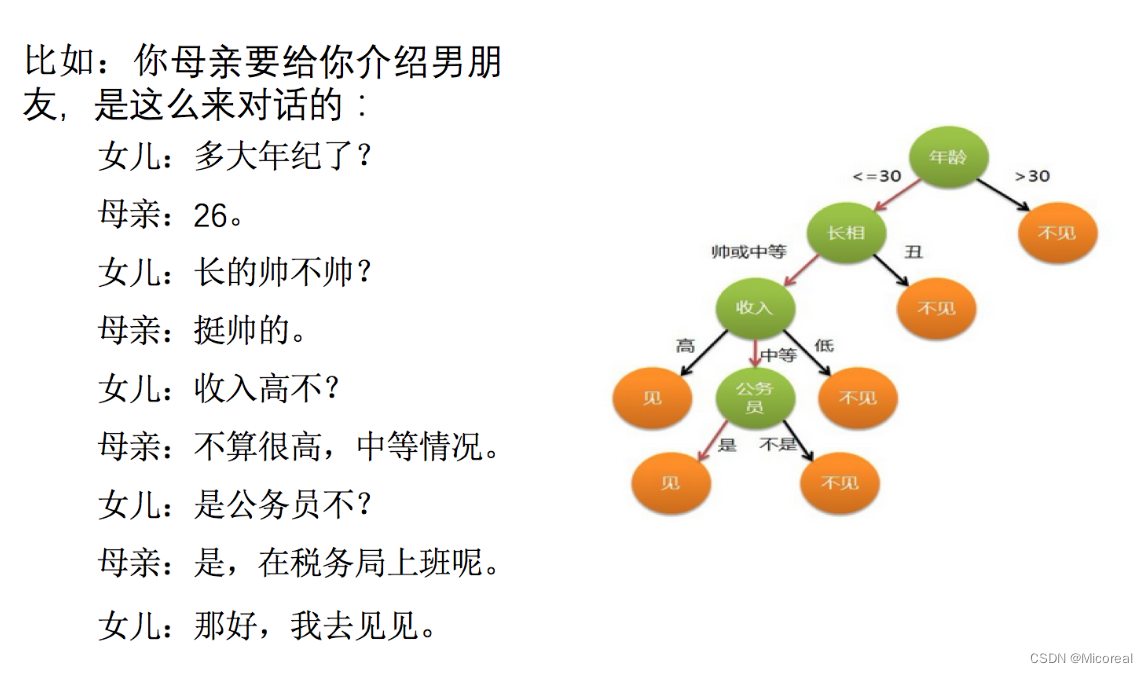
决策树的基本原理就是类似我们的if-else,从根节点开始,不断进行判断,最后走到一个叶子节点,就是我们相对应的结局,而我们需要根据自己的需要去构建出这么一棵决策树,构建决策树要根据什么原则来构建呢?实际上采用的熵
信息熵
系统越有序,熵值越低;系统越混乱或者分散,熵值越高,在之前的决策树,我们采用的是香农的信息熵公式进行判断到底是什么需要优先排在上面,什么排在下面再进行判断。
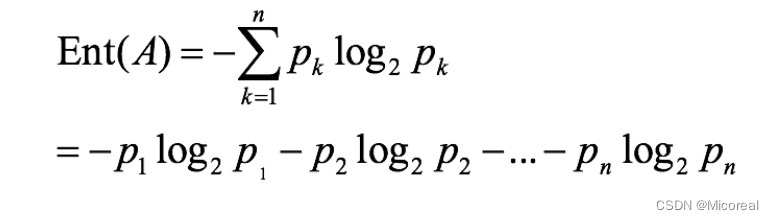
而我么进行排列的顺序一大顺序就是按照信息熵的信息增益来进行判断的。
信息增益
信息增益:以某特征划分数据集前后的熵的差值。熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
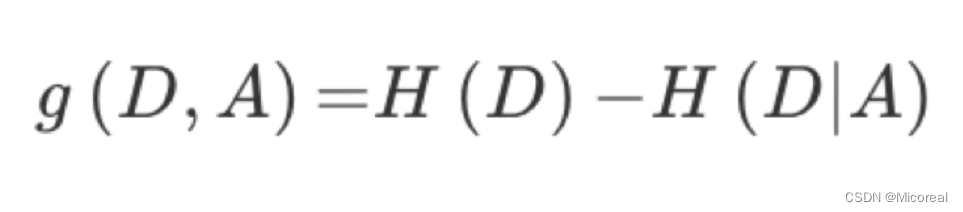
信息增益 = entroy(前) - entroy(后),然后来判断到底是哪一个来的效果更好,就是选择哪一个。
这个就是经典的id3 算法,但是对于id3算法来说,他的一个巨大的缺陷就是他受特征量多的那一个影响太严重,这个需要根据个人的想法进行判断是否采用这个算法。
信息增益率
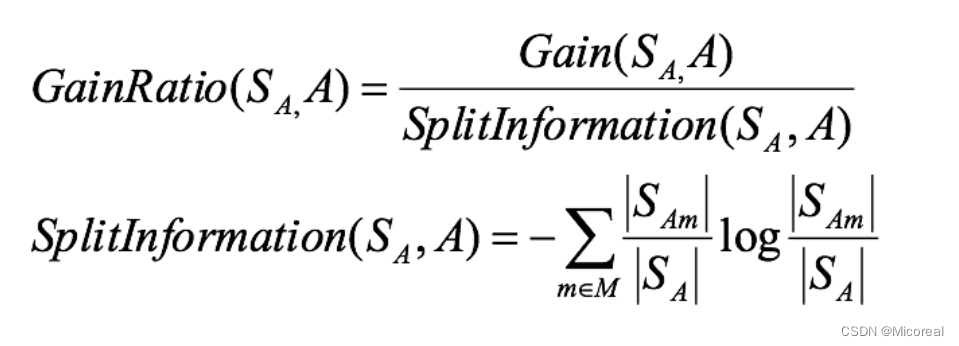
这个就是在原本的计算的时候除掉一个总数。
Gini指数
基尼值Gini(D):从数据集D中随机抽取两个样本,其类别标记不一致的概率。故,Gini(D)值越小,数据集D的纯度越高。
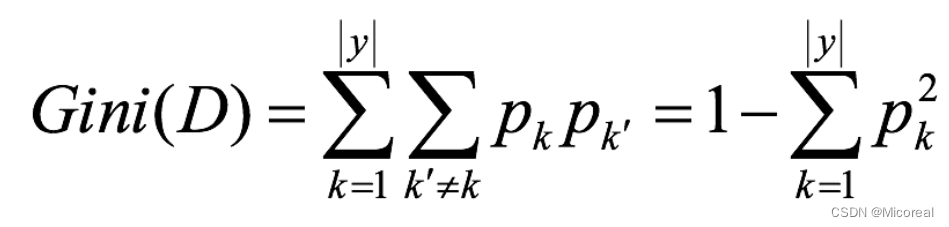
一般,选择使划分后基尼系数最小的属性作为最优化分属性
剪枝
为了防止过拟合现象,需要剪枝进行剪掉我们的部分数据。
预剪枝:
- 每一个结点所包含的最小样本数目,例如10,则该结点总样本数小于10时,则不再分
- 指定树的高度或者深度,例如树的最大深度为4
- 指定结点的熵小于某个值,不再划分。随着树的增长, 在训练样集上的精度是单调上升的, 然而在独立的测试样例上测出的精度先上升后下降。
后剪枝:
实际上就是在看到了前面的效果之后的剪枝,剪枝也跟上面是一致的。
api介绍
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)criterion 特征选择标准
"gini"或者"entropy",前者代表基尼系数,后者代表信息增益。一默认"gini",即CART算法。min_samples_split
内部节点再划分所需最小样本数
这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。min_samples_leaf
叶子节点最少样本数
这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。之前的10万样本项目使用min_samples_leaf的值为5,仅供参考。max_depth
决策树最大深度
决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间random_state
随机数种子
随机森林------集成学习初识
基本使用
