C/C++每日一练(20230225)

目录
1. 工龄问题求解 ★
2. 字符图形输出 ★★
3. LRU 缓存机制 ★★★
1. 工龄问题求解
给定公司N名员工的工龄,要求按工龄增序输出每个工龄段有多少员工。输入首先给出正整数N,即员工总人数; 随后给出N个整数,即每个员工的工龄,范围在[0, 99]。其中,0-9为第1个工龄段,10-19为第2个工龄段,…,90-99为第10个工龄段。按工龄的递增顺序输出每个工龄的员工个数,格式为:“工龄:人数”。每项占一行。如果人数为0则不输出该项。
代码:
#include <stdio.h>
int main()
{int i,n,a[11]= {0},x;scanf("%d",&n);for(i=0; i<n; i++){scanf("%d",&x);if(x<=9)a[1]++;else if(x>9&&x<=19)a[2]++;else if(x>19&&x<=29)a[3]++;else if(x>29&&x<=39)a[4]++;else if(x>39&&x<=49)a[5]++;else if(x>49&&x<=59)a[6]++;else if(x>59&&x<=69)a[7]++;else if(x>69&&x<=79)a[8]++;else if(x>79&&x<=89)a[9]++;elsea[10]++;}for(i=0;i<=10;i++){if(a[i]>0){printf("%d-%d:%d\n",i*10-10,i*10-1,a[i]);}}
}2. 字符图形输出
编程实现把输入任意整数n后,可打印出n行三角字符阵列图形。例如,输入整数5时,程序运行结果如下:
ENTER A NUMBER:5<回车>
A C F J O
B E I N
D H M
G L
K代码:
#include <iostream>
using namespace std;
char a[100][100];
int main()
{char c = 'A';int n = 5;for (int i = 0; i < n; i++){for (int j = i; j >= 0; j--){a[j][i-j] = c++;}}for (int i = 0; i < n; i++){for (int j = 0; j < n - i; j++){cout << a[i][j] << " ";}cout << endl;}
}3. LRU 缓存机制
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制
实现 LRUCache 类:
LRUCache(int capacity)以正整数作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]输出
[null, null, null, 1, null, -1, null, -1, 3, 4]解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 30000 <= key <= 100000 <= value <= 105- 最多调用
2 * 105次get和put
代码:
#include <bits/stdc++.h>
using namespace std;
class LRUCache
{
private:int _cap;list<pair<int, int>> cache;unordered_map<int, list<pair<int, int>>::iterator> umap;
public:LRUCache(int capacity){_cap = capacity;}int get(int key){auto iter = umap.find(key);if (iter == umap.end())return -1;pair<int, int> kv = *umap[key];cache.erase(umap[key]);cache.push_front(kv);umap[key] = cache.begin();return kv.second;}void put(int key, int value){auto iter = umap.find(key);if (iter != umap.end()){cache.erase(umap[key]);cache.push_front(make_pair(key, value));umap[key] = cache.begin();return;}if (cache.size() == _cap){auto iter = cache.back();umap.erase(iter.first);cache.pop_back();cache.push_front(make_pair(key, value));umap[key] = cache.begin();}else{cache.push_front(make_pair(key, value));umap[key] = cache.begin();}}
};int main()
