2023_Spark_实验十四:SparkSQL入门操作
1、将emp.csv、dept.csv文件上传到分布式环境,再用
hdfs dfs -put dept.csv /input/
hdfs dfs -put emp.csv /input/
将本地文件put到hdfs文件系统的input目录下
2、或者调用本地文件也可以。区别:sc.textFile("file:///D:\\temp\\emp.csv")
import org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.types._import spark.implicits._case classEmp(empno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)val lines =sc.textFile("hdfs://Master:9000/input/emp.csv").map(_.split(","))val allEmp = lines.map(x=>Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))val allEmpDF = allEmp.toDFallEmpDF.show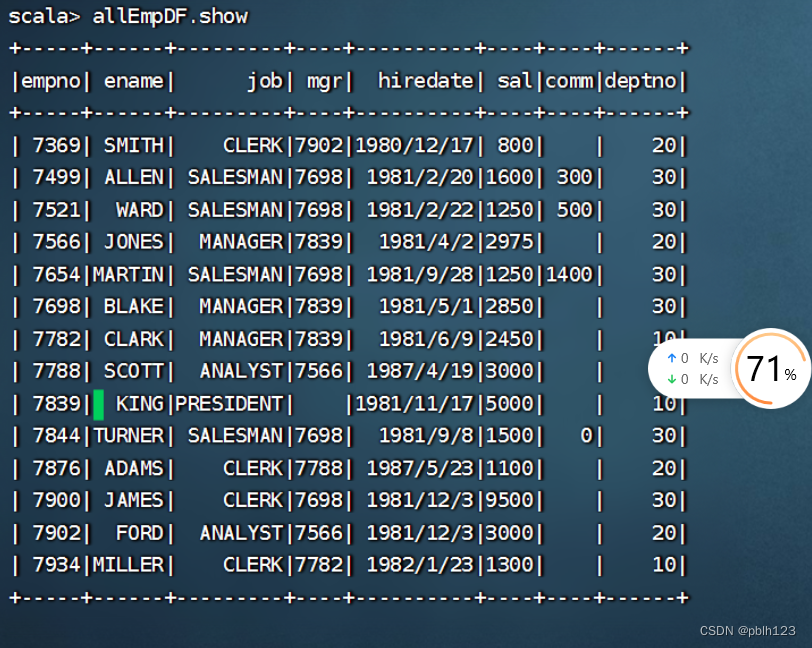
-
StructType 是个case class,一般用于构建schema.
-
因为是case class,所以使用的时候可以不用new关键字
构造函数
-
可以传入Seq,List,Array,都是可以的~
-
还可以用无参的构造器,因为它有一个无参的构造器.
例子
private val schema: StructType = StructType(List(StructField("name", DataTypes.StringType),StructField("age", DataTypes.IntegerType)))也可以是