# 随机森林 使用了集成学习
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV# 还是使用上面的数据 不详细介绍
#----------------------------------------------------------------------
titan = pd.read_csv("./dataset/titanic/titan_train.csv")
x = titan[["Pclass", "Age", "Sex"]]
y = titan["Survived"]
im = SimpleImputer(missing_values=np.nan, strategy='mean')
x['Age'] = im.fit_transform(x[['Age']])
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
#----------------------------------------------------------------------# 随机森林进行训练 随机森林搭配网格训练
rf = RandomForestClassifier()
# n_estimators 代表的就是有几棵树
param = {"n_estimators": [120,200,300], "max_depth": [5, 8, 15, 25, 30]}
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("随机森林预测的准确率为:", gc.score(x_test, y_test))
输出:
随机森林预测的准确率为: 0.7802690582959642
api介绍
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200Criterion:string,可选(default =“gini”)分割特征的测量方法max_depth:integer或None,可选(默认=无)树的最大深度 5,8,15,25,30max_features="auto”,每个决策树的最大特征数量
If "auto", then max_features=sqrt(n_features).
If "sqrt", then max_features=sqrt(n_features)(same as "auto").
If "log2", then max_features=log2(n_features).
If None, then max_features=n_features.bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样min_samples_split:节点划分最少样本数min_samples_leaf:叶子节点的最小样本数超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
相关文章:
35 机器学习(三):混淆矩阵|朴素贝叶斯|决策树|随机森林
文章目录 分类模型的评估混淆矩阵精确率和召回率 接口介绍其他的补充 朴素贝叶斯基础原理介绍拉普拉斯平滑下面给出应用的例子朴素贝叶斯的思辨 决策树基础使用基本原理信息熵信息增益信息增益率Gini指数 剪枝api介绍 随机森林------集成学习初识基本使用api介绍 分类模型的评估…...

ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+
该错误提示表示您的 OpenSSL 版本过低,无法兼容 urllib3 v2.0。 解决此问题的方法是升级您的 OpenSSL 版本至 1.1.1 或以上。具体操作如下: 方法一: 检查您的 OpenSSL 版本,使用以下命令: openssl version 如果您的…...

webrtc gcc算法(1)
老的webrtc gcc算法,大概流程: 这两个拥塞控制算法分别是在发送端和接收端实现的, 接收端的拥塞控制算法所计算出的估计带宽, 会通过RTCP的remb反馈到发送端, 发送端综合两个控制算法的结果得到一个最终的发送码率,并以…...

2022年亚太杯APMCM数学建模大赛C题全球变暖与否全过程文档及程序
2022年亚太杯APMCM数学建模大赛 C题 全球变暖与否 原题再现: 加拿大的49.6C创造了地球北纬50以上地区的气温新纪录,一周内数百人死于高温;美国加利福尼亚州死亡谷是54.4C,这是有史以来地球上记录的最高温度;科威特53…...

苹果开发者 Xcode发布TestFlight全流程
打包前注意事项 使用Xcode导出安装包之前,必须先确认账户的所有合约是否全部同意,如果有不同意的,在出包的时候会弹出报错 这是什么意思 这意味着您有一些需要在应用商店连接上验证的协议(protocol)/契约(Contract)。解决方案 连接到应用商店…...
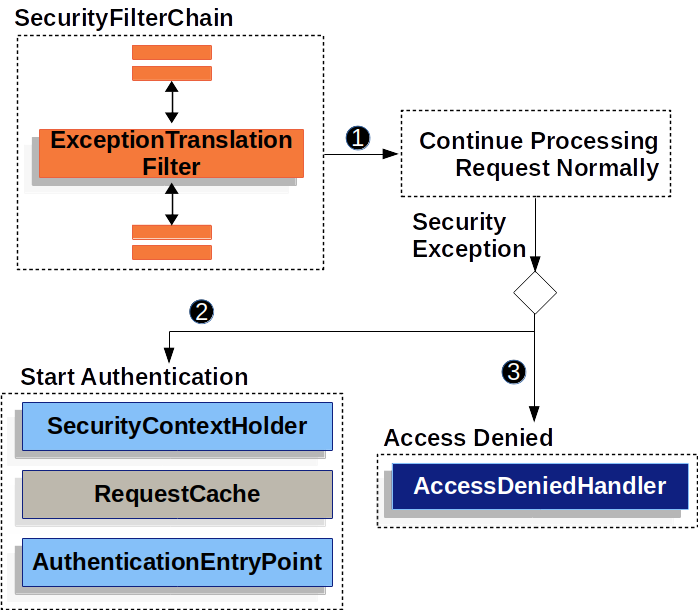
Spring Security—Servlet 应用架构
目录 一、Filter(过滤器)回顾 二、DelegatingFilterProxy 三、FilterChainProxy 四、SecurityFilterChain 五、Security Filter 六、打印出 Security Filter 七、添加自定义 Filter 到 Filter Chain 八、处理 Security 异常 九、保存认证之间的…...
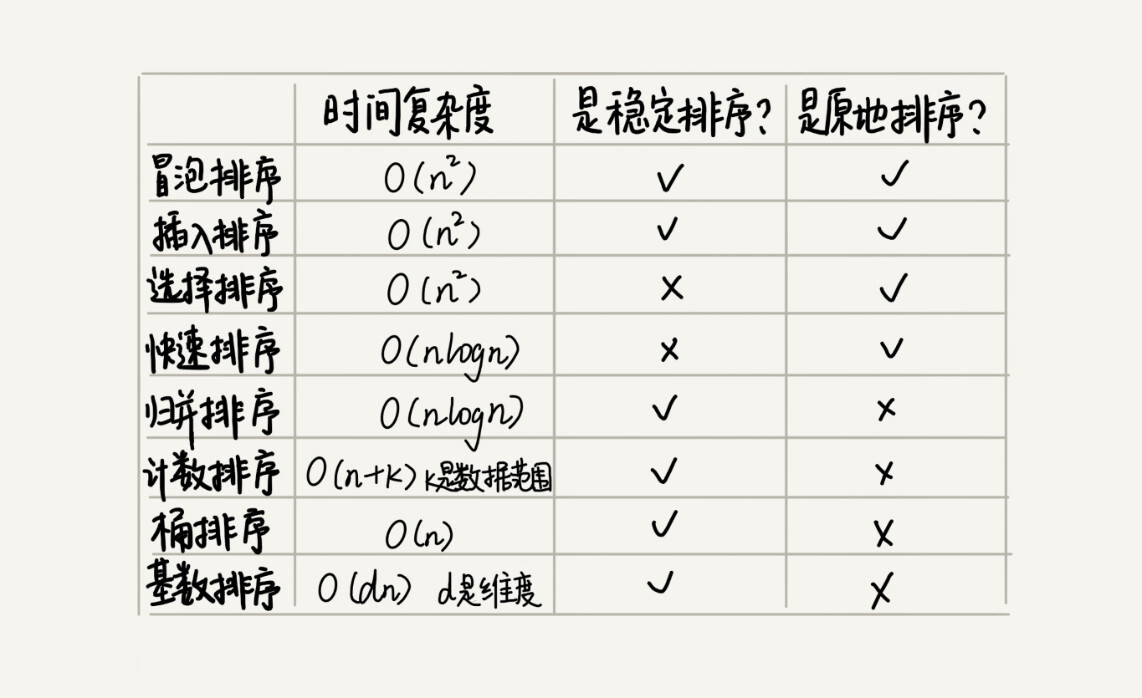
排序优化:如何实现一个通用的、高性能的排序函数?
文章来源于极客时间前google工程师−王争专栏。 几乎所有的编程语言都会提供排序函数,比如java中的Collections.sort()。在平时的开发中,我们都是直接使用,这些排序函数是如何实现的?底层都利用了哪种排序算法呢? 问题…...
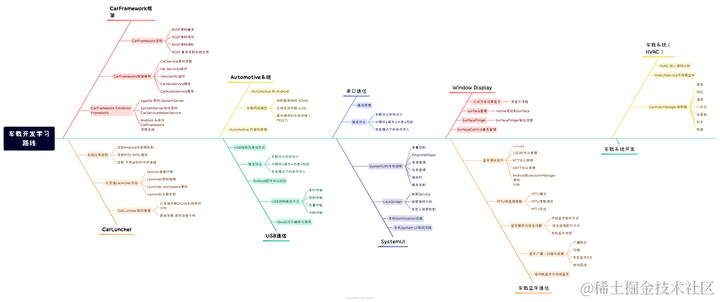
车载开发学习——CAN总线
CAN总线又称为汽车总线,全程为“控制器局域网(Controller Area Network)”,即区域网络控制器,它将区域内的单一控制单元以某种形式连接在一起,形成一个系统。在这个系统内,大家以一种大家都认可…...

2023年知名国产数据库厂家汇总
随着信创国产化的崛起,大家纷纷在寻找可替代的国产数据库厂家。这里小编就给大家汇总了一些国内知名数据库厂家,仅供参考哦! 2023年知名国产数据库厂家汇总 1、人大金仓 2、瀚高 3、高斯 4、阿里云 5、华为云 6、浪潮 7、达梦 8、南大…...