{LRUCache Cache = LRUCache(2);Cache.put(1, 1); // 缓存是 {1=1}Cache.put(2, 2); // 缓存是 {1=1, 2=2}cout << Cache.get(1) << endl; // 返回 1Cache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}cout << Cache.get(2) << endl; // 返回 -1 (未找到)Cache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}cout << Cache.get(1) << endl; // 返回 -1 (未找到)cout << Cache.get(3) << endl; // 返回 3cout << Cache.get(4) << endl; // 返回 4return 0;
} 以下代码摘自CSDN博客的不同文章(已附原文出处链接)
代码2:
#include <bits/stdc++.h>
using namespace std;class LRUCache {struct node{int key;int value;struct node *pre;struct node *next;node(int k,int v):key(k),value(v),pre(NULL),next(NULL){}};int cap=0; //表示当前容量node *head,*tail;void push_front(node *cur) //头部插入{if(cap==0){head=cur;tail=cur;cap++;}else{cur->next=head;head->pre=cur;head=cur;cap++;} }void push_back(node *cur) //尾部插入{if(cap==0){head=cur;tail=cur;cap++;}else{cur->pre=tail;tail->next=cur;tail=cur;cap++;} }void pop_front() //头部弹出 {if(cap==0) return;node *p=head;head=p->next;delete p;cap--;}void pop_back() //尾部弹出 {if(cap==0) return;node *p=tail;tail=p->pre;delete p;cap--;}void sethead(node *p) //将p结点变为新的头部{if(p==head) return;else if(p==tail){p->pre->next=NULL;tail=p->pre;p->next=head;head->pre=p;p->pre==NULL;head=p;}else{p->pre->next=p->next;p->next->pre=p->pre;p->next=head;head->pre=p;p->pre=NULL;head=p;}}
public:LRUCache(int capacity): m_capacity(capacity){}int get(int key) {if(!m.count(key)) return -1; //不在哈希表中,直接返回-1node *p=m[key];sethead(p);//提到链表头部return head->value;}void put(int key, int value) {if(!m.count(key)) //如果不在缓存中{node *cur=new node(key,value);m[key]=cur; //加入哈希表//1.容量已满,去掉尾结点从头插入if(cap==m_capacity){m.erase(tail->key);//将要弹出的尾结点对应映射从哈希表中删除 pop_back();push_front(cur); //头部插入}//2.容量未满,直接头部插入else push_front(cur); }else //在缓存中 ,旧值更新 {node *p=m[key];p->value=value;sethead(p); //提到链表头部}}
private:int m_capacity;unordered_map<int,node*>m;
};int main()
{LRUCache Cache = LRUCache(2);Cache.put(1, 1); // 缓存是 {1=1}Cache.put(2, 2); // 缓存是 {1=1, 2=2}cout << Cache.get(1) << endl; // 返回 1Cache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}cout << Cache.get(2) << endl; // 返回 -1 (未找到)Cache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}cout << Cache.get(1) << endl; // 返回 -1 (未找到)cout << Cache.get(3) << endl; // 返回 3cout << Cache.get(4) << endl; // 返回 4return 0;
} 来源:LRU缓存机制的实现(C++版本)_作者:一坨大西瓜
代码3:
#include <bits/stdc++.h>
using namespace std;class LRUCache {
