Hadoop3教程(十八):MapReduce之MapJoin案例分析
文章目录
- (118)MapJoin案例需求分析
- ReduceJoin的问题
- 如何解决ReduceJoin的问题
- 如何将一个文件主动缓存到集群的内存里
- (119)MapJoin案例代码实现
- 参考文献
(118)MapJoin案例需求分析
ReduceJoin的问题
在ReduceJoin中,合并的操作是在Reduce阶段进行的,所以相比Map阶段,Reduce阶段的处理压力过大。另外,相同的产品ID的数据会进入同一个Reducer中,如果这个产品ID下数据过多,其他产品ID的数据很少,那么会导致前面那个Reducer压力过大,这就是数据倾斜问题。
如何解决ReduceJoin的问题
那如何解决这种问题呢?
比较好的方法是不使用ReduceJoin,使用MapJoin,即在Map阶段实现拼接。
思路简单来说,就是将产品码表放进内存,orders.txt正常切片进入mapper,然后mapper处理的时候,就逐行对orders.txt里的数据进行产品码值的替换。
基于这种方式,MapJoin的适用场景也就很明显了,MapJoin适用于一张或多张表特别小(不能把内存撑爆了),一张表特别大的场景。
如何将一个文件主动缓存到集群的内存里
那问题来了,在Hadoop里怎么把一张表主动缓存到内存当中,且还能在map()里调用呢?
首先我们需要在驱动类里,指定将文件加载到缓存:
//缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file:///e:/cache/pd.txt"));
//如果是集群运行,需要设置HDFS路径
job.addCacheFile(new URI("hdfs://hadoop102:8020/cache/pd.txt"));// MapJoin的话就不需要Reduce阶段了
job.setNumReduceTasks(0);
然后在自定义Mapper类的setup()里,按以下流程编写代码,以读取缓存的文件数据:
//1. 获取缓存的文件;
// 2.循环读取缓存文件中每一行;
// 3. 切割;
// 4. 缓存数据到集合;
setup()执行完成后,才会执行map()。
所以我们最后在map()里,获取一行后,截取到pid,从内存中码表拿到产品中文名,拼接给出就可以。
(119)MapJoin案例代码实现
过了一遍教程,其实就是对上一小节的代码实现。
总的来说,就是只有一个Map阶段,在Map阶段中,在map()处理之前,先把码表读进内存中,然后map()在一行一行读取后,直接使用内存中的码表对指定字段进行替换即可。
对我来讲用处不大,所以这里直接跳过,但还是补充一下代码:
在MapJoinDriver驱动类中添加缓存文件:
package com.atguigu.mapreduce.mapjoin;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;public class MapJoinDriver {public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {// 1 获取job信息Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 设置加载jar包路径job.setJarByClass(MapJoinDriver.class);// 3 关联mapperjob.setMapperClass(MapJoinMapper.class);// 4 设置Map输出KV类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);// 5 设置最终输出KV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);// 加载缓存数据job.addCacheFile(new URI("file:///D:/input/tablecache/pd.txt"));// Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0job.setNumReduceTasks(0);// 6 设置输入输出路径FileInputFormat.setInputPaths(job, new Path("D:\\input"));FileOutputFormat.setOutputPath(job, new Path("D:\\output"));// 7 提交boolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}
}
在MapJoinMapper类中的setup方法中读取缓存文件,并在map()里进行替换:
package com.atguigu.mapreduce.mapjoin;import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;public class MapJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> {private Map<String, String> pdMap = new HashMap<>();private Text text = new Text();//任务开始前将pd数据缓存进pdMap@Overrideprotected void setup(Context context) throws IOException, InterruptedException {//通过缓存文件得到小表数据pd.txtURI[] cacheFiles = context.getCacheFiles();Path path = new Path(cacheFiles[0]);//获取文件系统对象,并开流FileSystem fs = FileSystem.get(context.getConfiguration());FSDataInputStream fis = fs.open(path);//通过包装流转换为reader,方便按行读取BufferedReader reader = new BufferedReader(new InputStreamReader(fis, "UTF-8"));//逐行读取,按行处理String line;while (StringUtils.isNotEmpty(line = reader.readLine())) {//切割一行
//01 小米String[] split = line.split("\t");pdMap.put(split[0], split[1]);}//关流IOUtils.closeStream(reader);}@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//读取大表数据
//1001 01 1String[] fields = value.toString().split("\t");//通过大表每行数据的pid,去pdMap里面取出pnameString pname = pdMap.get(fields[1]);//将大表每行数据的pid替换为pnametext.set(fields[0] + "\t" + pname + "\t" + fields[2]);//写出context.write(text,NullWritable.get());}
}
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
:MapReduce之MapJoin案例分析)
Hadoop3教程(十八):MapReduce之MapJoin案例分析
文章目录 (118)MapJoin案例需求分析ReduceJoin的问题如何解决ReduceJoin的问题如何将一个文件主动缓存到集群的内存里 (119)MapJoin案例代码实现参考文献 (118)MapJoin案例需求分析 ReduceJoin的问题 在R…...