【ARM Coresight SoC-400/SoC-600 专栏导读】
文章目录 1. ARM Coresight SoC-400/SoC-600 专栏导读目录1.1 Coresight 专题1.1.1 Performance Profiling1.1.2 ARM Coresight DS-5 系列 1. ARM Coresight SoC-400/SoC-600 专栏导读目录 本专栏全面介绍 ARM Coresight 系统 及SoC-400, SoC-600 中的各个组件。 1.1 Coresigh…...

在Go中创建自定义错误
引言 Go提供了两种在标准库中创建错误的方法,[errors.New和fmt.Errorf],当与用户交流更复杂的错误信息时,或在调试时与未来的自己交流时,有时这两种机制不足以充分捕获和报告所发生的情况。为了传达更复杂的错误信息并实现更多的…...
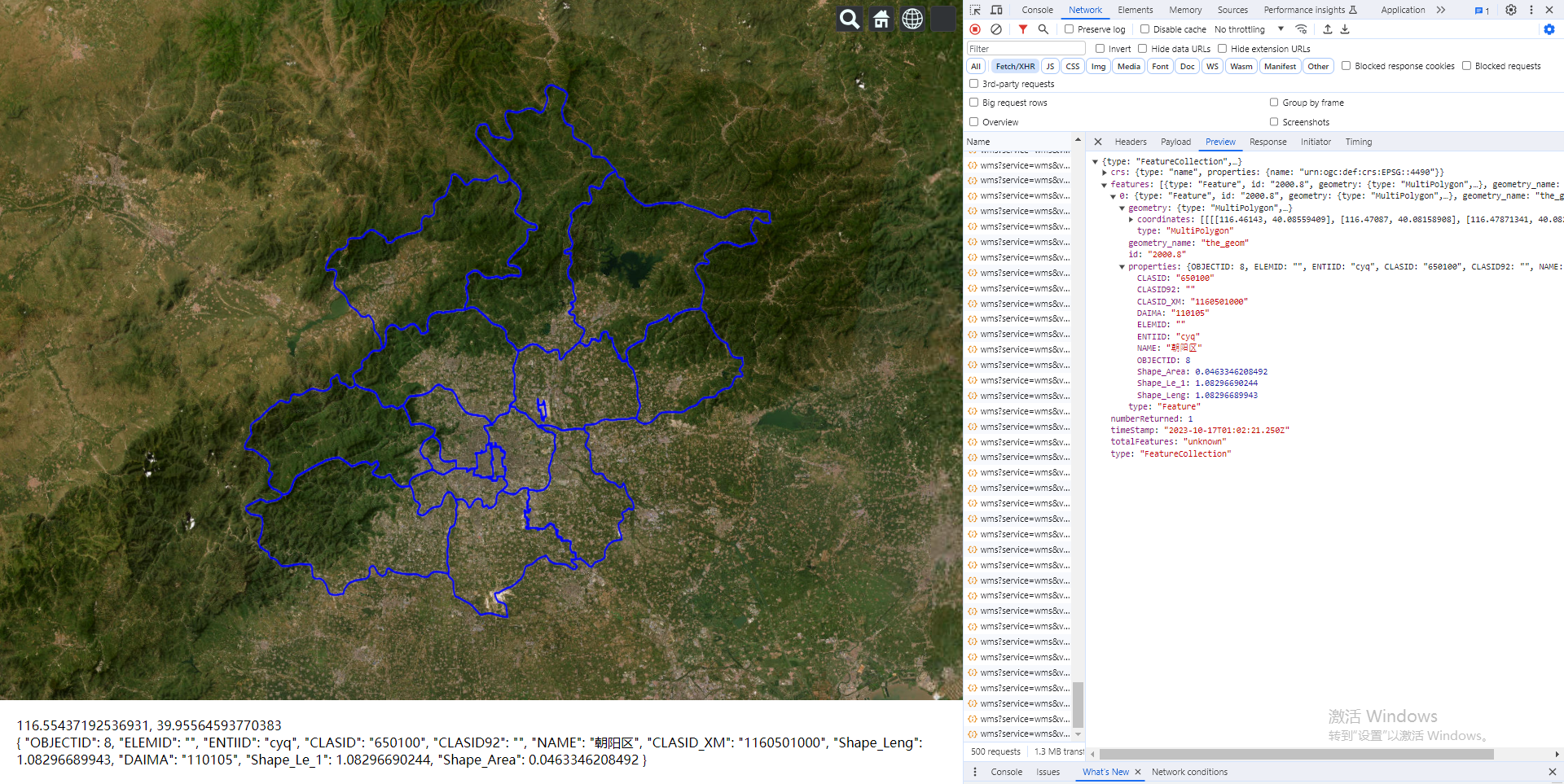
Vue.js2+Cesium1.103.0 十三、通过经纬度查询 GeoServer 发布的 wms 服务下的 feature 对象的相关信息
Vue.js2Cesium1.103.0 十三、通过经纬度查询 GeoServer 发布的 wms 服务下的 feature 对象的相关信息 Demo <template><divid"cesium-container"style"width: 100%; height: 100%;"><div style"position: absolute;z-index: 999;bott…...