public:struct ListNode {//使用结构体建立双向链表,包含前驱、后继、key-value和构造函数ListNode *pre;ListNode *next;int key;int val;ListNode(int _key, int _val) : pre(NULL), next(NULL), key(_key), val(_val) {};};LRUCache(int capacity) : max_cnt(capacity), cnt(0) {head = new ListNode(-1, -1);tail = new ListNode(-1, -1);head->next = tail;//首尾相接tail->pre = head;}void update(ListNode *p) {//更新链表if (p->next == tail) return;//将p与前后连接断开p->pre->next = p->next;p->next->pre = p->pre;//将p插入尾节点p->pre = tail->pre;p->next = tail;tail->pre->next = p;tail->pre = p;}int get(int key) {//获取值unordered_map<int, ListNode*>::iterator it = m.find(key);if (it == m.end()) return -1;ListNode *p = it->second;//提取p的value后更新pupdate(p);return p->val;}void put(int key, int value) {if (max_cnt <= 0) return;unordered_map<int, ListNode*>::iterator it = m.find(key);//查找key值是否存在//先延长链表再判断,如果超出,则删除节点if (it == m.end()) {//如果不存在,则放在双向链表头部,即链表尾ListNode *p = new ListNode(key, value);//初始化key和valuem[key] = p;//建立新的map//在尾部插入新节点p->pre = tail->pre;tail->pre->next = p;tail->pre = p;p->next = tail;cnt++;//计数+1if (cnt > max_cnt) {//如果计数大于了缓存最大值//删除头结点ListNode *pDel = head->next;head->next = pDel->next;pDel->next->pre = head;//在链表中删除后,需要在map中也删除掉unordered_map<int, ListNode*>::iterator itDel = m.find(pDel->key);m.erase(itDel);//delete pDel;cnt--;}}else {//如果存在ListNode *p = it->second;//因为map的second存储的是key对应的链表地址,所以将其赋给pp->val = value;//计算p内存块中的value值update(p);//更新p}}private:int max_cnt;//最大缓存数量int cnt;//缓存计数unordered_map<int, ListNode*> m;//记录数据和其链表地址ListNode *head;//链表头ListNode *tail;//链表尾
};int main()
{LRUCache Cache = LRUCache(2);Cache.put(1, 1); // 缓存是 {1=1}Cache.put(2, 2); // 缓存是 {1=1, 2=2}cout << Cache.get(1) << endl; // 返回 1Cache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}cout << Cache.get(2) << endl; // 返回 -1 (未找到)Cache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}cout << Cache.get(1) << endl; // 返回 -1 (未找到)cout << Cache.get(3) << endl; // 返回 3cout << Cache.get(4) << endl; // 返回 4return 0;
} 来源:C++ 实现LRU缓存机制_作者:SanfordZhu
代码4:
#include <bits/stdc++.h>
using namespace std;class LRUCache {