SOAR安全事件编排自动化响应-安全运营实战
SOAR是最近几年安全市场上最火热的词汇之一。各个安全产商都先后推出了相应的产品,但大部分都用得不是很理想。SOAR不同与传统的安全设备,买来后实施部署就完事,SOAR是一个安全运营系统,是实现安全运营过程中人、工具、流程的有效…...

连锁药店的自有品牌之争:老百姓大药房能否突围?
文丨新熔财经 作者丨楷楷 近年来,随着医保谈判药品的“双通道”(即消费者可在有资质的药店买到新进医保的创新药),以及“门诊统筹”将药店纳入医保报销等医改政策出台,药企开始重新重视起零售药店渠道,很…...

智能台灯语音控制丨解放双手
台灯是日常生活中一种常见的照明产品。以往的台灯大多都是采取手动控制,通过按键去对台灯的亮度进行调整。随着科技的发展,台灯也开始走向了智能化。人们已经能够对智能台灯进行语音控制,通过调节灯光开关、色温、灯光亮度等操作,…...

网络库OKHTTP(2)面试题
序、慢慢来才是最快的方法。 背景 OkHttp 是一套处理 HTTP 网络请求的依赖库,由 Square 公司设计研发并开源,目前可以在 Java 和 Kotlin 中使用。对于 Android App 来说,OkHttp 现在几乎已经占据了所有的网络请求操作。 OKHttp源码官网 问1…...

探索Java NIO:究竟在哪些领域能大显身手?揭秘原理、应用场景与官方示例代码
一、NIO简介 Java NIO(New IO)是Java SE 1.4引入的一个新的IO API,它提供了比传统IO更高效、更灵活的IO操作。与传统IO相比,Java NIO的优势在于它支持非阻塞IO和选择器(Selector)等特性,能够更…...

论文阅读 Memory Enhanced Global-Local Aggregation for Video Object Detection
Memory Enhanced Global-Local Aggregation for Video Object Detection Abstract 人类如何识别视频中的物体?由于单一帧的质量低下,仅仅利用一帧图像内的信息可能很难让人们在这一帧中识别被遮挡的物体。我们认为人们识别视频中的物体有两个重要线索&…...