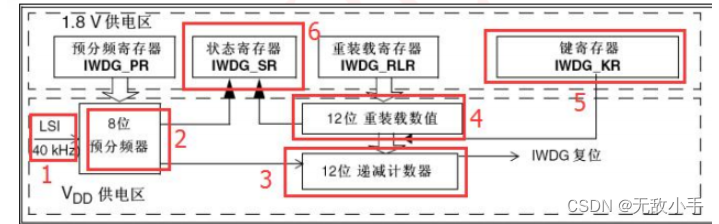
使用STM32怎么喂狗 (IWDG)
STM32F1 的独立看门狗(以下简称 IWDG)。 STM32F1内部自带了两个看门狗,一个是独立看门狗 IWDG,另一个是窗口看门狗 WWDG, 本章只介绍独立看门狗 IWDG,窗口看门狗 WWDG 会在后面章节介绍。 本章要实现的功能…...
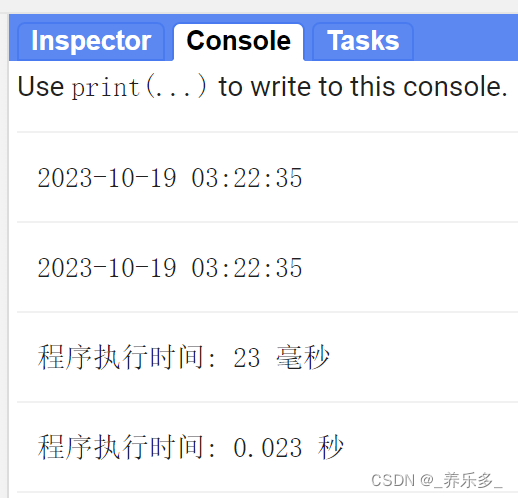
GEE:计算和打印GEE程序的执行时间
作者:CSDN @ _养乐多_ 本文记录了计算和打印程序的执行时间的Google Earth Engine (GEE)代码,并举例说明。 大家在执行GEE代码的时候,有时候为了对比两个不同的脚本,不知道代码执行花费了多少时间。本文记录了打印代码执行时间的函数,并举了一个应用案例说明。可以知道…...
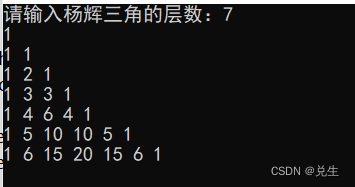
GDPU 数据结构 天码行空5
一、实验目的 1.掌握队列的顺序存储结构 2.掌握队列先进先出运算原则在解决实际问题中的应用 二、实验内容 仿照教材顺序循环队列的例子,设计一个只使用队头指针和计数器的顺序循环队列抽象数据类型。其中操作包括:初始化、入队…...

