【ChatGLM2-6B】在只有CPU的Linux服务器上进行部署
简介
ChatGLM2-6B 是清华大学开源的一款支持中英双语的对话语言模型。经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,具有62 亿参数的 ChatGLM2-6B 已经能生成相当符合人类偏好的回答。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
准备工作
安装wget
- 删除自带的wget:
yum remove wget - 重新安装wget:
yum -y install wget - 检测wget版本:
rpm -qa | grep "wget"
若出现以下,则成功。
[root@localhost ~]# rpm -qa | grep "wget"
wget-1.14-18.el7_6.1.x86_64
安装ANACONDA
- 官网下载页面:
https://www.anaconda.com/download#downloads - Linux64位下载:
wget https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh - 安装:
sh Anaconda3-2023.09-0-Linux-x86_64.sh - 会出现很多信息,一路
yes下去,观看文档用q跳过 - 查看版本验证是否安装成功:
conda -V
(base) [root@localhost ~]# conda -V
conda 23.7.4
安装pytorch
- 前往
pytorch官网:https://pytorch.org/ - 选择
Stable,Linux,Conda,Python,CPU - 执行给出的指令:
conda install pytorch torchvision torchaudio cpuonly -c pytorch
创建虚拟Python环境
- conda创建虚拟环境:
conda create --name ChatGLM2 python=3.10.6 -y
- –name 后面ChatGLM2为创建的虚拟环境名称
- python=之后输入自己想要的python版本
- -y表示后面的请求全部为yes,这样就不用自己每次手动输入yes了。
- 激活虚拟环境:
conda activate ChatGLM2
大语言模型ChatGLM2-6B安装
- 源码/文档:
https://github.com/THUDM/ChatGLM2-6B - 下载源码:
git clone https://github.com/THUDM/ChatGLM2-6B - 创建ChatGLM2项目的虚拟环境:
python -m venv venv - 激活虚拟环境venv:
source ./venv/bin/activate - 安装依赖(豆瓣源):
pip install -r requirements.txt -i https://pypi.douban.com/simple
- 参数:-r 是read的意思,可以把要安装的文件统一写在一个txt中,批量下载
- 参数:-i 后面是下载的网址,这里使用的是豆瓣源,下载安装大概十几分钟
- 清华大学源:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn- 阿里云源:
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
- 也可以离线安装
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install -r requirements.txt --no-index --find-links=/home/ChatGLM2/chatglm2-dependence
- 安装依赖:
pip install gradio -i https://pypi.douban.com/simple
从Hugging Face Hub下载模型实现和参数文件
- 在上面的
ChatGLM2-6B目录下新建THUDM文件夹 - 在
THUDM文件夹下新建chatglm2-6b文件夹和chatglm2-6b-int4文件夹 - 下载模型实现和参数文件:
git clone https://huggingface.co/THUDM/chatglm2-6b - 也可以仅下载模型实现:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b - 然后从清华大学下载模型参数文件:
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2F&mode=list - 把下载后的所有文件放到上面新建的
chatglm2-6b文件夹 - 如果需要使用量化模型和参数,