Java 常用类(包装类)
目录 八大Wrapper类包装类的分类 装箱和拆箱包装类和基本数据类型之间的转换常见面试题 包装类方法包装类型和String类型的相互转换包装类常用方法(以Integer类和Character类为例)Integer类和Character类的常用方法 Integer创建机制(面试题&a…...
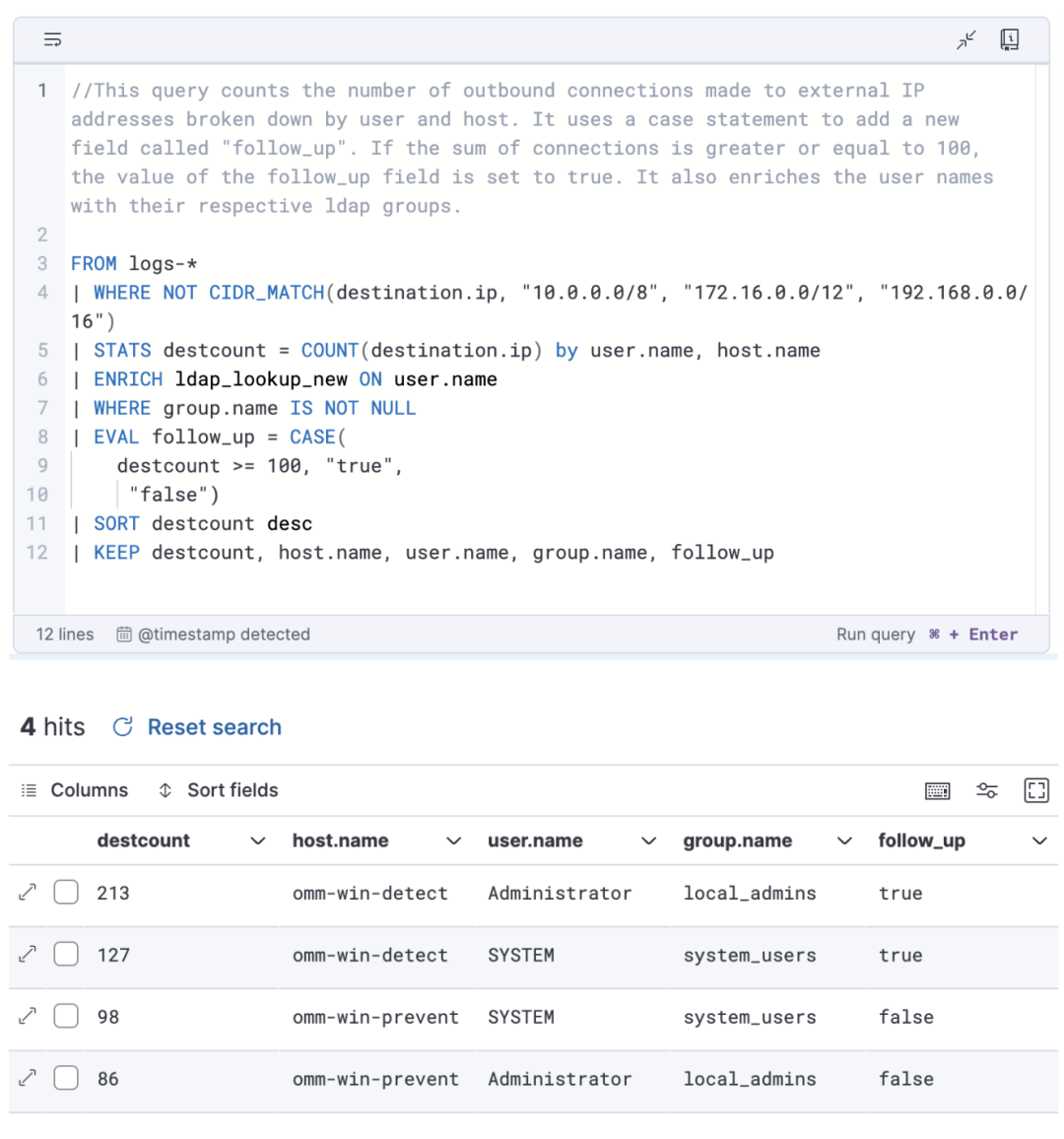
ES|QL:Elasticsearch的 新一代查询语言
作者:李捷 “学会选择很难。学会正确选择更难。而在一个充满无限可能的世界里学会正确选择则更难,也许是太难了。” 巴里-施瓦茨(Barry Schwartz)在《选择的悖论--多就是少》(The Paradox of Choice -More is Less&…...
C语言实现句子中的单词颠倒排序
一、运行结果 二、源代码 # define _CRT_SECURE_NO_WARNINGS # include <stdio.h> # include <assert.h>//实现逆转函数; void reverse(char* left, char* right) {//断言left和right都不能为空;assert(left);assert(right);//循环逆转字母…...

MySQL学习(八)——锁
文章目录 1. 锁概述2. 全局锁2.1 全局锁的必要性2.2 语法2.3 全局锁的特点 3. 表级锁3.1 表锁3.2 元数据锁3.3 意向锁3.4 自增锁 4. 行级锁4.1 介绍4.2 记录锁4.3 间隙锁4.4 临键锁 1. 锁概述 锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,除传…...