private val schema: StructType = StructType(Array(StructField("name", DataTypes.StringType),StructField("age", DataTypes.IntegerType)))-
还可以调用无参构造器,这么写
private val schema = (new StructType).add(StructField("name", DataTypes.StringType)).add(StructField("age", DataTypes.IntegerType))-
这个无参的构造器,调用了一个有参构造器.this里面是个方法,这个方法的返回值是Array类型,实际上就是无参构造器调用了主构造器
def this() = this(Array.empty[StructField])case class StructType(fields: Array[StructField]) extends DataType with Seq[StructField] {}
import org.apache.spark.sql.types._val myschema =StructType(List(StructField("empno",DataTypes.IntegerType),StructField("ename",DataTypes.StringType),StructField("job",DataTypes.StringType),StructField("mgr",DataTypes.StringType),StructField("hiredate",DataTypes.StringType),StructField("sal",DataTypes.IntegerType),StructField("comm",DataTypes.StringType),StructField("deptno",DataTypes.IntegerType)))val empcsvRDD = sc.textFile("hdfs://Master:9000/input/emp.csv").map(_.split(","))import org.apache.spark.sql.Rowval rowRDD=empcsvRDD.map(line => Row (line(0).toInt,line(1),line(2),line(3),line(4),line(5).toInt,line(6),line(7).toInt))val df = spark.createDataFrame(rowRDD,myschema)
将people.json文件上传到分布式环境
hdfs dfs -put people.json /inputhdfs dfs -put emp.json /input//读json文件
val df = spark.read.json("hdfs://Master:9000/input/emp.json")df.show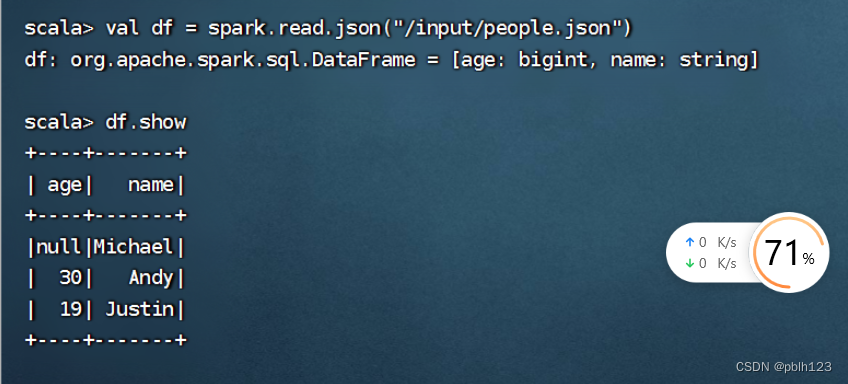
df.select ("ename").show
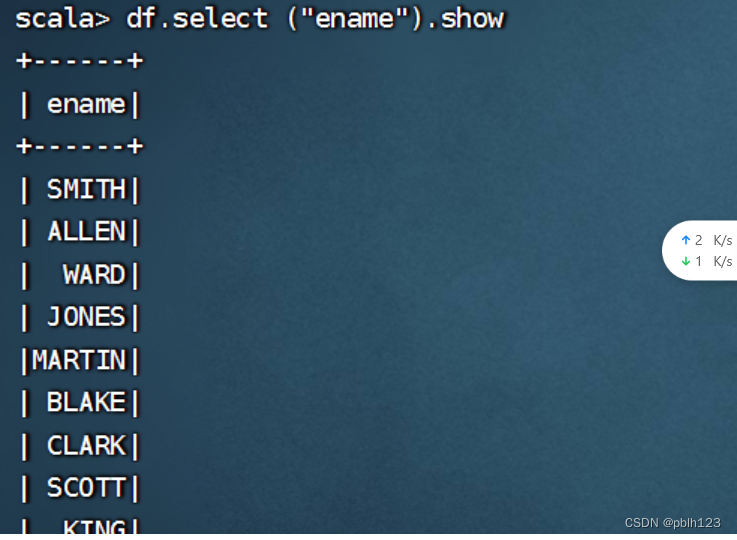
df.select($"ename").show
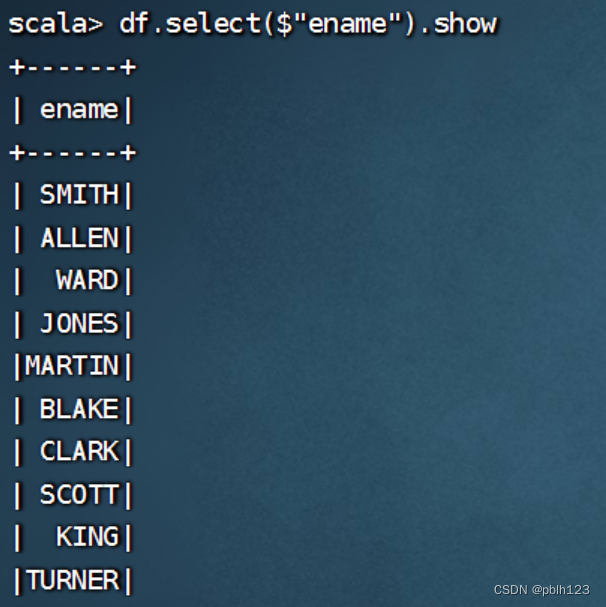
df.select($"ename",$"sal",$"sal"+100).show
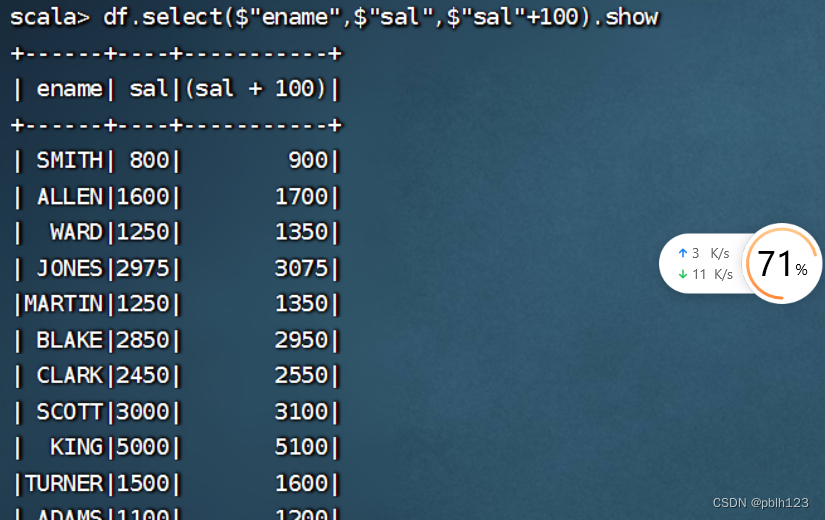
df.filter($"sal">2000).show
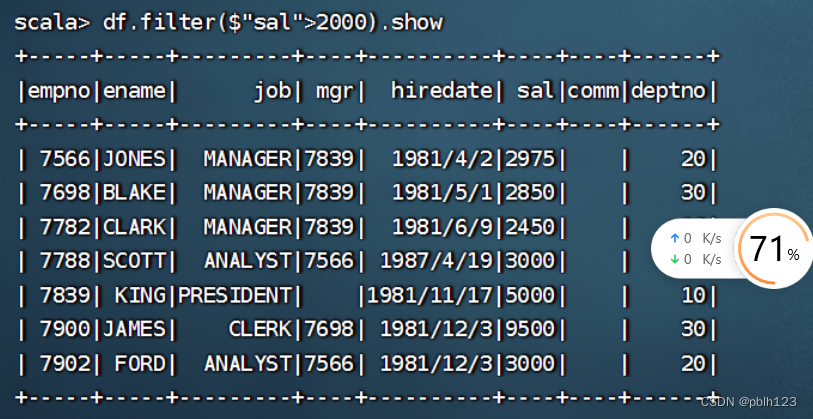
df.groupBy($"deptno").count.show
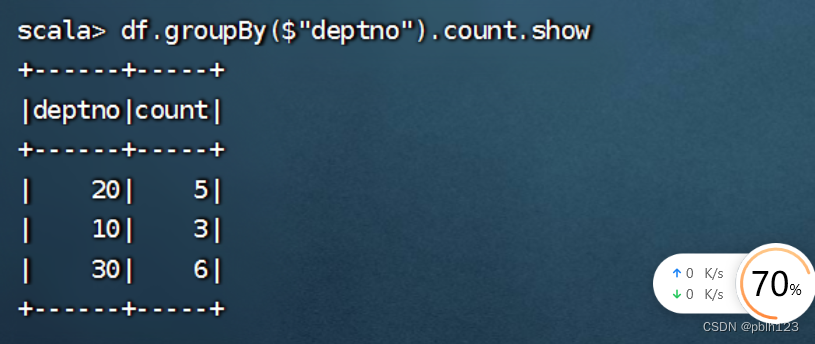
df.createOrReplaceTempView("emp")
spark.sql("select * from emp").show
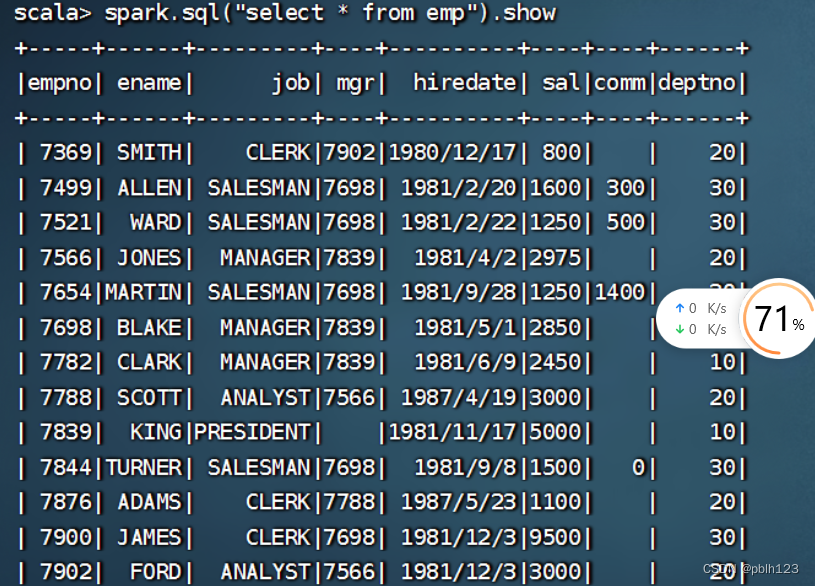
spark.sql("select * from emp where deptno=10").show