chatglm2-6b-int4的模型和参数文件地址:https://huggingface.co/THUDM/chatglm2-6b-int4,下载方式与chatglm2-6b一样
- 国内无法访问huggingface.co,可以让国外的朋友帮忙下载
- 可以从这里下载模型实现
- 然后从清华大学下载参数文件
修改启动脚本
如果使用有chatglm2-6b-int4,需要修改
cli_demo.py、api.py、web_demo.py、web_demo2.py
# 修改前
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()# 修改后
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b-int4", trust_remote_code=True)
# GPU用cuda(),CPU用float()
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4", trust_remote_code=True).float()
修改 web_demo.py文件
- 除了需要按上面修改,还需要在最后一行,将
demo.queue().lanuch函数改为如下
demo.queue().launch(share=True, inbrowser=True, server_name = '0.0.0.0')
- 在
predict函数中,第二句话改为
for response, history in model.stream_chat ( tokenizer ,input ,history,past_key_values=past_key_values, return_past_key_values=False, max_length=max_length, top_p=top_p,
temperature=temperature)
启动
- 启动基于
Gradio的网页版demo:python web_demo.py - 启动基于
Streamlit的网页版demo:streamlit run web_demo2.py - 网页版
demo会运行一个Web Server,并输出地址。在浏览器中打开输出的地址即可使用。 经测试,基于Streamlit的网页版Demo会更流畅。 - 命令行
Demo:python cli_demo.py
API部署
- 安装额外的依赖:
pip install fastapi uvicorn -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com - 运行:
python api.py - 通过
POST方法进行调用:
curl -X POST "http://192.168.3.109:8000" -H "Content-Type: application/json" -d "{\"prompt\": \"你好\", \"history\": []}"
- 得到的返回值为
{"response":"你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。","history":[["你好","你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。"]],"status":200,"time":"2023-10-18 14:26:48"}
可视化交互界面
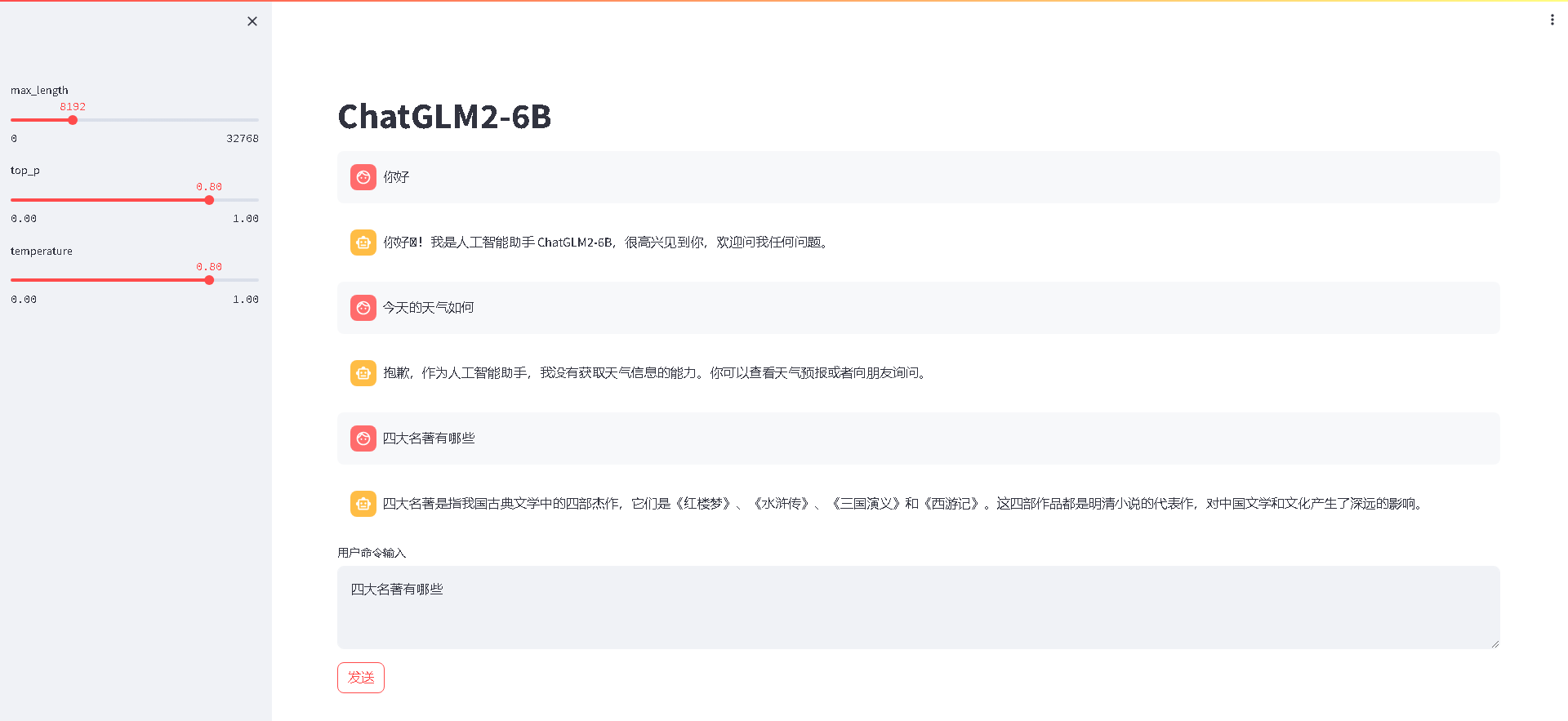
协议
- 本仓库的代码依照
Apache-2.0协议开源,ChatGLM2-6B模型的权重的使用则需要遵循Model License。ChatGLM2-6B权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
总结
- 如果机器的内存资源不多,命令行交互模式、可视化模式、API模式,通常只能运行一种
- 再启动另外一个脚本时,会导致前一个启动的进行被
killed ChatGLM2在多个中文数据集上测试结果优于GPT,比上代版本ChatGLM1有较大改善,受限于训练数据和资源,从实际效果看推理对话内容仍比较简单,本次部署在云端的CPU,推理过程需要几分钟,甚至十几分钟,不过重在体验,看下效果。有兴趣的话使用GPU能够较大程度提高反应速度,几秒就能给出答案。
相关文章:
【ChatGLM2-6B】在只有CPU的Linux服务器上进行部署
简介 ChatGLM2-6B 是清华大学开源的一款支持中英双语的对话语言模型。经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,具有62 亿参数的 ChatGLM2-6B 已经能生成相当符合人类偏好的回答。结合模型量化技术,用户可以在消费级的显卡上进行本地部署&…...