SQLAlchemy学习-12.查询之 order_by 按desc 降序排序
前言 sqlalchemy的query默认是按id升序进行排序的,当我们需要按某个字段降序排序,就需要用到 order_by。 order_by 排序 默认情况下 sqlalchemy 的 query 默认是按 id 升序进行排序的 res session.query(Project).all() print(res) # [<Project…...

如何轻松打造数字人克隆系统+直播系统?OEM教你快速部署数字人SaaS系统源码
数字人做为国内目前最热门的人工智能创业赛道,连BAT都在跑步入局,中小企业更是渴望不渴及。但随着我国数字人头部品牌企业温州专帮信息科技有限公司旗下灰豚AI数字人平台的开源。使得中小企业零门槛可以轻松打造灰豚AI数字人一模一样的平台。灰豚数字人A…...
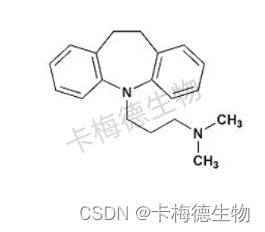
药物滥用第四篇介绍
OXY: 羟考酮(Oxycodone,OXY),分子式为C18H21NO4,是一种半合成的蒂巴因衍生物。羟考酮为半合成的纯阿片受体激动药,其作用机制与吗啡相似,主要通过激动中枢神经系统内的阿片受体而起镇…...