让iPhone用电脑的网络上网
让iPhone用电脑的网络上网,可以按照以下步骤操作: 在iPhone上找到并点击“设置”选项,进入“蜂窝移动网络”。打开“个人热点”选项。此时下方的弹出对话框会显示“仅USB”。用数据线将你的iPhone与电脑相连,并在电脑上打开“控制…...
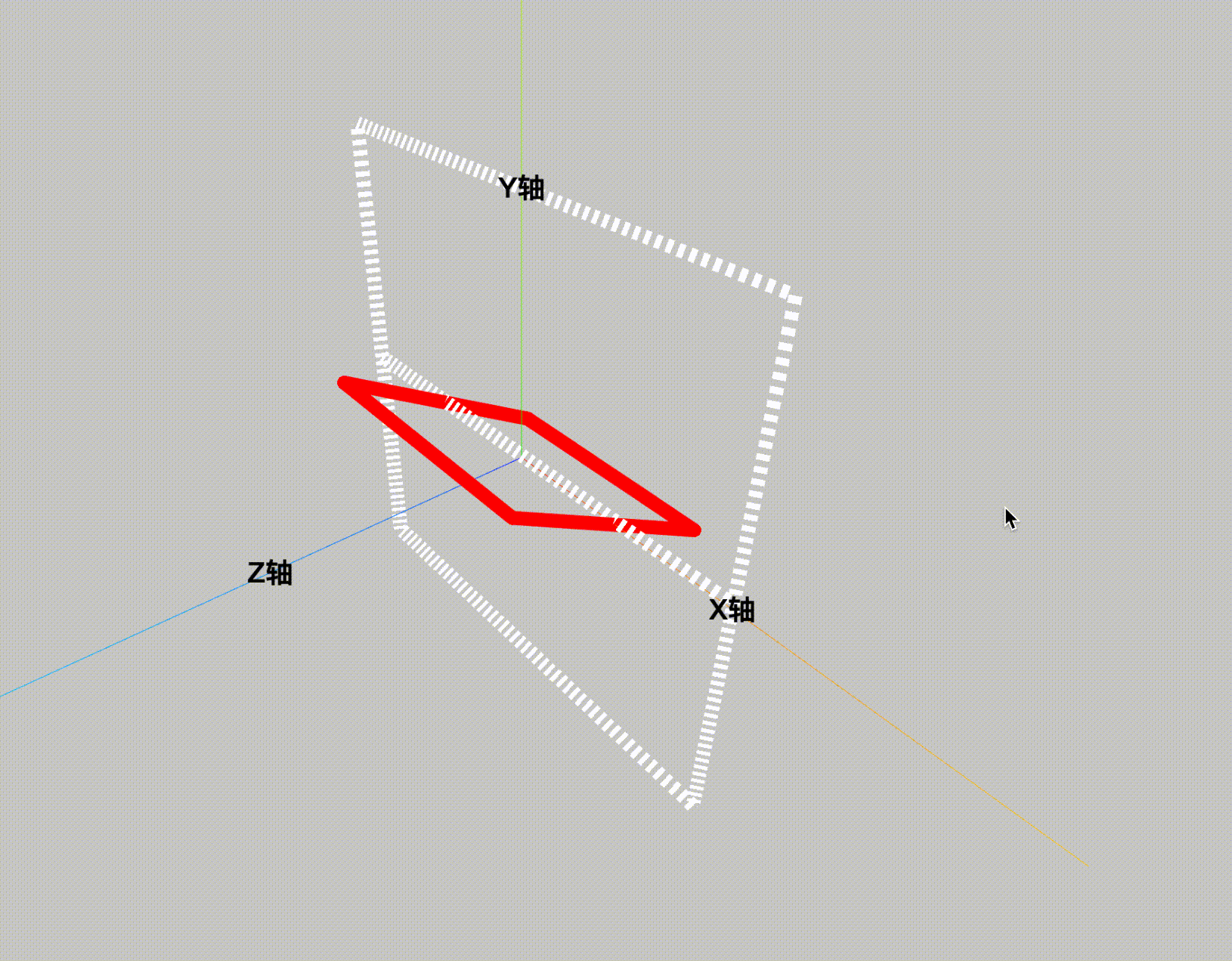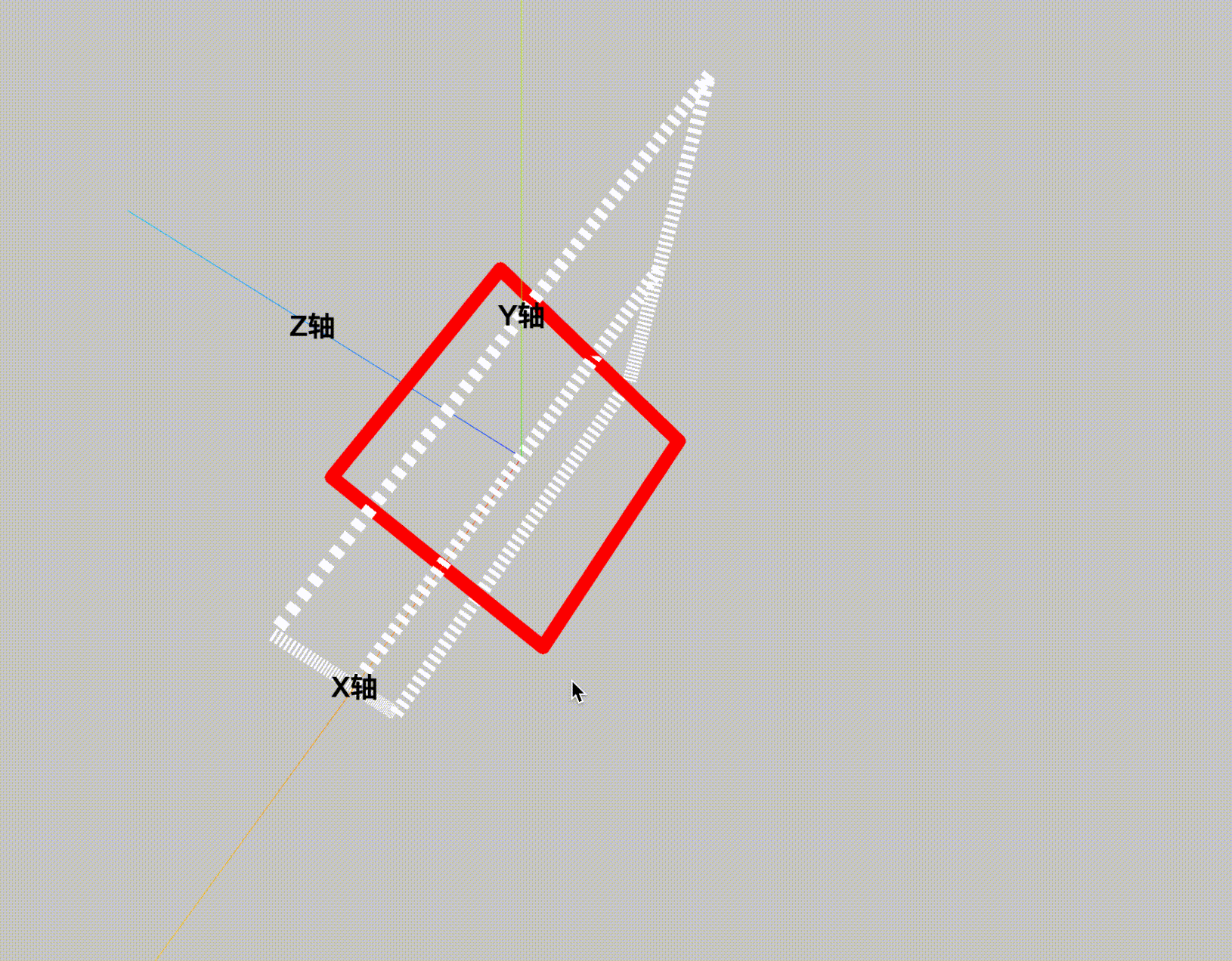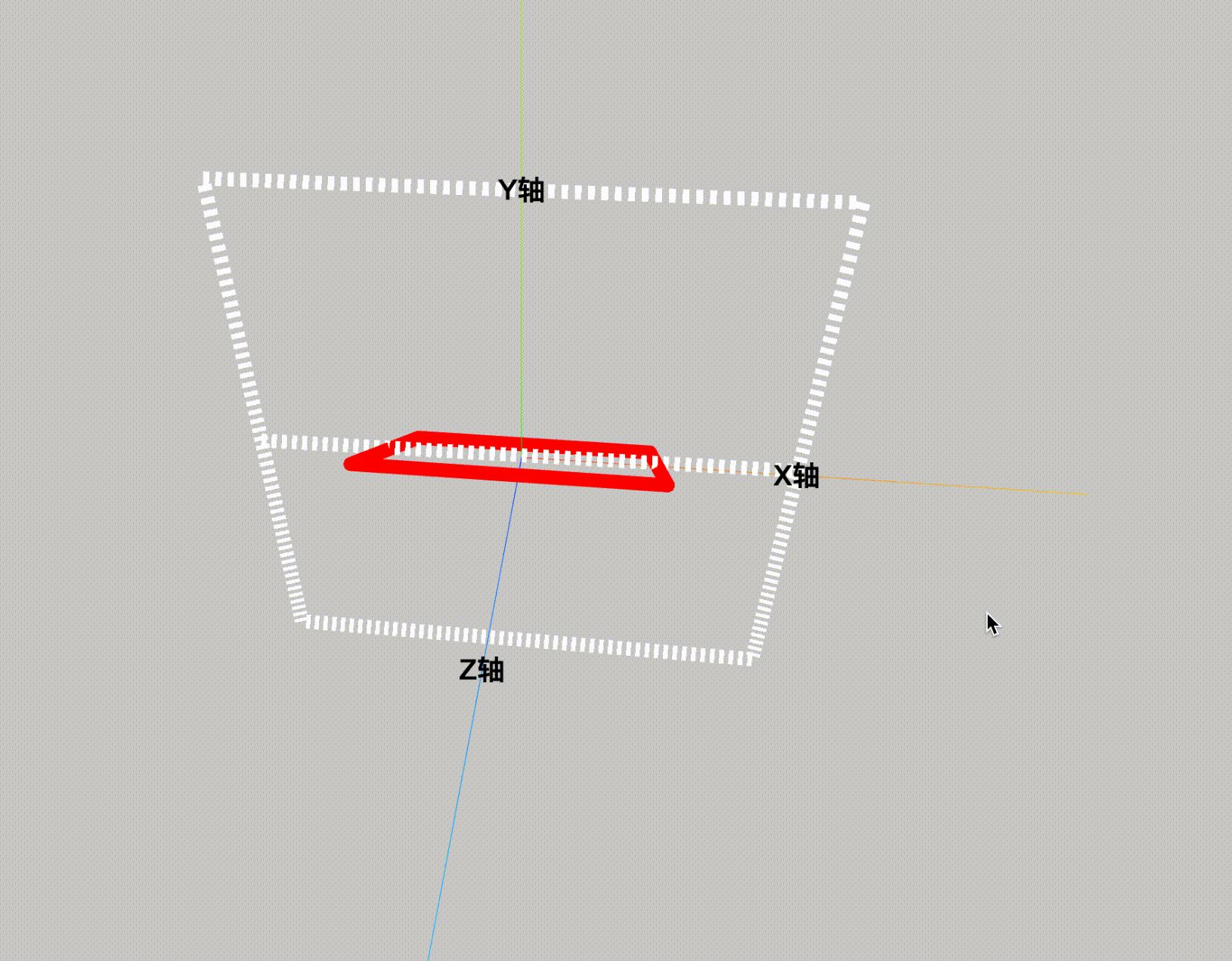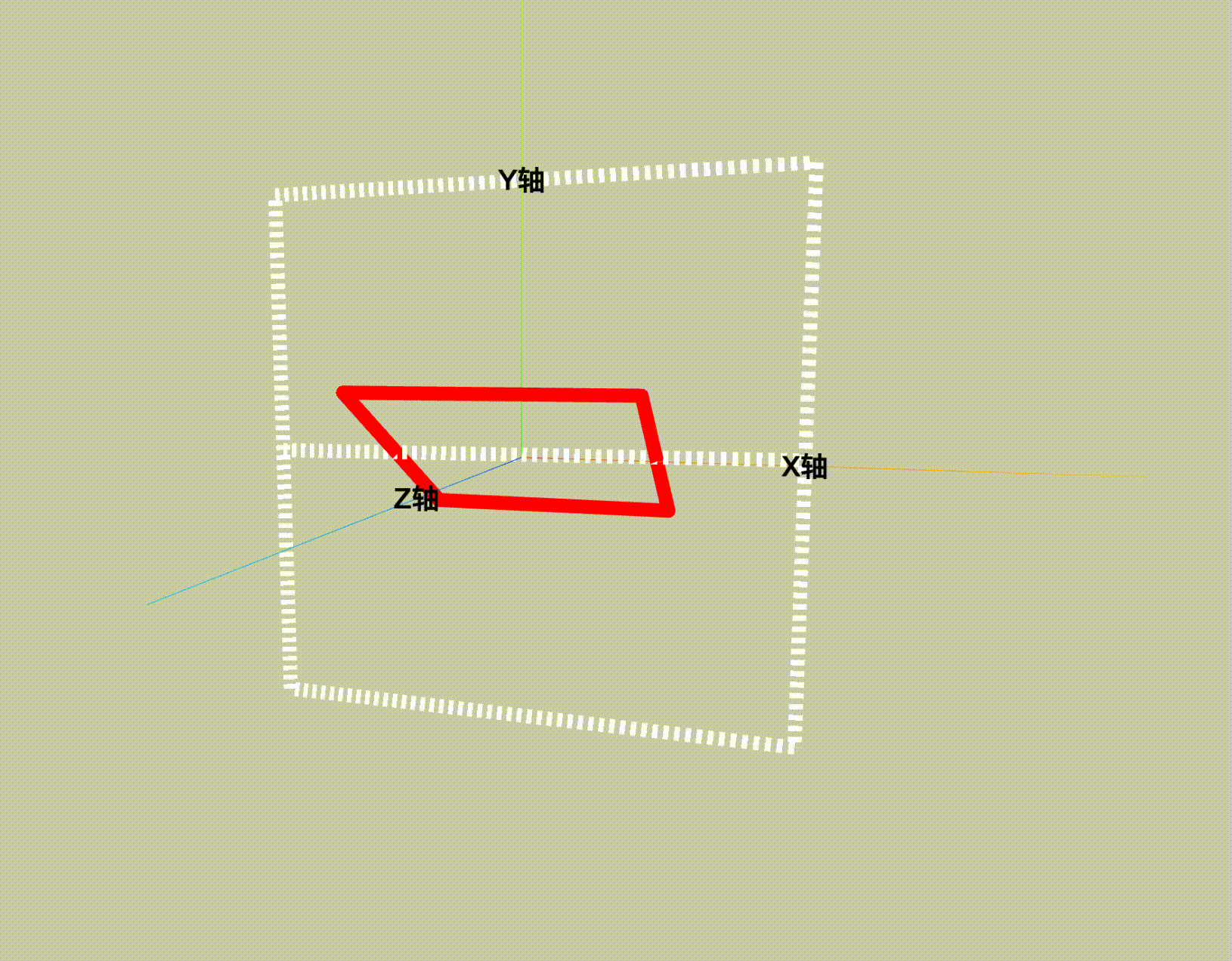
ThreeJS-3D教学十-有宽度的line
webgl中线是没有宽度的,现实的应用中一般做法都是将线拓宽成面来绘制。默认threejs的线宽是无法调节的,需要用有厚度的线 THREE.Line2。 先看效果图: 看下代码: <!DOCTYPE html> <html lang"en"> <he…...