Xilinx IP 10 Gigabit Ethernet Subsystem IP
Xilinx IP 10 Gigabit Ethernet Subsystem IP 10 Gb 以太网子系统在 10GBASE-R/KR 模式下提供 10 Gb 以太网 MAC 和 PCS/PMA,以提供 10 Gb 以太网端口。发送和接收数据接口使用 AXI4 流接口。可选的 AXI4-Lite 接口用于内部寄存器的控制接口。 • 设计符合 10 Gb 以太网规范…...

ubuntu下yolox tensorrt模型部署
TensorRT系列之 Windows10下yolov8 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov8 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov7 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov6 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov5 tensorrt模型加速…...

外汇天眼:外汇投资入门必看!做好3件事,任何人都能提高交易胜率
近年来外汇市场愈来愈热络,许多投资人看准世界金融变化的趋势,纷纷开始入场布局,期望把握行情大赚一笔。 如果你之前没有做过外汇交易,建议最好先透过「外汇天眼学院」学习各种相关的知识与技术分析,等到对外汇有一定的…...

idea dubge 详细
目录 一、概述 二、debug操作分析 1、打断点 2、运行debug模式 3、重新执行debug 4、让程序执行到下一次断点后暂停 5、让断点处的代码再加一行代码 6、停止debug程序 7、显示所有断点 8、添加断点运行的条件 9、屏蔽所有断点 10、把光标移到当前程序运行位置 11、单步跳过 12、…...
短视频矩阵系统/pc、小程序版独立原发源码开发搭建上线
短视频剪辑矩阵系统开发源码----源头搭建 矩阵系统源码主要有三种框架:Spring、Struts和Hibernate。Spring框架是一个全栈式的Java应用程序开发框架,提供了IOC容器、AOP、事务管理等功能。Struts框架是一个MVC架构的Web应用程序框架,用于将数…...

Linux不同格式的文件怎么压缩和解压
Linux不同格式的文件怎么压缩和解压 tar介绍不同格式文件压缩和解压 tar介绍 tar(tape archive)是一个在Unix和类Unix操作系统中用于文件打包和归档的命令行工具。它通常与其他工具(例如gzip、bzip2、xz)一起使用来创建归档文件并…...

Java 领域模型之失血、贫血、充血、胀血模型
1.失血模型 失血模型仅仅包含数据的定义和getter/setter方法,业务逻辑和应用逻辑都放到服务层中。这种类在Java中叫POJO。 action service: 核心业务(复杂度:重) model:简单Set Get dao :数据持…...

ifndef是什么,如何使用?
引言 使用HbuilderX uni-ui模板创建的uni-app项目,main.js文件中看到有如下的注释: // #ifndef VUE3 ...... // #endif // #ifdef VUE3 ...... // #endif 相信很多没有uini-app项目开发经验的朋友,初次接触uni-app项目,可…...