spark.sql("select deptno,sum(sal) from emp group by deptno").show

//1 创建一个普通的 view 和一个全局的 viewdf.createOrReplaceTempView("emp1")df.createGlobalTempView("emp2")//2 在当前会话中执行查询,均可查询出结果spark.sql("select * from emp1").showspark.sql("select * from global_temp.emp2").show//3 开启一个新的会话,执行同样的查询spark.newSession.sql("select * from emp1").show //运行出错spark.newSession.sql("select * from global_temp.emp2").show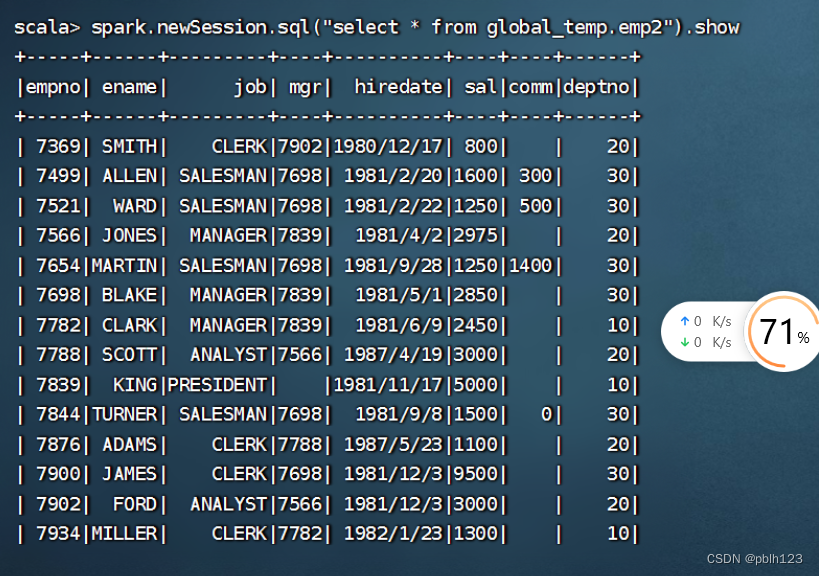
//7、创建 Datasets//创建 DataSet,方式一:使用序列//1、定义 case classcase class MyData(a:Int,b:String)//2、生成序列,并创建 DataSetval ds = Seq(MyData(1,"Tom"),MyData(2,"Mary")).toDS//3、查看结果ds.showds.collect
//创建 DataSet,方式二:使用 JSON 数据//1、定义 case classcase class Person(name: String, gender: String)//2、通过 JSON 数据生成 DataFrameval df = spark.read.json(sc.parallelize("""{"gender": "Male", "name": "Tom"}""":: Nil))//3、将 DataFrame 转成 DataSetdf.as[Person].showdf.as[Person].collect
//创建 DataSet,方式三:使用 HDFS 数据val linesDS = spark.read.text("hdfs://Master:9000/input/word.txt").as[String]val words = linesDS.flatMap(_.split(" ")).filter(_.length > 3)words.showwords.collect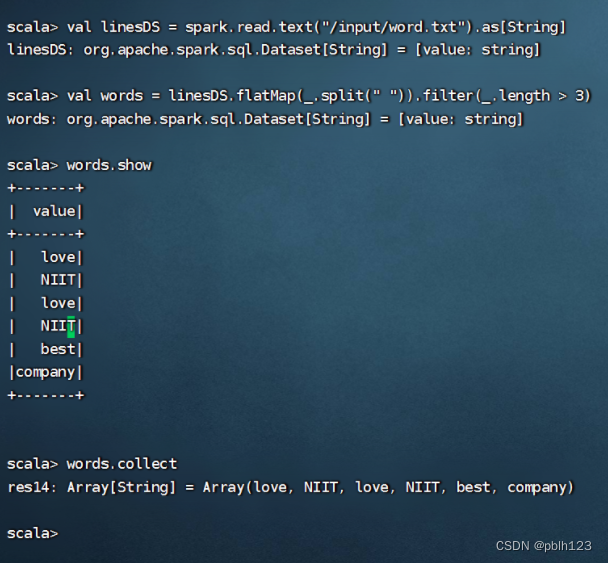
val result = linesDS.flatMap(_.split(" ")).map((_,1)).groupByKey(x => x._1).countresult.showresult.orderBy($"value").show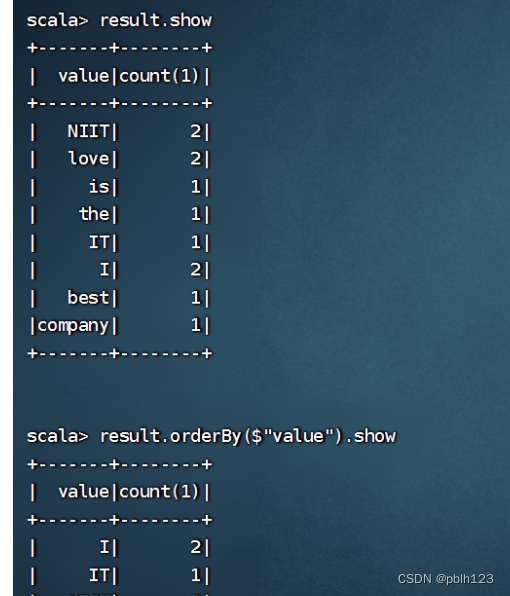
1、将emp.json文件上传到分布式环境,再用
hdfs dfs -put emp.json /input/
将本地文件put到hdfs文件系统的input目录下
//8、Datasets 的操作案例//1.使用 emp.json 生成 DataFrameval empDF = spark.read.json("hdfs://Master:9000/input/emp.json")//查询工资大于 3000 的员工empDF.where($"sal" >= 3000).show//创建 case classcase classEmp(empno:Long,ename:String,job:String,hiredate:String,mgr:String,sal:Long,comm:String,deptno:Long)//生成 DataSets,并查询数据val empDS = empDF.as[Emp]//查询工资大于 3000 的员工empDS.filter(_.sal > 3000).show//查看 10 号部门的员工empDS.filter(_.deptno == 10).show//多表查询//1、创建部门表val deptRDD=sc.textFile("hdfs://Master:9000/input/dept.csv").map(_.split(","))case class Dept(deptno:Int,dname:String,loc:String)val deptDS = deptRDD.map(x=>Dept(x(0).toInt,x(1),x(2))).toDS//2、创建员工表case classEmp(empno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)val empRDD = sc.textFile("hdfs://Master:9000/input/emp.csv").map(_.split(","))val empDS = empRDD.map(x =>Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt)).toDS//3、执行多表查询:等值链接val result = deptDS.join(empDS,"deptno")//另一种写法:注意有三个等号val result = deptDS.joinWith(empDS,deptDS("deptno")===empDS("deptno"))//查看执行计划:result.explain相关文章:
2023_Spark_实验十四:SparkSQL入门操作
1、将emp.csv、dept.csv文件上传到分布式环境,再用 hdfs dfs -put dept.csv /input/ hdfs dfs -put emp.csv /input/ 将本地文件put到hdfs文件系统的input目录下 2、或者调用本地文件也可以。区别:sc.textFile("file:///D:\\temp\\emp.csv&qu…...
如何将几个模型合并成一个
1、什么时候需要合并模型? 组装和装配:当你需要将多个零件或组件组装成一个整体时,可以合并它们成为一个模型。例如,在制造业中,当需要设计和展示一个完整的机械装置或产品时,可以将各个零部件合并成一个模…...