public:int cap;list<pair<int,int>> li;unordered_map<int, list<pair<int,int>>::iterator > up;LRUCache(int capacity) {cap=capacity;}int get(int key) {if(up.find(key)!=up.end()){auto tmp= *up[key]; //获取该元素值li.erase(up[key]); //在链表中去除该元素,erase参数为迭代器li.push_front(tmp); //将该元素放在链表头部up[key]=li.begin(); //重新索引该元素return tmp.second; //返回值}return -1;}void put(int key, int value) {if(up.find(key)!=up.end()){auto tmp=*up[key];li.erase(up[key]);tmp.second=value;li.push_front(tmp);up[key]=li.begin();}else{if(up.size()>=cap){auto tmp=li.back();li.pop_back();up.erase(tmp.first); }li.push_front(make_pair(key,value));up[key]=li.begin(); } }
};int main()
{LRUCache Cache = LRUCache(2);Cache.put(1, 1); // 缓存是 {1=1}Cache.put(2, 2); // 缓存是 {1=1, 2=2}cout << Cache.get(1) << endl; // 返回 1Cache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}cout << Cache.get(2) << endl; // 返回 -1 (未找到)Cache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}cout << Cache.get(1) << endl; // 返回 -1 (未找到)cout << Cache.get(3) << endl; // 返回 3cout << Cache.get(4) << endl; // 返回 4return 0;
} 来源:[LeetCode][C++] LRU缓存机制_作者:消失男孩
附录
页面置换算法
在进程运行过程中,若其所要访问的页面不在内存而需把它们调入内存,但内存已无空闲空间时,为了保证该进程能正常运行,系统必须从内存中调出一页程序或数据送磁盘的对换区中。但应将哪个页面调出,须根据一定的算法来确定。通常,把选择换出页面的算法称为页面置换算法(Page-Replacement Algorithms)。 置换算法的好坏, 将直接影响到系统的性能。一个好的页面置换算法,应具有较低的页面更换频率。从理论上讲,应将那些以后不再会访问的页面换出,或把那些在较长时间内不会再访问的页面调出。存在着许多种置换算法,它们都试图更接近于理论上的目标。
最近最少使用(LRU)
是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
最佳置换算法(OPT)
这是一种理想情况下的页面置换算法,但实际上是不可能实现的。该算法的基本思想是:发生缺页时,有些页面在内存中,其中有一页将很快被访问(也包含紧接着的下一条指令的那页),而其他页面则可能要到10、100或者1000条指令后才会被访问,每个页面都可以用在该页面首次被访问前所要执行的指令数进行标记。最佳页面置换算法只是简单地规定:标记最大的页应该被置换。这个算法唯一的一个问题就是它无法实现。当缺页发生时,操作系统无法知道各个页面下一次是在什么时候被访问。虽然这个算法不可能实现,但是最佳页面置换算法可以用于对可实现算法的性能进行衡量比较。
先进先出置换算法(FIFO)
最简单的页面置换算法是先入先出(FIFO)法。这种算法的实质是,总是选择在主存中停留时间最长(即最老)的一页置换,即先进入内存的页,先退出内存。理由是:最早调入内存的页,其不再被使用的可能性比刚调入内存的可能性大。建立一个FIFO队列,收容所有在内存中的页。被置换页面总是在队列头上进行。当一个页面被放入内存时,就把它插在队尾上。这种算法只是在按线性顺序访问地址空间时才是理想的,否则效率不高。因为那些常被访问的页,往往在主存中也停留得最久,结果它们因变“老”而不得不被置换出去。
FIFO的另一个缺点是,它有一种异常现象,即在增加存储块的情况下,反而使缺页中断率增加了。当然,导致这种异常现象的页面走向实际上是很少见的。
最少使用(LFU)置换算法
在采用最少使用置换算法时,应为在内存中的每个页面设置一个移位寄存器,用来记录该页面被访问的频率。该置换算法选择在之前时期使用最少的页面作为淘汰页。由于存储器具有较高的访问速度,例如100 ns,在1 ms时间内可能对某页面连续访问成千上万次,因此,通常不能直接利用计数器来记录某页被访问的次数,而是采用移位寄存器方式。每次访问某页时,便将该移位寄存器的最高位置1,再每隔一定时间(例如100 ns)右移一次。这样,在最近一段时间使用最少的页面将是∑Ri最小的页。LFU置换算法的页面访问图与LRU置换算法的访问图完全相同;或者说,利用这样一套硬件既可实现LRU算法,又可实现LFU算法。应该指出,LFU算法并不能真正反映出页面的使用情况,因为在每一时间间隔内,只是用寄存器的一位来记录页的使用情况,因此,访问一次和访问10 000次是等效的。
——以上附录文字来源于百度百科
相关文章:
C/C++每日一练(20230225)
目录 1. 工龄问题求解 ★ 2. 字符图形输出 ★★ 3. LRU 缓存机制 ★★★ 1. 工龄问题求解 给定公司N名员工的工龄,要求按工龄增序输出每个工龄段有多少员工。输入首先给出正整数N,即员工总人数; 随后给出N个整数,即每个员工…...