PXIE板卡,4口QSFP+,PCIE GEN3 X8,XILINX FPGA XCVU3P设计
PXIE板卡,4口QSFP,PCIE GEN3 X8,基于XILINX FPGA XCVU3P设计。 1:电路拓扑 ● 支持利用 EEPROM 存储数据; ● 电源时序控制和总功耗监控; 2:电路调试 3:测试 PCIE gen3 x8&#…...
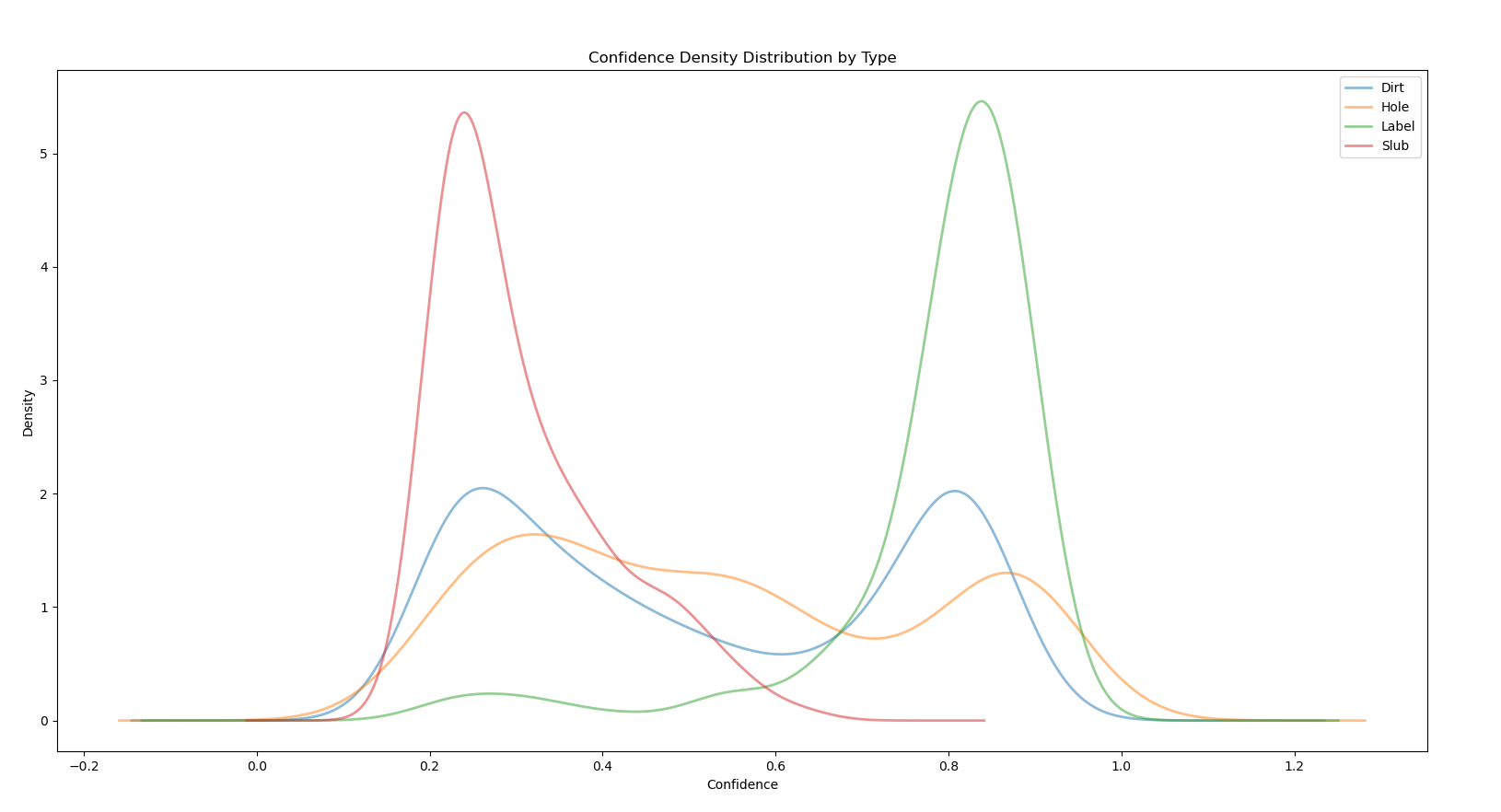
数据分析:密度图
目前拥有的数据如图,三列分别对应瑕疵种类,对应的置信 度,x方向坐标。 现在想要做的事是观看瑕疵种类和置信度之间的关系。 要显示数据分布的集中程度,可以使用以下几种常见的图形来观察: 1、箱线图(Box P…...