异常气体识别与飘移
Olfactory Target/Background Odor Detection via Self-expression Model 解决非目标气体检测 摘要:提出了SeELM模型(自表达ELM模型) 分为两步:1.对获得的数据集进行建模,计算出自我表达系数矩阵,2.对于异…...

分类预测 | Matlab实现WOA-BiLSTM鲸鱼算法优化双向长短期记忆神经网络的数据多输入分类预测
分类预测 | Matlab实现WOA-BiLSTM鲸鱼算法优化双向长短期记忆神经网络的数据多输入分类预测 目录 分类预测 | Matlab实现WOA-BiLSTM鲸鱼算法优化双向长短期记忆神经网络的数据多输入分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现WOA-BiLSTM鲸鱼算法…...
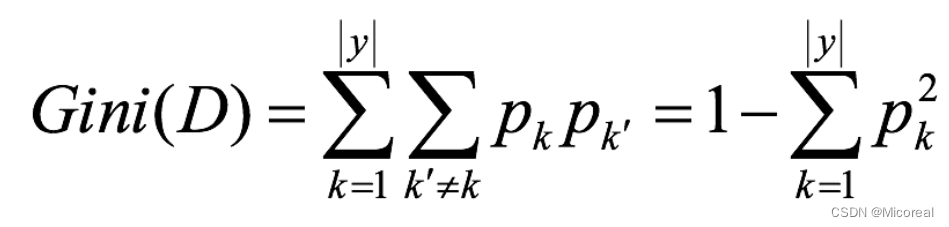
35 机器学习(三):混淆矩阵|朴素贝叶斯|决策树|随机森林
文章目录 分类模型的评估混淆矩阵精确率和召回率 接口介绍其他的补充 朴素贝叶斯基础原理介绍拉普拉斯平滑下面给出应用的例子朴素贝叶斯的思辨 决策树基础使用基本原理信息熵信息增益信息增益率Gini指数 剪枝api介绍 随机森林------集成学习初识基本使用api介绍 分类模型的评估…...

ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+
该错误提示表示您的 OpenSSL 版本过低,无法兼容 urllib3 v2.0。 解决此问题的方法是升级您的 OpenSSL 版本至 1.1.1 或以上。具体操作如下: 方法一: 检查您的 OpenSSL 版本,使用以下命令: openssl version 如果您的…...

webrtc gcc算法(1)
老的webrtc gcc算法,大概流程: 这两个拥塞控制算法分别是在发送端和接收端实现的, 接收端的拥塞控制算法所计算出的估计带宽, 会通过RTCP的remb反馈到发送端, 发送端综合两个控制算法的结果得到一个最终的发送码率,并以…...

2022年亚太杯APMCM数学建模大赛C题全球变暖与否全过程文档及程序
2022年亚太杯APMCM数学建模大赛 C题 全球变暖与否 原题再现: 加拿大的49.6C创造了地球北纬50以上地区的气温新纪录,一周内数百人死于高温;美国加利福尼亚州死亡谷是54.4C,这是有史以来地球上记录的最高温度;科威特53…...