nyist最终淘汰赛第一场
我出的题喜欢吗 我要水题解所以每一篇题解都分一个博客 A 题解链接: Atcoder abc257 E_霾まる的博客-CSDN博客 构造贪心题 在本次淘汰赛中较难 B 题解链接: atcoder abc217 D_霾まる的博客-CSDN博客 STL二分题, 当然你可以数组二分, 相对麻烦一点 在本次淘汰赛中较简单…...

《零成本实现Web自动化测试--基于Selenium》 Selenium-RC
一. 简介 Selenium-RC可以适应更复杂的自动化测试需求,而不仅仅是简单的浏览器操作和线性执行。Selenium-RC能够充分利用编程语言来构建更复杂的自动化测试案例,例如读写文件、查询数据库和E-mail邮寄测试报告。 当测试案例遇到selenium-IDE不支持的逻辑…...
)
来阿里我的收获是什么?(未完待续)
不知不觉来阿里两年多了,每天都过的很充实,感觉这段时间没有学到什么东西,但是又觉得收获满满,恰好又好久没有动笔写过些什么了,所以有了这个动笔念头。 之前技术方面记录的比较多,这次就记录一些比较磨心的…...

golang net/http库的学习
net/http 是 Golang 标准库中用来构建 HTTP 服务器和客户端的包,它提供了很多功能强大的方法和接口,可以让您方便地构建和处理 HTTP 请求和响应。下面是一些学习 net/http 的建议: 了解 HTTP 协议。在学习 net/http 之前,建议先了…...
)
Spring(AOP)
目录 1. 预备知识-动态代理 1.1 什么是动态代理1.2 动态代理的优势1.3 基于JDK动态代理实现2. AOP 2.1 基本概念2.2 AOP带来的好处3. Spring AOP 3.1 前置通知3.2 后置通知3.3 环绕通知3.4 异常通知3.5 适配器 1. 预备知识-动态代理 1.1 什么是动态代理 动态代理利用Java的反…...
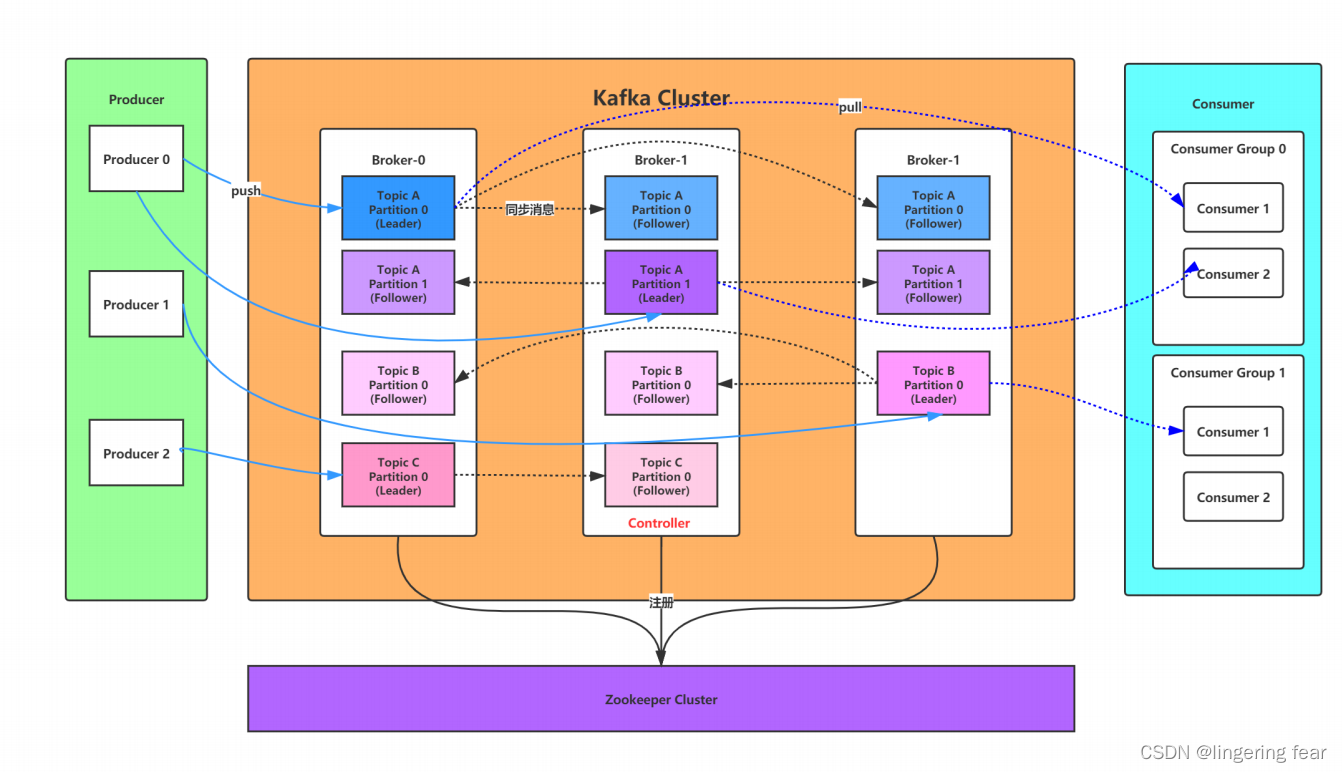
服务搭建篇(六) Kafka + Zookeeper集群搭建
一.Zookeeper 1.什么是Zookeeper ZooKeeper 是一个开源的分布式协调框架,是Apache Hadoop 的一个子项目,主要 用来解决分布式集群中应用系统的一致性问题。Zookeeper 的设计目标是将那些复杂且容 易出错的分布式一致性服务封装起来,构成一个…...