docker load and build过程的一些步骤理解
docker load 命令执行原理 “docker load” command, the following steps are followed to load an image from a specified tar file to the local image repository: Parsing the tar file: Docker first parses the tar file to check its integrity and verify the form…...

批量处理图像模板
以下是一个Python模板,用于批量处理图像并将处理后的图像保存在另一个文件夹中。在此示例中,将使用Pillow库来处理图像,可以使用其他图像处理库,根据需要进行修改。 首先,确保已经安装了Pillow库,可以使…...
2023_Spark_实验十四:SparkSQL入门操作
1、将emp.csv、dept.csv文件上传到分布式环境,再用 hdfs dfs -put dept.csv /input/ hdfs dfs -put emp.csv /input/ 将本地文件put到hdfs文件系统的input目录下 2、或者调用本地文件也可以。区别:sc.textFile("file:///D:\\temp\\emp.csv&qu…...
如何将几个模型合并成一个
1、什么时候需要合并模型? 组装和装配:当你需要将多个零件或组件组装成一个整体时,可以合并它们成为一个模型。例如,在制造业中,当需要设计和展示一个完整的机械装置或产品时,可以将各个零部件合并成一个模…...

异常气体识别与飘移
Olfactory Target/Background Odor Detection via Self-expression Model 解决非目标气体检测 摘要:提出了SeELM模型(自表达ELM模型) 分为两步:1.对获得的数据集进行建模,计算出自我表达系数矩阵,2.对于异…...

分类预测 | Matlab实现WOA-BiLSTM鲸鱼算法优化双向长短期记忆神经网络的数据多输入分类预测
分类预测 | Matlab实现WOA-BiLSTM鲸鱼算法优化双向长短期记忆神经网络的数据多输入分类预测 目录 分类预测 | Matlab实现WOA-BiLSTM鲸鱼算法优化双向长短期记忆神经网络的数据多输入分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现WOA-BiLSTM鲸鱼算法…...
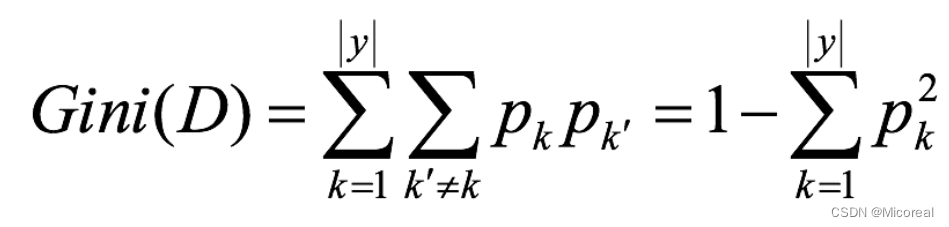
35 机器学习(三):混淆矩阵|朴素贝叶斯|决策树|随机森林
文章目录 分类模型的评估混淆矩阵精确率和召回率 接口介绍其他的补充 朴素贝叶斯基础原理介绍拉普拉斯平滑下面给出应用的例子朴素贝叶斯的思辨 决策树基础使用基本原理信息熵信息增益信息增益率Gini指数 剪枝api介绍 随机森林------集成学习初识基本使用api介绍 分类模型的评估…...

ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+
该错误提示表示您的 OpenSSL 版本过低,无法兼容 urllib3 v2.0。 解决此问题的方法是升级您的 OpenSSL 版本至 1.1.1 或以上。具体操作如下: 方法一: 检查您的 OpenSSL 版本,使用以下命令: openssl version 如果您的…...

webrtc gcc算法(1)
老的webrtc gcc算法,大概流程: 这两个拥塞控制算法分别是在发送端和接收端实现的, 接收端的拥塞控制算法所计算出的估计带宽, 会通过RTCP的remb反馈到发送端, 发送端综合两个控制算法的结果得到一个最终的发送码率,并以…...

揭秘冷轧精密带钢DC03-C340:3大核心特性如何赋能精密制造?
朋友们,今天咱们不聊虚的,就聊聊工厂车间里最实在的东西——材料。你是不是也遇到过这样的烦心事:花大价钱买回来的钢带,一上冲床就开裂,废品率居高不下;或者热处理后表面出现诡异的蓝线,抛光怎…...

ECharts折线图入门学习:从基础到实战的完整指南
引言 折线图是数据可视化中最常用的图表类型之一,特别适合展示数据随时间变化的趋势。ECharts作为一款功能强大的JavaScript可视化库,提供了丰富的配置选项和交互功能,能够轻松创建出专业、美观的折线图。本文将带领大家从零开始学习ECharts折…...
)
别再手动标图了!用CVAT和YOLOv5搭建半自动标注流水线(保姆级避坑指南)
从零构建CVATYOLOv5半自动标注系统:工程化实践与效率革命 标注数据是AI开发中最耗时却无法绕过的环节。我曾为一个客户项目标注3万张工业零件图像,团队3人整整耗费两周——直到发现CVAT与训练好的YOLOv5模型结合,能将效率提升400%。本文将分…...

Git二分法精准定位Bug
Git二分法定位Bug的原理Git二分法基于二分查找算法,通过自动在提交历史中不断缩小范围,定位引入Bug的特定提交。其核心是利用git bisect命令,结合测试脚本或手动验证,高效识别问题根源。准备工作确保本地仓库有完整的提交历史&…...

拆解Meta Ray-Ban同款主控:高通AR1芯片如何让AI眼镜‘听懂’你的手势和眼神?
高通AR1芯片如何赋能Meta Ray-Ban:从异构计算到交互革命 当你的眼镜能读懂眼神、响应手势,甚至预判你的需求时,科技与日常的边界便被重新定义。Meta Ray-Ban智能眼镜之所以成为现象级产品,核心秘密藏在仅指甲盖大小的高通AR1芯片中…...

STM32环境检测系统设计与物联网应用
1. 项目概述这个基于STM32的环境检测系统是我去年为一个工业客户开发的解决方案,经过3个月的迭代优化已经稳定运行了半年多。系统通过多种传感器实时监测环境参数,并将数据上传至OneNet云平台,实现了本地和远程的双重监控。提示:项…...

告别命令行:5分钟掌握ffmpegGUI视频处理新方式
告别命令行:5分钟掌握ffmpegGUI视频处理新方式 【免费下载链接】ffmpegGUI ffmpeg GUI 项目地址: https://gitcode.com/gh_mirrors/ff/ffmpegGUI ffmpegGUI是一款创新的跨平台视频处理工具,它将强大的FFmpeg命令行功能转化为直观的图形界面操作&a…...
)
导入MotorCAD API(需先安装MotorCAD的Python接口)
基于Motorcad的4极6槽 内转子采用内插式磁钢 3000rpm 输出转矩 2.6Nm 效率93%外径 94mm 轴向长度70mm 功率800w 直流母线380V 永磁同步电机(永磁直流无刷)模型(PMSM或者是BLDC) 最近捣鼓了个小功率PMSM模型,用MotorCAD搭了个4极6槽内插式的&a…...

3大核心优势!猫抓视频捕获工具让流媒体解析效率提升100%
3大核心优势!猫抓视频捕获工具让流媒体解析效率提升100% 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓浏览器扩展是一款专业的网…...

硬件解放:开源工具突破设备限制的深度探索指南
硬件解放:开源工具突破设备限制的深度探索指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 当你的设备被厂商贴上"过时"标签&#x…...