苹果开发者 Xcode发布TestFlight全流程
打包前注意事项 使用Xcode导出安装包之前,必须先确认账户的所有合约是否全部同意,如果有不同意的,在出包的时候会弹出报错 这是什么意思 这意味着您有一些需要在应用商店连接上验证的协议(protocol)/契约(Contract)。解决方案 连接到应用商店…...
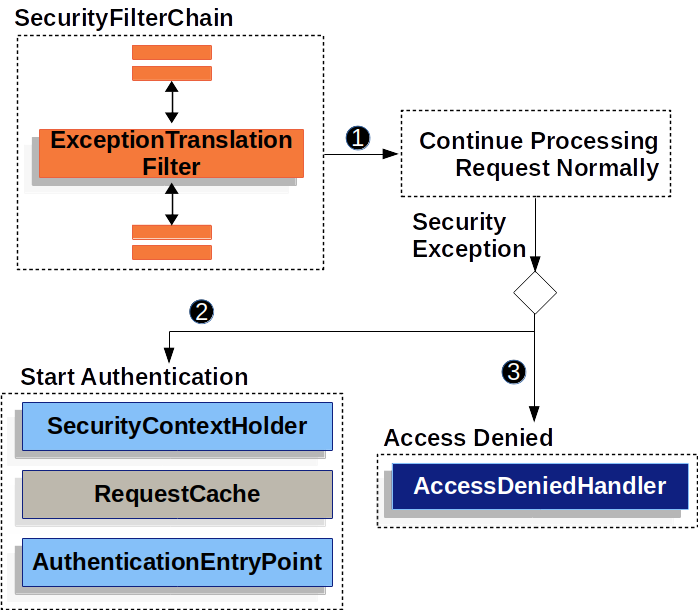
Spring Security—Servlet 应用架构
目录 一、Filter(过滤器)回顾 二、DelegatingFilterProxy 三、FilterChainProxy 四、SecurityFilterChain 五、Security Filter 六、打印出 Security Filter 七、添加自定义 Filter 到 Filter Chain 八、处理 Security 异常 九、保存认证之间的…...
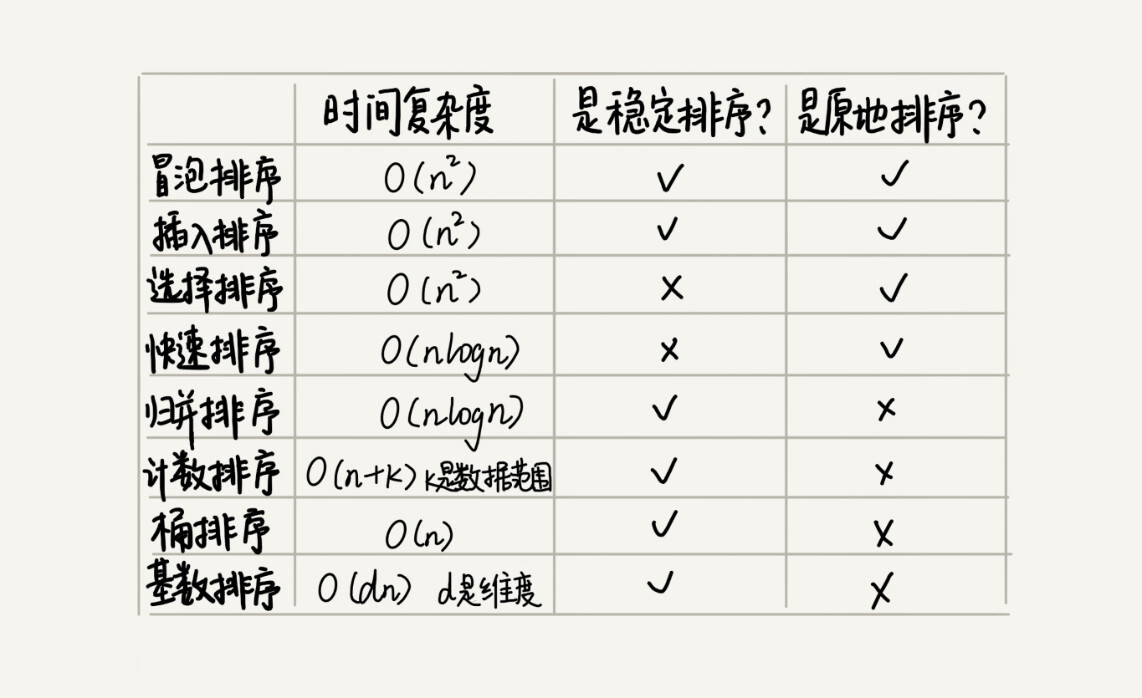
排序优化:如何实现一个通用的、高性能的排序函数?
文章来源于极客时间前google工程师−王争专栏。 几乎所有的编程语言都会提供排序函数,比如java中的Collections.sort()。在平时的开发中,我们都是直接使用,这些排序函数是如何实现的?底层都利用了哪种排序算法呢? 问题…...
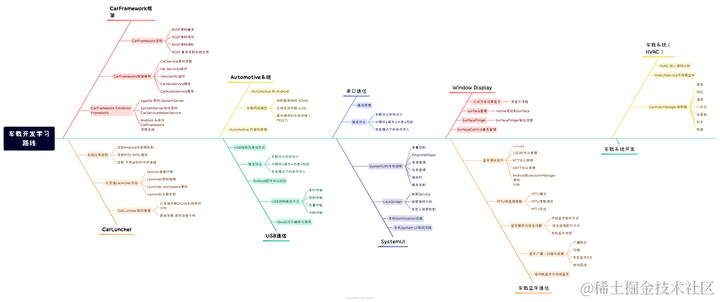
车载开发学习——CAN总线
CAN总线又称为汽车总线,全程为“控制器局域网(Controller Area Network)”,即区域网络控制器,它将区域内的单一控制单元以某种形式连接在一起,形成一个系统。在这个系统内,大家以一种大家都认可…...

2023年知名国产数据库厂家汇总
随着信创国产化的崛起,大家纷纷在寻找可替代的国产数据库厂家。这里小编就给大家汇总了一些国内知名数据库厂家,仅供参考哦! 2023年知名国产数据库厂家汇总 1、人大金仓 2、瀚高 3、高斯 4、阿里云 5、华为云 6、浪潮 7、达梦 8、南大…...

【ARM Coresight SoC-400/SoC-600 专栏导读】
文章目录 1. ARM Coresight SoC-400/SoC-600 专栏导读目录1.1 Coresight 专题1.1.1 Performance Profiling1.1.2 ARM Coresight DS-5 系列 1. ARM Coresight SoC-400/SoC-600 专栏导读目录 本专栏全面介绍 ARM Coresight 系统 及SoC-400, SoC-600 中的各个组件。 1.1 Coresigh…...