安装Elasticsearch步骤(包含遇到的问题及解决方案)
注:笔者是在centos云服务器环境下安装的Elasticsearch 目录 1.安装前准备 2.下载Elasticsearch 3.启动Elasticsearch 非常容易出问题 第一次运行时,可能出现如下错误: 一、内存不足原因启动失败 二、使用root用户启动问题 三、启动ES自…...

网络编程面试笔试真题
网络编程笔试面试真题 1、关于Linux系统中多线程的信号处理,说法中不正确的是? A:在线程环境霞,产生的信号是传递给整个进程的 B:一般情况下,信号会随机给进程的一个线程 C:对某个信号处理函数…...
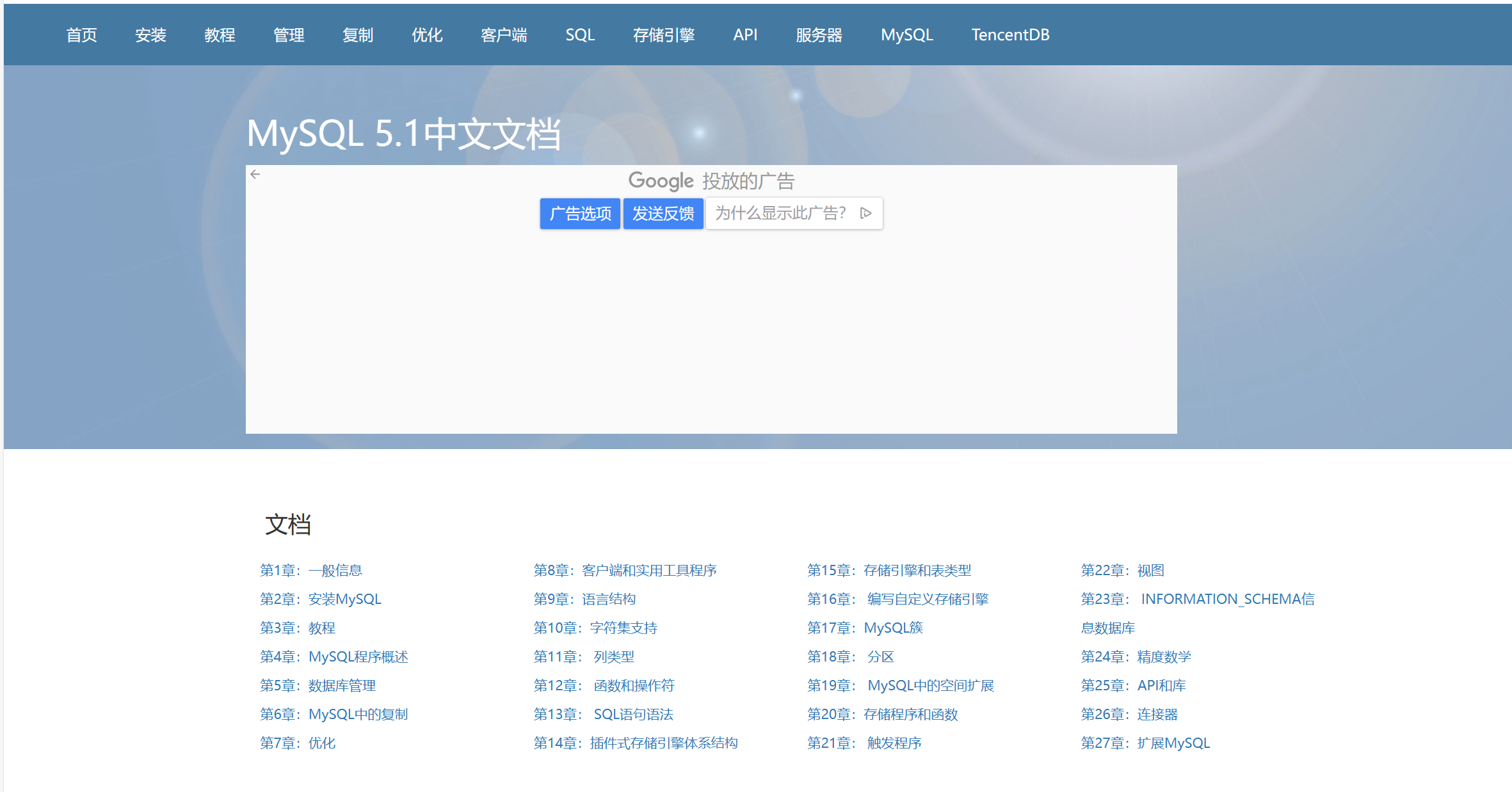
MySQL官方文档如何查看,MySQL中文文档
这里写自定义目录标题 MySQL官方文档如何查看MySQL中文文档 MySQL官方文档如何查看 MySQL官网地址:https://dev.mysql.com/doc/ 比如这里我要找InnoDB架构 MySQL中文文档 MySQL 5.1中文文档地址:https://www.mysqlzh.com/...
)
第七章:最新版零基础学习 PYTHON 教程—Python 列表(第四节 -如何在 Python 中查找列表的长度)
列表是 Python 日常编程不可或缺的一部分,所有 Python 用户都必须学习,了解其实用程序和操作是必不可少的,而且总是有好处的。因此,本文讨论了找到第一个这样的实用程序。使用Python 的列表中的元素。 目录 在 Python 中查找列表的长度...