Apache Doris (四十三): Doris数据更新与删除 - Update数据更新
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录 1. Update数据更新原理...
面试算法29:排序的循环链表
问题 在一个循环链表中节点的值递增排序,请设计一个算法在该循环链表中插入节点,并保证插入节点之后的循环链表仍然是排序的。 分析 首先分析在排序的循环链表中插入节点的规律。当在图4.15(a)的链表中插入值为4的节点时&…...

实战利器:借助快马平台构建磁盘空间分析器,cmd命令深度应用
今天想和大家分享一个非常实用的工具开发经验——如何用cmd命令构建一个磁盘空间分析器。这个工具在我们日常系统维护和磁盘管理中特别有用,尤其是当C盘突然变红或者需要清理大文件的时候。 工具核心功能设计 这个磁盘空间分析器主要解决几个实际问题:…...

利用快马平台与openclaw切换模型功能,快速构建待办事项应用原型
最近在尝试快速构建一个待办事项应用的原型时,发现InsCode(快马)平台的AI代码生成功能特别适合这种场景。通过平台内置的openclaw切换模型功能,可以快速比较不同AI模型生成的代码风格差异,大大缩短了原型开发周期。下面分享下我的实践过程&am…...

OpenClaw对接Qwen3-4B实战:5步完成本地模型调用与自动化任务
OpenClaw对接Qwen3-4B实战:5步完成本地模型调用与自动化任务 1. 为什么选择OpenClawQwen3-4B组合 去年冬天第一次听说OpenClaw时,我正被重复性的文件整理工作折磨得焦头烂额。作为一个习惯用脚本解决问题的开发者,我试过各种自动化工具&…...

3D元器件库在PCB设计中的关键作用与应用
1. 为什么你需要一套完整的3D元器件库作为一名电子工程师,我深知在PCB设计过程中,3D元器件库的重要性。传统的2D设计虽然能满足基本需求,但在实际生产装配时往往会遇到各种意想不到的机械干涉问题。记得我刚开始做硬件设计时,就曾…...

数字记忆自主化:GetQzonehistory技术架构与数据保护实践指南
数字记忆自主化:GetQzonehistory技术架构与数据保护实践指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 一、技术演进视角下的数据脆弱性危机 数字存储技术的迭代速度与…...

当相机位姿已知:利用COLMAP从稀疏到稠密重建的实战指南
1. 环境准备与数据格式转换 在开始COLMAP重建之前,我们需要确保环境配置正确,并完成相机位姿数据的格式转换。COLMAP支持Windows、Linux和macOS系统,但为了获得最佳性能,建议使用配备NVIDIA显卡的机器,并安装CUDA加速版…...

Z-Image Turbo实际作品分享:城市风光生成效果
Z-Image Turbo实际作品分享:城市风光生成效果 本文所有内容均为技术效果展示,不涉及任何政治敏感内容,所有案例均为技术演示用途。 1. 效果概览:城市风光的AI艺术呈现 Z-Image Turbo作为基于Gradio和Diffusers构建的高性能AI绘图…...

基于S7-300与组态王的智能药片装瓶机控制系统优化设计
1. 智能药片装瓶机控制系统的核心价值 在制药生产线上,药片装瓶环节看似简单却暗藏玄机。传统的人工装瓶方式不仅效率低下,还容易出现计数错误、交叉污染等问题。我曾在某药企亲眼见过工人因疲劳导致装瓶数量出错,最终整批药品不得不报废的案…...

LangGraph多智能体框架:构建持久化AI智能体的终极指南 [特殊字符]
LangGraph多智能体框架:构建持久化AI智能体的终极指南 🚀 【免费下载链接】langgraph Build resilient language agents as graphs. 项目地址: https://gitcode.com/GitHub_Trending/la/langgraph 在当今快速发展的AI领域,多智能体框架…...

500套帐篷发往西非:我们凭什么拿下这单?
一句吐槽,让我们抓住了机会年初,天津京路发科技收到一封西非询盘:500套支架帐篷,用于安置点。客户顺带吐槽了一句:“之前的帐篷,没撑过上一个雨季。”我们懂了——价格不是关键,耐造才是。先看气…...