在Go中创建自定义错误
引言 Go提供了两种在标准库中创建错误的方法,[errors.New和fmt.Errorf],当与用户交流更复杂的错误信息时,或在调试时与未来的自己交流时,有时这两种机制不足以充分捕获和报告所发生的情况。为了传达更复杂的错误信息并实现更多的…...
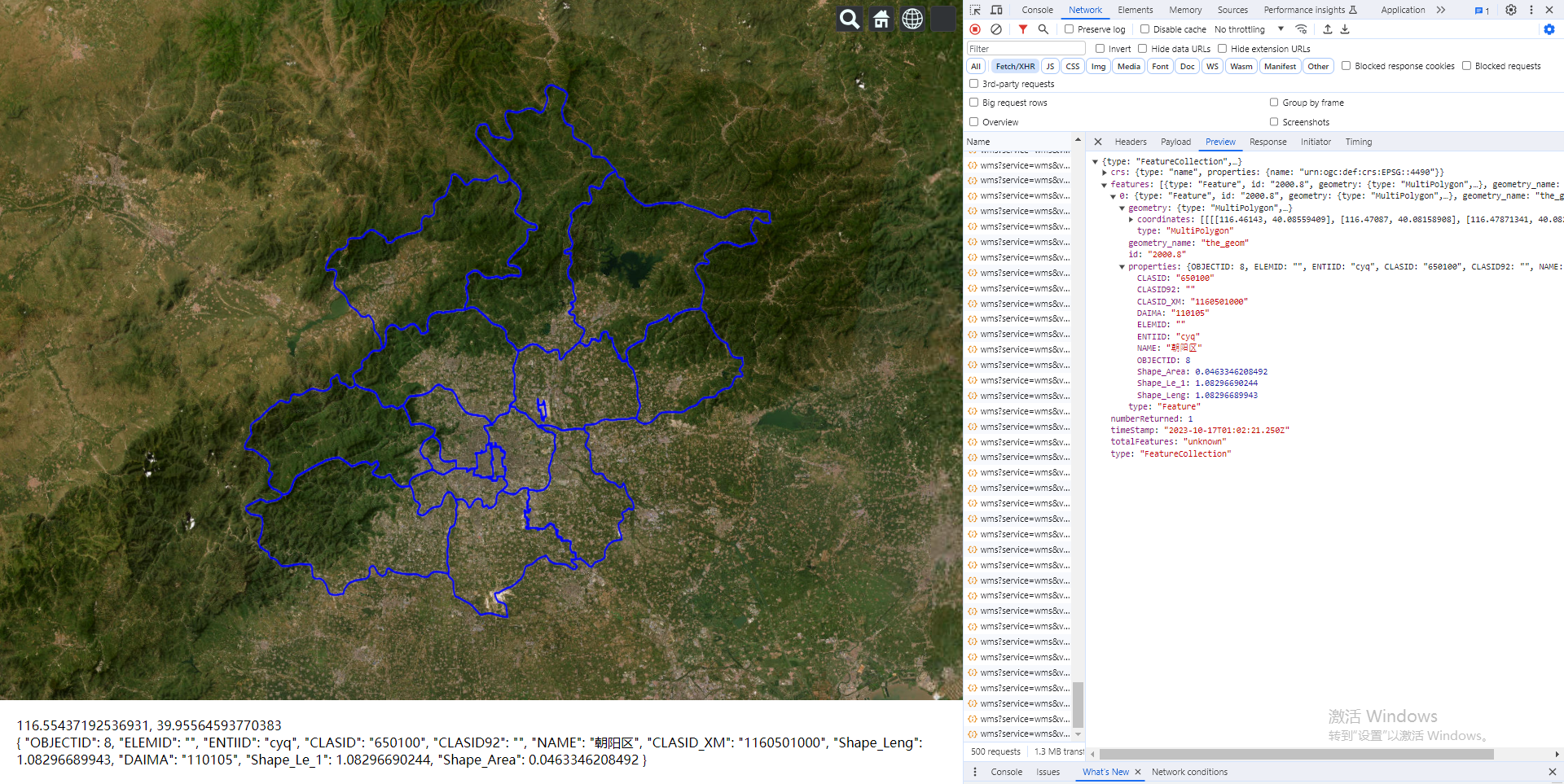
Vue.js2+Cesium1.103.0 十三、通过经纬度查询 GeoServer 发布的 wms 服务下的 feature 对象的相关信息
Vue.js2Cesium1.103.0 十三、通过经纬度查询 GeoServer 发布的 wms 服务下的 feature 对象的相关信息 Demo <template><divid"cesium-container"style"width: 100%; height: 100%;"><div style"position: absolute;z-index: 999;bott…...
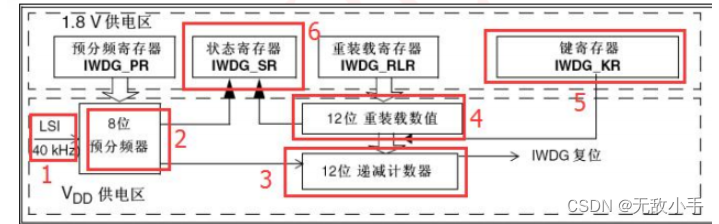
使用STM32怎么喂狗 (IWDG)
STM32F1 的独立看门狗(以下简称 IWDG)。 STM32F1内部自带了两个看门狗,一个是独立看门狗 IWDG,另一个是窗口看门狗 WWDG, 本章只介绍独立看门狗 IWDG,窗口看门狗 WWDG 会在后面章节介绍。 本章要实现的功能…...
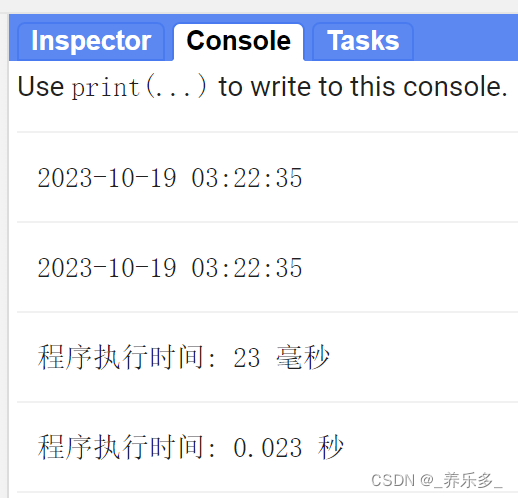
GEE:计算和打印GEE程序的执行时间
作者:CSDN @ _养乐多_ 本文记录了计算和打印程序的执行时间的Google Earth Engine (GEE)代码,并举例说明。 大家在执行GEE代码的时候,有时候为了对比两个不同的脚本,不知道代码执行花费了多少时间。本文记录了打印代码执行时间的函数,并举了一个应用案例说明。可以知道…...
GDPU 数据结构 天码行空5
一、实验目的 1.掌握队列的顺序存储结构 2.掌握队列先进先出运算原则在解决实际问题中的应用 二、实验内容 仿照教材顺序循环队列的例子,设计一个只使用队头指针和计数器的顺序循环队列抽象数据类型。其中操作包括:初始化、入队…...