Go基础-可变参数函数
文章目录1 定义2 语法3 给可变函数参数传入切片4 修改可变参数函数中的切片1 定义 可变参数函数是一种参数个数可变的函数。 2 语法 语法 //关键字 函数名(参数1, elems为T类型的可变参数) 返回值类型 func name(params type, elems ...T) returntype{// 函数体 }…...
kali环境搭建
一、渗透为什么要使用kali? 1、系统开源 kali linux实际上是开源的操作系统,其中内置了几百种工具而且是免费的,可以非常方便的为测试提供上手即用的整套工具,而不需要繁琐的搭建环境,及收集工具下载安装等步骤 2、系统…...
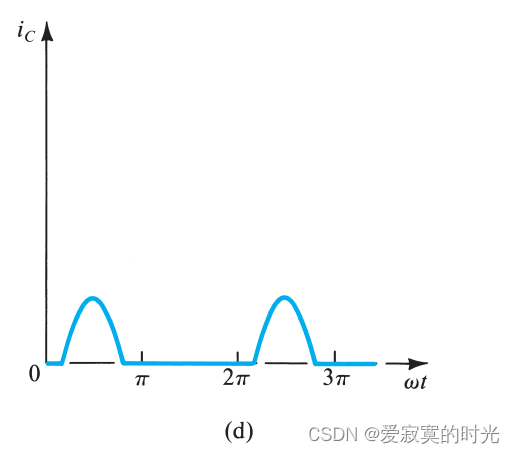
电子技术——输出阶类型
电子技术——输出阶类型 输出阶作为放大器的最后一阶,其必须有较低的阻抗来保证较小的增益损失。作为放大器的最后一阶,输出阶需要处理大信号类型,因此小信号估计模型不适用于输出阶。尽管如此,输出阶的线性也非常重要。实际上&a…...

C++设计模式(21)——中介者模式
亦称: 调解人、控制器、Intermediary、Controller、Mediator 意图 中介者模式是一种行为设计模式, 能让你减少对象之间混乱无序的依赖关系。 该模式会限制对象之间的直接交互, 迫使它们通过一个中介者对象进行合作。 问题 假如你有一个创建…...

Gin获取Response Body引发的OOM
有轮子尽量用轮子 😭 😭 😭 😭 😭 😭 我们在开发中基于Gin开发了一个Api网关,但上线后发现内存会在短时间内暴涨,然后被OOM kill掉。具体内存走势如下图: 放大其中一次 在…...