XPS虽没流行,但还在使用!在Windows 10中打开XPS文件的最佳方法
当Windows Vista发布时,微软推出了XPS格式,这是PDF的替代品。XPS文件格式并不是什么新鲜事,但从未获得过多大的吸引力。 因此,XPS(XML Paper Specification)文件是微软对Adobe PDF文件的竞争对手。尽管XPS…...
23 种设计模式详解(C#案例)
🚀设计模式简介 设计模式(Design pattern)代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时…...

@SpringBootApplication配置了scanBasePackages导致请求一直404,分析下原因
出现RequestMapping注解的Controller类可能是因为SpringBootApplication注解中配置了scanBasePackages导致的请求一直返回404错误。 SpringBootApplication注解是Spring Boot的核心注解之一,它用于启动Spring Boot应用程序。这个注解实际上是一个组合注解ÿ…...

3步打造自平衡机器人:零基础实战DIY攻略
3步打造自平衡机器人:零基础实战DIY攻略 【免费下载链接】Cubli_Mini 项目地址: https://gitcode.com/gh_mirrors/cu/Cubli_Mini 自平衡机器人作为 robotics 领域的经典项目,一直是爱好者入门的理想选择。Cubli_Mini 作为开源项目中的佼佼者&…...

告别重复造轮子:用快马平台高效生成ibbot开发脚手架与核心模块
今天想和大家分享一个提升ibbot开发效率的实用技巧。作为一个经常需要开发对话机器人的程序员,我发现每次从零开始搭建项目结构、编写基础模块特别耗时。最近尝试用InsCode(快马)平台生成项目脚手架,效果出乎意料的好。 项目结构自动生成 平台能根据自然…...

DBShadow横空出世,Dapper.net的天花板盖不住了
一、DBShadow是什么DBShadow是.net开源的高性能ORMDBShadow使用开源项目ShadowSql高效拼接sqlDBShadow使用开源项目PocoEmit.Mapper高效映射查询参数和查询结果也就是说SqlBuilder(ShadowSql)OOM(PocoEmit.Mapper)ORM(DBShadow)二、DBShadow和Dapper对比一下1. Dapper代码await…...
)
从连续到离散:用Python小例子复现Mamba SSM的零阶保持离散化(含完整代码)
从连续到离散:用Python小例子复现Mamba SSM的零阶保持离散化(含完整代码) 在深度学习领域,状态空间模型(State Space Model, SSM)因其对序列数据的强大建模能力而备受关注。Mamba作为SSM的最新演进&#x…...

3步掌握AntiMicroX:让游戏手柄变身全能控制中心
3步掌握AntiMicroX:让游戏手柄变身全能控制中心 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https://gitcode.com/GitHub_Tren…...

实测美胸-年美-造相Z-Turbo:一键部署,效果超乎想象
实测美胸-年美-造相Z-Turbo:一键部署,效果超乎想象 1. 镜像简介与核心特点 美胸-年美-造相Z-Turbo是基于Xinference框架部署的文生图模型服务,专为快速生成高质量图像而设计。这个镜像继承了Z-Image-Turbo的优秀基因,并针对特定…...

深入解析SSL/TLS握手协议:从理论到Wireshark实战分析
1. SSL/TLS协议的前世今生 每次在浏览器地址栏看到那个小锁图标,你有没有好奇过它背后是怎么工作的?这就是SSL/TLS协议在保护我们的数据安全。SSL(安全套接层)和它的继任者TLS(传输层安全)就像网络世界的&q…...

逆向思维:从资源困境到自由获取,猫抓如何重塑你的网页体验
逆向思维:从资源困境到自由获取,猫抓如何重塑你的网页体验 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾面对心仪…...

HunyuanVideo-Foley高算力适配:RTX4090D显存利用率优化至92%实测
HunyuanVideo-Foley高算力适配:RTX4090D显存利用率优化至92%实测 1. 镜像概述与核心优势 HunyuanVideo-Foley私有部署镜像专为视频与音效生成任务深度优化,基于RTX 4090D 24GB显存硬件平台打造。经过CUDA 12.4与驱动550.90.07的针对性调优,…...

GNSS数据处理避坑指南:从CDDIS、IGS等官网下载BSX、DCB文件的保姆级教程
GNSS数据处理避坑指南:从CDDIS、IGS等官网下载BSX、DCB文件的保姆级教程 第一次接触GNSS数据处理时,面对各种数据中心的复杂目录和神秘的文件命名规则,我完全懵了。记得当时为了找一个.BSX文件,整整花了两天时间在不同网站间来回切…...