SQLAlchemy学习-12.查询之 order_by 按desc 降序排序
前言 sqlalchemy的query默认是按id升序进行排序的,当我们需要按某个字段降序排序,就需要用到 order_by。 order_by 排序 默认情况下 sqlalchemy 的 query 默认是按 id 升序进行排序的 res session.query(Project).all() print(res) # [<Project…...

Gitee与奇安信代码卫士的Java安全扫描实战指南
1. 为什么Java项目需要安全扫描? 最近几年,随着数字化转型加速,Java应用的安全问题越来越受到重视。我见过太多因为代码漏洞导致的数据泄露事件,很多都是因为开发过程中忽视了基础的安全检查。就拿去年某知名电商平台的用户信息泄…...

CMake 导言
为什么选择 CMake 在掌握 Linux 基础后,我们知道一个项目通常由多个源文件组成。想要构建这个项目,就需要按照一定的规则对源文件进行编译和链接,而这些规则通常需要在 Makefile 中定义。 但随着项目体量增大,手写 Makefile 会变得…...
)
5分钟搞懂FGSM:用Python手把手教你生成第一个对抗样本(附代码)
5分钟搞懂FGSM:用Python手把手教你生成第一个对抗样本(附代码) 对抗样本生成听起来像是黑客的专属技能,但今天我要告诉你:用不到10行Python代码就能实现。去年我在一个图像识别项目中第一次遭遇对抗样本攻击——系统将…...

text2vec-base-chinese终极指南:如何用768维向量彻底改变中文语义理解
text2vec-base-chinese终极指南:如何用768维向量彻底改变中文语义理解 【免费下载链接】text2vec-base-chinese 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/text2vec-base-chinese 还在为中文文本的语义匹配而头疼吗?传统的基于关…...

马年市场快报分析:欧美组合式一氧化碳及可燃气体报警器指南
马年市场快报分析:欧美组合式一氧化碳及可燃气体报警器指南根据您提供的快报内容,我将从专业角度逐步分析欧美组合式一氧化碳(CO)及可燃气体报警器的关键信息,包括安全标准、风险因素、探测器区别、安装建议以及相关产…...

千问3.5-2B科研助手应用:论文插图内容解析、实验数据图趋势简述生成
千问3.5-2B科研助手应用:论文插图内容解析、实验数据图趋势简述生成 1. 科研场景下的视觉语言模型应用 在科研工作中,论文插图和实验数据图是研究成果展示的重要载体。传统的人工解读和分析过程往往耗时费力,特别是当需要处理大量图表时。千…...

掌握QMK Toolbox的4个实战阶段:开源键盘定制工具从入门到精通的学习路径
掌握QMK Toolbox的4个实战阶段:开源键盘定制工具从入门到精通的学习路径 【免费下载链接】qmk_toolbox A Toolbox companion for QMK Firmware 项目地址: https://gitcode.com/gh_mirrors/qm/qmk_toolbox QMK Toolbox是一款专为机械键盘定制开发的开源工具&a…...

【个人推荐】一些好用的录音转写工具
因为助教课备课的缘故,需要录制讲座的音频以整理知识点。一次讲座的音频内容很长,即使3x速快进播放依然很耗费时间,因此录音转写的需求浮现了出来。于是闲暇之余探索了下市面上的录音转写工具,浅浅记录下体验。 下面主要推荐三款…...

DeepSeek-Coder-V2-Lite-Instruct用户调研:开发者眼中的AI编程助手痛点与需求
DeepSeek-Coder-V2-Lite-Instruct用户调研:开发者眼中的AI编程助手痛点与需求 【免费下载链接】DeepSeek-Coder-V2-Lite-Instruct 开源代码智能利器——DeepSeek-Coder-V2,性能比肩GPT4-Turbo,全面支持338种编程语言,128K超长上下…...

Cursor Pro完整解锁方案:一站式解决AI编程助手使用限制的终极指南
Cursor Pro完整解锁方案:一站式解决AI编程助手使用限制的终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reach…...