不同方案特性对比
特性对比项 2.4G 蓝牙 868M WIFI 通信速率 低 低 低 高 距离(实用可靠) 20米 10米 30米 15米 确定性 高 低 高 高 可靠性(距离内) 高 低 高 高 刷新一个标签时间(通常) 0.5-1s …...
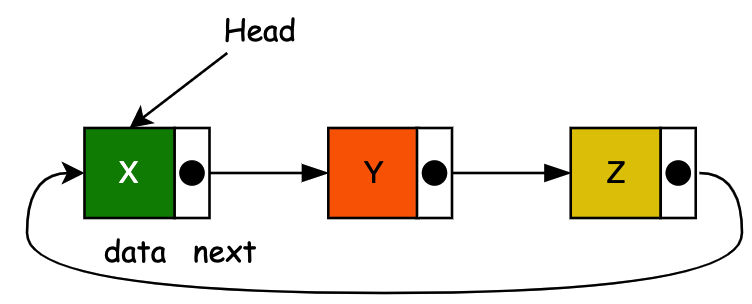
线性数据结构:链表 LinkList
一、前言 链表的历史 于1955-1956年,由兰德公司的Allen Newell、Cliff Shaw和Herbert A. Simon开发了链表,作为他们的信息处理语言的主要数据结构。链表的另一个早期出现是由 Hans Peter Luhn 在 1953 年 1 月编写的IBM内部备忘录建议在链式哈希表中使…...
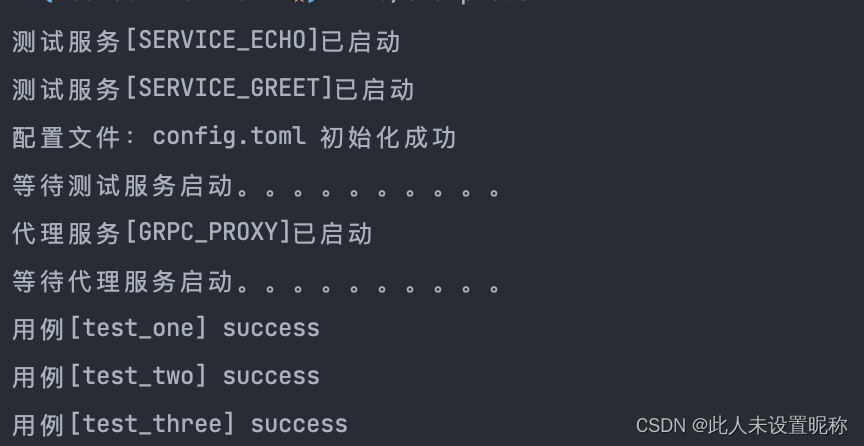
对restful的支持 rust-grpc-proxy
目录前言快速体验说明1. 启动目标服务2. 启动代理3. 测试4. example.sh尾语前言 继上一篇博文的展望,这个月rust-grpc-proxy提供了对restful的简单支持。 并且提供了完成的用例,见地址如下, https://github.com/woshihaoren4/grpc-proxy/tre…...
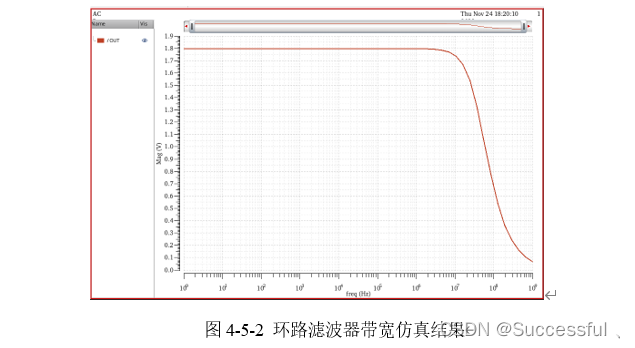
【模拟集成电路】环路滤波器(LPF)设计
环路滤波器 LPF 设计 前言环路滤波器设计仿真结果各部分链接链接:前言 本文主要内容是对环路滤波器 模块设计设计进行阐述,LPF在电荷泵频率综合器中,主要作用是进行滤波,消除毛刺,因此一个简单的RC就可以起到很好的效果…...

adb及cmd部分常用命令
adb及cmd部分常用命令cmd常用命令adb常用命令内存/cpu相关此文章日常记录,有可能存在不准确的地方,仅供参考即可。 cmd常用命令 返回上一级: cd… 进入指定盘: D: 进入指定路径: cd 文件路径 查看子文件列表…...
ProtoBuf介绍
1 编码和解码编写网络应用程序时,因为数据在网络传输的都是二进制字节码数据,在发送数据时进行编码,在接受数据时进行解码codec(编码器)的组成部分有2个:decoder(解码器)和encoder&a…...

数据结构:完全二叉树开胃菜小练习
目录 一.前言 二.完全二叉树的重要结构特点 三.完全二叉树开胃菜小练习 1.一个重要的数学结论 2.简单的小练习 一.前言 关于树及完全二叉树的基础概念(及树结点编号规则)参见:http://t.csdn.cn/imdrahttp://t.csdn.cn/imdra 完全二叉树是一种非常重要的数据结构: n个结点的…...

mybatis与jpa
1、官方文档 mybatis:mybatis-spring – jpa:https://springdoc.cn/spring-data-jpa/ 应用文档 jpa详解_java菜鸟1的博客-CSDN博客 JPA简介及其使用详解_Tourist-xl的博客-CSDN博客_jpa的作用 2、使用比较 mybatis一般用于互联网性质的项目&#x…...

如何用openpilot升级你的驾驶体验:让300+车型秒变智能座驾
如何用openpilot升级你的驾驶体验:让300车型秒变智能座驾 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tren…...

利用Taotoken审计日志功能追踪与分析团队内部的模型使用情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken审计日志功能追踪与分析团队内部的模型使用情况 对于项目管理者或安全运维人员而言,清晰掌握团队内部大模…...

LDDC终极指南:如何快速获取精准的逐字歌词
LDDC终极指南:如何快速获取精准的逐字歌词 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目地址: https:/…...

Java全栈工程师面试实录:从基础到微服务的深度技术对话
Java全栈工程师面试实录:从基础到微服务的深度技术对话 面试官与程序员的对话 面试官(李哥): 你好,欢迎来参加我们公司的面试。我是李哥,负责技术面试。先简单介绍一下你自己吧。 程序员(张浩&a…...

告别手动下载:用CNKI-download轻松实现知网文献批量获取
告别手动下载:用CNKI-download轻松实现知网文献批量获取 【免费下载链接】CNKI-download :frog: 知网(CNKI)文献下载及文献速览爬虫 (Web Scraper for Extracting Data) 项目地址: https://gitcode.com/gh_mirrors/cn/CNKI-download 还在为毕业论文的文献收…...

告别繁琐操作:用VSCode插件‘Open in Browser’和‘CSS Peek’打造流畅的实时预览调试工作流
极速开发实战:VSCode插件组合拳实现HTML/CSS无缝调试 每次修改完CSS样式都要手动切换到浏览器刷新页面?在庞大的代码库中寻找某个CSS定义像大海捞针?这些问题困扰着无数前端开发者。今天我们将解锁VSCode中两个看似简单却威力巨大的插件——O…...

终极QRazyBox指南:免费在线修复损坏二维码的完整教程
终极QRazyBox指南:免费在线修复损坏二维码的完整教程 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否遇到过重要二维码因为打印模糊、水渍污损或物理磨损而无法扫描的困扰&a…...

罗技鼠标宏逆向工程:PUBG后坐力补偿系统的架构设计与实现
罗技鼠标宏逆向工程:PUBG后坐力补偿系统的架构设计与实现 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在竞技射击游戏中ÿ…...
终极免费实时屏幕翻译工具:Translumo完全使用指南
终极免费实时屏幕翻译工具:Translumo完全使用指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾经因…...

AI时代,那些还在知乎认真回答问题的人
文/窦文雪编辑/李乐2023年5月1日,德里克文坐在电脑前,终于决定发出一些东西。那一天对他来说,更像是某种迟到多年的开场。此前十多年,他一直是知乎上一个安静的旁观者。很多时候,他躲在页面背后,看各个领域…...